简单的 OCR 识别验证码 Demo | Keras 实现_XianxinMao的博客
How to implement an OCR model using CNNs, RNNs, and CTC loss.
This example demonstrates a simple OCR model built with the Functional API. Apart from combining CNN and RNN, it also illustrates how you can instantiate a new layer and use it as an “Endpoint layer” for implementing CTC loss. For a detailed guide to layer subclassing, please check out this page in the developer guides.
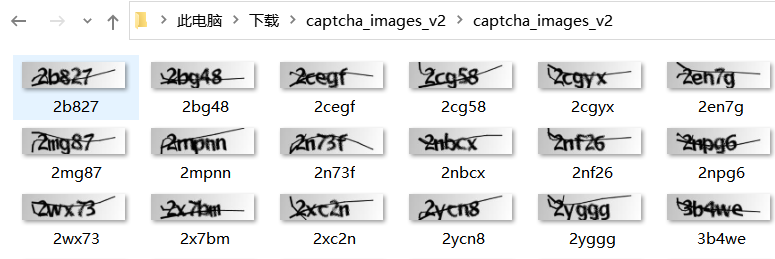
我把本次用到的数据集下载过来了,我们要解决的是验证码识别问题,然后每张图片里的验证码就是图片名称
The dataset contains 1040 captcha files as png images. The label for each sample is a string, the name of the file (minus the file extension). We will map each character in the string to an integer for training the model. Similary, we will need to map the predictions of the model back to strings. For this purpose we will maintain two dictionaries, mapping characters to integers, and integers to characters, respectively.
关于这篇 OCR 识别验证码文章,我只会解读关键代码部分,完整的代码我会放在 Github 仓库: https://github.com/MaoXianXin/Tensorflow_tutorial/blob/ViT/OCR/demo.py,大家可以自取。
# Get list of all the images
images = sorted(list(map(str, list(data_dir.glob("*.png")))))
labels = [img.split(os.path.sep)[-1].split(".png")[0] for img in images]
characters = set(char for label in labels for char in label)
print("Number of images found: ", len(images))
print("Number of labels found: ", len(labels))
print("Number of unique characters: ", len(characters))
print("Characters present: ", characters)
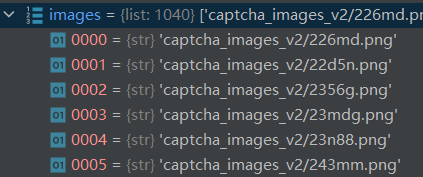
images 的展示如下所示,所以此处我们得到的 images 其实是一个图片路劲列表
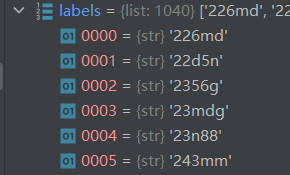
labels 的展示结果如下所示,这里每个 labels 里的元素都是和上面的 images 的元素一一对应的。
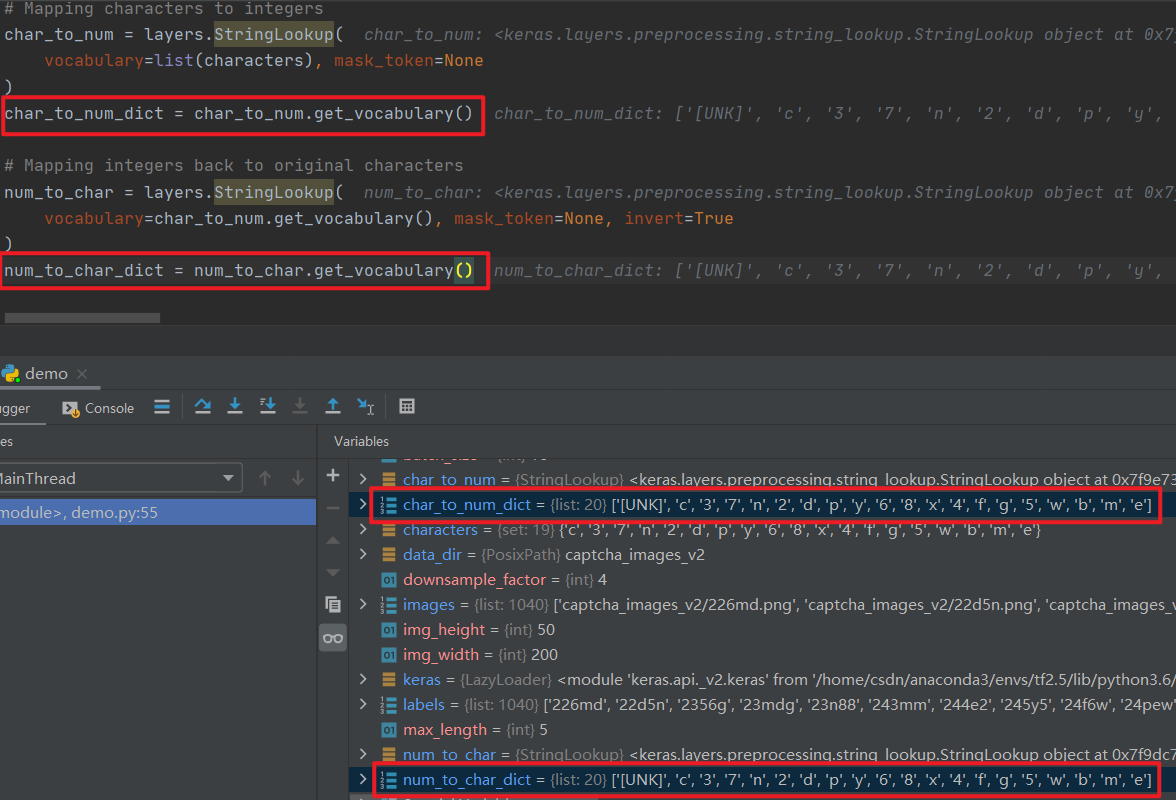
这里我们通过 set 进行去重,最后得到了 1040 张图片的 label name 所用到的所有字符集合

# Mapping characters to integers
char_to_num = layers.StringLookup(
vocabulary=list(characters), mask_token=None
)
# Mapping integers back to original characters
num_to_char = layers.StringLookup(
vocabulary=char_to_num.get_vocabulary(), mask_token=None, invert=True
)
下图展示上面代码中的 vocabulary,也就是我们基于 characters 的 19 个字符,建立起来的字典,用于 StringLookup
_, ax = plt.subplots(4, 4, figsize=(10, 5))
for batch in train_dataset.take(1):
images = batch["image"]
labels = batch["label"]
for i in range(16):
img = (images[i] * 255).numpy().astype("uint8")
label = tf.strings.reduce_join(num_to_char(labels[i])).numpy().decode("utf-8")
ax[i // 4, i % 4].imshow(img[:, :, 0].T, cmap="gray")
ax[i // 4, i % 4].set_title(label)
ax[i // 4, i % 4].axis("off")
plt.show()
下图是对原始验证码图片的展示结果:

从图片来看,这个验证码是 N 多年前的了,现在的难多了,不过也算一个 Demo 供大家学习吧
最后放一下预测的结果吧,因为我才刚接触 OCR 所以很多实验也没做,更多的经验心得方面估计要后面才能分享

从预测结果来看,用这个 Demo 的网络,解决这种简单问题,看来没毛病哈。
登录后可发表评论
点击登录