大家好,我是辣条,这是我爬虫系列的第26篇。
爱美之心人皆有之,正所谓窈窕淑女君子好逑,美好敲代码的一天从好看的桌面壁纸开始,好看的桌面壁纸从美女壁纸开始。今天给大家带来福利啦,爬取美女图片作为桌面壁纸!【防止有人捶我打擦边球,都是正经的图片,自己想歪了是你的事,仅供学习交流】
采集目标
网址:36壁纸
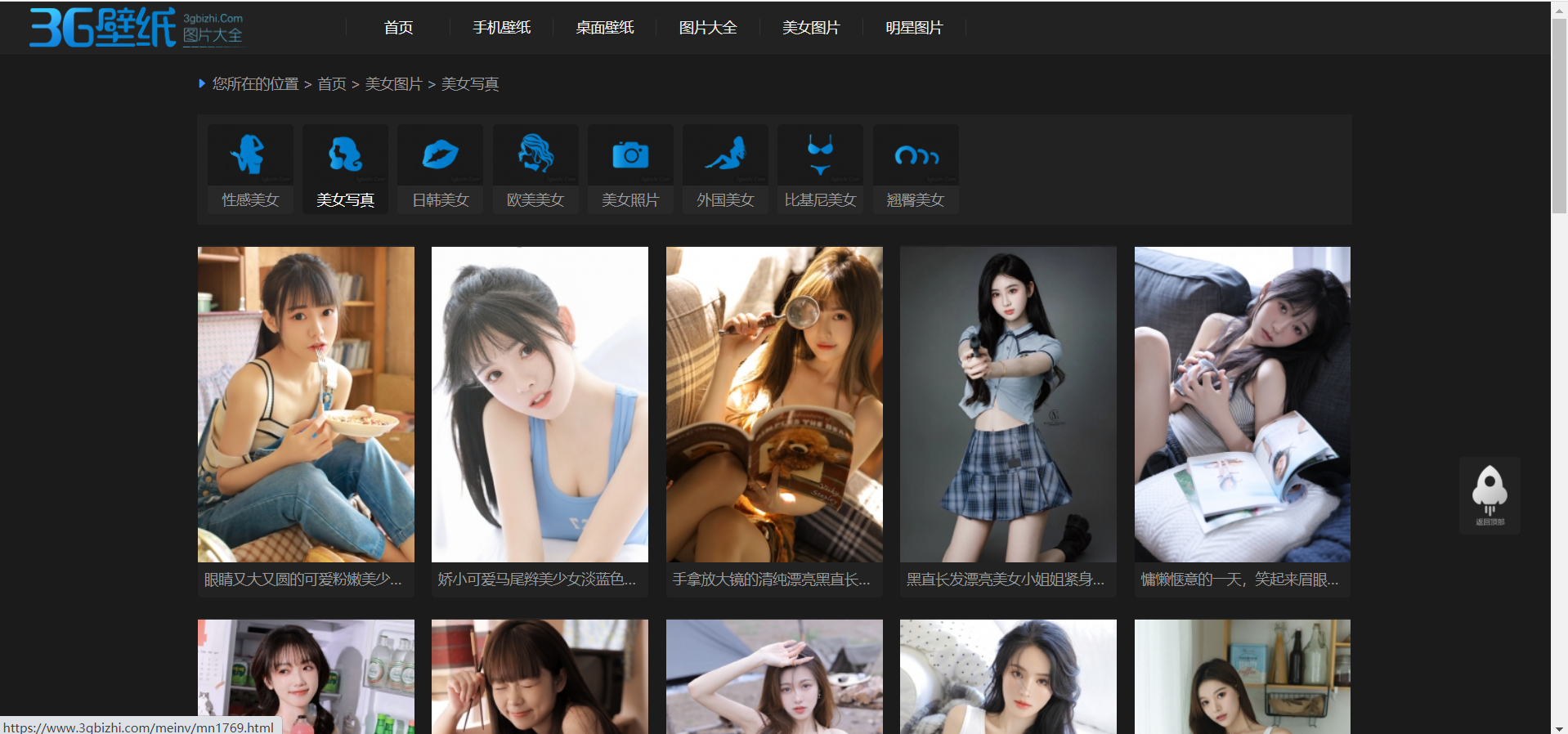
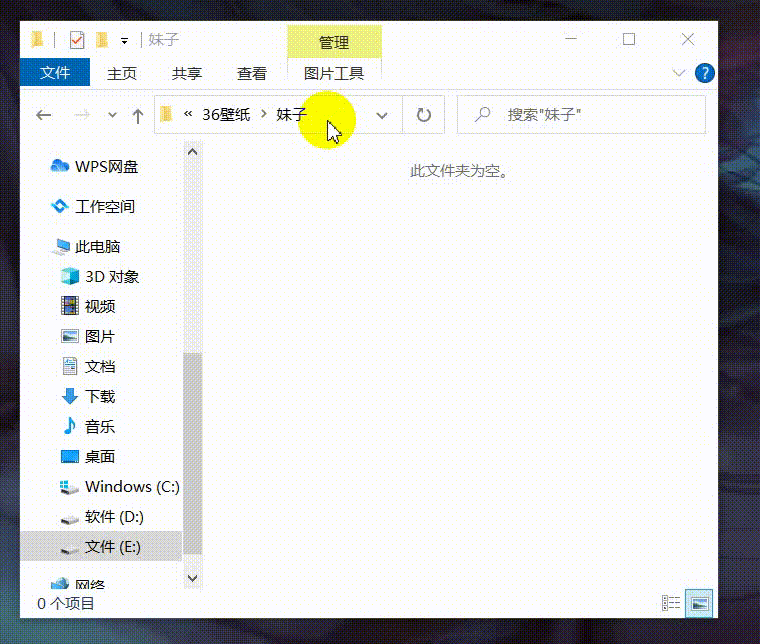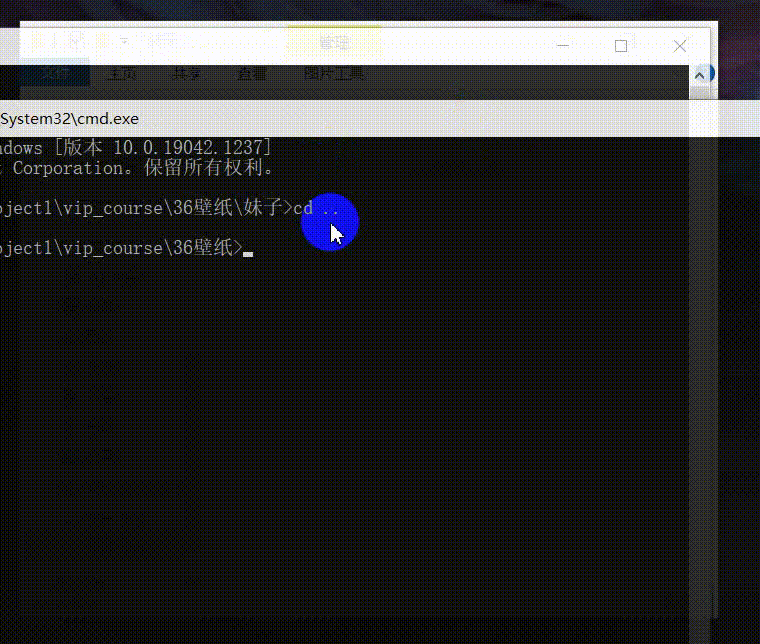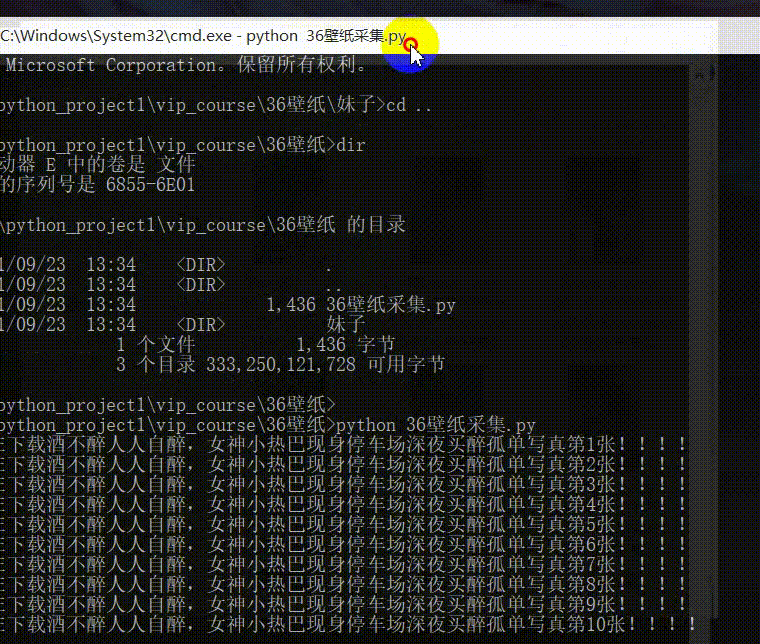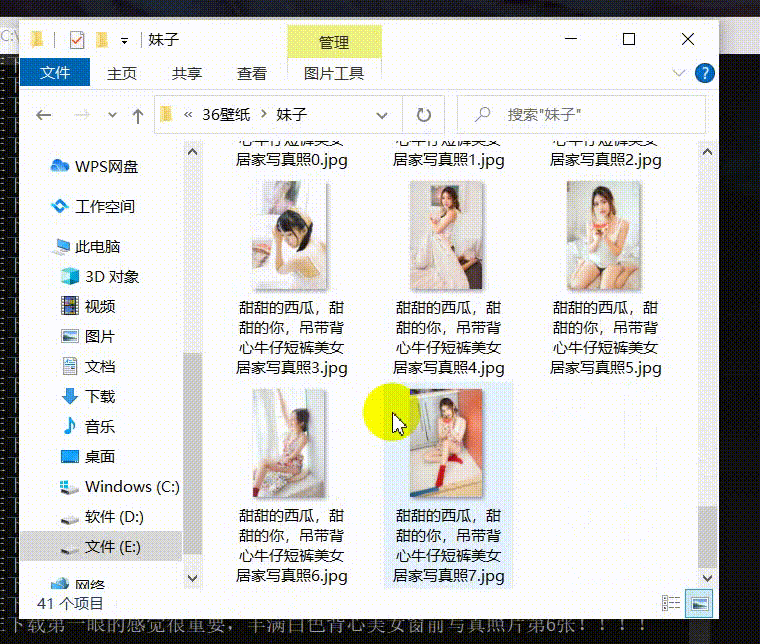
展示效果
工具使用
开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests, lxml
项目思路解析
获取网页数据首先需要分辨数据是静态数据还是动态数据检验方法在网页源代码搜索你需要数据的关键字,要是有的话就是静态数据,没有的话就是动态数据,当前网页数据加载方式是通过url换页,通过循环的方式加载页面数据,使用requests发送网络请求获取当前网页数据,通过xpath语法定位到网页链接请求
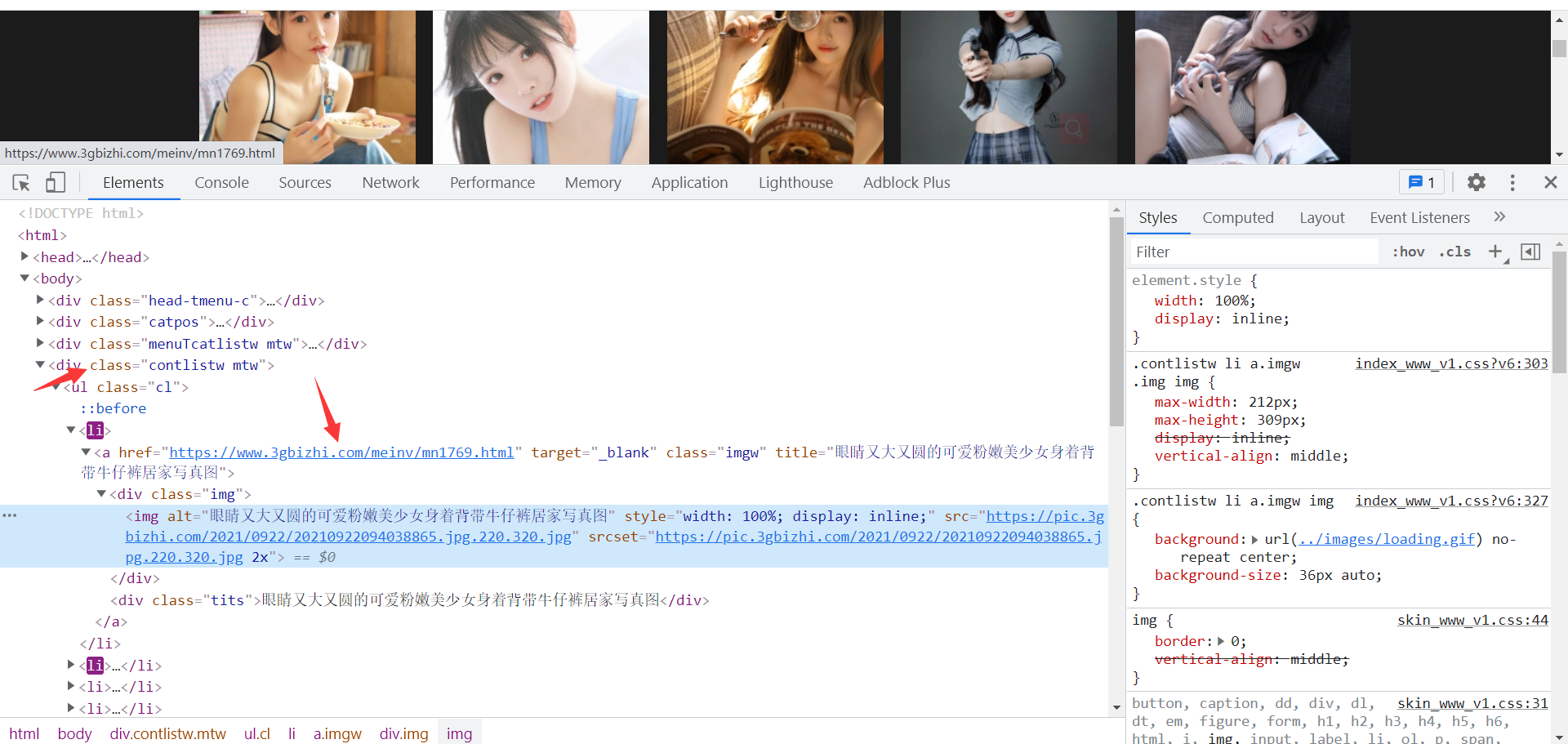
记住在这里提取的数据是html链接我们要的一大批数据在详情页面
提取出当前网页所以的详情页面链接,xpath提取的数据为列表,循环取出每个数据依次发送请求
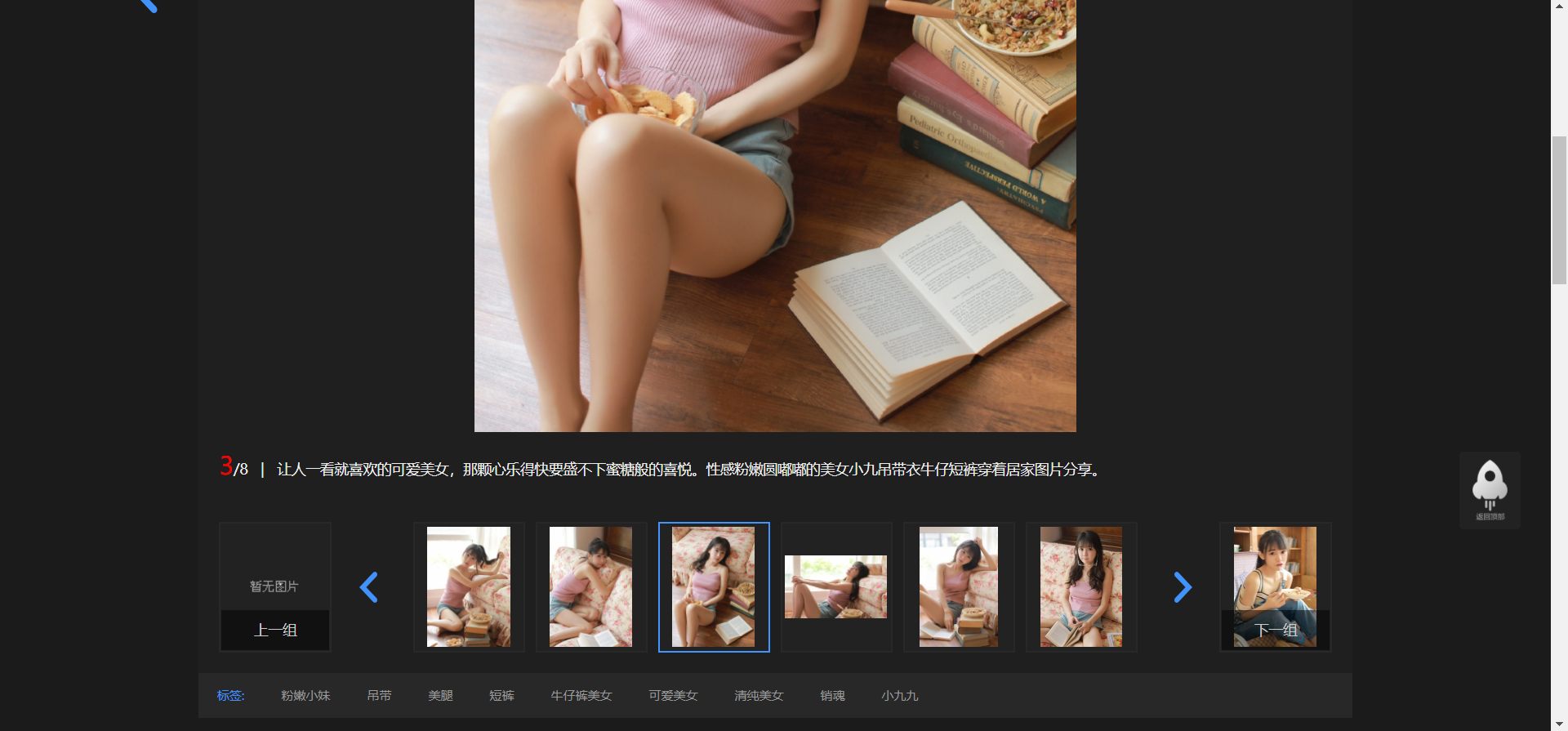
我们要获取的图片都在这里按照通样的方法使用xpath方式进行定位获取到所以详细图片的位置
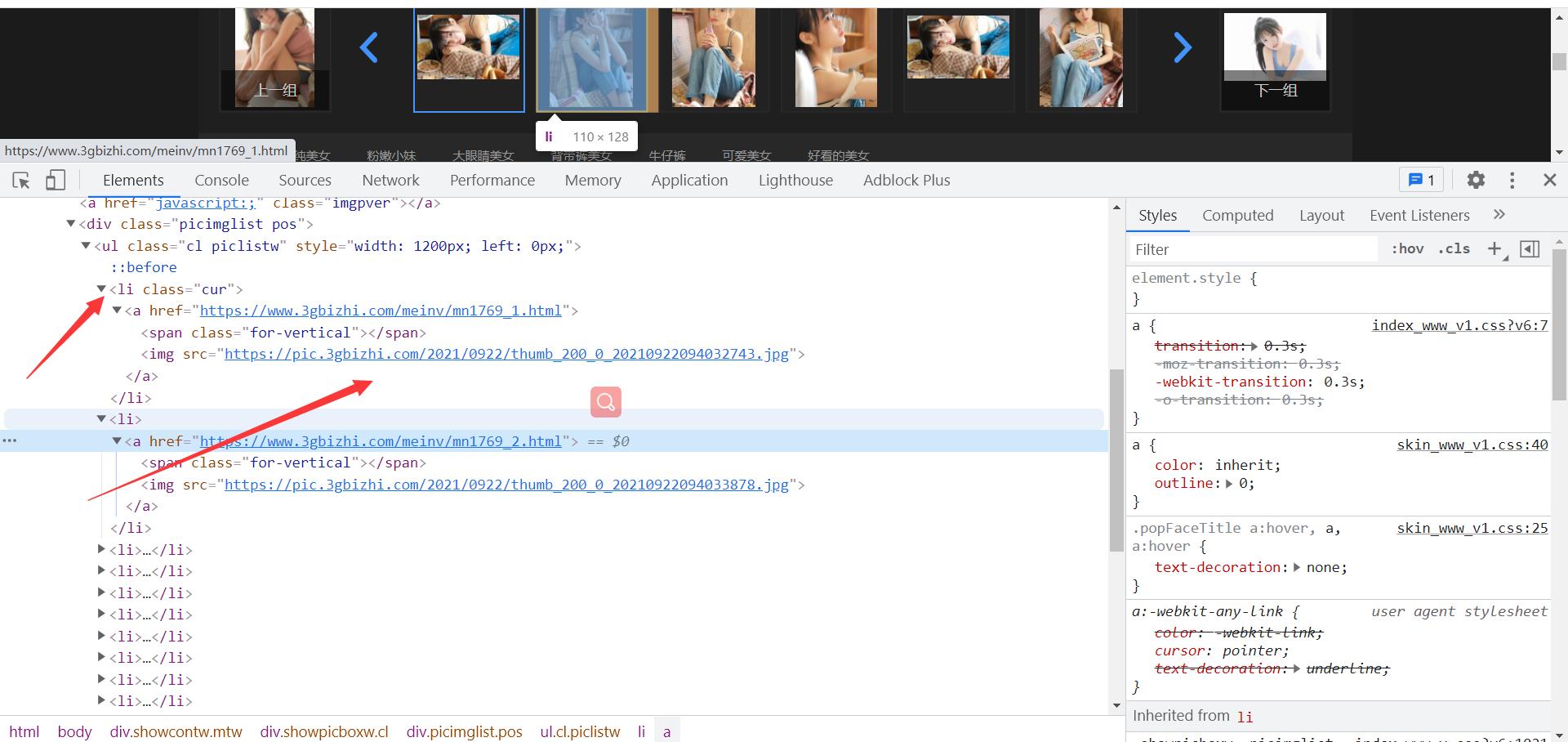

获取到全部图片地址,这个图片需要注意的是是缩略图我们需要找出缩略图和大图url的区别
https://pic.3gbizhi.com/2021/0922/20210922094032743.jpg https://pic.3gbizhi.com/2021/0922/thumb_200_0_20210922094032743.jpg
缩略图比大图多了thumb_200_0_ 进行分割在进行拼接,对图片的发送网络请求获取到详细的图片数据,在进行保存
简易源码分享
import requests
from lxml import etree
headers = {
'Cookie': 'Hm_lvt_c8263f264e5db13b29b03baeb1840f60=1632291839,1632373348; Hm_lpvt_c8263f264e5db13b29b03baeb1840f60=1632373697',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
for i in range(2, 3):
url = f'https://www.3gbizhi.com/meinv/xgmn_{i}.html'
response = requests.get(url, headers=headers)
html = etree.HTML(response.text)
href_list = html.xpath('//div[@class="contlistw mtw"]//ul[@class="cl"]/li/a/@href')
title_list = html.xpath('//div[@class="contlistw mtw"]//ul[@class="cl"]/li/a/@title')
for href, title in zip(href_list, title_list):
res = requests.get(href, headers=headers)
html_data = etree.HTML(res.text)
img_url_list = html_data.xpath('//div[@class="picimglist pos"]/ul/li/a/img/@src')
print(img_url_list)
num = 0
for img_url in img_url_list:
img_url = ''.join(img_url.split('thumb_200_0_'))
result = requests.get(img_url, headers=headers).content
with open('妹子/' + title + str(num) + '.jpg', 'wb')as f:
f.write(result)
num += 1
print(f'正在下载{title}第{num}张!!!!')行业资料:添加即可领取PPT模板、简历模板、行业经典书籍PDF。
面试题库:历年经典,热乎的大厂面试真题,持续更新中,添加获取。
学习资料:含Python、爬虫、数据分析、算法等学习视频和文档,添加获取
交流加群:大佬指点迷津,你的问题往往有人遇到过,技术互助交流。
领取
