 坚持坚持再坚持!!!
坚持坚持再坚持!!!
如果文章对于你有帮助,欢迎收藏、关注、点赞与订阅专栏
有任何疑问欢迎私信
目录
- 第 11 天 - 函数
- 定义函数
- 声明和调用函数
- 无参数函数
- 返回值的函数 - 第 1 部分
- 带参数的函数
- 使用键和值传递参数
- 返回值的函数 - 第 2 部分
- 带默认参数的函数
- 任意数量的参数
- 函数中的默认参数和任意数量的参数
- 函数作为另一个函数的参数
- 第 12 天 - 模块
- 什么是模块
- 创建模块
- 导入模块
- 从模块导入函数
- 从模块导入函数并重命名
- 导入内置模块
- 操作系统模块
- 系统模块
- 统计模块
- 数学模块
- 字符串模块
- 随机模块
- 第 13 天 - 列表理解
- Lambda 函数
- 创建 Lambda 函数
- 另一个函数中的 Lambda 函数
- 第 14 天 - 高阶函数
- 作为参数的函数
- 作为返回值的函数
- Python 闭包
- Python 装饰器
- 创建装饰器
- 将多个装饰器应用于单个函数
- 在装饰器函数中接受参数
- 内置高阶函数
- Python - 地图函数
- Python - 过滤功能
- Python - 减少函数
- 第 15 天 - Python 类型错误
- 语法错误
- 名称错误
- 索引错误
- 模块未找到错误
- 属性错误
- 密钥错误
- 类型错误
- 导入错误
- 值错误
- 零分误差
- 第 16 天 - Python 日期时间
- 获取日期时间信息
- 使用strftime格式化日期输出
- 使用strptime 将字符串转换为时间
- 使用日期时间中的日期
- 代表时间的时间对象
- 两个时间点之间的差异使用
- 使用timedelata 的两个时间点之间的差异
- 第 17 天 - 异常处理
- 在 Python 中打包和解包参数
- 开箱
- 包装
- 装箱单
- 在 Python 中传播
- 枚举
- 压缩
- 第 18 天 - 正则表达式
- 常用表达
- 该重模块
- re模块中的方法
- 使用 RegEx Split 拆分文本
- 编写正则表达式模式
- 方括号
- 正则表达式中的转义字符(\)
- 一次或多次(+)
- 时期(。)
- 零次或多次(*)
- 零次或一次(?)
- 正则表达式中的量词
- 购物车 ^
- 第 19 天 - 文件处理
- 打开文件进行阅读
- 打开文件进行写入和更新
- 删除文件
- 文件类型
- 带有 txt 扩展名的文件
- 带有 json 扩展名的文件
- 将 JSON 更改为字典
- 将字典更改为 JSON
- 保存为 JSON 文件
- 带有 csv 扩展名的文件
- 带有 xlsx 扩展名的文件
- 带有 xml 扩展名的文件
- 第 20 天 - Python 包管理器(PIP)
- 什么是PIP?
- 安装PIP
- 使用 pip 安装包
- 卸载软件包
- 包裹清单
- 显示包
- 画中画冻结
- 从 URL 读取
- 创建包
- 关于包的更多信息
第 11 天 - 函数
到目前为止,我们已经看到了许多内置的 Python 函数。今天,我们将重点介绍自定义函数。什么是函数?在开始制作函数之前,让我们先了解一下什么是函数以及为什么需要它们?
定义函数
函数是设计用于执行特定任务的可重用代码块或编程语句。为了定义或声明一个函数,Python 提供了def关键字。以下是定义函数的语法。只有在调用或调用函数时才执行代码的功能块。
声明和调用函数
当我们创建一个函数时,我们称之为声明一个函数。当我们开始使用它时,我们称它为调用或调用一个函数。函数可以带参数或不带参数声明。
# 语法
# 声明函数
def function_name ():
代码
代码
# 调用函数
function_name ()
无参数函数
函数可以不带参数声明。
例子:
def generate_full_name ():
first_name = 'Asabeneh'
last_name = 'Yetayeh'
space = ''
full_name = first_name + space + last_name
print ( full_name )
generate_full_name () #调用一个函数
def add_two_numbers ():
num_one = 2
num_two = 3
total = num_one + num_two
print ( total )
add_two_numbers ()
返回值的函数 - 第 1 部分
函数也可以返回值,如果函数没有return语句,则函数的值为None。让我们使用 return 重写上述函数。从现在开始,当我们调用函数并打印它时,我们会从函数中获取一个值。
def generate_full_name ():
first_name = 'Asabeneh'
last_name = 'Yetayeh'
space = ''
full_name = first_name + space + last_name
return full_name
print ( generate_full_name ())
def add_two_numbers ():
num_one = 2
num_two = 3
total = num_one + num_two
返回 总
打印( add_two_numbers () )
带参数的函数
在函数中,我们可以传递不同的数据类型(数字、字符串、布尔值、列表、元组、字典或集合)作为参数
- 单参数:如果我们的函数接受一个参数,我们应该用一个参数调用我们的函数
# 语法
# 声明一个函数
def function_name ( parameter ):
代码
代码
# 调用函数
print ( function_name ( argument ))
例子:
def greetings ( name ):
message = name + ', 欢迎来到 Python for Everyone!'
返回 消息
打印(问候('Asabeneh'))
def add_ten ( num ):
十 = 10
返回 num + 十
打印( add_ten ( 90 ))
def square_number ( x ):
return x * x
print ( square_number ( 2 ) )
def area_of_circle ( r ):
PI = 3.14
area = PI * r ** 2
return area
print ( area_of_circle ( 10 ) )
def sum_of_numbers ( n ):
total = 0
for i in range ( n + 1 ):
total += i
print ( total )
print ( sum_of_numbers ( 10 )) # 55
print ( sum_of_numbers ( 100 )) # 5050
- 两个参数:一个函数可能有也可能没有一个或多个参数。一个函数也可以有两个或多个参数。如果我们的函数接受参数,我们应该使用参数调用它。让我们检查一个带有两个参数的函数:
# 语法
# 声明一个函数
def function_name ( para1 , para2 ):
代码
代码
# 调用函数
print ( function_name ( arg1 , arg2 ))
例子:
def generate_full_name ( first_name , last_name ):
space = ' '
full_name = first_name + space + last_name
return full_name
print ( 'Full Name: ' , generate_full_name ( 'Asabeneh' , 'Yetayeh' ))
def sum_two_numbers ( num_one , num_two ):
sum = num_one + num_two
return sum
print ( '两个数字的和:' , sum_two_numbers ( 1 , 9 ))
高清 calculate_age(CURRENT_YEAR,birth_year):
年龄 = CURRENT_YEAR - birth_year
回报 年龄;
打印('年龄:',计算年龄(2021年,1819年))
DEF weight_of_object(质量,重心):
重量 = STR(质量 * 重力)+ “N” #的值必须改变到一个字符串第一
返回 重量
打印(“的物体的重量以牛顿:”,weight_of_object(100,9.81 ))
使用键和值传递参数
如果我们使用键和值传递参数,则参数的顺序无关紧要。
# 语法
# 声明一个函数
def function_name ( para1 , para2 ):
代码
代码
# 调用函数
print ( function_name ( para1 = 'John' , para2 = 'Doe' )) # 这里参数的顺序无关紧要
例子:
def print_fullname ( firstname , lastname ):
space = ' '
full_name = firstname + space + lastname
print ( full_name )
print ( print_fullname ( firstname = 'Asabeneh' , lastname = 'Yetayeh' ))
def add_two_numbers ( num1 , num2 ):
total = num1 + num2
print ( total )
print ( add_two_numbers ( num2 = 3 , num1 = 2 )) # 顺序无所谓
返回值的函数 - 第 2 部分
如果我们不使用函数返回值,那么我们的函数默认返回None。要使用函数返回值,我们使用关键字return后跟我们要返回的变量。我们可以从函数返回任何类型的数据类型。
- 返回字符串:
示例:
def print_name ( firstname ):
return firstname
print_name ( 'Asabeneh' ) # Asabeneh
def print_full_name ( firstname , lastname ):
space = ' '
full_name = firstname + space + lastname
return full_name
print_full_name ( firstname = 'Asabeneh' , lastname = 'Yetayeh' )
- 返回一个数字:
例子:
def add_two_numbers ( num1 , num2 ):
total = num1 + num2
return total
print ( add_two_numbers ( 2 , 3 ))
高清 calculate_age(CURRENT_YEAR,birth_year):
年龄 = CURRENT_YEAR - birth_year
回报 年龄;
打印('年龄:',计算年龄(2019年,1819年))
- 返回一个布尔值:
示例:
def is_even ( n ):
if n % 2 == 0 :
print ( 'even' )
return True # return 停止函数的进一步执行,类似于 break
return False
print ( is_even ( 10 )) # True
print ( is_even ( 7 ) )) # 错误
- 返回列表:
示例:
DEF find_even_numbers(Ñ):
找齐 = []
为 我 在 范围(Ñ + 1):
如果 我 % 2 == 0:
找齐。追加(我)
返回 找齐
打印(find_even_numbers(10))
带默认参数的函数
有时我们在调用函数时将默认值传递给参数。如果我们在调用函数时不传递参数,将使用它们的默认值。
# 语法
# 声明一个函数
def function_name ( param = value ):
代码
代码
# 调用函数
function_name ()
function_name ( arg )
例子:
def greetings ( name = 'Peter' ):
message = name + ',欢迎大家使用 Python!
返回 消息
打印(问候())
打印(问候('Asabeneh'))
def generate_full_name ( first_name = 'Asabeneh' , last_name = 'Yetayeh' ):
space = ' '
full_name = first_name + space + last_name
return full_name
打印(生成全名())
打印(生成全名('大卫','史密斯'))
DEF calculate_age(birth_year,CURRENT_YEAR = 2021):
年龄 = CURRENT_YEAR - birth_year
返回 年龄;
打印('年龄:',计算年龄(1821))
DEF weight_of_object(质量,重心 = 9.81):
重量 = STR(质量 * 重力)+ “N” #的值必须改变到字符串第一
返回 重量
打印(“牛顿的物体的重量:”,weight_of_object(100) ) # 9.81 - 地球表面的平均重力
打印( '以牛顿为单位的物体重量:' , weight_of_object ( 100 , 1.62 ))# 月球表面的重力
任意数量的参数
如果我们不知道传递给函数的参数数量,我们可以通过在参数名称前添加 * 来创建一个可以接受任意数量参数的函数。
# 语法
# 声明一个函数
def function_name ( * args ):
代码
代码
# 调用函数
function_name ( param1 , param2 , param3 ,..)
例子:
def sum_all_nums ( * nums ):
total = 0
for num in nums :
total += num # 同total = total + num
return total
print ( sum_all_nums ( 2 , 3 , 5 )) # 10
函数中的默认参数和任意数量的参数
def generate_groups ( team , * args ):
print ( team )
for i in args :
print ( i )
print ( generate_groups ( 'Team-1' , 'Asabeneh' , 'Brook' , 'David' , 'Eyob' ))
函数作为另一个函数的参数
#您可以将函数作为参数传递
def square_number ( n ):
return n * n
def do_something ( f , x ):
return f ( x )
print ( do_something ( square_number , 3 )) # 27
到目前为止,您取得了很多成就。继续!您刚刚完成了第 11 天的挑战,距离通往伟大之路还有 11 步。
第 12 天 - 模块
什么是模块
模块是包含一组代码或一组可以包含在应用程序中的功能的文件。模块可以是包含单个变量、函数或大型代码库的文件。
创建模块
为了创建一个模块,我们在 python 脚本中编写代码并将其保存为 .py 文件。在项目文件夹中创建一个名为 mymodule.py 的文件。让我们在这个文件中写一些代码。
# mymodule.py 文件
def generate_full_name ( firstname , lastname ):
return firstname + ' ' + lastname
在您的项目目录中创建 main.py 文件并导入 mymodule.py 文件。
导入模块
要导入文件,我们仅使用import关键字和文件名。
# main.py 文件
import mymodule
print ( mymodule . generate_full_name ( 'Asabeneh' , 'Yetayeh' )) # Asabeneh Yetayeh
从模块导入函数
我们可以在一个文件中包含多个函数,并且可以以不同的方式导入所有函数。
# main.py 文件
from mymodule import generate_full_name , sum_two_nums , person ,重力
打印( generate_full_name ( 'Asabneh' , 'Yetayeh' ))
print ( sum_two_nums ( 1 , 9 ))
mass = 100 ;
重量 = 质量 * 重力
打印(重量)
打印(人[ '名字' ])
从模块导入函数并重命名
在导入过程中,我们可以重命名模块的名称。
#main.py文件
从 MyModule的 进口 generate_full_name 如 全名,sum_two_nums 作为 总,人 作为 p,重力 为 克
打印(全名('Asabneh' ,'Yetayeh' ))
打印(总共(1,9))
的质量 = 100 ;
重量 = 质量 * g
打印(重量)
打印(p )
打印( p [ 'firstname' ])
导入内置模块
像其他编程语言一样,我们也可以通过使用关键字import 导入文件/函数来导入模块。让我们导入我们将大部分时间使用的公共模块。一些常见的内置模块:math、datetime、os、sys、random、statistics、collections、json、re
操作系统模块
使用 python os模块可以自动执行许多操作系统任务。Python 中的 OS 模块提供创建、更改当前工作目录、删除目录(文件夹)、获取其内容、更改和识别当前目录的功能。
# 导入模块
import os
# 创建目录
os . mkdir ( 'directory_name' )
# 改变当前目录
os . chdir ( 'path' )
# 获取当前工作目录
os . getcwd ()
# 删除目录
os . 目录()
系统模块
sys 模块提供用于操作 Python 运行时环境的不同部分的函数和变量。函数 sys.argv 返回传递给 Python 脚本的命令行参数列表。此列表中索引 0 处的项目始终是脚本的名称,索引 1 处是从命令行传递的参数。
script.py 文件示例:
import sys
#print(sys.argv[0], argv[1],sys.argv[2]) # 这行会打印出: filename argument1 argument2
print ( 'Welcome {}. Enjoy {} Challenge!' . format ( sys . argv [ 1 ], sys . argv [ 2 ]))
现在要检查这个脚本是如何工作的,我在命令行中写了:
python script.py Asabeneh 30DaysOfPython
结果:
欢迎,享受 30DayOfPython 挑战!
一些有用的 sys 命令:
# 退出 sys
sys。exit ()
# 要知道最大的整数变量需要
sys。maxsize
# 要知道环境路径
sys . path
# 要知道您使用的 python 版本
sys。版本
统计模块
统计模块提供数值数据的数理统计功能。此模块中定义的流行统计函数:mean、median、mode、stdev等。
from statistics import * # 导入所有统计模块
age = [ 20 , 20 , 4 , 24 , 25 , 22 , 26 , 20 , 23 , 22 , 26 ]
print ( mean ( ages )) # ~22.9
print ( median ( ages) )) # 23
打印(模式(年龄)) # 20
打印(stdev(年龄)) #~2.3
数学模块
包含许多数学运算和常数的模块。
进口 数学
打印(数学。PI) #3.141592653589793,PI常数
打印(数学。SQRT(2)) #1.4142135623730951,平方根
打印(数学。POW(2,3)) #8.0,指数函数
打印(数学。地板(9.81)) #9,四舍五入到最低
打印(数学。小区(9.81)) # 10,四舍五入到最高
打印( math . log10 ( 100 )) # 2,以10为底的对数
现在,我们已经导入了math模块,其中包含许多可以帮助我们进行数学计算的功能。要检查模块具有哪些功能,我们可以使用help(math)或dir(math)。这将显示模块中的可用功能。如果我们只想从模块中导入一个特定的函数,我们按如下方式导入它:
从 数学 导入 pi
打印( pi )
也可以一次导入多个函数
从 数学 进口 PI,SQRT,POW,地板,小区,日志10
打印(PI) #3.141592653589793
打印(SQRT(2)) #1.4142135623730951
打印(POW(2,3)) #8.0
打印(地板(9.81)) #9
打印(上限( 9.81 )) #10
打印(数学。LOG10(100)) #2
但是如果我们想导入 math 模块中的所有函数,我们可以使用 * 。
from math import *
print ( pi ) # 3.141592653589793, pi 常数
打印( sqrt ( 2 )) # 1.4142135623730951, 平方根
打印( pow ( 2 , 3 )) # 8.0, 指数
打印( floor ( 9.81 ) 四舍五入)最低的
打印( ceil ( 9.81 )) # 10,四舍五入到最高的
打印( math .log10 ( 100 )) # 2
当我们导入时,我们还可以重命名函数的名称。
from math import pi as PI
print ( PI ) # 3.141592653589793
字符串模块
字符串模块是一个用于多种用途的有用模块。下面的示例显示了 string 模块的一些用法。
进口 字符串
打印(串。ascii_letters)#abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
打印(串。位数) #0123456789
打印(串。标点符号) #“#$%&'()* +, - 。/?:; <=> @ [\] ^_`{|}~
随机模块
到目前为止,您已经熟悉了导入模块。让我们再做一个导入来熟悉它。让我们导入random模块,它给我们一个 0 到 0.9999 之间的随机数… random模块有很多功能,但在本节中我们将只使用random和randint。
from random import random , randint
print ( random ()) # 不带任何参数;它返回一个介于 0 和 0.9999 之间的值
print ( randint ( 5 , 20 )) # 它返回一个介于 [5, 20] 之间的随机整数
你要走得很远。继续!您刚刚完成了第 12 天的挑战,距离通往伟大之路还有 12 步。
第 13 天 - 列表理解
Python 中的列表推导式是一种从序列创建列表的紧凑方式。这是创建新列表的一种快捷方式。列表理解比使用for循环处理列表快得多。
# 语法
[ i for i in iterable if expression ]
示例:1
例如,如果您想将字符串更改为字符列表。您可以使用几种方法。让我们看看其中的一些:
# 一种方式
language = 'Python'
lst = list ( language ) # 将字符串改为列表
print ( type ( lst )) # list
print ( lst ) # ['P', 'y', 't', 'h' , '在']
# 第二种方式:list comprehension
lst = [ i for i in language ]
print ( type ( lst )) # list
print ( lst ) # ['P', 'y', 't', 'h', 'o', 'n']
示例:2
例如,如果你想生成一个数字列表
# 生成数字
numbers = [ i for i in range ( 11 )] # 生成从 0 到 10 的
数字print ( numbers ) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 ]
# 可以在迭代期间进行数学运算
squares = [ i * i for i in range ( 11 )]
print ( squares ) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 也可以创建一个元组列表
numbers = [( i , i * i ) for i in range ( 11 )]
print ( numbers ) # [(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
示例:2
列表推导式可以与 if 表达式结合使用
# 生成偶数
even_numbers = [ i for i in range ( 21 ) if i % 2 == 0 ] # 生成 0 到 21 范围内的偶数列表
print ( even_numbers ) # [0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
# 生成奇数
odd_numbers = [ i for i in range ( 21 ) if i % 2 != 0 ] # 生成0到21范围内的奇数
print ( odd_numbers ) # [1, 3, 5, 7, 9, 11 , 13, 15, 17, 19]
# 过滤数字:让我们从下面的列表中过滤掉正偶数
numbers = [ - 8 , - 7 , - 3 , - 1 , 0 ,1 , 3 , 4 , 5 , 7 , 6 , 8 , 10 ]
positive_even_numbers = [ i for i in range ( 21 ) if i % 2 == 0 and i > 0 ]
print ( positive_even_numbers ) # [2, 4, 6 , 8, 10, 12, 14, 16, 18, 20]
# 展平一个三维数组
list_of_lists = [[ 1 , 2 , 3 ], [ 4 , 5 , 6 ], [ 7 , 8 , 9 ]]
flattened_list = [ number for row in list_of_lists for number in row ]
print ( flattened_list ) # [1, 2, 3, 4, 5, 6, 7, 8, 9]
Lambda 函数
Lambda 函数是一个没有名字的小型匿名函数。它可以接受任意数量的参数,但只能有一个表达式。Lambda 函数类似于 JavaScript 中的匿名函数。当我们想在另一个函数中编写匿名函数时,我们需要它。
创建 Lambda 函数
要创建 lambda 函数,我们使用lambda关键字,后跟参数,后跟表达式。请参阅下面的语法和示例。Lambda 函数不使用 return,但它显式返回表达式。
# 语法
x = lambda param1 , param2 , param3 : param1 + param2 + param2
print ( x ( arg1 , arg2 , arg3 ))
例子:
# 命名函数
def add_two_nums ( a , b ):
return a + b
print ( add_two_nums ( 2 , 3 )) # 5
# 让我们把上面的函数
改成 lambda 函数add_two_nums = lambda a , b : a + b
print ( add_two_nums ( 2 , 3 )) # 5
# 自调用 lambda 函数
( lambda a , b : a + b )( 2 , 3 ) # 5 - 需要将其封装在 print() 中才能在控制台中查看结果
square = lambda x : x ** 2
print ( square ( 3 )) # 9
cube = lambda x : x ** 3
print ( cube ( 3 )) # 27
# 多个变量
multiple_variable = lambda a , b , c : a ** 2 - 3 * b + 4 * c
print ( multiple_variable ( 5 , 5 , 3 )) # 22
另一个函数中的 Lambda 函数
在另一个函数中使用 lambda 函数。
def power ( x ):
返回 lambda n : x ** n
cube = power ( 2 )( 3 ) # 函数 power 现在需要 2 个参数来运行,在单独的圆括号中
print ( cube ) # 8
two_power_of_five = power ( 2 )( 5 )
print ( two_power_of_five ) # 32
保持良好的工作。保持势头,天空是极限!您刚刚完成了第 13 天的挑战,距离通往伟大之路还有 13 步。
第 14 天 - 高阶函数
在 Python 中,函数被视为一等公民,允许您对函数执行以下操作:
- 一个函数可以接受一个或多个函数作为参数
- 一个函数可以作为另一个函数的结果返回
- 一个函数可以修改
- 一个函数可以赋值给一个变量
今天,我们将介绍:
- 将函数作为参数处理
- 将函数作为另一个函数的返回值返回
- 使用 Python 闭包和装饰器
作为参数的函数
def sum_numbers ( nums ): # 普通函数
返回 sum ( nums ) # 一个滥用内置 sum 函数的悲伤函数 :<
def high_order_function ( f , lst ): # 函数作为参数
summation = f ( lst )
return summation
result = Higher_order_function ( sum_numbers , [ 1 , 2 , 3 , 4 , 5 ])
print ( result ) # 15
作为返回值的函数
def square ( x ): # 一个平方函数
return x ** 2
def cube ( x ): # 一个立方体函数
return x ** 3
def absolute ( x ): # 一个绝对值函数
if x >= 0 :
return x
else :
return - ( x )
def Higher_order_function ( type ): # 一个高阶函数返回一个函数
if type == 'square' :
return square
elif type == 'cube' :
return cube
elif type == 'absolute' :
return absolute
result = Higher_order_function ( 'square' )
print ( result ( 3 )) # 9
result = Higher_order_function ( 'cube' )
print ( result ( 3 )) # 27
result = Higher_order_function ( 'absolute' )
print ( result ( - 3 )) # 3
从上面的例子可以看出,高阶函数根据传递的参数返回不同的函数
Python 闭包
Python 允许嵌套函数访问封闭函数的外部作用域。这被称为闭包。让我们看看闭包在 Python 中是如何工作的。在 Python 中,闭包是通过在另一个封装函数中嵌套一个函数然后返回内部函数来创建的。请参阅下面的示例。
例子:
def add_ten ():
十 = 10
def add ( num ):
返回 num + 十
返回 添加
closure_result = add_ten()
打印(closure_result(5)) #15
打印(closure_result(10)) #20
Python 装饰器
装饰器是 Python 中的一种设计模式,它允许用户在不修改其结构的情况下向现有对象添加新功能。装饰器通常在定义要装饰的函数之前调用。
创建装饰器
要创建装饰器函数,我们需要一个带有内部包装函数的外部函数。
例子:
# 普通函数
def greeting ():
return 'Welcome to Python'
def uppercase_decorator ( function ):
def wrapper ():
func = function ()
make_uppercase = func . upper ()
return make_uppercase
return wrapper
g = uppercase_decorator ( greeting )
print ( g ()) # 欢迎来到 PYTHON
## 让我们用一个装饰器来实现上面的例子
'''这个装饰器函数是一个
以函数为参数的
高阶函数''' def uppercase_decorator ( function ):
def wrapper ():
func = function ()
make_uppercase = func。upper ()
return make_uppercase
return wrapper
@ uppercase_decorator
def greeting ():
return 'Welcome to Python'
print ( greeting ()) # WELCOME TO PYTHON
将多个装饰器应用于单个函数
'''这些装饰器函数是以
函数为参数的高阶函数'''
# 第一个装饰器
def uppercase_decorator ( function ):
def wrapper ():
func = function ()
make_uppercase = func . upper ()
返回 make_uppercase
返回 包装器
# 第二个装饰器
def split_string_decorator ( function ):
def wrapper ():
func = function ()
splitted_string = func . split ()
返回 splitted_string
返回 包装器
@ split_string_decorator
@ uppercase_decorator # 在这种情况下,装饰器的顺序很重要 - .upper() 函数不适用于列表
def greeting ():
return 'Welcome to Python'
print ( greeting ()) # WELCOME TO PYTHON
在装饰器函数中接受参数
大多数时候我们需要我们的函数接受参数,所以我们可能需要定义一个接受参数的装饰器。
d
ef decorator_with_parameters ( function ):
def wrapper_accepting_parameters ( para1 , para2 , para3 ):
function ( para1 , para2 , para3 )
print ( "I live in {}" . format ( para3 ))
return wrapper_accepting_parameters
@ decorator_with_parameters
高清 print_full_name(FIRST_NAME,姓氏,国家):
打印(“我是{} {}我爱教”。格式(
如first_name,姓氏,国家))
print_full_name ( "Asabeneh" , "Yetayeh" , '芬兰' )
内置高阶函数
我们在本部分中介绍的一些内置高阶函数是map()、filter和reduce。Lambda 函数可以作为参数传递,而 lambda 函数的最佳用例是 map、filter 和 reduce 等函数。
Python - 地图函数
map() 函数是一个内置函数,它接受一个函数和 iterable 作为参数。
# 语法
映射(函数,可迭代)
示例:1
numbers = [ 1 , 2 , 3 , 4 , 5 ] # iterable
def square ( x ):
return x ** 2
numbers_squared = map ( square , numbers )
print ( list ( numbers_squared )) # [1, 4, 9, 16 , 25]
# 让我们用一个 lambda 函数
来 应用它numbers_squared = map ( lambda x : x ** 2, numbers )
print ( list ( numbers_squared )) # [1, 4, 9, 16, 25]
示例:2
numbers_str = [ '1' , '2' , '3' , '4' , '5' ] # 可迭代
numbers_int = map ( int , numbers_str )
print ( list ( numbers_int )) # [1, 2, 3, 4, 5]
示例:3
names = [ 'Asabeneh' , 'Lidiya' , 'Ermias' , 'Abraham' ] # 可迭代
def change_to_upper ( name ):
返回 name。上()
names_upper_cased = map ( change_to_upper , names )
print ( list ( names_upper_cased )) # ['ASABENEH', 'LIDIYA', 'ERMIAS', 'ABRAHAM']
# 让我们用一个 lambda 函数来应用它
names_upper_cased = map ( lambda name : name . upper (), names )
print ( list ( names_upper_cased )) # ['ASABENEH', 'LIDIYA', 'ERMIAS', 'ABRAHAM']
实际上 map 所做的是迭代一个列表。例如,它将名称更改为大写并返回一个新列表。
Python - 过滤功能
filter() 函数调用指定的函数,该函数为指定的可迭代对象(列表)的每个项目返回布尔值。它过滤满足过滤条件的项目。
# 语法
过滤器(函数,可迭代)
示例:1
# 只过滤偶数
数字 = [ 1 , 2 , 3 , 4 , 5 ] # iterable
def is_even ( num ):
if num % 2 == 0 :
return True
return False
even_numbers = filter ( is_even , numbers )
print ( list ( even_numbers )) # [2, 4]
示例:2
数字 = [ 1 , 2 , 3 , 4 , 5 ] # 可迭代
def is_odd ( num ):
if num % 2 != 0 :
return True
return False
奇数 = 过滤器( is_odd ,数字)
打印(列表(奇数)) # [1, 3, 5]
# 过滤长名称
names = [ 'Asabeneh' , 'Lidiya' , 'Ermias' , 'Abraham' ] # iterable
def is_name_long ( name ):
if len ( name ) > 7 :
return True
return False
long_names = filter ( is_name_long , names )
print ( list ( long_names )) # ['Asabeneh']
Python - 减少函数
在减少()函数的fucntools模块里定义,我们应该从这个模块导入。与 map 和 filter 一样,它需要两个参数,一个函数和一个可迭代对象。但是,它不会返回另一个可迭代对象,而是返回单个值。
示例:1
numbers_str = [ '1' , '2' , '3' , '4' , '5' ] # iterable
def add_two_nums ( x , y ):
return int ( x ) + int ( y )
total = reduce ( add_two_nums , numbers_str )
print ( total ) # 15
第 15 天 - Python 类型错误
当我们编写代码时,我们经常会犯错或其他一些常见的错误。如果我们的代码无法运行,Python 解释器将显示一条消息,其中包含有关问题发生位置和错误类型信息的反馈。它有时也会为我们提供可能的修复建议。了解编程语言中不同类型的错误将帮助我们快速调试我们的代码,也可以让我们更好地完成我们的工作。
让我们一一看看最常见的错误类型。首先让我们打开 Python 交互式 shell。转到您的计算机终端并编写“python”。python交互式shell将被打开。
语法错误
示例 1:语法错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 打印 '世界你好'
文件 “<标准输入>” ,行 1
打印 的'Hello World'
^
SyntaxError错误:缺少 括号 中 调用 到 '打印'。 意思是 打印('你好世界')?
>> >
正如您所看到的,我们犯了一个语法错误,因为我们忘记用括号将字符串括起来,而 Python 已经提出了解决方案。让我们修复它。
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 打印 '世界你好'
文件 “<标准输入>” ,行 1
打印 的'Hello World'
^
SyntaxError错误:缺少 括号 中 调用 到 '打印'。 意思是 打印('你好世界')?
>> > 打印('你好世界')
你好 世界
>> >
错误是SyntaxError。修复后,我们的代码顺利执行。让我们看看更多的错误类型。
名称错误
示例 1:名称错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 打印(年龄)
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
NameError:名 “年龄” 是 没有 定义
>> >
从上面的消息中可以看出,名称年龄没有定义。是的,我们确实没有定义年龄变量,但我们试图将它打印出来,就像我们已经声明它一样。现在,让我们通过声明它并赋值来解决这个问题。
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 打印(年龄)
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
NameError:名 '年龄' 被 未 限定
>> > 年龄 = 25
>> > 打印(年龄)
25
>> >
错误类型是NameError。我们通过定义变量名来调试错误。
索引错误
示例 1:索引错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 数 = [ 1,2,3,4,5 ]
>> > 号[ 5 ]
回溯(最 近期 呼叫 最后):
File "<stdin>" , line 1 , in < module >
IndexError : list index out of range
>> >
在上面的例子中,Python 引发了一个IndexError,因为列表只有从 0 到 4 的索引,所以它超出了范围。
模块未找到错误
示例 1:ModuleNotFoundError
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 进口 数学
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
ModuleNotFoundError:无 名为 “数学”的
模块>> >
在上面的例子中,我故意在数学中添加了一个额外的 s 并且引发了 ModuleNotFoundError。让我们通过从数学中删除额外的 s 来解决它。
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 进口 数学
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
ModuleNotFoundError:无 名为 “数学”的
模块>> > 导入 数学
>> >
我们修复了它,所以让我们使用 math 模块中的一些函数。
属性错误
示例 1:属性错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 进口 数学
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
ModuleNotFoundError:无 名为 “数学”的
模块>> > 导入 数学
>> > 数学。PI
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
AttributeError的:模块 '数学' 有 没有 属性 'PI'
>> >
如你所见,我又犯了一个错误!我尝试从 maths 模块调用 PI 函数,而不是 pi。它引发了一个属性错误,这意味着该功能在模块中不存在。让我们通过从 PI 更改为 pi 来修复它。
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 进口 数学
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
ModuleNotFoundError:无 名为 “数学”的
模块>> > 导入 数学
>> > 数学。PI
回溯(最 近期的 通话 最后):
文件 “<标准输入>” ,线 1,在 <模块>
AttributeError的:模块 '数学' 有 没有 属性 'PI'
>> > 数学。圆周率
3.141592653589793
>> >
现在,当我们从 math 模块调用 pi 时,我们得到了结果。
密钥错误
示例 1:密钥错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > users = { 'name' : 'Asab' , 'age' : 250 , 'country' : 'Finland' }
>> > users [ 'name' ]
'阿萨布'
>>>用户[ '县']
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
KeyError异常:'县'
>> >
如您所见,用于获取字典值的键中存在拼写错误。所以,这是一个关键错误,修复非常简单。我们开工吧!
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > user = { 'name' : 'Asab' , 'age' : 250 , 'country' : 'Finland' }
>> > user [ 'name' ]
'阿萨布'
>>>用户[ '县']
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
KeyError异常:'县'
>> > 用户[ '国家' ]
'芬兰'
>> >
我们调试了错误,运行了代码并获得了值。
类型错误
示例 1:类型错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 4 + '3'
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
类型错误: 操作数 类型(小号)为 +:'INT' 和 'STR'
>> >
在上面的示例中,由于我们无法向字符串添加数字,因此会引发 TypeError。第一个解决方案是将字符串转换为 int 或 float。另一种解决方案是将数字转换为字符串(结果将是“43”)。让我们遵循第一个修复程序。
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 4 + '3'
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
类型错误: 操作数 类型(小号)为 +:'INT' 和 'STR'
>> > 4 + INT('3' )
7
>> > 4 + 浮动('3' )
7.0
>> >
错误消除,我们得到了预期的结果。
导入错误
示例 1:类型错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 从 数学 进口 电力
回溯(最 近期的 通话 最后):
文件 “<标准输入>”,线 1,在 <模块>
无法 从“数学”导入 名称 “power ” >> >
数学模块中没有名为 power 的函数,它有一个不同的名称:pow。让我们更正一下:
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 从 数学 进口 电力
回溯(最 近期的 通话 最后):
文件 “<标准输入>”,线 1,在 <模块>
无法 从'math' >> > from math import pow >> > pow ( 2 , 3 )
8.0 >> >导入 名称 'power'
值错误
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > INT('12A' )
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
无效 字面 为 INT()与 碱 10:'12A'
>> >
在这种情况下,我们不能将给定的字符串更改为数字,因为其中包含 ‘a’ 字母。
零分误差
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 1 / 0
回溯(最 近期 呼叫 最后):
文件 “<标准输入>” ,线 1,在 <模块>
ZeroDivisionError: 按 零
>> >
我们不能将一个数除以零。
我们已经介绍了一些 python 错误类型,如果你想查看更多关于它的信息,请查看关于 python 错误类型的 python 文档。如果您擅长阅读错误类型,那么您将能够快速修复错误,并且您还将成为一名更好的程序员。
你很优秀。你成功了一半。
第 16 天 - Python 日期时间
Python 有datetime模块来处理日期和时间。
导入 日期时间
打印(目录(日期时间))
[ 'MAXYEAR' ,'MINYEAR' ,'__builtins__' ,'__cached__' ,'__doc__' ,'__file__' ,'__loader__' ,'__name__' ,'__PACKAGE__' ,'__spec__' ,'日期','日期时间',' datetime_CAPI'、'sys'、'time'、'timedelta'、'timezone'、'tzinfo' ]
使用 dir 或 help 内置命令可以知道某个模块中的可用功能。如您所见,在 datetime 模块中有许多函数,但我们将重点介绍date、datetime、time和timedelta。让我们一一看看。
获取日期时间信息
from datetime import datetime
now = datetime。现在()
打印(现在) # 2021-07-08 07:34:46.549883
day = now . 天 # 8
月 = 现在。月 # 7
年 = 现在。年 # 2021
小时 = 现在。小时 # 7
分钟 = 现在。分钟 # 38
秒 = 现在。第二
时间戳 = 现在。时间戳()
打印(日,月,年,小时,分钟)
打印('时间戳',时间戳)
打印(f' {天} / {月} / {年},{小时}:{分钟} ') #8 /7/2021, 7:38
时间戳或 Unix 时间戳是从 1970 年 1 月 1 日 UTC 开始经过的秒数。
使用strftime格式化日期输出
from datetime import datetime
new_year = datetime ( 2020 , 1 , 1 )
print ( new_year ) # 2020-01-01 00:00:00
day = new_year。天
月 = new_year。月
年 = new_year。年
小时 = new_year。小时
分钟 = new_year。分
第二 = new_year。第二
打印(日、月、年、小时、分钟)#1 1 2020 0 0
打印(f' {天} / {月} / {年} , {小时} : {分钟} ') # 1/1/2020, 0:0
可以在此处找到使用strftime方法和文档格式化日期时间。
from datetime import datetime
# 当前日期和时间
now = datetime . 现在()
t = 现在。strftime ( "%H:%M:%S" )
打印( "time:" , t )
time_one = now。strftime ( "%m/%d/%Y, %H:%M:%S" )
# mm/dd/YY H:M:S 格式
打印( "time one:" , time_one )
time_two = now . 时间("%d/%m/%Y, %H:%M:%S" )
# dd/mm/YY H:M:S 格式
打印( "time two:" , time_two )
时间:01 :05 :01
时间一:12/05/2019,01:05 :01 第二
时间:05/12/2019,01:05:01
这是我们用来格式化时间的所有strftime符号。此模块的所有格式的示例。
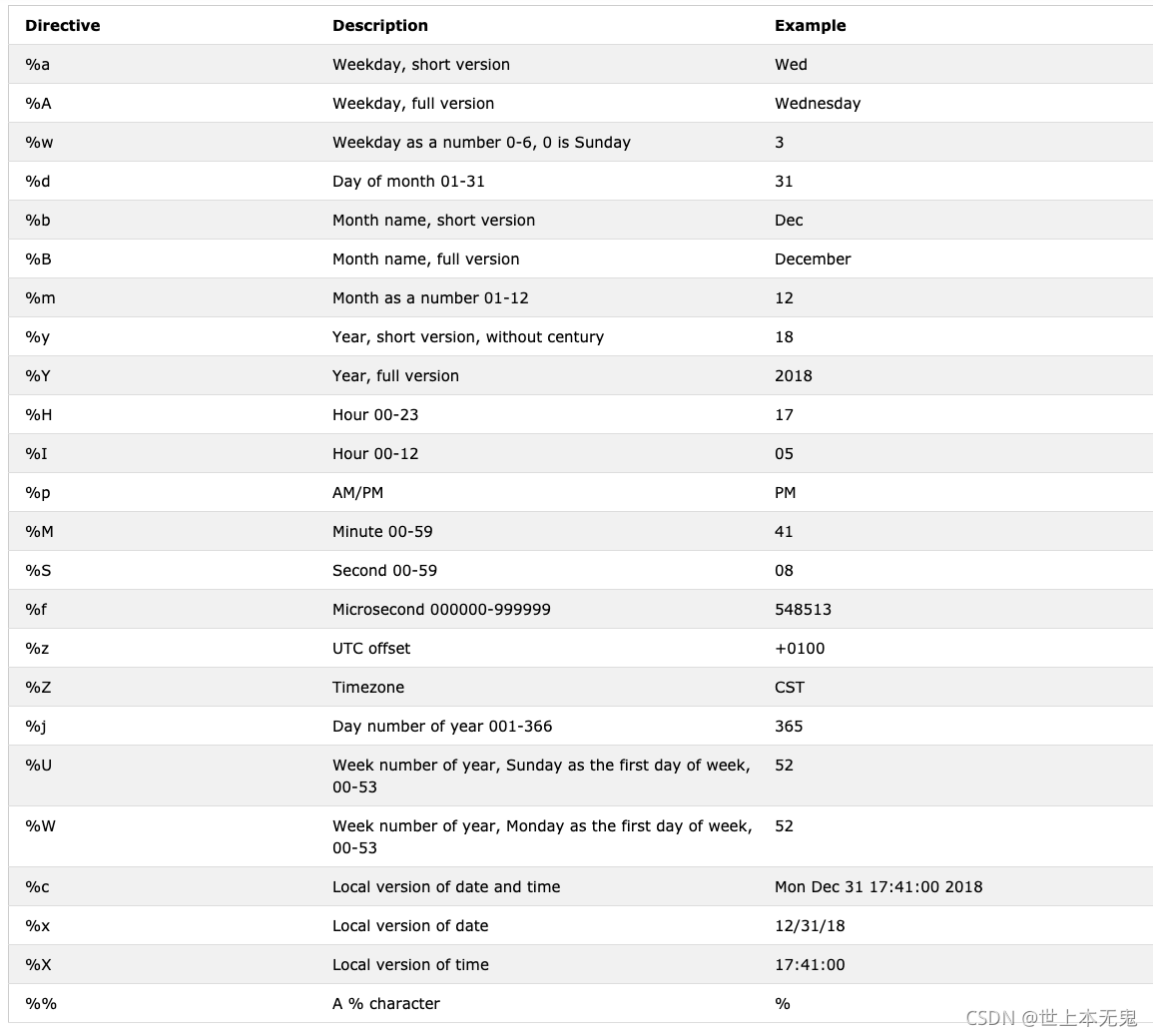
使用strptime 将字符串转换为时间
这是一个有助于理解格式的文档。
from datetime import datetime
date_string = "5 December, 2019"
print ( "date_string =" , date_string )
date_object = datetime。strptime ( date_string , "%d %B, %Y" )
打印( "date_object =" , date_object )
date_string = 2019 年 12 月 5 日
date_object = 2019-12-05 00:00:00
使用日期时间中的日期
from datetime import date
d = date ( 2020 , 1 , 1 )
print ( d )
print ( 'Current date:' , d . today ()) # 2019-12-05
# 今天的日期对象
today = date . today ()
print ( "Current year:" , today . year ) # 2019
print ( "Current month:" , today .月)#12
打印(“当前天:” ,今。日) #5
代表时间的时间对象
from datetime import time
# time(hour = 0, minute = 0, second = 0)
a = time ()
print ( "a =" , a )
# time(hour, minute and second)
b = time ( 10 , 30 , 50 )
print ( "b =" , b )
# time(hour, minute and second)
c = time ( hours = 10 , minute = 30 , second = 50 )
print ( "c =" , c )
# time(hour, minute, second
, microsecond ) d = time ( 10 , 30 , 50 , 200555 )
print ( "d =" , d )
输出 a = 00:00:00
b = 10:30:50
c = 10:30:50
d = 10:30:50.200555
两个时间点之间的差异使用
today = date ( year = 2019 , month = 12 , day = 5 )
new_year = date ( year = 2020 , month = 1 , day = 1 )
time_left_for_newyear = new_year - today
# 新年还剩27天,0:00 :00
打印('新年还剩时间:',time_left_for_newyear)
t1 = 日期时间(年 = 2019,月 = 12,日 = 5,小时 = 0,分钟 = 59,秒 = 0)
t2 = 日期时间(年 = 2020,月 = 1,日 = 1,小时 = 0,分钟 = 0 ,秒 = 0)
diff = t2 - t1
print ( 'Time left for new year:' , diff ) # 新年剩余时间:26 天,23:01:00
使用timedelata 的两个时间点之间的差异
从 日期时间 进口 timedelta
T1 = timedelta(周= 12,天= 10,小时= 4,秒= 20)
T2 = timedelta(天= 7,小时= 5,分钟= 3,秒= 30)
T3 = T1 - T2
打印( "t3 =" , t3)
date_string = 2019 年 12 月 5 日
date_object = 2019-12-05 00:00:00
t3 = 86 天,22:56:50
第 17 天 - 异常处理
Python 使用try和except来优雅地处理错误。错误的优雅退出(或优雅处理)是一种简单的编程习惯用法 - 程序检测到严重的错误情况并因此以受控方式“优雅退出”。通常,作为优雅退出的一部分,程序会向终端或日志打印描述性错误消息,这使我们的应用程序更加健壮。异常的原因通常在程序本身之外。异常的一个例子可能是不正确的输入、错误的文件名、无法找到文件、IO 设备故障。优雅地处理错误可以防止我们的应用程序崩溃。
我们在上一节中介绍了不同的 Python错误类型。如果我们在我们的程序中使用try和except,那么它不会在这些块中引发错误。
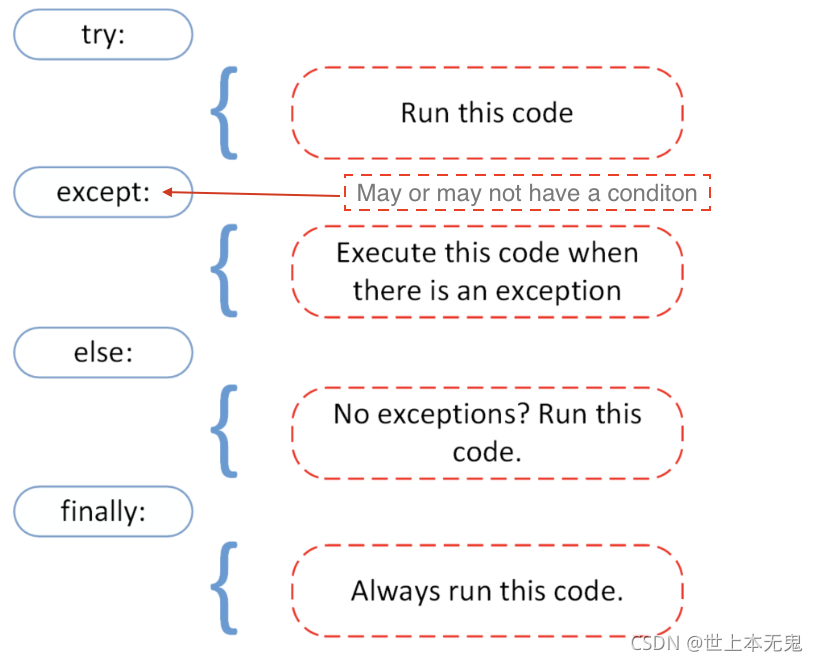
尝试:
代码 在 此 块 如果 事情 去 也
只是:
代码 在 此 块 来看 ,如果 事情 去 错了
例子:
尝试:
打印(10 + '5')
除了:
打印('出了点问题')
在上面的例子中,第二个操作数是一个字符串。我们可以将其更改为 float 或 int 以将其与数字相加以使其工作。但是没有任何更改,将执行第二个块,除了。
例子:
try :
name = input ( 'Enter your name:' )
year_born = input ( 'Year youbirth :' )
age = 2019 - year_born
print ( f'You are { name } . And your age is { age } .' )
除了:
打印('出了点问题')
在上面的例子中,异常块将运行,我们不知道确切的问题。为了分析问题,我们可以使用 except 的不同错误类型。
在下面的示例中,它将处理错误并告诉我们引发的错误类型。
try :
name = input ( 'Enter your name:' )
year_born = input ( 'Year youbirth :' )
age = 2019 - year_born
print ( f'You are { name } . And your age is { age } .' )
除了 TypeError :
打印( '发生类型错误' )
除了 ValueError :
打印( '发生值错误' )
除外 ZeroDivisionError :
打印('发生零除错误')
输入您的姓名:Asabeneh
出生年份:1920
出现类型错误
在上面的代码中,输出将是TypeError。现在,让我们添加一个额外的块:
try :
name = input ( 'Enter your name:' )
year_born = input ( 'Year youbirth :' )
age = 2019 - int ( year_born )
print ( '你是{name}。你的年龄是{age}。' )
除了 TypeError :
打印( '发生类型错误' )
除了 ValueError :
打印( '发生值错误' )
除了 ZeroDivisionError :
打印(“发生零除法错误”)
else:
打印(“我通常使用 try 块运行”)
最后:
打印(“我总是运行。”)
输入您的姓名:Asabeneh
出生年份:1920
你是阿萨贝尼。而你的年龄是 99 岁。
我通常使用 try 块运行
我总是跑。
它也将上面的代码缩短如下:
try :
name = input ( 'Enter your name:' )
year_born = input ( 'Year youbirth :' )
age = 2019 - int ( year_born )
print ( 'You are {name}. And your age is {age}.' )
除了 异常 为 e :
打印( e )
在 Python 中打包和解包参数
我们使用两个运算符:
- 对于元组
** 用于字典
让我们在下面举个例子。它只需要参数,但我们有列表。我们可以解压缩列表并更改参数。
开箱
拆箱清单
def sum_of_five_nums ( a , b , c , d , e ):
返回 a + b + c + d + e
lst = [ 1 , 2 , 3 , 4 , 5 ]
print ( sum_of_five_nums ( lst )) # TypeError: sum_of_five_nums() 缺少 4 个必需的位置参数:'b'、'c'、'd' 和 'e'
当我们运行此代码时,它会引发错误,因为此函数将数字(而不是列表)作为参数。让我们解压/解构列表。
def sum_of_five_nums ( a , b , c , d , e ):
返回 a + b + c + d + e
lst = [ 1 , 2 , 3 , 4 , 5 ]
打印( sum_of_five_nums ( * lst )) # 15
我们还可以在期望开始和结束的范围内置函数中使用解包。
numbers = range ( 2 , 7 ) # 带有单独参数的普通调用
print ( list ( numbers )) # [2, 3, 4, 5, 6]
args = [ 2 , 7 ]
numbers = range ( * args ) # call with从列表中解压出来的参数
print ( numbers ) # [2, 3, 4, 5,6]
列表或元组也可以这样解包:
country = [ '芬兰' , '瑞典' , '挪威' , '丹麦' , '冰岛' ]
fin , sw , nor , * rest = countries
print ( fin , sw , nor , rest ) # 芬兰 瑞典 挪威 ['丹麦', '冰岛']
numbers = [ 1 , 2 , 3 , 4 , 5 , 6 , 7]
one , * middle , last = numbers
print ( one , middle , last ) # 1 [2, 3, 4, 5, 6] 7
解压字典
def unpacking_person_info ( name , country , city , age ):
返回 f' { name }住在{ country } , { city }。他是{年龄}岁。
dct = { 'name' : 'Asabeneh' , 'country' : 'Finland' , 'city' : 'Helsinki' , 'age' : 250 }
打印(unpacking_person_info(** DCT))#Asabeneh住在芬兰赫尔辛基。他今年 250 岁。
包装
有时我们永远不知道有多少参数需要传递给 python 函数。我们可以使用打包方法让我们的函数接受无限数量或任意数量的参数。
装箱单
def sum_all ( * args ):
s = 0
for i in args :
s += i
return s
print ( sum_all ( 1 , 2 , 3 )) # 6
print ( sum_all ( 1 , 2 , 3 , 4 , 5 , 6 , 7 )) # 28
打包字典
DEF packing_person_info(** kwargs):
#检查kwargs的类型,它是一个字典类型
#打印(类型(kwargs))
#打印字典项
为 键 在 kwargs:
打印(“{键} = {kwargs [键]} " )
返回 kwargs
打印(packing_person_info(名称= “Asabeneh”,
国家= “芬兰”,城市= “赫尔辛基”,年龄= 250))
名称 = Asabeneh
国家 = 芬兰
城市 = 赫尔辛基
年龄 = 250
{ “姓名”:“阿萨本尼”,“国家”:“芬兰”,“城市”:“赫尔辛基”,“年龄”:250}
在 Python 中传播
就像在 JavaScript 中一样,在 Python 中传播是可能的。让我们在下面的例子中检查一下:
lst_one = [ 1 , 2 , 3 ]
lst_two = [ 4 , 5 , 6 , 7 ]
lst = [ 0 , * list_one , * list_two ]
print ( lst ) # [0, 1, 2, 3, 4, 5, 6 , 7]
country_lst_one = [ '芬兰' , '瑞典' , '挪威' ]
country_lst_two = [ '丹麦' ,'冰岛' ]
nordic_countries = [ * country_lst_one , * country_lst_two ]
print ( nordic_countries ) # ['芬兰', '瑞典', '挪威', '丹麦', '冰岛']
枚举
如果我们对列表的索引感兴趣,我们使用enumerate内置函数来获取列表中每个项目的索引。
为 索引,项目 在 枚举([ 20,30,40 ]):
打印(指数,产品)
对于 index,i 在 enumerate ( countries ) 中:
print ( 'hi' )
if i == 'Finland' :
print ( 'The country {i} has been found at index {index}' )
国家芬兰被发现在指数 1。
压缩
有时我们想在循环时组合列表。请参阅下面的示例:
水果 = [ '香蕉','橙色','芒果','柠檬','酸橙' ]
蔬菜 = [ '番茄','马铃薯','卷心菜','洋葱','胡萝卜' ]
水果和蔬菜 = []
对于 ˚F,v 在 拉链(水果,蔬菜):
fruits_and_veges。追加({ '水果':'蔬菜' : v })
打印(水果和蔬菜)
[{ '水果':'香蕉','蔬菜':'番茄' },{ '水果':'橙色','蔬菜':'土豆' },{ '水果':'芒果','蔬菜':'卷心菜' },{ '水果':'柠檬','蔬菜':'洋葱' },{ '水果':'酸橙','蔬菜':'胡萝卜' }]
第 18 天 - 正则表达式
常用表达
正则表达式或 RegEx 是一种特殊的文本字符串,有助于在数据中查找模式。RegEx 可用于检查某些模式是否存在于不同的数据类型中。要首先在 python 中使用 RegEx,我们应该导入名为re的 RegEx 模块。
该重模块
导入模块后,我们可以使用它来检测或查找模式。
进口 重新
re模块中的方法
为了找到一个模式,我们使用不同的re字符集集,允许在字符串中搜索匹配项。
- re.match():仅在字符串第一行的开头搜索,如果找到则返回匹配的对象,否则返回 None。
- re.search:如果字符串中的任何地方都有匹配对象,包括多行字符串,则返回一个匹配对象。
- re.findall:返回包含所有匹配项的列表
- re.split:获取一个字符串,在匹配点处将其拆分,返回一个列表
- re.sub:替换字符串中的一个或多个匹配项
比赛
# 语法
重新。匹配(子串,串,再。我)
#子是一个字符串或图案,字符串是我们要寻找的图案文字,如re.I是忽略大小写
进口 重新
txt = '我喜欢教 python 和 javaScript'
# 它返回一个具有跨度的对象,并且匹配
match = re。match ( '我爱教' , txt , re . I )
print ( match ) # <re.Match object; span=(0, 15), match='I love to Teaching'>
# 我们可以使用 span
span = match将匹配的开始和结束位置作为元组获取。span ()
print ( span ) # (0, 15)
# 让我们从 span 中找到开始和停止位置
start , end = span
print ( start , end ) # 0, 15
substring = txt [ start : end ]
print ( substring ) # 我喜欢教书
从上面的示例中可以看出,我们正在寻找的模式(或我们正在寻找的子字符串)是I love to Teaching。仅当文本以模式开头时,match 函数才返回一个对象。
进口 重新
txt = '我喜欢教 python 和 javaScript'
match = re。match ( '我喜欢教' , txt , re . I )
print ( match ) # None
字符串不与I like to Teaching串在一起,因此没有匹配,匹配方法返回 None。
搜索
# 语法
re . match ( substring , string , re . I )
# substring 是一个模式,string 是我们要查找的模式的文本,re.I 是 case ignore flag
进口 重新
txt = '''Python 是人类有史以来最美丽的语言。
我推荐 Python 作为第一门编程语言'''
# 它返回一个具有 span 和 match
match = re的对象。search ( 'first' , txt , re . I )
print ( match ) # <re.Match object; span=(100, 105), match='first'>
# 我们可以使用 span
span = match将匹配的开始和结束位置作为元组获取。span ()
print ( span ) # (100, 105)
# 让我们从 span
start , end = span
print找到开始和停止位置( start , end ) # 100 105
substring = txt [ start : end ]
print ( substring ) # first
如您所见,搜索比匹配好得多,因为它可以在整个文本中查找模式。搜索返回具有找到的第一个匹配项的匹配对象,否则返回None。一个更好的re函数是findall。此函数检查整个字符串中的模式并将所有匹配项作为列表返回。
使用findall搜索所有匹配项
findall()将所有匹配项作为列表返回
txt = '''Python 是人类有史以来最美丽的语言。
我推荐 Python 作为第一门编程语言'''
# 它返回一个列表
matches = re . findall ( 'language' , txt , re . I )
print ( matches ) # ['language', 'language']
如您所见,在字符串中找到了两次language一词。让我们多练习一些。现在我们将在字符串中查找 Python 和 python 单词:
txt = '''Python 是人类有史以来最美丽的语言。
我推荐 Python 作为第一门编程语言'''
# 它返回列表
匹配 = re . findall ( 'python' , txt , re . I )
print ( matches ) # ['Python', 'python']
由于我们使用re.I,因此包括小写和大写字母。如果我们没有 re.I 标志,那么我们将不得不以不同的方式编写我们的模式。让我们来看看:
txt = '''Python 是人类有史以来最美丽的语言。
我推荐 Python 作为第一门编程语言'''
匹配 = 重新。findall ( 'Python|python' , txt )
打印(匹配) # ['Python', 'python']
#
匹配 = re . findall ( '[Pp]ython' , txt )
打印(匹配) # ['Python', 'python']
替换子串
txt = '''Python 是人类有史以来最美丽的语言。
我推荐 Python 作为第一门编程语言'''
match_replaced = re。sub ( 'Python|python' , 'JavaScript' , txt , re . I )
print ( match_replaced ) # JavaScript 是人类有史以来最美丽的语言。
# 或
match_replaced = re . sub ( '[Pp]ython' , 'JavaScript' , txt , re . I )
打印( match_replaced ) # JavaScript 是人类有史以来最美丽的语言。
让我们再添加一个例子。除非我们删除 % 符号,否则以下字符串真的很难阅读。用空字符串替换 % 将清除文本。
txt = '''%I a%m te%%a%%che%r% a%n%d %% I l%o%ve te%ach%ing。
T%he%re i%sn%o%th%ing as r%ewarding a%se%duc%at%i%ng a%n%de%m%p%ow%er%ing p%e%o%请。
我找到 te%a%ching m%ore i%n%t%er%%es%ting t%h%an 任何其他 %jobs。
D%o%es 这%sm%ot%iv%a%te %y%o%u 到b%eat%e%a%cher?'''
匹配 = 重新。sub ( '%' , '' , txt )
打印(匹配)
我是老师,我喜欢教书。
没有什么比教育和赋予人们权力更有价值的了。
我发现教学比任何其他工作都有趣。这会激励你成为一名教师吗?
使用 RegEx Split 拆分文本
txt = '''我是老师,我喜欢教学。
没有什么比教育和赋予人们权力更有价值的了。
我发现教学比任何其他工作都有趣。
这会激励你成为一名教师吗?'''
print ( re . split ( ' \n ' , txt )) # splitting using \n - end of line symbol
[ '我是老师,我喜欢教学。' , '没有什么比教育和赋予人们权力更有意义的了。' , '我发现教学比任何其他工作都有趣。' , '这会激励你成为一名教师吗?' ]
编写正则表达式模式
要声明一个字符串变量,我们使用单引号或双引号。声明 RegEx 变量r’’。下面的模式只用小写字母标识苹果,为了使它不区分大小写,我们应该重写我们的模式,或者我们应该添加一个标志。
进口 重新
regex_pattern = r'apple'
txt = '苹果和香蕉是水果。一句陈词滥调说,医生的一天一个苹果已经被一天一个香蕉所取代,医生远离我。'
匹配 = re。findall ( regex_pattern , txt )
打印(匹配) # ['apple']
# 为了不区分大小写添加标志 '
matches = re . findall ( regex_pattern , txt , re . I )
print ( matches ) # ['Apple', 'apple']
# 或者我们可以使用一组字符方法
regex_pattern = r'[Aa]pple' # 这意味着第一个字母可以是苹果或苹果
匹配 = 重。findall ( regex_pattern , txt )
print ( matches ) # ['Apple', 'apple']
- []:一组字符
[ac] 表示 a 或 b 或 c
[az] 表示从 a 到 z 的任何字母
[AZ] 表示从 A 到 Z 的任何字符
[0-3] 表示 0 或 1 或 2 或 3
[0-9] 表示 0 到 9 之间的任意数字
[A-Za-z0-9] 任何单个字符,即 a 到 z、A 到 Z 或 0 到 9
- \:用于转义特殊字符
\d 表示:匹配字符串包含数字的地方(0-9 的数字)
\D 表示:匹配不包含数字的字符串
-
. : 除换行符以外的任何字符(\n)
-
^:以
r’^substring’ eg r’^love’, 一个以单词 love 开头的句子
r’[^abc] 表示不是 a,不是 b,不是 c。
- $:以
r’substring ′ 例 如 r ′ l o v e ' 例如 r'love ′例如r′love’,以单词 love 结尾的句子
- *:零次或多次
r’[a]*’ 表示一个可选的或者它可以出现多次。
- +:一次或多次
r’[a]+’ 表示至少一次(或多次)
- ?: 零次或一次
r’[a]?’ 表示零次或一次
-
{3}:正好 3 个字符
-
{3,}:至少 3 个字符
-
{3,8}:3 到 8 个字符
-
|: 要么
r’apple|banana’ 表示苹果或香蕉
- ():捕获和分组

让我们用例子来阐明上面的元字符
方括号
让我们使用方括号来包含小写和大写
regex_pattern = r'[Aa]pple' # 这个方括号表示 A 或 a
txt = '苹果和香蕉是水果。一句陈词滥调说,医生的一天一个苹果已经被一天一个香蕉所取代,让医生远离我。
匹配 = 重新。findall ( regex_pattern , txt )
print ( matches ) # ['Apple', 'apple']
如果我们要寻找香蕉,我们写的模式如下:
regex_pattern = r'[Aa]pple|[Bb]anana' # 这个方括号表示 A 或 a
txt = '苹果和香蕉是水果。一句陈词滥调说,医生的一天一个苹果已经被一天一个香蕉所取代,让医生远离我。
匹配 = 重新。findall ( regex_pattern , txt )
print ( matches ) # ['Apple', 'banana', 'apple', 'banana']
使用方括号和或运算符,我们设法提取Apple、apple、Banana 和banana。
正则表达式中的转义字符(\)
regex_pattern = r'\d' # d 是一个特殊字符,表示digits
txt = '此正则表达式示例于2019年12月6日制作并于2021年7月8日修订'
matches = re。findall ( regex_pattern , txt )
print ( matches ) # ['6', '2', '0', '1', '9', '8', '2', '0', '2', '1 '],这不是我们想要的
一次或多次(+)
regex_pattern = r'\d+' # d 是一个特殊字符,表示数字,+ 表示一次或多次
txt = '此正则表达式示例于 2019 年 12 月 6 日制作,2021 年 7 月 8 日修订'
matches = re . findall ( regex_pattern , txt )
print ( matches ) # ['6', '2019', '8', '2021'] - 现在更好了!
时期(。)
regex_pattern = r'[a].' # 这个方括号表示 a 和 。表示除换行符
txt = '''Apple 和香蕉是水果'''
匹配 = re之外的任何字符。findall ( regex_pattern , txt )
print ( matches ) # ['an', 'an', 'an', 'a', 'ar']
regex_pattern = r'[a].+' # . 任何字符,+ 任何字符一次或多次
匹配 = re。findall ( regex_pattern , txt )
print ( matches ) # ['and 香蕉是水果']
零次或多次(*)
零次或多次。该模式可能不会出现,也可能会出现多次。
regex_pattern = r'[a].*' # . 任何字符,* 任何字符零次或多次
txt = '''Apple 和香蕉是水果'''
匹配 = re。findall ( regex_pattern , txt )
print ( matches ) # ['and 香蕉是水果']
零次或一次(?)
零次或一次。该模式可能不会出现,也可能出现一次。
txt = '''我不确定是否有约定如何写电子邮件这个词。
有些人把它写成电子邮件,其他人可能把它写成电子邮件或电子邮件。'''
regex_pattern = r'[Ee]-?mail' # ? 在这里意味着 '-' 是可选的
matches = re。findall ( regex_pattern , txt )
print ( matches ) # ['e-mail', 'email', 'Email', 'E-mail']
正则表达式中的量词
我们可以使用大括号指定我们在文本中查找的子字符串的长度。让我们想象一下,我们对长度为 4 个字符的子字符串感兴趣:
txt = '此正则表达式示例于 2019 年 12 月 6 日制作并于 2021 年 7 月 8 日修订'
regex_pattern = r'\d{4}' # 正好四次
匹配 = re . findall ( regex_pattern , txt )
打印(匹配) # ['2019', '2021']
TXT = '这个正则表达式示例被做了2019年12月6,并修改了有关2021年7月8'
regex_pattern = R '\ d {1,4}' #1至4
匹配 = 重。findall ( regex_pattern , txt )
print ( matches ) # ['6', '2019', '8', '2021']
购物车 ^
- 以。。开始
txt = '此正则表达式示例于 2019 年 12 月 6 日制作并于 2021 年 7 月 8 日修订'
regex_pattern = r'^This' # ^ 表示以
matches = re开头。findall ( regex_pattern , txt )
打印(匹配) # ['This']
- 否定
txt = '此正则表达式示例制作于2019年12月6日,修改于2021年7月8日'
regex_pattern = r'[^A-Za-z ]+' # ^ in set 字符表示否定,不是A到Z,不是a 到 z,没有空格
匹配 = re。findall ( regex_pattern , txt )
print ( matches ) # ['6,', '2019', '8', '2021']
第 19 天 - 文件处理
到目前为止,我们已经看到了不同的 Python 数据类型。我们通常以不同的文件格式存储我们的数据。除了处理文件之外,我们还将在本节中看到不同的文件格式(.txt、.json、.xml、.csv、.tsv、.excel)。首先,让我们熟悉处理具有常见文件格式(.txt)的文件。
文件处理是编程的重要组成部分,它允许我们创建、读取、更新和删除文件。在 Python 中,我们使用open()内置函数来处理数据。
# 语法
open ( 'filename' , mode ) # mode(r, a, w, x, t,b) 可以是读、写、更新
- “r” - 读取 - 默认值。打开一个文件进行读取,如果文件不存在则返回错误
- “a” - Append - 打开一个文件进行追加,如果文件不存在则创建该文件
- “w” - 写入 - 打开一个文件进行写入,如果文件不存在则创建该文件
- “x” - Create - 创建指定的文件,如果文件存在则返回错误
- “t” - 文本 - 默认值。文本模式
- “b” - 二进制 - 二进制模式(例如图像)
打开文件进行阅读
打开的默认模式是读取,因此我们不必指定 ‘r’ 或 ‘rt’。我在文件目录中创建并保存了一个名为 reading_file_example.txt 的文件。让我们看看它是如何完成的:
f = open ( './files/reading_file_example.txt' )
print ( f ) # <_io.TextIOWrapper name='./files/reading_file_example.txt' mode='r' encoding='UTF-8'>
正如你在上面的例子中看到的,我打印了打开的文件,它提供了一些关于它的信息。打开的文件有不同的读取方法:read()、readline、readlines。必须使用close()方法关闭打开的文件。
- read():将整个文本作为字符串读取。如果我们想限制我们想要读取的字符数,我们可以通过将 int
值传递给read(number)方法来限制它。
f = 打开( './files/reading_file_example.txt' )
txt = f。读取()
打印(类型( txt ))
打印( txt )
f。关闭()
#输出
<类' str ' >
这是一个显示如何打开文件和读取的示例。
这是正文的第二行。
我们不打印所有文本,而是打印文本文件的前 10 个字符。
f = 打开( './files/reading_file_example.txt' )
txt = f。读取(10)
打印(类型(txt))
打印(txt)
f。关闭()
# output
< class ' str ' >
这是一个
- readline() : 只读取第一行
f = 打开( './files/reading_file_example.txt' )
line = f。readline ()
打印(类型(行))
打印(行)
f。关闭()
# output
< class ' str ' >
这是一个显示如何打开文件和读取的示例。
- readlines():逐行读取所有文本并返回行列表
f = 打开( './files/reading_file_example.txt' )
行 = f。readlines ()
打印(类型(行))
打印(行)
f。关闭()
# output
< class ' list ' >
[ '这是一个显示如何打开文件和读取的示例。\n ' , '这是文本的第二行。' ]
另一种将所有行作为列表获取的方法是使用splitlines():
f = 打开( './files/reading_file_example.txt' )
行 = f。读()。splitlines ()
打印(类型(行))
打印(行)
f。关闭()
# output
< class ' list ' >
[ '这是一个显示如何打开文件和读取的示例。' , '这是正文的第二行。' ]
打开文件后,我们应该关闭它。很容易忘记关闭它们。有一种使用with打开文件的新方法- 自行关闭文件。让我们用with方法重写前面的例子:
使用 open ( './files/reading_file_example.txt' )作为 f:
lines = f。读()。splitlines ()
打印(类型(行))
打印(行)
# output
< class ' list ' >
[ '这是一个显示如何打开文件和读取的示例。' , '这是正文的第二行。' ]
打开文件进行写入和更新
要写入现有文件,我们必须向open()函数添加一个模式作为参数:
- “a” - 追加 - 将追加到文件的末尾,如果文件没有,它会创建一个新文件。
- “w” - 写入 - 将覆盖任何现有内容,如果它创建的文件不存在。
让我们将一些文本附加到我们一直在阅读的文件中:
使用 open ( './files/reading_file_example.txt' , 'a' )作为 f :
f。write ( '此文本必须附加在最后' )
如果文件不存在,下面的方法会创建一个新文件:
使用 open ( './files/writing_file_example.txt' , 'w' )作为 f :
f。write ( '此文本将写入新创建的文件' )
删除文件
我们在上一节中已经看到,如何使用os模块创建和删除目录。现在再次,如果我们想删除一个文件,我们使用os模块。
导入 操作系统
os。删除('./files/example.txt')
如果文件不存在,remove 方法将引发错误,因此最好使用这样的条件:
导入 os
如果 os。路径。存在( './files/example.txt' ):
os。remove ( './files/example.txt' )
else :
print ( '文件不存在' )
文件类型
带有 txt 扩展名的文件
带有txt扩展名的文件是一种非常常见的数据形式,我们在上一节中已经介绍过。让我们转到 JSON 文件
带有 json 扩展名的文件
JSON 代表 JavaScript 对象表示法。实际上,它是一个字符串化的 JavaScript 对象或 Python 字典。
例子:
# 字典
person_dct = {
"name" : "Asabeneh" ,
"country" : "Finland" ,
"city" : "Helsinki" ,
"skills" :[ "JavaScrip" , "React" , "Python" ]
}
# JSON: 一个字符串形式的字典
person_json = "{'name': 'Asabeneh', 'country': 'Finland', 'city': 'Helsinki', 'skills': ['JavaScrip', 'React', ' Python']}”
# 我们使用三个引号并使其多行以使其更具可读性
person_json = '''{
"name":"Asabeneh",
"country":"Finland",
"city":"Helsinki",
"skills":[ "JavaScrip", "React","Python"]
}'''
将 JSON 更改为字典
要将 JSON 更改为字典,首先我们导入 json 模块,然后使用load方法。
import json
# JSON
person_json = '''{
"name": "Asabeneh",
"country": "Finland",
"city": "Helsinki",
"skills": ["JavaScrip", "React", "Python" ]
}'''
# 让我们将 JSON 更改为字典
person_dct = json . 加载(person_json)
打印(类型(person_dct))
打印(person_dct)
打印(person_dct [ 'name' ])
# output
< class ' dict ' >
{ ' name ' : ' Asabeneh ' , ' country ' : ' Finland ' , ' city ' : ' Helsinki ' , ' skills ' :[ ' JavaScrip ' , ' React ' , ' Python ' ] }
阿萨贝内
将字典更改为 JSON
要将字典更改为 JSON,我们使用json 模块中的dumps方法。
import json
# python 字典
person = {
"name" : "Asabeneh" ,
"country" : "Finland" ,
"city" : "Helsinki" ,
"skills" : [ "JavaScrip" , "React" , "Python" ]
}
# 让我们把它转换成 json
person_json = json . dumps ( person , indent = 4 ) # indent 可以是 2, 4, 8. 美化json
print ( type ( person_json ))
print ( person_json )
# output
#打印时没有引号,但实际上是字符串
# JSON 没有类型,它是字符串类型。
<类' str ' >
{
“名称”: “ Asabeneh ”,
“国家”: “芬兰”,
“城市”: “赫尔辛基”,
“技能”:[
“ JavaScrip ”,
“ React ”,
“ Python ”
]
}
保存为 JSON 文件
我们也可以将数据保存为 json 文件。让我们使用以下步骤将其保存为 json 文件。写一个json文件,我们使用json.dump()方法,它可以带字典、输出文件、ensure_ascii和缩进。
import json
# python 字典
person = {
"name" : "Asabeneh" ,
"country" : "Finland" ,
"city" : "Helsinki" ,
"skills" : [ "JavaScrip" , "React" , "Python" ]
}
使用 open ( './files/json_example.json' , 'w' , encoding = 'utf-8' )作为 f :
json。转储(人,f,ensure_ascii = False,缩进= 4)
在上面的代码中,我们使用了编码和缩进。缩进使 json 文件易于阅读。
带有 csv 扩展名的文件
CSV 代表逗号分隔值。CSV 是一种简单的文件格式,用于存储表格数据,例如电子表格或数据库。CSV 是数据科学中非常常见的数据格式。
例子:
"name","country","city","skills"
"Asabeneh","Finland","Helsinki","JavaScript"
例子:
使用open ( './files/csv_example.csv' )导入csv
作为f :
csv_reader = csv。读取器(˚F,分隔符= '' )#瓦特使用,读者方法来读取CSV LINE_COUNT = 0为行中csv_reader:
如果LINE_COUNT == 0:
打印(f'Column名称是:{ “” 。加入(行)}
' )
line_count += 1
else :
print (
f' \t { row [ 0 ] }是一位老师。他住在{ row [ 1 ] } , { row [ 2 ] } .' )
line_count += 1
print ( f '行数: { line_count } ' )
#输出:
列名是:姓名、国家、城市、技能
Asabeneh 是一名教师。他住在芬兰赫尔辛基。
行数:2
带有 xlsx 扩展名的文件
要读取 excel 文件,我们需要安装xlrd包。在我们介绍了使用 pip 安装软件包之后,我们将介绍这一点。
导入 xlrd
excel_book = xlrd。open_workbook(”样品。XLS)
打印(excel_book。nsheets)
打印(excel_book。sheet_names)
带有 xml 扩展名的文件
XML 是另一种看起来像 HTML 的结构化数据格式。在 XML 中,标签不是预定义的。第一行是一个 XML 声明。person 标签是 XML 的根。该人具有性别属性。 示例:XML
<? xml版本= " 1.0 " ?>
<人 性别= “女性” >
< name >Asabeneh</ name >
<国家>芬兰</国家>
< city >赫尔辛基</ city >
<技能>
<技能>JavaScrip</技能>
<技能>反应</技能>
<技能>Python</技能>
</技能>
</人>
有关如何读取 XML 文件
导入 xml。etree。ElementTree 作为 ET
树 = ET。解析( './files/xml_example.xml' )
root = tree。getroot()
打印('根标签:',根。标签)
的打印('属性:',根。ATTRIB)
为 孩子 在 根:
打印('字段:',孩子。标签)
#输出
根标签:人
属性:{ '性别':'男性' }
字段:名称
领域:国家
领域:城市
领域:技能
第 20 天 - Python 包管理器(PIP)
什么是PIP?
PIP 代表首选安装程序。我们使用pip来安装不同的 Python 包。包是一个 Python 模块,可以包含一个或多个模块或其他包。我们可以安装到应用程序的一个或多个模块是一个包。在编程中,我们不必编写每个实用程序,而是安装包并将它们导入到我们的应用程序中。
安装PIP
如果您没有安装 pip,让我们现在安装它。转到您的终端或命令提示符并复制并粘贴以下内容:
asabeneh@Asabeneh: ~ $ pip install pip
通过写入检查是否安装了 pip
pip --version
asabeneh @ Asabeneh:〜 $ PIP - -版本
点子 21.1。3 来自 / usr / local / lib / python3。7 /站点-包/ pip(python 3.9 .6)
如您所见,我使用的是 pip 版本 21.1.3,如果您看到某个数字低于或高于该数字,则表示您已安装 pip。
让我们检查一下 Python 社区中出于不同目的使用的一些包。只是为了让您知道有许多软件包可用于不同的应用程序。
使用 pip 安装包
让我们尝试安装numpy,称为 numeric python。它是机器学习和数据科学社区中最受欢迎的软件包之一。
NumPy 是使用 Python 进行科学计算的基础包。其中包括:
- 一个强大的 N 维数组对象
- 复杂的(广播)功能
- 用于集成 C/C++ 和 Fortran 代码的工具
- 有用的线性代数、傅立叶变换和随机数功能
asabeneh@Asabeneh: ~ $ pip install numpy
让我们开始使用 numpy。打开你的python交互式shell,编写python然后导入numpy,如下所示:
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 导入 numpy
>> > numpy。版本。版本
' 1.20。1 '
>> > lst = [ 1 , 2 , 3 ,4 , 5 ]
>> > np_arr = numpy。数组( lst )
>> > np_arr
数组([ 1 , 2 , 3 , 4 , 5 ])
>> > len ( np_arr )
5
>> > np_arr * 2
数组([ 2 , 4 , 6 , 8 , 10 ])
>> > np_arr + 2
数组([ 3 , 4 , 5 , 6 , 7 ])
>> >
Pandas 是一个开源的、BSD 许可的库,为 Python 编程语言提供高性能、易于使用的数据结构和数据分析工具。让我们安装numpy的大哥pandas:
asabeneh@Asabeneh: ~ $ pip install pandas
asabeneh @ Asabeneh:~ $ python
Python 3.9。6(默认,2021 年6月 28 日 ,15:26:21)
[锵 11.0 0.0(铛- 1100.0。33.8)在 达尔文
式 的“帮助”,“版权”,“信用” 或 “许可” 的 更多 信息。
>> > 导入 熊猫
本节不是关于 numpy 或 pandas,在这里我们试图学习如何安装包以及如何导入它们。如果需要,我们将在其他部分讨论不同的包。
让我们导入一个网页浏览器模块,它可以帮助我们打开任何网站。我们不需要安装这个模块,它已经在 Python 3 中默认安装了。例如,如果你想随时打开任意数量的网站,或者你想安排一些事情,可以使用这个webbrowser模块。
import webbrowser # 网页浏览器模块打开网站
# url 列表:python
url_lists = [
'http://www.python.org' ,
'https://www.linkedin.com/in/asabeneh/' ,
'https://github.com/Asabeneh' ,
'https://twitter.com/Asabeneh' ,
]
#打开在不同的选项卡网站上面的列表中
的 网址 在 url_lists:
网页浏览器。open_new_tab ( url )
卸载软件包
如果您不想保留已安装的软件包,可以使用以下命令删除它们。
pip 卸载包名
包裹清单
查看我们机器上已安装的软件包。我们可以使用 pip 后跟列表。
点子列表
显示包
显示有关包的信息
pip 显示包名
asabeneh@Asabeneh: ~ $ pip show pandas
名称:熊猫
版本:1.2.3
总结:强大的数据结构,用于数据分析、时间序列和统计
主页:http://pandas.pydata.org
作者:无
作者邮箱:无
许可证:BSD
位置:/usr/local/lib/python3.7/site-packages
需要:python-dateutil、pytz、numpy
必填项:
如果我们想要更多细节,只需添加 --verbose
asabeneh@Asabeneh: ~ $ pip show --verbose pandas
名称:熊猫
版本:1.2.3
总结:强大的数据结构,用于数据分析、时间序列和统计
主页:http://pandas.pydata.org
作者:无
作者邮箱:无
许可证:BSD
位置:/usr/local/lib/python3.7/site-packages
需要:numpy、pytz、python-dateutil
必填项:
元数据版本:2.1
安装程序:pip
分类器:
开发状态 :: 5 - 量产/稳定
环境 :: 控制台
操作系统 :: 独立于操作系统
目标受众 :: 科学/研究
编程语言 :: Python
编程语言 :: Python :: 3
编程语言 :: Python :: 3.5
编程语言 :: Python :: 3.6
编程语言 :: Python :: 3.7
编程语言 :: Python :: 3.8
编程语言 :: Cython
主题 :: 科学/工程
入口点:
[pandas_plotting_backends]
matplotlib = pandas:plotting._matplotlib
画中画冻结
生成已安装的 Python 包及其版本,输出适合在需求文件中使用。requirements.txt 文件是一个文件,它应该包含 Python 项目中所有已安装的 Python 包。
asabeneh@Asabeneh: ~ $ pip freeze
文档工具==0.11
Jinja2==2.7.2
标记安全==0.19
Pygments==1.6
狮身人面像==1.2.2
pip freeze 为我们提供了使用、安装的软件包及其版本。我们将它与 requirements.txt 文件一起用于部署。
从 URL 读取
到目前为止,您已经熟悉如何读取或写入位于本地机器上的文件。有时,我们想使用 url 或 API 从网站读取。API 代表应用程序接口。它是一种主要作为 json 数据在服务器之间交换结构化数据的方法。要打开网络连接,我们需要一个名为requests的包- 它允许打开网络连接并实现 CRUD(创建、读取、更新和删除)操作。在本节中,我们将只介绍读取矿石获取 CRUD 的一部分。
让我们安装请求:
asabeneh @ Asabeneh : ~ $ pip install requests
我们将在requests模块中看到get、status_code、headers、text和json方法:
- get():打开网络并从 url 获取数据 - 它返回一个响应对象
- status_code : 获取数据后,我们可以检查操作的状态(成功、错误等)
- headers : 检查标题类型
- text : 从获取的响应对象中提取文本
- json :提取json数据让我们从这个网站读取一个txt文件,https://www.w3.org/TR/PNG/iso_8859-1.txt。
import requests # 导入请求模块
url = 'https://www.w3.org/TR/PNG/iso_8859-1.txt' # 来自网站的文本
响应 = 请求。get ( url ) # 打开网络并获取数据
print ( response )
print ( response . status_code ) # status code, success:200
print ( response . headers ) # headers 信息
print ( response . text ) # 给出来自的所有文本这一页
<响应 [200] >
200
{ “日期”:“格林威治标准时间 2019 年 12 月 8 日 18:00:31 ”,“最后修改时间”:“格林威治标准时间 2003 年 11 月 7 日星期五 05:51:11 ”,“ etag ”:“ 17e9-3cb15080808087 -gzip" ' , '接受范围' : '字节' , '缓存控制' : ' max-age=31536000 ' , '过期' : '2020 年 12 月 7 日星期一 18:00:31 GMT包括子域;预载', '内容安全策略': '升级不安全请求' }
- 让我们从 API 中读取。API 代表应用程序接口。它是一种在服务器之间交换结构数据的手段,主要是 json 数据。API
示例:https : //restcountries.eu/rest/v2/all。让我们使用requests模块阅读这个 API 。
导入 请求
url = 'https://restcountries.eu/rest/v2/all' # 国家 API
响应 = 请求。get ( url ) # 打开网络并获取数据
print ( response ) # response 对象
print ( response . status_code ) # status code, success:200
countries = response . json ()
打印(国家[: 1 ]) # 我们只对第一个国家进行切片,去掉切片可以看到所有国家
<响应 [200] >
200
[{ ' alpha2Code ':' AF ',
' alpha3Code ':' AFG ',
' altSpellings ':[ ' AF ','阿富汗' ],
'区域':652230.0,
'边界':[ ' IRN ',' PAK ' , ' TKM ' , ' UZB ', 'TJK ',' CHN ' ],
' callingCodes ':[ ' 93 ' ],
'资本':'喀布尔',
' cioc ':' AFG ',
'货币':[{ '代码':' AFN ','姓名' : '阿富汗阿富汗尼' , '符号':' ؋ ' }],
'区域居民称谓词':'阿富汗',
'标志':' https://restcountries.eu/data/afg.svg ',
'基尼':27.8,
'语言':[{ ' iso639_1 ':“ ps ”,
“ iso639_2 ”:“脓液”,
“名称”:'普什图语' ' nativeName ':' پښتو “ },
{ ' iso639_1 ':' uz ',
' iso639_2 ':' uzb ',
' name ':' Uzbek ',
' nativeName ':' Oʻzbek ' },
{ ' iso639_1 ':' TK ',
' iso639_2 ':'三轮',
'名称':'土库曼',
' nativeName ':'土库曼' }],
'经纬度':[33.0,65.0],
'名称':'阿富汗' ,
'本地名称':' افغانستان ',
' numericCode ': ' 004 ',
'人口':27657145,
'地区': '亚洲',
' regionalBlocs ':[{ '首字母缩略词': ' SAARC名称'南亚区域协会',
'南亚区域协会':合作' ,
'otherAcronyms “:[],
' otherNames ':[]}],
' subregion ':'南亚',
'时区':[ ' UTC+04:30 ' ],
' topLevelDomain ':[ '. af ' ],
' translations ':{ ' br ':' Afeganistão ',
' de ':'阿富汗',
' ES ':'阿富汗',
' FA ':' افغانستان ',
' FR ':'阿富汗',
'小时':'阿富汗',
'它':'阿富汗',
' JA ':'アフガニスタン',
' nl ':'阿富汗',
' pt ':' Afeganistão ' }}]
我们使用响应对象中的json()方法,如果我们正在获取 JSON 数据。对于 txt、html、xml 等文件格式,我们可以使用text。
创建包
我们根据一些标准将大量文件组织在不同文件夹和子文件夹中,以便我们可以轻松查找和管理它们。如您所知,一个模块可以包含多个对象,例如类、函数等。一个包可以包含一个或多个相关模块。一个包实际上是一个包含一个或多个模块文件的文件夹。让我们使用以下步骤创建一个名为 mypackage 的包:
在 30DaysOfPython 文件夹中创建一个名为 mypacakge 的新文件夹在 mypackage 文件夹中创建一个空的init .py 文件。使用以下代码创建模块 algorithm.py 和 greet.py:
# mypackage/arithmetics.py
#arithmetics.py
def add_numbers ( * args ):
total = 0
for num in args :
total += num
return total
def 减法( a , b ):
返回( a - b )
def multiple ( a , b ):
返回 a * b
def 除法( a , b ):
返回 a / b
def 余数( a , b ):
返回 a % b
def power ( a , b ):
返回 a ** b
# mypackage/greet.py
# greet.py
def greet_person ( firstname , lastname ):
return f' { firstname } { lastname },欢迎来到 30DaysOfPython Challenge!
包的文件夹结构应如下所示:
─ 我的包裹
├── __init__.py
├──算术.py
└── 问候.py
现在让我们打开 python 交互式 shell 并尝试我们创建的包:
asabeneh@Asabeneh: ~ /Desktop/30DaysOfPython$ python
Python 3.9.6(默认,2021 年 6 月 28 日,15:26:21)
[Clang 11.0.0 (clang-1100.0.33.8)] 在达尔文
输入“ help ”、“ copyright ”、“ credits ”或“ license ” 以获取更多信息。
>>> from mypackage 导入算法
>>>算术.add_numbers(1, 2, 3, 5)
11
>>>算术.减法(5, 3)
2
>>>算术.multiple(5, 3)
15
>>>算术.除法(5, 3)
1.6666666666666667
>>>算术.remainder(5, 3)
2
>>> 算术.power(5, 3)
125
>>> from mypackage 导入问候
>>> greet.greet_person( ' Asabeneh ' , ' Yetayeh ' )
' Asabeneh Yetayeh,欢迎参加 30DaysOfPython 挑战赛!'
>>>
如您所见,我们的软件包运行良好。包文件夹包含一个名为init .py的特殊文件- 它存储包的内容。如果我们将init .py 放在包文件夹中,python start 会将其识别为包。在初始化指定从模块的资源导入到其他Python文件的.py自曝。导入包时,空的init .py 文件使所有函数都可用。该INIT的.py是必不可少的文件夹以通过Python作为一个包被识别。
关于包的更多信息
- 数据库
SQLAlchemy 或 SQLObject - 面向对象访问多个不同的数据库系统
pip 安装 SQLAlchemy
- Web开发
Django - 高级 Web 框架。
pip 安装 django
Flask - 基于 Werkzeug、Jinja 2 的 Python 微框架。(它是 BSD 许可的)
pip 安装烧瓶
- HTML解析器
Beautiful Soup - 专为快速周转项目(如屏幕抓取)而设计的 HTML/XML 解析器,将接受不良标记。
pip 安装 beautifulsoup4
PyQuery - 在 Python 中实现 jQuery;显然比 BeautifulSoup 快。
- XML处理
ElementTree - Element 类型是一个简单但灵活的容器对象,旨在在内存中存储分层数据结构,例如简化的 XML 信息集。–注意:Python 2.5 及更高版本在标准库中有 ElementTree
- 图形用户界面
PyQt - 跨平台 Qt 框架的绑定。
TkInter - 传统的 Python 用户界面工具包。
- 数据分析、数据科学和机器学习
Numpy:Numpy(numeric python) 被称为 Python 中最受欢迎的机器学习库之一。
Pandas:是 Python 中的数据分析、数据科学和机器学习库,提供高级数据结构和多种分析工具。
SciPy:SciPy 是一个面向应用程序开发人员和工程师的机器学习库。SciPy 库包含用于优化、线性代数、集成、图像处理和统计的模块。
Scikit-Learn:它是 NumPy 和 SciPy。它被认为是处理复杂数据的最佳库之一。
TensorFlow:是谷歌构建的机器学习库。
Keras:被认为是 Python 中最酷的机器学习库之一。它提供了一种更简单的机制来表达神经网络。Keras 还提供了一些用于编译模型、处理数据集、图形可视化等的最佳实用程序。
- 网络:
requests:是一个我们可以用来向服务器发送请求的包(GET、POST、DELETE、PUT)
pip 安装请求

🎉 恭喜! 🎉你是一个非凡的人,你有非凡的潜力。
作为一个续集更新,感兴趣了解下面的学习内容,记得关注我,你们的三连是我持续输出的动力,感谢。