前言
据说「 前言 」 写太多会被人唾弃,所以,这次直接进入正题。
「 画解数据结构 」
点击我跳转末尾 获取 粉丝专属 《算法和数据结构》源码。
❤️《画解数据结构》(1-1)画解顺序表❤️
❤️《画解数据结构》(1-2)画解链表❤️
❤️《画解数据结构》(1-3)画解栈❤️
❤️《画解数据结构》(1-4)画解队列❤️
❤️《画解数据结构》(1-5)画解双端队列❤️
❤️《画解数据结构》(1-6)画解哈希表❤️
❤️《画解数据结构》(2-1)画解树❤️
❤️《画解数据结构》(2-2)画解二叉树❤️
❤️《画解数据结构》(2-3)画解二叉搜索树❤️
❤️《画解数据结构》(2-4)画解堆❤️
❤️《画解数据结构》(2-5)画解AVL树❤️
❤️《画解数据结构》(2-6)画解线段树❤️
❤️《画解数据结构》(2-7)画解字典树❤️
❤️《画解数据结构》(2-8)画解霍夫曼树❤️
❤️《画解数据结构》(2-9)画解并查集❤️
❤️《画解数据结构》(3-1)画解图❤️
❤️《画解数据结构》(3-2)画解二分匹配❤️
❤️《画解数据结构》(3-3)画解最短路❤️
❤️《画解数据结构》(3-5)画解最小生成树❤️
❤️《画解数据结构》(3-4)画解强连通❤️
一、顺序表的概念
1、顺序存储
顺序存储结构,是指用一段地址连续的存储单元依次存储线性表的数据元素。

2、存储方式
在编程语言中,用一维数组来实现顺序存储结构,在C语言中,把第一个数据元素存储到下标为 0 的位置中,把第 2 个数据元素存储到下标为 1 的位置中,以此类推。
3、长度和容量
数组的长度指的是数组当前有多少个元素,数组的容量指的是数组最大能够存放多少个元素。如果数组元素大于最大能存储的范围,在程序上是不允许的,可能会产生意想不到的问题,实现上是需要规避的。

如上图所示,数组的长度为 5,即红色部分;容量为 8,即红色 加 蓝色部分。
4、数据结构定义
#define MAXN 1024
#define DataType int // (1)
struct SeqList {
DataType data[MAXN]; // (2)
int length; // (3)
};
-
(
1
)
(1)
(1) 数组类型为
DataType,定义为int; -
(
2
)
(2)
(2)
SeqList定义的就是一个最多存放MAXN个元素的数组,MAXN代表数组容量; -
(
3
)
(3)
(3)
length代表数组长度,即当前的元素个数。
二、常用接口实现
1、只读接口
1)索引
索引 就是通过 数组下标 寻找 数组元素 的过程。C语言实现如下:
DataType SeqListIndex(struct SeqList *sq, int i) {
return sq->data[i]; // (1)
}
- ( 1 ) (1) (1) 调用方需要注意 i i i 的取值必须为非负整数,且小于数组最大长度。否则有可能导致异常,引发崩溃。
- 索引的算法时间复杂度为
O
(
1
)
O(1)
O(1)。

2)查找
查找 就是通过 数组元素 寻找 数组下标 的过程,是索引的逆过程。
对于有序数组,可以采用 二分 进行查找,时间复杂度为
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n);对于无序数组,只能通过遍历比较,由于元素可能不在数组中,可能遍历全表,所以查找的最坏时间复杂度为
O
(
n
)
O(n)
O(n)。
简单介绍一个线性查找的例子,实现如下:
DataType SeqListFind(struct SeqList *sq, DataType dt) {
int i;
for(i = 0; i < sq->length; ++i) { // (1)
if(sq->data[i] == dt) {
return i; // (2)
}
}
return -1; // (3)
}
- ( 1 ) (1) (1) 遍历数组元素;
- ( 2 ) (2) (2) 对数组元素 和 传入的数据进行判等,一旦发现相等就返回对应数据的下标;
-
(
3
)
(3)
(3) 当数组遍历完还是找不到,说明这个数据肯定是不存在的,直接返回
−
1
-1
−1。

3)获取长度
获取 数组的长度 指的是查询当前有多少元素。可以直接用结构体的内部变量。C语言代码实现如下:
DataType SeqListGetLength(struct SeqList *sq) {
return sq->length;
}
2、可写接口
1)插入
插入接口定义为:在数组的第 k k k 个元素前插入一个数 v v v。由于数组是连续存储的,那么从 k k k 个元素往后的元素都必须往后移动一位,当 k = 0 k=0 k=0 时,所有元素都必须移动,所以最坏时间复杂度为 O ( n ) O(n) O(n)。C语言代码实现如下:
int SeqListInsert(struct SeqList *sq, int k, DataType v) {
int i;
if(sq->length == MAXN) {
return 0; // (1)
}
for(i = sq->length; i > k; --i) {
sq->data[i] = sq->data[i-1]; // (2)
}
sq->data[k] = v; // (3)
sq->length ++; // (4)
return 1; // (5)
}
- ( 1 ) (1) (1) 当元素个数已满时,返回 0 0 0 代表插入失败;
- ( 2 ) (2) (2) 从第 k k k 个数开始,每个数往后移动一个位置,注意必须逆序;
- ( 3 ) (3) (3) 将第 k k k 个数变成 v v v;
- ( 4 ) (4) (4) 插入了一个数,数组长度加一;
- ( 5 ) (5) (5) 返回 1 1 1 代表插入成功;
2)删除
插入接口定义为:将数组的第 k k k 个元素删除。由于数组是连续存储的,那么第 k k k 个元素删除,往后的元素势必要往前移动一位,当 k = 0 k=0 k=0 时,所有元素都必须移动,所以最坏时间复杂度为 O ( n ) O(n) O(n)。C语言代码实现如下:
int SeqListDelete(struct SeqList *sq, int k) {
int i;
if(sq->length == 0) {
return 0; // (1)
}
for(i = k; i < sq->length - 1; ++i) {
sq->data[i] = sq->data[i+1]; // (2)
}
sq->length --; // (3)
return 1; // (4)
}
- ( 1 ) (1) (1) 返回0代表删除失败;
- ( 2 ) (2) (2) 从前往后;
- ( 3 ) (3) (3) 数组长度减一;
- ( 4 ) (4) (4) 返回1代表删除成功;
三、优缺点
1、优点
1)无须为表示表中元素逻辑关系而增加额外的存储空间;
2)随机存取元素时可以达到
O
(
1
)
O(1)
O(1),效率高;
2、缺点
1)插入和删除时需要移动大量元素;
2)必须一开始就确定存储空间的容量;
四、数组相关算法
1、线性枚举
1)问题描述
给定一个长度为 n ( 1 ≤ n ≤ 1 0 5 ) n(1 \le n \le 10^5) n(1≤n≤105) 的整型数组,求所有数组元素中的其中的最小值。
2)动图演示
3)示例说明
蓝色的数据代表的是数组数据,红色的数据代表当前枚举到的数据,这样就可以遍历所有的数据进行逻辑处理了。
4)算法描述
遍历数组,进行条件判断,条件满足则执行逻辑。这里的条件就是 枚举到的数 是否小于 当前最小值,执行逻辑为 将 当前枚举到的数 赋值给 当前最小值;
5)源码详解
int findMin(int* nums, int numsSize){
int i, min = 100000;
for(i = 0; i < numsSize; ++i) { // (1)
if(nums[i] < min) { // (2)
min = nums[i];
}
}
return min; // (3)
}
- ( 1 ) (1) (1) 遍历数组中所有的数;
-
(
2
)
(2)
(2) 如果 当前枚举到的数 比记录的变量
min小,则将它赋值给min;否则,不做任何处理; -
(
3
)
(3)
(3) 最后,
min中存储的就是整个数组的最小值。
2、前缀和差分
1)问题描述
给定一个 n ( n ≤ 1 0 5 ) n (n \le 10^5) n(n≤105) 个元素的整型数组 a i a_i ai,再给出 m ( m ≤ 1 0 5 ) m(m \le 10^5) m(m≤105) 次询问,每次询问是一个区间 [ l , r ] [l, r] [l,r],求 h ( l , r ) = ∑ k = l r a k h(l,r) = \sum_{k=l}^r a_k h(l,r)=∑k=lrak
2)动图演示
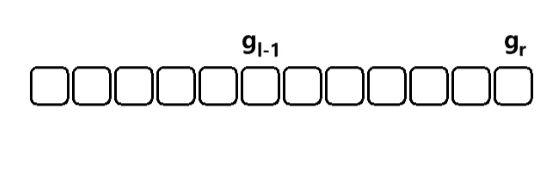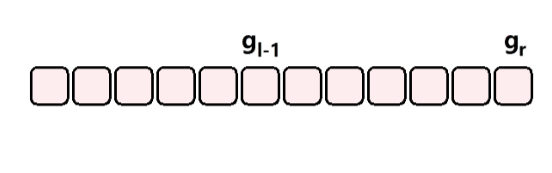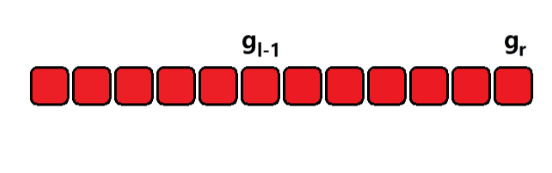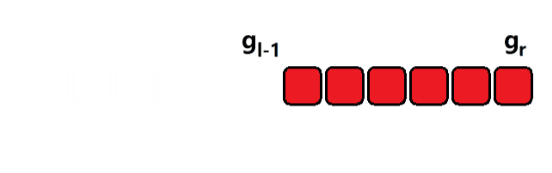
3)样例分析
如上图所示,只需要记录一个前缀和,然后就可以通过一次减法将区间的值计算出来。时间复杂度 O ( 1 ) O(1) O(1)。这种就是差分的思想。
4)算法描述
第一个枚举,利用一个数组sum,存储前
i
i
i 个元素的和。
第二个枚举,读入
m
m
m 组数据
l
,
r
l, r
l,r,对每组数据,通过
O
(
1
)
O(1)
O(1) 获取答案,即
s
u
m
r
−
s
u
m
l
−
1
sum_r - sum_{l-1}
sumr−suml−1。
5)源码详解
int sum[maxn];
int* prefixSum(int* nums, int numsSize, int m, int *l, int *r){
int i;
int *ret;
for(i = 0; i < numsSize; ++i) {
sum[i] = nums[i];
if(i)
sum[i] += sum[i-1]; // (1)
}
ret = (int *) malloc( m * sizeof(int) ); // (2)
for(i = 0; i < m; ++i) {
int leftsum = l==0? 0 : sum[l-1]; // (3)
int rightsum = sum[r];
ret[i] = rightsum - leftsum; // (4)
}
return ret;
}
- ( 1 ) (1) (1) 计算前缀和;
- ( 2 ) (2) (2) 需要返回的数组;
- ( 3 ) (3) (3) 这里是为了防止数组下标越界;
- ( 4 ) (4) (4) 核心 O ( 1 ) O(1) O(1) 的差分计算;
3、双指针
1)问题描述
给定一个长度为 n ( 1 ≤ n ≤ 1 0 7 ) n (1 \le n \le 10^7) n(1≤n≤107) 的字符串 s s s,求一个最长的满足所有字符不重复的子串。
2)动图演示

3)样例说明
维护两个指针
i
i
i 和
j
j
j,区间
[
i
,
j
]
[i, j]
[i,j] 内的子串,应该时刻保持其中所有字符不重复,一旦发现重复字符,就需要自增
i
i
i(即执行
i
=
i
+
1
i = i + 1
i=i+1);否则,执行
j
=
j
+
1
j = j + 1
j=j+1,直到
j
j
j 不能再增加为止。
过程中,记录合法情况下
j
−
i
+
1
j - i + 1
j−i+1 的最大值。
4)算法描述
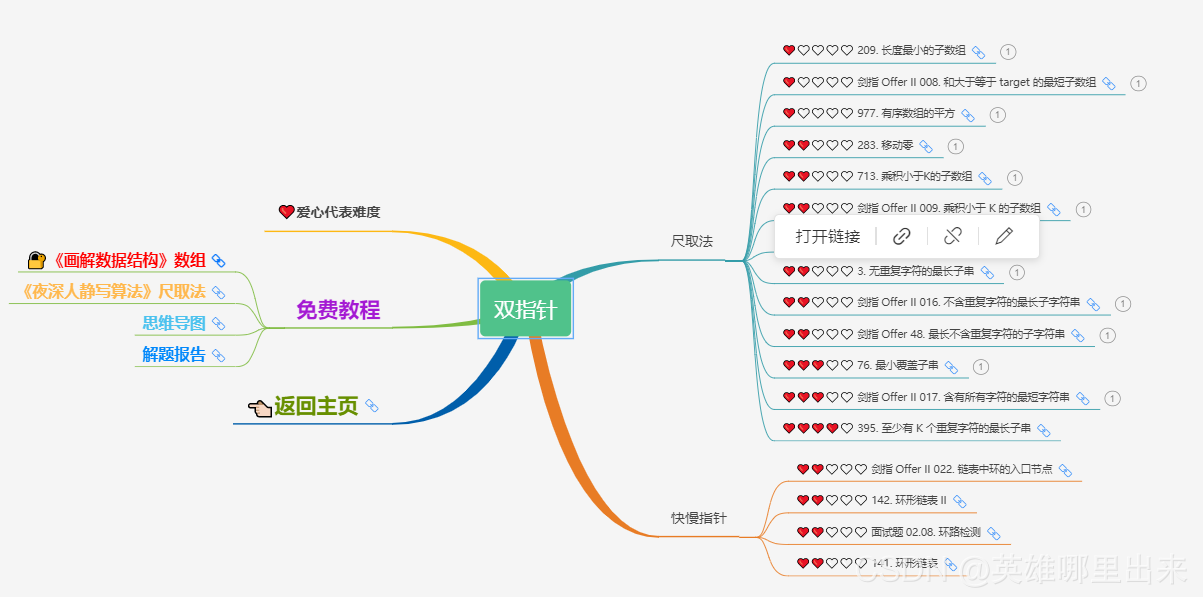
如上文所述,这种利用问题特性,通过两个指针,不断调整区间,从而求出问题最优解的算法就叫 “尺取法”,由于利用的是两个指针,所以又叫 “双指针” 算法。
这里 “尺” 的含义,主要还是因为这类问题,最终要求解的都是连续的序列(子串),就好比一把尺子一样,故而得名。
算法描述如下:
1)初始化 i = 0 i=0 i=0, j = i − 1 j=i-1 j=i−1,代表一开始 “尺子” 的长度为 0;
2)增加 “尺子” 的长度,即 j = j + 1 j = j +1 j=j+1;
3)判断当前这把 “尺子” [ i , j ] [i, j] [i,j] 是否满足题目给出的条件:
3.a)如果不满足,则减小 “尺子” 长度,即 i = i + 1 i = i + 1 i=i+1,回到 3);
3.b)如果满足,记录最优解,回到 2);
- 上面这段文字描述的比较官方,其实这个算法的核心,只有一句话:
满足条件时, j j j++;不满足条件时, i i i++; - 如图所示,当区间
[
i
,
j
]
[i, j]
[i,j] 满足条件时,用蓝色表示,此时
j
j
j 自增;反之闪红,此时
i
i
i 自增。

5)源码详解
int getmaxlen(int n, char *str, int& l, int& r) {
int ans = 0, i = 0, j = -1, len; // 1)
memset(h, 0, sizeof(h)); // 2)
while (j++ < n - 1) { // 3)
++h[ str[j] ]; // 4)
while (h[ str[j] ] > 1) { // 5)
--h[ str[i] ];
++i;
}
len = j - i + 1;
if(len > ans) // 6)
ans = len, l = i, r = j;
}
return ans;
}
- 1)初始化
i = 0, j = -1,代表 s [ i : j ] s[i:j] s[i:j] 为一个空串,从空串开始枚举; - 2)需要维护一个哈希表,哈希表记录的是当前枚举的区间 s [ i : j ] s[i:j] s[i:j] 中每个字符的个数;
- 3)只推进子串的右端点;
- 4)在哈希表中记录字符的个数;
- 5)当
h[ str[j] ] > 1满足时,代表出现了重复字符str[j],这时候左端点 i i i 推进,直到没有重复字符为止; - 6)记录当前最优解的长度
j - i + 1,更新; - 这个算法执行完毕,我们就可以得到最长不重复子串的长度为 a n s ans ans,并且 i i i 和 j j j 这两个指针分别只自增 n n n 次,两者自增相互独立,是一个相加而非相乘的关系,所以这个算法的时间复杂度为 O ( n ) O(n) O(n) 。
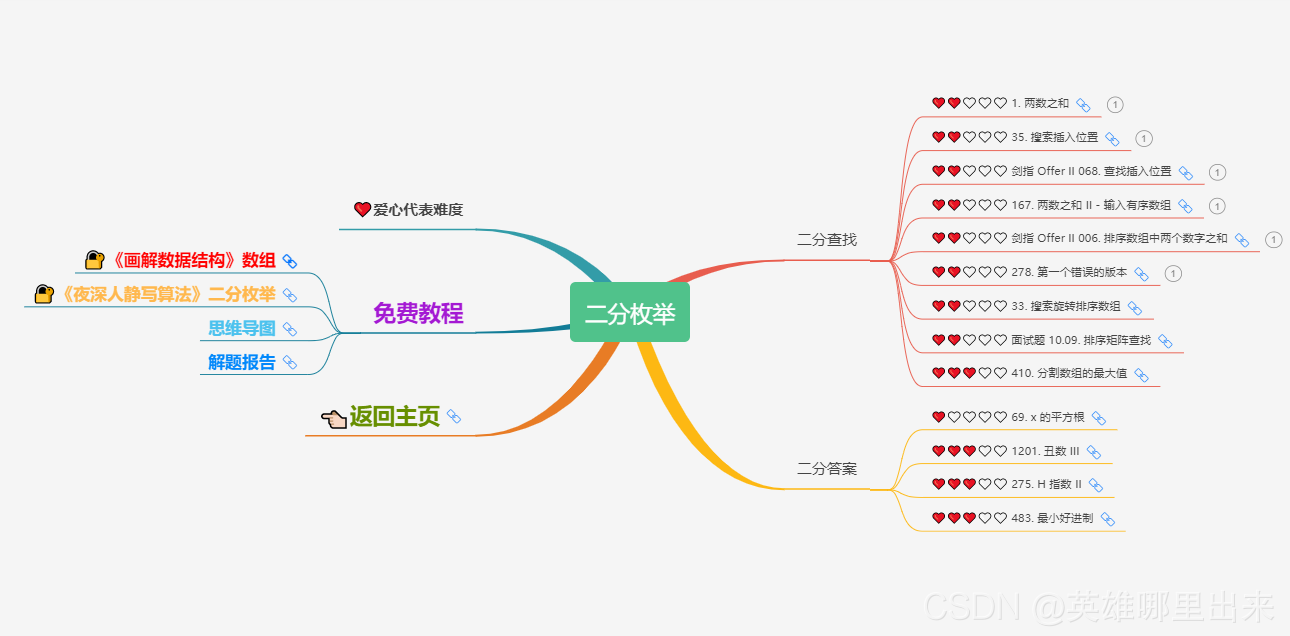
4、二分枚举
1)问题描述
给定一个 n ( n ≤ 1 0 6 ) n(n \le 10^6) n(n≤106) 个元素的有序整型数组和一个 t a r g e t target target 值,求在 O ( l o g 2 n ) O(log_2n) O(log2n) 的时间内找到值为 t a r g e t target target 的整型的数组下标,不存在则返回 -1。
2)动图演示

3)样例说明
需要找值为
5
5
5 的这个元素。
黄色箭头 代表都是左区间端点
l
l
l,红色箭头 代表右区间端点
r
r
r。蓝色的数据为数组数据,绿色的数字代表的是数组下标,初始化
l
=
0
l = 0
l=0,
r
=
7
r = 7
r=7,由于数组有序,则可以直接折半,令
m
i
d
=
(
l
+
r
)
/
2
=
3
mid = (l + r) / 2 = 3
mid=(l+r)/2=3,则
5
5
5 一定落入区间
[
0
,
3
]
[0, 3]
[0,3],这时候令
r
=
3
r = 3
r=3,继续执行,直到
l
>
r
l > r
l>r 结束迭代。
最后,当
m
i
d
=
2
mid=2
mid=2 时,找到数据 5。
4)算法描述
a)令初始情况下,数组下标从 0 开始,且数组长度为
n
n
n,则定义一个区间,它的左端点是
l
=
0
l=0
l=0,右端点是
r
=
n
−
1
r = n-1
r=n−1;
b)生成一个区间中点
m
i
d
=
(
l
+
r
)
/
2
mid = (l + r) / 2
mid=(l+r)/2,并且判断
m
i
d
mid
mid 对应的数组元素和给定的目标值的大小关系,主要有三种:
b.1)目标值 等于 数组元素,直接返回
m
i
d
mid
mid;
b.2)目标值 大于 数组元素,则代表目标值应该出现在区间
[
m
i
d
+
1
,
r
]
[mid+1, r]
[mid+1,r],迭代左区间端点:
l
=
m
i
d
+
1
l = mid + 1
l=mid+1;
b.3)目标值 小于 数组元素,则代表目标值应该出现在区间
[
l
,
m
i
d
−
1
]
[l, mid-1]
[l,mid−1],迭代右区间端点:
r
=
m
i
d
−
1
r = mid - 1
r=mid−1;
c)如果这时候
l
>
r
l > r
l>r,则说明没有找到目标值,返回
−
1
-1
−1;否则,回到 b)继续迭代。
5)源码详解
int search(int *nums, int numsSize, int target) {
int l = 0, r = numsSize - 1; // (1)
while(l <= r) { // (2)
int mid = (l + r) >> 1; // (3)
if(nums[mid] == target) {
return mid; // (4)
}else if(target > nums[mid]) {
l = mid + 1; // (5)
}else if(target < nums[mid]) {
r = mid - 1; // (6)
}
}
return -1; // (7)
}
- ( 1 ) (1) (1) 初始化区间左右端点;
- ( 2 ) (2) (2) 一直迭代左右区间的端点,直到 左端点 大于 右端点 结束;
-
(
3
)
(3)
(3)
>> 1等价于除 2,也就是这里mid代表的是l和r的中点; -
(
4
)
(4)
(4)
nums[mid] == target表示正好找到了这个数,则直接返回下标mid; -
(
5
)
(5)
(5)
target > nums[mid]表示target这个数在区间 [ m i d + 1 , r ] [mid+1, r] [mid+1,r] 中,所以才有左区间赋值如下:l = mid + 1; -
(
6
)
(6)
(6)
target < nums[mid]表示target这个数在区间 [ l , m i d − 1 ] [l, mid - 1] [l,mid−1] 中,所以才有右区间赋值如下:r = mid - 1; -
(
7
)
(7)
(7) 这一步呼应了
(
2
)
(2)
(2),表示这不到给定的数,直接返回
-1;
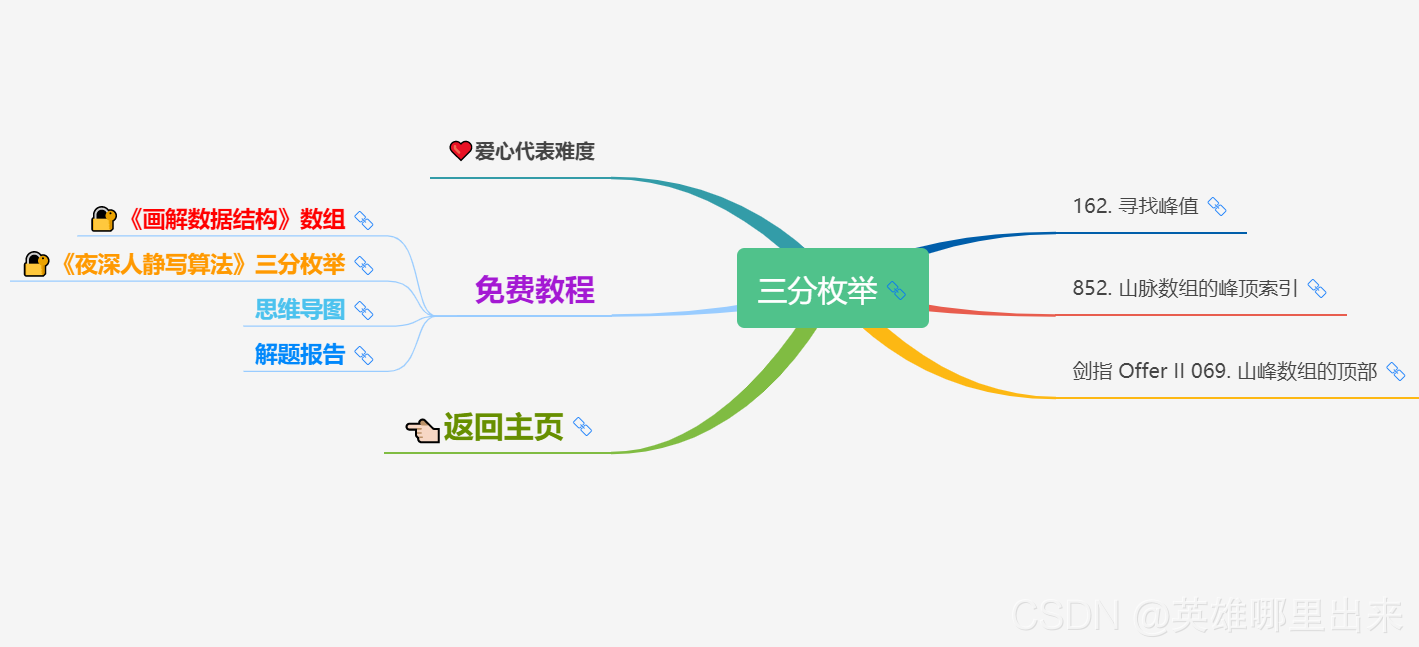
5、三分枚举
三分枚举 类似 二分枚举 的思想,也是将区间一下子砍掉一块基本完全不可能的块,从而减小算法的时间复杂度。只不过 二分枚举 解决的是 单调性 问题。而 三分枚举 解决的是 极值问题。
6、插入排序
1)问题描述
给定一个 n n n 个元素的数组,数组下标从 0 0 0 开始,采用「 插入排序 」将数组按照 「升序」排列。
2)动图演示

3)样例说明
| 图示 | 含义 |
|---|---|
| ■ 的柱形 | 代表尚未排好序的数 |
| ■ 的柱形 | 代表正在执行 比较 和 移动 的数 |
| ■ 的柱形 | 代表已经排好序的数 |
| ■ 的柱形 | 代表待执行插入的数 |
我们看到,首先需要将 「第二个元素」 和 「第一个元素」 进行 「比较」,如果 前者 小于等于 后者,则将 后者 进行向后 「移动」,前者 则执行插入;
然后,进行第二轮「比较」,即 「第三个元素」 和 「第二个元素」、「第一个元素」 进行 「比较」, 直到 「前三个元素」 保持有序 。
最后,经过一定轮次的「比较」 和 「移动」之后,一定可以保证所有元素都是 「升序」 排列的。
4)算法描述
整个算法的执行过程分以下几步:
1) 循环迭代变量 i = 1 → n − 1 i = 1 \to n-1 i=1→n−1;
2) 每次迭代,令 x = a [ i ] x = a[i] x=a[i], j = i − 1 j = i-1 j=i−1,循环执行比较 x x x 和 a [ j ] a[j] a[j],如果产生 x ≤ a [ j ] x \le a[j] x≤a[j] 则执行 a [ j + 1 ] = a [ j ] a[j+1] = a[j] a[j+1]=a[j]。然后执行 j = j + 1 j = j + 1 j=j+1,继续执行 2);否则,跳出循环,回到 1)。
5)源码详解
#include <stdio.h>
int a[1010];
void Input(int n, int *a) {
for(int i = 0; i < n; ++i) {
scanf("%d", &a[i]);
}
}
void Output(int n, int *a) {
for(int i = 0; i < n; ++i) {
if(i)
printf(" ");
printf("%d", a[i]);
}
puts("");
}
void InsertSort(int n, int *a) { // (1)
int i, j;
for(i = 1; i < n; ++i) {
int x = a[i]; // (2)
for(j = i-1; j >= 0; --j) { // (3)
if(x <= a[j]) { // (4)
a[j+1] = a[j]; // (5)
}else
break; // (6)
}
a[j+1] = x; // (7)
}
}
int main() {
int n;
while(scanf("%d", &n) != EOF) {
Input(n, a);
InsertSort(n, a);
Output(n, a);
}
return 0;
}
-
(
1
)
(1)
(1)
void InsertSort(int n, int *a)为 插入排序 的实现,代表对a[]数组进行升序排序。 -
(
2
)
(2)
(2) 此时
a[i]前面的i-1个数都认为是排好序的,令x = a[i]; - ( 3 ) (3) (3) 逆序的枚举所有的已经排好序的数;
-
(
4
)
(4)
(4) 如果枚举到的数
a[j]比需要插入的数x大,则当前数往后挪一个位置; - ( 5 ) (5) (5) 执行挪位置的 O ( 1 ) O(1) O(1) 操作;
- ( 6 ) (6) (6) 否则,跳出循环;
-
(
7
)
(7)
(7) 将
x插入到合适位置;
7、选择排序
1)问题描述
给定一个 n n n 个元素的数组,数组下标从 0 0 0 开始,采用「 选择排序 」将数组按照 「升序」排列。
2)动图演示

3)样例说明
| 图示 | 含义 |
|---|---|
| ■ 的柱形 | 代表尚未排好序的数 |
| ■ 的柱形 | 代表正在执行 比较 的数 |
| ■ 的柱形 | 代表已经排好序的数 |
| ■ 的柱形 | 有两种:1、记录最小元素 2、执行交换的元素 |
我们发现,首先从 「第一个元素」 到 「最后一个元素」 中选择出一个 「最小的元素」,和 「第一个元素」 进行 「交换」;
然后,从 「第二个元素」 到 「最后一个元素」 中选择出一个 「最小的元素」,和 「第二个元素」 进行 「交换」。
最后,一定可以保证所有元素都是 「升序」 排列的。
4)算法描述
整个算法的执行过程分以下几步:
1) 循环迭代变量 i = 0 → n − 1 i = 0 \to n-1 i=0→n−1;
2) 每次迭代,令 m i n = i min = i min=i, j = i + 1 j = i+1 j=i+1;
3) 循环执行比较 a [ j ] a[j] a[j] 和 a [ m i n ] a[min] a[min],如果产生 a [ j ] < a [ m i n ] a[j] \lt a[min] a[j]<a[min] 则执行 m i n = j min = j min=j。执行 j = j + 1 j = j + 1 j=j+1,继续执行这一步,直到 j = = n j == n j==n;
4) 交换 a [ i ] a[i] a[i] 和 a [ m i n ] a[min] a[min],回到 1)。
5)源码详解
#include <stdio.h>
int a[1010];
void Input(int n, int *a) {
for(int i = 0; i < n; ++i) {
scanf("%d", &a[i]);
}
}
void Output(int n, int *a) {
for(int i = 0; i < n; ++i) {
if(i)
printf(" ");
printf("%d", a[i]);
}
puts("");
}
void Swap(int *a, int *b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
void SelectionSort(int n, int *a) { // (1)
int i, j;
for(i = 0; i < n - 1; ++i) { // (2)
int min = i; // (3)
for(j = i+1; j < n; ++j) { // (4)
if(a[j] < a[min]) {
min = j; // (5)
}
}
Swap(&a[i], &a[min]); // (6)
}
}
int main() {
int n;
while(scanf("%d", &n) != EOF) {
Input(n, a);
SelectionSort(n, a);
Output(n, a);
}
return 0;
}
-
(
1
)
(1)
(1)
void SelectionSort(int n, int *a)为选择排序的实现,代表对a[]数组进行升序排序。 - ( 2 ) (2) (2) 从首元素个元素开始进行 n − 1 n-1 n−1 次跌迭代。
-
(
3
)
(3)
(3) 首先,记录
min代表当前第 i i i 轮迭代的最小元素的下标为 i i i。 - ( 4 ) (4) (4) 然后,迭代枚举第 i + 1 i+1 i+1 个元素到 最后的元素。
-
(
5
)
(5)
(5) 选择一个最小的元素,并且存储下标到
min中。 - ( 6 ) (6) (6) 将 第 i i i 个元素 和 最小的元素 进行交换。
8、冒泡排序
1)问题描述
给定一个 n n n 个元素的数组,数组下标从 0 0 0 开始,采用「 冒泡排序 」将数组按照 「升序」排列。
2)动图演示

3)样例说明
| 图示 | 含义 |
|---|---|
| ■ 的柱形 | 代表尚未排好序的数 |
| ■ 的柱形 | 代表正在执行比较的两个数 |
| ■ 的柱形 | 代表已经排好序的数 |
我们看到,首先需要将 「第一个元素」 和 「第二个元素」 进行 「比较」,如果 前者 大于 后者,则进行 「交换」,然后再比较 「第二个元素」 和 「第三个元素」 ,以此类推,直到 「最大的那个元素」 被移动到 「最后的位置」 。
然后,进行第二轮「比较」,直到 「次大的那个元素」 被移动到 「倒数第二的位置」 。
最后,经过一定轮次的「比较」 和 「交换」之后,一定可以保证所有元素都是 「升序」 排列的。
4)算法描述
整个算法的执行过程分以下几步:
1) 循环迭代变量 i = 0 → n − 1 i = 0 \to n-1 i=0→n−1;
2) 每次迭代,令 j = i j = i j=i,循环执行比较 a [ j ] a[j] a[j] 和 a [ j + 1 ] a[j+1] a[j+1],如果产生 a [ j ] > a [ j + 1 ] a[j] \gt a[j+1] a[j]>a[j+1] 则交换两者的值。然后执行 j = j + 1 j = j + 1 j=j+1,这时候对 j j j 进行判断,如果 j ≥ n − 1 j \ge n-1 j≥n−1,则回到 1),否则继续执行 2)。
5)源码详解
#include <stdio.h>
int a[1010];
void Input(int n, int *a) {
for(int i = 0; i < n; ++i) {
scanf("%d", &a[i]);
}
}
void Output(int n, int *a) {
for(int i = 0; i < n; ++i) {
if(i)
printf(" ");
printf("%d", a[i]);
}
puts("");
}
void Swap(int *a, int *b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
void BubbleSort(int n, int *a) { // (1)
bool swapped;
int last = n;
do {
swapped = false; // (2)
for(int i = 0; i < last - 1; ++i) { // (3)
if(a[i] > a[i+1]) { // (4)
Swap(&a[i], &a[i+1]); // (5)
swapped = true; // (6)
}
}
--last;
}while (swapped);
}
int main() {
int n;
while(scanf("%d", &n) != EOF) {
Input(n, a);
BubbleSort(n, a);
Output(n, a);
}
return 0;
}
-
(
1
)
(1)
(1)
void BubbleSort(int n, int *a)为冒泡排序的实现,代表对a[]数组进行升序排序。 -
(
2
)
(2)
(2)
swapped标记本轮迭代下来,是否有元素产生了交换。 -
(
3
)
(3)
(3) 每次冒泡的结果,会执行
last的自减,所以待排序的元素会越来越少。 - ( 4 ) (4) (4) 如果发现两个相邻元素产生逆序,则将它们进行交换。保证右边的元素一定不比左边的小。
-
(
5
)
(5)
(5)
swap实现了元素的交换,这里需要用&转换成地址作为传参。 - ( 6 ) (6) (6) 标记更新。一旦标记更新,则代表进行了交换,所以下次迭代必须继续。
一、链表的概念
- 对于顺序存储的结构,如数组,最大的缺点就是:插入 和 删除 的时候需要移动大量的元素。所以,基于前人的智慧,他们发明了链表。
1、链表定义
链表 是由一个个 结点 组成,每个 结点 之间通过 链接关系 串联起来,每个 结点 都有一个 后继节点,最后一个 结点 的 后继结点 为 空结点。如下图所示:

- 由链接关系
A -> B组织起来的两个结点,B被称为A的后继结点,A被称为B的前驱结点。 - 链表 分为 单向链表、双向链表、循环链表 等等,本文要介绍的链表是 单向链表。
- 由于链表是由一个个 结点 组成,所以我们先来看下 结点 的实现。
2、结点结构体定义
typedef int DataType;
struct ListNode {
DataType data; // (1)
ListNode *next; // (2)
};
-
(
1
)
(1)
(1) 数据域:可以是任意类型,由编码的人自行指定;这段代码中,利用
typedef将它和int同名,本文的 数据域 也会全部采用int类型进行讲解; - ( 2 ) (2) (2) 指针域:指向 后继结点 的地址;
- 一个结点包含的两部分如下图所示:

3、结点的创建
- 我们通过 C语言 中的库函数
malloc来创建一个 链表结点,然后对 数据域 和 指针域 进行赋值,代码实现如下:
ListNode *ListCreateNode(DataType data) {
ListNode *node = (ListNode *) malloc ( sizeof(ListNode) ); // (1)
node->data = data; // (2)
node->next = NULL; // (3)
return node; // (4)
}
-
(
1
)
(1)
(1) 利用系统库函数
malloc分配一块内存空间,用来存放ListNode即链表结点对象; -
(
2
)
(2)
(2) 将 数据域 置为函数传参
data; - ( 3 ) (3) (3) 将 指针域 置空,代表这是一个孤立的 链表结点;
- ( 4 ) (4) (4) 返回这个结点的指针。
- 创建完毕以后,这个孤立结点如下所示:

二、链表的创建 - 尾插法
- 那么接下来,让我们看下如何通过一个 数组中的数据 来创建一个链表。
1、算法描述
首先介绍 尾插法 ,顾名思义,即 从链表尾部插入 的意思,就是记录一个 链表尾结点,然后遍历给定数组,将数组元素一个一个插到链表的尾部,每插入一个结点,则将它更新为新的 链表尾结点。注意初始情况下,链表尾结点 为空。
2、动画演示

上图演示的是 尾插法 的整个过程,其中:
head 代表链表头结点,创建完一个结点以后,它就保持不变了;
tail 代表链表尾结点,即动图中的 绿色结点;
vtx 代表正在插入链表尾部的结点,即动图中的 橙色结点,插入完毕以后,vtx 变成 tail;
- 看完这个动图,你应该已经大致理解了 链表的创建过程。那么接下来,我们用程序语言来描述一下整个过程,这里采用的是 C语言 的形式,如果你是 Java、C#、Python 技术栈的,也可以试着写出自己的版本。
- 语言并不是关键,思维才是关键。
3、源码详解
- C语言 实现如下:
ListNode *ListCreateListByTail(int n, int a[]) {
ListNode *head, *tail, *vtx; // (1)
int idx;
if(n <= 0)
return NULL; // (2)
idx = 0;
vtx = ListCreateNode(a[0]); // (3)
head = tail = vtx; // (4)
while(++idx < n) { // (5)
vtx = ListCreateNode(a[idx]); // (6)
tail->next = vtx; // (7)
tail = vtx; // (8)
}
return head; // (9)
}
对应的注释如下:
( 1 ) (1) (1)head存储头结点的地址,tail存储尾结点的地址,vtx存储当前正在插入结点的地址;
( 2 ) (2) (2) 当需要创建的元素个数为 0 时,直接返回空链表;
( 3 ) (3) (3) 创建一个 数据域 为a[0]的链表结点;
( 4 ) (4) (4) 由于初始情况下只有一个结点,所以将链表头结点head和链表尾结点tail都置为vtx;
( 5 ) (5) (5) 从数组第 1 个元素 (0 - based) 开始,循环遍历数组;
( 6 ) (6) (6) 由于数组中第 0 个元素已经创建过了,所以这里只需要对除了第 0 个元素以外的数据创建链表结点;
( 7 ) (7) (7) 结点创建出来后,将当前链表尾结点tail的 后继结点 置为vtx;
( 8 ) (8) (8) 将最近创建的结点vtx作为新的 链表尾结点;
( 9 ) (9) (9) 返回链表头结点;
- 尾插法 比较符合直观的思维逻辑,但是就代码量来说还是有点长(注意:在实现相同功能的情况下,代码应该是越简洁,越简单越好的)。
- 于是,我们引入了另一种创建链表的方式 —— 头插法。
三、链表的创建 - 头插法
1、算法描述
头插法,顾名思义,就是每次从头结点前面进行插入,但是这样一来,就会导致插入的数据元素是 逆序 的,所以我们需要 逆序访问数组 执行插入,此所谓 负负得正 的思想。
- 它的特点是代码量短,且 常数时间复杂度 低。虽然没有 尾插法 那么直观,但是代码简洁,更加容易阅读。
2、动画演示

上图所示的是 头插法 的整个插入过程,其中:
head 代表链表头结点,即动图中的 绿色结点,每新加一个结点,头结点就变成了新加入的结点;
tail 代表链表尾结点,创建完一个结点以后,它就保持不变了;
vtx 代表正在插入链表头部的结点,即动图中的 橙色结点,插入完毕以后,vtx 变成 head;
3、源码详解
ListNode *ListCreateListByHead(int n, int *a) {
ListNode *head = NULL, *vtx; // (1)
while(n--) { // (2)
vtx = ListCreateNode(a[n]); // (3)
vtx->next = head; // (4)
head = vtx; // (5)
}
return head; // (6)
}
对应的注释如下:
( 1 ) (1) (1)head存储头结点的地址,初始为空链表,vtx存储当前正在插入结点的地址;
( 2 ) (2) (2) 总共需要插入 n n n 个结点,所以采用逆序的 n n n 次循环;
( 3 ) (3) (3) 创建一个元素值为a[i]的链表结点,注意,由于逆序,所以这里 i i i 的取值为 n − 1 → 0 n-1 \to 0 n−1→0;
( 4 ) (4) (4) 将当前创建的结点的 后继结点 置为 链表的头结点head;
( 5 ) (5) (5) 将链表头结点head置为vtx;
( 6 ) (6) (6) 返回链表头结点;
- 头插法 的代码量比 尾插法 少了三分之一,而且将 创建结点的逻辑 统一起来了。这句话什么意思呢?仔细观察可以发现,尾插法 在实现过程中,
ListCreateNode在代码里出现了两次,而 头插法 只出现了一次,将流程简化了,所以还是推荐使用 头插法。
四、链表的打印
1、打印的作用
- 可视化 能够帮助我们更好的理解数据结构。所以,对于一种数据结构,如何通过 输出函数 将它 打印到控制台 上,就成了我们接下来要做的事情。
- 我会用 C语言 来实现,但是只要你掌握了这套自己验证的方法,那么就算用其他语言,一样可以验证自己代码的正确性。
那么,如何打印一个链表呢?我们可以这么思考:
链表的每个结点都有一个 后继结点 ,我们可以用A -> B代表结点B是结点A的 后继结点,而对于最后一个结点而言,它的后继可以用NULL表示。所以,我们可以循环输出所有结点并且带上->,然后在最后加上NULL。
2、源码详解
- C语言实现如下:
void ListPrint(ListNode *head) {
ListNode *vtx = head;
while(vtx) { // (1)
printf("%d -> ", vtx->data); // (2)
vtx = vtx->next; // (3)
}
printf("NULL\n"); // (4)
}
对应的注释如下:
( 1 ) (1) (1) 从头结点开始,循环遍历所有结点;
( 2 ) (2) (2) 遍历到的结点,将结点的 数据域 带上->后输出;
( 3 ) (3) (3) 将 当前结点 置为 当前结点 的 后继结点,继续迭代;
( 4 ) (4) (4) 最后输出一个NULL,代表一个完整的链表;
- 对于上面例子中的链表,调用这个函数,得到的结果为:
1 -> 3 -> 8 -> 2 -> 6 -> NULL
3、测试用例
- 例如,我们在 头插法 的实现过程中,加上一句 链表的打印 语句,代码实现如下:
ListNode *ListCreateListByHead(int n, int *a) {
ListNode *head = NULL, *vtx;
while(n--) {
vtx = ListCreateNode(a[n]);
vtx->next = head;
head = vtx;
ListPrint(head); /*看这里,看这里!*/
}
return head;
}
- 运行后得到的结果如下:
6 -> NULL
2 -> 6 -> NULL
8 -> 2 -> 6 -> NULL
3 -> 8 -> 2 -> 6 -> NULL
1 -> 3 -> 8 -> 2 -> 6 -> NULL
- 这样,我们就能更加进一步的确保我们实现 头插法 这个算法的正确性了。
验证算法的正确性有两个有效的办法:
( 1 ) (1) (1) 构造大量的 测试数据 进行输入输出测试;
( 2 ) (2) (2) 打印每一个操作后,数据结构的 当前状态,看是否和预期相符;
- 对 链表 进行打印,就是利用了这里的第 ( 2 ) (2) (2) 点,这个方法虽然原始,但是能够让你对每一步操作都了然于胸, 尤其是写到后面,代码量爆炸的时候,这个方法往往能够让你规避很多不必要的逻辑错误。
五、链表元素的索引
1、算法描述
给定一个链表头结点
head,并且给定一个索引值 i ( i ≥ 0 ) i (i \ge 0) i(i≥0),求这个链表的第 i i i 个结点(为了和 C语言 的数组下标保持一致,我们假定链表头结点代表第 0 个结点)。
- 这实际上是一个 遍历链表 的过程,我们先来看下动画演示。
2、动画演示

上图演示的是通过遍历,索引到第 3 个结点(下标从 0 开始计数)的过程,其中:
head 代表链表头结点;
tail 代表链表尾结点;
j / temp 代表当前枚举到的第 j ( j ≥ 0 ) j (j \ge 0) j(j≥0)个结点,即动图中的 橙色实心结点;
3、源码详解
ListNode *ListGetNode(ListNode *head, int i) {
ListNode *temp = head; // (1)
int j = 0; // (2)
while(temp && j < i) { // (3)
temp = temp->next; // (4)
++j; // (5)
}
if(!temp || j > i) {
return NULL; // (6)
}
return temp; // (7)
}
-
(
1
)
(1)
(1)
temp代表从链表头开始的 游标指针,用于对链表进行 遍历 操作; -
(
2
)
(2)
(2)
j代表当前访问到了第 j j j 个结点; -
(
3
)
(3)
(3) 如果 游标指针 非空,并且
j < i,则代表还没访问到目标结点,继续执行循环; - ( 4 ) (4) (4) 将 游标指针 的 后继结点 作为新一轮的 游标指针,继续迭代;
-
(
5
)
(5)
(5)
j自增,等价于j = j + 1; -
(
6
)
(6)
(6) 当 游标指针 为空,或者
j > i,则说明给定的i超过了链表长度,返回 空结点; -
(
7
)
(7)
(7) 最后,返回找到的第
i个结点;
4、测试用例
void testListGetNode(ListNode *head) {
int i;
for(i = 0; i < 7; ++i) {
ListNode *node = ListGetNode(head, i);
if(!node)
printf("index(%d) is out of range.\n", i);
else
printf("node(%d) is %d.\n", i, node->data);
}
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a); // (1)
testListGetNode(head); // (2)
return 0;
}
- 这个测试用例,首先第 ( 1 ) (1) (1) 步,利用 头插法 对给定数组创建了一个链表;然后第 ( 2 ) (2) (2) 步,枚举 i ∈ [ 0 , 6 ] i \in [0, 6] i∈[0,6],分别去取链表的第 i i i 个结点,运行结果如下:
node(0) is 1.
node(1) is 3.
node(2) is 8.
node(3) is 2.
node(4) is 6.
index(5) is out of range.
index(6) is out of range.
- 这表明当下标在链表元素个数范围内时,能够找到对应结点;否则,返回的是空节点;进一步验证了程序实现的正确性。
5、算法分析
1)时间复杂度
- 索引结点的操作,最坏情况下需要遍历整个链表,所以时间复杂度为 O ( n ) O(n) O(n)。
2)空间复杂度
- 整个索引过程只记录了两个变量:游标结点 和 当前索引值。和链表长度无关,所以空间复杂度为 O ( 1 ) O(1) O(1)。
六、链表元素的查找
1、算法描述
给定一个链表头
head,并且给定一个值 v v v,查找出这个链表上 数据域 等于 v v v 的第一个结点。
- 查找的过程,基本和索引类似,也是对链表的遍历操作,首先请看动画演示。
2、动画演示
上图演示的是通过遍历,查找到值为 2 的结点的过程,其中:
head 代表链表头结点;
tail 代表链表尾结点;
j / temp 代表当前枚举到的第 j ( j ≥ 0 ) j (j \ge 0) j(j≥0)个结点,即动图中的 橙色实心结点;
3、源码详解
ListNode *ListFindNodeByValue(ListNode *head, DataType v) {
ListNode *temp = head; // (1)
while(temp) { // (2)
if(temp->data == v) {
return temp; // (3)
}
temp = temp->next; // (4)
}
return NULL; // (5)
}
-
(
1
)
(1)
(1)
temp代表从 链表头 开始遍历的 游标指针; - ( 2 ) (2) (2) 如果 游标指针 非空,继续循环 ;
-
(
3
)
(3)
(3) 一旦发现 数据域 和 给定的 参数
v相等,立即返回该结点对应的指针; - ( 4 ) (4) (4) 否则,将 游标指针 的 后继结点 作为新一轮的 游标指针,继续迭代;
- ( 5 ) (5) (5) 一直到链表尾都找不到,返回 NULL;
4、测试用例
void testListFindNodeByValue(ListNode *head) {
int i;
for(i = 1; i <= 6; ++i) {
ListNode *node = ListFindNodeByValue(head, i);
if(!node)
printf("value(%d) is not found!\n", i);
else
printf("value(%d) is found!\n", i);
}
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a);
testListFindNodeByValue(head);
return 0;
}
- 这个测试用例,就是选择了
[
1
,
6
]
[1, 6]
[1,6] 这六个数,然后依次利用
ListFindNodeByValue去链表中查找,运行结果如下:
value(1) is found!
value(2) is found!
value(3) is found!
value(4) is not found!
value(5) is not found!
value(6) is found!
5、算法分析
1)时间复杂度
- 查找结点的操作,最坏情况下就是找不到,需要遍历整个链表,所以时间复杂度为 O ( n ) O(n) O(n)。
2)空间复杂度
- 整个查找过程只记录了一个变量:游标指针。和链表长度无关,所以空间复杂度为 O(1)。
七、链表结点的插入
1、算法描述
给定一个链表头
head,并且给定一个位置 i ( i ≥ 0 ) i(i \ge 0) i(i≥0) 和 一个值 v v v,求生成一个值为 v v v 的结点,并且将它插入到 链表 第 i i i 个结点之后。
- 首先,我们需要找到第 i i i 个位置,可以利用上文提到的 链表结点的索引;然后,再执行插入操作,而插入操作分为两步:第一步就是 创建结点 的过程;第二步,是断开之前第 i i i 个结点 和 第 i + 1 i+1 i+1 个结点之间的 “链”,并且将创建出来的结点 “链接” 到两者之间。来看下动图演示。
2、动画演示

上图演示的是通过遍历,将数据为 8 的结点插入到链表第 1 个(下标从 0 开始)结点后的过程,其中:
head 代表链表头结点;
tail 代表链表尾结点;
pre 代表待插入结点的 前驱结点,也是 游标指针 指代的结点,即动图中的 橙色实心结点;
aft 代表 待插入结点 的 后继结点,即动图中的 蓝色实心结点;
vtx 代表将要插入的结点,即动图中的 绿色实心结点;
3、源码详解
ListNode *ListInsertNode(ListNode *head, int i, DataType v) {
ListNode *pre, *vtx, *aft; // (1)
int j = 0; // (2)
pre = head; // (3)
while(pre && j < i) { // (4)
pre = pre->next; // (5)
++j; // (6)
}
if(!pre) {
return NULL; // (7)
}
vtx = ListCreateNode(v); // (8)
aft = pre->next; // (9)
vtx->next = aft; // (10)
pre->next = vtx; // (11)
return vtx; // (12)
}
-
(
1
)
(1)
(1) 预先定义三个指针,当结点插入完毕后,
pre -> vtx -> aft; -
(
2
)
(2)
(2) 定义一个计数器,当
j == i时,表明找到要插入的位置; - ( 3 ) (3) (3) 从 链表头结点 开始迭代遍历链表;
- ( 4 ) (4) (4) 如果还没有到链表尾,或者没有找到插入位置则继续循环;
- ( 5 ) (5) (5) 将 游标指针 的 后继结点 作为新一轮的 游标指针,继续迭代;
- ( 6 ) (6) (6) 计数器加 1;
- ( 7 ) (7) (7) 元素个数不足,无法找到给定位置,返回 NULL;
-
(
8
)
(8)
(8) 创建一个值为
v的 孤立结点; -
(
9
)
→
(
11
)
(9) \to (11)
(9)→(11) 这三步就是为了将
vtx插入到pre -> aft之间,插入完毕后pre -> vtx -> aft。 - ( 12 ) (12) (12) 最后,返回插入的那个结点;
4、测试用例
void testListInsertNode(ListNode *head) {
ListPrint(head);
ListInsertNode(head, 1, 8);
ListPrint(head);
}
int main() {
int a[5] = {1, 3, 2, 6};
ListNode *head = ListCreateListByHead(4, a);
testListInsertNode(head);
return 0;
}
- 这个测试用例,就是在原链表
1 -> 3 -> 2 -> 6的基础上,在第 1 个结点(0 - based)的后面插入一个值为 8 的结点,并且返回这个结点。这个例子的运行结果如下:
1 -> 3 -> 2 -> 6 -> NULL
执行插入操作!
1 -> 3 -> 8 -> 2 -> 6 -> NULL
5、算法分析
1)时间复杂度
- 虽然插入操作本身是 O ( 1 ) O(1) O(1) 的,但是这里有一步 索引结点 的操作,最坏情况下就是找不到对应的结点,需要遍历整个链表,所以时间复杂度为 O ( n ) O(n) O(n)。
2)空间复杂度
- 整个查找和插入的过程只记录了三个变量,和链表长度无关,所以空间复杂度为 O ( 1 ) O(1) O(1)。
八、链表结点的删除
1、算法描述
给定一个链表头
head,并且给定一个位置 i ( i ≥ 0 ) i(i \ge 0) i(i≥0),将位置为 i i i 的结点删除,并且返回新链表的头结点(为什么要返回头结点?因为被删掉的有可能是原来的头结点)。
- 链表结点的删除问题可以分为三种情况进行讨论,如下:

- ( 1 ) (1) (1) 空链表:无法进行删除,直接返回 空结点;
- ( 2 ) (2) (2) 非空链表删除头结点:缓存下 头结点 的 后继结点,释放 头结点 内存,再返回这个 后继结点;
- ( 3 ) (3) (3) 非空链表删除非头结点:通过遍历,找到 需要删除结点 的 前驱结点,如果 需要删除结点 自身为 空,则返回 链表头结点;否则,缓存 需要删除结点 以及它的 后继结点,将 前驱结点 指向 后继结点,然后再释放 需要删除结点 的内存,返回 链表头结点;
2、动画演示

上图演示的是通过遍历,将第 2 号结点(下标从 0 开始)删除的过程,其中:
head 代表链表头结点;
tail 代表链表尾结点;
pre 代表待删除结点的前驱结点,也是游走指针指代的结点,即动图中的 橙色实心结点;
aft 代表待删除结点的后继结点,即动图中的 绿色实心结点;
del 代表将要删除的结点,即动图中的 红色实心结点;
3、源码详解
ListNode *ListDeleteNode(ListNode *head, int i) {
ListNode *pre, *del, *aft;
int j = 0;
if(head == NULL) {
return NULL; // (1)
}
if(i == 0) { // (2)
del = head; // (3)
head = head->next; // (4)
free(del); // (5)
return head; // (6)
}
pre = head; // (7)
while(pre && j < i - 1) { // (8)
pre = pre->next;
++ j;
}
if(!pre || !pre->next) { // (9)
return head;
}
del = pre->next; // (10)
aft = del->next; // (11)
pre->next = aft; // (12)
free(del); // (13)
return head; // (14)
}
- ( 1 ) (1) (1) 空链表,无法执行删除,直接返回;
- ( 2 ) (2) (2) 需要删除链表第 0 个结点;
- ( 3 ) (3) (3) 缓存第 0 个结点;
- ( 4 ) (4) (4) 将新的 链表头结点 变为 当前头结点 的 后继结点;
-
(
5
)
(5)
(5) 调用系统库函数
free释放内存; - ( 6 ) (6) (6) 返回新的 链表头结点;
- ( 7 ) (7) (7) 从 链表头结点 开始遍历链表;
-
(
8
)
(8)
(8) 找到将要被删除结点的 前驱结点
pre; - ( 9 ) (9) (9) 如果 前驱结点 为空,或者 需要删除的结点 为空,则直接返回当前 链表头结点;
-
(
10
)
(10)
(10) 缓存需要删除的结点到
del; -
(
11
)
(11)
(11) 缓存需要删除结点的后继结点到
aft; - ( 12 ) (12) (12) 将需要删除的结点的前驱结点指向它的后继结点;
- ( 13 ) (13) (13) 释放需要删除结点的内存空间;
- ( 14 ) (14) (14) 返回链表头结点;
4、测试用例
void testListDeleteNode(ListNode *head) {
ListPrint(head);
printf("执行 2 号结点删除操作!\n");
head = ListDeleteNode(head, 2);
ListPrint(head);
printf("执行 0 号结点删除操作!\n");
head = ListDeleteNode(head, 0);
ListPrint(head);
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a); // (1)
testListDeleteNode(head); // (2)
return 0;
}
- 这个用例的第
(
1
)
(1)
(1) 步通过 头插法 创建了一个
1 -> 3 -> 8 -> 2 -> 6的链表, 然后将 2 号结点删除,再将 头结点删除,运行结果如下:
1 -> 3 -> 8 -> 2 -> 6 -> NULL
执行 2 号结点删除操作!
1 -> 3 -> 2 -> 6 -> NULL
执行 0 号结点删除操作!
3 -> 2 -> 6 -> NULL
5、算法分析
1)时间复杂度
- 删除结点本身的时间复杂度为 O ( 1 ) O(1) O(1)。
- 但是由于需要查找到需要删除的结点,所以总的时间复杂度还是 O ( n ) O(n) O(n) 的。
2)空间复杂度
- 不需要用到额外空间,所以总的时间复杂度为 O ( 1 ) O(1) O(1)。
九、链表的销毁
1、算法描述
链表的销毁,就是需要将 所有结点 的内存空间进行释放,并且需要将 链表的头结点 置空。
- 链表的销毁,可以理解成不断删除第 0 号结点的过程,直到链表头为空位置,只是一个循环调用,这里就不多做介绍,有兴趣的朋友可以自行实现一下。
2、动画演示

上图所示的是 链表销毁 的整个插入过程,其中:
head 代表链表头结点,即动图中的 绿色结点,每删除一个结点,头结点 就变成了之前头结点的 后继结点;
tail 代表链表尾结点;
temp 代表 待删除结点,即动图中的 橙色结点,执行删除后,它的内存空间就释放了;
3、源码详解
void ListDestroyList(ListNode **pHead) { // (1)
ListNode *head = *pHead; // (2)
while(head) { // (3)
head = ListDeleteNode(head, 0); // (4)
}
*pHead = NULL; // (5)
}
- ( 1 ) (1) (1) 这里必须用二级指针,因为删除后需要将链表头置空,普通的指针传参无法影响外部指针变量;
- ( 2 ) (2) (2) 给 链表头结点 解引用,即通过 链表头结点的地址 获取 链表头结点;
- ( 3 ) (3) (3) 如果链表非空,则继续循环;
- ( 4 ) (4) (4) 每次迭代,删除 链表头结点,并且返回其 后继结点 作为新的 链表头结点;
-
(
5
)
(5)
(5) 最后,将 链表头结点 置空,这样当函数返回时,传参的
head才能是NULL,否则外部会得到一个内存已经释放了的 野指针;
4、测试用例
void ListDestroyList(ListNode **pHead) {
ListNode *head = *pHead;
while(head) {
head = ListDeleteNode(head, 0);
}
*pHead = NULL;
}
void testListDestroyList(ListNode **head) {
ListPrint(*head);
ListDestroyList(head);
ListPrint(*head);
}
int main() {
int a[5] = {1, 3, 8, 2, 6};
ListNode *head = ListCreateListByHead(5, a);
testListDestroyList(&head);
return 0;
}
- 测试用例主要是先创建了一个链表,然后通过不断删除 链表头结点,并且打印当前链表的过程,所以运行结果中我们可以看到整个链表的删除过程,当所有结点都被删除以后,
head变为NULL。
1 -> 3 -> 8 -> 2 -> 6 -> NULL
3 -> 8 -> 2 -> 6 -> NULL
8 -> 2 -> 6 -> NULL
2 -> 6 -> NULL
6 -> NULL
NULL
NULL
5、算法分析
1)时间复杂度
- 删除链表头结点的过程,每次从头部开始删除,所以时间复杂度为 O ( 1 ) O(1) O(1)。
- 总共遍历 n n n 次删除,是乘法关系,所以总的时间复杂度是 O ( n ) O(n) O(n) 的。
2)空间复杂度
- 全程只需要一个 游标指针 用于遍历链表,和链表长度无关,所以总的时间复杂度为 O ( 1 ) O(1) O(1)。
十、链表的优缺点
1、优点
内存分配:
由于是链式存储,随时增加元素随时分配内存,不需要像数组那样进行预分配存储空间;
插入:
当拥有链表某个结点的指针时,在它 后继位置 插入一个新的结点的的时间复杂度为 O ( 1 ) O(1) O(1);
删除:
当拥有链表某个结点的指针时,删除它的 后继结点 的时间复杂度为 O ( 1 ) O(1) O(1);
2、缺点
索引:
索引第几个结点时,时间复杂度为 O ( n ) O(n) O(n);
查找:
查找是否存在某个结点时,时间复杂度为 O ( n ) O(n) O(n);
一、栈的概念
1、栈的定义
栈 是仅限在 表尾 进行 插入 和 删除 的 线性表。
栈 又被称为 后进先出 (Last In First Out) 的线性表,简称 LIFO 。
2、栈顶
栈 是一个线性表,我们把允许 插入 和 删除 的一端称为 栈顶。

3、栈底
和 栈顶 相对,另一端称为 栈底,实际上,栈底的元素我们不需要关心。

二、接口
1、可写接口
1)数据入栈
栈的插入操作,叫做 入栈,也可称为 进栈、压栈。如下图所示,代表了三次入栈操作:

2)数据出栈
栈的删除操作,叫做 出栈,也可称为 弹栈。如下图所示,代表了两次出栈操作:

3)清空栈
一直 出栈,直到栈为空,如下图所示:

2、只读接口
1)获取栈顶数据
对于一个栈来说只能获取 栈顶 数据,一般不支持获取 其它数据。
2)获取栈元素个数
栈元素个数一般用一个额外变量存储,入栈 时加一,出栈 时减一。这样获取栈元素的时候就不需要遍历整个栈。通过 O ( 1 ) O(1) O(1) 的时间复杂度获取栈元素个数。
3)栈的判空
当栈元素个数为零时,就是一个空栈,空栈不允许 出栈 操作。
三、栈的顺序表实现
1、数据结构定义
对于顺序表,在 C语言 中表现为 数组,在进行 栈的定义 之前,我们需要考虑以下几个点:
1)栈数据的存储方式,以及栈数据的数据类型;
2)栈的大小;
3)栈顶指针;
- 我们可以定义一个 栈 的 结构体,C语言实现如下所示:
#define DataType int // (1)
#define maxn 100005 // (2)
struct Stack { // (3)
DataType data[maxn]; // (4)
int top; // (5)
};
-
(
1
)
(1)
(1) 用
DataType这个宏定义来统一代表栈中数据的类型,这里将它定义为整型,根据需要可以定义成其它类型,例如浮点型、字符型、结构体 等等; -
(
2
)
(2)
(2)
maxn代表我们定义的栈的最大元素个数; -
(
3
)
(3)
(3)
Stack就是我们接下来会用到的 栈结构体; -
(
4
)
(4)
(4)
DataType data[maxn]作为栈元素的存储方式,数据类型为DataType,可以自行定制; -
(
5
)
(5)
(5)
top即栈顶指针,data[top-1]表示栈顶元素,top == 0代表空栈;
2、入栈
1、动画演示

如图所示,蓝色元素 为原本在栈中的元素,红色元素 为当前需要 入栈 的元素,执行完毕以后,栈顶指针加一。具体来看下代码实现。
2、源码详解
- 入栈 操作,算上函数参数列表,总共也才几句话,代码实现如下:
void StackPushStack(struct Stack *stk, DataType dt) { // (1)
stk->data[ stk->top ] = dt; // (2)
stk->top = stk->top + 1; // (3)
}
-
(
1
)
(1)
(1)
stk是一个指向栈对象的指针,由于这个接口会修改栈对象的成员变量,所以这里必须传指针,否则,就会导致函数执行完毕,传参对象没有任何改变; - ( 2 ) (2) (2) 将传参的元素放入栈中;
- ( 3 ) (3) (3) 将栈顶指针自增 1;
- 注意,这个接口在调用前,需要保证 栈顶指针 小于 栈元素最大个数,即
stk->top < maxn, - 如果 C语言 写的熟练,我们可以把 ( 2 ) (2) (2) 和 ( 3 ) (3) (3) 合成一句话,如下:
void StackPushStack(struct Stack *stk, DataType dt) {
stk->data[ stk->top++ ] = dt;
}
stk->top++表达式的值是自增前的值,并且自身进行了一次自增。
3、出栈
1、动画演示

如图所示,蓝色元素 为原本在栈中的元素,红色元素 为当前需要 出栈 的元素,执行完毕以后,栈顶的指针减一。具体来看下代码实现。
2、源码详解
- 出栈 操作,只需要简单改变将 栈顶 减一 即可,代码实现如下:
void StackPopStack(struct Stack* stk) {
--stk->top;
}
4、清空栈
1、动画演示

如图所示,对于数组来说,清空栈的操作只需要将 栈顶指针 置为栈底,也就是数组下标 0 即可,下次继续 入栈 的时候会将之前的内存重复利用。
2、源码详解
- 清空栈的操作只需要将 栈顶 指针直接指向 栈底 即可,对于顺序表,也就是 C语言 中的数组来说,栈底 就是下标 0 的位置了,代码实现如下:
void StackClear(struct Stack* stk) {
stk->top = 0;
}
5、只读接口
- 只读接口包含:获取栈顶元素、获取栈大小、栈的判空,实现如下:
DataType StackGetTop(struct Stack* stk) {
return stk->data[ stk->top - 1 ]; // (1)
}
int StackGetSize(struct Stack* stk) {
return stk->top; // (2)
}
bool StackIsEmpty(struct Stack* stk) {
return !StackGetSize(stk); // (3)
}
- ( 1 ) (1) (1) 数组中栈元素从 0 开始计数,所以实际获取元素时,下标为 栈顶元素下标 减一;
- ( 2 ) (2) (2) 因为只有在入栈的时候,栈顶指针才会加一,所以它 正好代表了 栈元素个数;
- ( 3 ) (3) (3) 当 栈元素 个数为 零 时,栈为空。
6、栈的顺序表实现源码
- 栈的顺序表实现的源码如下:
/************************************* 栈的顺序表实现 *************************************/
#define DataType int
#define bool int
#define maxn 100010
struct Stack {
DataType data[maxn];
int top;
};
void StackClear(struct Stack* stk) {
stk->top = 0;
}
void StackPushStack(struct Stack *stk, DataType dt) {
stk->data[ stk->top++ ] = dt;
}
void StackPopStack(struct Stack* stk) {
--stk->top;
}
DataType StackGetTop(struct Stack* stk) {
return stk->data[ stk->top - 1 ];
}
int StackGetSize(struct Stack* stk) {
return stk->top;
}
bool StackIsEmpty(struct Stack* stk) {
return !StackGetSize(stk);
}
/************************************* 栈的顺序表实现 *************************************/
四、栈的链表实现
1、数据结构定义
对于链表,在进行 栈的定义 之前,我们需要考虑以下几个点:
1)栈数据的存储方式,以及栈数据的数据类型;
2)栈的大小;
3)栈顶指针;
- 我们可以定义一个 栈 的 结构体,C语言实现如下所示:
typedef int DataType; // (1)
struct StackNode; // (2)
struct StackNode { // (3)
DataType data;
struct StackNode *next;
};
struct Stack {
struct StackNode *top; // (4)
int size; // (5)
};
- ( 1 ) (1) (1) 栈结点元素的 数据域,这里定义为整型;
-
(
2
)
(2)
(2)
struct StackNode;是对链表结点的声明; -
(
3
)
(3)
(3) 定义链表结点,其中
DataType data代表 数据域;struct StackNode *next代表 指针域; -
(
4
)
(4)
(4)
top作为 栈顶指针,当栈为空的时候,top == NULL;否则,永远指向栈顶; -
(
5
)
(5)
(5) 由于 求链表长度 的算法时间复杂度是
O
(
n
)
O(n)
O(n) 的, 所以我们需要记录一个
size来代表现在栈中有多少元素。每次 入栈时size自增,出栈时size自减。这样在询问栈的大小的时候,就可以通过 O ( 1 ) O(1) O(1) 的时间复杂度。
2、入栈
1、动画演示

如图所示,head 为栈顶,tail 为栈底,vtx 为当前需要 入栈 的元素,即图中的 橙色结点。入栈 操作完成后,栈顶 元素变为 vtx,即图中 绿色结点。
2、源码详解
- 入栈 操作,其实就是类似 头插法,往链表头部插入一个新的结点,代码实现如下:
void StackPushStack(struct Stack *stk, DataType dt) {
struct StackNode *insertNode = (struct StackNode *) malloc( sizeof(struct StackNode) ); // (1)
insertNode->next = stk->top; // (2)
insertNode->data = dt; // (3)
stk->top = insertNode; // (4)
++ stk->size; // (5)
}
-
(
1
)
(1)
(1) 利用
malloc生成一个链表结点insertNode; -
(
2
)
(2)
(2) 将 当前栈顶 作为
insertNode的 后继结点; -
(
3
)
(3)
(3) 将
insertNode的 数据域 设置为传参dt; -
(
4
)
(4)
(4) 将
insertNode作为 新的栈顶; - ( 5 ) (5) (5) 栈元素 加一;
3、出栈
1、动画演示

如图所示,head 为栈顶,tail 为栈底,temp 为当前需要 出栈 的元素,即图中的 橙色结点。出栈 操作完成后,栈顶 元素变为之前 head 的 后继结点,即图中 绿色结点。
2、源码详解
- 出栈 操作,由于链表头结点就是栈顶,其实就是删除这个链表的头结点的过程。代码实现如下:
void StackPopStack(struct Stack* stk) {
struct StackNode *temp = stk->top; // (1)
stk->top = temp->next; // (2)
free(temp); // (3)
--stk->size; // (4)
}
-
(
1
)
(1)
(1) 将 栈顶指针 保存到
temp中; - ( 2 ) (2) (2) 将 栈顶指针 的 后继结点 作为新的 栈顶;
- ( 3 ) (3) (3) 释放之前 栈顶指针 对应的内存;
- ( 4 ) (4) (4) 栈元素减一;
4、清空栈
1、动画演示

清空栈 可以理解为,不断的出栈,直到栈元素个数为零。
2、源码详解
- 对于链表而言,清空栈 的操作需要删除每个链表结点,代码实现如下:
void StackClear(struct Stack* stk) {
while(!StackIsEmpty(stk)) { // (1)
StackPopStack(stk); // (2)
}
stk->top = NULL; // (3)
}
- ( 1 ) (1) (1) - ( 2 ) (2) (2) 的每次操作其实就是一个 出栈 的过程,如果 栈 不为空;则进行 出栈 操作,直到 栈 为空;
- ( 2 ) (2) (2) 然后将 栈顶指针 置为空,代表这是一个空栈了;
5、只读接口
- 只读接口包含:获取栈顶元素、获取栈大小、栈的判空,实现如下:
DataType StackGetTop(struct Stack* stk) {
return stk->top->data; // (1)
}
int StackGetSize(struct Stack* stk) {
return stk->size; // (2)
}
int StackIsEmpty(struct Stack* stk) {
return !StackGetSize(stk);
}
-
(
1
)
(1)
(1)
stk->top作为 栈顶指针,它的 数据域data就是 栈顶元素的值,返回即可; -
(
2
)
(2)
(2)
size记录的是 栈元素个数; - ( 3 ) (3) (3) 当 栈元素 个数为 零 时,栈为空。
6、栈的链表实现源码
- 栈的链表实现源码如下:
/************************************* 栈的链表实现 *************************************/
typedef int DataType;
struct StackNode;
struct StackNode {
DataType data;
struct StackNode *next;
};
struct Stack {
struct StackNode *top;
int size;
};
void StackPushStack(struct Stack *stk, DataType dt) {
struct StackNode *insertNode = (struct StackNode *) malloc( sizeof(struct StackNode) );
insertNode->next = stk->top;
insertNode->data = dt;
stk->top = insertNode;
++ stk->size;
}
void StackPopStack(struct Stack* stk) {
struct StackNode *temp = stk->top;
stk->top = temp->next;
--stk->size;
free(temp);
}
DataType StackGetTop(struct Stack* stk) {
return stk->top->data;
}
int StackGetSize(struct Stack* stk) {
return stk->size;
}
int StackIsEmpty(struct Stack* stk) {
return !StackGetSize(stk);
}
void StackClear(struct Stack* stk) {
while(!StackIsEmpty(stk)) {
StackPopStack(stk);
}
stk->top = NULL;
stk->size = 0;
}
/************************************* 栈的链表实现 *************************************/
五、两种实现的优缺点
1、顺序表实现
在利用顺序表实现栈时,入栈 和 出栈 的常数时间复杂度低,且 清空栈 操作相比 链表实现 能做到 O ( 1 ) O(1) O(1),唯一的不足之处是:需要预先申请好空间,而且当空间不够时,需要进行扩容,扩容方式本文未提及,可以参考以下文章:《C/C++ 面试 100 例》(四)vector 扩容策略。
2、链表实现
在利用链表实现栈时,入栈 和 出栈 的常数时间复杂度略高,主要是每插入一个栈元素都需要申请空间,每删除一个栈元素都需要释放空间,且 清空栈 操作是 O ( n ) O(n) O(n) 的,直接将 栈顶指针 置空会导致内存泄漏。好处就是:不需要预先分配空间,且在内存允许范围内,可以一直 入栈,没有顺序表的限制。
一、概念
1、队列的定义
队列 是仅限在 一端 进行 插入,另一端 进行 删除 的 线性表。
队列 又被称为 先进先出 (First In First Out) 的线性表,简称 FIFO 。

2、队首
允许进行元素删除的一端称为 队首。如下图所示:

3、队尾
允许进行元素插入的一端称为 队尾。如下图所示:

二、接口
1、可写接口
1)数据入队
队列的插入操作,叫做 入队。它是将 数据元素 从 队尾 进行插入的过程,如图所示,表示的是 插入 两个数据(绿色 和 蓝色)的过程:

2)数据出队
队列的删除操作,叫做 出队。它是将 队首 元素进行删除的过程,如图所示,表示的是 依次 删除 两个数据(红色 和 橙色)的过程:

3)清空队列
队列的清空操作,就是一直 出队,直到队列为空的过程,当 队首 和 队尾 重合时,就代表队尾为空了,如图所示:

2、只读接口
1)获取队首数据
对于一个队列来说只能获取 队首 数据,一般不支持获取 其它数据。
2)获取队列元素个数
队列元素个数一般用一个额外变量存储,入队 时加一,出队 时减一。这样获取队列元素的时候就不需要遍历整个队列。通过 O ( 1 ) O(1) O(1) 的时间复杂度获取队列元素个数。
3)队列的判空
当队列元素个数为零时,就是一个 空队,空队 不允许 出队 操作。
三、队列的顺序表实现
1、数据结构定义
对于顺序表,在 C语言 中表现为 数组,在进行 队列的定义 之前,我们需要考虑以下几个点:
1)队列数据的存储方式,以及队列数据的数据类型;
2)队列的大小;
3)队首指针;
4)队尾指针;
- 我们可以定义一个 队列 的 结构体,C语言实现如下所示:
#define DataType int // (1)
#define maxn 100005 // (2)
struct Queue { // (3)
DataType data[maxn]; // (4)
int head, tail; // (5)
};
-
(
1
)
(1)
(1) 用
DataType这个宏定义来统一代表队列中数据的类型,这里将它定义为整型,根据需要可以定义成其它类型,例如浮点型、字符型、结构体 等等; -
(
2
)
(2)
(2)
maxn代表我们定义的队列的最大元素个数; -
(
3
)
(3)
(3)
Queue就是我们接下来会用到的 队列结构体; -
(
4
)
(4)
(4)
DataType data[maxn]作为队列元素的存储方式,即 数组,数据类型为DataType,可以自行定制; -
(
5
)
(5)
(5)
head即队首指针,tail即队尾指针,head == tail代表空队;当队列非空时,data[head]代表了队首元素(而队尾元素是不需要关心的);
2、入队
1、动画演示

如图所示,绿色元素 为新插入队尾的数据,执行完毕以后,队尾指针加一,队首指针不变。需要注意的是,顺序表实现时,队尾指针指向的位置是没有数据的,具体来看下代码实现。
2、源码详解
- 入队 操作,算上函数参数列表,总共也才几句话,代码实现如下:
void QueueEnqueue(struct Queue *que, DataType dt) { // (1)
que->data[ que->tail ] = dt; // (2)
que->tail = que->tail + 1; // (3)
}
-
(
1
)
(1)
(1)
que是一个指向队列对象的指针,由于这个接口会修改队列对象的成员变量,所以这里必须传指针,否则,就会导致函数执行完毕,传参对象没有任何改变; - ( 2 ) (2) (2) 将传参的元素 入队;
- ( 3 ) (3) (3) 将 队尾指针 自增 1;
- 注意,这个接口在调用前,需要保证 队尾指针 小于 队列元素最大个数,即
que->tail < maxn, - 如果 C语言 写的熟练,我们可以把 ( 2 ) (2) (2) 和 ( 3 ) (3) (3) 合成一句话,如下:
void QueueEnqueue(struct Queue *que, DataType dt) {
que->data[ que->tail++ ] = dt;
}
que->tail++表达式的值是自增前的值,并且自身进行了一次自增。
3、出队
1、动画演示

如图所示,橙色元素 为原先的 队首元素,执行 出队 操作以后,黃色元素 成为当前的 队首元素,执行完毕以后,队首指针加一。由于是顺序表实现,队首元素前面的那些元素已经变成无效的了,具体来看下代码实现。
2、源码详解
- 出队 操作,只需要简单的改变,将 队首指针 加一 即可,代码实现如下:
void QueueDequeue(struct Queue* que) {
++que->head;
}
4、清空队列
1、动画演示

如图所示,对于数组来说,清空队列的操作只需要将 队首指针 和 队尾指针 都置零 即可,数据不需要清理,下次继续 入队 的时候会将之前的内存重复利用。
2、源码详解
- 清空队列的操作只需要将 队首指针 和 队尾指针 都归零即可,代码实现如下:
void QueueClear(struct Queue* que) {
que->head = que->tail = 0;
}
5、只读接口
- 只读接口包含:获取队首元素、获取队列大小、队列的判空,实现如下:
DataType QueueGetFront(struct Queue* que) {
return que->data[ que->head ]; // (1)
}
int QueueGetSize(struct Queue* que) {
return que->tail - que->head; // (2)
}
int QueueIsEmpty(struct Queue* que) {
return !QueueGetSize(que); // (3)
}
-
(
1
)
(1)
(1)
que->head代表了 队首指针,即 队首下标,所以真正的 队首元素 是que->data[ que->head ]; - ( 2 ) (2) (2) 因为只有在 入队 的时候,队尾指针 加一;出队 的时候,队首指针 加一;所以 队列元素个数 就是两者的差值;
- ( 3 ) (3) (3) 当 队列元素 个数为 零 时,队列为空。
6、队列的顺序表实现源码
- 队列的顺序表实现的源码如下:
/**************************** 顺序表 实现队列 ****************************/
#define DataType int
#define maxn 100005
struct Queue {
DataType data[maxn];
int head, tail;
};
void QueueClear(struct Queue* que) {
que->head = que->tail = 0;
}
void QueueEnqueue(struct Queue *que, DataType dt) {
que->data[ que->tail++ ] = dt;
}
void QueueDequeue(struct Queue* que) {
++que->head;
}
DataType QueueGetFront(struct Queue* que) {
return que->data[ que->head ];
}
int QueueGetSize(struct Queue* que) {
return que->tail - que->head;
}
int QueueIsEmpty(struct Queue* que) {
return !QueueGetSize(que);
}
/**************************** 顺序表 实现队列 ****************************/
四、队列的链表实现
1、数据结构定义
对于链表,在进行 队列的定义 之前,我们需要考虑以下几个点:
1)队列数据的存储方式,以及队列数据的数据类型;
2)队列的大小;
3)队首指针;
4)队尾指针;
- 我们可以定义一个 队列 的 结构体,C语言实现如下所示:
typedef int DataType; // (1)
struct QueueNode; // (2)
struct QueueNode { // (3)
DataType data;
struct QueueNode *next;
};
struct Queue {
struct QueueNode *head, *tail; // (4)
int size; // (5)
};
- ( 1 ) (1) (1) 队列结点元素的 数据域,这里定义为整型;
-
(
2
)
(2)
(2)
struct QueueNode;是对 链表结点 的声明; -
(
3
)
(3)
(3) 定义链表结点,其中
DataType data代表 数据域;struct QueueNode *next代表 指针域; -
(
4
)
(4)
(4)
head作为 队首指针,tail作为 队尾指针; -
(
5
)
(5)
(5) 由于 求链表长度 的算法时间复杂度是
O
(
n
)
O(n)
O(n) 的, 所以我们需要记录一个
size来代表现在队列中有多少元素。每次 入队时size自增,出队时size自减。这样在询问 队列 的大小的时候,就可以通过 O ( 1 ) O(1) O(1) 的时间复杂度。
2、入队
1、动画演示

如图所示,head 为 队首元素,tail 为 队尾元素,vtx 为当前需要 入队 的元素,即图中的 橙色结点。入队 操作完成后,队尾元素 变为 vtx,即图中 绿色结点。
2、源码详解
- 入队 操作,其实就是类似 尾插法,往链表尾部插入一个新的结点,代码实现如下:
void QueueEnqueue(struct Queue *que, DataType dt) {
struct QueueNode *insertNode = (struct QueueNode *) malloc( sizeof(struct QueueNode) );
insertNode->data = dt; // (1)
insertNode->next = NULL;
if(que->tail) { // (2)
que->tail->next = insertNode;
que->tail = insertNode;
}else {
que->head = que->tail = insertNode; // (3)
}
++que->size; // (4)
}
-
(
1
)
(1)
(1) 利用
malloc生成一个链表结点insertNode,并且填充 数据域 和 指针域; -
(
2
)
(2)
(2) 如果当前 队尾 不为空,则将
insertNode作为 队尾 的 后继结点,并且更新insertNode作为新的 后继结点; -
(
3
)
(3)
(3) 否则,队首 和 队尾 都为
insertNode; - ( 4 ) (4) (4) 队列元素 加一;
3、出队
1、动画演示

如图所示,head 为 队首元素,tail 为 队尾元素,temp 为当前需要 出队 的元素,即图中的 橙色结点。出队 操作完成后,队首元素 变为之前 head 的 后继结点,即图中 绿色结点。
2、源码详解
- 出队 操作,由于链表头结点就是 队首,其实就是删除这个链表的头结点的过程。代码实现如下:
void QueueDequeue(struct Queue* que) {
struct QueueNode *temp = que->head; // (1)
que->head = temp->next; // (2)
free(temp); // (3)
--que->size; // (4)
if(que->size == 0) { // (5)
que->tail = NULL;
}
}
-
(
1
)
(1)
(1) 将 队首 保存到
temp中; - ( 2 ) (2) (2) 将 队首 的 后继结点 作为新的 队首;
- ( 3 ) (3) (3) 释放之前 队首 对应的内存;
- ( 4 ) (4) (4) 队列元素减一;
- ( 5 ) (5) (5) 当队列元素为空时,别忘了将 队尾 指针置空;
4、清空队列
1、动画演示

清空队列 可以理解为:不断的 出队,直到 队列元素 个数为零为止。由于链表结点是动态申请的内存,所以在没有其它结点引用时,是需要释放内存的,不像数组那样直接将 队首指针 和 队尾指针 置空就行的。
2、源码详解
- 对于链表而言,清空队列 的操作需要删除每个链表结点,代码实现如下:
void QueueClear(struct Queue* que) {
while(!QueueIsEmpty(que)) { // (1)
QueueDequeue(que); // (2)
}
}
- ( 1 ) (1) (1) - ( 2 ) (2) (2) 的每次操作其实就是一个 出队 的过程,如果 队列 不为空;则进行 出队 操作,直到 队列 为空;
5、只读接口
- 只读接口包含:获取队首元素、获取队列大小、队列的判空,实现如下:
DataType QueueGetFront(struct Queue* que) {
return que->head->data; // (1)
}
int QueueGetSize(struct Queue* que) {
return que->size; // (2)
}
int QueueIsEmpty(struct Queue* que) {
return !QueueGetSize(que); // (3)
}
-
(
1
)
(1)
(1)
que->head作为 队首指针,它的 数据域data就是 队首元素的值,返回即可; -
(
2
)
(2)
(2)
size记录的是 队列元素 的个数; - ( 3 ) (3) (3) 当 队列元素 个数为 零 时,队列为空。
6、队列的链表实现源码
/**************************** 链表 实现队列 ****************************/
typedef int DataType;
struct QueueNode;
struct QueueNode {
DataType data;
struct QueueNode *next;
};
struct Queue {
struct QueueNode *head, *tail;
int size;
};
void QueueEnqueue(struct Queue *que, DataType dt) {
struct QueueNode *insertNode = (struct QueueNode *) malloc( sizeof(struct QueueNode) );
insertNode->data = dt;
insertNode->next = NULL;
if(que->tail) {
que->tail->next = insertNode;
que->tail = insertNode;
}else {
que->head = que->tail = insertNode;
}
++que->size;
}
void QueueDequeue(struct Queue* que) {
struct QueueNode *temp = que->head;
que->head = temp->next;
free(temp);
--que->size;
if(que->size == 0) {
que->tail = NULL;
}
}
DataType QueueGetFront(struct Queue* que) {
return que->head->data;
}
int QueueGetSize(struct Queue* que) {
return que->size;
}
int QueueIsEmpty(struct Queue* que) {
return !QueueGetSize(que);
}
void QueueClear(struct Queue* que) {
que->head = que->tail = NULL;
que->size = 0;
}
/**************************** 链表 实现队列 ****************************/
五、两种实现的优缺点
1、顺序表实现
在利用顺序表实现队列时,入队 和 出队 的常数时间复杂度低,且 清空队列 操作相比 链表实现 能做到
O
(
1
)
O(1)
O(1),唯一的不足之处是:需要预先申请好空间,而且当空间不够时,需要进行扩容,扩容方式本文未提及,可以参考以下文章:《C/C++ 面试 100 例》(四)vector 扩容策略。
当然,可以采用 循环队列,能够很大程度上避免扩容问题,但是当 入队速度 大于 出队速度 时,不免还是会遇到扩容的问题。
2、链表实现
在利用链表实现队列时,入队 和 出队 的常数时间复杂度略高,主要是每插入一个队列元素都需要申请空间,每删除一个队列元素都需要释放空间,且 清空队列 操作是
O
(
n
)
O(n)
O(n) 的,直接将 队首指针 和 队尾指针 置空会导致内存泄漏。
好处就是:不需要预先分配空间,且在内存允许范围内,可以一直 入队,没有顺序表的限制。当然,链表的实现明显比数组实现要复杂,编码的时候容易出错。
需要注意的是,本文在讲解过程中,顺序表实现 的 队尾 和 链表实现 的 队尾 不是一个概念,顺序表实现的队尾没有实际元素值,而链表实现的则不然,请自行加以区分。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解双端队列。
本文已超五万字,为了增加阅读体验,更多内容请收看:画解哈希表。
本文已超五万字,为了增加阅读体验,更多内容请收看:画解树。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解二叉树。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解二叉搜索树。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解堆。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解二叉平衡树。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解线段树。
本文已超五万字,为了增加阅读体验,更多内容请收看:画解字典树。
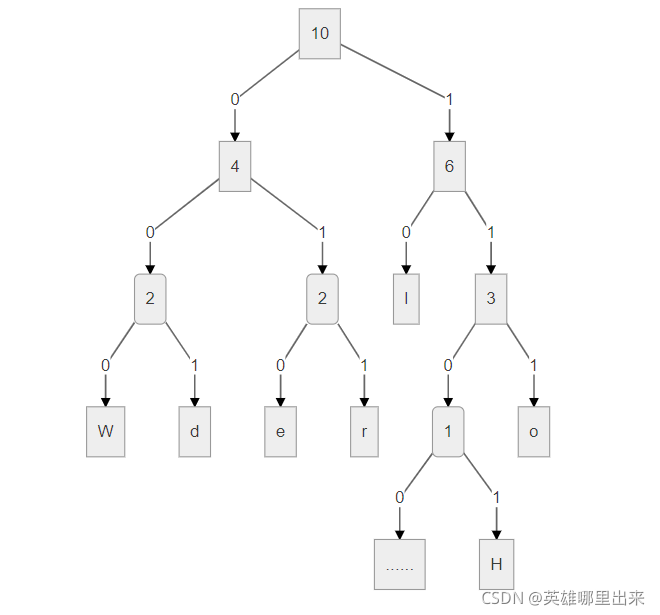
本文已超五万字,为了增加阅读体验,更多内容请收看:画解霍夫曼树。
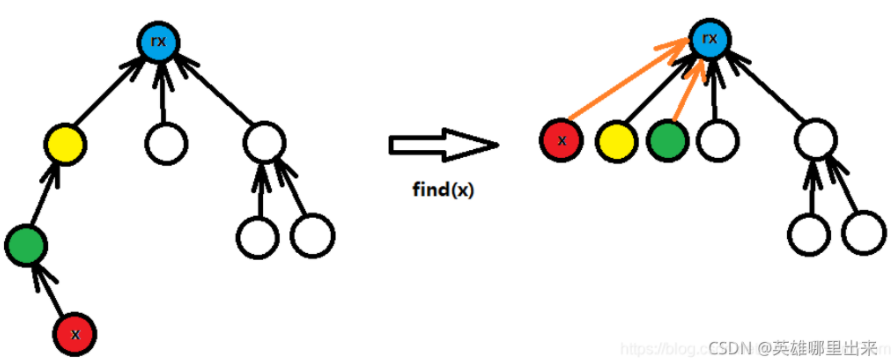
本文已超五万字,为了增加阅读体验,更多内容请收看:画解并查集。
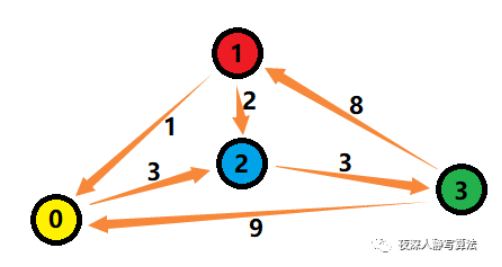
本文已超五万字,为了增加阅读体验,更多内容请收看:画解图。
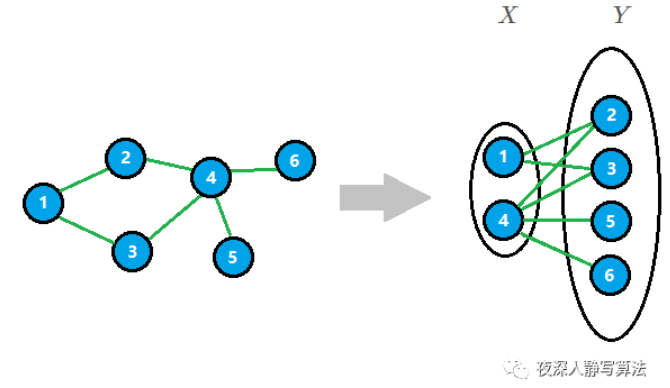
本文已超五万字,为了增加阅读体验,更多内容请收看:画解二分匹配。
本文已超五万字,为了增加阅读体验,更多内容请收看:画解最短路。
本文已超五万字,为了增加阅读体验,更多内容请收看:画解最小生成树。

本文已超五万字,为了增加阅读体验,更多内容请收看:画解强连通。
有关🌳《画解数据结构》🌳 的源码均开源,链接如下:《画解数据结构》

相信看我文章的大多数都是「 大学生 」,能上大学的都是「 精英 」,那么我们自然要「 精益求精 」,如果你还是「 大一 」,那么太好了,你拥有大把时间,当然你可以选择「 刷剧 」,然而,「 学好算法 」,三年后的你自然「 不能同日而语 」。
那么这里,我整理了「 几十个基础算法 」 的分类,点击开启:
如果链接被屏蔽,或者有权限问题,可以私聊作者解决。
大致题集一览:



为了让这件事情变得有趣,以及「 照顾初学者 」,目前题目只开放最简单的算法 「 枚举系列 」 (包括:线性枚举、双指针、前缀和、二分枚举、三分枚举),当有 一半成员刷完 「 枚举系列 」 的所有题以后,会开放下个章节,等这套题全部刷完,你还在群里,那么你就会成为「 夜深人静写算法 」专家团 的一员。
不要小看这个专家团,三年之后,你将会是别人 望尘莫及 的存在。如果要加入,可以联系我,考虑到大家都是学生, 没有「 主要经济来源 」,在你成为神的路上,「 不会索取任何 」。
🔥让天下没有难学的算法🔥
C语言免费动漫教程,和我一起打卡! 🌞《光天化日学C语言》🌞
入门级C语言真题汇总 🧡《C语言入门100例》🧡
几张动图学会一种数据结构 🌳《画解数据结构》🌳
组团学习,抱团生长 🌌《算法入门指引》🌌
竞赛选手金典图文教程 💜《夜深人静写算法》💜
粉丝专属福利
语言入门:《光天化日学C语言》(示例代码)
语言训练:《C语言入门100例》试用版
数据结构:《画解数据结构》源码
算法入门:《算法入门》指引
算法进阶:《夜深人静写算法》算法模板