介绍
说起 Kafka 很多同学都知道,即使你没有用过也知道,它是消息队列中数一数二的运动健将,他可以承载每秒钟上百万此的数据处理,但问什么 Kafka 可以这么快呢?
归纳原因主要有这四点原因,磁盘顺序读写、页缓存、零拷贝、批量操作。
对比 RocketMQ
说到 Kafka 有一个话题我们无法回避,就是与其他消息队列的对比。这里我们以 RocketMQ 为例,Kafka 与 RocketMQ 有着完全不同的使用场景。
看下图,RocketMQ 就行一个高压水枪他的流速快横截面积小,吞吐量不高处理速度快。而Kafaka 采用完全相反的设计横截面积大,吞吐量高处理速度慢。

四大特点
1. 顺序读写
为什么顺序读写快呢,来看下面一篇测试文章,有权威的测试分别对机械硬盘、固态硬盘、内存进行随机与顺序读写测试。
黄色为随机读写,蓝色为顺序读写。可以看到随机读写性能依次是机械硬盘、固态硬盘、内存。而顺序读写机械硬盘反而强于固态硬盘,对于企业来说存储空间SSD、内存是非常昂贵的。所以 Kafaka 在设计的时候也是根据这个进行来顺序存储的。

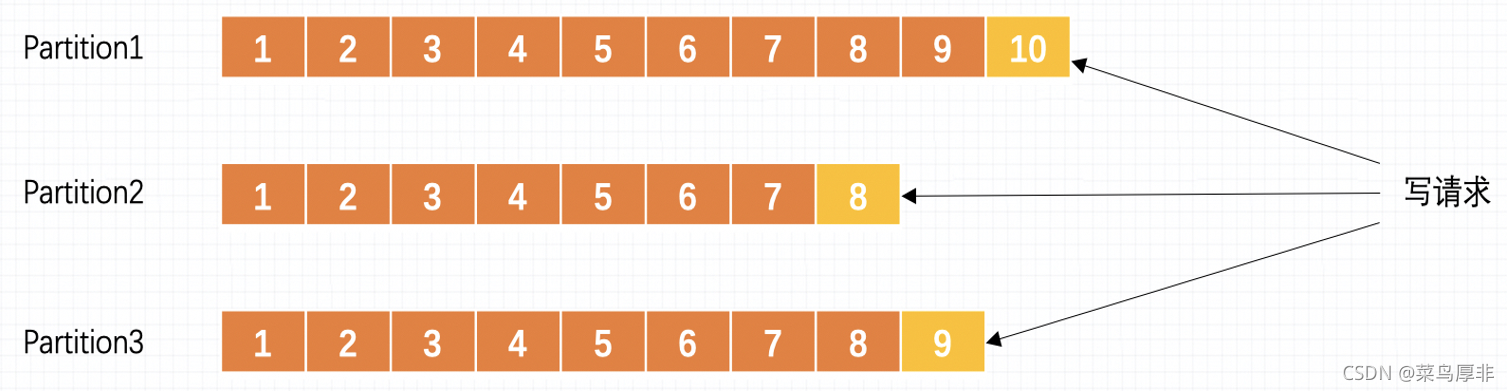
在 Kafka 中一个概念叫做 Partition ,分区的意思用来存储消息,生产者生产的消息都是从末尾进行添加。
这里设计到一个新的问题,就是消费过的消息消费了之后进行删除不就破坏了消息的顺序关系了吗。这里 Kafka 做了个折中的处理,不进行实时的消息删除,而是在某个时间进行批量删除的,这个比单个删除效率要高。
2. 页缓存
页缓存相对来说比较简单,页缓存在操作系统层面是保存数据的一个基本单位,Kafka 避免使用 JVM,直接使用操作系统的页缓存特性提高处理速度,进而避免了JVM GC 带来的性能损耗。
3. 零拷贝
作为 Kafka 运行在 Linux 操作系统,作为 Linux 操作系统,它有一个特性叫做零拷贝。就是在用户态与内核态不再发生拷贝。
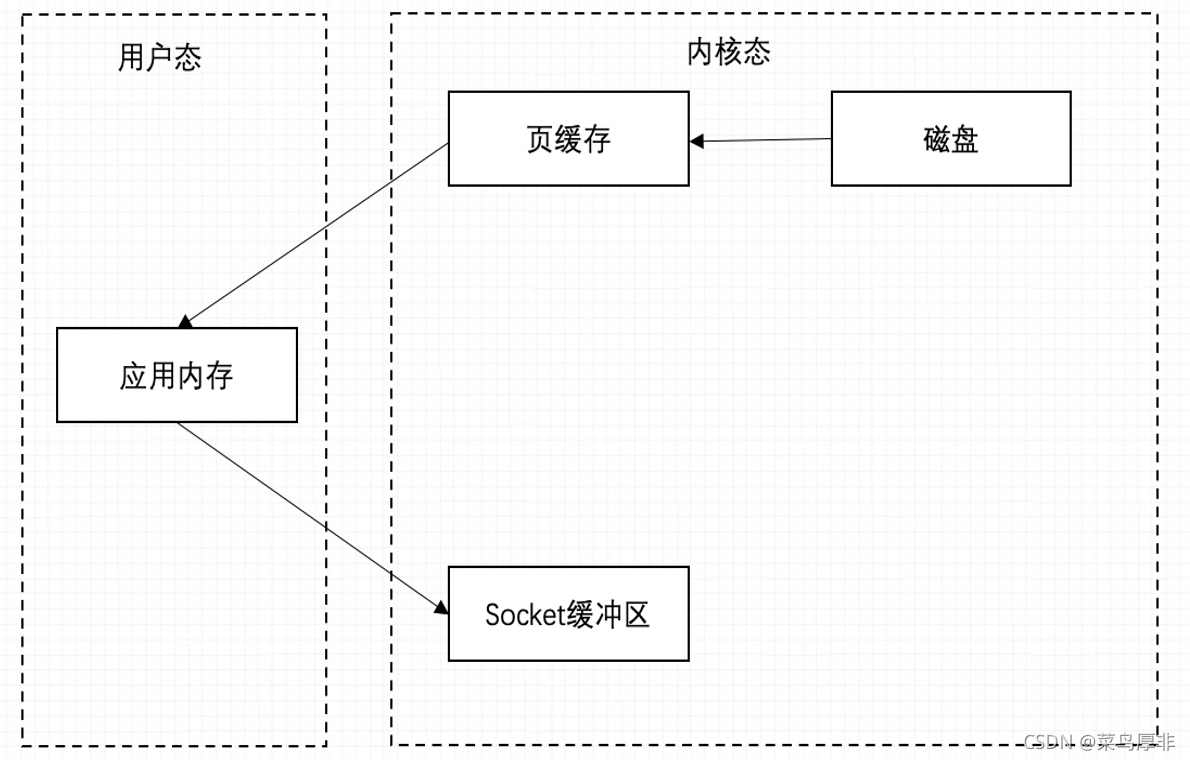
接下来我使用更加形象化进行解释,来看下图。假设现在有一条数据需要应用程序进行操作,但是他现在存储在磁盘上。操作系统层面会将磁盘信息加载到页缓存,之后再 copy 到应用层面的应用内存,需要发送的时候再加载到 socket 缓冲区。
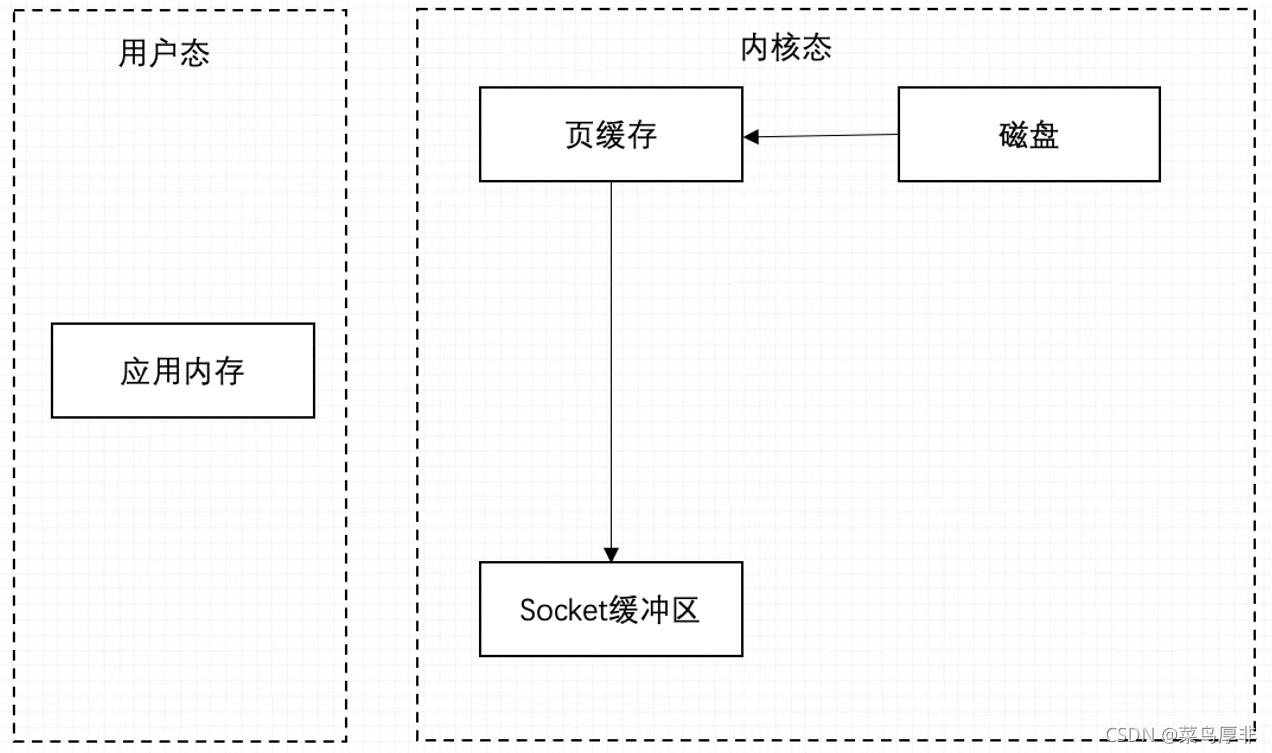
但 Kafka 不是这么做的,来看下图。当数据需要操作会加载到内核态的页缓存中,需要发送是再加载到 socket 缓冲区中。其中就少了与用户态之间的 copy 动作,如果再处理海量数据的时候,效率就提高了很多。
4. 批量操作

最后一个呢是批处理,同学可以想一下在 JDBC 中数据库的操作,会有些批量处理操作,它用来提高网络利用率与数据库执行效率。
在 kafka 中页提高了大量批处理的 API ,可以对数据进行统一的压缩合并,通过更小的数据包在网络中进行数据发送,再进行后续处理,这在大量数据处理中,效率提高是非常明显的。