文章目录
- Linux管道符
- 命令格式
- 实战
- 正则表达式
- 实战
- 找出所有的hello单词
- 找出hello单词后面有world单词
- 以0开头然后是两个数字然后是一个连字符-,最后是8个数字
- 匹配以字符h开头的单词
- 匹配刚好6个字符的单词
- 匹配一个或更多连接的数字
- 匹配5-12位的QQ号
- grep
- 定义
- 格式
- 实战
- 查找文件内容包含h的行数
- 查找文件内容不包含h的行数
- 查找以n开头的行
- 查找以k结尾的行
- sed
- 定义
- 语法
- 查看帮助
- 操作
- 新增
- 取代(c)
- 删除
- 插入
- 打印
- 取代(s)
- 直接修改文件内容
- awk
- 定义
- 命令形式
- 常用参数
- 实战
- 搜索/etc/passwd/有root关键字的所有行,并显示对应的shell
- 打印/etc/passwd的第二行信息
- 使用begin加入标题
- 自定义分隔符
Linux管道符
命令格式
命令1的正确输出作为命令2的操作对象
[root@web1 Test]#命令1 | 命令2
实战
创建一个文本文件,输入任意内容
[root@web1 Test]# touch test.txt
[root@web1 Test]# vim test.txt
hello world
how are you?
i am fine,thanks
nice to meet you
good luck
查看在test.txt中包含hello的行
[root@web1 Test]# cat test.txt | grep "hello"
hello world
[root@web1 Test]#
查看在test.txt中包含h的行
[root@web1 Test]# cat test.txt | grep "h"
hello world
how are you?
i am fine,thanks
[root@web1 Test]#
当然,还可以有其他操作,比如
[root@web1 Test]# su xwk
[xwk@web1 Test]$ ping 127.0.0.1|whoami
xwk
[xwk@web1 Test]$ su
密码:
[root@web1 Test]# ping 127.0.0.1|whoami
root
[root@web1 Test]#
正则表达式
| 常用的元字符 | |
|---|---|
| . (点号) | 匹配除换行符以外的任意字符 |
| \w | 匹配字母、数字、下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| 常用的限定符 | |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
实战
推荐一个网站,可以在线进行正则表达式测试
https://tool.oschina.net/regex
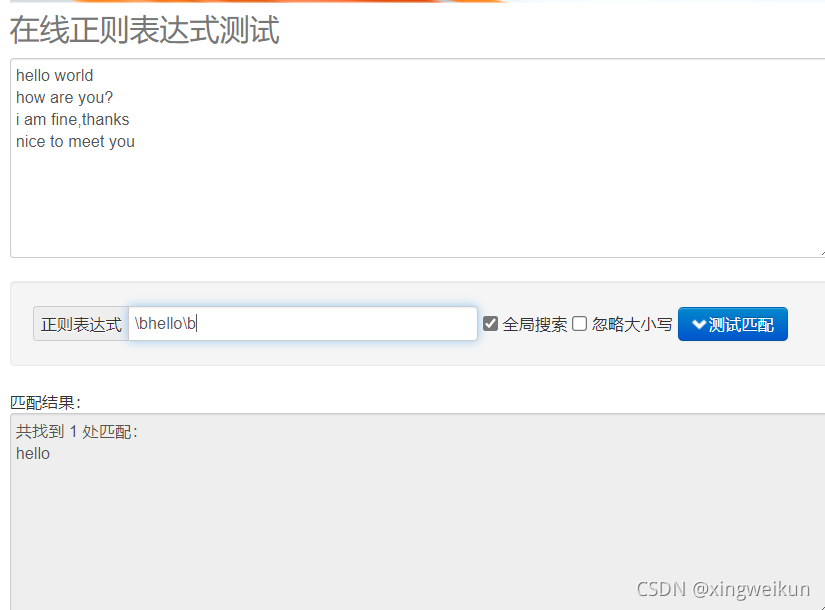
找出所有的hello单词
\bhello\b
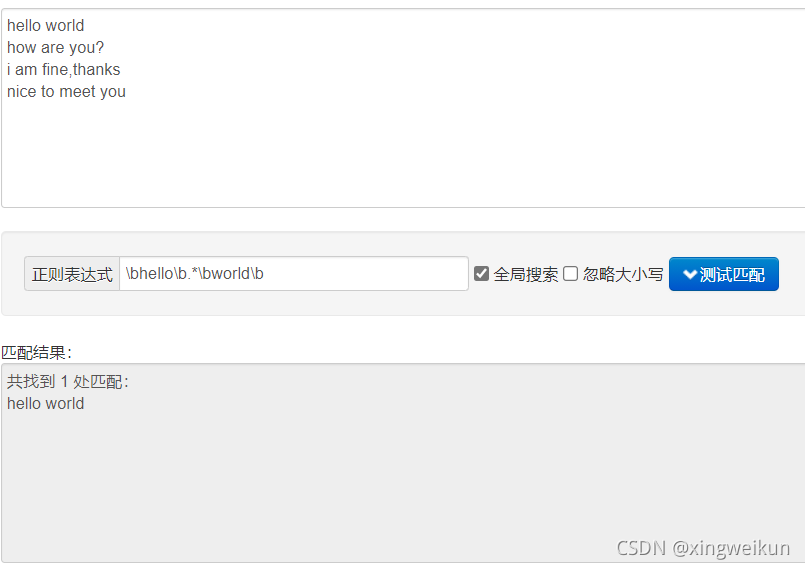
找出hello单词后面有world单词
\bhello\b.*\bworld\b
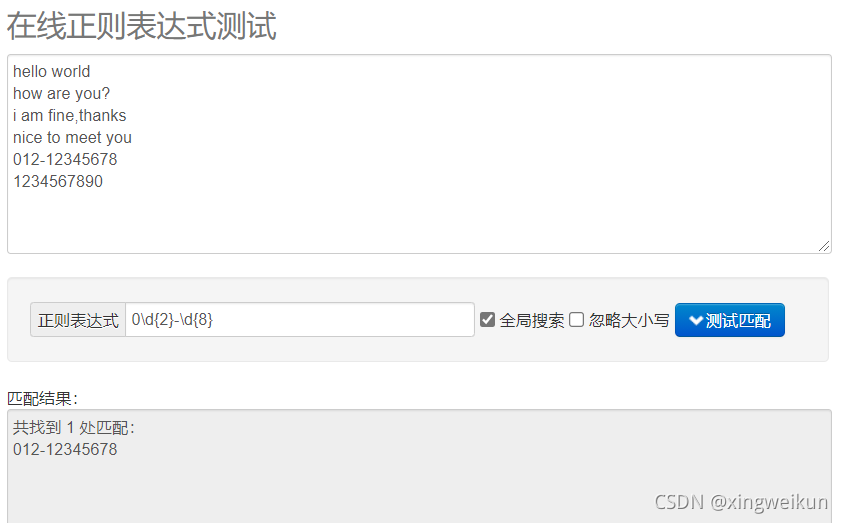
以0开头然后是两个数字然后是一个连字符-,最后是8个数字
0\d{2}-\d{8}
匹配以字符h开头的单词
\bh\w*\b

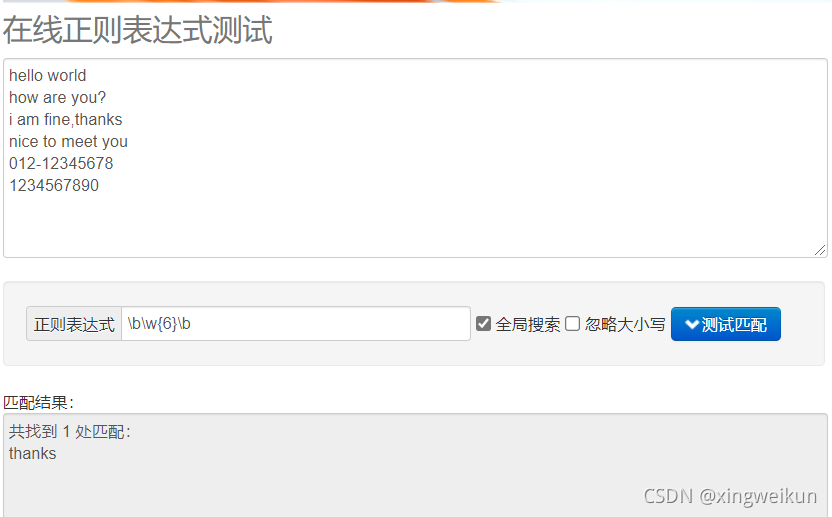
匹配刚好6个字符的单词
\b\w{6}\b
匹配一个或更多连接的数字
\d+
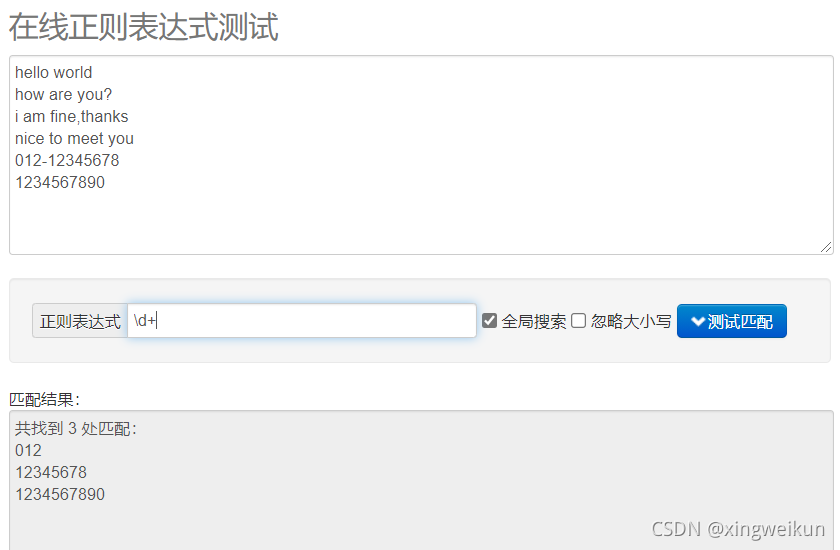
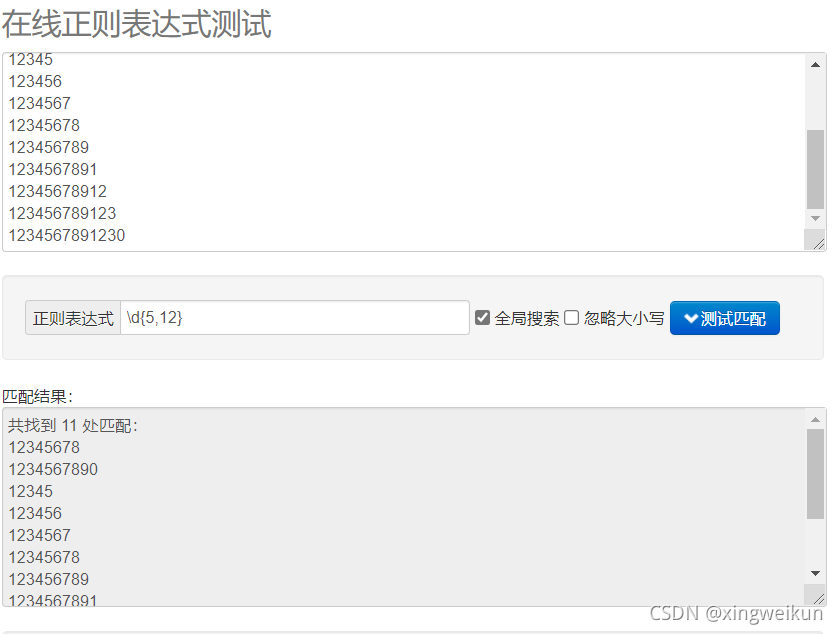
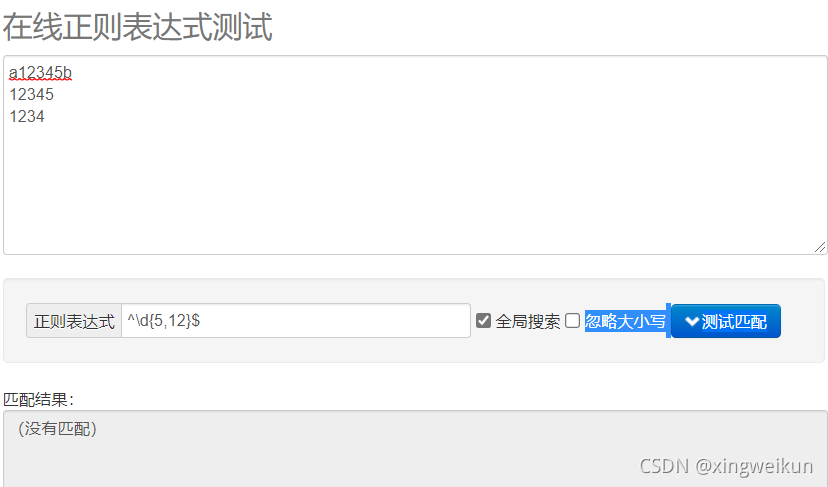
匹配5-12位的QQ号
\d{5,12}
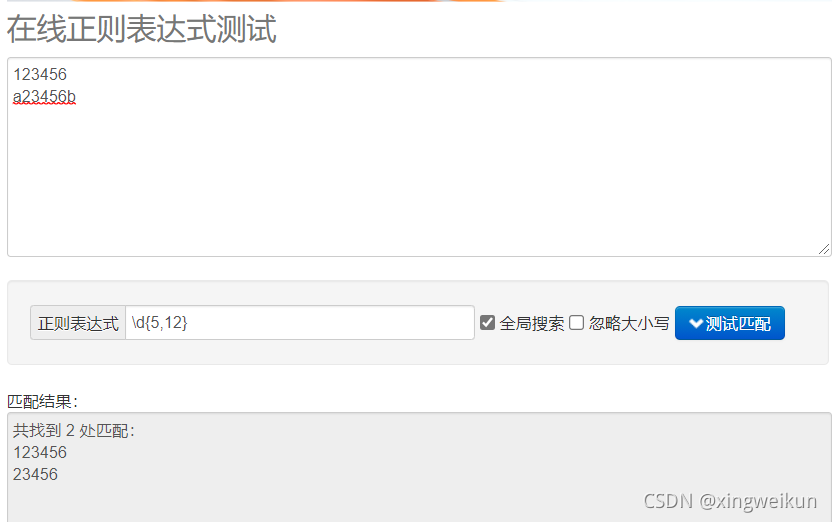
弊端,前后加字母依然可以匹配到,如
改进
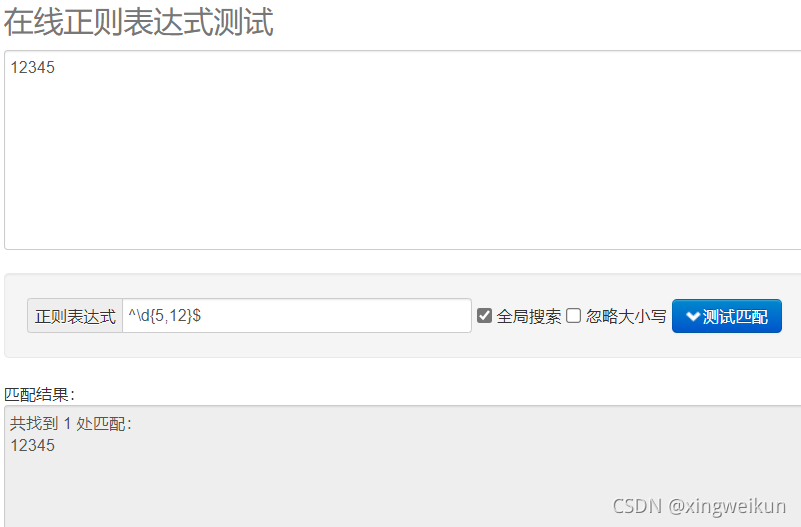
^\d{5,12}$
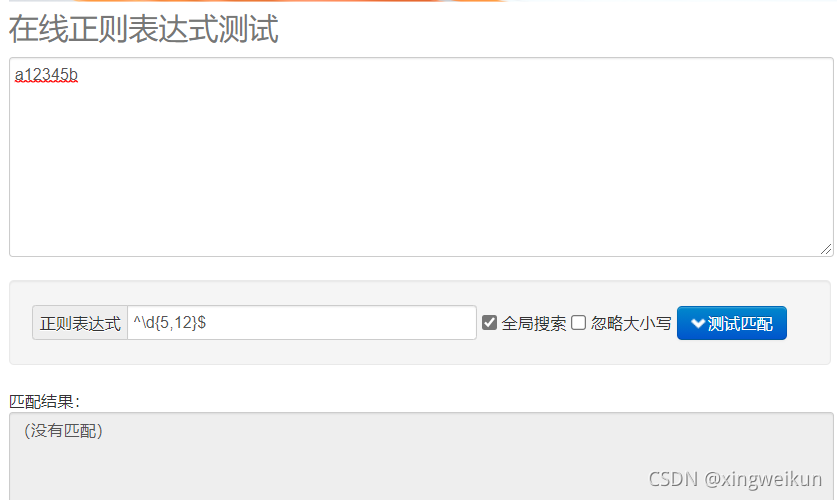
目前这个匹配只能输入一条,输入多条就会连正确的也匹配不到,不知道为什么
grep
定义
根据用户指定的模式对目标文本进行过滤,显示被匹配到的行。
格式
grep [OPTIONS] PATTERN [FILE]
| 符号 | 说明 |
|---|---|
| -v | 显示不被pattern匹配到的行 |
| -i | 忽略字符大小写 |
| -n | 显示匹配的行号 |
| -c | 统计匹配的字数 |
| -o | 仅显示匹配到的字符串 |
| -E | 使用ERE,相当于egrep |
实战
查找文件内容包含h的行数
[root@web1 Test]# grep -n h test.txt
1:hello world
2:how are you?
3:i am fine,thanks
[root@web1 Test]#
查找文件内容不包含h的行数
[root@web1 Test]# grep -nv h test.txt
4:nice to meet you
5:good luck
[root@web1 Test]#
查找以n开头的行
[root@web1 Test]# grep -n ^n test.txt
4:nice to meet you
[root@web1 Test]#
查找以k结尾的行
[root@web1 Test]# grep -n k$ test.txt
5:good luck
[root@web1 Test]#
sed
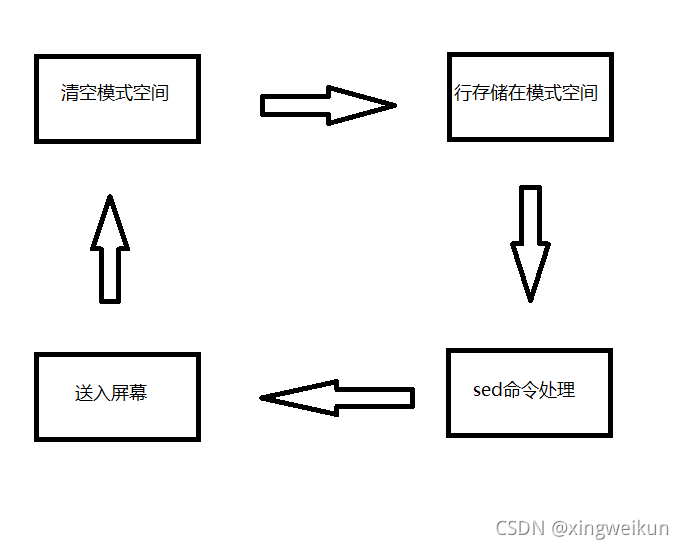
定义
sed是流编辑器,一次处理一行内容
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
| 符号 | 说明 |
|---|---|
| a | 新增 |
| c | 取代(c的后面可以接字串,这些字串可以取代n1,n2之间的行) |
| d | 删除 |
| i | 插入 |
| p | 打印 |
| s | 取代(直接进行取代工作) |
查看帮助
man sed 或 sed -h
操作
以下操作仅返回改变结果,不直接更改原文件里的内容,除非vim编辑,否则test.txt内容不变。
新增
在第4行的下一行(第5行)新增add_to_4
[root@web1 Test]# sed -e '4 a add_to_4' test.txt
hello world
how are you?
i am fine,thanks
nice to meet you
add_to_4
good luck
[root@web1 Test]#
取代(c)
将原本的1-3行内容用hi取代
[root@web1 Test]# sed -e '1,3c hi' test.txt
hi
nice to meet you
good luck
[root@web1 Test]#
删除
删除文档1-2行
[root@web1 Test]# sed -e '1,2d' test.txt
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
插入
第二行插入insert_to_2
[root@web1 Test]# sed -e '2i insert_to_2' test.txt
hello world
insert_to_2
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
打印
打印存在h的行
[root@web1 Test]# sed -n '/h/p' test.txt
hello world
how are you?
i am fine,thanks
[root@web1 Test]#
取代(s)
为了更容易理解,我们重新编辑一下test.txt文本
[root@web1 Test]# cat test.txt
hello world
hello hello hello
hello
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
观察两条命令返回结果的不同之处,加g与不加g有什么区别?
[root@web1 Test]# sed -e 's/hello/hi/' test.txt
hi world
hi hello hello
hi
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]# sed -e 's/hello/hi/g' test.txt
hi world
hi hi hi
hi
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
下面改变文件内容
直接修改文件内容
修改前文件内容
[root@web1 Test]# cat test.txt
hello world
hello hello hello
hello
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
文件修改后
[root@web1 Test]# sed -i 's/hello/hi/g' test.txt
[root@web1 Test]# cat test.txt
hi world
hi hi hi
hi
how are you?
i am fine,thanks
nice to meet you
good luck
[root@web1 Test]#
awk
定义
把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行后续处理。
命令形式
awk 'pattern+action'[FILE]
常用参数
| 参数 | 说明 |
|---|---|
| FILENAME awk | 浏览的文件名 |
| BEGIN | 处理文本之前要执行的操作 |
| END | 处理文本之后要执行的操作 |
| FS | 设置输入域分隔符,等价于命令行-F选项 |
| NF | 浏览记录的域的个数(列数) |
| NR | 已读的记录数(行数) |
| OFS | 输出域分隔符 |
| ORS | 输出记录分隔符 |
| RS | 控制记录分隔符 |
| $0 | 整条记录 |
| $1 | 表示当前行的第一个域,以此类推 |
实战
搜索/etc/passwd/有root关键字的所有行,并显示对应的shell
[root@web1 Test]# awk -F: '/root/{print $7}' /etc/passwd
/bin/bash
/sbin/nologin
/sbin/nologin
[root@web1 Test]#
打印/etc/passwd的第二行信息
[root@web1 Test]# awk -F: 'NR==2{print $0}' /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
[root@web1 Test]#
使用begin加入标题
[root@web1 Test]# awk -F: 'BEGIN{print "BEGIN BEGIN"} {print $1,$2}' /etc/passwd
自定义分隔符
[root@web1 Test]# echo "111 222|333 444|555 666"
111 222|333 444|555 666
[root@web1 Test]# echo "111 222|333 444|555 666"|awk 'BEGIN{RS="|"}{print $0}'
111 222
333 444
555 666
[root@web1 Test]#
呼——终于写完了,熟能生巧,这些命令还是要多练一练。
最好能像回答1+1=2一样,别人问你,你张口就能回答出来(手动滑稽,手动狗头保命)嘿嘿~