本期与大家分享的是,小北精心整理的Hbase学习笔记,希望对大家能有帮助,喜欢就给点鼓励吧,记得三连哦!欢迎各位大佬评论区指教讨论!
💜🧡💛制作不易,各位大佬们给点鼓励!
🧡💛💚点赞👍 ➕ 收藏⭐ ➕ 关注✅
💛💚💙欢迎各位大佬指教,一键三连走起!
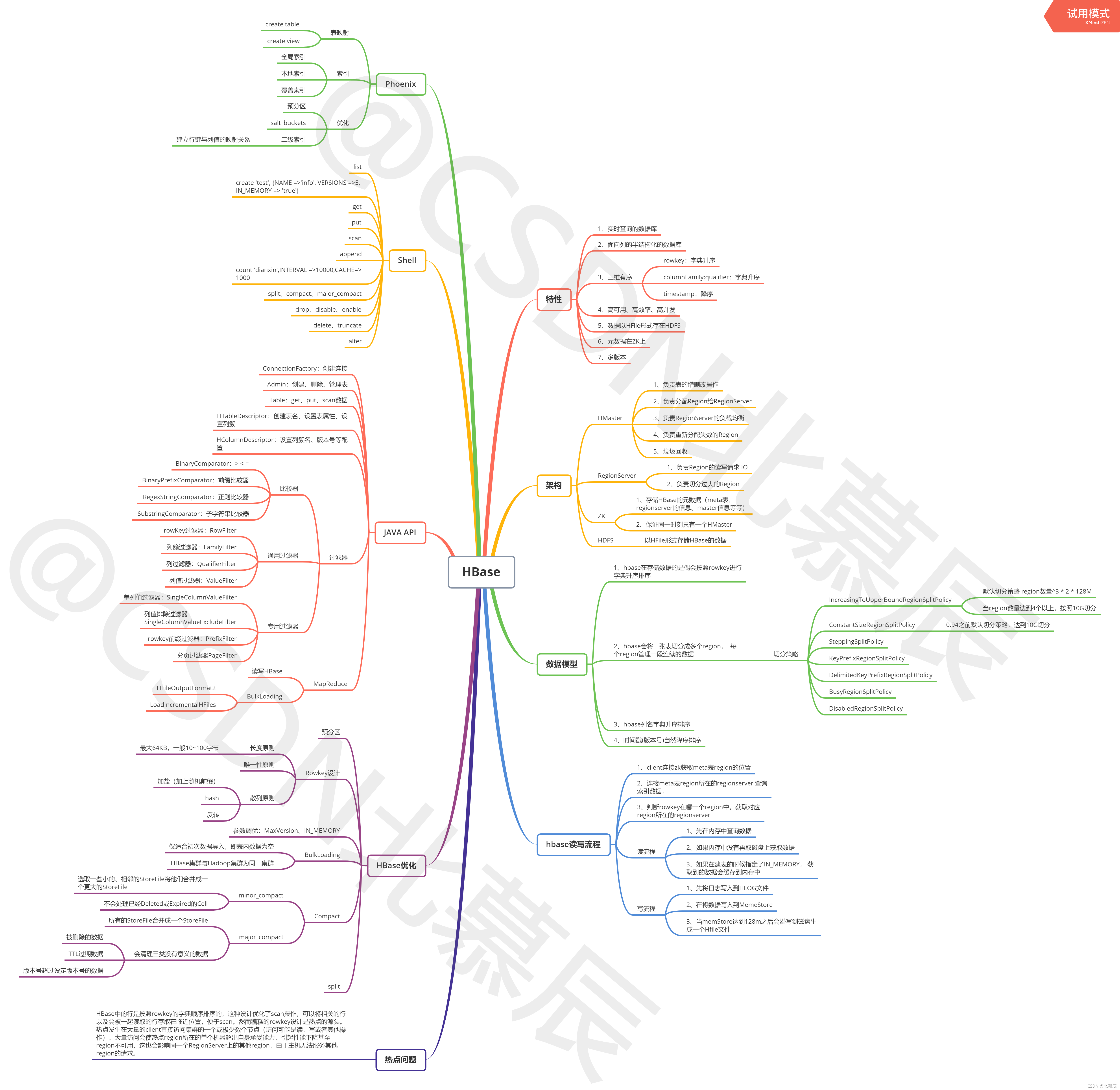
🧡HBase总结图解
🧡一、HBase基础部分
💜1、HBase简介
💜2、Hbase的系统架构
💜3、HBase的数据模型
💜4、HBase的特点
💜5、HBase的RowKey
💜6、HBase的列簇和列
💜7、HBase的时间戳
💜8、HBase的Cell单元格
💜9、HBase的HLog(WAL log)
💜10、HBase的 Region分裂策略
💜11、HBase的Compaction操作
💜12、HBase的读写流程
🧡二、HBase Shell
🧡三、HBase 的过滤器
💜1、过滤器
💜2、过滤器的作用
💜3、比较过滤器
💚比较运算符
💚常见的六大比较过滤器
💜4、专用过滤器
💜5、Bloom Filter 布隆过滤器
💚Bloom Filter 工作原理
💚Bloom Filter 在HBase中的应用
🧡四、HBase的高可用
🧡五、HBase框架及读写流程
🧡六、MapReduce读写HBase
🧡七、HBase调优
💜1、Pre-Creating Regions(预分区)
💜2、预分区实现步骤
💜3、HBase的Rowkey设计
💚rowkey长度原则
💚rowkey散列原则
💚rowkey唯一原则
💚热点问题,及解决方法
💚其它的一些调优建议
💜4、HBase In Memory
💜5、HBase Max Version
💜6、HBase Compact & Split
💜7、HBase BulkLoading
🧡八、HBase Phoenix
HBase总结图解
点我返回目录
一、HBase基础部分
点我返回目录
在学习HBase之前我们要先了解下Hadoop的生态系统,认识HBase在Hadoop生态系统中的职责:

1、HBase简介
点我返回目录
-
HBase – 是Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库
-
HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为其分布式协同服务
-
HBase主要用来存储非结构化和半结构化的松散数据(列式存储 NoSQL 数据库)
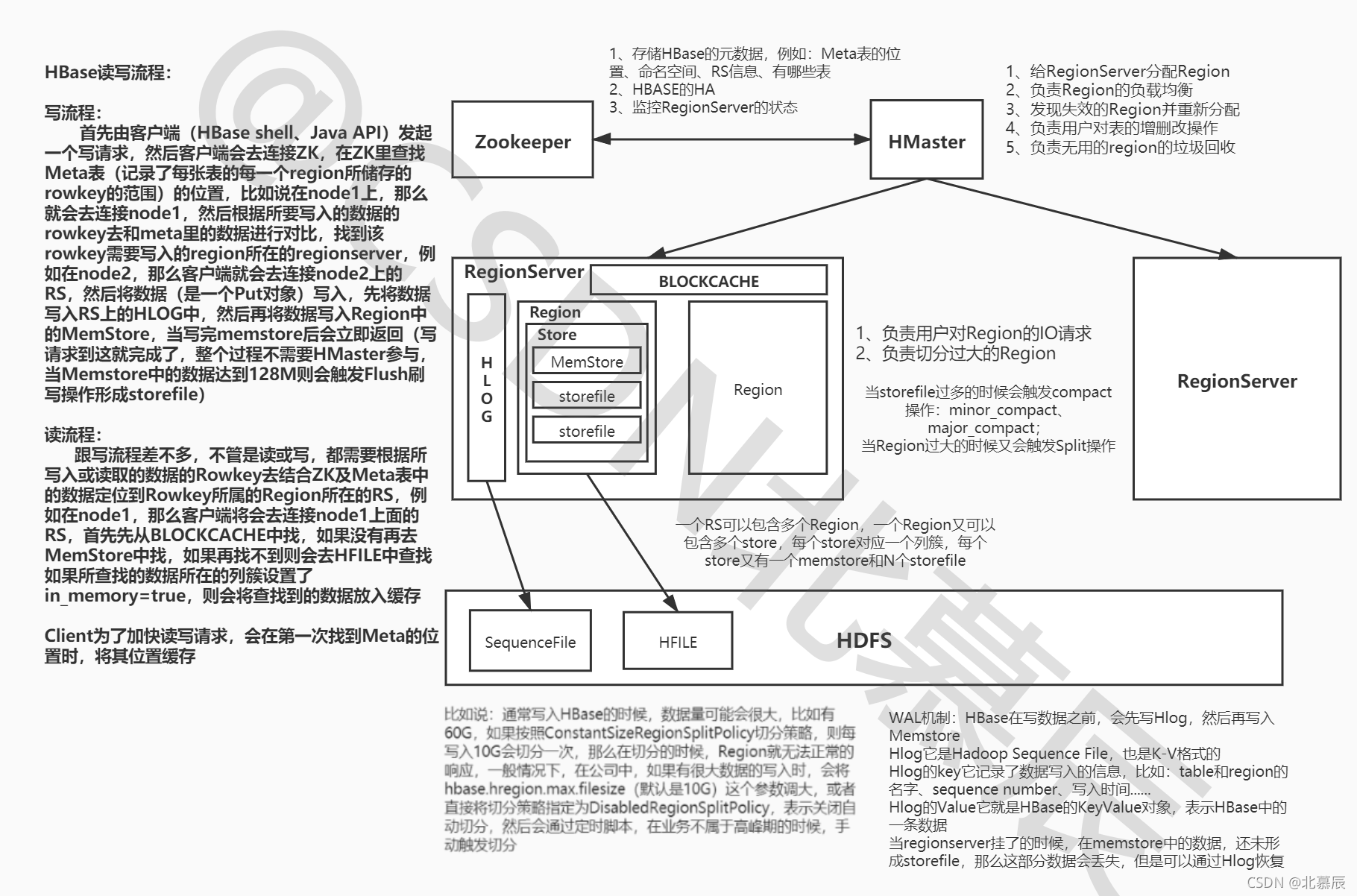
2、Hbase的系统架构
点我返回目录

HMaster的职责:
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- 管理用户对table的增删改操作
HRegionServer的职责:
- Region server维护region,处理对这些region的IO请求
- Region server负责切分在运行过程中变得过大的region
Region的功能:
HBase会自动地把表水平划分成多个区域(Region),每个Region会保存一个表里面某段连续的数据;每个表一开始只有一个Region,随着数据的不断插入表中,Region会不断地增大,当增大到一个阀值的时候,Region就会等分为两个新的Region(裂变)。这样,当table中的行不断增多,就会有越来越多的Region。这样一张完整的表被保存在多个Regionserver 上。
Memstore 与 storefile的功能:
一个Region由多个store组成,而一个store对应一个CF(列族)store包括位于内存中的memstore和位于磁盘的storefile,写操作会先写入memstore,当memstore中的数据达到某个阈值,HRegionServer会启动flashcache进程写入storefile,每次写入形成单独的一个storefile,当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile,当一个region所有storefile的大小和数量超过一定阈值后,会把当前的region分割为两个,并由HMaster分配到相应的regionserver服务器,以实现负载均衡。而客户端检索数据,会先在memstore找,若找不到会再去找storefile。
3、HBase的数据模型
点我返回目录
HRegion是HBase中分布式存储和负载均衡的最小单元。 而,最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。 HRegion由一个或者多个Store组成,每个store保存一个columns family。每个Strore又由一个memStore和0至多个StoreFile组成。如:StoreFile以HFile格式保存在HDFS上。
4、HBase的特点
点我返回目录
- 存储的数据量大:一个表可以有上亿行,上百万列。
- 面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
- 稀疏:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
- 无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态地增加,同一张表中不同的行可以有截然不同的列。
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配, 版本号就是单元格插入时的时间戳。
- 数据类型单一:HBase中的数据都是字节数组,没有类型。
5、HBase的RowKey
点我返回目录
- 唯一标识一行数据
- 可以通过RowKey获取一行数据
- 按照字典顺序排序的。
- Rowkey只能存储64k的字节数据 10-100byte
6、HBase的列簇和列
点我返回目录
- 列簇是属于表的Schema的一部分,在建表的时候必须指定至少一个Columns Family(列簇)
- HBase中的列归属于某一个列簇
- HBase在储存、权限控制、版本控制都是在列簇层面上进行
- 一个列簇对应一个store
- 列名以列族作为前缀,每个“列族”都可以有多个列成员(column);如course:a, course:b, 新的列族成员(列)可以随后按需、动态加入。
- HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
7、HBase的时间戳
点我返回目录
- HBase的时间戳就是一直提到的版本的概念,每条数据插入的时候都会记录插入时间(时间戳,64位整型)。时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间,时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
- 如果有多个版本,会按照时间戳的倒序(时间戳越大,表示数据越新)储存数据,在获取的时候,如果不指定版本,那么会默认最新一条的数据
- 如果设置了TTL(Time to Live),那么HBase将会根据TTL以及数据的时间戳去删除过期的数据
8、HBase的Cell单元格
点我返回目录
- Cell 是由 {row key,column(=< family> + < label>),version} 唯一确定的 单元。
- Cell 中的数据是没有类型的,全部是字节码形式存储。单元格的内容是未解析的字节数组。
- Cell 由行和列的坐标交叉决定。
- 单元格是有版本的。
9、HBase的HLog(WAL log)
点我返回目录
- HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。
- HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的KeyValue。
10、HBase的 Region分裂策略
点我返回目录
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,以达到负载均衡 , 这也是Hbase的一个优点 。
-
ConstantSizeRegionSplitPolicy策略
0.94版本前,HBase region的默认切分策略
当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。
但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
- 阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,形成热点,这对业务来说并不是什么好事。
- 如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
-
IncreasingToUpperBoundRegionSplitPolicy策略
0.94版本~2.0版本默认切分策略
总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。
但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系.region split阈值的计算公式是:
-
设regioncount:是region所属表在当前regionserver上的region的个数
-
阈值 = regioncount^3 * 128M * 2,当然阈值并不会无限增长,最大不超过MaxRegionFileSize(10G),当region中最大的store的大小达到该阈值的时候进行region split
例如:
- 第一次split阈值 = 1^3 * 256 = 256MB
- 第二次split阈值 = 2^3 * 256 = 2048MB
- 第三次split阈值 = 3^3 * 256 = 6912MB
- 第四次split阈值 = 4^3 * 256 = 16384MB > 10GB,因此取较小的值10GB
- 后面每次split的size都是10GB了
特点
- 相比ConstantSizeRegionSplitPolicy,可以自适应大表、小表;
- 在集群规模比较大的情况下,对大表的表现比较优秀
- 对小表不友好,小表可能产生大量的小region,分散在各regionserver上
- 小表达不到多次切分条件,导致每个split都很小,所以分散在各个regionServer上
-
-
SteppingSplitPolicy策略
2.0版本默认切分策略
相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些
region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系- 如果region个数等于1,切分阈值为flush size 128M * 2
- 否则为MaxRegionFileSize。
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
-
KeyPrefixRegionSplitPolicy策略
根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中。
-
DelimitedKeyPrefixRegionSplitPolicy策略
保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。
按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分。 -
BusyRegionSplitPolicy策略
按照一定的策略判断Region是不是Busy状态,如果是即进行切分
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
-
DisabledRegionSplitPolicy策略
不启用自动拆分, 需要指定手动拆分
11、HBase的Compaction操作
点我返回目录
Minor Compaction:
- 指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次 Minor Compaction 的结果是更少并且更大的StoreFile。
Major Compaction:
- 指将所有的StoreFile合并成一个StoreFile,这个过程会清理三类没有意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,major compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发major compaction功能,改为手动在业务低峰期触发。
深入理解 HBase Compaction 机制,好文解析:https://cloud.tencent.com/developer/article/1488439
12、HBase的读写流程
点我返回目录

二、HBase Shell
点我返回目录
语法1:创建表
create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}
# 创建一个User表,并且有一个info列族
create 'User','info'
语法2:查看所有表
list
语法3:查看表详情
describe 'User'
语法4:表修改
# 删除指定的列族
alter 'User', 'delete' => 'info'
#增加新的列族
alter 'User', NAME => 'info'
语法5:插入数据
put <table>,<rowkey>,<family:column>,<value>
#例如:
put 'User', 'row1', 'info:name', 'xiaoming'
put 'User', 'row2', 'info:age', '18'
put 'User', 'row3', 'info:sex', 'man'
语法6:根据rowKey查询某个记录
get <table>,<rowkey>,[<family:column>,....]
#例如:
get 'User', 'row2'
语法7:查询所有记录
scan <table>, {COLUMNS => [ <family:column>,.... ], LIMIT => num}
#扫描所有记录
scan 'User'
#扫描前2条
scan 'User', {LIMIT => 2}
#范围查询 STARTROW(开始rowkey) ENDROW(结束rowkey)
scan 'User', {STARTROW => 'row2'}
scan 'User', {STARTROW => 'row2', ENDROW => 'row2'}
scan 'User', {STARTROW => 'row2', ENDROW => 'row3'}
#另外,还可以添加TIMERANGE和FITLER等高级功能
#STARTROW,ENDROW必须大写,否则报错;查询结果不包含等于ENDROW的结果集
语法8:统计表记录数
count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
#INTERVAL设置多少行显示一次及对应的rowkey,默认1000;
#CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
语法9:删除
#删除列
delete 'User', 'row1', 'info:age'
#指定rowkey删除
deleteall 'User', 'row2'
#删除表中所有数据
truncate 'User'
语法10:表管理
#禁用表
disable 'User'
#启用表
enable 'User'
#测试表是否存在
exists 'User'
#删除表,删除前,必须先disable禁用表
disable 'User'
drop 'User'
三、HBase 的过滤器
1、过滤器
点我返回目录
HBase 的基本 API,包括增、删、改、查等。其中的增、删都是相对简单的操作,与传统的 RDBMS 相比,这里的查询操作略显苍白,只能根据特性的行键进行查询(Get)或者根据行键的范围来查询(Scan)。但是HBase 不仅提供了这些简单的查询,同时还提供了更加高级的过滤器(Filter)来查询。
2、过滤器的作用
点我返回目录
- 过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端
- 过滤器的类型很多,但是可以分为两大类:
- 比较过滤器:可应用于rowkey、列簇、列、列值过滤器
- 专用过滤器:只能适用于特定的过滤器
3、比较过滤器
点我返回目录
过滤器可以根据列族、列、版本等更多的条件来对数据进行过滤,基于 HBase 本身提供的三维有序(行键,列,版本有序),这些过滤器可以高效地完成查询过滤的任务,带有过滤器条件的 RPC 查询请求会把过滤器分发到各个 RegionServer(这是一个服务端过滤器),这样也可以降低网络传输的压力。而,使用过滤器至少需要两类参数:一类是抽象的操作符,另一类是比较器
比较运算符
HBase 提供了枚举类型的变量来表示这些抽象的操作符:
LESS : 小于
LESS_OR_EQUAL : 小于等于
EQUAL : 等于
NOT_EQUAL:不等于
GREATER_OR_EQUAL : 大于等于
GREATER: 大于
NO_OP ; 不比较,排除所有
常见的六大比较过滤器
点我返回目录
BinaryComparator
二进制比较器,按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[])
BinaryPrefixComparator
前缀二进制比较器。与二进制比较器不同的是,只比较前缀是否相同。
NullComparator
判断给定的是否为空
BitComparator
按位比较
RegexStringComparator
提供一个正则的比较器,仅支持 EQUAL 和非EQUAL
SubstringComparator
判断提供的子串是否出现在值中,并且不区分大小写。
列值过滤器:效率较低,需要做全表扫描
SingleColumnValueFilter:用于测试值的情况(相等,不等,范围 、、、)
列簇过滤器:
FamilyFilter:用于过滤列族(通常在 Scan 过程中通过设定某些列族来实现该功能,而不是直接使用该过滤器)。
列名过滤器:
QualifierFilter:用于列名(Qualifier)过滤。
行键过滤器:效率较高,行键前缀过滤效率较高
RowFilter:行键过滤器,一般来讲,执行 Scan 使用 startRow/stopRow 方式比较好,而 RowFilter 过滤器也可以完成对某一行的过滤。
4、专用过滤器
点我返回目录
单列值过滤器:SingleColumnValueFilter
SingleColumnValueFilter会返回满足条件的cell所在行的所有cell的值(即会返回一行数据)
列值排除过滤器:SingleColumnValueExcludeFilter
与SingleColumnValueFilter相反,会排除掉指定的列,其他的列全部返回
rowkey前缀过滤器:PrefixFilter
通过PrefixFilter前缀过滤器查询以150010008开头的所有前缀的rowkey
分页过滤器PageFilter
使用PageFilter分页效率比较低,每次都需要扫描前面的数据,直到扫描到所需要查的数据
可设计一个合理的rowkey来实现分页需求
5、Bloom Filter 布隆过滤器
点我返回目录
Bloom Filter(布隆过滤器)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。
它的用法其实是很容易理解的,我们拿个HBase中应用的例子来说下,我们已经知道rowKey存放在HFile中,那么为了从一系列的HFile中查询某个rowkey,我们就可以通过 Bloom Filter 快速判断 rowkey 是否在这个HFile中,从而过滤掉大部分的HFile,减少需要扫描的Block。
Bloom Filter 工作原理
点我返回目录
BloomFilter对于HBase的随机读性能至关重要,对于get操作以及部分scan操作可以剔除掉不会用到的HFile文件,以减少实际IO次数,提高随机读性能。简单地介绍一下Bloom Filter的工作原理,Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为0,如下图所示:

假如此时有一个集合S = {x1, x2, … xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围。对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。比如元素x1被hash函数映射到数字8,那么位数组的第8位就会被置为1。下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,3,6)和(4,7,10),对应的位会被置为1:

现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
 从上面的内容我们可以得知,Bloom Filter有两个很重要的参数
从上面的内容我们可以得知,Bloom Filter有两个很重要的参数
哈希函数个数
位数组的大小
Bloom Filter 在HBase中的应用
点我返回目录
HFile 中和 Bloom Filter 相关的Block,
Scanned Block Section(扫描HFile时被读取):Bloom Block
Load-on-open-section(regionServer启动时加载到内存):BloomFilter Meta Block、Bloom Index Block
Bloom Block:Bloom数据块,存储Bloom的位数组
Bloom Index Block:Bloom数据块的索引
BloomFilter Meta Block:从HFile角度看bloom数据块的一些元数据信息,大小个数等等。
HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
HFile中的Bloom Block中存储的就是上面说的位数组,当HFile很大时,Data Block 就会很多,同时KeyValue也会很多,需要映射入位数组的rowKey也会很多,所以为了保证准确率,位数组就会相应越大,那Bloom Block也会越大,为了解决这个问题就出现了Bloom Index Block,一个HFile中有多个Bloom Block(位数组),根据rowKey拆分,一部分连续的Key使用一个位数组。这样查询rowKey就要先经过Bloom Index Block(在内存中)定位到Bloom Block,再把Bloom Block加载到内存,进行过滤。
四、HBase的高可用
点我返回目录

五、HBase框架及读写流程
点我返回目录
六、MapReduce读写HBase
点我返回目录

七、HBase调优
点我返回目录
1、Pre-Creating Regions(预分区)
点我返回目录
- 默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候, 所有的HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分。 一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入 HBase时,会按照region分区情况,在集群内做数据的负载均衡。
- 如果知道hbase数据表的key的分布情况,就可以在建表的时候对hbase进行region的预分区。这样做的好处是防止大数据量插入的热点问题,提高数据插入的效率。
2、预分区实现步骤
点我返回目录
首先就是要想明白数据的key是如何分布的,然后规划一下要分成多少region,每个region的startkey和endkey是多少,然后将规划的key写到一个文件中。比如,key的前几位字符串都是从0001~0010的数字,这样可以分成10个region,划分key的文件如下:注意不要多一行空行
为什么后面会跟着一个"|",是因为在ASCII码中,"|"的值是124,大于所有的数字和字母等符号,当然也可以用“~”(ASCII-126)。分隔文件的第一行为第一个region的stopkey,每行依次类推,最后一行不仅是倒数第二个region的stopkey,同时也是最后一个region的startkey。也就是说分区文件中填的都是key取值范围的分隔点,如下图所示:

3、HBase的Rowkey设计
点我返回目录
HBase是三维有序存储的,通过rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
HBase中rowkey可以唯一标识一行记录,在HBase查询的时候,有三种方式:
-
通过get方式,指定rowkey获取唯一一条记录
-
通过scan方式,设置startRow和stopRow参数进行范围匹配
-
全表扫描,即直接扫描整张表中所有行记录
rowkey长度原则
点我返回目录
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以 byte[] 形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因如下:数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。
rowkey散列原则
点我返回目录
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率。
rowkey唯一原则
点我返回目录
必须在设计上保证其唯一性,rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
热点问题,及解决方法
点我返回目录
HBase中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey设计是热点的源头。 热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他region,由于主机无法服务其他region的请求。 设计良好的数据访问模式以使集群被充分,均衡的利用。
为了避免写热点,设计rowkey使得不同行在同一个region,但是在更多数据情况下,数据应该被写入集群的多个region,而不是一个。
下面是一些常见的避免热点问题的方法以及它们的优缺点:
加盐
点我返回目录
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
点我返回目录
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转
点我返回目录
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转
点我返回目录
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp 追加到key的末尾,例如[key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。
比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计:
[userId反转][Long.Max_Value - timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value - timestamp]
如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value - 起始时间],stopRow是[userId反转][Long.Max_Value - 结束时间]
其它的一些调优建议
点我返回目录
- 尽量减少rowkey和列的大小,当具体的值在系统间传输时,它的rowkey,列簇、列名,时间戳也会一起传输。如果你的rowkey、列簇名、列名很大,甚至可以和具体的值相比较,那么将会造成大量的冗余,不利于数据的储存与传输。列族尽可能越短越好,最好是一个字符;列名也尽可能越短越好,冗长的列名虽然可读性好,但是更短的列名存储在HBase中会更好
4、HBase In Memory
点我返回目录
- 创建表的时候,可以通过HColumnDescriptor.setInMemory(true)将表放到 RegionServer的缓存中,保证在读取的时候被cache命中。
5、HBase Max Version
- 创建表的时候,可以通过HColumnDescriptor.setMaxVersions(int maxVersions)设置 表中数据的最大版本,如果只需要保存最新版本的数据,那么可以设置 setMaxVersions(1)。
6、HBase Compact & Split
点我返回目录
-
在HBase中,数据在更新时首先写入WAL 日志(HLog)和内存(MemStore)中, MemStore中的数据是排序的,当MemStore累计到一定阈值时,由单独的线程flush到磁盘上,成为一个StoreFile。与此同时, 系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了
-
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。
7、HBase BulkLoading
点我返回目录
优点:
-
如果我们一次性入库hbase巨量数据,处理速度慢不说,还特别占用Region资源, 一个比较高效便捷的方法就是使用 “Bulk Loading”方法,即HBase提供的HFileOutputFormat类。
-
它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接生成这种hdfs内存储的数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载。
限制:
-
仅适合初次数据导入,即表内数据为空,或者每次入库表内都无数据的情况。
-
HBase集群与Hadoop集群为同一集群,即HBase所基于的HDFS为生成HFile的MR的集群
八、HBase Phoenix
点我返回目录
Hbase适合存储大量的对关系运算要求低的NOSQL数据,受Hbase 设计上的限制不能直接使用原生的API执行在关系数据库中普遍使用的条件判断和聚合等操作。Hbase很优秀,一些团队寻求在Hbase之上提供一种更面向普通开发人员的操作方式,Apache Phoenix即是。
Phoenix 基于Hbase给面向业务的开发人员提供了以标准SQL的方式对Hbase进行查询操作,并支持标准SQL中大部分特性:条件运算,分组,分页,等高级查询语法。
有关phoenix的详细介绍,和使用操作,下一期整理!
链接位置先给预留好,嘻嘻