深度学习
以神经网络算法为基础的机器学习
深度学习算法:
BP神经网络
卷积神经网络
循环神经网络
基于注意的循环神经网络
对抗神经网络
神经网络
脑神经网络
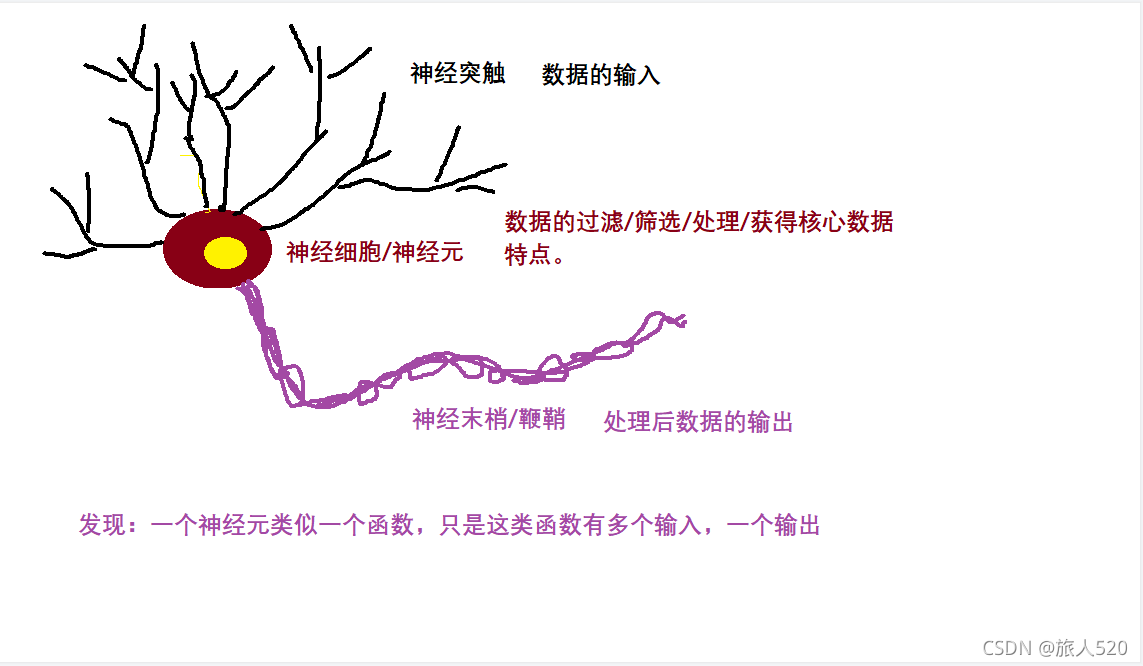
人工神经网络
一堆函数的网络
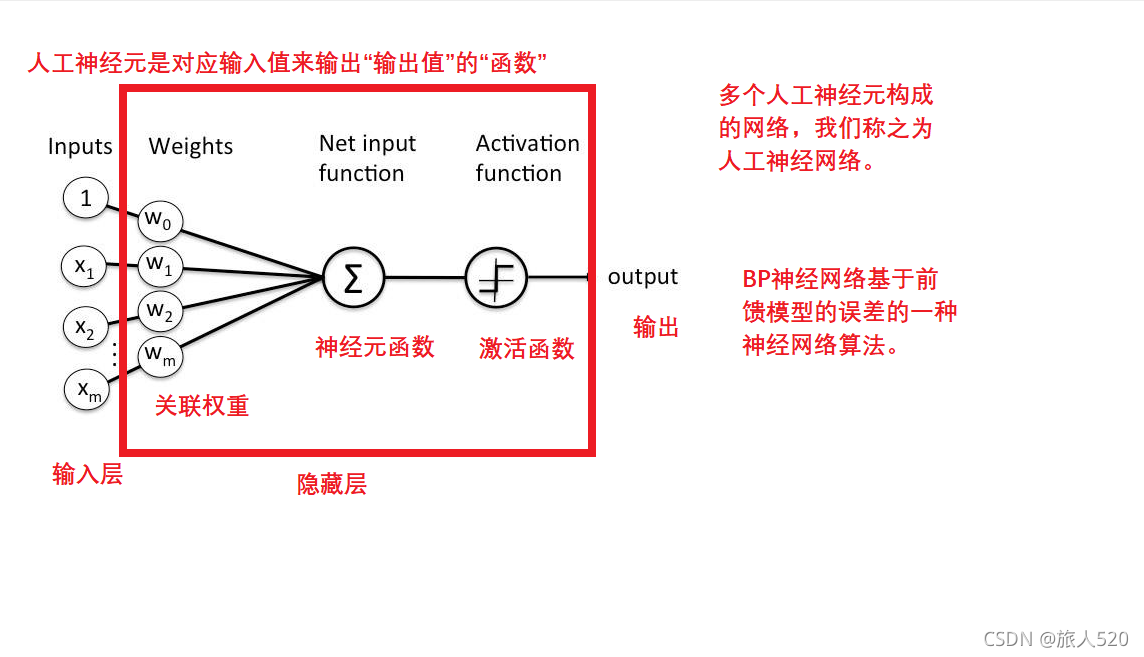
卷积神经网络
使用卷积运算作为神经元函数的神经网络,我们称之为卷积神经网络
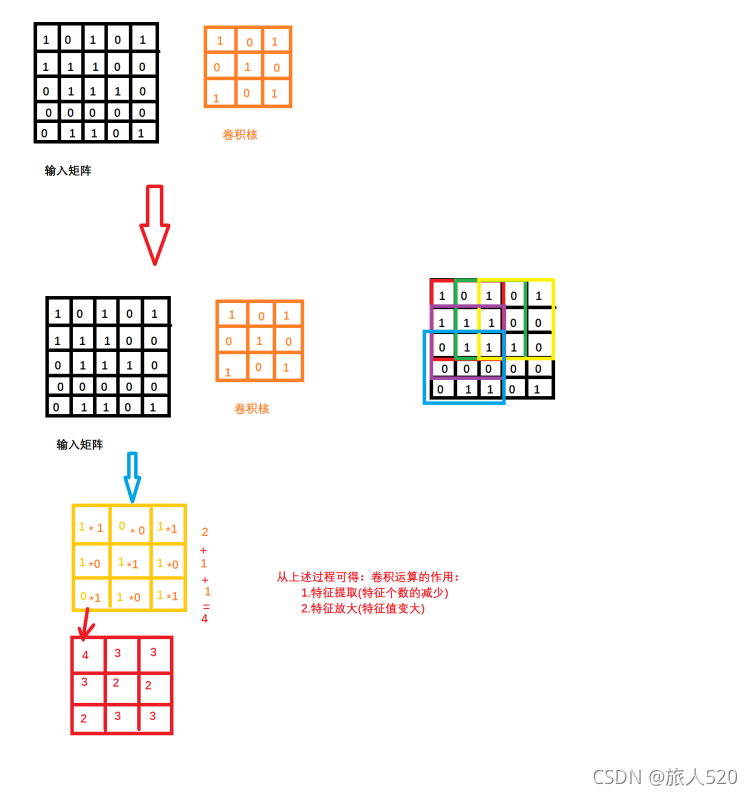
使用范围:
二维的图形特征提取
卷积神经网络的结构
常用层
输入层:数据的输入
关联权重层(*可以加,可以不加)
卷积层:实现卷积过程
池化层:对主要特征降维
全连接层:将特征图全连接
输出层:获取输出结果
其他层
正则化层
高级层(激活函数/其他的函数)
超参数:在机器学习中,需要反复迭代求得的参数,称之为超参数。
卷积层:
卷积运算:
作用:
1.特征提取
2.特征降维
卷积核:
卷积核:也叫过滤器
卷积核的移动
卷积核在输入矩阵中移动的格子数,称之为步长。
步长 >= 1
卷积核的大小
卷积核的大小也是一个超参数,一般会选择奇数行列。
卷积核的内容
卷积核的内容也需要反复迭代求得。
常见的卷积核
->水平边缘检测滤波器
->垂直边缘检测滤波器
->增强图片中心滤波器
输入数据于卷积核不匹配的问题:
填充,填充的大小也是超参数。
填充的过程:
在输入矩阵外围填充一圈0
填充大小为p = (f - 1)/2
f为卷积核的大小
一次卷积后,卷积得到的输出矩阵(特征图)的大小:
s:步幅
f:卷积核的大小
n:输入矩阵的大小
p:填充
输出矩阵的大小为:(n + 2p -f)/s + 1
n f
5x5 3x3 s=1 p=0 (5+0-3)/1 + 1 = 3
5x5 3x3 s=2 p=1 (5+2-3)/2 + 1 = 3
多通道卷积如何实现:
日常生活中,图片都是彩色的。是RGB图片。
320*240
RGB24:一个像素点占24bit位:
R:G:B : 8:8:8
320 * 240 * 3
按RGB不同的通道,就能得到3个像素信息矩阵。
然而对彩色图片的卷积,就变成了对三个不同通道的矩阵进行卷积。我们把这种卷积方式称之为多通道卷积。
如何处理多通道卷积:
此时就需要对不同通道使用不同的卷积核,而多个卷积核我们放在同一层面上进行卷积时,通常将其放入同一个卷积核组。
真实情况是会使用不同的卷积核组分别对多通道数据进行卷积。
多通道卷积结果的运算:
每个卷积核组卷积完成后的输出,等同于单通道卷积
但是输出多个特征图,特征图的个数取决于卷积核组的个数。
单通道卷积案例:
n:32*32 = 1024
s : 1
f : 5
p : 0
(n + 2p -f)/s + 1 = 27/1 + 1 = 28
28 * 28 = 784
2*2的采样控件
14 * 14 = 196
导致模型失败的原因:
过拟合:
模型需要的特征值过于详细,导致模型没有泛化能力。
案例:
白马非马
白天鹅不是天鹅
欠拟合:
模型提取的特征值太少,导致识别错误。
案例:
指鹿为马
池化层:(采样)
池化的作用:
1.池化层在CNN中,可以用来减小尺寸、提高运算速度以及减小噪声影响,让各特征更具有健壮性。
2.降低网络训练参数及模型的过拟合程度
什么是池化:
池化(Pooling)又称为下采样,通过卷积层获得图像的特征后,理论上可以直接使用这些特征训练分类器(如softmax)。但是,这样做将面临巨大的计算量的挑战,而且容易产生过拟合的现象。
池化的手段:
->最大池化
在池化区域中,取最大值,代表该区域的特征值
->均值池化
在池化区域中,取平均值值,代表该区域的特征值
->随机池化
在池化区域中,随机取一个值,代表该区域的特征值
池化区域的大小:是反复迭代求得的。
激活函数:
什么是激活函数:
sigmod
Tanh函数
ReLU函数
激活函数的作用:
卷积神经网络与标准神经网络类似,为了保证其非线性,也需要使用激活函数,即在卷积运算后,把输出值另加偏移量,输入到激活函数,然后作为下一层的输入
全连接:
进行多通道卷积/单通道卷积之后,会得到一些张量矩阵。将多维张量连接成一个一维张量,这个过程称之为全连接。
常见的卷积神经网络结构:
Le-Net5:串联型卷积神经网络
GoogLeNet:Inception模型:并联型卷积神经网络
卷积神经网络的目的:
1.得到最优的神经网络结构
2.得到最优的超参数组
3.解决特征提取和特征降维的问题
opencv
图形图像处理库,C++、Python等编程语言的接口
如何安装:
pip install opencv-python -i https://mirrors.aliyun.com/pypi/simple/
使用opencv采集视频并且进行人脸检测定位
import cv2 as cv
#打开系统中默认第一个摄像头类似于linux下打开/dev/video0
cap = cv.VideoCapture(0)
path = "D:\\Program Files\\Python36\\Lib\\site-packages\\cv2\\data\\"
face_class = cv.CascadeClassifier(path+"haarcascade_frontalface_default.xml")
while True:
#读取摄像头采到的数据
ret,img = cap.read()
#将采集到的彩色图片转换为灰度图片
img_gray = cv.cvtColor(img, cv.COLOR_RGB2GRAY)
faces = face_class.detectMultiScale(img_gray, 1.3, 5)
for (x,y,w,h) in faces:
cv.rectangle(img,(x,y),(x+w,y+h),(0,0,255),3)
#想要确保图片显示没有问题,建议先创建一个namedWindow
cv.namedWindow("pic",cv.WINDOW_AUTOSIZE)
cv.imshow("video",img)
#判断是否按下q键
if cv.waitKey(1) & 0xFF == ord('q'):
break
#销毁显示的所有窗体
cv.destroyAllWindows()
#释放掉创建出来的摄像头对象
cap.release()使用python实现录音功能
库:pyaudio
安装:pip install pyaudio
例子:
import pyaudio
import wave
#一个管理PyAudio实例的说明(每一帧的大小)
CHUNK = 1024
#采集样例的位深度
FORMAT = pyaudio.paInt16
#通道数
CHANNELS = 2
#样例的速率
RATE = 44100
#录音时间
RECORD_SECONDS = 5
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()python 语音播放
语音播放包 pygame
包的安装:pip install pygame
例子:
import pygame
import time
#音频初始化
pygame.mixer.init()
#加载音频
pygame.mixer.music.load("auido.mp3")
#开始播放
pygame.mixer.music.play()
#等待播放(播放的过程)
time.sleep(3)
#停止播放
pygame.mixer.music.stop()
#注意:延时一定要有,不然听不到声音百度AI平台的使用
人脸对比
EasyDL
"""
EasyDL 图像分类 调用模型公有云API Python3实现
"""
import json
import base64
import requests
"""
使用 requests 库发送请求
使用 pip(或者 pip3)检查我的 python3 环境是否安装了该库,执行命令
pip freeze | grep requests
若返回值为空,则安装该库
pip install requests
"""
# 目标图片的 本地文件路径,支持jpg/png/bmp格式
IMAGE_FILEPATH = "1.jpg"
# 可选的请求参数
# top_num: 返回的分类数量,不声明的话默认为 6 个
PARAMS = {"top_num": 2}
# 服务详情 中的 接口地址
MODEL_API_URL = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/classification/mycheckface"
# 调用 API 需要 ACCESS_TOKEN。若已有 ACCESS_TOKEN 则于下方填入该字符串
# 否则,留空 ACCESS_TOKEN,于下方填入 该模型部署的 API_KEY 以及 SECRET_KEY,会自动申请并显示新 ACCESS_TOKEN
ACCESS_TOKEN = ""
API_KEY = "gPhZUzA3yk70zSplKKhw5Itb"
SECRET_KEY = "GlSQaRcgDlmALq2CkTUD1XbAA9QanCYb"
print("1. 读取目标图片 '{}'".format(IMAGE_FILEPATH))
with open(IMAGE_FILEPATH, 'rb') as f:
base64_data = base64.b64encode(f.read())
base64_str = base64_data.decode('UTF8')
print("将 BASE64 编码后图片的字符串填入 PARAMS 的 'image' 字段")
PARAMS["image"] = base64_str
if not ACCESS_TOKEN:
print("2. ACCESS_TOKEN 为空,调用鉴权接口获取TOKEN")
auth_url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials" "&client_id={}&client_secret={}".format(API_KEY, SECRET_KEY)
auth_resp = requests.get(auth_url)
auth_resp_json = auth_resp.json()
ACCESS_TOKEN = auth_resp_json["access_token"]
print("新 ACCESS_TOKEN: {}".format(ACCESS_TOKEN))
else:
print("2. 使用已有 ACCESS_TOKEN")
print("3. 向模型接口 'MODEL_API_URL' 发送请求")
request_url = "{}?access_token={}".format(MODEL_API_URL, ACCESS_TOKEN)
response = requests.post(url=request_url, json=PARAMS)
response_json = response.json()
response_str = json.dumps(response_json, indent=4, ensure_ascii=False)
print("结果:{}".format(response_str))
print(response_json['results'][0]['name'])语音合成
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '24873305'
API_KEY = 'uzWDokZaiYxGTH5Sn1UKnN85'
SECRET_KEY = 'H3l5DBSfGbq7QsFgHAfPri04azPWVITs'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你这黑厮,甚是嚣张,不知是烧窑的还是卖炭的', 'zh', 1, {
'vol': 8, 'per':3, 'spd':4,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f:
f.write(result)语言识别
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '24873305'
API_KEY = 'uzWDokZaiYxGTH5Sn1UKnN85'
SECRET_KEY = 'H3l5DBSfGbq7QsFgHAfPri04azPWVITs'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
ret = client.asr(get_file_content('audio.wav'), 'wav', 16000, {
'dev_pid': 1737,
})
print(ret['result'][0])