全网最详细的大数据ELK文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
系列历史文章
美文搜索案例
一、需求
二、准备工作
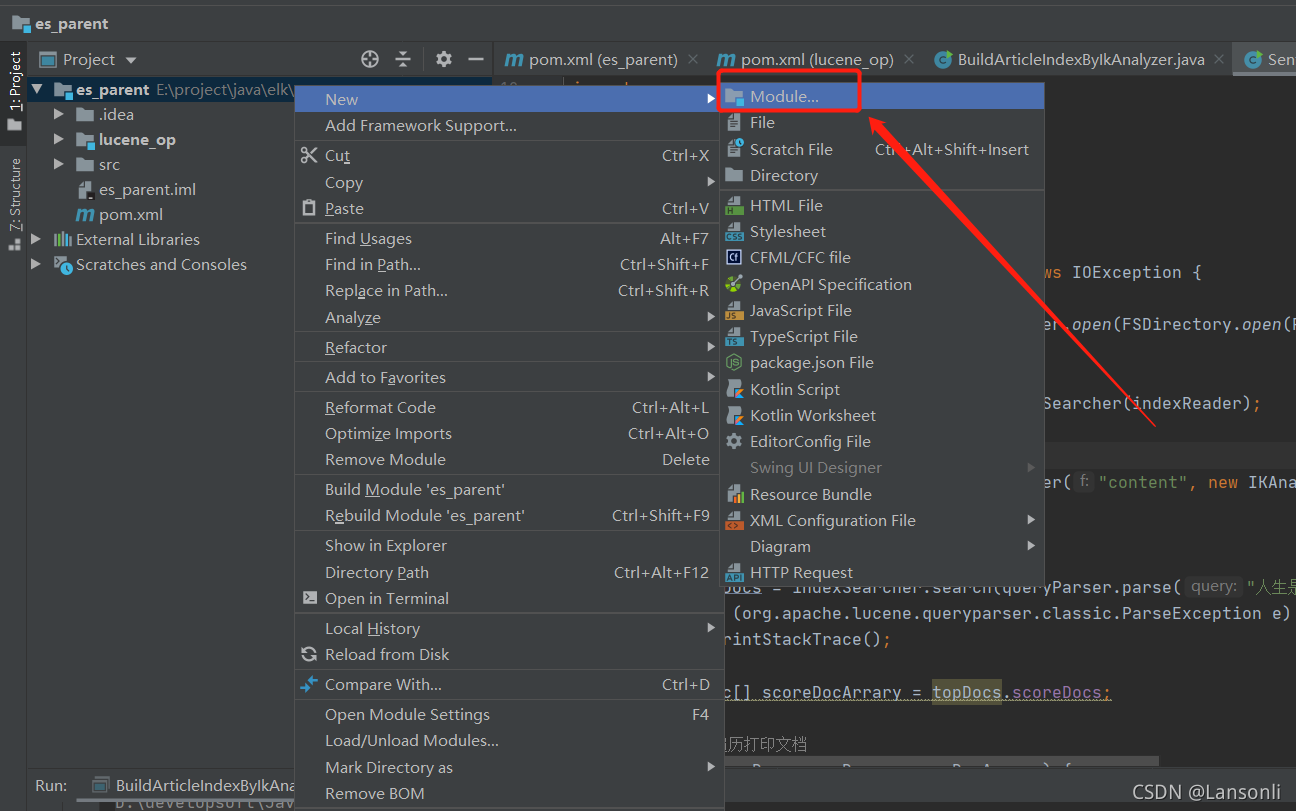
1、创建IDEA项目
2、创建父工程
3、添加lucene模块
4、导入Maven依赖
5、创建包和类
6、导入文章数据
三、建立索引库
1、实现步骤
2、参考代码
3、执行效果
四、关键字查询
1、需求
2、准备工作
3、开发步骤
4、参考代码
5、执行效果
五、搜索词语问题
六、分词器与中文分词器
七、使用IK分词器重构案例
1、准备工作
2、实现步骤
3、参考代码
4、执行效果
5、问题
八、句子搜索
1、实现步骤
2、参考代码
3、执行效果
系列历史文章
2021年大数据ELK(五):Elasticsearch中的核心概念
2021年大数据ELK(四):Lucene的美文搜索案例
2021年大数据ELK(三):Lucene全文检索库介绍
2021年大数据ELK(二): Elasticsearch简单介绍
2021年大数据ELK(一):集中式日志协议栈Elastic Stack简介
美文搜索案例
一、需求
在资料中的文章文件夹中,有很多的文本文件。这里面包含了一些非常有趣的软文。而我们想要做的事情是,通过搜索一个关键字就能够找到哪些文章包含了这些关键字。例如:搜索「hadoop」,就能找到hadoop相关的文章。
需求分析:
要实现以上需求,我们有以下两种办法:
- 用户输入搜索关键字,然后我们挨个读取文件,并查找文件中是否包含关键字
- 我们先挨个读取文件,对文件的文本进行分词(例如:按标点符号),然后建立索引,用户输入关键字,根据之前建立的索引,搜索关键字。
很明显,第二种方式要比第一种效果好得多,性能也好得多。所以,我们下面就使用Lucene来建立索引,然后根据索引来进行检索。
二、准备工作
1、创建IDEA项目
此处在IDEA中的工程模型如下:
2、创建父工程
| groupId | cn.it |
| artifactId | es_parent |
3、添加lucene模块
| groupId | cn.it |
| artifactId | lucene_op |
4、导入Maven依赖
导入依赖到lucene_op的pom.xml
<dependencies>
<!-- lucene核心类库 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.4.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
5、创建包和类
- 在java目录创建 cn.it.lucene 包结构
- 创建BuildArticleIndex类
6、导入文章数据
- 在 lucene_op 模块下创建名为 data 的目录,用来存放文章文件
- 在 lucene_op 模块下创建名为 index 的目录,用于存放最后生成的索引文件
- 将资料/文章目录下的txt文件复制到 data 目录中
三、建立索引库
1、实现步骤
- 构建分词器(StandardAnalyzer)
- 构建文档写入器配置(IndexWriterConfig)
- 构建文档写入器(IndexWriter,注意:需要使用Paths来)
- 读取所有文件构建文档
- 文档中添加字段
| 字段名 | 类型 | 说明 |
| file_name | TextFiled | 文件名字段,需要在索引文档中保存文件名内容 |
| content | TextFiled | 内容字段,只需要能被检索,但无需在文档中保存 |
| path | StoredFiled | 路径字段,无需被检索,只需要在文档中保存即可 |
- 写入文档
- 关闭写入器
2、参考代码
package cn.it.lucene;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
public class BuildArticleIndex {
public static void main(String[] args) throws IOException {
// 1. 构建分词器(StandardAnalyzer)
StandardAnalyzer standardAnalyzer = new StandardAnalyzer();
// 2. 构建文档写入器配置(IndexWriterConfig)
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(standardAnalyzer);
// 3. 构建文档写入器(IndexWriter)
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")), indexWriterConfig);
// 4. 读取所有文件构建文档
File articleDir = new File("E:\\project\\java\\elk\\es_parent\\lucene_op\\data");
File[] fileList = articleDir.listFiles();
for (File file : fileList) {
// 5. 文档中添加字段
Document docuemnt = new Document();
docuemnt.add(new TextField("file_name", file.getName(), Field.Store.YES));
docuemnt.add(new TextField("content", FileUtils.readFileToString(file, "UTF-8"), Field.Store.NO));
docuemnt.add(new StoredField("path", file.getAbsolutePath() + "/" + file.getName()));
// 6. 写入文档
indexWriter.addDocument(docuemnt);
}
// 7. 关闭写入器
indexWriter.close();
}
}
3、执行效果
四、关键字查询
1、需求
输入一个关键字“心”,根据关键字查询索引库中是否有匹配的文档
2、准备工作
- 前提:基于文章文本文件,已经生成好了索引
- 在cn.it.lucene包下创建一个类KeywordSearch
3、开发步骤
- 使用DirectoryReader.open构建索引读取器
- 构建索引查询器(IndexSearcher)
- 构建词条(Term)和词条查询(TermQuery)
- 执行查询,获取文档
- 遍历打印文档(可以使用IndexSearch.doc根据文档ID获取到文档)
- 关键索引读取器
4、参考代码
package cn.it.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
public class KeywordSearch {
public static void main(String[] args) throws IOException {
// 1. 构建索引读取器
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")));
// 2. 构建索引查询器
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 3. 执行查询,获取文档
TermQuery termQuery = new TermQuery(new Term("content", "心"));
TopDocs topDocs = indexSearcher.search(termQuery, 50);
ScoreDoc[] scoreDocArrary = topDocs.scoreDocs;
// 4. 遍历打印文档
for (ScoreDoc scoreDoc : scoreDocArrary) {
int docId = scoreDoc.doc;
Document document = indexSearcher.doc(docId);
System.out.println("文件名:" + document.get("file_name") + " 路径:" + document.get("path"));
}
indexReader.close();
}
}
5、执行效果
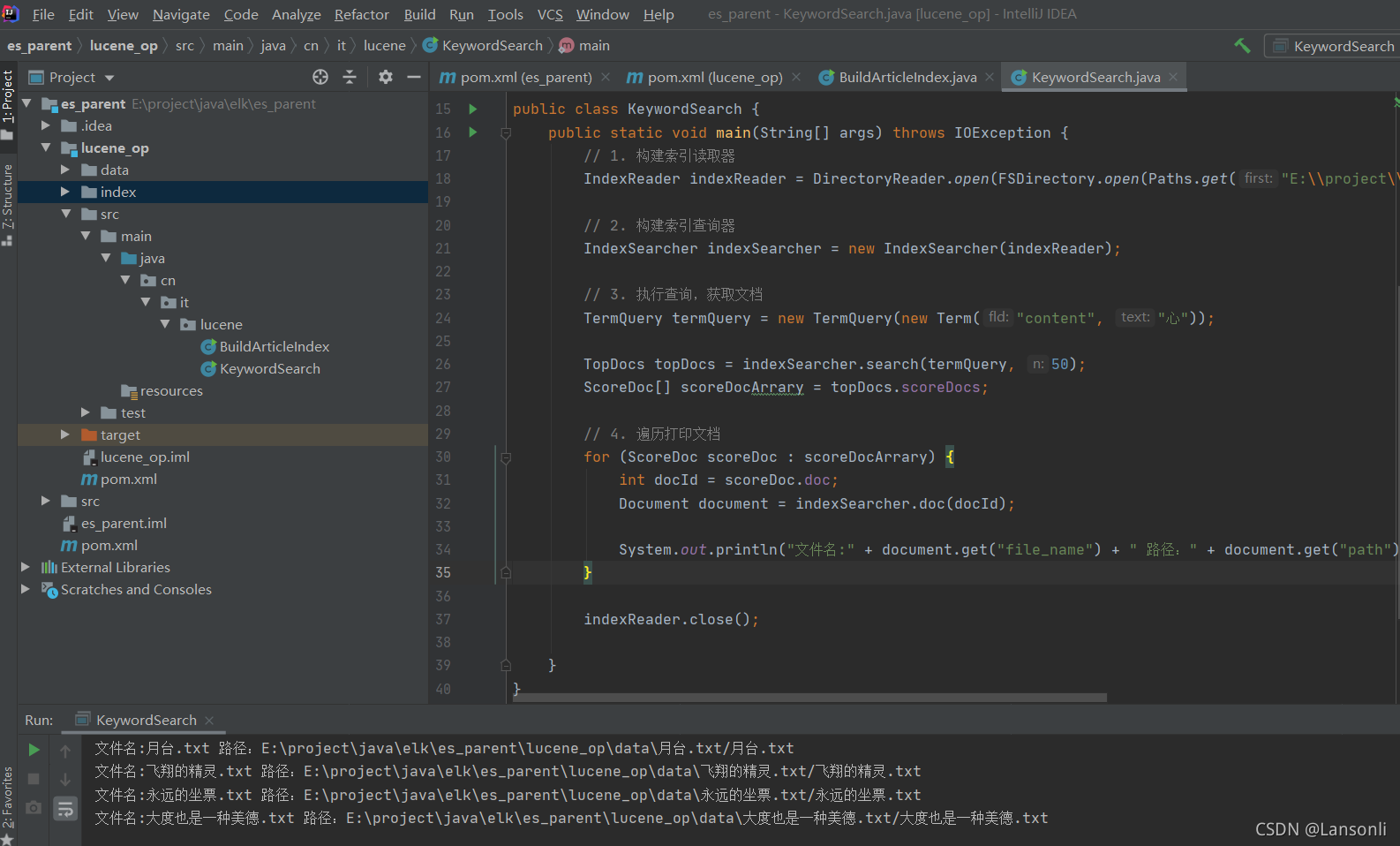
五、搜索词语问题
上述代码,都是一个字一个字的搜索,但如果搜索一个词,例如:“情愿”,我们会发现,我们什么都搜索不出来。所以,接下来,我们还需要来解决搜索一个词的问题。
六、分词器与中文分词器
分词器是指将一段文本,分割成为一个个的词语的动作。例如:按照停用词进行分隔(的、地、啊、吧、标点符号等)。我们之前在代码中使用的分词器是Lucene中自带的分词器。这个分词器对中文很不友好,只是将一个一个字分出来,所以,就会从后出现上面的问题——无法搜索词语。
所以,基于该背景,我们需要使用跟适合中文的分词器。中文分词器也有不少,例如:
- Jieba分词器
- IK分词器
- 庖丁分词器
- Smarkcn分词器
等等。此处,我们使用比较好用的IK分词器来进行分词。
IK已经实现好了Lucene的分词器:https://github.com/wks/ik-analyzer
| IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的 IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IKAnalyzer3.0特性: 采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和最大词长两种切分模式;具有83万字/秒(1600KB/S)的高速处理能力。 采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符 优化的词典存储,更小的内存占用。支持用户词典扩展定义 针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);引入简单搜索表达式,采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。 |
七、使用IK分词器重构案例
1、准备工作
添加Maven依赖
<dependency>
<groupId>com.jianggujin</groupId>
<artifactId>IKAnalyzer-lucene</artifactId>
<version>8.0.0</version>
</dependency>创建BuildArticleIndexByIkAnalyzer类
2、实现步骤
把之前生成的索引文件删除,然后将之前使用的StandardAnalyzer修改为IKAnalyzer。然后重新生成索引。
3、参考代码
package cn.it.lucene;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class BuildArticleIndexByIkAnalyzer {
public static void main(String[] args) throws IOException {
// 1. 构建分词器(StandardAnalyzer)
IKAnalyzer ikAnalyzer = new IKAnalyzer();
// 2. 构建文档写入器配置(IndexWriterConfig)
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(ikAnalyzer);
// 3. 构建文档写入器(IndexWriter)
IndexWriter indexWriter = new IndexWriter(
FSDirectory.open(Paths.get("E:\\project\\java\\elk\\es_parent\\lucene_op\\index")), indexWriterConfig);
// 4. 读取所有文件构建文档
File articleDir = new File("E:\\project\\java\\elk\\es_parent\\lucene_op\\data");
File[] fileList = articleDir.listFiles();
for (File file : fileList) {
// 5. 文档中添加字段
Document docuemnt = new Document();
docuemnt.add(new TextField("file_name", file.getName(), Field.Store.YES));
docuemnt.add(new TextField("content", FileUtils.readFileToString(file, "UTF-8"), Field.Store.NO));
docuemnt.add(new StoredField("path", file.getAbsolutePath() + "/" + file.getName()));
// 6. 写入文档
indexWriter.addDocument(docuemnt);
}
// 7. 关闭写入器
indexWriter.close();
}
}
4、执行效果
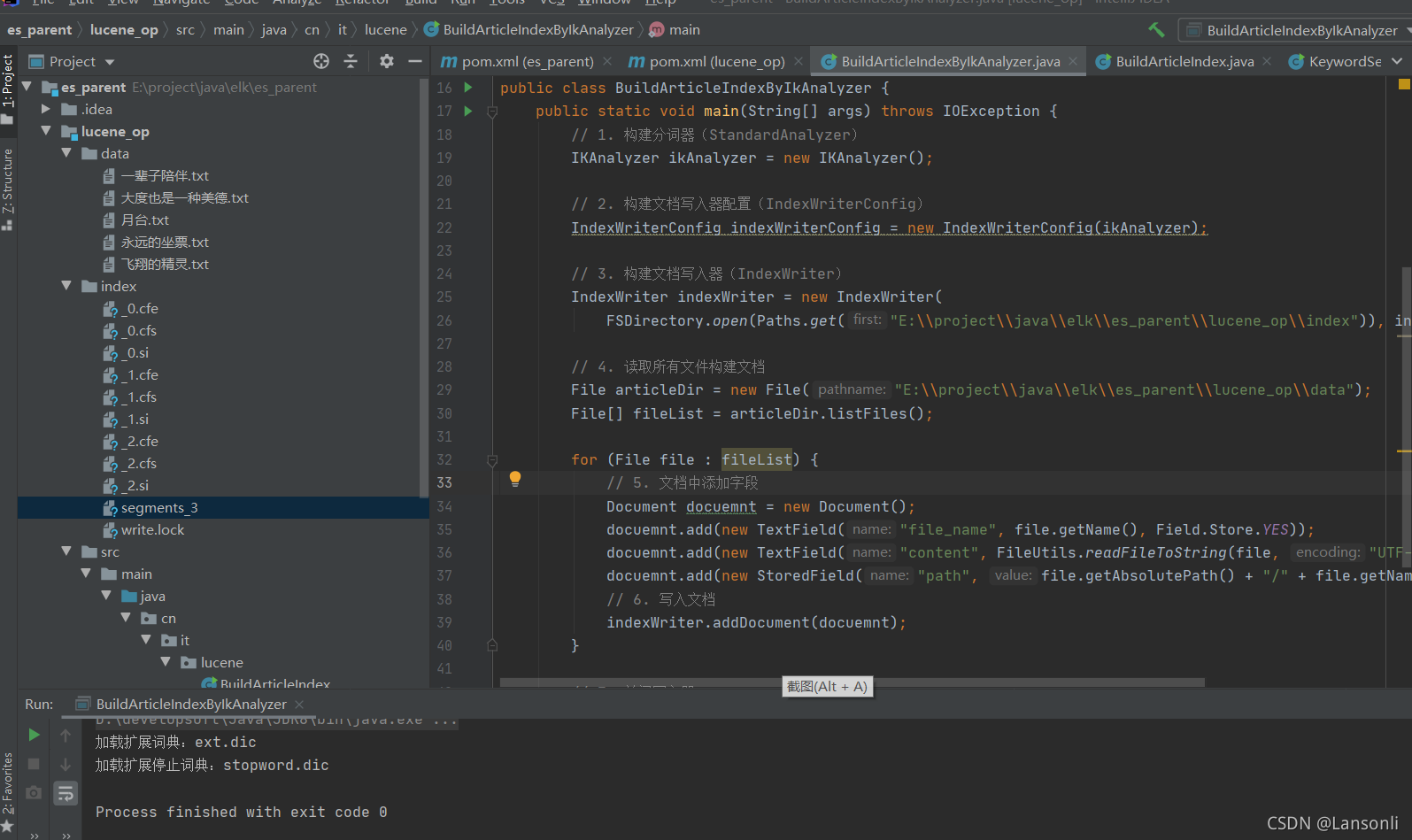
5、问题
通过使用IK分词器进行分词,我们发现,现在我们的程序可以搜索词语了。但如果我们输入一句话:人生是一条河,我们想要搜索出来与其相关的文章。应该如何实现呢?
八、句子搜索
在cn.it.lucene 包下创建一个SentenceSearch类
1、实现步骤
要实现搜索句子,其实是将句子进行分词后,再进行搜索。我们需要使用QueryParser类来实现。通过QueryParser可以指定分词器对要搜索的句子进行分词。
2、参考代码
package cn.it.lucene;
import java.io.IOException;
import java.nio.file.Paths;
import java.text.ParseException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class SentenceSearch {
public static void main(String[] args) throws IOException {
// 1. 构建索引读取器
IndexReader indexReader = DirectoryReader.open(FSDirectory.open(Paths.get("D:\\project\\51.V8.0_NoSQL_MQ\\ElasticStack\\code\\es_parent\\lucene_op\\index")));
// 2. 构建索引查询器
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 3. 执行查询,获取文档
QueryParser queryParser = new QueryParser("content", new IKAnalyzer());
TopDocs topDocs = null;
try {
topDocs = indexSearcher.search(queryParser.parse("人生是一条河"), 50);
} catch (org.apache.lucene.queryparser.classic.ParseException e) {
e.printStackTrace();
}
ScoreDoc[] scoreDocArrary = topDocs.scoreDocs;
// 4. 遍历打印文档
for (ScoreDoc scoreDoc : scoreDocArrary) {
int docId = scoreDoc.doc;
Document document = indexSearcher.doc(docId);
System.out.println("文件名:" + document.get("file_name") + " 路径:" + document.get("path"));
}
indexReader.close();
}
}
3、执行效果

- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨