目录
一、KingbaseES数据库简介:
数据库包括两层概念:
数据库管理系统:
关系型数据库:
二、KingbaseES总体结构:
逻辑功能架构:
架构基础:
三、数据访问:
SQL:
PL/SQL:
四、存储结构:
物理存储结构:
物理存储结构简介:
数据文件:
控制文件:
日志文件:
WAL日志:
逻辑存储结构:
逻辑存储结构概述:
表空间:
数据文件(磁盘管理):
Page/Block(页)
Extent(区)
Global Allocation Map(简称GAM)
Page Free Space(简称PFS)
段(表、索引):
Index Allocation Map(简称IAM)
sys_class.relfilenode
五、事务:
数据库事务:
事务的特性:
原子性(Atomicity):
一致性(Consistency):
隔离性(Isolation):
持久性(Durability):
数据库对事务的管理:
数据的一致性和并发控制
事务的隔离级别:
读已提交 (Read committed)
可串行化 (Serializable)
并发控制的实现
多版本并发控制
六、实例体系结构:
实例结构
数据库文件
KingbaseES 实例
后台进程
服务进程
内存管理
数据页面缓存
日志页面缓存
锁缓存
临时分配的内存
七、后台工作进程:
一、KingbaseES数据库简介:
数据库包括两层概念:
- 数据库是一个实体,它是能够合理的保管数据的“仓库”,用户在仓库中存放需要进行管理的事务数据,"数据"和"库"两个概念结合成为数据库。
- 数据库是数据管理的一种方法和技术,它能更合适地组织数据、更方便地维护数据、更严格的控制数据和更有效的利用数据。
数据库管理系统:
数据库管理系统是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。
关系型数据库:
关系型数据库将复杂的数据结构归结为简单的二元关系(即二维表格形式)。在关系型数据库中,对数据的操作几乎全部建立在一个或者多个关系表格上,通过这些关联的表格分类、合并、连接或选取等运算实现数据的管理。KingbaseES属于典型的商用关系型数据库管理系统。
关系型数据库特点:
关系型数据库在存储数据时实际上是采用一张二维表(类似Word及Excel中表格)。 通过SQL结构化查询语言来存取、管理关系型数据库的数据。 关系型数据库在保持数据安全和数据一致性方面很强,遵循ACID理论。
二、KingbaseES总体结构:
金仓数据库KingbaseES V8R3 的技术架构如下图所示:
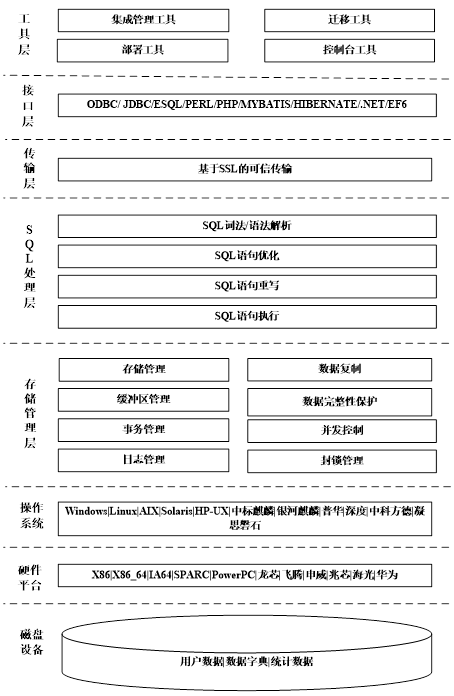
- 存储管理层:主要实现数据存储管理、数据复制、数据完整性保护、封锁、并发控制、事务管理、缓存管理、日志空间管理等;
- SQL处理层:主要负责SQL接口底层(函数、索引、数据字典、存储过程、触发器)的实现、解析、优化、执行和缓存处理等
- 传输层:主要实现基于SSL的可信传输。
SSL(Secure Sockets Layer 安全套接字协议),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层与应用层之间对网络连接进行加密。
- 接口层:提供各种常见数据库访问接口:(ODBC/JDBC/ESQL/PERL/PHP/MYBATIS/HIBERNATE/.NET/EF6)及其驱动程序实现
- 工具层:提供给管理员大量便捷高效的数据库管理工具和开发工具。
KingbaseES 的安全防护手段和策略贯穿以上各个层次,提供特权分立、访问控制、存储加密等多种安全组件和功能,为数据库管理系统提供内核级的层层安全防护。
逻辑功能架构:

架构基础:
在数据库术语里,KingbaseES使用客户端/服务器的模型。一次KingbaseES会话由下列相关的进程组成:
- 服务器进程:
管理数据库文件、接受来自客户端应用与数据库的连接并代表客户端在数据库上执行操作。
- 客户端进程:
客户端应用本身是多种多样的:可以是一个面向文本的工具,也可以是一个图形界面的应用,或是一个通过访问数据库来显示网页的网页服务器,或是一个特制的数据库管理工具。
与典型的客户端/服务器应用(C/S应用)一样,这些客户端和服务器可以运行在不同的主机上,它们通过TCP/IP网络连接通讯。
KingbaseES服务器可以处理来自客户端的多个并发请求。因此,它为每个连接启动一个新的进程。从此时开始,客户端和新服务器进程就不再经过最初的kingbase进程的干涉进行通讯。因此,主服务器进程总是在运行并等待着客户端联接,而客户端和相关联的服务器进程则是起起停停。
三、数据访问:
SQL:
SQL语言是一种非过程化的数据库命令语言,它能使用户方便地操纵关系数据库。目前绝大多数的关系数据库系统都支持它。
作为关系数据库的通用语言,结构化查询语言SQL是操控数据库的基础。几乎所有常见关系数据库管理系统都支持结构化查询语言SQL。用户需要使用SQL语句来访问数据库中的数据并完成数据库各项操作。
PL/SQL:
PL/SQL是一种用于KingbaseES数据库系统的可载入的过程语言,能够使得结构化查询语言SQL更加易用。此外,所有用SQL语句编写的程序都是可移植的。这些程序通常仅需通过很少的修改,便可从一个数据库移植到另一个数据库。
KingbaseES数据库系统提供PL/SQL语言,这种过程化的语言允许用户创建存储过程、用户自定义函数、触发器。
这些过程或用户自定义函数有输入、输出参数和返回值,我们统一把使用PL/SQL语言创建的存储过程、用户自定义函数以及触发器统一称为“存储模块”。存储模块与表和视图等数据库对象一样被存储在数据库中,供用户随时调用。在功能上,相当于客户端的一段SQL批处理程序,它为用户提供了一种高效率的编程手段,成为现代数据库系统的重要特征。
四、存储结构:
KingbaseES的数据存储管理主要完成数据文件空间分配回收、组织和管理等功能。这些管理,是按页面为单位进行的。
在KingbaseES数据库中,数据文件被组织成一个个页面(Page),页面大小为8k。对数据文件的I/O操作都是以页面为单位。
物理存储结构:
物理存储结构简介:
KingbaseES数据库初始化过程会创建一个数据库实例。KingbaseES创建数据库实例时会自动创建数据库:SAMPLES、SECURITY和TEST。每个数据库中可以包含多个数据库对象,如表、索引、序列等。

KingbaseES数据库实例管理的所有数据在物理上都以操作系统文件的方式存放在磁盘上。
物理数据库结构可以在操作系统级别上查看。
RDBMS的一个特点是逻辑数据结构(如表、视图和索引)独立于物理存储结构。
关系数据库管理系统(Relational Database Management System:RDBMS)是指包括相互联系的逻辑组织和存取这些数据的一套程序 (数据库管理系统软件)。关系数据库管理系统就是管理关系数据库,并将数据逻辑组织的系统。
因为物理和逻辑结构是分开的,所以可以在不影响对逻辑结构访问的情况下管理数据的物理存储。例如,重命名数据库文件不会重命名存储在其中的表。一般而言,数据库集簇所使用的配置和数据文件都被一起存储在集簇的数据目录里,常用的目录名为data。由不同数据库实例所管理的多个集簇可以在同一台机器上共存。
data目录包含几个子目录以及一些控制文件,如表"data目录下的内容"所示。除了这些必要的东西之外,kingbase.conf、sys_hba.conf和sys_ident.conf通常都存储在data中,但也可以将其存放在地方。
data目录:
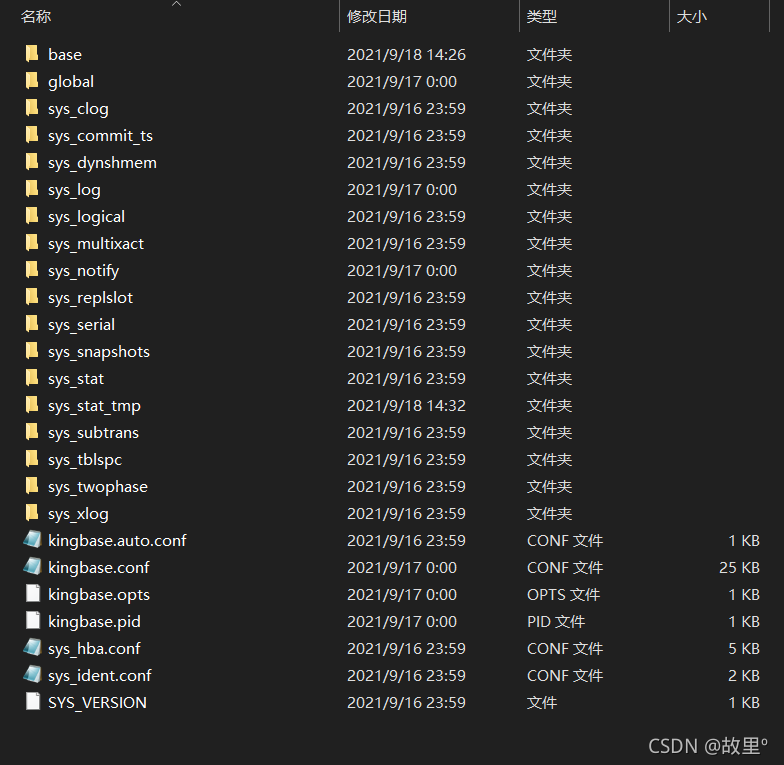
| 文件名 | 描述 |
| SYS_VERSION | 一个包含KingbaseES主版本号的文件 |
| base | 包含每个数据库对应的子目录的子目录 |
| global | 包含集簇范围的表的子目录,比如sys_database |
| sys_commit_ts | 包含事务提交时间戳数据的子目录 |
| sys_clog | 包含事务提交状态数据的子目录 |
| sys_dynshmem | 包含被动态共享内存子系统所使用的文件的子目录 |
| sys_logical | 包含用于逻辑复制的状态数据的子目录 |
| sys_multixact | 包含多事务(multi-t ransaction)状态数据的子目录(用于共享的行锁) |
| sys_notify | 包含LISTEN/NOTIFY状态数据的子目录 |
| sys_replslot | 包含复制槽数据的子目录 |
| sys_serial | 包含已提交的可序列化事务信息的子目录 |
| sys_snapshots | 包含导出的快照的子目录 |
| sys_stat | 包含用于统计子系统的永久文件的子目录 |
| sys_stat_tmp | 包含用于统计信息子系统的临时文件的子目录 |
| sys_subtrans | 包含子事务状态数据的子目录 |
| sys_tblspc | 包含指向表空间的符号链接的子目录 |
| sys_twophase | 包含用于预备事务状态文件的子目录 |
| sys_xlog | 包含 WAL (预写日志)文件的子目录 |
| kingbase.auto.conf | 一个用于存储由ALTER SYSTEM 设置的配置参数的文件 |
| kingbase.opts | 一个 记录服务器最后一次启动时使用的命令行参数的文件 |
| postmaster.pid | 一个锁文件,记录着当前的 kingbase 进程ID(PID)、集簇数据目录路 径、kingbase启动时间戳、端口号、Unix域套接字目 录路径(Windows上为空)、第一个可用的listen_a ddress(IP地址或者*,或者为空表示不在TCP上监听 )以及共享内存段ID(服务器关闭后该文件不存在) |
数据文件:
数据文件包含数据和对象,例如表、索引、存储过程和视图。
控制文件:
KingbaseES主服务器的配置主要通过修改配置文件kingbase.conf完成。配置文件sys_hba.conf和sys_ident.conf主要用于控制客户端认证。
日志文件:
日志文件记录数据库的操作信息。包含恢复数据库中的所有事务所需的信息。
WAL日志:
预写式日志(Write-Ahead Logging(WAL))是保证数据完整性、实现事务日志的一种标准方法。WAL的中心思想是对数据文件的修改(它们是表和索引的载体)当且仅当只能发生在这些修改已经被记录在日志中之后,即在描述这些变化的日志被刷到持久存储以后。如果遵循这种过程,将不需要在每个事务提交时刷写数据页面到磁盘,因为知道在发生崩溃时可以使用日志来恢复数据库:任何还没有被应用到数据页面的改变可以根据其日志记录重做
WAL的优点:
使用WAL显著减少了磁盘写的次数。因为只有日志文件需要被刷出到磁盘以保证事务被提交。而被事务改变的每一个数据文件不必被刷出。日志文件被按照顺序写入,因此同步日志的代价要远小于刷写数据页面的代价。在处理很多影响数据存储不同部分的小事务的服务器上这一点尤其明显。
使用WAL能够保证数据页的完整性。
提供数据库在线备份和恢复的可能。通过归档的WAL文件,可以支持恢复到手头的WAL文件包含的任意时刻:只需要简单地安装以前的数据库的物理备份,然后重放WAl到自己希望的时间。另外,物理备份还不必是数据库状态的一个即时快照--如果它是花了一段时间制作的话,因为WAL日志的重放将修复任何内部的不一致。
WAL配置:
在KingbaseES中,主要通过设置kingbase.conf文件中相关参数来配置WAL。部分WAL相关的参数还会影响数据库的性能,参考服务器配置可获取有关服务器配置的一般信息。
逻辑存储结构:
逻辑存储结构概述:
KingbaseES数据库为数据库中的所有对象分配逻辑空间,并存放在数据文件中。在KingbaseES数据库内部,所有的数据文件组合在一起被划分到一个或者多个表空间中,所有的数据库内部对象都存放在这些表空间中。同时,表空间被进一步划分为段、簇和页(也称块)。通过这种细分,可以使得KingbaseES数据库能够更加高效地控制磁盘空间的利用率。
表空间是数据库的逻辑划分,一个表空间只能属于一个数据库。所有的数据库对象都存放在指定的表空间中。但主要存放的是表,所以称作表空间。
用户可以通过“CREATE TABLESPACE”语句来创建自己的表空间。对已经存在的表空间,用户可以通过“DROP TABLESPACE”语句来将其删除。
表空间:
表空间允许在文件系统里定义那些代表数据库对象的文件存放的位置。 一旦创建了表空间,那么就可以在创建数据库对象的时候引用它。一个数据库可以有一个或多个表空间,创建数据库时自动创建系统表空间,并为缺省的默认表空间。一个表空间只隶属于一个数据库,只有在创建了数据库之后才能创建属于它的表空间。
隶属于一个数据库的表空间用于存储该数据库的数据库对象。在创建数据库对象时可以使用TABLESPACE子句指明该对象所使用的表空间;没有给出 TABLESPACE 子句,则这些对象使用缺省表空间。
KingbaseES中的表空间允许数据库管理员在文件系统中定义用来存放表示数据库对象的文件的位置。一旦被创建,表空间就可以在创建数据库对象时通过名称引用。
通过使用表空间,管理员可以控制一个KingbaseES安装的磁盘布局。这么做至少有两个用处。首先,如果初始化集簇所在的分区或者卷用光了空间,而又不能在逻辑上扩展或者做别的什么操作,那么表空间可以被创建在一个不同的分区上,直到系统可以被重新配置。
其次,表空间允许管理员根据数据库对象的使用模式来优化性能。例如,一个很频繁使用的索引可以被放在非常快并且非常可靠的磁盘上,如一种非常贵的固态设备。同时,一个很少使用的或者对性能要求不高的存储归档数据的表可以存储在一个便宜但比较慢的磁盘系统上。
数据文件(磁盘管理):
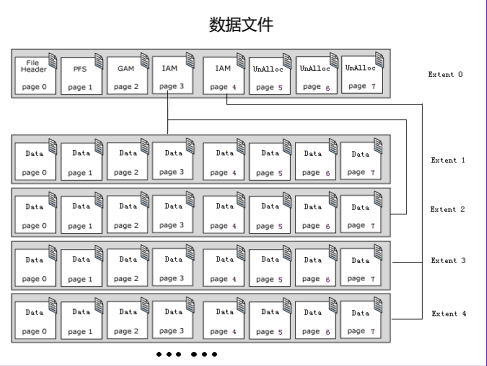
Page/Block(页)
将数据文件中的空间从逻辑上划分成一个个页面(数据块)。页面是数据库I/O的基本单位,即只能整页读写数据文件,页面的大小默认是8K。
Extent(区)
把数据文件中8个连续的Page构成的空间称为一个Extent。Extent是数据库进行数据文件空间分配/释放的基本单位。每个表、索引、序列对象都是由若干个区组成。
Global Allocation Map(简称GAM)
负责记录其所在数据文件的Extent的分配情况。GAM页中除GAM头外,剩下空间的每一位(bit)均对应一个Extent的分配情况。若某bit位为1,则表明该bit位所关联的Extent已被分配,反之未被分配。一个8K大小的GAM页面所能覆盖的文件范围是:(8*1024-64)*(8*8K),约4GB空间。我们约定第一个GAM页出现在文件的第3个页面位置(即:第2个索引位置),因此,第N个GAM页的出现位置是:8*8128*8*N+2
Page Free Space(简称PFS)
用于记录本数据文件中页面的空间使用情况。对文件中的每个页面,PFS中都有一个字节与之对应,该字节记录了该页面的状态。每个页面可能有三种状态:PFS_FREE:该页面已被物理分配,但尚未分配给任何对象或控制页PFS_DATA:该对象被分配作为数据页使用; PFS_CTRL:该对象被分配作为控制页使用。与GAM页类似,PFS页前64bytes被预留位页头,剩下8*1024-64=8128一共覆盖8128*8K=64MB空间。故PFS页每隔8128个页面出现一次,系统初始化把第一个PFS页放在数据文件的第二个页面位置,即:第1号数据页面,由此可知,第N个PFS页的位置在8128*N+1。
段(表、索引):
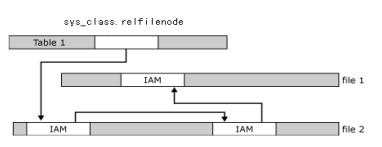
Index Allocation Map(简称IAM)
负责记录分配给其的Extent情况。每个IAM页只隶属于一个数据库对象(例如:表),但一个数据库对象可包含多个IAM页,由此可见IAM页与数据库对象的关系是1对1,而数据库对象与IAM页的关系是1对多.IAM的结构与GAM页类似,除IAM头外,剩下空间的每一位(bit)均对应着一个与IAM相关的Extent。若某bit位为1,则表明该bit位所关联的Extent已被分配给该IAM,反之未被分配。若一个IAM页面大小为8K,则除IAM头(64 bytes)外,一个IAM页面所能覆盖的文件范围是:(8*1024-64)*(8*8K),约4GB空间。但与GAM也不同之处在于:IAM的出现位置不固定,只在在创建数据库对象的时候才分配
sys_class.relfilenode
负责记录隶属于该表/索引的第一个IAM页的地址,从而可以找出隶属于该表/索引的所有页面
五、事务:
数据库事务:
数据库中的事务一个独立的逻辑单元。一个或多个 SQL语句的集合。数据库工作的基本单位是事务,事务是不能被拆分的。一个事务执行的结果只可能有两个:事务内的语句都成功执行,事务执行成功,即事务提交;或事务执行失败,本事务不对数据造成任何影响,即事务回滚。为了更形象的描述事务,举一个简单的例子:银行数据库如何处理客户转账。一个客户有这样的要求:把一笔钱从 A 帐户转到 B 帐户。这个要求可以拆分为三个独立的部分:
-
帐户A划走这笔钱
-
帐户B增加这笔钱
-
记录这笔交易
整个交易过程数据库确保最终达到如下两种状态中的一个:
-
三条语句都成功执行,达到转账目的并且做交易记录。 整个事务提交,数据应用到数据库。
-
其中一条语句执行过程发生错误,比如 A 帐户资金不足,B帐户不存在,或者在整个交易过程中发生硬件故障,数据库停机。 整个事务回滚,执行成功的语句被撤销,执行失败的语句不对数据造成影响,还未执行的语句不再执行。数据回滚到此事务未开始的状态。 无论什么原因,整个业务逻辑不允许出现诸如帐户 A 上的钱被划走,而却没有到达帐户B,或者这个交易没有被记录这样的中间结果,整个交易必须是原子性的,要么整个操作成功,要么整个操作失败。数据库的事务概念正是吻合了此要求。
一条 SQL 语句成功执行标志着:
-
SQL语句被解析,语法正确。
-
SQL语句是有效的,语义正确。
-
一些数据可能被更改,但是这些更改不是永久性的,在此语句所在事务提交前,数据的更改并没有在整个数据库生效。
对于事务的执行结果,只能有提交和回滚。
-
提交操作意味着:事务内的语句对数据的改变被数据库接受。这将造成数据对于整个数据库发生永久性的改变。
-
回滚操作意味着:这个事务内所有对数据造成的更改全部被撤销。
一条 SQL 语句执行失败会回滚整个事务。
事务的特性:
为了保证数据库中的数据一致性,确保KingbaseES 能够在并发访问和系统发生故障时对数据进行维护,事务作为数据库工作的基本单位,具有下列四个特性,称为事务的 ACID 特性。
原子性(Atomicity):
一个事务对数据库的所有操作,是一个不可分割的工作单元。这些操作要么全部执行,要么什么也不做。
一致性(Consistency):
一个事务独立执行的结果应保持数据库的一致性,即数据不会因为事务的执行而遭受破坏。例如事务的概念里银行转账的例子,保证了数据的一致性。
隔离性(Isolation):
在多个事务并发执行时,系统应保证与这些事务先后单独执行时的结果一样,此时称事务达到了隔离性的要求,也就是在多个并发事务执行时,保证执行结果是正确的,如同单用户环境一样。隔离性是由KingbaseES 的并发控制子系统实现的。
持久性(Durability):
一个事务一旦完成全部操作后,它对数据库的所有更新应永久地反映在数据库中。即使以后系统发生故障,也应保留这个事务执行的痕迹。事务的持久性由 KingbaseES 的恢复管理子系统实现。
事务是恢复和并发控制的基本单位。KingbaseES 能够保证事务的 ACID 特性不被破坏,分为以下几种情况:
-
多个事务并发运行时,不同事务的操作交叉执行。KingbaseES保证多个事务的交叉运行不影响这些事务的原子性。
-
事务在运行过程中被强行终止。KingbaseES保证被强行终止的事务对数据库和其他事务没有任何影响。
数据库对事务的管理:
对于事务的管理,KingbaseES 支持事务的隐式和显式提交,即自动提交和非自动提交。
自动提交事务
默认一个 SQL 语句为一个事务,当此语句执行成功后,由系统隐式提交。数据更改被数据库接受。当 SQL 执行失败,自然视做回滚,不对数据造成影响。 KingbaseES 默认提交事务方式为自动提交。
非自动提交事务
事务的开始为第一个 SQL 语句。事务的结束必须用户显式的使用 COMMIT 语句提交整个事务或者使用 ROLLBACK 语句回滚整个事务。如果客户端连接断开,那么未提交的事务做回滚操作。 当用户想自己控制事务的执行,可以显式的用 BEGIN 语句开始一个事务,然后在事务结束时应该使用 COMMIT 或 ROLLBACK 语句显式提交。
接口中也有对事务提交方式的控制,配置相应的配置文件可以使会话处于自动提交或非自动提交模式。
一个事务的提交和回滚对数据库实例造成的影响为:
一个事务提交对数据库实例造成如下影响:
所有数据库更改对整个数据库生效。
保证此事务产生的日志写到磁盘。
释放所有此事务进行过程中申请的锁。
数据库标记此事务结束。
一个事务回滚对数据库实例造成如下影响:
撤销所有对数据的更改到此事务开始之前的状态。
释放所有此事务进行过程中申请的锁。
数据库标记此事务结束。
数据的一致性和并发控制
在实际应用中数据库资源对用户是共享的,不同的用户在不同或相同的时刻使用数据库,这就是数据库的并发操作。在多用户数据库环境中,并发操作提高了数据库资源的使用效率,但若对这种并发操作不加限制就会破坏数据的完整性和一致性问题。
由于数据库工作的基本单位是事务,针对事务并发操作中的各类问题,SQL 标准提出了事务的隔离级别概念。
事务的隔离级别:
并发操作虽然可以改善系统的资源利用率和短事务的响应时间,但是在运行中必须对并发事务加以控制,否则会引发一些问题,SQL92 标准对这些情况进行了分类,以及提出了解决办法。
由于一个事务可能包含多个 SQL 语句,SQL 语句是顺序执行的。T1 和 T2 两个事务在一个数据库上并发执行,可能有如下类型的问题:
读“脏”数据(Dirty Read)
事务 T1 更新了一个数据,并且在 T1 提交或者回滚前,另外一个事务T2读取了那个数据。如果 T1 这个时候回滚,那么T2就读取了一个未提交的虚假的值,即“脏”数据。
不可重复读(Non-Repeatable 或 Fuzzy Read)
事务 T1 读取了一个数据。这个时候另外一个事务 T2 修改或者删除了这个数据并且提交了。如果 T1 尝试再读取一次这个数据,就会发现再次读到的数据与之前不一致或不存在。
幻象读(Phantom Read)
事务 T1 读取了若干个满足某个查询条件的数据。这个时候事务 T2 创建了一个数据恰好也满足 T1 的这个查询条件。如果这个时候 T1 再次根据这个查询条件进行读取,它会发现会多出了部分数据。
很显然,高并发度带来了数据的不一致,这些情况一些是用户不愿意见到,一些则是无法接受的。用户需要在高并发带来的高性能和数据的一致性之间做取舍。SQL92 标准提出了事务隔离级别,来解决上面的问题。
| 隔离级别 | 读脏数据 | 不可重复读 | 读幻象数据 |
|---|---|---|---|
| 读未提交(Read uncommitted) | 可能 | 可能 | 可能 |
| 读已提交(Read committed) | 不可能 | 可能 | 可能 |
| 可重复的读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
四个隔离级别从上到下对事务执行的并发程度进行了不同程度的限制,更加严格的限制在带来更好的数据一致性的同时,也会损失更多并发带来的高性能。
实际使用中,隔离级别并不是越高就越好,大多数情况下应用并不需要很高的数据一致性。相反的,在多用户环境下,更强调的是并发度。所以综合考虑选取一个折中的办法往往能达到最优的效果。
KingbaseES向用户提供两种隔离级别:读已提交(Read committed)和可串行化(Serializable)。这一点与 Oracle 一致。
读已提交 (Read committed)
READ COMMITTED 是 KingbaseES 默认的事务隔离级别。在运行在该隔离级别的事务中,查询语句只能看到该查询开始执行之前提交的数据,而不会看到任何未提交的数据或查询执行期间并发的其它事务提交的数据,但是该查询可以看到本事务中查询之前执行的数据更新。 在 READ COMMITTED 隔离级别下,对于事务 T1 中的更新和删除语句,与查询语句相同,只能看到语句开始执行时提交的数据行,但是,这些数据行可能已经被同时并发的另一个事务 B 更新,在这种情况下,事务 T1 将等待事务 T2 回滚或提交。如果事务 T2 回滚,则事务 T1 在原来的数据上继续更新,如果事务 T2 提交了,将分两种情况,1):如果事务 T2 删除了该行,则事务 T1 忽略该行,2):如果事务 T2 对该行进行了更新,则事务 T1 判断该行的新值是否还满足条件,如果满足条件,则事务 T1 在新数据行上进行更新,如果不满足条件,则忽略该行。 在 READ COMMITTED 隔离级别下,同一个事务的不同查询看到的可能是不同的数据,因此会出现不可重复读的问题。这种隔离级别对于大多数的应用已经能够满足要求,但有些应用需要提供更加严格的数据一致性。 为了避免同样的查询得到不同的结果,在 READ COMMITTED 隔离级别下,应用程序在同一事务内应该尽量避免重复的查询。
可串行化 (Serializable)
SERIALIZABLE 提供了更加严格的事务隔离级别,在该事务隔离级别下,事务并发执行,其结果与某个串行执行顺序的结果完全相同。 在运行在 SERIALIZABLE 隔离级别的事务中,查询语句只能看到该事务开始执行之前已经提交的数据,而不会看到任何未提交的数据或事务执行期间,并发的其它事务提交的数据,但是该查询可以看到本事务中查询之前执行的数据更新。 在 SERIALIZABLE 隔离级别下,对于事务 T1 中更新和删除语句,与查询语句相同,只能看到事务开始执行时提交的数据行,但是,这些数据行可能已经被同时并发的另一个事务 T2 更新(事务 T2 开始的时间在事务 T1 前),在这种情况下,事务 T1 将等待事务 T2 回滚或提交。如果事务 T2 回滚,则事务 T1 在原来的数据上继续更新,如果事务 T2 提交了,则事务 T1 就会出错回滚,因为一个串行事务不能修改在该事务开始后被其它事务修改的数据。 SERIALIZABLE 隔离级别可以确保每个事务看到一个完全一致的数据,但是当出现并发更新时,后更新的事务必须回滚,只能在之前的更新提交后再重新执行。 在 SERIALIZABLE 隔离级别下,应用程序如果碰到更新语句回滚,应该重执行更新语句所在的整个事务。
有关事务隔离级别的设置请参见 SET TRANSACTION 语法描述。 KingbaseES还提供参数 deadlock_timeout 来设置等锁的时间,解决事务并发操作长期进行锁等待的问题。
并发控制的实现
KingbaseES在多用户环境的并发访问,是通过多版本并发控制和封锁机制共同实现的。
多版本并发控制
多版本并发控制,即 MVCC(Multi-version concurrency control)。对于表里的某个一行 R,多版本并发控制通过每个写 R 的操作建立 R 的一个新版本,当执行一个读 R 的操作时,针对操作所在的事务,系统选择 R 的一个正确版本来进行操作。多版本并发控制的一个显著好处是读操作和写操作并不互斥。例如:如果用户 A 希望读取表 T 上的所有数据,而此时用户 B 正在更新表 T 上的某行数据 r。对于多版本并发控制系统,B 用户的更新操作对于 r 生成新的版本r(i)进行修改,而不是直接修改修改数据。用户 A 读操作同样获取一个版本的数据r(j)。所以利用区分版本的方式,用户 A 不必等待 B 的完成。 这里的版本概念也称作快照(snapshot)。一个快照就是在某个时刻的数据库映像。比如,当事务开始时,系统为对应的时间点的数据生成一个快照。在这个快照中包含的数据十分关键,可能包含了那个时刻未提交的事务所产生的数据,还可能包含了那个时刻已经提交的事务产生的数据。换句话说一些数据在这个快照中是可见的,另一些是不可见的。毫无疑问,这影响到了数据的一致性。 可以用快照对数据的可见性,定义数据库的隔离级别。
读已提交 (Read committed)
当一个事务隔离级别为读已提交时,在事务里每个 SQL 语句开始时,按规则生成一个快照,对于还没有提交的数据,认为不可见,否则可见。
可串行化 (Serializable)
当一个事务隔离级别为可串行化时,事务开始时生成一个快照,如果在这个事务开始时还没有提交的数据,认为它们不可见,否则可见。 多版本控制带来的巨大好处是最大可能的支持并发的查询操作,即使修改数据时也不会阻塞读。
5.5.2.2. 封锁
除了多版本并发控制,封锁机制也是实现并发访问的必不可少的手段。 KingbaseES使用锁控制用户对数据库对象,包括:表、页面、元组、事务、非表对象(函数,触发器等)的并发访问。
| 编号 | 锁 模式(LOCKMODE) | 对应操作 | 与之冲突的模式 |
|---|---|---|---|
| 1 | AccessShareLock | SELECT | 8 |
| 2 | RowShareLock | SELECT FOR UPDATE | 7,8 |
| 3 | RowExclusiveLock | INSERT, UPDATE, DELETE | 5,6,7,8 |
| 4 | ShareUp dateExclusiveLock | VACUUM | 4,5,6,7,8 |
| 5 | ShareLock | CREATE INDEX | 3,4,6,7,8 |
| 6 | Shar eRowExclusiveLock | like ExclusiveLock, but allows ROW SHARE | 3,4,5,6,7,8 |
| 7 | ExclusiveLock | blocks ROW SHARE | 2,3,4,5,6,7,8 |
| 8 | Ac cessExclusiveLock | DROP TABLE, ALTER TABLE | 全部 |
如果一个对象被加上了一种模式的锁,那么其他用户如果想加上和此模式相冲突的锁,就会发生冲突。这个用户必须等待,直到加上的锁被释放。
KingbaseES 支持用户手动对表加锁,详细信息请查看 LOCK 语法描述。
两到多个事务相互争用资源时,可能发生死锁。KingbaseES 支持自动检测死锁,并且自动处理。
例如:事务 T1 已经获得表 A 上的排它锁(如成功更新表 A 上的列 a:update A set a = 1;),事务T2 已经获得表 B 上的排它锁(如成功更新表 B 行的列 a:update B set a = 1;),现在 T1 申请表 B 上的排它锁(如尝试更新表 B 上的列 a:update B set a = 1;),由于冲突,发生锁等待,这时 T2 申请表 A 上的排它锁(如尝试更新表 A 上的列 a:update A set a = 1;),也冲突,形成死锁。这时 KingbaseES 检测到 T1 和 T2 发生死锁,强制回滚 T2 ,解决死锁。
六、实例体系结构:
实例结构
KingbaseES 数据库管理系统,由数据库文件和KingbaseES实例组成。
数据库文件
数据库文件为存储用户数据以及元数据的一组磁盘文件。 元数据为描述数据库结构、配置和控制有关的信息。
KingbaseES 实例
包含若干对存储的数据进行操作的数据库服务进程,还包括分配和管理内存,统计各种信息,以及实现各种协调工作的后台进程。一台设备上,可以同时运行多个实例。 实例注册成实例服务后,会有唯一的名字标志一个实例。 一个 KingbaseES 实例在操作系统上表现为一个 KingbaseES 进程,它可以由控制器启动,也可以单独用命令行启动。 一个 KingbaseES 实例管理多个逻辑上的数据库。启动一个 KingbaseES 实例后,使用客户端可以访问到这个实例管理的任意一个数据库。
KingbaseES 实例的结构以及和数据库文件的关系可以表示为:
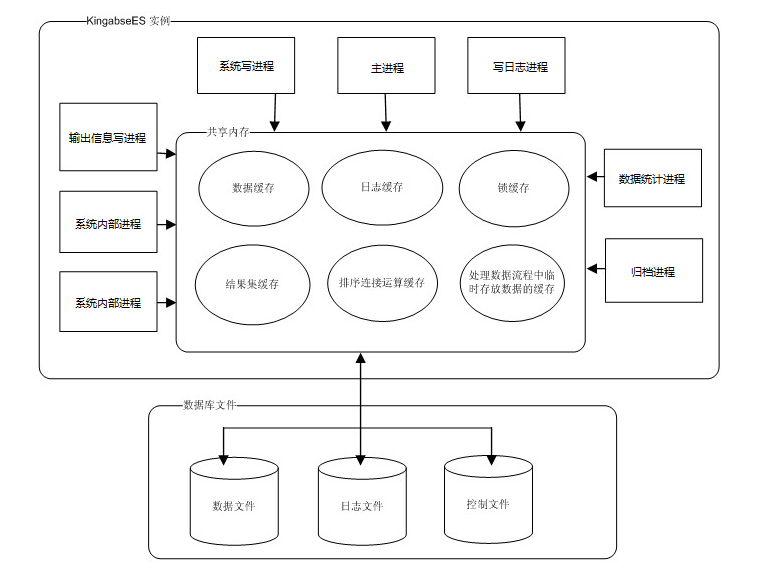
图 6.1.15 KingbaseES 实例和数据库文件
以下是 KingbaseES 实例的详细介绍。
数据库服务进程是多进程结构
KingbaseES 数据库服务进程,称该进程为一个“KingbaseES 数据库实例”。 在一个数据目录只能同时启动一个实例,不同的数据目录可以同时以不同的端口,手动启动为不同的实例。
KingbaseES实例采用多进程架构,因此一个实例中会包含多个进程。这些进程按照功能的不同可以分为后台进程和服务进程两类:
后台进程
KingbaseES 主进程
主进程负责统一管理各服务进程和其他后台进程。 该进程负责启动服务进程和其他后台进程,并且在子进程退出的时候做清理工作。 该进程负责分发来自操作系统的信号到各子进程。系统退出时,主进程负责发送信号通知各子进程退出,然后再停止自己。
后台写进程
在这个进程中,共享缓冲池上的脏页会逐渐定期地写入持久存储(例如HDD、SSD)。
检查点进程
用来执行检查点过程。
自动vacuum进程
会定期地在服务器上执行vacuum。
WAL日志写进程
这个进程周期性地将WAL缓冲区上的WAL数据写入和刷新到持久存储。
统计进程
在此进程中,会收集sys_stat_activity和sys_stat_database等统计信息。
日志写进程
写日志线程负责将日志缓冲区中的日志页面写出到日志文件中。
归档进程
归档进程负责将日志文件归档到指定的位置。
服务进程
KingbaseES 用服务进程来处理连接到数据库服务的客户端请求。 对于每个客户端的连接,KingbaseES主进程接收到客户端连接后,会为其创建一个新的服务进程。 该进程负责实际处理客户端的数据库请求,连接断开时退出。
内存管理
KingbaseES 统一管理实例所用的内存资源。配置参数 shared_buffers 决定了数据库实例使用多少内存。当系统启动时,数据库实例向操作系统申请一块大内存(大小由 shared_buffers 决定)作为共享内存。在这之后各个进程对内存资源的使用都在这块内存里操作。
KingbaseES 对于共享内存的使用主要可以分为以下几部分:
数据页面缓存
在内存里缓存数据页面,shared_buffers 越大,在内存里保存的数据页面就越多。相同条件下操作数据时进行的 IO 操作更少。
日志页面缓存
日志缓冲区,操作数据时产生的日志都放在这个缓冲区上,由写日志线程和服务线程刷到磁盘。 参数 wal_buffers 设置日志页面缓存大小。
排序和连接运算使用的缓存
服务器对元组进行排序或者连接运算时,需要用到内存缓存数据。如果所需的运算还需更大的空间,KingbaseES 会借助于临时文件完成。 参数 work_mem 设置每个服务进程排序和连接运算使用的缓存大小。
锁缓存
多线程并发操作会用到锁,KingbaseES 从共享内存开辟独立的内存空间用于存放锁信息。 锁缓存的大小由总的共享内存大小决定。
临时分配的内存
服务器在处理数据流程中,用于临时存放数据所使用的内存,也从共享内存里分配。 KingbaseES 对于共享内存的使用通常是可配置的,详细信息请参考 内存。
七、后台工作进程:
KingbaseES可以被扩展用来在独立进程中运行用户提供的代码。
此进程将被kingbase启动、停止和监控,这使它们的生命期与服务器的状态紧密联系。这些进程具有选项可以挂接上KingbaseES的共享内存区域,并且可以从内部连接到数据库。它们也可以连续地运行多个事务,就像一个正常的被客户端连接的服务器进程。同样,通过链接到libkci,它们可以连接到服务器并像一个正常客户端应用工作。
通过将模块名放在shared_preload_libraries中,可以在KingbaseES被启动时初始化后台工作者。
一个希望运行后台工作者的模块需要通过在其_SYS_init()中调用RegisterBackgroundWorker(BackgroundWorker *worker)来注册它。
也可以在系统启动后通过调用函数RegisterDynamicBackgroundWorker(BackgroundWorker *worker, BackgroundWorkerHandle **handle)来启动后台工作者。
与只能在kingbase内调用的RegisterBackgroundWorker不同,必须从一个常规后端调用RegisterDynamicBackgroundWorker。
typedef void (*bgworker_main_type)(Datum main_arg);
typedef struct BackgroundWorker
{
char bgw_name[BGW_MAXLEN];
char bgw_type[BGW_MAXLEN];
int bgw_flags;
BgWorkerStartTime bgw_start_time;
int bgw_restart_time; /* in seconds, or BGW_NEVER_RESTART */
char bgw_library_name[BGW_MAXLEN];
char bgw_function_name[BGW_MAXLEN];
Datum bgw_main_arg;
char bgw_extra[BGW_EXTRALEN];
int bgw_notify_pid;
} BackgroundWorker;| 参数 | 描述 |
|---|---|
| bgw_name 和 bgw_type | bgw_name和bgw_type是要被用在日志消息、进程列表和类似环境中的字符串。 对于同种类型的所有后台工作者,bgw_type应该相同,这样才可能将进程列表 中的这些工作组分组。另一方面,bgw_name可以包含有关特定进程的额外信息 (通常,bgw_name中的字符串在某种程度上也会包含类型,但没有严格要求)。 |
| bgw_flags | 一个按位与的位掩码,用于指示模块想要的能力。可能的值是: |
| BGWORKER _SHMEM _ACCESS | 请求共享内存访问。没有共享内存使用权的工作者不能访问任何的KingbaseES 共享数据结构,例如重量级或者轻量级锁、共享缓冲区以及该工作者本身想要创 建和使用的任何自定义数据结构。 |
| BGWORKER _BACKEND _DATABASE _CONNE CTION | 请求建立数据库连接的能力,这样它后面可以通过建立起的连接运行事务和查询。 一个使用BGWORKER_BACKEND_DATABASE_CONNECTION来连接一个数据库 的后台工作者也必须使用BGWORKER_SHMEM_ACCESS挂接到共享内存,否则工作 者启动将会失败。 |
| bgw_start _time | 服务器状态,在该状态中kingbase会启动该进程,它可以是 BgWorkerStart_KingbaseStart(在kingbase本身完成初始化之后立即启动, 这种进程不能使用数据库连接)、BgWorkerStart_ConsistentState(当一个 热后备中达到一个一致性状态之后立即启动,允许进程连接到数据库并运行只读查 询)和BgWorkerStart_RecoveryFinished(在系统进入到正常读写状态后立即 启动)之一。注意后两种值在服务器不是一个热后备的情况下是等同的。注意这种 设置仅仅表示何时启动进程,当一个不同状态到达时它们不会停止。 |
| bgw_restart _time | 是在崩溃情况下kingbase启动进程之前等待的时间间隔,以秒计。它可以是任何 正值,或者BGW_NEVER_RESTART,表示在出现崩溃后不重启进程。 |
| bgw_library _name | 是应该在其中定位后台工作者初始入口点的库名称。所指的库将被工作者进程动态 载入并且bgw_function_name将被用来标识要调用的函数。如果从核心代码载入 一个函数,必须被设置为"kingbase"。 |
| bgw_func tion_name | 一个动态载入库中的一个函数名,该函数将被用作一个新后台工作者的初始入口点。 |
| bgw_main _arg | 后台工作者主函数的Datum参数。这个主函数应该有一个单一的Datum类型的参数, 并且返回void。bgw_main_arg将被作为参数传递。此外,全局变量 MyBgworkerEntry指向注册时传入的BackgroundWorker结构的一份拷贝,工作者 会发现检查这个结构会很有用。 |
| bgw_extra | 可以包含要传递给后台工作者的额外数据。与bgw_main_arg不同,这个数据 不会被作为一个参数传递给工作者的主函数,而是按照上面所述通过MyBgworkerEntry 来访问。 |
| bgw_notify _pid | 一个KingbaseES后端进程的PID,当后台工作者进程启动或者退出时,kingbase 会向这个PID所指的进程发送SIGUSR1。对于在kingbase启动时注册的工作者,它应 该为0;或者注册该工作者的后端不希望等待该工作者启动时,它也应该为0。否则, 它应该被初始化为MyProcPid。 |
运行起来后,进程可以通过调用BackgroundWorkerInitializeConnection(char *dbname, char *username)或者BackgroundWorkerInitializeConnectionByOid(Oid dboid, Oid useroid)来连接数据库。这使得该进程可以使用SPI接口运行事务和查询。
如果dbname为NULL或者dboid为InvalidOid,该会话没有连接到任何特定数据库,但共享的目录可以被访问。
如果username为NULL或者useroid为InvalidOid,该进程将以在initdb阶段创建的数据库管理员账号运行。
如果BGWORKER_BYPASS_ALLOWCONN被指定为flags,可以绕过该限制连接不允许用户连接的数据库。在每一个后台进程中,只能调用两者之一,并且只能调用一次,所以不可能切换数据库。
当控制到达后台工作者的主函数时,信号初始会被阻塞,并且必须被它解除阻塞。这是为了允许进程自定义它的信号处理器。在新进程中可以通过调用BackgroundWorkerUnblockSignals来解除对信号的阻塞,还可以通过调用BackgroundWorkerBlockSignals来阻塞信号。
如果一个后台工作者的bgw_restart_time被配置为BGW_NEVER_RESTART,或者它退出时的退出码为0,又或者它是被TerminateBackgroundWorker所终止,它将会被kingbase在退出时自动解除注册。否则,它将在等待通过bgw_restart_time配置的时间段之后被重新启动,或者在kingbase因为一次后端失败重新初始化集簇时立刻被重启。需要临时禁止执行的后端应该使用可中断的休眠而不是退出,这可以通过调用WaitLatch()实现。调用该函数时要确保WL_POSTMASTER_DEATH标志被设置,并且验证在kingbase本身被终止的紧急情况下产生的快速退出返回码。
当一个后台工作者通过RegisterDynamicBackgroundWorker函数注册时,后端可以执行该注册以获得有关该工作者的状态信息。希望这样做的后端应该把一个BackgroundWorkerHandle *的地址作为第二个参数传递给RegisterDynamicBackgroundWorker。如果工作者被成功地注册,这个指针将被用一个非透明句柄初始化,它之后会被传递给GetBackgroundWorkerPid(BackgroundWorkerHandle *,pid_t *)或者TerminateBackgroundWorker(BackgroundWorkerHandle *)。GetBackgroundWorkerPid可以被用来测试工作者的状态:返回值为BGWH_NOT_YET_STARTED表示该工作者还未被kingbase启动;BGWH_STOPPED表示它已经被启动但是不再运行;而BGWH_STARTED表示它正在运行。在最后一种情况下,PID也将被通过第二个参数返回。TerminateBackgroundWorker导致kingbase发送SIGTERM给工作者(如果它在运行),并且在它不再运行时尽快解除注册。
在某些情况下,一个注册后台工作者的进程可能希望等待该工作者启动起来。实现方式是:将bgw_notify_pid初始化成MyProcPid并且接着把注册时得到的BackgroundWorkerHandle *传递给WaitForBackgroundWorkerStartup(BackgroundWorkerHandle *handle,pid_t *)函数。这个函数将阻塞直到kingbase已经尝试启动该后台工作者,或者直到kingbase死亡。如果后台工作者正在运行,返回值将是BGWH_STARTED,并且其PID将被写入到所提供的地址。否则,返回值将是BGWH_STOPPED或者BGWH_POSTMASTER_DIED。
进程也可以等待一个后台工作者关闭,方法是使用WaitForBackgroundWorkerShutdown(BackgroundWorkerHandle *handle)函数并且传入注册时得到的BackgroundWorkerHandle *。这个函数将阻塞直至后台工作者退出或者kingbase死掉。当后台工作者退出时,返回值是BGWH_STOPPED,如果kingbase死掉则会返回BGWH_POSTMASTER_DIED。
如果一个后台工作者通过服务器编程接口(SPI)用NOTIFY命令发送异步通知,在提交外层事务之后它应该显式地调用ProcessCompletedNotifies,这样通知才能被发送出去。如果一个后台工作者通过SPI使用LISTEN注册为接收异步通知,它将记录那些通知,但是对于工作者来说没有程序化的方式可以拦截以及响应那些通知。
src/test/modules/worker_spi模块包含了一个实例,它展示了一些有用的技巧。
注册的后台工作者的最大数量由max_worker_processes限制。
【本文正在参与炫“库”行动-人大金仓征文大赛】
CSDN![]() https://marketing.csdn.net/p/98bd30353e7cb998b6070a89e8b91edb
https://marketing.csdn.net/p/98bd30353e7cb998b6070a89e8b91edb