1.2.1 变量、行、缩进与注释
1.2.2 数据类型-数字与字符串
1.2.3 列表与字典
1.2.4 运算符介绍与实践
1.3.1 if语句
1.3.2 for语句
1.3.3 while语句
1.3.4 try except异常处理语句
1.4.1函数的定义与调用
1.4.2 函数返回值、作用域
1.4.3 一些重要的基本函数介绍
1.4.4 Python库与模块介绍
2.2.1 我的第一个网页
2.2.3 逐渐完善的网页
2.3.1 获取百度新闻网页源代码
2.4.1 正则表达式之findall
2.4.2 正则表达式之非贪婪匹配1
2.4.3 正则表达式之非贪婪匹配2
2.4.4 正则表达式之换行
2.4.5 正则表达式之小知识点补充
1.2.1 变量、行、缩进与注释
# =============================================================================
# 1.2.1 变量、行、缩进与注释
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融基础 获取源代码
# 1 变量
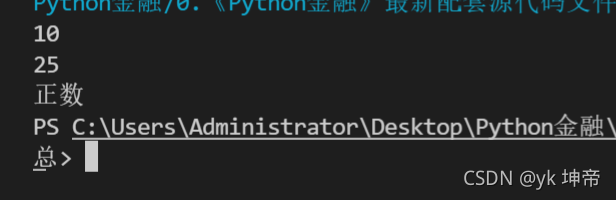
x = 10
print(x)
x = x + 15
print(x)
# 2 行
# 代码都是一行一行写的
# 3 缩进,先不用管这个什么意思,之后会讲,只要知道在if和else后面那个语句要有个缩进,按Tab键快速缩进
x = 10
if x > 0:
print('正数')
else:
print('负数')
# 4 注释
'''
两种注释的方法:
1.#后的内容是注释的内容,# 是shift + 3按出来的
2.三个单引号左右包着
'''
# 这之后是注释内容,快捷键在pycharm里是ctrl + /,在spyder里是ctrl + 1
'''这里面是注释内容'''
1.2.2 数据类型-数字与字符串
# =============================================================================
# 1.2.2 数据类型-数字与字符串
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融基础 获取源代码
# 不同类型的数据不可以相加,下面的内容会报错,我把它注释掉了
# a = 1 + '1'
# print(a)
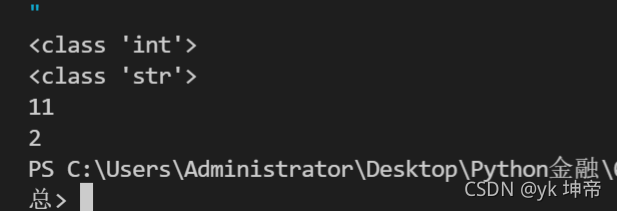
a = 1
print(type(a))
a = '1'
print(type(a))
# 将数字转换成字符串
a = 1
b = str(a) # 将数字转换成字符串,并赋值给变量b
c = b + '1'
print(c)
# 将字符串转换成数字
a = '1'
b = int(a) # 将字符串转换成数字,并赋值给变量b
c = b + 1
print(c)
1.2.3 列表与字典
# =============================================================================
# 1.2.3 列表与字典
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融基础 获取源代码
# # 列表
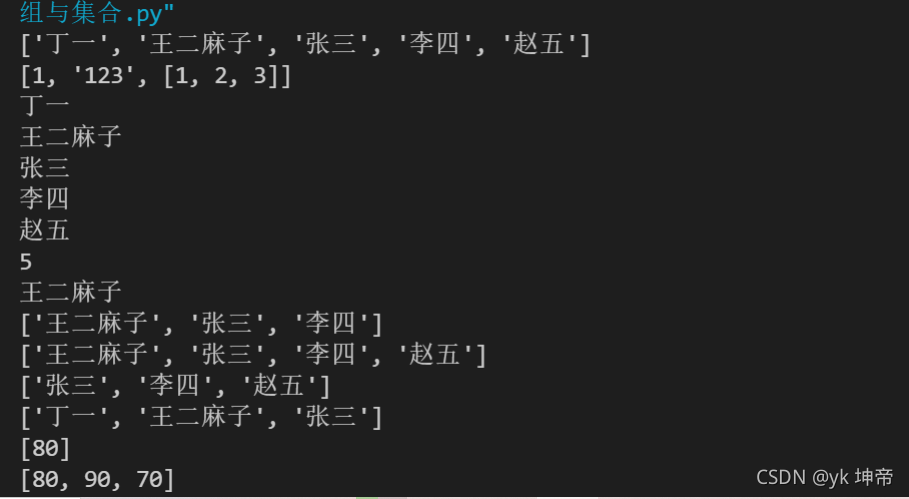
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
print(class1)
list1 = [1, '123', [1, 2, 3]]
print(list1)
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
for i in class1: # 这个for语句之后会重点讲,这边大家先运行看看效果即可
print(i)
# 统计列表的元素个数的函数:len函数
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
a = len(class1)
print(a)
# 调取一个列表元素的方法
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
a = class1[1]
print(a)
# 选取多个列表元素的方法:列表切片
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
a = class1[1:4]
print(a)
b = class1[1:] # 选取从第二个元素到最后
c = class1[-3:] # 选取从列表倒数第三个元素到最后
d = class1[:-2] # 选取倒数第二个元素前的所有元素(因为左闭右开,所以不包含倒数第二个元素)
print(b)
print(c)
print(d)
# 列表增加元素的办法:append方法,这个先了解下即可
score = []
score.append(80)
print(score)
score = []
score.append(80)
score.append(90)
score.append(70)
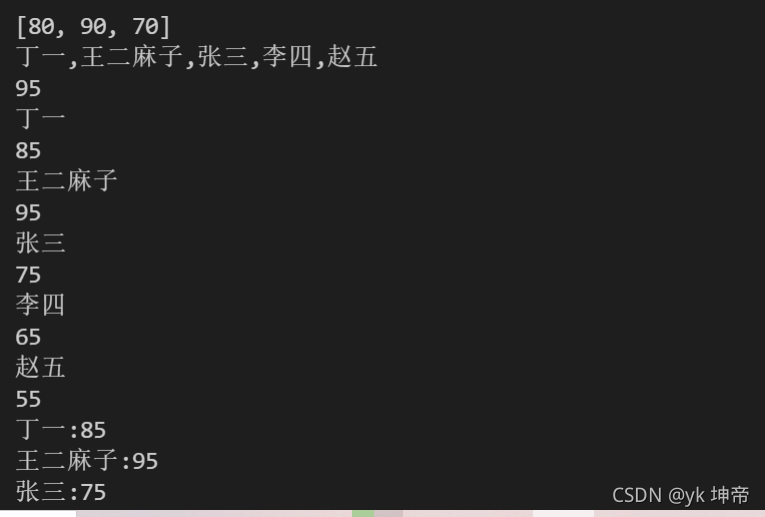
print(score)
# 列表转换成字符串,这个先了解下即可,很远之后才用的上
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
a = ",".join(class1)
print(a)
'''字典,关于字典这个知识,先了解下即可'''
# 字典名["键名"]提取值
class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55}
score = class1['王二麻子']
print(score)
# 遍历字典内容1
class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55}
for i in class1: # 这个i代表的是字典中的键,也就是丁一、王二麻子等
print(i)
print(class1[i])
# 遍历字典内容2
class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55}
for i in class1:
print(i + ':' + str(class1[i])) # 注意要str把85等数字转换成字符串,才能进行字符串拼接
# 遍历字典内容3
class1 = {'丁一': 85, '王二麻子': 95, '张三': 75, '李四': 65, '赵五': 55}
a = class1.items()
print(a)
'''元组和集合(了解即可)'''
# 元组 其实和列表基本一样,区别在于元组里的元素不可修改,及包围的括号为小括号
a = ('丁一', '王二', '张三', '李四', '赵五') # 这就是个元组,是不是和列表很像呢
print(a[1:3])
# 集合
a = ['丁一', '丁一', '王二', '张三', '李四', '赵五']
print(set(a)) # 通过set()函数可以获得一个集合,集合一个主要特点,就是用来去重,结果为:{'丁一', '王二', '赵五', '张三', '李四'}

1.2.4 运算符介绍与实践
# =============================================================================
# 1.2.4 运算符介绍与实践
# =============================================================================
# 1 算术运算符:+ 、-、*、/
a = 'hello'
b = 'world'
c = a + ' ' + b
print(c)
# 2 比较运算符: > , <, ==
score = -10
if score < 0:
print('该新闻是负面新闻,录入数据库')
a = 1
b = 2
if a == b: # 注意这边是两个等号
print('a和b相等')
else:
print('a和b不相等')
# 3 逻辑运算符:not,and,or
score = -10
year = 2018
if (score < 0) and (year == 2018):
print('录入数据库')
else:
print('不录入数据库')
1.3.1 if语句
# =============================================================================
# 1.3.1 if语句
# =============================================================================
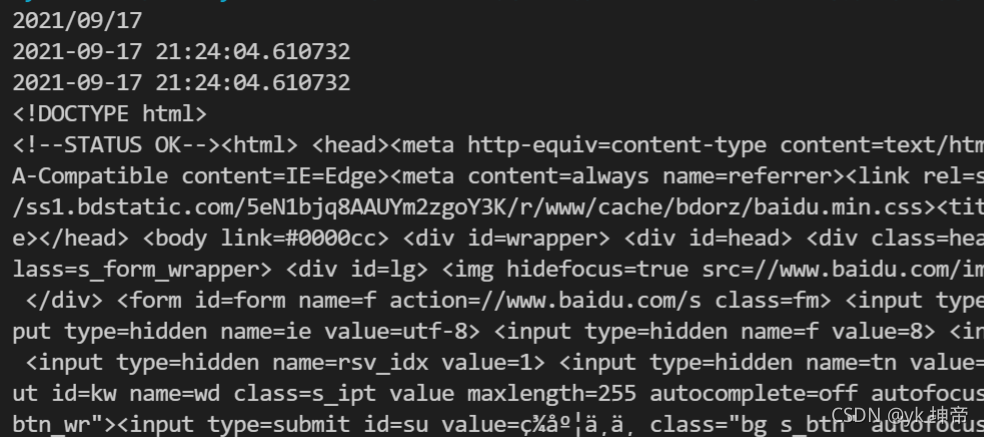
score = 100
year = 2018
if (score < 0) and (year == 2018):
print('录入数据库')
else:
print('不录入数据库')
score = 85
if score >= 60:
print('及格')
else:
print('不及格')
# 多种情况,这个用到的较少,了解即可
score = 55
if score >= 80:
print('优秀')
elif (score >= 60) and (score < 80):
print('及格')
else:
print('不及格')
1.3.2 for语句
# =============================================================================
# 1.3.2 for语句
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
for i in class1:
print(i)
# 这个i只是个代号,可以换成任何别的内容
class1 = ['丁一', '王二麻子', '张三', '李四', '赵五']
for haha in class1:
print(haha)
# for和range函数合用
for i in range(3):
print('hahaha')
'''
总结
(1)对于"for i in 区域"来说,如果说这个区域是一个列表,那么那个i就表示这个列表里的每一个元素;
(2)对于"for i in 区域"来说,如果说这个区域是一个range(n),那么那个i就表示0到n -1这n个数字,之前提到过,python中序号都是从0开始的,所以这边也是从0开始,到n - 1结束。
(3)对于"for i in 区域"来说,若区域是一个字典,那么i就表示字典的键名;
'''
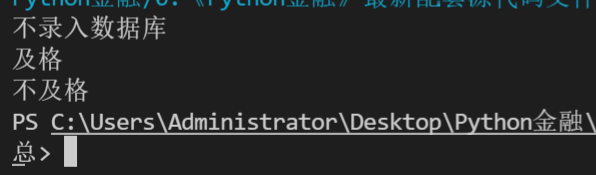
# 注意python中序号都是从0开始的
for i in range(5):
print(i)
# 在实战中的应用
title = ['标题1', '标题2', '标题3', '标题4', '标题5']
for i in range(len(title)): # len(title)表示一个有多少个新闻,这里是5;这里的i就表示数字0-4
print(str(i+1) + '.' + title[i]) # 这个其实把字符串进行一个拼接

1.3.3 while语句
# =============================================================================
# 1.3.3 while语句
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
a = 1
while a < 3:
print(a)
a = a + 1 # 或者写成 a += 1,+=是一种偷懒的写法
# while True在爬虫实战中用于24小时不间断爬取,在第7讲将会详细讲解
while True:
print('hahaha')

1.3.4 try except异常处理语句
# =============================================================================
# 1.3.4 try except异常处理语句
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
try:
print(1 + 'a')
except:
print('主代码运行失败')
# 下面为实战中的演示
try:
# 这里是百度新闻爬取的代码
print(1 + '1')
print('百度新闻爬取成功')
except:
print('百度新闻爬取失败')
try:
# 这里是百度新闻爬取的代码,之后第五第七章会讲
print(1 + 'a')
print('百度新闻爬取成功')
except:
print('百度新闻爬取失败')
try:
# 这里是新浪财经新闻爬取的代码,之后爬虫进阶课会讲
print('新浪财经新闻爬取成功')
except:
print('新浪财经新闻爬取失败')
try:
# 这里是微信推文爬取的代码,之后爬虫进阶课会讲
print('微信推文爬取成功')
except:
print('微信推文爬取失败')

1.4.1函数的定义与调用
# =============================================================================
# 1.4.1函数的定义与调用
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
# 定义及调用函数
def y(x):
print(x+1)
y(1) # 调用函数
def y(x):
print(x+1)
y(1) # 第一次调用函数
y(2) # 第二次调用函数
y(3) # 第三次调用函数
# 传入两个参数
def y(x, z):
print(x + z + 1)
y(1, 2)
# 有时候不需要参数也可以定义函数,这个了解即可
def y():
x = 1
print(x+1)
y() # 调用函数
# 函数在实战中的应用展示
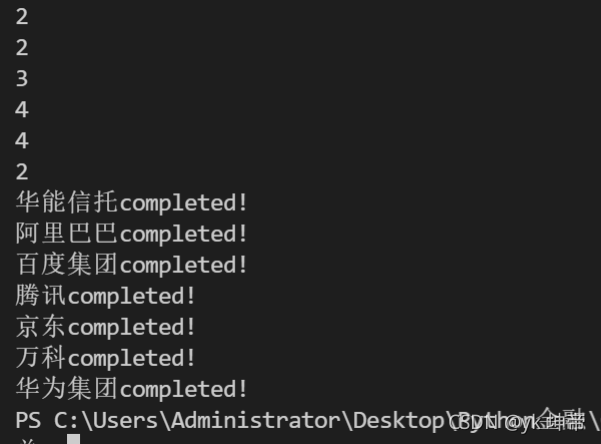
def baidu(company):
# 这里是具体爬虫代码,之后会讲
print(company + 'completed!')
companys = ['华能信托', '阿里巴巴', '百度集团', '腾讯', '京东', '万科', '华为集团']
for i in companys:
baidu(i)
'''
复习:
对于"for i in 区域"来说,如果说这个区域是一个列表,那么那个i就表示这个列表里的每一个元素;
'''
1.4.2 函数返回值、作用域
# =============================================================================
# 1.4.2 函数返回值、作用域
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
# 这里的company只是个代号,你可以换成任何东西,比如keyword,cat,dog都可以,注意函数内容里的company也要相应改变
def baidu(keyword):
# 这里是具体爬虫代码,第七章会讲
print(keyword + 'completed!')
companys = ['华能信托', '阿里巴巴', '百度', '腾讯', '京东', '万科', '建设银行']
for i in companys:
baidu(i)
'''2.返回值'''
def y(x):
return(x+1)
y(1)
'''return相当于看不见的print,它是把原来该print的值赋值给了y(x)这个函数,学术点的说法就是该函数的返回值为:x+1'''
def y(x):
return(x+1)
a = y(1)
print(a) # 这样才能把 y(1) 打印出来,或者直接写print(y1)
# 在实战中的应用
def baidu(keyword):
# 这里是具体爬虫代码,之后讲
return(keyword + 'completed!')
a = baidu('华能信托')
print(a)
# return不加括号也是可以的
def baidu(keyword):
# 这里是具体爬虫代码,第七章会讲
return keyword + 'completed!' #这里把括号去掉了
a = baidu('华能信托')
print(a)
'''3.变量作用域(了解即可)'''
x = 1
def y(x):
x = x + 1
print(x)
y(3)
print(x)
# 其实函数参数只是个代号,可以换成任何内容
x = 1
def y(z):
z = z + 1
print(z)
y(3)
print(x)
1.4.3 一些重要的基本函数介绍
# =============================================================================
# 1.4.3 一些重要的基本函数介绍
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
# 1 print函数,记得加括号即可,快捷方式,写pri的时候按一下tab键会自动变成print()
print('hello world')
print(1, 'hello', [1, 2, '123']) # 通过逗号,也可以同时打印多个内容(可以是不同类型的数据),会通过空格自动分隔
print(str(1) + 'hello') # 如果通过+号字符串拼接,则需要是同样是字符串类型
# 2 str函数与int函数 - 字符串与数字转换
score = 85
print('A公司今日评分为' + str(score) + '分。') # 不加str就成了字符串与数字相加会报错的
score = '85'
score = int(score) # 不加int的话,下面字符串'85'和数字80没法比较
if score > 80:
print('OK')
# 2 len函数
# len函数可以统计列表里元素的个数
title = ['标题1', '标题2', '标题3', '标题4', '标题5']
href = ['网址1', '网址2', '网址3', '网址4', '网址5']
for i in range(len(title)): # len(title)表示一个有多少个新闻,这里是5
href[i] = 'www.baidu.com/' + href[i] # 这个其实就相当于 a = a + 1
print(str(i+1) + '.' + title[i]) # 这个其实把字符串进行一个拼接
print(href[i])
# len函数还可以统计字符串个数
a = '123华小智abcd'
print(len(a))
# 4 replace函数 - 替换你想替换的内容
a ='<em>阿里巴巴</em>电商脱贫成“教材” 累计培训逾万名县域干部'
a = a.replace('<em>','')
a = a.replace('</em>','')
print(a)
# 5 strip函数 - 删除空白符
a =' 华能信托2018年上半年行业综合排名位列第5 '
a = a.strip()
print(a)
# 6 split函数 - 分割字符串
a = '2018年12月12日 08:07'
a = a.split(' ')[0]
print(a)
# 注意,split分割完是一个列表
a = '2018年12月12日 08:07'
a = a.split(' ')
print(a)
# 7 异常处理函数try except函数,其实应该叫异常处理语句,后来调整到1.3.4小节了
try:
print(1 + 'a')
except:
print('主代码运行失败')
try:
# 这里是百度新闻爬取的代码
print(1 + '1')
print('百度新闻爬取成功')
except:
print('百度新闻爬取失败')
try:
# 这里是百度新闻爬取的代码,之后第五第七章会讲
print(1 + 'a')
print('百度新闻爬取成功')
except:
print('百度新闻爬取失败')
try:
# 这里是新浪财经新闻爬取的代码,之后爬虫进阶课会讲
print('新浪财经新闻爬取成功')
except:
print('新浪财经新闻爬取失败')
try:
# 这里是微信推文爬取的代码,之后爬虫进阶课会讲
print('微信推文爬取成功')
except:
print('微信推文爬取失败')
1.4.4 Python库与模块介绍
# =============================================================================
# 1.4.4 Python库与模块介绍
# =============================================================================
个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码
# 显示时间的一种方式
import time
print(time.strftime("%Y/%m/%d"))
# 显示时间的另一种方式
from datetime import datetime
print(datetime.now())
# 上面的代码也可以这么写,不一定要写成from import
import datetime
print(datetime.datetime.now())
# 尝试获取百度首页的网页源代码,可以把这个网址换成别的试试看
import requests
url = 'https://www.baidu.com/'
res = requests.get(url).text
print(res)
# 获取Python官网首页的网页源代码
import requests
url = 'https://www.python.org'
res = requests.get(url).text
# print(res) # 获取到的内容较多,感兴趣的读者可以将注释取消看看运行结果,小技巧:按Ctrl+/可以添加和取消注释
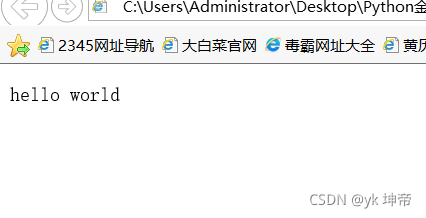
2.2.1 我的第一个网页
<!DOCTYPE html>
<html>
<p>hello world</p>
</html>
2.2.3 逐渐完善的网页
<!DOCTYPE html>
<html>
<body>
<h1>���DZ��� 1</h1>
<p>���DZ���1�µĶ��䡣</p>
<h2>���DZ��� 2</h2>
<a href="https://www.baidu.com">���Ǵ����ӵ�����</a>
</body>
</html>

2.3.1 获取百度新闻网页源代码
# =============================================================================
# 2.3.1 获取百度新闻网页源代码
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴'
res = requests.get(url, headers=headers).text
print(res)
2.4.1 正则表达式之findall
# =============================================================================
# 2.4.1 正则表达式之findall
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
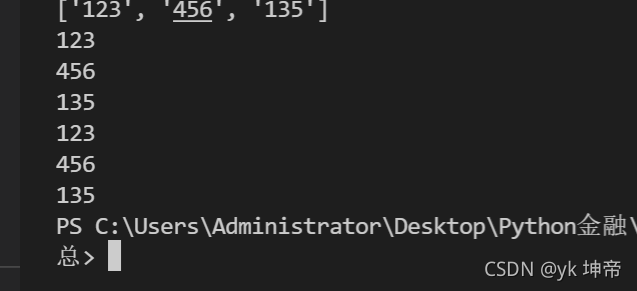
import re
content = 'Hello 123 world 456 华小智Python基础教学135'
result = re.findall('\d\d\d',content)
print(result)
# 注意获取到的是一个列表
print(result[0])
print(result[1])
print(result[2])
# 更简单的遍历方法,其中len表示列表长度,range(n)表示0到n-1
for i in range(len(result)):
print(result[i])
2.4.2 正则表达式之非贪婪匹配1
# =============================================================================
# 2.4.2 正则表达式之非贪婪匹配1
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
# 非贪婪匹配之(.*?) 简单示例1
import re
res = '文本A百度新闻文本B'
source = re.findall('文本A(.*?)文本B', res)
print(source)
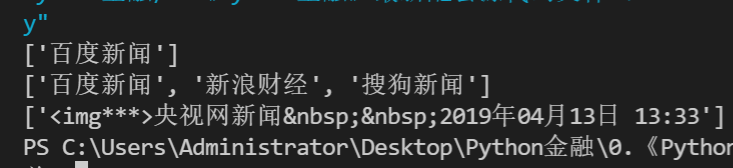
# 非贪婪匹配之(.*?) 简单示例2 注意获取到的结果是一个列表
import re
res = '文本A百度新闻文本B,新闻标题文本A新浪财经文本B,文本A搜狗新闻文本B新闻网址'
p_source = '文本A(.*?)文本B'
source = re.findall(p_source, res)
print(source)
# 非贪婪匹配之(.*?) 实战演练
import re
res = '<p class="c-author"><img***>央视网新闻 2019年04月13日 13:33</p>'
p_info = '<p class="c-author">(.*?)</p>'
info = re.findall(p_info, res)
print(info)
2.4.3 正则表达式之非贪婪匹配2
# =============================================================================
# 2.4.3 正则表达式之非贪婪匹配2
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
# 非贪婪匹配之.*? 简单示例
import re
res = '<h3>文本C<变化的网址>文本D新闻标题</h3>'
p_title = '<h3>文本C.*?文本D(.*?)</h3>'
title = re.findall(p_title, res)
print(title)
# 非贪婪匹配之.*? 实战演练
import re
res = '<h3 class="c-title"><a href="网址" data-click="{一堆英文}"><em>阿里巴巴</em>代码竞赛现全球首位AI评委 能为代码质量打分</a>'
p_title = '<h3 class="c-title">.*?>(.*?)</a>'
title = re.findall(p_title, res)
print(title)

2.4.4 正则表达式之换行
# =============================================================================
# 2.4.4 正则表达式之换行
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
import re
res = '''<h3 class="c-title">
<a href="https://baijiahao.baidu.com/s?id=1631161702623128831&wfr=spider&for=pc"
data-click="{
一堆我们不关心的英文
}"
target="_blank"
>
<em>阿里巴巴</em>代码竞赛现全球首位AI评委 能为代码质量打分
</a>
'''
p_href = '<h3 class="c-title">.*?<a href="(.*?)"'
p_title = '<h3 class="c-title">.*?>(.*?)</a>'
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
print(href)
print(title)
# 清除换行符号
for i in range(len(title)):
title[i] = title[i].strip()
print(title)

2.4.5 正则表达式之小知识点补充
# =============================================================================
# 2.4.5 正则表达式之小知识点补充
# =============================================================================
# 个人公众号 yk 坤帝
# 后台回复 python金融爬虫 获取源代码
# 1 re.sub()方法实现批量替换
# 1.1 传统方法-replace()函数
title = ['<em>阿里巴巴</em>代码竞赛现全球首位AI评委 能为代码质量打分']
title[0] = title[0].replace('<em>','')
title[0] = title[0].replace('</em>','')
print(title[0])
# 1.2 re.sub()方法
import re
title = ['<em>阿里巴巴</em>代码竞赛现全球首位AI评委 能为代码质量打分']
title[0] = re.sub('<.*?>', '', title[0])
print(title[0])
# 2 中括号[ ]的用法:使在中括号里的内容不再有特殊含义
company = '*华能信托'
company1 = re.sub('[*]', '', company)
print(company1)

个人公众号 yk 坤帝
后台回复 python金融基础 获取源代码