摘要:
1:本文讨论了多线程、多进程、并发和并行的底层逻辑;
2:本文将运用多线程对一个简单的美股爬虫程序进行改造;
3:创建线程方式有很多,本文仅使用了Threading模块调用对象的方式创建线程,此外本文就线程过多时互斥锁的数据同步作用进行代码展示;
4:为方便察看程序运行,开发环境选择了Jupytor notebook;
5:本文依旧是基于干货的分享;
目录
一、引子
二、线程、进程、并发和并行
三、基于多线程对爬虫程序进行改造
3.1 原代码
3.2 小试牛刀
3.3 互斥锁
3.5 多线程起飞
四、总结
五、参考资料
一、引子
笔者通常使用API和爬虫获取数据,API往往可以高效实现庞大的数据需求,但由于API的局限性,有时候不得不自己写爬虫获取一些偏门数据。不过与API比起来爬虫就显得很苍白了,除了与反爬程序猿相爱相杀斗智斗勇外,程序的效率也是令人头疼的问题。尤其不开VPN爬取外网,一个网址请求好几秒,随便请求个一万次少则俩仨小时,多则折腾一整晚。要是再碰上“404 Page Not Found”,“500 Internal Server Error” 直接昏古企。。

改进办法无非有二:1)对语法、逻辑、传参等方式进行修改,提高运行速度;2)开多线程和多进程。
代码风格是基本功,也是个很大的话题,先不谈。本文将基于多线程对一个简单的爬虫程序进行改造,后续有空再更新关于多进程的文章。
二、线程、进程、并发和并行
本着思维重于代码的观点,在上代码前依旧讨论下理念性的东西,对理论不感兴趣的话可以直接从第三部分开始看。
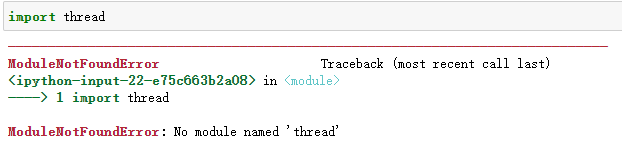
对于多线程,python提供了两个内置模块:thread和threading,thread是源生模块,threading则是在thread的基础上进行了封装及改进。目前thread模块基本已被废弃,在 Python3 中不能再使用thread模块。目前的黑科技是threading 模块,不过Python3 也将 thread 重命名为了 "_thread"
有观点认为Python的多线程是伪多线程,在python设计的时候,还没有多核处理器的概念。因此,为了设计方便与线程安全直接设计了一个锁GIL(the Global Interpreter Lock 全局解释锁),这个锁要求任何进程一次只能有一个线程在执行。
那么问题来了,既然Python一次只有一个线程在运行,threading创建的多线程是什么鬼?
其实Python的多个线程的确实是开了,也的确存在对应的线程对象,只是GIL这把锁在底层同时只允许一条线程持有GIL锁。在笔者理解来看,Python无法实现并行开发,threading就是让程序开了几个线程,只是在底层运行时这些线程都是并发运行的。这里笔者用一个不那么雅但却通俗易懂的例子展示多线程、多进程、并行与并发的概念。
如图一,一男子同时和三个女孩子交往,当他和A看电影时假装去上厕所,实际去和B喝茶了,喝茶喝到一半又找借口跑去和C聊天。这样的过程其实就是一个多线程并发,即:男孩子只有一个,而女孩子有三个,一个男孩子无法同时处理这么多女孩子,只能在触发某种条件时(例如看电影半小时,喝茶5分钟,聊天一次等)跑去撩另一个女孩子。
多进程就不一样了,现在有两个男孩子,他们可以分摊这些任务,并且重要的是被分配好的任务(如:男孩1和a喝茶,男孩2和c看电影)是可以同时进行的,即多进程并行。至于b, 她可以和多线程男孩例子中的逻辑一样看作备胎,男孩在和a喝茶时偷偷溜出去和b聊天。当然,b也可以选择成为一个渣女,即在男孩二和c看电影时与c抢资源。
图一:一个通俗易懂的例子

看完上面的例子,只要把男孩替换为CPU,女孩替换为程序就得到了线程、进程、并发与并行的逻辑,只是现在不是男孩子抢女孩子,而是程序去抢CPU资源。如图二,并发与串行相似,运行时多个线程同时去抢CPU资源,先抢到的先执行,当满足一定条件时CPU就会主动放弃当前程序,被另一个程序抢走资源,如此循环下去直到所有的程序被执行完毕。
多进程依样画葫芦,由于多个CPU的存在,几个程序可以被分配到不同的CUP上同时执行。但值得注意的是笔者在图二中将任务B与CPU核心二的进程用虚线连了起来,因为B也有可能会与C抢进程资源,这取决于编程语言,程序与逻辑。例如在C语言下B完全有可能和C抢资源;但在python下,任务AB同属于一个程序,C属于另一个程序,若此时又没有开多进程,那么由于GIL锁的存在B会与A抢资源。
图二:多线程与多进程底层逻辑

注:以上逻辑均是笔者自己的总结,如有欠缺之处欢迎指正
小结:
看懂了多线程,多进程,并发与并行的逻辑和Python的GIL锁,那么其实可以得到这样的结论:因为python设计上的原因, python的线程都是在同一个核心上运行的。python的线程不会提高效率, 只是提供了并发执行的能力。从图二上看多线程并发效率是不及多进程并行的,毕竟多了一个CPU同时工作。但事无绝对,开一个新的进程往往要消耗CPU很多空间,多进程在运行一些小型程序时比一定比多线程更快。
三、基于多线程对爬虫程序进行改造
既然多线程这么高大上;多线程这么炫酷;多线程这么香;笔者作为一个曾经在梦里单手开法拉利的分析湿怎能错过。这就写一个小型爬虫,搭一波多线程并发高速路。

3.1 原代码
笔者准备从新浪上爬取美股三大市场指数所有成分股的简称 。
话不多说,上代码:
import requests
import re
import datetime # 仅仅用于测试程序运行时间
start_org = datetime.datetime.now()
stock_list=[]
#pages={"NQ":164,"SP500":26,"DJ":2}
page=[164,26,2]
a = 0
for i in range(len(page)):
markets=i+1
market_list=[]
for i2 in range(int(page[i])):
pages=i2+1
url="https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page="+str(pages)+"&num=20&sort=&asc=0&market=&id=&type="+ str(markets)
#新浪用来翻页的真实网址是被隐藏在js里的
response = requests.get(url).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
market_list.extend(symbol)
print("已经爬取{}".format(symbol))
stock_list.append(market_list)
stock_list
end_org = datetime.datetime.now()
print("执行程序时间",end_org-start_org)查看下运行时间,2分钟的样子,可以说是很慢了。

3.2 小试牛刀
接下来用threading对以上代码上多线程,导入我们的的Super idol:
import threadingthreading的类对象主要有下面这些参数,
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)target即是希望执行多线程的目标函数,args传入元组作为target调用对象的参数,而kwargs则传入关键字参数字典作为调用对象的参数。至于group,daemon小程序基本用不到,如果感兴趣可以查看附录笔者筛选的技术文档。
既然创建多线程要调用函数,把之前的源代码爬虫部分写成函数的形式:
def craw(*data): #*add可接收多个以非关键字方式传入的参数
url = data[0]
stock_list = data [1]
lock = threading.Lock()
for i in url:
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
stock_list.extend(symbol)
print(threading.current_thread().getName() +"已经爬取{}".format(symbol))
print("爬取完成,共爬取%d条数据"% len(stock_list))
#print(stock_list, len(stock_list),id(stock_list))
return stock_list接下来创建两个线程试试看,分别调用刚刚写好的craw, 传入各自元组作为参数。爬取的公司结果都存进stock_list。
start_org = datetime.datetime.now()
page, url_list=[164,26,2], []
a = 0
#global stock_list
for i in range(len(page)):
markets=i+1
for i2 in range(int(page[i])):
pages=i2+1
url="https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page="+str(pages)+"&num=20&sort=&asc=0&market=&id=&type="+ str(markets)
url_list.append(url)
half = len(url_list)//2
stock_list=[]
#创建线程,分别执行总列表的前一半和后一半:
t1 = threading.Thread(target = craw, args=(url_list[:half], stock_list),name="task2")
t2 = threading.Thread(target = craw, args=(url_list[half:], stock_list),name="task2")
t1.start() # 开启线程
t2.start() # 开启线程
t1.join() # 结束线程
t2.join() # 结束线程
print("总列表",stock_list, len(stock_list),id(stock_list))
end_org = datetime.datetime.now()
print("双线程执行程序时间",end_org-start_org)同样的,查看运行时间:42秒

what!?双线程竟然快这么多,这难到是传说中的1+1>2?笔者很快有了个大胆的想法:

quin = len(url_list)//5
t1 = threading.Thread(target = craw, args=(url_list[:quin], stock_list),name="task1")
t2 = threading.Thread(target = craw, args=(url_list[quin:quin*2], stock_list),name="task2")
t3 = threading.Thread(target = craw, args=(url_list[quin*2:quin*3], stock_list),name="task3")
t4 = threading.Thread(target = craw, args=(url_list[quin*3:quin*4], stock_list),name="task4")
t5 = threading.Thread(target = craw, args=(url_list[quin*4:], stock_list),name="task5")
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t1.join()
t2.join()
t3.join()
t4.join()
t5.join()把刚刚的列表quintail,创建5个线程,岂不是几秒就爬完哈哈哈
运行结束一看。。

what??41秒?

而且爬取的结果中开始出现了很多错误。。
后面才了解到原来是多线程抢着对同一个变量修改造成的混乱,当线程数越多,出错率也越高。如何解决呢,这就要引入互斥锁的概念。
3.3 互斥锁
由于没有控制多个线程对同一资源的访问而对数据造成破坏,使得线程运行的结果不可预期的现象称为“线程不安全”。Python自带的GIL锁也是出于这样的目的才只允许一个线程。因此,多个线程都修改某一个共享数据的时候,需要进行同步控制。最简单的同步机制是引入互斥锁。互斥锁为资源引入一个状态:锁定/非锁定,在threading模块中可以使用对象:threading.Lock()使用互斥锁, 通过acquire 方法和 release 方法可以控制互斥锁的锁定与解锁。
这下在craw里再加个互斥锁解决之前抢资源报错的问题:
lock = threading.Lock() #调用互斥锁的类对象
for i in url:
lock.acquire() # 锁定
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
stock_list.extend(symbol)
print(threading.current_thread().getName() +"已经爬取{}".format(symbol))
lock.release() # 解锁
刚刚开五个线程的方式也比较笨,换成for循环自动创建线程并且放入列表做成一个线程池,依旧quintail,创建5个线程。
stock_list,threads_pool=[],[]
for i in range (0,6):
t1 = threading.Thread(target = craw, args=(url_list[quin*i:quin*(i+1)], stock_list),name="task{}".format(i))
threads_pool.append(t1)
t1.start()
for i in threads_pool:
i.join()3.5 多线程起飞
整合以上改进的代码
start_org = datetime.datetime.now()
page, url_list=[164,26,2], []
a = 0
for i in range(len(page)):
markets=i+1
for i2 in range(int(page[i])):
pages=i2+1
url="https://stock.finance.sina.com.cn/usstock/api/jsonp.php/IO.XSRV2.CallbackList['fTqwo9s8$wLka1yh']/US_CategoryService.getChengfen?page="+str(pages)+"&num=20&sort=&asc=0&market=&id=&type="+ str(markets)
url_list.append(url)
def craw(*data):
url = data[0]
stock_list = data [1]
lock = threading.Lock()
for i in url:
lock.acquire()
response = requests.get(i).text
symbol = re.findall('"symbol":"(.*?)","cname"',response,re.S)
stock_list.extend(symbol)
print(threading.current_thread().getName() +"已经爬取{}".format(symbol))
lock.release()
print("爬取完成,共爬取%d条数据"% len(stock_list))
#print(stock_list, len(stock_list),id(stock_list))
return stock_list
quin = len(url_list)//5
stock_list,threads_pool=[],[]
for i in range (0,6):
t1 = threading.Thread(target = craw, args=(url_list[quin*i:quin*(i+1)], stock_list),name="task{}".format(i))
threads_pool.append(t1)
t1.start()
for i in threads_pool:
i.join()
print("总列表",stock_list, len(stock_list),id(stock_list))
end_org = datetime.datetime.now()
print("五线程执行程序时间",end_org-start_org)运行结果:36秒,也不再出错了

四、总结
从两分钟压缩到36秒,笔者还挺满意的。理论上来说双线程(42秒)效率不会比单线程(2分钟)快这么多,不过笔者并没有考虑网络影响,网站服务器,电脑等因素影响,毕竟同样一个程序再同一台电脑上运行时间都会有些许差异。可以肯定的是多线程的确提高了程序的效率,但线程数并不是越多越好,太多的线程反而会出现边际递减甚至负增长,出错乱的概率也会变大。同时,针对一些大型一点的程序,仅仅使用多线程就显得有些苍白了。其实多线程是个很大的话题,创建线程的方式并不只有文中这一种,例如还可通过使用threading.Thread类的子类创建线程;互斥锁也不止文中这一种,其它例如递归锁、条件变量对象、事件对象和栅栏对象等概念就不做更多展开了,文末筛选了一些技术文档作为资料供大家参考。
笔者写了一晚上,本来只想放放代码拉跨一下,忍不住还是把底层逻辑盘了一遍。学习工作之余进行创作,更新不一定会很快,但您若不弃,我们风雨共济。
五、参考资料
Python内置库:threading(多线程) https://www.cnblogs.com/guyuyun/p/11185832.html
https://www.cnblogs.com/guyuyun/p/11185832.html
python多线程编程(3): 使用互斥锁同步线程https://www.cnblogs.com/holbrook/archive/2012/03/04/2378947.html
Python并发之多线程![]() https://www.cnblogs.com/blueberry-mint/p/13722871.html
https://www.cnblogs.com/blueberry-mint/p/13722871.html
Python3入门之线程threading常用方法![]() https://www.cnblogs.com/chengd/articles/7770898.html
https://www.cnblogs.com/chengd/articles/7770898.html