一、网络配置:
1.1 配置单机网络:
1.2 关闭防火墙:
1.3 SSH连接Centos7:
1.4 配置hosts文件:
二、JDK配置:
三、Zookeeper集群配置:
四、Hadoop集群配置:
4.1 文件建立
4.2 JAVA路径设置
4.2.1 hadoop-env.sh配置
4.2.2 yarn-env.sh配置
4.3 Hadoop集群文件配置
4.3.1 core-site.xml配置
4.3.2 hdfs-site.xml配置:
4.3.3 mapred-site.xml配置
4.4 Hadoop集群搭建
4.4.1 克隆节点
4.4.2 配置免密登录
4.4.3 启动Zookeeper
4.4.4 启动Hadoop集群
一、网络配置:
1.1 配置单机网络:
配置虚拟机网络之前,我们需要打开cmd输入ipconfig,得到:

IPv4 地址以及默认网关中显示的是为物理机的ip地址,在ip地址中各类网络地址的子网都是不同的。
例如:172.16.x.x是指B类网络地址,而.x.x则是在整个172.16下的子网ip地址
因此,在编辑Centos7的网络地址的时候,需要找到自己的网络地址,可以通过子网掩码进行确认几类网络地址,之后通过VM-编辑-虚拟机网络编辑进行修改,即:
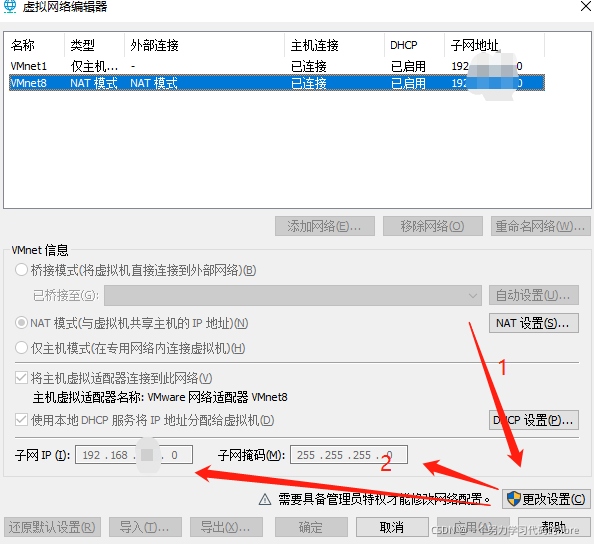
通过学习网络上其他大佬的文章,子网IP选择和物理机的Network地址一致,Host地址不一致,可以为之后深入Centos学习节约一点时间。
进入Centos7界面之后,选择root用户登录,之后进入终端,输入ifconfig可以看到自己的网络地址:
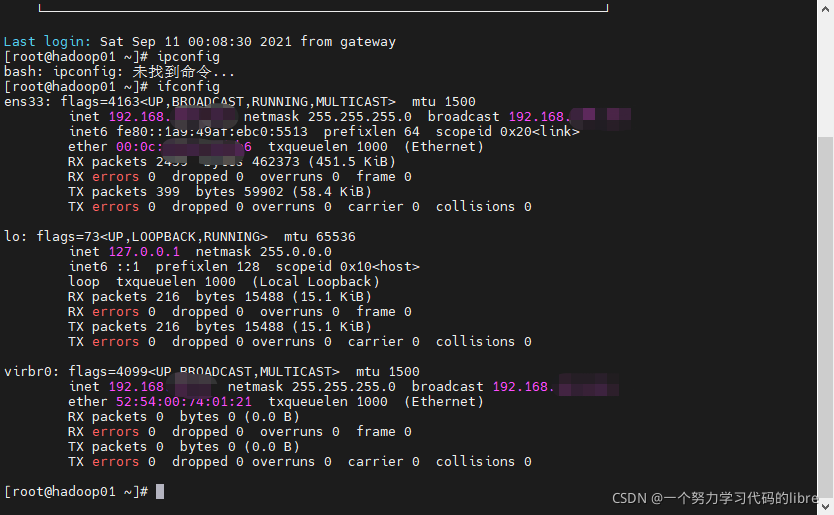
如果是没配置过网络的Centos7,则这是配置完网络之后应该出现的截图。通过修改ifcfg-ens33文件实现对Centos7网络配置:
vim /etc/sysconfig/network-scripts/ifcfg-ens33 进入ens33文件之后,需要配置的是
BOOTPROTO = “static”
ONBOOT=yes
IPADDR=Network地址+自己设置的host地址
host地址一般是从129开始,而搭建hadoop集群所需要的其他节点host设置,则是在master机器的host地址之上迭代+1。
GATEWAY=Network地址+2 例如172.16.1.2
NETMASK地址以及DNS地址可以选择填写或者不填,在下图示例中是没有填写进去。
NETMASK=几类地址的子网掩码,例如255.255.255.0是C类地址的子网掩码
DNS=8.8.8.8,这个属于Google公司的dns码
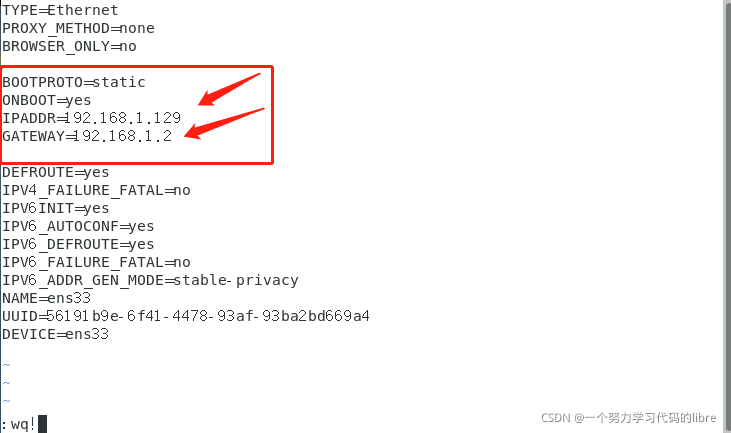
修改完ens33文件之后,保存并重启网络:
service network restart再输入ifconfig,则可以看到自己刚刚在上面所设置的ip地址。
1.2 关闭防火墙:
几乎现在每一台计算机系统都有配置自己的防火墙,而防火墙可以避免我们的计算机陷入不安全的环境当中。但是基于对Hadoop集群的学习以及是在VM虚拟机里面,因此我们可以选择直接关闭防火墙的自启动,避免每一次登录Centos7都会发生防火墙隔离的问题。但如果是基于自己系统里面,我建议每一次使用前再关闭防火墙。
systemctl stop firewalld.service #停止防火墙
systemctl status firewalld.service #查看防火墙状态
systemctl disable firewalld.service #关闭防火墙在Centos7里面,stop、start、status、disable以及restart分别对应着操作中的停止、开始、状态、禁止、重启的操作逻辑,因此,在操作其他语句时,我们亦可以尝试使用。
1.3 SSH连接Centos7:
这里阐述的是通过SSH软件MobaXterm(官网有免费版本,学习用的小伙伴可以和我一样使用免费版本降低学习成本)连接VM虚拟机中的Centos7的教程:
首先,我使用ssh软件的目的是因为VM虚拟机进行本机切换是需要输入CTRL+ALT跳出虚拟机操作界面,这使得我学习之路有点难受。因此,我选择使用SSH软件连接VM虚拟机中的Centos7,可以避免这个问题。同时,有些人无法从主机上传文件到虚拟机中(具体解决办法可以查询其他大佬的文章)或指定目录,而SSH软件帮助我们迅速的解决这一问题。
从官网下载MobaXterm软件是纯英文版本,而如何进行远程连接呢?首先我们需要将修改虚拟机的IP地址(这一步,我们已经完成),之后选择MobaXterm中的:

后输入自己的Centos7中的IP地址,以及相关账号的姓名之后:
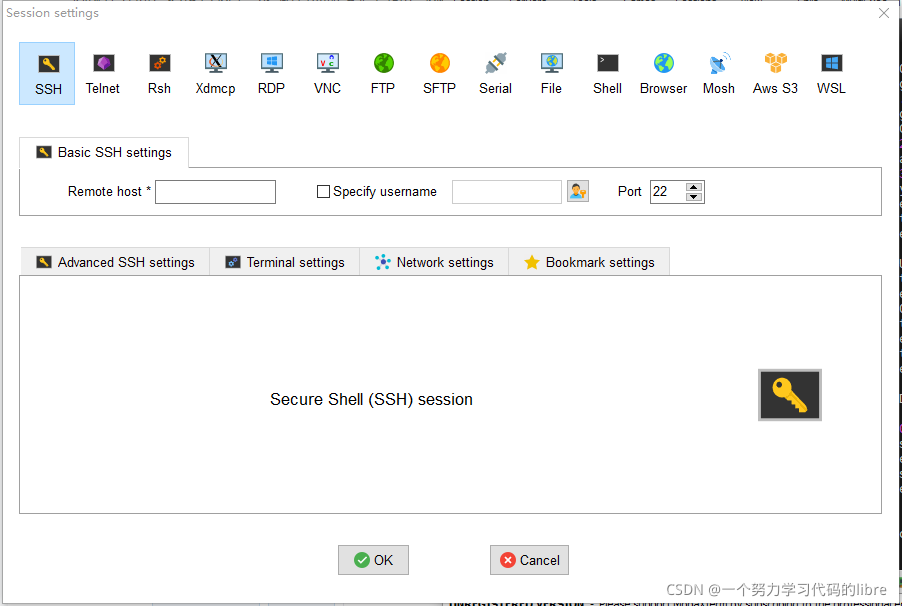
点击OK,并在命令行界面中输入密码,实现Centos7命令行界面使用(这过程中VM虚拟机中的Centos7需要保持启动状态)。
1.4 配置hosts文件:
这一步,是提前进行hosts文件配置,我们也可以在克隆完成之后再进行,并通过SCP命令将hosts文件进行同步。
首先,我们先进行主机名字的修改:
hostnamectl set-hostname master #每台机器的主机名需要不同
hostnamectl set-hostname slave1 #推荐使用master、slave1、slave2
hostnamectl set-hostname slave2
.
.
.
并输入bash进行刷新,然后打开HOSTS文件进行配置:
vim /etc/hosts #输入IP地址 主机名
#有多少台节点就输入多少IP地址和主机名
#需要区分IP地址配置完成之后,需要保证每一台节点的主机名和IP地址与HOSTS文件中写入的一致性
二、JDK配置:
配置Hadoop以及Zookeeper之前,我们还需要对Centos7中的JDK环境进行配置。虽然在Centos7中,我们已经有系统自带的JDK环境:
java -version
但是,系统自带的JDK可能会与我们使用的Hadoop与Zookeeper造成错误,因此我们需要对自带的JDK进行删除,可以输入下面这行代码,查找到所有与JAVA有关的文件。
rpm -qa | grep java而删除自带的JDK,我们只需要删除所有带有OPENJDK文件,例如:
rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.262.b10-1.el7.x86_64将所有OPENJDK文件删除之后,我们输入java -version命令可以得到:

这样一来,我们的自带JDK系统已经删除完毕。然后,进入JDK官网下载Linux版本的JDK。注意,不需要下载太高版本的JDK,否则会因为JDK自带因素导致无法正常运行Hadoop和Zookeeper(亲身体验过安装没问题,启动一直报错的痛苦),推荐下载Java 8。
将下载完成的JDK文件导入Centos7中,如果是使用Vm虚拟机,需要注意当前用户是ROOT或者是普通用户,避免找不到文件位置,而使用SSH连接软件,需要注意上传目录是在哪里。
上传之后,对JDK进行解压,JDK文件名代表着JDK-版本-操作系统-x64/32位,因此建议使用TAB键完成JDK文件名的匹配。
tar -zxvf jdk-8u301-linux-x64.tar.gz解压之后,使用:
mv jdk1.8.0_301/ /usr/local/java将JDK文件移到/USR/LOCAL/下面,并重命名为JAVA,可以通过ls命令进行确认。需要注意的是本文全程使用的是ROOT用户进行安装。
解压完JDK,我们需要对JAVA进行环境配置,类似于Windows的环境配置:
vim /etc/profile打开编辑/ETC/PROFILE文件之后,新建一行,并将JAVA所在位置等信息进行写入,即:
#java
export JAVA_HOME=/usr/local/java #JAVA所在实际文件位置
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin完成之后,重启PROFILE文件(推荐):
source /etc/profile我们可以通过JAVA -VERSION命令进行查看:

三、Zookeeper集群配置:
Zookeeper的安装文件是从官网中下载,注意的是Zookeeper的版本不要最新,也不要太过老(因为有些版本的STATUS会发生No Runing现象,本文以Zookeeper3.6.3为例)。
将zookeeper导入到Centos7,进行解压、移动的操作:
tar -zxvf zookeeper-xxxx.tar.gz #tab补全
mv zookeeper-xxx /usr/local/zookeeper #tab补全
cd /usr/local/zookeeper在zookeeper文件路径下,建立DATA文件目录和LOGS文件目录:
mkdir data;mkdir logs并且,将ZOOKEEPER文件目录下的CONF文件目录下的zoo_sample.cfg文件进行复制粘贴重命名操作:
cp zoo_sample.cfg zoo.cfg进入到zoo.cfg文件编辑中,修改以下图所示:
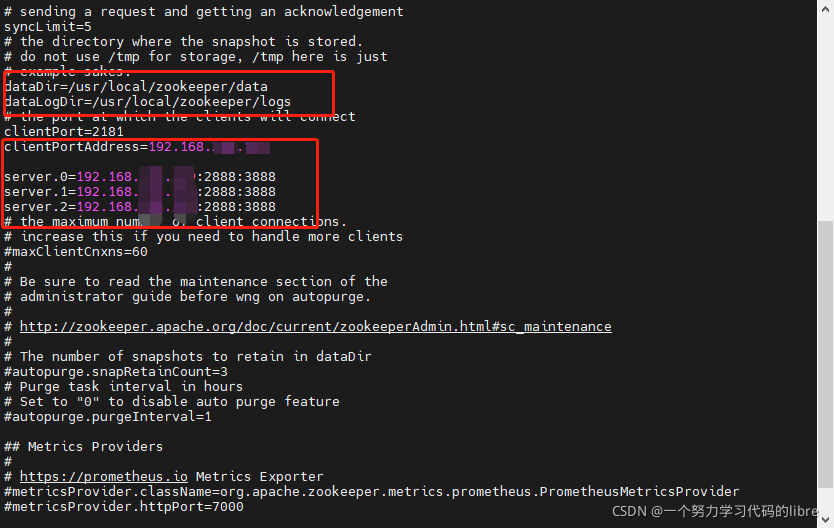
代码:
dataDir=/usr/local/zookeeper/data #data存放地方
dataLogDir=/usr/local/zookeeper/logs #log存放地方
clientPortAddress=192.168.x.x #本机IP,避免localhost现象,可以不加
server.0=192.168.x.x:2888:3888 #server0-2指的是节点,一般用的是1-250
server.1=192.168.x.y:2888:3888 #填入多台Centos7的IP地址
server.2=192.168.x.z:2888:3888 #2888是内部通信地址,3888是选举leader使用
保存后:
cd /usr/local/zookeeper/data #到data地址
mkdir myid #建立myid文件,需要和server.匹配
echo 0 >> myid #通过echo将id写入myid如果要将Zookeeper文件在任意目录下调用,需要编辑PROFILE文件:
vim /etc/profile
#zookeeper #输入
export ZOOKEEPER_HOME=/usr/local/zookeeper #所在位置
export PATH=$PATH:$ZOOKEEPER_HOME/bin
因为我们配置的是ZOOKEEPER集群,因此启动前需要保证所有节点都启动。如果是按照本文顺序先配置单机,再克隆出其他节点的话,现在启动ZOOKEEPER会出现其他节点报错的信息:
/usr/local/zookeeper/bin/zkServer.sh start #在zookeeper/bin路径下进行配置启动成功截图(三台节点同时在线)为:
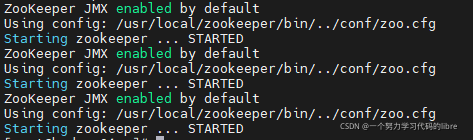
后将 START 换成 STATUS/STOP则分别是上文中所提及的状态以及停止服务。
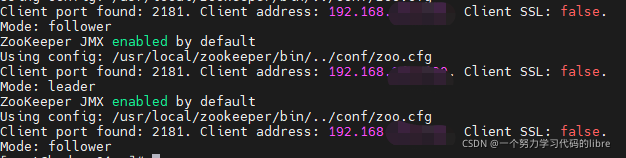
同时,如果我们想一键启动ZOOKEEPER则可以通过在ROOT目录或其他路径下建立一个.sh文件进行操作,同时需要用CHMOD命令进行权限给予 chmod 775 文件名.sh:
#! /bin/bash
case $1 in
"start"){
for i in 192.168.x.x 192.168.x.y 192.168.x.z #三台机的主机名或IP地址
do
ssh $i "/usr/local/zookeeper/bin/zkServer.sh start" #同一个路径下
done
};;
"stop"){
for i in 192.168.x.x 192.168.x.y 192.168.x.z
do
ssh $i "/usr/local/zookeeper/bin/zkServer.sh stop"
done
};;
"status"){
for i in 192.168.x.x 192.168.x.y 192.168.x.z
do
ssh $i "/usr/local/zookeeper/bin/zkServer.sh status"
done
};;
esac
四、Hadoop集群配置:
4.1 文件建立
首先,我们需要从官网中下载Hadoop文件到本机中,并上传到Centos7。之后进行重复上文的动作,将Hadoop文件解压,并移动到/USR/LOCAL路径下:
tar -zxvf hadoop-2.10.1.tar.gz #tab补齐即可
mv hadoop-2.10.1/ /usr/local/hadoop #会重命名为hadoop文件
cd /usr/local/hadoop/ #到路径下,如果找不到则是路径写错了同样,如果我们要在任意目录下启动Hadoop集群,则需要将Hadoop路径写入到PROFILE路径下面:
vim /etc/profile
#hadoop
export HADOOP_HOME=/usr/local/hadoop #Hadoop路径
export PATH=$PATH:${HADOOP_HOME}/bin编辑完成之后,通过重启PROFILE文件进行测试:
source /etc/profile
had #当tab能自动补齐时,则编辑成功现在,我们需要知道的是Hadoop集群是需要进行数据存储,因此我们需要建立一个DATA文件进行数据存储。
mkdir -p /usr/local/data/temp
mkdir -p /usr/local/data/hdfs/name
mkdir -p /usr/local/data/hdfs/data当我们将这些外部东西设置好了之后,我们需要进行内部“装饰”,首先需要我们在Hadoop文件夹下,然后进入到ETC/HADOOP目录下:
cd etc/hadoop/4.2 JAVA路径设置
接下来,大家如果怕自己编辑文件错误,可以通过CP命令将文件复制一份重命名为其他,进行备份。然后,我们开始编辑,首先是将JAVA路径配置进去。
4.2.1 hadoop-env.sh配置
编辑hadoop-env.sh文件:
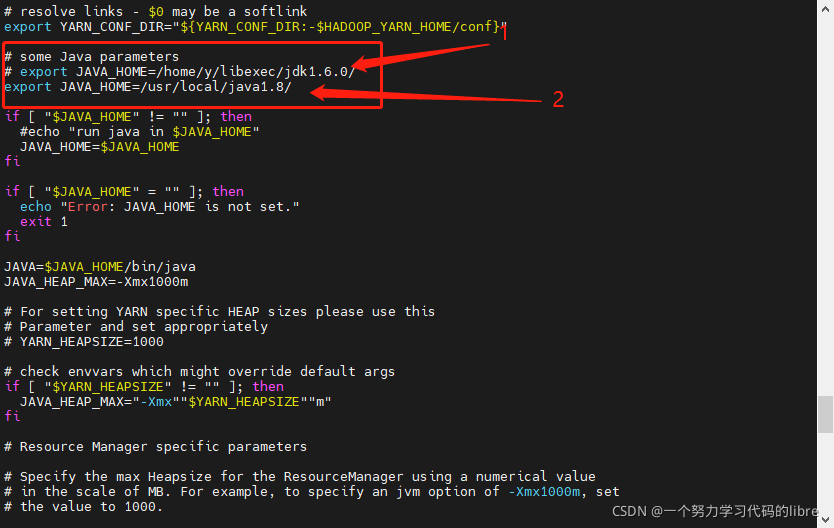
vim hadoop-env.sh然后在文件中查找找到JAVA_HOME,插入下面的代码,并把之前的JAVA_HOME进行屏蔽:
export JAVA_HOME=/usr/local/java #java所在路径如图:
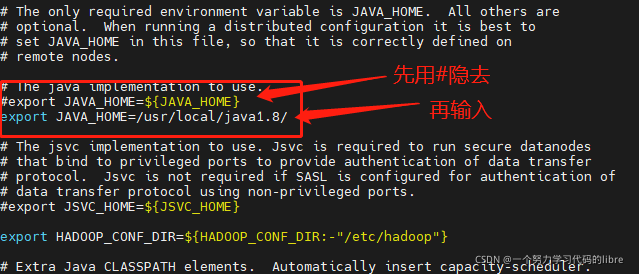
4.2.2 yarn-env.sh配置
编辑 yarn-env.sh文件:
vim yarn-env.sh同样的查找到文件中的JAVA_HOME路径,将之前的屏蔽掉后插入下面代码:
export JAVA_HOME=/usr/local/java #java所在路径如图:
4.3 Hadoop集群文件配置
接下来进行Hadoop集群文件的配置,还是那一句话,如果担心配置错误的话,建议可以CP文件进行备份。所有代码都要输入到<configuration></configuration>中
4.3.1 core-site.xml配置
编辑core-site.xml文件:
vim core-site.xml输入以下代码:
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value> #masterIP地址
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value> #masterIP地址
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/data/tmp</value> #上文中建立的data文件
<description>节点上本地的hadoop临时文件夹</description>
</property>
<!--流文件的缓冲区单位KB-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--执行zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name> #zookeeper的IP需要与下面输入一致
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
4.3.2 hdfs-site.xml配置:
编辑hdfs-site.xml文件:
vim hdfs-site.xml输入以下代码:
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/data/hdfs/name</value> #根据实际修改
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/data/hdfs/data</value> #根据实际修改
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>副本个数,默认是3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop01:50090</value> #根据实际修改
<!-- hadoop01是master 的 主机名 -->
</property>
4.3.3 mapred-site.xml配置
由于mapred-site.xml被Hadoop文件自动设置了.template,因此需要首先去掉.template才能使用,推荐以下操作:
cp mapred-site.xml.template mapred-site.xml编辑mapred-site.xml
vim mapred-site.xml输入以下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
4.3.4 yarn-site.xml配置
编辑yarn-site.xml
vim yarn-site.xml输入以下代码
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value> #推荐master
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.3.5 slaves文件配置
到这一步,我们需要先编辑slaves文件:
vim slaves然后,把LOCALHOST给删除,更换成SLAVE1、SLAVE2
slave1 #或者是IP地址
slave24.4 Hadoop集群搭建
4.4.1 克隆节点
首先,我们关闭现在的Centos7
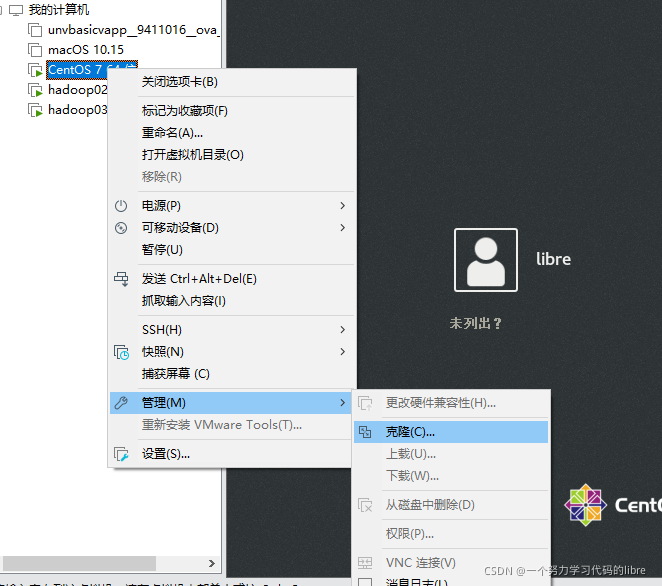
shutdown now然后,右键虚拟机,选择管理-克隆-完整克隆(注意不要把克隆机放在C盘,不然你会发现C盘又被占用了点空间),如图:
克隆好两台Centos7后,我们可以发现现在只需要修改ENS33文件中的IP地址、ZOOKEEPER文件目录下的DATA目录下的MYID,以及主机名即可,具体操作如下:
修改ens33文件:
vim /etc/sysconfig/network-scripts/ifcfg-ens33 修改地方如图:
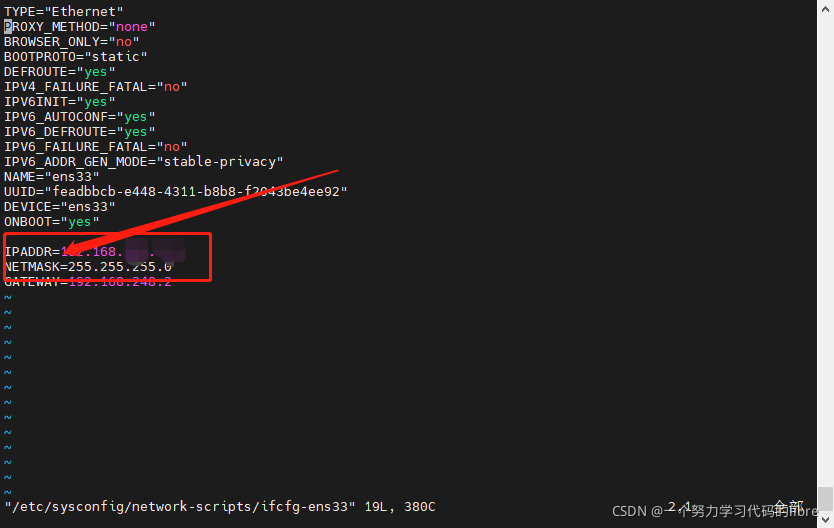
同时,需要我们输入的IP地址和HOSTS文件的IP地址一致,否则无法启动SSH免密登录,查看的代码:
cat /etc/hosts #需要修改则将cat和vim互换Myid修改的代码如下:
cd /usr/local/zookeeper/data #到data地址
echo 1 >> myid #通过echo将id写入myid注意的地方是,MYID的ID需要和server.x相匹配,同时也需要保证server.x的IP和HOSTS文件的IP一致
主机名修改的代码如下:
hostnamectl set-hostname slave1 #推荐使用master、slave1、slave2
hostnamectl set-hostname slave2
.
.
.
然后重启:
reboot测试是否可以连接
ping 主机名 #也可以是主机的IP然后,如图:

4.4.2 配置免密登录
现在我们需要实现的是A机免密访问B机,同时B机也可以免密访问A机。
ssh-keygen -t rsa #在master上,三次回车即可将master公钥拷贝在一个文件里面
cat id_rsa.pub >> authorized_keys然后把其他节点的密码也输入到同一个文件,需要登录其他节点上
ssh slave1 #slave1为节点名
ssh-copy-id -i master #master主机名或IP地址回到master主机上,输入:
chmod 600 authorized_keys
chmod 700 .ssh然后通过SCP把authorized_keys传到其他节点上:
scp /root/.ssh/authorized_keys slave1:/root/.ssh/通过SSH其他节点,测试是否成功
ssh 节点名 #注意第一次启动需要密码,接下里就不用4.4.3 启动Zookeeper
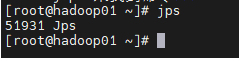
输入JPS,保证自己节点机器上没有运行ZOOKEEPER,如图:
然后在集群节点下面输入以下代码,或者是用.sh文件一键启动,可以用STATUS或者是JPS查看:
/usr/local/zookeeper/bin/zkServer.sh start #在zookeeper/bin路径下进行配置4.4.4 启动Hadoop集群
第一次启动Hadoop集群,需要在master节点上格式化,代码如下:
hdfs namenode -format然后格式化后,输入以下代码,启动Hadoop集群:
/usr/local/hadoop/sbin/start-all.sh start如图,可以通过JPS查看进程:

到目前为止,HADOOP集群和ZOOKEEPER集群配置完成。
如果大家觉得不错的话可以给波支持,写这一波文章,主要是为了提升自己对HADOOP的理解,接下里我还会继续更新对HADOOP学习,冲!