文章目录
- 😘 闲聊几句
- 👍 list
- 👍list的反转和排序
- 👍set/multiset
- 👍对组
- 👍map / multimap
- ❤️最后
😘 闲聊几句
时间过的很快,码神马上就要开学了,这也是STL系列的最后一篇了,假期学了不少,距离自己的奥赛巅峰水平可以说是十分接近了,如果说学这c++有什么用的话,可能就是兴趣所至吧,在博客更新之际,也认识了不少行业大佬,给我提了不少意见,感谢!STL完了以后,就是算法和python脚本吧,做自己想做的事情,更要做难的事情,总体来说STL的浏览量不多,但是还要说,why?因为有些算法题,你适当的使用STL,用过的都知道👍,所以我还是坚持将STL讲完了、
那就这么多,开始吧:
- list ——链表
- set ——关联式容器,底层是由二叉树实现的
- map容器
👍 list
对数据结构中链表陌生的兄弟们,可以看下我的码神爆肝5w字数据结构,记得我说过一句话,数组的缺点就是链表的优点,链表的缺点就是链表的优点,还记得数组的优点是什么?数组的优点是:可以随机访问,缺点是:插入和删除要移动所有元素,同样可以类比出链表的优缺点。
STL中的链表略有不同,是STL中链表是双向链表
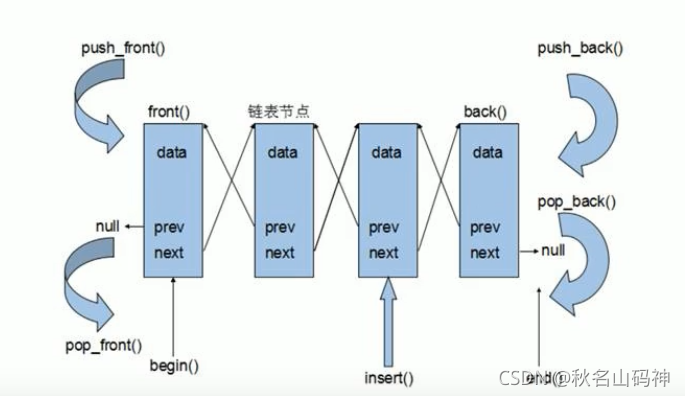
和vector的操作基本一致,比较不同的是在删除操作时多了个remove(c):删除与c一样的数据,开车了
#include<iostream>
#include<list>
using namespace std;
void print(list<int> &l)
{
for (list<int> ::iterator it = l.begin(); it != l.end(); it++)
{
cout << *it<<" ";
}
cout << endl;
}
void test01()
{
list<int> l;
l.push_back(10);
l.push_back(20);
l.push_front(100);
l.push_front(200);
if (l.empty())
{
cout << "为空";
}
else
{
cout<<l.size()<<endl;
}
print(l);
//200 100 10 20
l.pop_back();
print(l);
//200 100 10
l.clear();
}
int main()
{
test01();
return 0;
}
这里对比,vector值得注意的是list是链式存储,所以在迭代器iterator中出现,it+1,等操作,取而代之的是it++,一个一个走
用专业方式就是说,支持it+1,是支持随机访问,反之就是不支持随机访问不能用at和【】
👍list的反转和排序
这个我感觉还是有点用的,所以单独说一下,
先来说反转:reverse函数
排序:有个algorithm中的sort不知道还记得不?但是有个前提是,sort只适用在随机访问的数据结构中,list为了方便引入了专门的sort,使用方法是l.sort(),
下面我们用代码来实现一下,这俩个功能
#include<iostream>
#include<algorithm>
#include<list>
using namespace std;
void print(list<int> &L)//打印
{
for (list<int> ::iterator it = L.begin(); it != L.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
bool fanzhuan(int v1,int v2)
{
return v1 > v2;
}
void test01()
{
list<int> l1;
l1.push_back(10);
l1.push_back(20);
l1.push_back(30);
l1.push_back(20);
l1.push_back(10);
print(l1);
l1.reverse();
print(l1);
//从小到大排
l1.sort();
print(l1);
//从大到小
l1.reverse();
print(l1);
//换一个方式
l1.push_front(10);
l1.sort(fanzhuan);
print(l1);
}
int main()
{
test01();
return 0;
}
可以看到我在实现从大到小时,使用了俩个方法,我们为什么不直接反转呢?原因还是从效率上考虑的,首先我们要明白反转的本质是:
初始化一个为 null 的 previous node(prev),然后遍历链表的同时,当前 node (curr)的下一个(next)指向前一个 node(prev), 在改变当前 node 的指向之前,用一个临时变量记录当前 node 的下一个 node. 即
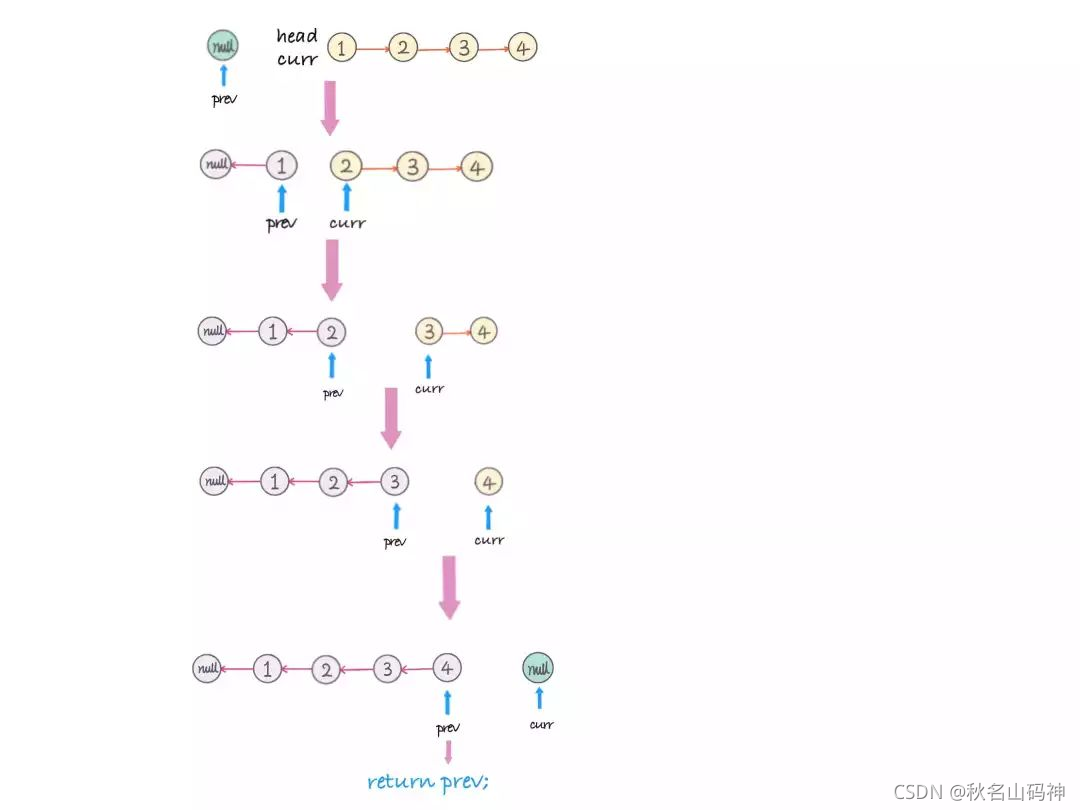
可以看出时间效率有点低,所以用bool变量写了个函数,来实现从小到大的排序。
👍set/multiset
所有元素都会在插入时自动被排序这应该是它最主要的特定了!
这两个是属于关联式容器,其底层架构是由二叉树实现的,那么如果没有区别,肯定是不行的,要不然直接用一个不就好了嘛,看区别:
- set不允许有重复元素
- multiset允许有重复元素
看一下set的基本操作:
- empty
- size
- swap——交换俩个集合
- insert——插入
- erase——删除
- 清空:erase(s.benin(),s.end())
- clear()
- find—查找
- 存在返回s的迭代器,不存在返回s.end()
- count(key)——统计key的个数
//set是一个容器,区别是当他刚插入是就已经排好了,集合
#include<set>
#include<iostream>
using namespace std;
void print(set<int> &s)
{
for (set<int> ::iterator it = s.begin(); it != s.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
void test01()
{
set<int>s1;
s1.insert(10);
s1.insert(20);
s1.insert(5);
s1.insert(1);
set<int>s2;
s2.insert(44);
s2.insert(11);
s2.insert(55);
print(s2);
print(s1);
//交换
s1.swap(s2);
print(s2);
print(s1);
cout<<s1.cout(11);
//应该是1,因为s1和s2互换了序列
int num=s1.count(10);
cout<<num<<endl;
应该为0
cout << s1.size() << " " << s2.size();
}
int main()
{
test01();
return 0;
}
multiset,下来我们来验证一下,前面说过这个容器允许重复插入,这个头文件仍然使用set
下面我们用仿函数来改变set的排序,让它从大到小来进行排序
#include<iostream>
#include<set>
#include<algorithm>
using namespace std;
//仿函数
class compare
{
public:
bool operator()(int l1,int l2)
{
return l1 > l2;
}
};
void print(set<int> &s)
{
for (set<int> ::iterator it = s.begin(); it != s.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
void test01()
{
set<int> s;
s.insert(30);
s.insert(20);
s.insert(40);
s.insert(50);
s.insert(10);
print(s);
//排序
set<int, compare>s1;
s1.insert(30);
s1.insert(20);
s1.insert(40);
s1.insert(50);
s1.insert(10);
//print(s1);
for (set<int, compare>::iterator it = s1.begin(); it != s1.end(); it++)
{
cout << *it << " ";
}
}
int main()
{
test01();
return 0;
}
👍对组
听名字来看,应该是成对出现的,所以叫对组,比较简单
#include<iostream>
#include<string>
using namespace std;
void test01()
{
pair<string, int> p(string("masheng"), 20);
cout << p.first << " " << p.second << endl;
pair<string, int>p1("tom", 18);
cout << p1.first << " " << p1.second << endl;
}
int main()
{
test01();
return 0;
}
这里我们运用到了pair关键字,对
👍map / multimap
也是使用频率比较高的容器,由于它的性能高,效率高,其底层是由红黑树实现的,但是如果展开来讲红黑树的话,太长了,所以我们,直接来看这个容器,值得注意的一点是:这个容器的每一个元素都是pair,上会讲到的对组,其中对组的第一个元素为key(键值),后一个元素为value(实值)。
这俩个容器的区别有点像set
map中不允许有重复的key值元素
multimap允许有重复的key值元素
都有的特点有:
- 所有的元素都自动排列
- 可以根据key值快速找到value值
#include<map>
#include<iostream>
using namespace std;
void print(map<int,int> &m1)
{
for (map<int,int> ::iterator it=m1.begin();it!=m1.end();it++)
{
cout << it->first << " " << it->second;
}
cout << endl;
}
void test01()
{
map<int, int> m;
//用pair传入
m.insert(pair<int, int>(1, 5));
m.insert(pair<int, int>(8, 5));
m.insert(pair<int, int>(3, 5));
//可以看出根据key值来排序
map<int, int>m1(m);
m1 = m;
print(m);
}
int main()
{
test01();
return 0;
}
和其他容器一样,我们看几个函数
- size——大小
- empty——是否为空
- swap——交换集合
- insert——之前用到过的插入
- clear——清空
- erase——删除
- find——查找到了返回迭代器,查找不到返回end
- count——通上也是统计
值得注意的是map的用【】插入,查找的功能
在用【】查找时,如果查找的数据没有,那么编译器会自动赋值一个数据给到map容器,插入时,value值为0,key值为所查找的值
m[5]=10;,假如5没有,那么5对应的value就为10,或者是这样m【5】;这样5对应0
还有插入:m.insert(make_pair(5,20))和上面的m.insert(<int,int>5,20)
都是比较常用的,但是我不建议在插入时使用【】
void test01()
{
map<int, int>m;
m[5];
print(m);
}
❤️最后
码神的开车之旅STL车型也算是圆满结束了,不知道你怎么样?关键是去找各个容器的相同点和不同点来进行对比的记忆,不知道你们有没有看到,就是在学了几个容器后,发现都是大同小异,不难,对吧?底层都是写好的,应用都是靠自己了,在更新完stl后,我也是要休息几天准备下大学生活了,感谢支持,停几天,给大家更新,还是老样子:
如果觉得文章对你有帮助,🎉欢迎关注🔎点赞👍收藏⭐️留言📝,一键四连支持,你的支持就是我创作最大的动力。
💌 欢迎大家在评论区提出意见和建议!💌