本期与大家分享的是,小北用心整理的与HIVE相关的常见的面试题,希望对大家能有帮助,大家喜欢就给点鼓励吧,欢迎各位大佬评论区指教讨论!
💜🧡💛制作不易,各位大佬们给点鼓励!
🧡💛💚点赞👍 ➕ 收藏⭐ ➕ 关注✅
💛💚💙欢迎各位大佬指教,一键三连走起!
往期好文推荐:
🔶🔷Hive从入门到精通,HQL硬核整理四万字,全面总结,附详细解析,赶紧收藏吧!!
🔶🔷Hadoop深入浅出 ——三大组件HDFS、MapReduce、Yarn框架结构的深入解析式地详细学习【建议收藏!!!】
🔶🔷Redis从青铜到王者,从环境搭建到熟练使用,看这一篇就够了,超全整理详细解析,赶紧收藏吧!!!
🔶🔷硬核整理四万字,学会数据库只要一篇就够了,盘它!MySQL基本操作以及常用的内置函数汇总整理
🔶🔷Redis主从复制 以及 集群搭建 详细步骤解析,赶快收藏练手吧!
🔶🔷Hadoop集群HDFS、YARN高可用HA详细配置步骤说明,附Zookeeper搭建详细步骤【建议收藏!!!】
🔶🔷SQL进阶-深入理解MySQL,JDBC连接MySQL实现增删改查,赶快收藏吧!
⭕ 🧡1、Hive的排序函数有哪些(4种)
⭕ 🧡2、Hive 内部表和外部表的区别
⭕ 🧡3、Hive 和(传统)数据库比较
⭕ 🧡4、说下你对窗口函数的了解
⭕ 🧡5、窗口函数row_number,rank,dense_rank有什么区别
⭕ 🧡6、Hive的自定义函数
⭕ 🧡7、Hive 的架构
⭕ 🧡8、 Hive 优化
⭕ 🧡9、count(*),count(1),count(’ 字段名 ')区别
⭕ 🧡10、hive的存储格式
⭕ 🧡11、hive的数据压缩
⭕ 🧡12、hive的元数据存储
⭕ 🧡13、介绍一下hive的分区
⭕ 🧡14、介绍下hive的分桶
⭕ 🧡15、hive的组成部分有哪些
⭕ 🧡16、使用hive的优缺点
⭕ 🧡17、hive的SQL执行顺序
⭕ 🧡18、hive有没有索引,如果有,请介绍下
⭕ 🧡19、hive的后期运维,该如何调度
⭕ 🧡20、数据仓库,为什么要分层
⭕ 🧡21、数据倾斜,是怎么产生的
⭕ 🧡22、数据倾斜,如何处理
⭕ 🧡23、使用hive建数据仓库,有哪些模型
1、Hive的排序函数有哪些(4种)
点我返回目录
- Sort By:分区内有序;
- Order By:全局排序,对所有数据进行排序,只有一个 Reducer;
- Distrbute By:类似 MR 中 Partition,进行分区,结合 sort by 使用,分区字段 store by 排序字段。
- Cluster By:当 分区条件和排序条件相同时,也就是Distribute by 和 Sort by 字段相同时,可以使用 Cluster by 方式。Cluster by 除了具有 Distribute by 的功能外还兼具 Sort by 的功能。但是排序只能是升序排序,不能指定排序规则为 ASC 或者 DESC。
2、Hive 内部表和外部表的区别
点我返回目录
- 内部表(managed table)没有被external修饰,外部表(external table)被external修饰
- 内部表数据是由Hive自身管理的,而外部表的数据是由HDFS管理的
- 内部表存储数据的路径需要在 hive/warehouse/目录下(hive.metastore.warehouse.dir),而外部表的路径可以自定义。
- 删除表后,内部表的数据文件和表信息(元数据)都被删除,外部表仅删除表信息(元数据)但HDFS上的数据文件不会被删除。
- 修改内部表会将修改信息直接同步到元数据,而修改外部表的表结构和分区时,则需要修复(MSCK REPAIR TABLE table_name;)
3、Hive 和(传统)数据库比较
点我返回目录
- 查询语言。类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
- 数据存储位置。所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
- 数据格式。Hive 中没有定义专门的数据格式。而在数据库中,所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
- 数据更新。Hive 对数据的改写和添加比较弱化,0.14版本之后支持,需要启动配置项。而数据库中的数据通常是需要经常进行修改的。
- 索引。Hive 在加载数据的过程中不会对数据进行任何处理。因此访问延迟较高。数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
- 执行计算。Hive 中执行是通过 MapReduce 来实现的而数据库通常有自己的执行引擎。
- 数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
4、说下你对窗口函数的了解
点我返回目录
- SQL中的聚合函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的。但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时HSQL便引入了窗口函数来解决这种需求。
- RANK() 排序相同时会重复,总数不会变
- DENSE_RANK() 排序相同时会重复,总数会减少
- ROW_NUMBER() 会根据顺序计算
1) OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
2) CURRENT ROW:当前行
3) n PRECEDING:往前 n 行数据
4) n FOLLOWING:往后 n 行数据
5) UNBOUNDED : 起 点 , UNBOUNDED PRECEDING 表 示 从 前 面 的 起 点 ,UNBOUNDED FOLLOWING 表示到后面的终点
6) LAG(col,n):往前第 n 行数据
7) LEAD(col,n):往后第 n 行数据
8) NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对于每一行,NTILE 返回此行所属的组的编号。注意:n 必须为 int 类型。
Hive窗口函数,详解
5、窗口函数row_number,rank,dense_rank有什么区别
点我返回目录
- RANK():函数会生成一个数据项在分组中的排序, 排序相同时会重复,会在名次中留下“空位”,但总数不会变(总排序不变)
- DENSE_RANK() :函数会生成一个数据项在分组中的排序, 排序相同时会重复,但不会在名次中留下“空位”,总数会减少(总排序改变,会减少)
- ROW_NUMBER() 会根据顺序计算,从1开始生成一个分组内的排序序列,当排序的值相同时会按照表中的记录顺序来排序,也就是说,使用row_number()函数排序不会生成相同的序号。
ROW_NUMBER RANK DENSE_RANK 三者的区别,详解
6、Hive的自定义函数
点我返回目录
Hive自定义函数包括三种UDF、UDAF、UDTF
- UDF(User-Defined-Function) :一进一出
- UDAF(User- Defined Aggregation Funcation) :聚集函数,多进一出。
- UDTF(User-Defined Table-Generating Functions): 一进多出。
自定义函数使用步骤 :(在HIVE会话中add 自定义函数的jar文件,然后创建function继而使用函数)
- 编写自定义函数
- 打包上传到集群机器中
- 进入hive客户端,添加jar包: add jar jar包路径
- 创建临时函数:create temporary function 函数名 as ‘主类名’;
- 销毁临时函数: drop temporary function 函数名;
7、Hive 的架构
点我返回目录
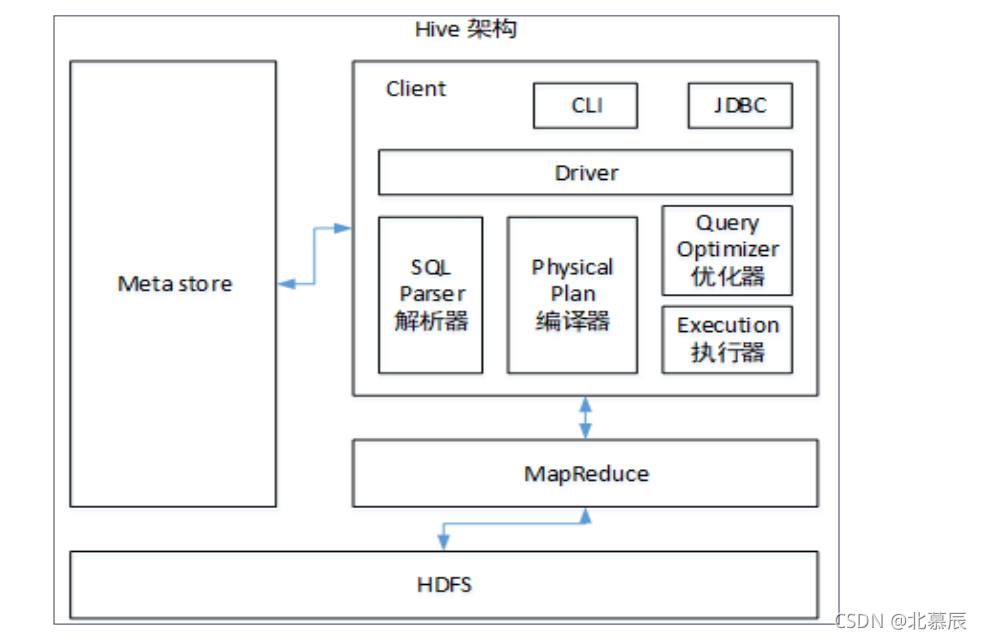
hive架构介绍,详解
8、 Hive 优化
点我返回目录
(1)MapJoin优化
如果没有指定 MapJoin 或者不符合 MapJoin 的条件时,Hive 解析器会将 Join 操作转换成 Common Join,也就是指:在 Reduce 阶段完成 join,会容易发生数据倾斜问题。我们可以使用 MapJoin 把小表全部加载到内存后再在 map 端进行 join操作,这样就避免了 reducer 处理。
2)行列过滤优化
列处理优化:在 SELECT 查询时,只拿需要的列,如果有需要的列,那么尽量使用分区过滤,并且少用 SELECT *。
行处理优化:在分区剪裁过程中,当使用外关联时,若是将副表的过滤条件写在 Where 后面,那么就会先全表关联之后再过滤。
3)采用分桶技术、或者采用分区技术来进行hive优化
4)合理设置 Map 的个数
- (1)通常情况下:作业会通过 input 的目录产生一个或者多个 map 任务。主要的决定因素包括有:input 的文件总个数,input 的文件大小,集群设置的文件块大小等。
- (2) 但是map 数不是越多越好,如果一个任务有很多小文件(小文件是指远远小于块大小 128m),那么这样每个小文件也会被当做一个块,用一个 map 任务来完成,但是若一个 map 任务启动和初始化的时间远远大于逻辑处理的时间,那么就会造成很大的资源浪费。而且,同时可执行的 map 数也是受限的。但也并不是保证每个 map 处理接近 128m 的文件块,就一定没事了。例如现有一个 127m 大小的文件,而正常会用一个 map任务去完成,但是这个文件只有一个或者两个小字段,却有着几千万的记录,如果map 处理的逻辑比较复杂,用一个 map任务去做,肯定也比较耗时。针对上面描述的两种问题,我们需要采取两种不同的方式来处理解决,第一个即减少 map 数和第二个增加 map 数;
6)将小文件进行合并
在 Map 执行前合并小文件,从而减少 Map 数:CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)。但是HiveInputFormat 没有对小文件合并功能。
7)合理设置 Reduce 数
- Reduce 个数并不是越多越好
- (1)过多的启动和初始化 Reduce 也会消耗时间和资源;
- (2)另外,有多少个 Reduce,就会有多少个输出文件,如果生成了很多个小文件,而且这些小文件将会作为下一个任务的输入,俺么也会出现小文件过多的问题;此外,在设置 Reduce 个数的时候也需要考虑这两个原则:处理大数据量利用合适的 Reduce数;使单个 Reduce 任务处理数据量大小要合适;
8)常用参数
// 输出合并小文件
SET hive.merge.mapfiles = true; -- 默认 true,在 map-only 任务结束时合并
小文件
SET hive.merge.mapredfiles = true; -- 默认 false,在 map-reduce 任务结
束时合并小文件
SET hive.merge.size.per.task = 268435456; -- 默认 256M
SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小
小于该值时,启动一个独立的 map-reduce 任务进行文件 merge
9、count(*),count(1),count(’ 字段名 ')区别
点我返回目录
- count(*):统计所有的列,也就是统计行数,不会忽略列值为NULL的列
- count(1):包括了忽略的所有列,用1表示代码行,不会忽略列值为NULL的列
- count(‘字段名’):只统计包含字段名的那一列,统计时,会忽略列值为NULL的列
从执行结果上来看使用时它们的效率是一样的,但是:
- count(’主键名‘)执行效率要比count(1)快
- count(’非主键名‘)执行效率要比count(1)慢
- 如果表没有主键,有多个col,则 count(1)的执行效率比count(*)好
- 如果表有主键,则那么select count(’主键名‘)的执行效率最快
- 如果表仅有一个字段,则 select count(*)的执行效率最快
10、hive的存储格式
点我返回目录
Hive的数据存储基于Hadoop HDFS。Hive没有专门的数据文件格式,常见的有以下几种:TEXTFILE、SEQUENCEFILE、AVRO、RCFILE、ORCFILE、PARQUET;其中TextFile、RCFile、ORC、Parquet为Hive最常用的四大存储格式;
- TEXTFILE: 正常的文本格式,是Hive默认文件存储格式,存储文件默认每一行就是一条记录,可以指定任意的分隔符进行字段间的分割,但这个格式无压缩,需要的存储空间很大。
- RCFile:是Record Columnar的缩写,是一种行列存储相结合的存储方式,是Hadoop中第一个列文件格式, 能够很好的压缩和快速的查询性能,通常写操作比较慢,比非列形式的文件格式需要更多的内存空间和计算量,
- ORCFile:Hive从0.11版本开始提供了ORC的文件格式,ORC文件不仅仅是一种列式文件存储格式,最重要的是有着很高的压缩比,并且对于MapReduce来说是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅可以很大程度的节省HDFS存储资源,而且对数据的查询和处理性能有着非常大的提升,因为ORC较其他文件格式压缩比高,查询任务的输入数据量减少,使用的Task也就减少了。ORC能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩,当然这部分的CPU消耗是非常少的。
- Parquet:Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能。Parquet仅仅是一种存储格式,它是语言、平台无关的,并且不需要和任何一种数据处理框架绑定。这也是parquet相较于orc的仅有优势:支持嵌套结构。
存储效率及执行速度比较如下:
ORCFile存储文件读操作效率最高,耗时比较(ORC<Parquet<RCFile<TextFile)
ORCFile存储文件占用空间少,压缩效率高
(ORC<Parquet<RCFile<TextFile)
11、hive的数据压缩
点我返回目录
hive的数据压缩可以减少存储磁盘空间,可以降低单节点的磁盘IO,并且压缩后的数据占用的带宽会减少,可以加快数据在Hadoop集群中的流动速度,但是hive的数据压缩会需要花费额外的时间或者CPU资源来压缩和解压缩计算;数据压缩是文件处理很重要的方面,通过数据压缩来实现高效存储,而选择合适的压缩编解码器尤为重要。使用Avro和SequenceFile等文件格式是内置压缩支持的,压缩对用户几乎是完全透明的。对压缩编解码器的选择,通常会针对压缩编解码器的功能和性能是有一定的选择准则的,例如:
- 1.考虑时(时间)空(空间)效益:我们要对压缩编解码器的时间/空间进行权衡,通常计算成本越高的压缩编解码器的压缩比越好,能够产生更小的压缩输出;
- 2.可拆分性:我们可以将一个压缩文件拆分成多个供给多个mqpper使用,那么,若该压缩文件无法拆分那就只能使用一个mapper,同样,若压缩文件存储在不同的块(block)上,跨越了多个块,这样会缺失数据的局部性,因为这样,执行map任务时就会需要远程从不同DataNode上来拉取数据,会产生网络IO资源开销。
- 3.本地压缩支持:我们还要考虑到本地是否存在执行压缩和解压缩的本地库,有本地压缩支持。要比,没有底层本地库而使用java代码实现的压缩编解码器要好的多。
在hadoop 1.x版本之后对bzip2是原生支持的,但是不支持可拆分性,若要支持可拆分性就必须要启用Java bzip2。
12、hive的元数据存储
点我返回目录
hive默认元数据(Metastore)是存储在derby中的,但是derby是单session的,一般会修改存储在mysql中,hive的元数据表中存储着表的属性、名称、列、分区及其属性以及表数据所在的目录等等,即metastore中存储着hive创建的数据库,数据表等的元信息。例如元数据存储在mysql中,当客户端存取元数据时,客户端会先连接metastore服务,然后metastore再去连接MySQL来存取元数据,而通过metastore服务就可以实现多个客户端同时连接,而这些客户端就不需要知道MySQL的用户名和密码就可以操作存储在MySQL中的元数据,这样客户端就只需要连接metastore即可。
hive的元数据存储有三种部署方式:内嵌模式(Embedded)、本地模式(Local)以及远程模式(Remote);
- 内嵌模式(Embedded):也称为单用户模式,该模式是hive metastore最简单的一种模式,该模式使用的是内嵌的Derby数据库来存取元数据,不需要额外的Metastore服务,但是Derby仅支持一个客户端的访问,如果在创建第二个访问就会导致元数据访问失败
- 本地模式(Local):也称为多用户模式可以同时提供多个客户端连接到数据库,是matastore的默认模式。hive服务和metastore服务运行在同一个进程中,本地模式就是在本地安装MySQL数据库或其它数据库而不使用内嵌的Derby来存储元数据,
- 远程模式(Remote): 非Java客户端访问metastore,服务器端启动MetaStoreServer服务,客户端通过Thrift协议,使用MetaStoreServer来访问元数据库。该模式是将metastore作为一个单独的hive服务,也就是Hive服务和metastore在不同的进程内,可以是不同的机器。该模式会将数据库置于防火墙后,客户端也就不需要再通过用户名和密码来登录数据库了·,同时也保证了信息的安全性,避免了信息的泄漏。
13、介绍一下hive的分区
点我返回目录
在Hive 中使用Select查询语句一般会扫描整个表内容,而当单个表中的数据量越来越大的时候,使用select查询就会消耗很多不必要的资源。而这时就引入了分区的概念,分区表实际上是在表的目录下再以分区命名,创建子目录,hive分区就是进行分区裁剪,避免全表扫描,减少MapReduce处理的数据量,从而提高效率。但是分区也不是越多越好,一般都不超过3级,根据实际业务来衡量。
14、介绍下hive的分桶
点我返回目录
因为不是所有的数据集都可以形成合理的分区,为了解决这一问题hive中引入了分桶的概念,分桶就是指对于每一个表或者分区,可以进一步地细分成桶,而桶是对数据进行更细粒度的划分。Hive默认是关闭分桶的;当我们往分桶表中插入数据的时候,会根据 clustered by 指定的字段进行hash分组,并对指定的buckets个数进行取余,进而可以将数据分割成buckets个数个文件,以达到数据均匀分布,从而可以解决Map端的“数据倾斜”的问题,这样方便我们取抽样数据,提高Map join的效率,然而,我们实际使用时的分桶字段则需要根据业务进行设定。
15、hive的组成部分有哪些
点我返回目录
hive的组成部分包括有:
- Hive的数据查询语言,是一种类似与SQL的查询语言HQL。
- hive的元数据(metastore),用于存储hive创建的数据库,数据表等的元信息。
- JDBC接口,数据库编程,用于使用java api连接hive数据库进行操作。
- hive的编译器(Compiler),用于将hive编译成中间表示,对hql分析等等。
- hive执行的驱动(Driver),用于将各组成部分组合起来形成一个执行系统,包括了对会话的处理,查询获取数据等。
- hive的执行引擎(Execution Engine),基于hive的执行驱动,完成具体的hql执行操作,包括对mapreduce、hdfs、元数据等的操作。
16、使用hive的优缺点
点我返回目录
-
使用hive的优势:
- hive的hql语言操作简单便捷,容易上手,hive提供了类SQL查询语言HQL算法
- hive有很高的可扩展:hive为超大数据集专门设计了计算或扩展能力(使用Hadoop MapReduce做为计算引擎,HDFS做为存储系统)的函数,这样就避免了开发人员去写mapreduce,减少了开发人员学习的成本;而且一般状况下不须要重新启动hive服务,Hive就能够自由的扩展集群的规模。
- hive提供了统一的元数据管理设计
- hive的延展性较好:Hive可以支持用户自定义函数,用户能够根据实际的需求情况来实现函数进行数据挖掘
- hive的容错性很好:hive具有良好的容错性,当集群中任一节点出现问题时,hive SQL仍可以完成执行。
- hive的缺点(局限性)
- hive的HQL语言表达能力有限
- hive对于迭代式的算法不能表达
- hive不擅长对数据的挖掘,因为mapreduce对数据的处理这一过程的限制,导致效率更高的算法难以实现。
- hive的执行效率比较低下
- hive自动生成的MapReduce job,一般还不够智能化
- hive的调优比较困难,颗粒度比较粗
- hive的可控性比较差
17、hive的SQL执行顺序
点我返回目录
from where select group by having order by
https://www.cnblogs.com/gxgd/p/9431783.html
18、hive有没有索引,如果有,请介绍下
点我返回目录
在hive 0.7.0版本之后就,hive就添加了索引(其实就是索引表),提高了hive查询的指定列的速度;在索引表中存储着索引列的值(该列的值对应着hdfs的文件路径,也是指数据文件中的偏移量)。当通过索引列来执行查询时,hive会首先通过一个mapreduce去查询索引表,并且根据索引列的过滤条件查询出该索引列的值,然后根据值查找所对应的hdfs的文件目录以及偏移量,并且把这些数据输出到hdfs的一个文件中,然后再根据这个文件中去筛选原文件,来作为查询job的输入。使用索引,在select查询时可以避免全表扫描和资源浪费,同时也可以增快含有group by的分组语句的查询速度。
19、hive的后期运维,该如何调度
点我返回目录
我们可以通过将sql语句写在脚本中,然后使用脚本来执行hive的sql语句;可以监控任务的调度页面;也可以通过使用azkaban或者oozie来进行任务的调度。
20、数据仓库,为什么要分层
点我返回目录
- 数据分层可以让数据结构清晰化,每一个数据层都会有自己的作用域和职责,这样在使用表的时候,我们就能够更加简捷方便的查询到所需要的数据
- 数据分层能够减少重复的开发,对数据分层进行规范,开发一些中间层的数据,可以减少很多重复的计算
- 数据分层可以统一数据的输出口径
- 数据分层可以将复杂问题简单化,将一个复杂的问题划分给不同的数据层来解决特定的问题。极大的提高解决问题的效率。
21、数据倾斜,是怎么产生的
点我返回目录
数据倾斜一般是由于,key分布不均匀(实际上就是key重复, 比如 group by 或者 distinct的时候,会因为key的分布不均匀而产生数据倾斜);其次,就是数据重复,导致join操作时 笛卡尔积 而造成的数据膨胀。
数据倾斜主要表现在,任务进度长时间维持在99%(或100%),而查看任务的监控页面,发现只有少量的(1个或几个)reduce子任务未完成。这是因为其处理的数据量和其他reduce差异过大,而导致的数据倾斜。还有一种就是单一的reduce的记录数与平均记录数差异过大,通常这个差异可能会达到3倍以上,并且最长时长要远大于平均时长。
22、数据倾斜,如何处理
点我返回目录
解决数据倾斜问题,我们要首先看下业务上面的数据源头能否对数据进行过滤,比如 key为 null的数据,可以在业务层面进行优化。其次,再找到key重复的具体值,对该值进行拆分,hash或异步求和。
23、使用hive建数据仓库,有哪些模型
点我返回目录
hive数仓建模有星型,雪花型和星座型这主要的三种建仓模型;其中,星型是由多张维度表和一张事实表组成的,而维度表之间没有关系。若使用星型模型建数仓,那么对数据查询的性能要好些但是存储的数据会有冗余。雪花型建仓模型是星型建模的扩展,雪花型的维度表之间是有关系的,该模型也只有一张事实表。使用雪华型建仓,会减少存储数据的冗余,但是对数据的查询的性能就会有所损失,它需要通过多级连接来查询数据。而星座型建模也是星型的扩展,不过该模型会存在有多张事实表。