文章目录
- 认识Flask
- Flask
- 了解框架
- 为什么要用Web框架
- Flask框架的诞生
- Flask扩展包
- 安装环境
- 安装Flask
- 安装Flask依赖包
- 视图
- 从 Hello World 开始
- 扩展
- 请求钩子
- Flask装饰器路由的实现:
- Flask-Script扩展命令行
- 模板
- 变量
- 反向路由:
- 自定义错误页面:
- 过滤器:
- 字符串操作:
- 自定义过滤器:
- Web表单:
- WTForms支持的HTML标准字段
- WTForms常用验证函数
- 在HTML页面中直接写form表单:
- 视图函数中获取表单数据:
- 控制语句
- 常用的几种控制语句:
- 宏、继承、包含
- 定义宏
- 模板继承:
- 父模板:base.html
- 子模板:
- 包含(Include)
- Flask中的特殊变量和方法:
- config 对象:
- request 对象:
- 数据库
- 数据库安装
- 数据库的基本命令
- 使用Flask-SQLAlchemy管理数据库
- 常用的SQLAlchemy字段类型
- 常用的SQLAlchemy列选项
- 常用的SQLAlchemy关系选项
- 数据库基本操作
- 在视图函数中定义模型类
- 常用的SQLAlchemy查询过滤器
- 常用的SQLAlchemy查询执行器
- 查询:filter_by精确查询
- 查询数据后删除
- 更新数据
- 自定义模型类
- 定义模型
- 数据库迁移
- 创建迁移仓库
- 创建迁移脚本
- Flask—Mail
- 测试与部署
- 蓝图Blueprint
- 什么是蓝图?
- 蓝图的运行机制:
- 蓝图的使用:
- 动态路由示例(作者--图书):
- 单元测试
- 为什么要测试?
- 什么是单元测试?
- 发送邮件测试:
- 数据库测试:
- 部署
- 使用Gunicorn:
- 安装gunicorn
- 安装Nginx
- Restful
- REST的特点:
- 如何设计符合RESTful风格的API:
- 一、域名:
- 二、版本:
- 三、路径:
- 四、使用标准的HTTP方法:
- 五、过滤信息:
- 六、状态码:
- 七、错误信息:
- 八、响应结果:
- 九、使用链接关联相关的资源:
- 十、其他:
- 性能
- 一、不同角度的网站性能
- 二、性能的指标
- 三、性能的优化
- 总结:
认识Flask
Flask
Flask相对于Django而言是轻量级的Web框架。和Django不同,Flask轻巧、简洁,通过定制第三方扩展来实现具体功能。
可定制性,通过扩展增加其功能,这是Flask最重要的特点。Flask的两个主要核心应用是Werkzeug和模板引擎Jinja。

了解框架
Flask作为Web框架,它的作用主要是为了开发Web应用程序。那么我们首先来了解下Web应用程序。Web应用程序 (World Wide Web)诞生最初的目的,是为了利用互联网交流工作文档。
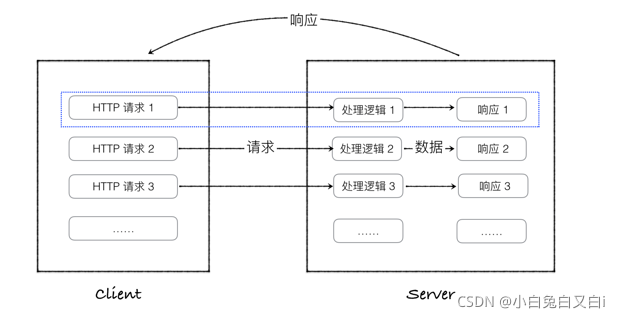
一切从客户端发起请求开始。
- 所有Flask程序都必须创建一个程序实例。 当客户端想要获取资源时,一般会通过浏览器发起HTTP请求。
- 此时,Web服务器使用一种名为WEB服务器网关接口的WSGI(Web Server GatewayInterface)协议,把来自客户端的请求都交给Flask程序实例
- Flask使用Werkzeug来做路由分发(URL请求和视图函数之间的对应关系)。根据每个URL请求,找到具体的视图函数。
- 在Flask程序中,路由一般是通过程序实例的装饰器实现。通过调用视图函数,获取到数据后,把数据传入HTML模板文件中,模板引擎负责渲染HTTP响应数据,然后由Flask返回响应数据给浏览器,最后浏览器显示返回的结果。
为什么要用Web框架
web网站发展至今,特别是服务器端,涉及到的知识、内容,非常广泛。这对程序员的要求会越来越高。如果采用成熟,稳健的框架,那么一些基础的工作,比如,网络操作、数据库访问、会话管理等都可以让框架来处理,那么程序开发人员可以把精力放在具体的业务逻辑上面。使用Web框架开发Web应用程序可以降低开发难度,提高开发效率。
总结一句话:避免重复造轮子。
Flask框架的诞生
Flask诞生于2010年,是Armin ronacher(人名)用Python语言基于Werkzeug工具箱编写的轻量级Web开发框架。它主要面向需求简单的小应用。
Flask本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展Flask-Mail,用户认证Flask-Login),都需要用第三方的扩展来实现。比如可以用Flask-extension加入ORM、窗体验证工具,文件上传、身份验证等。Flask没有默认使用的数据库,你可以选择MySQL,也可以用NoSQL。其 WSGI 工具箱采用 Werkzeug(路由模块) ,模板引擎则使用 Jinja2 。
可以说Flask框架的核心就是Werkzeug和Jinja2。
Python最出名的框架要数Django,此外还有Flask、Tornado等框架。虽然Flask不是最出名的框架,但是Flask应该算是最灵活的框架之一,这也是Flask受到广大开发者喜爱的原因。
Flask扩展包
- Flask-SQLalchemy:操作数据库;
- Flask-migrate:管理迁移数据库;
- Flask-Mail:邮件;
- Flask-WTF:表单;
- Flask-script:插入脚本;
- Flask-Login:认证用户状态;
- Flask-RESTful:开发REST API的工具;
- Flask-Bootstrap:集成前端TwitterBootstrap框架;
- Flask-Moment:本地化日期和时间;
Flask官方文档:
中文文档
安装环境
使用虚拟环境安装Flask,可以避免包的混乱和版本的冲突,虚拟环境是Python解释器的副本,在虚拟环境中你可以安装扩展包,为每个程序单独创建的虚拟环境,可以保证程序只能访问虚拟环境中的包。而不会影响系统中安装的全局Python解释器,从而保证全局解释器的整洁。
虚拟环境使用virtualenv创建,可以查看系统是否安装了virtualenv:
$ virtualenv --version
安装虚拟环境(须在联网状态下)
$ sudo pip install virtualenv
$ sudo pip install virtualenvwrapper
安装完虚拟环境后,如果提示找不到mkvirtualenv命令,须配置环境变量:
# 1、创建目录用来存放虚拟环境
mkdir $HOME/.virtualenvs
# 2、打开~/.bashrc文件,并添加如下:
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
# 3、运行
source ~/.bashrc
创建虚拟环境(ubuntu里须在联网状态下)
$ mkvirtualenv Flask_py
进入虚拟环境
$ workon Flask_py
退出虚拟环境
如果所在环境为真实环境,会提示deactivate:未找到命令
$ deactivate Flask_py
安装Flask
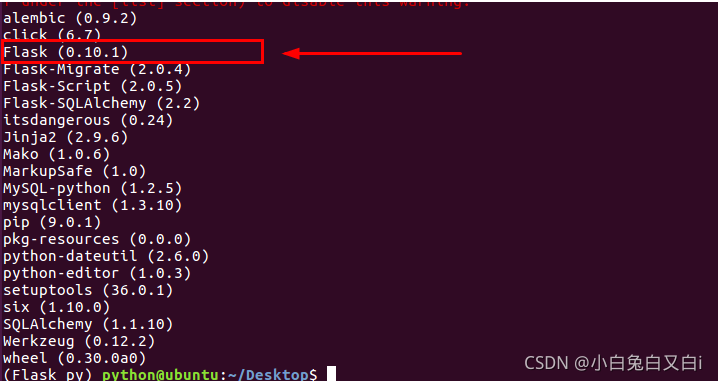
指定Flask版本安装
$ pip install flask==0.10.1
Mac系统:
$ easy_install flask==0.10.1
安装Flask依赖包
安装依赖包(须在虚拟环境中): 依赖就是开发以及程序运行需要使用的环境的集合。包括软件、插件等。我们一般会把需要使用的依赖给保存在一个文件中,命名为requirements的txt文件。如果在其它环境中要运行我们的项目,直接通过指令可以一次性安装所有依赖。
安装依赖包(须在虚拟环境中):
$ pip install -r requirements.txt
生成依赖包(须在虚拟环境中):
$ pip freeze > requirements.txt
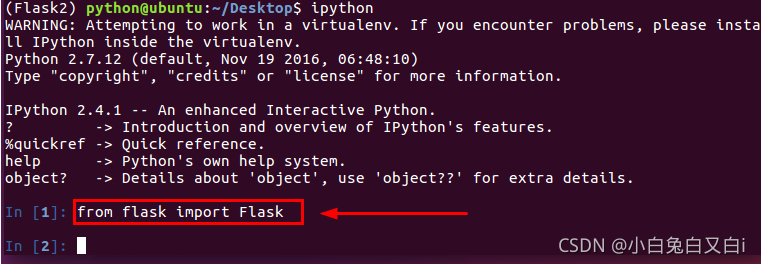
在ipython中测试安装是否成功
$ from flask import Flask
视图
从 Hello World 开始
Flask程序运行过程:
所有Flask程序必须有一个程序实例。
Flask调用视图函数后,会将视图函数的返回值作为响应的内容,返回给客户端。一般情况下,响应内容主要是字符串和状态码。
当客户端想要获取资源时,一般会通过浏览器发起HTTP请求。此时,Web服务器使用WSGI(Web Server Gateway Interface)协议,把来自客户端的所有请求都交给Flask程序实例。WSGI是为 Python 语言定义的Web服务器和Web应用程序之间的一种简单而通用的接口,它封装了接受HTTP请求、解析HTTP请求、发送HTTP,响应等等的这些底层的代码和操作,使开发者可以高效的编写Web应用。
程序实例使用Werkzeug来做路由分发(URL请求和视图函数之间的对应关系)。根据每个URL请求,找到具体的视图函数。 在Flask程序中,路由的实现一般是通过程序实例的route装饰器实现。route装饰器内部会调用add_url_route()方法实现路由注册。
调用视图函数,获取响应数据后,把数据传入HTML模板文件中,模板引擎负责渲染响应数据,然后由Flask返回响应数据给浏览器,最后浏览器处理返回的结果显示给客户端。
示例:
新建文件hello.py:
# 导入Flask类
from flask import Flask
#Flask类接收一个参数__name__
app = Flask(__name__)
# 装饰器的作用是将路由映射到视图函数index
@app.route('/')
def index():
return 'Hello World'
# Flask应用程序实例的run方法启动WEB服务器
if __name__ == '__main__':
app.run()
查看视图函数中的路由:
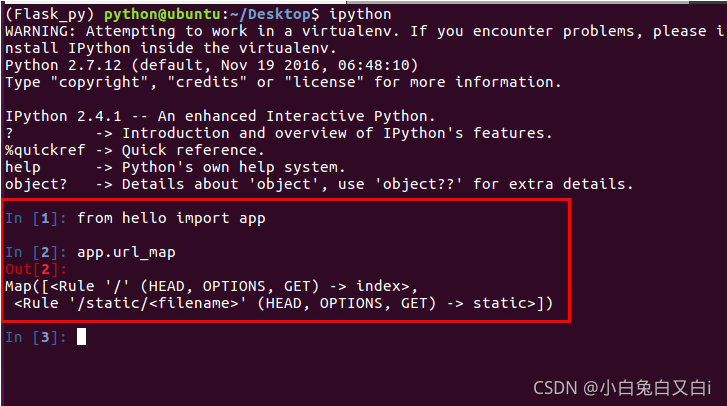
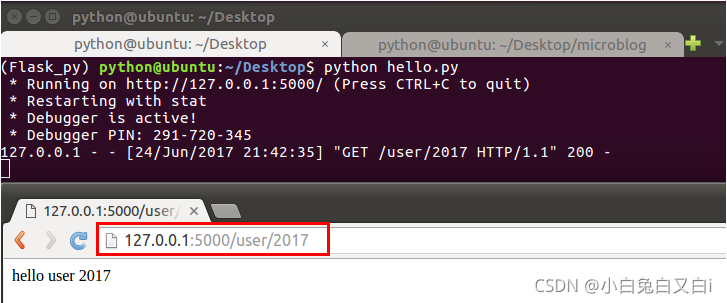
给路由传参示例:
有时我们需要将同一类URL映射到同一个视图函数处理,比如:使用同一个视图函数 来显示不同用户的个人信息。
# 路由传递的参数默认当做string处理,这里指定int,尖括号中冒号后面的内容是动态的
@app.route('/user/<int:id>')
def hello_itcast(id):
return 'hello itcast %d' %id
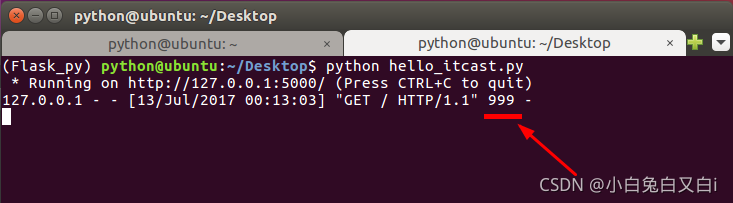
返回状态码示例:
return后面可以自主定义状态码(即使这个状态码不存在)。当客户端的请求已经处理完成,由视图函数决定返回给客户端一个状态码,告知客户端这次请求的处理结果。
@app.route('/')
def hello_itcast():
return 'hello itcast',999
abort函数:
如果在视图函数执行过程中,出现了异常错误,我们可以使用abort函数立即终止视图函数的执行。通过abort函数,可以向前端返回一个http标准中存在的错误状态码,表示出现的错误信息。
使用abort抛出一个http标准中不存在的自定义的状态码,没有实际意义。如果abort函数被触发,其后面的语句将不会执行。其类似于python中raise。
from flask import Flask,abort
@app.route('/')
def hello_itcast():
abort(404)
return 'hello itcast',999
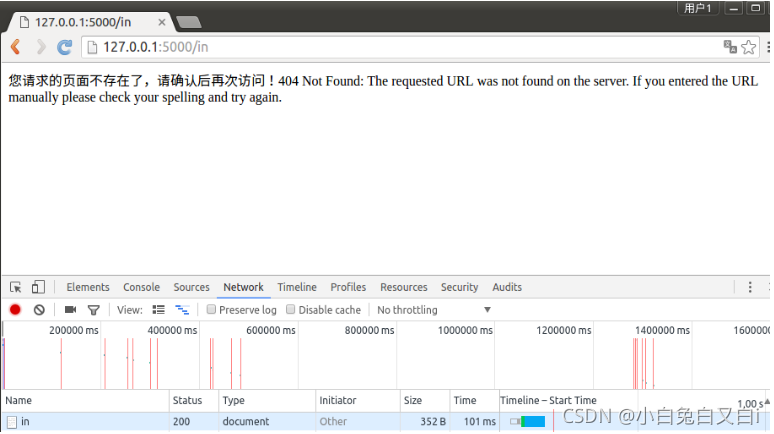
捕获异常:
在Flask中通过装饰器来实现捕获异常,errorhandler()接收的参数为异常状态码。视图函数的参数,返回的是错误信息。
@app.errorhandler(404)
def error(e):
return '您请求的页面不存在了,请确认后再次访问!%s'%e
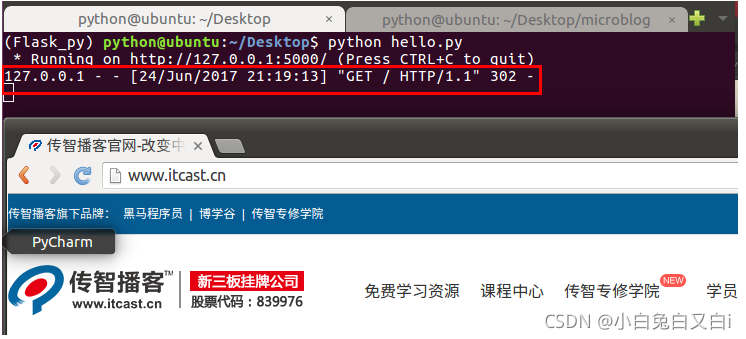
重定向redirect示例
from flask import redirect
@app.route('/')
def hello_itcast():
return redirect('http://www.itcast.cn')
正则URL示例:
正则URL是为了匹配指定的URL,而匹配指定的URL则可以达到限制访问,以及优化访问路径的目的。
from flask import Flask
from werkzeug.routing import BaseConverter
class Regex_url(BaseConverter):
def __init__(self,url_map,*args):
super(Regex_url,self).__init__(url_map)
self.regex = args[0]
app = Flask(__name__)
app.url_map.converters['re'] = Regex_url
@app.route('/user/<re("[a-z]{3}"):id>')
def hello_itcast(id):
return 'hello %s' %id
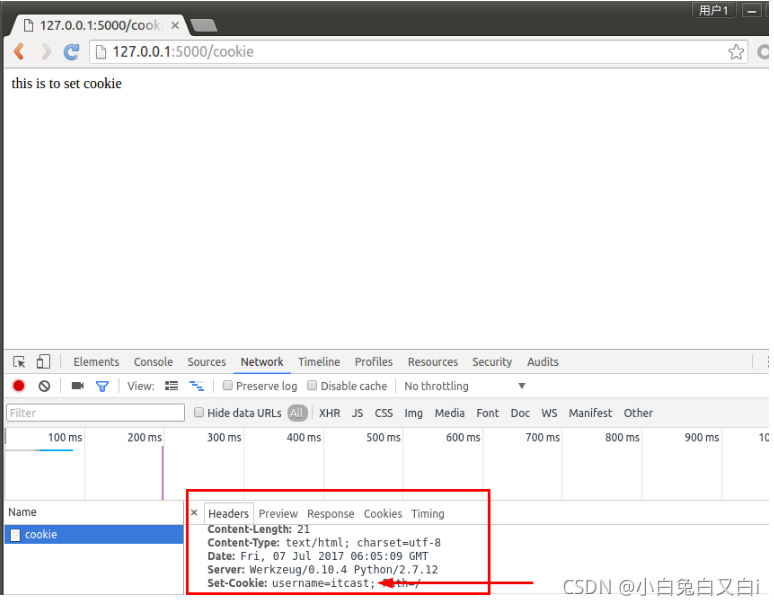
设置cookie和获取cookie
from flask import Flask,make_response
@app.route('/cookie')
def set_cookie():
resp = make_response('this is to set cookie')
resp.set_cookie('username', 'itcast')
return resp
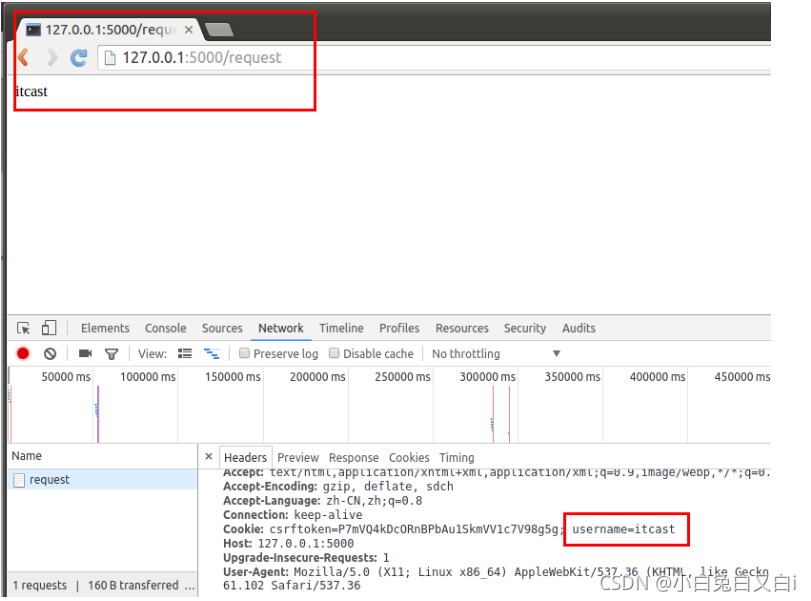
from flask import Flask,request
#获取cookie
@app.route('/request')
def resp_cookie():
resp = request.cookies.get('username')
return resp
扩展
上下文:相当于一个容器,保存了Flask程序运行过程中的一些信息。
Flask中有两种上下文,请求上下文和应用上下文。
请求上下文(request context)
request和session都属于请求上下文对象。
request:封装了HTTP请求的内容,针对的是http请求。举例:user = request.args.get(‘user’),获取的是get请求的参数。
session:用来记录请求会话中的信息,针对的是用户信息。举例:session[‘name’] = user.id,可以记录用户信息。还可以通过session.get(‘name’)获取用户信息。
应用上下文(application context)
current_app和g都属于应用上下文对象。
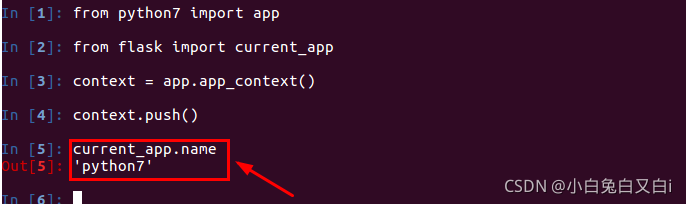
current_app:表示当前运行程序文件的程序实例。我们可以通过current_app.name打印出当前应用程序实例的名字。
g:处理请求时,用于临时存储的对象,每次请求都会重设这个变量。比如:我们可以获取一些临时请求的用户信息。
- 当调用app = Flask(name)的时候,创建了程序应用对象app;
- request 在每次http请求发生时,WSGI
server调用Flask.call();然后在Flask内部创建的request对象; - app的生命周期大于request和g,一个app存活期间,可能发生多次http请求,所以就会有多个request和g。
- 最终传入视图函数,通过return、redirect或render_template生成response对象,返回给客户端。
区别: 请求上下文:保存了客户端和服务器交互的数据。 应用上下文:在flask程序运行过程中,保存的一些配置信息,比如程序文件名、数据库的连接、用户信息等。
请求钩子
在客户端和服务器交互的过程中,有些准备工作或扫尾工作需要处理,比如:在请求开始时,建立数据库连接;在请求结束时,指定数据的交互格式。为了让每个视图函数避免编写重复功能的代码,Flask提供了通用设施的功能,即请求钩子。
请求钩子是通过装饰器的形式实现,Flask支持如下四种请求钩子:
before_first_request:在处理第一个请求前运行。
before_request:在每次请求前运行。
after_request:如果没有未处理的异常抛出,在每次请求后运行。
teardown_request:在每次请求后运行,即使有未处理的异常抛出。
Flask装饰器路由的实现:
Flask有两大核心:Werkzeug和Jinja2。Werkzeug实现路由、调试和Web服务器网关接口。Jinja2实现了模板。
Werkzeug是一个遵循WSGI协议的python函数库。其内部实现了很多Web框架底层的东西,比如request和response对象;与WSGI规范的兼容;支持Unicode;支持基本的会话管理和签名Cookie;集成URL请求路由等。
Werkzeug库的routing模块负责实现URL解析。不同的URL对应不同的视图函数,routing模块会对请求信息的URL进行解析,匹配到URL对应的视图函数,以此生成一个响应信息。
routing模块内部有Rule类(用来构造不同的URL模式的对象)、Map类(存储所有的URL规则)、MapAdapter类(负责具体URL匹配的工作);
Flask-Script扩展命令行
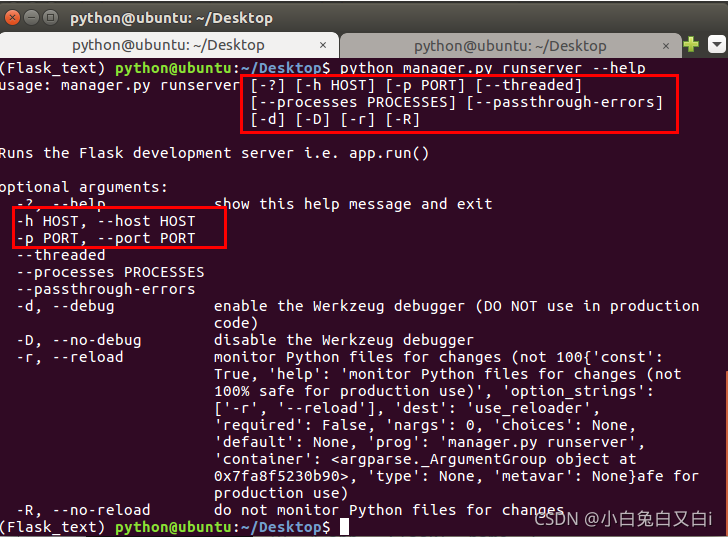
通过使用Flask-Script扩展,我们可以在Flask服务器启动的时候,通过命令行的方式传入参数。而不仅仅通过app.run()方法中传参,比如我们可以通过python hello.py runserver --host ip地址,告诉服务器在哪个网络接口监听来自客户端的连接。默认情况下,服务器只监听来自服务器所在计算机发起的连接,即localhost连接。
我们可以通过python hello.py runserver --help来查看参数。
from flask import Flask
from flask_script import Manager
app = Flask(__name__)
manager = Manager(app)
@app.route('/')
def index():
return '床前明月光'
if __name__ == "__main__":
manager.run()
模板
在前面的示例中,视图函数的主要作用是生成请求的响应,这是最简单的请求。实际上,视图函数有两个作用:处理业务逻辑和返回响应内容。在大型应用中,把业务逻辑和表现内容放在一起,会增加代码的复杂度和维护成本。本节学到的模板,它的作用即是承担视图函数的另一个作用,即返回响应内容。
模板其实是一个包含响应文本的文件,其中用占位符(变量)表示动态部分,告诉模板引擎其具体值需要从使用的数据中获取。使用真实值替换变量,再返回最终得到的字符串,这个过程称为“渲染”。
Flask使用Jinja2这个模板引擎来渲染模板。Jinja2能识别所有类型的变量,包括{}。 Jinja2模板引擎,Flask提供的render_template函数封装了该模板引擎,render_template函数的第一个参数是模板的文件名,后面的参数都是键值对,表示模板中变量对应的真实值。
Jinja2官方文档(http://docs.jinkan.org/docs/jinja2/)
我们先来认识下模板的基本语法:
{% if user %}
{{ user }}
{% else %}
hello!
<ul>
{% for index in indexs %}
<li> {{ index }} </li>
{% endfor %}
</ul>
通过修改一下前面的示例,来学习下模板的简单使用:
@app.route('/')
def hello_itcast():
return render_template('index.html')
@app.route('/user/<name>')
def hello_user(name):
return render_template('index.html',name=name)
变量
在模板中{{ variable }}结构表示变量,是一种特殊的占位符,告诉模板引擎这个位置的值,从渲染模板时使用的数据中获取;Jinja2除了能识别基本类型的变量,还能识别{};
<p>{{mydict['key']}}</p>
<p>{{mylist[1]}}</p>
<p>{{mylist[myvariable]}}</p>
from flask import Flask,render_template
app = Flask(__name__)
@app.route('/')
def index():
mydict = {'key':'silence is gold'}
mylist = ['Speech', 'is','silver']
myintvar = 0
return render_template('vars.html',
mydict=mydict,
mylist=mylist,
myintvar=myintvar
)
if __name__ == '__main__':
app.run(debug=True)
反向路由:
Flask提供了url_for()辅助函数,可以使用程序URL映射中保存的信息生成URL;url_for()接收视图函数名作为参数,返回对应的URL;
如调用url_for(‘index’,_external=True)返回的是绝对地址,在下面这个示例中是http://127.0.0.1:5000/index。
@app.route('/index')
def index():
return render_template('index.html')
@app.route('/user/')
def redirect():
return url_for('index',_external=True)
自定义错误页面:
from flask import Flask,render_template
@app.errorhandler(404)
def page_not_found(e):
return render_template('404.html'), 404
过滤器:
过滤器的本质就是函数。有时候我们不仅仅只是需要输出变量的值,我们还需要修改变量的显示,甚至格式化、运算等等,这就用到了过滤器。
过滤器的使用方式为:变量名 | 过滤器。 过滤器名写在变量名后面,中间用 | 分隔。如:{{variable | capitalize}},这个过滤器的作用:把变量variable的值的首字母转换为大写,其他字母转换为小写。 其他常用过滤器如下:
字符串操作:
safe:禁用转义;
<p>{{ '<em>hello</em>' | safe }}</p>
capitalize:把变量值的首字母转成大写,其余字母转小写;
<p>{{ 'hello' | capitalize }}</p>
lower:把值转成小写;
<p>{{ 'HELLO' | lower }}</p>
upper:把值转成大写;
<p>{{ 'hello' | upper }}</p>
title:把值中的每个单词的首字母都转成大写;
<p>{{ 'hello' | title }}</p>
trim:把值的首尾空格去掉;
<p>{{ ' hello world ' | trim }}</p>
reverse:字符串反转;
<p>{{ 'olleh' | reverse }}</p>
format:格式化输出;
<p>{{ '%s is %d' | format('name',17) }}</p>
striptags:渲染之前把值中所有的HTML标签都删掉;
<p>{{ '<em>hello</em>' | striptags }}</p>
列表操作
first:取第一个元素
<p>{{ [1,2,3,4,5,6] | first }}</p>
last:取最后一个元素
<p>{{ [1,2,3,4,5,6] | last }}</p>
length:获取列表长度
<p>{{ [1,2,3,4,5,6] | length }}</p>
sum:列表求和
<p>{{ [1,2,3,4,5,6] | sum }}</p>
sort:列表排序
<p>{{ [6,2,3,1,5,4] | sort }}</p>
语句块过滤(不常用):
{% filter upper %}
this is a Flask Jinja2 introduction
{% endfilter %}
自定义过滤器:
过滤器的本质是函数。当模板内置的过滤器不能满足需求,可以自定义过滤器。自定义过滤器有两种实现方式:一种是通过Flask应用对象的add_template_filter方法。还可以通过装饰器来实现自定义过滤器。
自定义的过滤器名称如果和内置的过滤器重名,会覆盖内置的过滤器。
**实现方式一:**通过调用应用程序实例的add_template_filter方法实现自定义过滤器。该方法第一个参数是函数名,第二个参数是自定义的过滤器名称。
def filter_double_sort(ls):
return ls[::2]
app.add_template_filter(filter_double_sort,'double_2')
**实现方式二:**用装饰器来实现自定义过滤器。装饰器传入的参数是自定义的过滤器名称。
@app.template_filter('db3')
def filter_double_sort(ls):
return ls[::-3]
Web表单:
web表单是web应用程序的基本功能。
它是HTML页面中负责数据采集的部件。表单有三个部分组成:表单标签、表单域、表单按钮。表单允许用户输入数据,负责HTML页面数据采集,通过表单将用户输入的数据提交给服务器。
在Flask中,为了处理web表单,我们一般使用Flask-WTF扩展,它封装了WTForms,并且它有验证表单数据的功能。
WTForms支持的HTML标准字段

WTForms常用验证函数
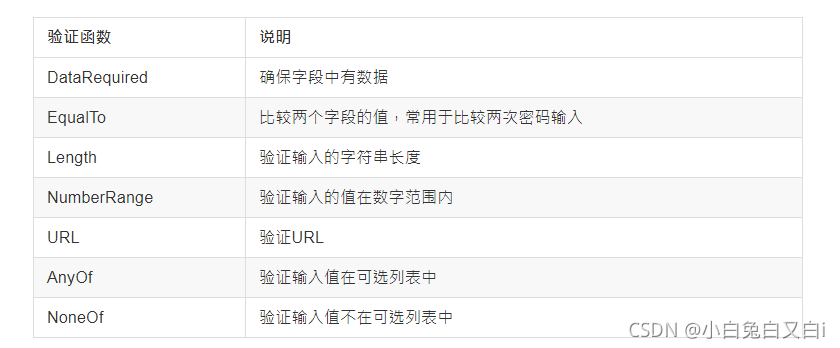
使用Flask-WTF需要配置参数SECRET_KEY。
CSRF_ENABLED是为了CSRF(跨站请求伪造)保护。 SECRET_KEY用来生成加密令牌,当CSRF激活的时候,该设置会根据设置的密匙生成加密令牌。
在HTML页面中直接写form表单:
#模板文件
<form method='post'>
<input type="text" name="username" placeholder='Username'>
<input type="password" name="password" placeholder='password'>
<input type="submit">
</form>
视图函数中获取表单数据:
from flask import Flask,render_template,request
@app.route('/login',methods=['GET','POST'])
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
print username,password
return render_template('login.html',method=request.method)
使用Flask-WTF实现表单。
配置参数:
app.config['SECRET_KEY'] = 'silents is gold'
模板页面:
<form method="post">
#设置csrf_token
{{ form.csrf_token() }}
{{ form.us.label }}
<p>{{ form.us }}</p>
{{ form.ps.label }}
<p>{{ form.ps }}</p>
{{ form.ps2.label }}
<p>{{ form.ps2 }}</p>
<p>{{ form.submit() }}</p>
{% for x in get_flashed_messages() %}
{{ x }}
{% endfor %}
</form>
视图函数:
#coding=utf-8
from flask import Flask,render_template,\
redirect,url_for,session,request,flash
#导入wtf扩展的表单类
from flask_wtf import FlaskForm
#导入自定义表单需要的字段
from wtforms import SubmitField,StringField,PasswordField
#导入wtf扩展提供的表单验证器
from wtforms.validators import DataRequired,EqualTo
app = Flask(__name__)
app.config['SECRET_KEY']='1'
#自定义表单类,文本字段、密码字段、提交按钮
class Login(Form):
us = StringField(label=u'用户:',validators=[DataRequired()])
ps = PasswordField(label=u'密码',validators=[DataRequired(),EqualTo('ps2','err')])
ps2 = PasswordField(label=u'确认密码',validators=[DataRequired()])
submit = SubmitField(u'提交')
@app.route('/login')
def login():
return render_template('login.html')
#定义根路由视图函数,生成表单对象,获取表单数据,进行表单数据验证
@app.route('/',methods=['GET','POST'])
def index():
form = Login()
if form.validate_on_submit():
name = form.us.data
pswd = form.ps.data
pswd2 = form.ps2.data
print name,pswd,pswd2
return redirect(url_for('login'))
else:
if request.method=='POST':
flash(u'信息有误,请重新输入!')
print form.validate_on_submit()
return render_template('index.html',form=form)
if __name__ == '__main__':
app.run(debug=True)
控制语句
常用的几种控制语句:
模板中的if控制语句
@app.route('/user')
def user():
user = 'dongGe'
return render_template('user.html',user=user)
<html>
<head>
{% if user %}
<title> hello {{user}} </title>
{% else %}
<title> welcome to flask </title>
{% endif %}
</head>
<body>
<h1>hello world</h1>
</body>
</html>
模板中的for循环语句
@app.route('/loop')
def loop():
fruit = ['apple','orange','pear','grape']
return render_template('loop.html',fruit=fruit)
<html>
<head>
{% if user %}
<title> hello {{user}} </title>
{% else %}
<title> welcome to flask </title>
{% endif %}
</head>
<body>
<h1>hello world</h1>
<ul>
{% for index in fruit %}
<li>{{ index }}</li>
{% endfor %}
</ul>
</body>
</html>
宏、继承、包含
类似于python中的函数,宏的作用就是在模板中重复利用代码,避免代码冗余。
Jinja2支持宏,还可以导入宏,需要在多处重复使用的模板代码片段可以写入单独的文件,再包含在所有模板中,以避免重复。
定义宏
{% macro input() %}
<input type="text"
name="username"
value=""
size="30"/>
{% endmacro %}
调用宏
{{ input() }}
定义带参数的宏
{% macro input(name,value='',type='text',size=20) %}
<input type="{{ type }}"
name="{{ name }}"
value="{{ value }}"
size="{{ size }}"/>
{% endmacro %}
调用宏,并传递参数
{{ input(value='name',type='password',size=40)}}
把宏单独抽取出来,封装成html文件,其它模板中导入使用
文件名可以自定义macro.html
{% macro function() %}
<input type="text" name="username" placeholde="Username">
<input type="password" name="password" placeholde="Password">
<input type="submit">
{% endmacro %}
在其它模板文件中先导入,再调用
{% import 'macro.html' as func %}
{% func.function() %}
模板继承:
模板继承是为了重用模板中的公共内容。一般Web开发中,继承主要使用在网站的顶部菜单、底部。这些内容可以定义在父模板中,子模板直接继承,而不需要重复书写。
{% block top %}``{% endblock %}标签定义的内容,相当于在父模板中挖个坑,当子模板继承父模板时,可以进行填充。
子模板使用extends指令声明这个模板继承自哪?父模板中定义的块在子模板中被重新定义,在子模板中调用父模板的内容可以使用super()。
父模板:base.html
{% block top %}
顶部菜单
{% endblock top %}
{% block content %}
{% endblock content %}
{% block bottom %}
底部
{% endblock bottom %}
子模板:
{% extends 'base.html' %}
{% block content %}
需要填充的内容
{% endblock content %}
- 模板继承使用时注意点:
- 不支持多继承。
- 为了便于阅读,在子模板中使用extends时,尽量写在模板的第一行。
- 不能在一个模板文件中定义多个相同名字的block标签。
- 当在页面中使用多个block标签时,建议给结束标签起个名字,当多个block嵌套时,阅读性更好。
包含(Include)
Jinja2模板中,除了宏和继承,还支持一种代码重用的功能,叫包含(Include)。它的功能是将另一个模板整个加载到当前模板中,并直接渲染。
示例:
include的使用
{\% include 'hello.html' %}
包含在使用时,如果包含的模板文件不存在时,程序会抛出TemplateNotFound异常,可以加上ignore missing关键字。如果包含的模板文件不存在,会忽略这条include语句。
示例:
include的使用加上关键字ignore missing
{\% include 'hello.html' ignore missing %}
宏、继承、包含:
- 宏(Macro)、继承(Block)、包含(include)均能实现代码的复用。
- 继承(Block)的本质是代码替换,一般用来实现多个页面中重复不变的区域。
- 宏(Macro)的功能类似函数,可以传入参数,需要定义、调用。
- 包含(include)是直接将目标模板文件整个渲染出来。
Flask中的特殊变量和方法:
在Flask中,有一些特殊的变量和方法是可以在模板文件中直接访问的。
config 对象:
config 对象就是Flask的config对象,也就是 app.config 对象。
{{ config.SQLALCHEMY_DATABASE_URI }}
request 对象:
就是 Flask 中表示当前请求的 request 对象,request对象中保存了一次HTTP请求的一切信息。
request常用的属性如下:
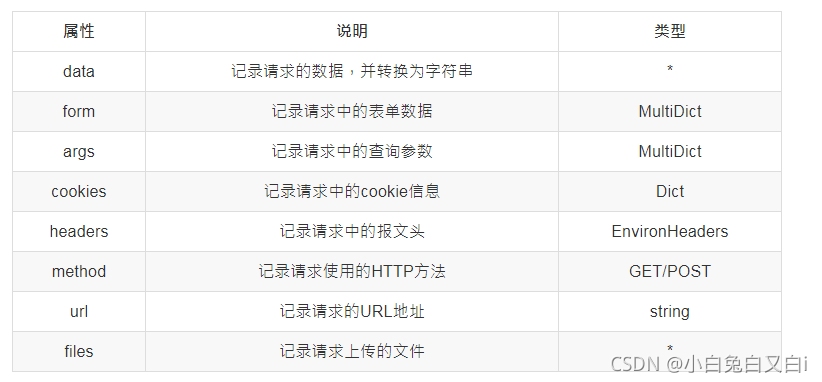
{{ request.url }}
url_for 方法:
url_for() 会返回传入的路由函数对应的URL,所谓路由函数就是被 app.route() 路由装饰器装饰的函数。如果我们定义的路由函数是带有参数的,则可以将这些参数作为命名参数传入。
{{ url_for('index') }}
{{ url_for('post', post_id=1024) }}
get_flashed_messages方法:
返回之前在Flask中通过 flash() 传入的信息列表。把字符串对象表示的消息加入到一个消息队列中,然后通过调用 get_flashed_messages() 方法取出。
{% for message in get_flashed_messages() %}
{{ message }}
{% endfor %}
数据库
数据库的设置
Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在表中,表用来给应用的实体建模,表的列数是固定的,行数是可变的。它使用结构化的查询语言。关系型数据库的列定义了表中表示的实体的数据属性。比如:商品表里有name、price、number等。
Flask本身不限定数据库的选择,你可以选择SQL或NOSQL的任何一种。也可以选择更方便的SQLALchemy,类似于Django的ORM。SQLALchemy实际上是对数据库的抽象,让开发者不用直接和SQL语句打交道,而是通过Python对象来操作数据库,在舍弃一些性能开销的同时,换来的是开发效率的较大提升。
SQLAlchemy是一个关系型数据库框架,它提供了高层的ORM和底层的原生数据库的操作。flask-sqlalchemy是一个简化了SQLAlchemy操作的flask扩展。
数据库安装
安装服务端
sudo apt-get install mysql-server
安装客户端
sudo apt-get install mysql-client
sudo apt-get install libmysqlclient-dev
数据库的基本命令
登录数据库
mysql -u root -p
创建数据库,并设定编码
create database <数据库名> charset=utf8;
显示所有数据库
show databases;
在Flask中使用mysql数据库,需要安装一个flask-sqlalchemy的扩展。
pip install flask-sqlalchemy
要连接mysql数据库,仍需要安装flask-mysqldb
pip install flask-mysqldb
使用Flask-SQLAlchemy管理数据库
使用Flask-SQLAlchemy扩展操作数据库,首先需要建立数据库连接。数据库连接通过URL指定,而且程序使用的数据库必须保存到Flask配置对象的SQLALCHEMY_DATABASE_URI键中。
对比下Django和Flask中的数据库设置:
Django的数据库设置:
Flask的数据库设置:
app.config[‘SQLALCHEMY_DATABASE_URI’] ='mysql://root:mysql@127.0.0.1:3
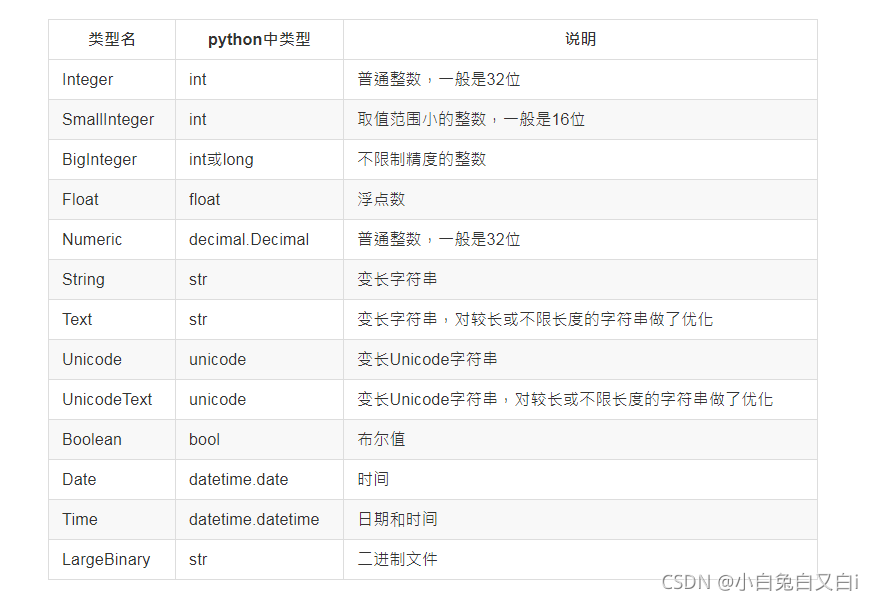
常用的SQLAlchemy字段类型
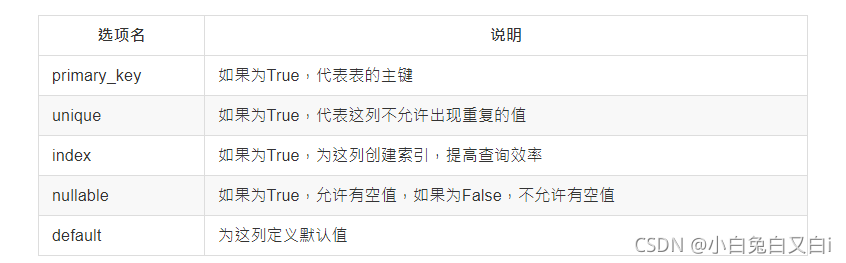
常用的SQLAlchemy列选项
常用的SQLAlchemy关系选项
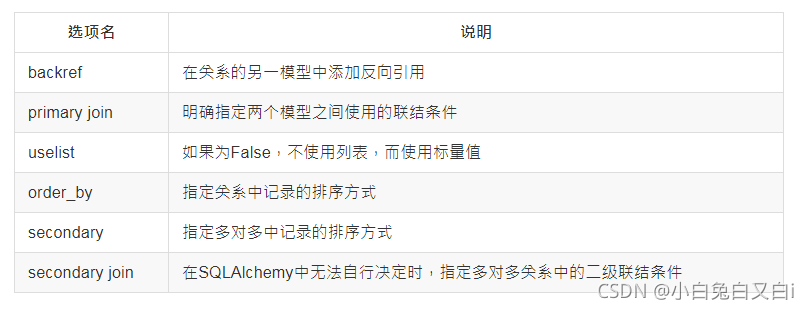
数据库基本操作
在Flask-SQLAlchemy中,插入、修改、删除操作,均由数据库会话管理。会话用db.session表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用commit()方法提交会话。
数据库会话是为了保证数据的一致性,避免因部分更新导致数据不一致。提交操作把会话对象全部写入数据库,如果写入过程发生错误,整个会话都会失效。
数据库会话也可以回滚,通过db.session.rollback()方法,实现会话提交数据前的状态。
在Flask-SQLAlchemy中,查询操作是通过query对象操作数据。最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
将数据添加到会话中示例:
user = User(name='python')
db.session.add(user)
db.session.commit()
在视图函数中定义模型类
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#设置连接数据库的URL
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/Flask_test'
#设置每次请求结束后会自动提交数据库中的改动
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#查询时会显示原始SQL语句
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
class Role(db.Model):
# 定义表名
__tablename__ = 'roles'
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
us = db.relationship('User', backref='role')
#repr()方法显示一个可读字符串
def __repr__(self):
return 'Role:%s'% self.name
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True, index=True)
email = db.Column(db.String(64),unique=True)
pswd = db.Column(db.String(64))
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
def __repr__(self):
return 'User:%s'%self.name
if __name__ == '__main__':
db.drop_all()
db.create_all()
ro1 = Role(name='admin')
ro2 = Role(name='user')
db.session.add_all([ro1,ro2])
db.session.commit()
us1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=ro1.id)
us2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=ro2.id)
us3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=ro2.id)
us4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=ro1.id)
db.session.add_all([us1,us2,us3,us4])
db.session.commit()
app.run(debug=True)
常用的SQLAlchemy查询过滤器

常用的SQLAlchemy查询执行器
创建表:
db.create_all()
删除表
db.drop_all()
插入一条数据
ro1 = Role(name='admin')
db.session.add(ro1)
db.session.commit()
#再次插入一条数据
ro2 = Role(name='user')
db.session.add(ro2)
db.session.commit()
一次插入多条数据
us1 = User(name='wang',email='wang@163.com',pswd='123456',role_id=ro1.id)
us2 = User(name='zhang',email='zhang@189.com',pswd='201512',role_id=ro2.id)
us3 = User(name='chen',email='chen@126.com',pswd='987654',role_id=ro2.id)
us4 = User(name='zhou',email='zhou@163.com',pswd='456789',role_id=ro1.id)
db.session.add_all([us1,us2,us3,us4])
db.session.commit()
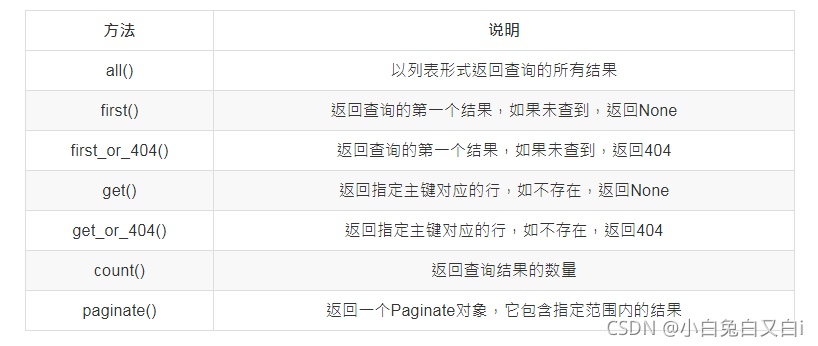
查询:filter_by精确查询
返回名字等于wang的所有人
User.query.filter_by(name='wang').all()

first()返回查询到的第一个对象
User.query.first()
all()返回查询到的所有对象
User.query.all()

filter模糊查询,返回名字结尾字符为g的所有数据。
User.query.filter(User.name.endswith('g')).all()

get(),参数为主键,如果主键不存在没有返回内容
User.query.get()
逻辑非,返回名字不等于wang的所有数据。
User.query.filter(User.name!='wang').all()

逻辑与,需要导入and,返回and()条件满足的所有数据。
from sqlalchemy import and_
User.query.filter(and_(User.name!='wang',User.email.endswith('163.com'))).all()
and_
逻辑或,需要导入or_
from sqlalchemy import or_
User.query.filter(or_(User.name!='wang',User.email.endswith('163.com'))).all()
or_
not_ 相当于取反
from sqlalchemy import not_
User.query.filter(not_(User.name=='chen')).all()
not_

查询数据后删除
user = User.query.first()
db.session.delete(user)
db.session.commit()
User.query.all()
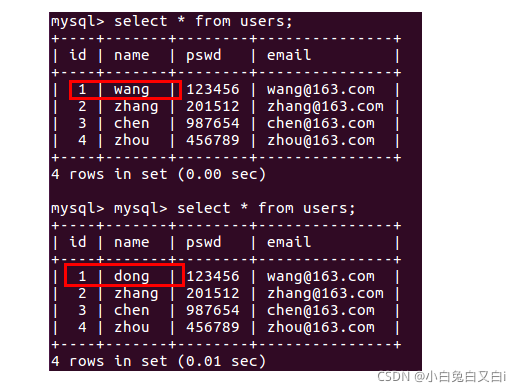
更新数据
user = User.query.first()
user.name = 'dong'
db.session.commit()
User.query.first()
使用update
User.query.filter_by(name='zhang').update({'name':'li'})

关联查询示例:角色和用户的关系是一对多的关系,一个角色可以有多个用户,一个用户只能属于一个角色。
查询角色的所有用户:
#查询roles表id为1的角色
ro1 = Role.query.get(1)
#查询该角色的所有用户
ro1.us

查询用户所属角色:
#查询users表id为3的用户
us1 = User.query.get(3)
#查询用户属于什么角色
us1.role

自定义模型类
定义模型
模型表示程序使用的数据实体,在Flask-SQLAlchemy中,模型一般是Python类,继承自db.Model,db是SQLAlchemy类的实例,代表程序使用的数据库。
类中的属性对应数据库表中的列。id为主键,是由Flask-SQLAlchemy管理。db.Column类构造函数的第一个参数是数据库列和模型属性类型。
如下示例:定义了两个模型类,作者和书名。
#coding=utf-8
from flask import Flask,render_template,redirect,url_for
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
#设置连接数据
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test1'
#设置每次请求结束后会自动提交数据库中的改动
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
#设置成 True,SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#实例化SQLAlchemy对象
db = SQLAlchemy(app)
#定义模型类-作者
class Author(db.Model):
__tablename__ = 'author'
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(32),unique=True)
email = db.Column(db.String(64))
au_book = db.relationship('Book',backref='author')
def __str__(self):
return 'Author:%s' %self.name
#定义模型类-书名
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer,primary_key=True)
info = db.Column(db.String(32),unique=True)
leader = db.Column(db.String(32))
au_book = db.Column(db.Integer,db.ForeignKey('author.id'))
def __str__(self):
return 'Book:%s,%s'%(self.info,self.lead)
创建表 db.create_all()
生成表

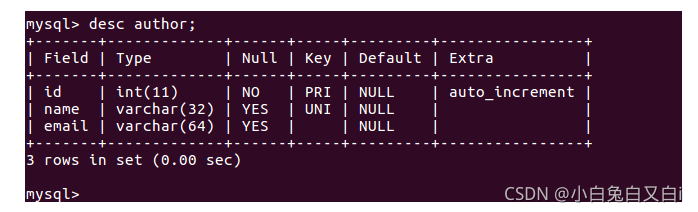
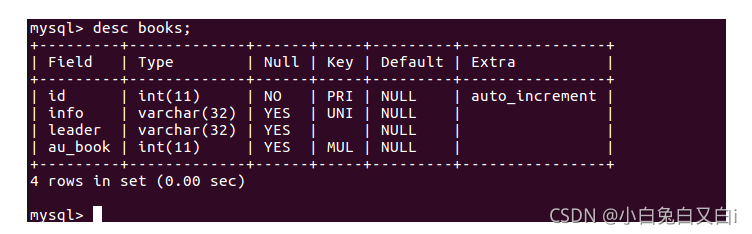
查看author表结构 desc author
查看author
查看books表结构 desc books
#coding=utf-8
from flask import Flask,render_template,url_for,redirect,request
from flask_sqlalchemy import SQLAlchemy
from flask_wtf import FlaskForm
from wtforms.validators import DataRequired
from wtforms import StringField,SubmitField
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@localhost/test1'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
app.config['SECRET_KEY']='s'
db = SQLAlchemy(app)
#创建表单类,用来添加信息
class Append(Form):
au_info = StringField(validators=[DataRequired()])
bk_info = StringField(validators=[DataRequired()])
submit = SubmitField(u'添加')
@app.route('/',methods=['GET','POST'])
def index():
#查询所有作者和书名信息
author = Author.query.all()
book = Book.query.all()
#创建表单对象
form = Append()
if form.validate_on_submit():
#获取表单输入数据
wtf_au = form.au_info.data
wtf_bk = form.bk_info.data
#把表单数据存入模型类
db_au = Author(name=wtf_au)
db_bk = Book(info=wtf_bk)
#提交会话
db.session.add_all([db_au,db_bk])
db.session.commit()
#添加数据后,再次查询所有作者和书名信息
author = Author.query.all()
book = Book.query.all()
return render_template('index.html',author=author,book=book,form=form)
else:
if request.method=='GET':
render_template('index.html', author=author, book=book,form=form)
return render_template('index.html',author=author,book=book,form=form)
#删除作者
@app.route('/delete_author<id>')
def delete_author(id):
#精确查询需要删除的作者id
au = Author.query.filter_by(id=id).first()
db.session.delete(au)
#直接重定向到index视图函数
return redirect(url_for('index'))
#删除书名
@app.route('/delete_book<id>')
def delete_book(id):
#精确查询需要删除的书名id
bk = Book.query.filter_by(id=id).first()
db.session.delete(bk)
#直接重定向到index视图函数
return redirect(url_for('index'))
if __name__ == '__main__':
db.drop_all()
db.create_all()
#生成数据
au_xi = Author(name='我吃西红柿',email='xihongshi@163.com')
au_qian = Author(name='萧潜',email='xiaoqian@126.com')
au_san = Author(name='唐家三少',email='sanshao@163.com')
bk_xi = Book(info='吞噬星空',lead='罗峰')
bk_xi2 = Book(info='寸芒',lead='李杨')
bk_qian = Book(info='飘渺之旅',lead='李强')
bk_san = Book(info='冰火魔厨',lead='融念冰')
#把数据提交给用户会话
db.session.add_all([au_xi,au_qian,au_san,bk_xi,bk_xi2,bk_qian,bk_san])
#提交会话
db.session.commit()
app.run(debug=True)
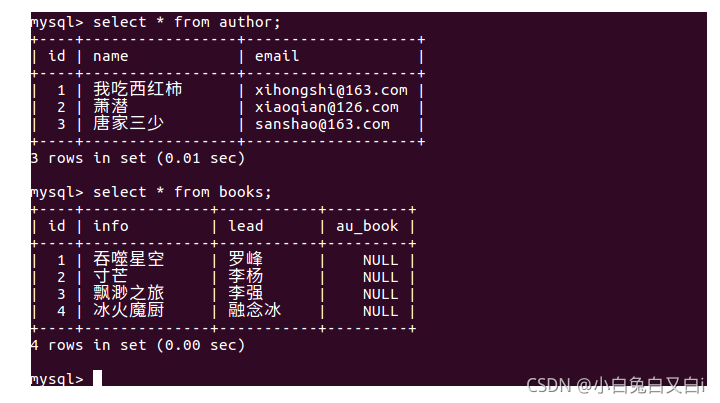
生成数据后,查看数据:
模板页面示例:
<h1>玄幻系列</h1>
<form method="post">
{{ form.csrf_token }}
<p>作者:{{ form.au_info }}</p>
<p>书名:{{ form.bk_info }}</p>
<p>{{ form.submit }}</p>
</form>
<ul>
<li>{% for x in author %}</li>
<li>{{ x }}</li><a href='/delete_author{{ x.id }}'>删除</a>
<li>{% endfor %}</li>
</ul>
<hr>
<ul>
<li>{% for x in book %}</li>
<li>{{ x }}</li><a href='/delete_book{{ x.id }}'>删除</a>
<li>{% endfor %}</li>
</ul>
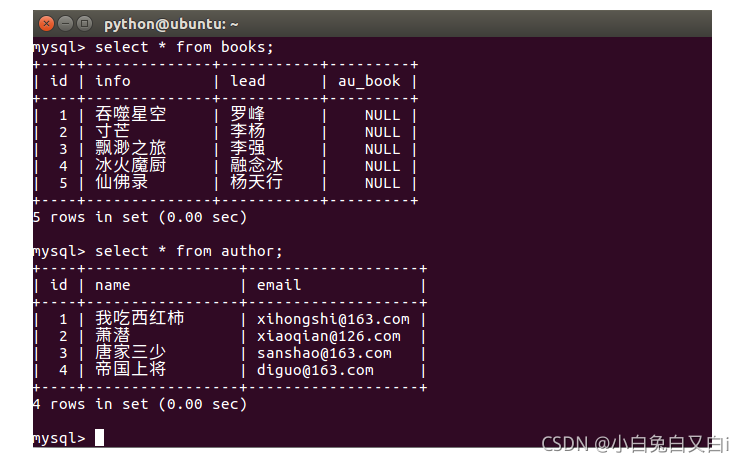
添加数据后,查看数据:
数据库迁移
在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库。最直接的方式就是删除旧表,但这样会丢失数据。
更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化,然后把变动应用到数据库中。
在Flask中可以使用Flask-Migrate扩展,来实现数据迁移。并且集成到Flask-Script中,所有操作通过命令就能完成。
为了导出数据库迁移命令,Flask-Migrate提供了一个MigrateCommand类,可以附加到flask-script的manager对象上。
首先要在虚拟环境中安装Flask-Migrate。
pip install flask-migrate
文件:database.py
#coding=utf-8
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate,MigrateCommand
from flask_script import Shell,Manager
app = Flask(__name__)
manager = Manager(app)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/Flask_test'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
db = SQLAlchemy(app)
#第一个参数是Flask的实例,第二个参数是Sqlalchemy数据库实例
migrate = Migrate(app,db)
#manager是Flask-Script的实例,这条语句在flask-Script中添加一个db命令
manager.add_command('db',MigrateCommand)
#定义模型Role
class Role(db.Model):
# 定义表名
__tablename__ = 'roles'
# 定义列对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return 'Role:'.format(self.name)
#定义用户
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
def __repr__(self):
return 'User:'.format(self.username)
if __name__ == '__main__':
manager.run()
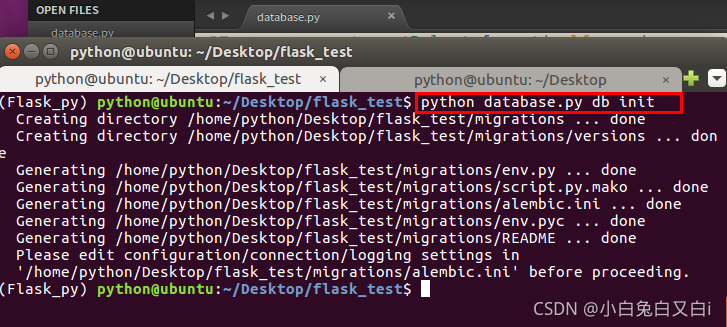
创建迁移仓库
#这个命令会创建migrations文件夹,所有迁移文件都放在里面。
python database.py db init
创建迁移脚本
自动创建迁移脚本有两个函数,upgrade()函数把迁移中的改动应用到数据库中。downgrade()函数则将改动删除。自动创建的迁移脚本会根据模型定义和数据库当前状态的差异,生成upgrade()和downgrade()函数的内容。对比不一定完全正确,有可能会遗漏一些细节,需要进行检查
#创建自动迁移脚本
python database.py db migrate -m 'initial migration'
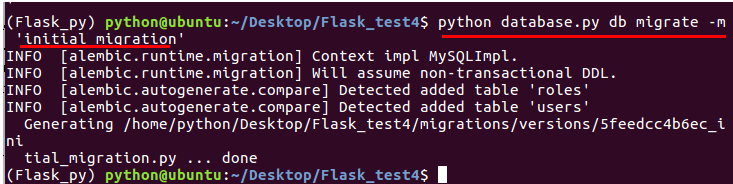
更新数据库
python database.py db upgrade
回退数据库
回退数据库时,需要指定回退版本号,由于版本号是随机字符串,为避免出错,建议先使用python database.py db history命令查看历史版本的具体版本号,然后复制具体版本号执行回退。
python database.py db downgrade 版本号
Flask—Mail
在开发过程中,很多应用程序都需要通过邮件提醒用户,Flask的扩展包Flask-Mail通过包装了Python内置的smtplib包,可以用在Flask程序中发送邮件。
Flask-Mail连接到简单邮件协议(Simple Mail Transfer Protocol,SMTP)服务器,并把邮件交给服务器发送。
如下示例,通过开启QQ邮箱SMTP服务设置,发送邮件。
from flask import Flask
from flask_mail import Mail, Message
app = Flask(__name__)
#配置邮件:服务器/端口/传输层安全协议/邮箱名/密码
app.config.update(
DEBUG = True,
MAIL_SERVER='smtp.qq.com',
MAIL_PROT=465,
MAIL_USE_TLS = True,
MAIL_USERNAME = '371673381@qq.com',
MAIL_PASSWORD = 'goyubxohbtzfbidd',
)
mail = Mail(app)
@app.route('/')
def index():
# sender 发送方,recipients 接收方列表
msg = Message("This is a test ",sender='371673381@qq.com', recipients=['shengjun@itcast.cn','371673381@qq.com'])
#邮件内容
msg.body = "Flask test mail"
#发送邮件
mail.send(msg)
print "Mail sent"
return "Sent Succeed"
if __name__ == "__main__":
app.run()
测试与部署
蓝图Blueprint
为什么学习蓝图?
我们学习Flask框架,是从写单个文件,执行hello world开始的。我们在这单个文件中可以定义路由、视图函数、定义模型等等。但这显然存在一个问题:随着业务代码的增加,将所有代码都放在单个程序文件中,是非常不合适的。这不仅会让代码阅读变得困难,而且会给后期维护带来麻烦。
如下示例:我们在一个文件中写入多个路由,这会使代码维护变得困难。
from flask import Flask
app = Flask(__name__)
@app.route('/')
def index():
return 'index'
@app.route('/list')
def list():
return 'list'
@app.route('/detail')
def detail():
return 'detail'
@app.route('/')
def admin_home():
return 'admin_home'
@app.route('/new')
def new():
return 'new'
@app.route('/edit')
def edit():
return 'edit'
问题:一个程序执行文件中,功能代码过多。就是让代码模块化。根据具体不同功能模块的实现,划分成不同的分类,降低各功能模块之间的耦合度。python中的模块制作和导入就是基于实现功能模块的封装的需求。
尝试用模块导入的方式解决: 我们把上述一个py文件的多个路由视图函数给拆成两个文件:app.py和admin.py文件。app.py文件作为程序启动文件,因为admin文件没有应用程序实例app,在admin文件中要使用app.route路由装饰器,需要把app.py文件的app导入到admin.py文件中。
# 文件app.py
from flask import Flask
# 导入admin中的内容
from admin import *
app = Flask(__name__)
@app.route('/')
def index():
return 'index'
@app.route('/list')
def list():
return 'list'
@app.route('/detail')
def detail():
return 'detail'
if __name__ == '__main__':
app.run()
# 文件admin.py
from app import app
@app.route('/')
def admin_home():
return 'admin_home'
@app.route('/new')
def new():
return 'new'
@app.route('/edit')
def edit():
return 'edit'
启动app.py文件后,我们发现admin.py文件中的路由都无法访问。 ==也就是说,python中的模块化虽然能把代码给拆分开,但不能解决路由映射的问题。 ==
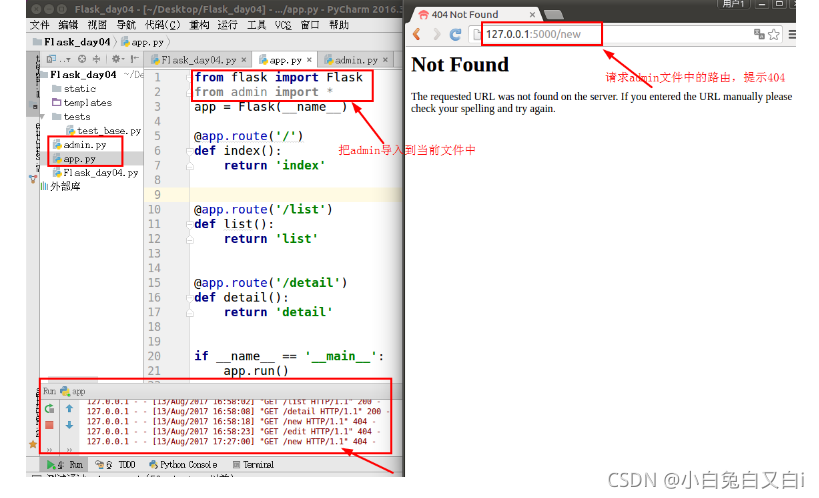
什么是蓝图?
蓝图:用于实现单个应用的视图、模板、静态文件的集合。
蓝图就是模块化处理的类。
简单来说,蓝图就是一个存储操作路由映射方法的容器,主要用来实现客户端请求和URL相互关联的功能。 在Flask中,使用蓝图可以帮助我们实现模块化应用的功能。
蓝图的运行机制:
蓝图是保存了一组将来可以在应用对象上执行的操作。注册路由就是一种操作,当在程序实例上调用route装饰器注册路由时,这个操作将修改对象的url_map路由映射列表。当我们在蓝图对象上调用route装饰器注册路由时,它只是在内部的一个延迟操作记录列表defered_functions中添加了一个项。当执行应用对象的 register_blueprint() 方法时,应用对象从蓝图对象的 defered_functions 列表中取出每一项,即调用应用对象的 add_url_rule() 方法,这将会修改程序实例的路由映射列表。
蓝图的使用:
一、创建蓝图对象。
#Blueprint必须指定两个参数,admin表示蓝图的名称,__name__表示蓝图所在模块
admin = Blueprint('admin',__name__)
二、注册蓝图路由。
@admin.route('/')
def admin_index():
return 'admin_index'
三、在程序实例中注册该蓝图。
app.register_blueprint(admin,url_prefix='/admin')
程序执行文件/test4/test.py
from flask import Flask
#导入蓝图对象
from login import logins
from user import users
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
#注册蓝图,第一个参数logins是蓝图对象,url_prefix参数默认值是根路由,如果指定,会在蓝图注册的路由url中添加前缀。
app.register_blueprint(logins,url_prefix='')
app.register_blueprint(users,url_prefix='')
if __name__ == '__main__':
app.run(debug=True)
创建蓝图:/test4/user.py
from flask import Blueprint,render_template
#创建蓝图,第一个参数指定了蓝图的名字。
users = Blueprint('user',__name__)
@users.route('/user')
def user():
return render_template('user.html')
创建蓝图:/test4/login.py
from flask import Blueprint,render_template
#创建蓝图
logins = Blueprint('login',__name__)
@logins.route('/login')
def login():
return render_template('login.html')
运行/test4/test.py文件
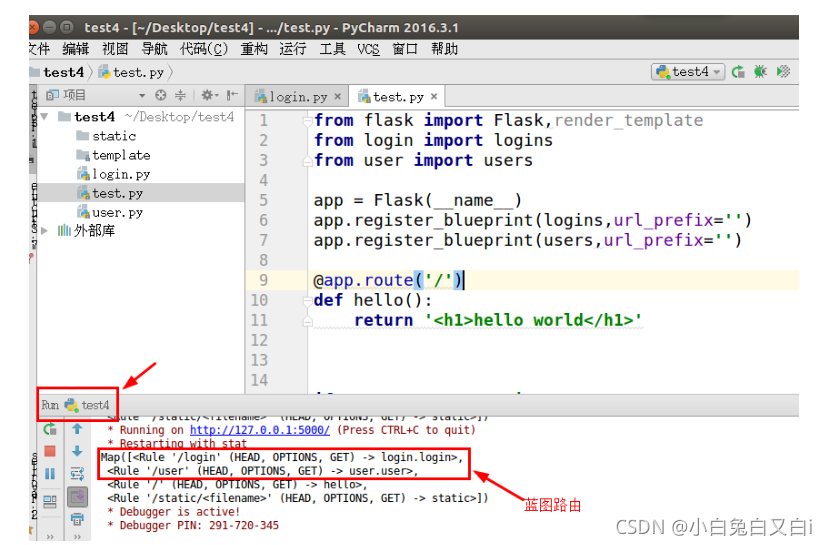
动态路由示例(作者–图书):
文件目录:Flask_test4/delete.py
from flask import Blueprint,redirect,url_for
app_au = Blueprint('app_au',__name__)
app_bk = Blueprint('app_bk',__name__)
from test4 import *
@app_au.route('/delete_au<id>')
def delete_au(id):
del_au = Author.query.filter_by(id=id).first()
db.session.delete(del_au)
db.session.commit()
return redirect(url_for('index'))
@app_bk.route('/delete_bk<id>')
def delete_bk(id):
del_bk = Book.query.filter_by(id=id).first()
db.session.delete(del_bk)
db.session.commit()
return redirect(url_for('index'))
文件目录:Flask_test4/test4.py
#coding=utf-8
#目的:创建两个模型类型,实现数据库的连接和数据的操作
from flask import Flask,render_template,request,redirect,url_for
from flask_sqlalchemy import SQLAlchemy
from flask_wtf import FlaskForm
from wtforms import StringField,SubmitField
from wtforms.validators import DataRequired
#导入delete文件中的蓝图对象
from delete import app_au,app_bk
app = Flask(__name__)
#对数据库连接的基本设置
app.config['SQLALCHEMY_DATABASE_URI']='mysql://root:mysql@localhost/test0'
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True
#把应用程序的实例和SQLAlchemy进行关联
db = SQLAlchemy(app)
app.config['SECRET_KEY'] = 'a'
#自定义表单,实现数据的输入保存操作
class Append(FlaskForm):
author = StringField(validators=[DataRequired()])
book = StringField(validators=[DataRequired()])
submit = SubmitField(u'提交')
#自定义模型类
class Author(db.Model):
__tablename__ = 'authors'
id = db.Column(db.Integer,primary_key=True)
name = db.Column(db.String(32),unique=True)
def __repr__(self):
return 'author:%s'%self.name
class Book(db.Model):
__tablename__ = 'books'
id = db.Column(db.Integer,primary_key=True)
info = db.Column(db.String(32),unique=True)
def __repr__(self):
return 'book:%s'%self.info
@app.route('/',methods=['GET','POST'])
def index():
au = Author.query.all()
bk = Book.query.all()
form = Append()
if form.validate_on_submit():
#从表单中获取数据
wtf_au = form.author.data
wtf_bk = form.book.data
#把数据存入模型类中
db_au = Author(name=wtf_au)
db_bk = Book(info=wtf_bk)
#添加到数据库操作
db.session.add_all([db_au,db_bk])
db.session.commit()
au = Author.query.all()
bk = Book.query.all()
return render_template('index.html',au=au,bk=bk,form=form)
if request.method == 'GET':
return render_template('index.html',au=au,bk=bk,form=form)
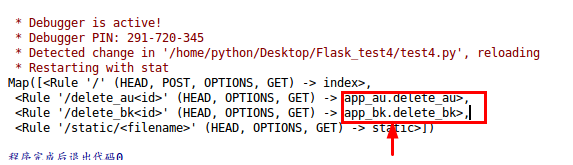
#注册蓝图
app.register_blueprint(app_au)
app.register_blueprint(app_bk)
if __name__ == '__main__':
print app.url_map
app.run(debug=True)
查看蓝图路由:蓝图路由可以分为两块,".“前面的是蓝图名称,”."后面的是视图函数名。
单元测试
为什么要测试?
Web程序开发过程一般包括以下几个阶段:[需求分析,设计阶段,实现阶段,测试阶段]。其中测试阶段通过人工或自动来运行测试某个系统的功能。目的是检验其是否满足需求,并得出特定的结果,以达到弄清楚预期结果和实际结果之间的差别的最终目的。
测试的分类:
测试从软件开发过程可以分为:单元测试、集成测试、系统测试等。在众多的测试中,与程序开发人员最密切的就是单元测试,因为单元测试是由开发人员进行的,而其他测试都由专业的测试人员来完成。所以我们主要学习单元测试。
什么是单元测试?
程序开发过程中,写代码是为了实现需求。当我们的代码通过了编译,只是说明它的语法正确,功能能否实现则不能保证。 因此,当我们的某些功能代码完成后,为了检验其是否满足程序的需求。可以通过编写测试代码,模拟程序运行的过程,检验功能代码是否符合预期。
单元测试就是开发者编写一小段代码,检验目标代码的功能是否符合预期。通常情况下,单元测试主要面向一些功能单一的模块进行。
举个例子:一部手机有许多零部件组成,在正式组装一部手机前,手机内部的各个零部件,CPU、内存、电池、摄像头等,都要进行测试,这就是单元测试。
在Web开发过程中,单元测试实际上就是一些“断言”(assert)代码。
断言就是判断一个函数或对象的一个方法所产生的结果是否符合你期望的那个结果。 python中assert断言是声明布尔值为真的判定,如果表达式为假会发生异常。单元测试中,一般使用assert来断言结果。
断言方法的使用:
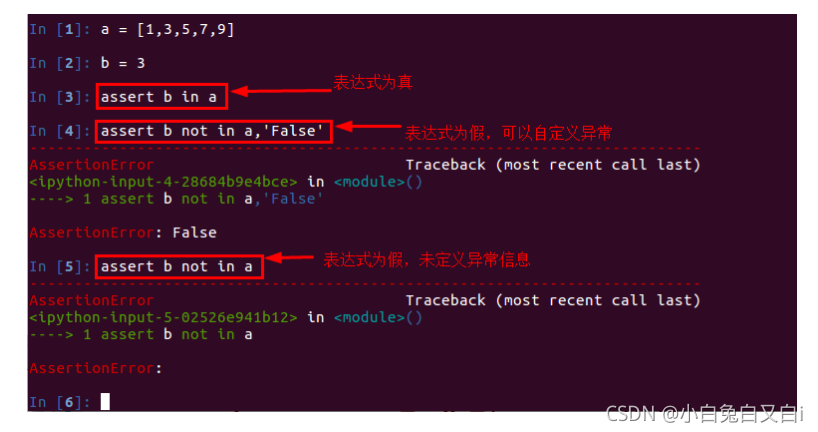
断言语句类似于:
if not expression:
raise AssertionError
常用的断言方法:
assertEqual 如果两个值相等,则pass
assertNotEqual 如果两个值不相等,则pass
assertTrue 判断bool值为True,则pass
assertFalse 判断bool值为False,则pass
assertIsNone 不存在,则pass
assertIsNotNone 存在,则pass
如何测试?
简单的测试用例:1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,
def fibo(x):
if x == 0:
resp = 0
elif x == 1:
resp = 1
else:
return fibo(x-1) + fibo(x-2)
return resp
assert fibo(5) == 5
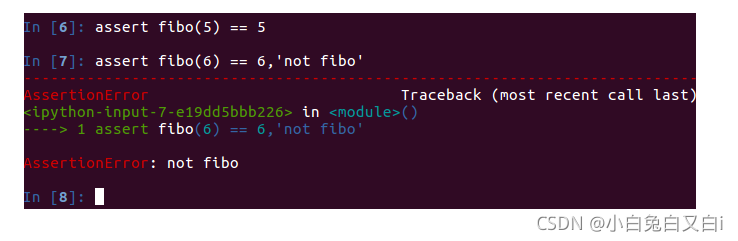
单元测试的基本写法:
首先,定义一个类,继承自unittest.TestCase
import unittest
class TestClass(unitest.TestCase):
pass
其次,在测试类中,定义两个测试方法
import unittest
class TestClass(unittest.TestCase):
#该方法会首先执行,方法名为固定写法
def setUp(self):
pass
#该方法会在测试代码执行完后执行,方法名为固定写法
def tearDown(self):
pass
最后,在测试类中,编写测试代码
import unittest
class TestClass(unittest.TestCase):
#该方法会首先执行,相当于做测试前的准备工作
def setUp(self):
pass
#该方法会在测试代码执行完后执行,相当于做测试后的扫尾工作
def tearDown(self):
pass
#测试代码
def test_app_exists(self):
pass
发送邮件测试:
#coding=utf-8
import unittest
from Flask_day04 import app
class TestCase(unittest.TestCase):
# 创建测试环境,在测试代码执行前执行
def setUp(self):
self.app = app
# 激活测试标志
app.config['TESTING'] = True
self.client = self.app.test_client()
# 在测试代码执行完成后执行
def tearDown(self):
pass
# 测试代码
def test_email(self):
resp = self.client.get('/')
print resp.data
self.assertEqual(resp.data,'Sent Succeed')
数据库测试:
#coding=utf-8
import unittest
from author_book import *
#自定义测试类,setUp方法和tearDown方法会分别在测试前后执行。以test_开头的函数就是具体的测试代码。
class DatabaseTest(unittest.TestCase):
def setUp(self):
app.config['TESTING'] = True
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@localhost/test0'
self.app = app
db.create_all()
def tearDown(self):
db.session.remove()
db.drop_all()
#测试代码
def test_append_data(self):
au = Author(name='itcast')
bk = Book(info='python')
db.session.add_all([au,bk])
db.session.commit()
author = Author.query.filter_by(name='itcast').first()
book = Book.query.filter_by(info='python').first()
#断言数据存在
self.assertIsNotNone(author)
self.assertIsNotNone(book)
部署
当我们执行下面的hello.py时,使用的flask自带的服务器,完成了web服务的启动。在生产环境中,flask自带的服务器,无法满足性能要求,我们这里采用Gunicorn做wsgi容器,来部署flask程序。Gunicorn(绿色独角兽)是一个Python WSGI的HTTP服务器。从Ruby的独角兽(Unicorn )项目移植。该Gunicorn服务器与各种Web框架兼容,实现非常简单,轻量级的资源消耗。Gunicorn直接用命令启动,不需要编写配置文件,相对uWSGI要容易很多。
区分几个概念:
WSGI:全称是Web Server Gateway Interface(web服务器网关接口),它是一种规范,它是web服务器和web应用程序之间的接口。它的作用就像是桥梁,连接在web服务器和web应用框架之间。
uwsgi:是一种传输协议,用于定义传输信息的类型。
uWSGI:是实现了uwsgi协议WSGI的web服务器。
我们的部署方式: nginx + gunicorn + flask
# hello.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return '<h1>hello world</h1>'
if __name__ == '__main__':
app.run(debug=True)
使用Gunicorn:
web开发中,部署方式大致类似。简单来说,前端代理使用Nginx主要是为了实现分流、转发、负载均衡,以及分担服务器的压力。Nginx部署简单,内存消耗少,成本低。Nginx既可以做正向代理,也可以做反向代理。
正向代理:请求经过代理服务器从局域网发出,然后到达互联网上的服务器。
特点:服务端并不知道真正的客户端是谁。
反向代理:请求从互联网发出,先进入代理服务器,再转发给局域网内的服务器。
特点:客户端并不知道真正的服务端是谁。
区别:正向代理的对象是客户端。反向代理的对象是服务端。
安装gunicorn
pip install gunicorn
查看命令行选项: 安装gunicorn成功后,通过命令行的方式可以查看gunicorn的使用信息。
$gunicorn -h
直接运行:
#直接运行,默认启动的127.0.0.1::8000
gunicorn 运行文件名称:Flask程序实例名
指定进程和端口号: -w: 表示进程(worker)。 -b:表示绑定ip地址和端口号(bind)。
$gunicorn -w 4 -b 127.0.0.1:5001 运行文件名称:Flask程序实例名
安装Nginx
$ sudo apt-get install nginx
Nginx配置:
默认安装到/usr/local/nginx/目录,进入目录。
启动nginx:
#启动
sudo sbin/nginx
#查看
ps aux | grep nginx
#停止
sudo sbin/nginx -s stop
打开/usr/local/nginx/conf/nginx.conf文件
erver {
# 监听80端口
listen 80;
# 本机
server_name localhost;
# 默认请求的url
location / {
#请求转发到gunicorn服务器
proxy_pass http://127.0.0.1:5001;
#设置请求头,并将头信息传递给服务器端
proxy_set_header Host $host;
}
}
Restful
2000年,Roy Thomas Fielding博士在他的博士论文《Architectural Styles and the Design of Network-based Software Architectures》中提出了几种软件应用的架构风格,REST作为其中的一种架构风格在这篇论文中进行了概括性的介绍。
REST:Representational State Transfer的缩写,翻译:“具象状态传输”。一般解释为“表现层状态转换”。
REST是设计风格而不是标准。是指客户端和服务器的交互形式。我们需要关注的重点是如何设计REST风格的网络接口。
REST的特点:
具象的。一般指表现层,要表现的对象就是资源。比如,客户端访问服务器,获取的数据就是资源。比如文字、图片、音视频等。
表现:资源的表现形式。txt格式、html格式、json格式、jpg格式等。浏览器通过URL确定资源的位置,但是需要在HTTP请求头中,用Accept和Content-Type字段指定,这两个字段是对资源表现的描述。
状态转换:客户端和服务器交互的过程。在这个过程中,一定会有数据和状态的转化,这种转化叫做状态转换。其中,GET表示获取资源,POST表示新建资源,PUT表示更新资源,DELETE表示删除资源。HTTP协议中最常用的就是这四种操作方式。
RESTful架构:
- 每个URL代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个http动词,对服务器资源进行操作,实现表现层状态转换。
如何设计符合RESTful风格的API:
一、域名:
将api部署在专用域名下:
http://api.example.com
或者将api放在主域名下:
http://www.example.com/api/
二、版本:
将API的版本号放在url中。
http://www.example.com/app/1.0/info
http://www.example.com/app/1.2/info
三、路径:
路径表示API的具体网址。每个网址代表一种资源。 资源作为网址,网址中不能有动词只能有名词,一般名词要与数据库的表名对应。而且名词要使用复数。
错误示例:
http://www.example.com/getGoods
http://www.example.com/listOrders
正确示例:
#获取单个商品
http://www.example.com/app/goods/1
#获取所有商品
http://www.example.com/app/goods
四、使用标准的HTTP方法:
对于资源的具体操作类型,由HTTP动词表示。 常用的HTTP动词有四个。
GET SELECT :从服务器获取资源。
POST CREATE :在服务器新建资源。
PUT UPDATE :在服务器更新资源。
DELETE DELETE :从服务器删除资源。
示例:
#获取指定商品的信息`
GET http://www.example.com/goods/ID
#新建商品的信息
POST http://www.example.com/goods
#更新指定商品的信息
PUT http://www.example.com/goods/ID
#删除指定商品的信息
DELETE http://www.example.com/goods/ID
五、过滤信息:
如果资源数据较多,服务器不能将所有数据一次全部返回给客户端。API应该提供参数,过滤返回结果。 实例:
#指定返回数据的数量
http://www.example.com/goods?limit=10
#指定返回数据的开始位置
http://www.example.com/goods?offset=10
#指定第几页,以及每页数据的数量
http://www.example.com/goods?page=2&per_page=20
六、状态码:
服务器向用户返回的状态码和提示信息,常用的有:
200 OK :服务器成功返回用户请求的数据
201 CREATED :用户新建或修改数据成功。
202 Accepted:表示请求已进入后台排队。
400 INVALID REQUEST :用户发出的请求有错误。
401 Unauthorized :用户没有权限。
403 Forbidden :访问被禁止。
404 NOT FOUND :请求针对的是不存在的记录。
406 Not Acceptable :用户请求的的格式不正确。
500 INTERNAL SERVER ERROR :服务器发生错误。
七、错误信息:
一般来说,服务器返回的错误信息,以键值对的形式返回。
{
error:'Invalid API KEY'
}
八、响应结果:
针对不同结果,服务器向客户端返回的结果应符合以下规范。
#返回商品列表
GET http://www.example.com/goods
#返回单个商品
GET http://www.example.com/goods/cup
#返回新生成的商品
POST http://www.example.com/goods
#返回一个空文档
DELETE http://www.example.com/goods
九、使用链接关联相关的资源:
在返回响应结果时提供链接其他API的方法,使客户端很方便的获取相关联的信息。
十、其他:
服务器返回的数据格式,应该尽量使用JSON,避免使用XML。
性能
一、不同角度的网站性能
普通用户认为的网站性能
网站性能对于普通用户来说,最直接的体现就是响应时间。用户在浏览器上直观感受到的网站响应速度,即从客户端发送请求,到服务器返回响应内容的时间。
做为网站开发人员来说,网站性能通常会和普通的用户理解的不一样。
普通用户感受到的网站性能,并不只是由网站服务器决定的。它还包括客户端计算机和服务器通信的时间,网站服务器处理响应的时间,客户端浏览器构造请求解析响应数据的时间。甚至,不同的计算机性能、不同浏览器解析HTML的速度、不同网络运营商提供的网络带宽房屋的差异,这些都会导致用户感受到响应时间,可能大于网站服务器处理请求的时间。
开发人员认为的网站性能
开发人员关注的主要是服务器应用程序本身,以及相关配套系统的性能。包括并发处理能力、系统稳定性、响应延迟等技术指标。
对性能优化的主要手段,包括使用缓存加速数据读取,使用集群提高数据吞吐能力,使用异步消息加快请求响应,使用代码改善程序性能。
运维人员认为的网站性能
运维人员关注的主要是服务器基础设施和资源利用率。如服务器硬件的配置、网络运营商的带宽、数据中心的网络架构等。主要优化手段有使用高性价比的服务器、建设优化骨干网络、利用虚拟化技术优化资源利用等。
二、性能的指标
从开发人员的角度,网站性能的指标主要有并发数和响应时间。
并发数
并发数是指系统能够处理请求的数量,对于网站服务器而言,并发数也就是网站并发用户数,指同时提交请求的用户数目。
与并发数相对应的还有网站在线用户数(登录用户数)和网站用户数(一般指注册用户数)。他们的关系一般是:网站用户数>网站用户在线数>网站用户并发数
响应时间
响应时间是最重要的性能指标,直接反映了系统的快慢。
常见的系统操作响应时间
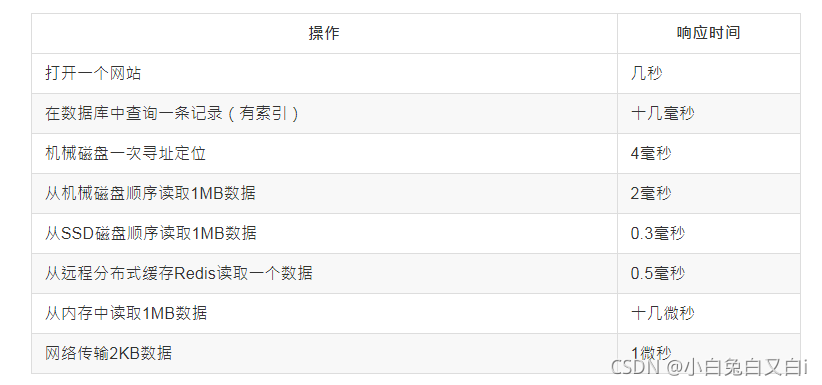
三、性能的优化
对于开发人员来说,网站性能优化一般包括Web前端性能优化、应用服务器性能优化、存储服务器性能优化三类。
Web前端性能优化
1、减少http请求 http协议是无状态的应用层协议,意味着每次http请求都需要建立通信链路、进行数据传输,而在服务器端,每个http请求都需要启动独立的线程去处理。减少http请求的数目可有效提高访问性能。
减少http的主要手段是合并CSS、合并javascript、合并图片。
2、使用浏览器缓存 对一个网站而言,CSS、javascript、logo、图标,这些静态资源文件更新的频率都比较低,而这些文件又几乎是每次http请求都需要的。如果将这些文件缓存在浏览器中,可以极好的改善性能。通过设置http头中的cache-control和expires的属性,可设定浏览器缓存,缓存时间可以自定义。
3、启用压缩 在服务器端对文件进行压缩,在浏览器端对文件解压缩,可有效减少通信传输的数据量。如果可以的话,尽可能的将外部的脚本、样式进行合并,多个合为一个。文本文件的压缩效率可达到80%以上,因此HTML、CSS、javascript文件启用GZip压缩可达到较好的效果。但是压缩对服务器和浏览器产生一定的压力,在网络带宽良好,而服务器资源不足的情况下要综合考虑。
4、CSS放在页面最上部,javascript放在页面最下面 浏览器会在下载完成全部CSS之后才对整个页面进行渲染,因此最好的做法是将CSS放在页面最上面,让浏览器尽快下载CSS。 Javascript则相反,浏览器在加载javascript后立即执行,有可能会阻塞整个页面,造成页面显示缓慢,因此javascript最好放在页面最下面。
应用服务器优化
应用服务器也就是处理网站业务的服务器,网站的业务代码都部署在这里,主要优化方案有缓存、异步、集群等。
1、合理使用缓存
当网站遇到性能瓶颈时,第一个解决方案一般是缓存。在整个网站应用中,缓存几乎无处不在,无论是客户端,还是应用服务器,或是数据库服务器。在客户端和服务器的交互中,无论是数据、文件都可以缓存,合理使用缓存对网站性能优化非常重要。
缓存一般用来存放那些读写次数比较高,变化较少的数据,比如网站首页的信息、商品的信息等。应用程序读取数据时,一般是先从缓存中读取,如果读取不到或数据已失效,再访问磁盘数据库,并将数据再次写入缓存。
缓存的基本原理是将数据存储在相对有较高访问速度的存储介质中,比如内存。一方面缓存访问速度快,另一方面,如果缓存的数据是需要经过计算处理得到的,那使用缓存还可以减少服务器处理数据的计算时间。
使用缓存并不是没有缺陷:内存资源是比较宝贵的,不可能将所有数据都缓存,一般频繁修改的数据不建议使用缓存,这会导致数据不一致。
网站数据缓存一般遵循二八定律,即80%的访问都在20%的数据上。所以,一般将这20%的数据缓存,可以起到改善系统性能,提高服务器读取效率。
2、异步操作
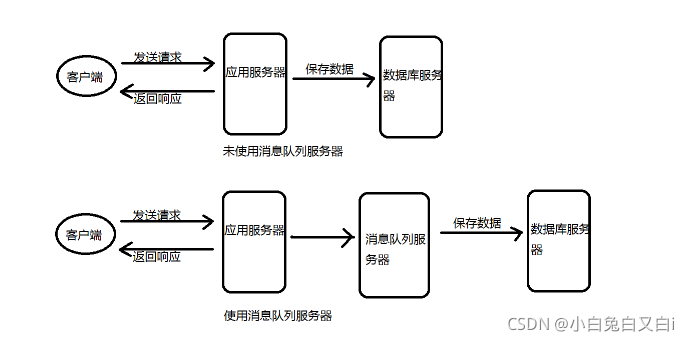
使用消息队列将调用异步化,可以改善网站系统的性能。
在不使用消息队列的情况下,用户的请求直接写入数据库,在高并发的情况下,会对数据库造成非常大的压力,也会延迟响应时间。
在使用消息队列后,用户请求的数据会发送给消息队列服务器,消息队列服务器会开启进程,将数据异步写入数据库。消息队列服务器的处理速度远超过数据库,因此用户的响应延迟可得到改善。
消息队列可以将短时间内的高并发产生的事务消息,存储在消息队列中,从而提高网站的并发处理能力。在电商网站的促销活动中,合理使用消息队列,可以抵御短时间内用户高并发的冲击。
3、使用集群
在网站高并发访问的情况下,使用负载均衡技术,可以为一个应用构建由多台服务器组成的服务器集群,将并发访问请求,分发到多台服务器上处理,避免单一服务器因负载过大,而导致响应延迟。
4、代码优化
网站的业务逻辑代码主要部署在应用服务器上,需要处理复杂的并发事务。合理优化业务代码,也可以改善网站性能。
任何web网站都会遇到多用户的并发访问,大型网站的并发用户会达到数万。每个用户请求都会创建一个独立的系统进程去处理。由于线程比进程更轻量,占用资源更少,所以,目前主流的web应用服务器都采用多线程的方式,处理并发用户的请求,因此,网站开发多数都是多线程编程。
使用多线程的另一个原因是服务器有多个CPU,现在手机都到了8核CPU的时代,一般的服务器至少是16核CPU,要想最大限度的使用这些CPU,必须启动多线程。
那么,启动多少线程合适呢?
启动线程数和CPU内核数量成正比,和IO等待时间成正比。如果都是计算型的任务,那么线程数最多不要超过CPU内核数,因为启动再多,CPU也来不及调用。如果任务是等待读写磁盘、网络响应,那么多启动线程会提高任务并发度,提高服务器性能。
或者用个简化的公式来描述:
启动线程数 = (任务执行时间/(任务执行事件 - IO等待时间)) * CPU内核数
5、存储优化
数据的读写是网站处理并发访问的另一瓶颈。使用缓存虽然可以解决一部分数据读写压力,但很多时候,磁盘仍然是系统最严重的瓶颈。而且磁盘是网站最重要的资产,磁盘的可用性和容错性也至关重要。
机械硬盘和固态硬盘 机械硬盘是目前最常用的硬盘,通过马达带动磁头到指定磁盘的位置访问数据,每次访问数据都需要移动磁头,在读取连续数据和随机访问上,磁头移动的次数相差巨大,因此机械硬盘的性能表现差别巨大,读写效率较低。而在网站应用中,大多数数据的访问都是随机的,在这种情况下,固态硬盘具有更高的性能。但目前固态硬盘在工艺上、数据可靠性上还有待提升,因此固态硬盘的使用尚未普及,从发展趋势看,取代机械硬盘应该是迟早的事情。
总结:
网站性能优化是在用户高并发访问,网站遇到问题时的解决方案。所以网站性能优化的主要内容是改善高并发用户访问情况下的网站响应速度。
网站性能优化的最终目的是改善用户的体验。但性能优化本身也是需要综合考虑的。比如说,性能提高一倍,服务器数量也要增加一倍,这样的优化是否可以考虑?
技术是由业务驱动的,离开业务的支撑,任何性能优化都是空中楼阁。
今天咱们就先学习到这里啦!有什么问题可关注我且私聊我啦!
非常感谢大家的阅读!
