金九银十,狂热的招聘季在悄声无息间开始了,小编也去尝试了一波,被杀的体无完肤,面试官问的和我想的根本不在一个节拍,现在就将最近失败的面试经历分享给大家,全搞懂的话,相当于你接到了5个offer,很负责任的告诉大家,这些都是我在面试过程中,面试官问我的,如果我先总结了这篇文章,结果一定会大相径庭。
本期特别推荐
❤️String、StringBuilder、StringBuffer详解❤️(附原理、测试case、建议收藏)
目录
1、实例化对象有哪几种方式
2、你用过单点登录吗?是如何实现的?
3、说一下什么是Spring IOC和AOP?
4、说一下AOP都有哪些基本理念?
5、再说一下AOP的使用场景
6、说一下Spring的常用注解都有哪些?
7、Springboot比spring多哪些注解
8、项目中是如何实现权限验证的,权限验证需要几张表
9、谈谈controller,接口调用的路径问题
10、mybatis中resultType和resultMap有什么区别?
11、myBatis查询多个id、myBatis常用属性
12、Oracle分页sql
13、oracle中如何进行分组排序取top3
14、数据库如何保证主键唯一性
15、Redis单线程多线程
16、JVM栈堆概念,何时销毁对象
17、Spring中都应用了哪些设计模式
18、简单介绍一下springboot
19、Spring Boot和Spring MVC有什么区别?
20、websocket应用的是哪个协议
21、Spring Boot如何访问不同的数据库
22、做过程序设计吗?
23、说一下cookie、session、token有什么区别?
24、如何设计数据库
25、性别是否适合做索引
26、如何查询重复的数据
27、查询网站在线人数
28、Redis取值存值问题
29、mybatis一级缓存、二级缓存
30、concurrentHashMap和HashTable有什么区别
31、hashmap存储的数据结构
32、HasmMap和HashSet的区别
33、synerchronized原理
34、什么是CAS
35、byte类型127+1等于多少
36、数据库一般会采取什么样的优化方法?
37、说一下事务的隔离级别
38、Object常用方法
39、beanFactory和factoryBean的区别
40、索引怎么定义,分哪几种
41、简单介绍一下Java多线程
42、easyExcel如何实现
43、ArrayList 和 Vector 的区别是什么?
44、Array 和 ArrayList 有何区别?
45、除了 ReetrantLock,你还接触过 JUC 中的哪些并发工具?
46、请谈谈 ReadWriteLock 和 StampedLock。
47、说一下 tcp 粘包是怎么产生的?
48、举一个用 Java 实现的装饰模式(decorator design pattern)?它是作用于对象层次还是类层次?
49、请举例说明如何在 Spring 中注入一个 Java Collection?
50、什么是 Swagger?你用 Spring Boot 实现了它吗?
51、什么是 Spring Profiles?
52、在 hibernate 中使用 Integer 和 int 做映射有什么区别?
53、mysql 的内连接、左连接、右连接有什么区别?
54、Redis支持的数据类型有哪些?
55、详细介绍一下 CMS 垃圾回收器?
56、新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
57、简述分代垃圾回收器是怎么工作的?
1、实例化对象有哪几种方式
纳尼?这么简单的问题,new一下不就好了?
- new
- clone()
- 通过反射机制创建
//用 Class.forName方法获取类,在调用类的newinstance()方法
Class<?> cls = Class.forName("com.dao.User");
User u = (User)cls.newInstance();- 序列化反序列化
//将一个对象实例化后,进行序列化,再反序列化,也可以获得一个对象(远程通信的场景下使用)
ObjectOutputStream out = new ObjectOutputStream (new FileOutputStream("D:/data.txt"));
//序列化对象
out.writeObject(user1);
out.close();
//反序列化对象
ObjectInputStream in = new ObjectInputStream(new FileInputStream("D:/data.txt"));
User user2 = (User) in.readObject();
System.out.println("反序列化user:" + user2);
in.close();2、你用过单点登录吗?是如何实现的?
(1)概念
单点登录SSO,说的是在一个多系统共存的环境下,用户在一处登录后,就不用在其他系统中登录,也就是用户的一次登录能得到其他所有系统的信任。
(2)单点登录的要点
①存储信任;
②验证信任;
(3)实现单点登录的三种方式
① 以cookie作为凭证
最简单的单点登录实现方式,是使用cookie作为媒介,存放用户凭证。
用户登录父应用之后,应用返回一个加密的cookie,当用户访问子应用的时候,携带上这个cookie,授权应用解密cookie进行校验,校验通过则登录当前用户。
缺点:
- cookie不安全
通过加密可以保证安全性,但如果对方掌握了解密算法就完蛋了。
- 不能跨域实现免登
② 通过JSONP实现
对于跨域问题,可以使用JSONP实现。用户在父应用中登录后,跟session匹配的cookie会存到客户端中,当用户需要登录子应用的时候,授权应用访问父应用提供的JSONP接口,并在请求中带上父应用域名下的cookie,父应用接收到请求,验证用户的登录状态,返回加密的信息,子应用通过解析返回来的加密信息来验证用户,如果通过验证则登录用户。
缺点:
这种方法虽然能解决跨域问题,但是治标不治本,没有解决cookie安全性的问题。
③ 通过页面重定向的方式
最后一种介绍的方式,是通过父应用和子应用来回重定向进行通信,实现信息的安全传递。
父应用提供一个GET方式的登录接口A(此时的父应用接口固定,攻击者无法去伪造),用户通过子应用重定向连接的方式访问这个接口,如果用户还没有登录,则返回一个登录页面,用户输入账号密码进行登录,如果用户已经登录了,则生成加密的token,并且重定向到子应用提供的验证token的接口B(此时的子应用接口固定,攻击者无法去伪造),通过解密和校验之后,子应用登录当前用户。
缺点:
这种方式较前面的两种方式,是解决了安全性和跨域的问题,但是并没有前面两种方式简单,安全与方便,本来就是矛盾的。
(4)使用独立登录系统
一般来说,大型应用会把授权的逻辑和用户信息的相关逻辑独立成一个应用,称为用户中心。用户中心不处理业务逻辑,只是处理用户信息的管理以及授权给第三方应用。第三方应用需要登录的时候,则把用户的登录请求转发给用户中心进行处理,用户处理完毕后返回凭证,第三方应用验证凭证,通过后就登录用户。
(5)sso(单点登录)与OAuth2.0(授权)的区别?
① sso(单点登录)
通常处理的是一个公司的不同应用间的访问登录问题,如企业应用有很多子系统,只需登录一个系统,就可以实现不同子系统间的跳转,而避免了登录操作;
通过cookie、jsonp、重定向来实现;
② OAuth2.0(授权)
解决的是服务提供方(如微信)给第三方应用授权的问题,简称微信登录;
是一种具体的协议,只是为用户资源的授权提供了一个安全的、开放的而又简易的标准,OAuth2.0(授权)为客户开发者开发web应用,桌面应用程序,移动应用及客厅设备提供特定的授权流程。
3、说一下什么是Spring IOC和AOP?
(1)什么是AOP?
AOP(Aspect Oriented Programming)称为面向切面编程,在程序开发中主要用来解决一些系统层面上的问题,比如日志,事务,权限等等,Struts2的拦截器设计就是基于AOP的思想,是个比较经典的例子。
在不改变原有逻辑的基础上,增加了一些额外的功能。代理也是这个功能,读写分离也是用AOP来实现的。
(2)AOP与OOP
AOP可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。OOP引入封装、继承、多态等概念来建立一种对象层次结构,用于模拟公共行为的一个集合。不过OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
(3)AOP
AOP技术恰恰相反,它利用一种称为“切面”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用的模块,并将其命名为“Aspect”,即切面。所谓“切面”,简单说就是那些与业务无关,却被业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多出,而各处基本相似,比如权限认证、日志、事务。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
4、说一下AOP都有哪些基本理念?
这个问题刚开始听到的时候,有些蒙蔽,AOP基本理念?什么鬼?我就将AOP的一些关键点说了一下,没想到面试官还挺满意,要学会变量的答题,不是面试官说什么就答什么,谁也不能保证都会。
(1)横切关注点
对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点;
(2)Aspect(切面)
通常是一个类,里面可以定义切入点和通知。
(3)JoinPoint(连接点)
程序执行过程中明确的点,一般是方法的调用,被拦截到的点。因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器。
(4)Advice(通知)
AOP在特定的切入点上执行的增强处理,有before(前置)、after(后置)、afterReturning(最终)、afterThrowing(异常)、around(环绕)。
(5)Pointcut(切入点)
带有通知的连接点,在程序中主要体现在书写切入点表达式。
(6)weave(织入)
将切面应用到目标对象并导致代理对象创建的过程。
(7)introduction(引入)
在不修改代码的前提下,引入可以在运行期为类动态地增加一些方法或字段。
(8)AOP代理(AOP Proxy)
AOP框架创建的对象,代理就是目标对象的加强。Spring中的AOP代理可以是JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类。
(9)目标对象(Target Object)
包含连接点的对象,也被称作被通知或被代理对象,POJO。
5、再说一下AOP的使用场景
我去,这面试官和Spring可上了,我服!
1、Authentication 权限
2、Caching 缓存
3、Context passing 内容传递
4、Error handling 错误处理
5、Lazy loading 懒加载
6、Debugging 调试
7、logging, tracing, profiling and monitoring 记录跟踪 优化 校准
8、Performance optimization 性能优化
9、Persistence 持久化
10、Resource pooling 资源池
11、Synchronization 同步
12、Transactions 事务、
客官,你还满意?
当我说到第七个应该场景的时候,面试官说可以了,哈哈,,耳朵起茧子了吧

6、说一下Spring的常用注解都有哪些?
实在太多,小编整理了一个专门的博客。
Spring常用注解
7、Springboot比spring多哪些注解
Spring Boot常用注解
8、项目中是如何实现权限验证的,权限验证需要几张表
我是用SpringSecuriy进行权限验证的,通过gateway进行路径的拦截,权限验证,权限验证大概就是根据roll的值进行判断,1普通用户2VIP用户4管理员,组成了类似于Linux中rwx的权限管理方法。
大概使用五张表,用户、角色、权限、还有用户与角色的关系表、角色和权限的关系表。
9、谈谈controller,接口调用的路径问题
(1)Spring MVC如何匹配请求路径
@RequestMapping是用来映射请求的,比如get请求、post请求、或者REST风格与非REST风格的。该注解可以用在类上或方法上,如果用在类上,表示是该类中所有方法的父路径。
@RequestMapping("/springmvc")
@Controller
public class SpringMVCTest {
@RequestMapping("/testRequestMapping")
public String testRequestMapping(){
System.out.println("testRequestMapping");
return SUCCESS;
}
}在类上还添加了一个@Controller注解,该注解在SpringMVC中负责处理由DispatcherServlet分发的请求,它把用户请求的数据经过业务处理层处理之后封装成一个model,然后再把该model返回给对应的view进行展示。
我们可以通过“springmvc/testRequestMapping”这个路径来定位到testRequestMapping这个方法,然后执行方法内的方法体。
RequestMapping可以实现模糊匹配路径,比如:
- ?表示一个字符;
- *表示任意字符;
- **匹配多层路径;
/springmvc/**/testRequestMapping 就可以匹配/springmvc/stu/getStudentInfo/testRequestMapping 这样的路径了。
(2)SpringMVC如何获取请求的参数
@PathVariable
该注解用来映射请求URL中绑定的占位符。通过@PathVariable可以将URL中占位符的参数绑定到controller处理方法的入参中。
@RequestMapping("/testPathVariable/{id}")
public String testPathVariable(@PathVariable(value="id") Integer id){
System.out.println("testPathVariable:" + id);
return SUCCESS;
}@RequestParam
该注解也是用来获取请求参数的,那么该注解和@PathVariable有什么不同呢?
@RequestMapping(value="/testRequestParam")
public String testRequestParam(@RequestParam(value="username") String username, @RequestParam(value="age", required=false, defaultValue="0") int age){
System.out.println("testRequestParam" + " username:" + username + " age:" +age);
return SUCCESS;
}(3)REST风格的请求
在SpringMVC中业务最多的应该是CRUD了
@RequestMapping(value="/testRest/{id}", method=RequestMethod.PUT)
public String testRestPut(@PathVariable(value="id") Integer id){
System.out.println("test put:" + id);
return SUCCESS;
}
@RequestMapping(value="/testRest/{id}", method=RequestMethod.DELETE)
public String testRestDelete(@PathVariable(value="id") Integer id){
System.out.println("test delete:" + id);
return SUCCESS;
}
@RequestMapping(value="/testRest", method=RequestMethod.POST)
public String testRest(){
System.out.println("test post");
return SUCCESS;
}
@RequestMapping(value="/testRest/{id}", method=RequestMethod.GET)
public String testRest(@PathVariable(value="id") Integer id){
System.out.println("test get:" + id);
return SUCCESS;
}10、mybatis中resultType和resultMap有什么区别?
(1)resultType是直接表示返回类型的(对应着我们的model对象中的实体)
(2)resultMap则是对外部ResultMap的引用(提前定义了db和model之间的隐射key-->value关系),但是resultType跟resultMap不能同时存在。
11、myBatis查询多个id、myBatis常用属性
myBatis查询多个id(我居然回答用对象来传递...)
Page<UserPoJo> getUserListByIds(@Param("ids") List<Integer> ids);<!--根据id列表批量查询user-->
<select id="getUserListByIds" resultType="com.guor.UserPoJo">
select * from student
where id in
<foreach collection="ids" item="userid" open="(" close=")" separator=",">
#{userid}
</foreach>
</select>12、Oracle分页sql
#不带排序的
SELECT * FROM (
SELECT ROWNUM AS rowno, t.* FROM worker t where ROWNUM <=20) table_alias
WHERE table_alias.rowno > 10;#带排序的
SELECT * FROM (
SELECT tt.*, ROWNUM AS rowno FROM (
SELECT t.* FROM worker t ORDER BY wkid aSC) tt WHERE ROWNUM <= 20) table_alias
WHERE table_alias.rowno >= 10;13、oracle中如何进行分组排序取top3
SELECT *
FROM (SELECT ROW_NUMBER() OVER(PARTITION BY prov ORDER BY counts DESC) rn,
prov,
kpi,
counts
FROM tab_a a)
WHERE rn < 314、数据库如何保证主键唯一性
(1)主键约束
主键列上没有任何两行具有相同值(即重复值),不允许空(NULL);
(2)唯一性约束
保证一个字段或者一组字段里的数据都与表中其它行的对应数据不同。和主键约束不同,唯一性约束允许为null,但是只能有一行;
(3)唯一性索引
不允许具有索引值相同的行,从而禁止重复的索引和键值;
(4)三者的区别
- 约束是用来检查数据的正确性;
- 索引是用来优化查询的;
- 创建唯一性约束会创建一个约束和一个唯一性索引;
- 创建唯一性索引只会创建一个唯一性索引;
- 主键约束和唯一性约束都会创建一个唯一性索引。
15、Redis单线程多线程
Redis是单线程的
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现的。
Redis6.0之后引入多线程,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。
16、JVM栈堆概念,何时销毁对象
- 类在程序运行的时候就会被加载,方法是在执行的时候才会被加载,如果没有任何引用了,Java自动垃圾回收,也可以用System.gc()开启回收器,但是回收器不一定会马上回收。
- 静态变量在类装载的时候进行创建,在整个程序结束时按序销毁;
- 实例变量在类实例化对象时创建,在对象销毁的时候销毁;
- 局部变量在局部范围内使用时创建,跳出局部范围时销毁;
17、Spring中都应用了哪些设计模式
这道题我答的惨不忍睹,设计模式倒是用过几个,你问我spring中都应用了哪些,这有点过分了吧。
(1)简单工厂模式
简单工厂模式的本质就是一个工厂类根据传入的参数,动态的决定实例化哪个类。
Spring中的BeanFactory就是简单工厂模式的体现,根据传入一个唯一的标识来获得bean对象。
(2)工厂方法模式
应用程序将对象的创建及初始化职责交给工厂对象,工厂Bean。
定义工厂方法,然后通过config.xml配置文件,将其纳入Spring容器来管理,需要通过factory-method指定静态方法名称。
(3)单例模式
Spring用的是双重判断加锁的单例模式,通过getSingleton方法从singletonObjects中获取bean。
(4)代理模式
Spring的AOP中,使用的Advice(通知)来增强被代理类的功能。Spring实现AOP功能的原理就是代理模式(① JDK动态代理,② CGLIB字节码生成技术代理。)对类进行方法级别的切面增强。
(5)装饰器模式
装饰器模式:动态的给一个对象添加一些额外的功能。
Spring的ApplicationContext中配置所有的DataSource。这些DataSource可能是不同的数据库,然后SessionFactory根据用户的每次请求,将DataSource设置成不同的数据源,以达到切换数据源的目的。
在Spring中有两种表现:
一种是类名中含有Wrapper,另一种是类名中含有Decorator。
(6)观察者模式
定义对象间的一对多的关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并自动更新。
Spring中观察者模式一般用在listener的实现。
(7)策略模式
策略模式是行为性模式,调用不同的方法,适应行为的变化 ,强调父类的调用子类的特性 。
getHandler是HandlerMapping接口中的唯一方法,用于根据请求找到匹配的处理器。
(8)模板方法模式
Spring JdbcTemplate的query方法总体结构是一个模板方法+回调函数,query方法中调用的execute()是一个模板方法,而预期的回调doInStatement(Statement state)方法也是一个模板方法。

18、简单介绍一下springboot
(1)Spring是什么
Spring框架为开发Java应用程序提供了全面的基础架构支持。它包含一些很好的功能,如依赖注入和开箱即用的模块,如Spring JDBC、Spring MVC、Spring Security、Spring AOP、Spring ORM、Spring Test。这些模块缩短应用程序的开发时间,提高了应用开发的效率。
(2)Spring Boot是什么
Spring Boot是Spring框架的扩展,它消除了设置Spring应用程序所需的XML配置,更快、更高效。
以下是Spring Boot中的一些特点:
- 嵌入tomcat,而且不需要部署tomcat;
- 提供的starter来简化maven配置;
- 创建Spring Boot项目时可以选择Spring应用;
- 提供外部化配置;
- 不需要配置xml了;
(3)MVC配置
Spring需要定义调度程序servlet,映射和其它支持配置。我们可以使用web.xml文件或Initializer类来完成此操作。
public class MyWebAppInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext container) {
AnnotationConfigWebApplicationContext context = new AnnotationConfigWebApplicationContext();
context.setConfigLocation("com.pingfangushi");
container.addListener(new ContextLoaderListener(context));
ServletRegistration.Dynamic dispatcher = container
.addServlet("dispatcher", new DispatcherServlet(context));
dispatcher.setLoadOnStartup(1);
dispatcher.addMapping("/");
}
} 还需要将@EnableWebMvc注释添加到@Configuration类,并定义一个视图解析器来解析从控制器返回的视图:
@EnableWebMvc
@Configuration
public class ClientWebConfig implements WebMvcConfigurer {
@Bean
public ViewResolver viewResolver() {
InternalResourceViewResolver bean
= new InternalResourceViewResolver();
bean.setViewClass(JstlView.class);
bean.setPrefix("/WEB-INF/view/");
bean.setSuffix(".jsp");
return bean;
}
} 和上述操作相比,Spring Boot只需在application配置文件中配置间隔属性就能完成上述操作:
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp (4)配置模板引擎 Thymeleaf
在Spring中,我们需要为视图解析器添加thymeleaf-spring5依赖项和一些配置:
@Configuration
@EnableWebMvc
public class MvcWebConfig implements WebMvcConfigurer {
@Autowired
private ApplicationContext applicationContext;
@Bean
public SpringResourceTemplateResolver templateResolver() {
SpringResourceTemplateResolver templateResolver = new SpringResourceTemplateResolver();
templateResolver.setApplicationContext(applicationContext);
templateResolver.setPrefix("/WEB-INF/views/");
templateResolver.setSuffix(".html");
return templateResolver;
}
@Bean
public SpringTemplateEngine templateEngine() {
SpringTemplateEngine templateEngine = new SpringTemplateEngine();
templateEngine.setTemplateResolver(templateResolver());
templateEngine.setEnableSpringELCompiler(true);
return templateEngine;
}
@Override
public void configureViewResolvers(ViewResolverRegistry registry) {
ThymeleafViewResolver resolver = new ThymeleafViewResolver();
resolver.setTemplateEngine(templateEngine());
registry.viewResolver(resolver);
}
} Spring Boot直接添加spring-boot-starter-thymeleaf依赖就行了。
(5)Spring Security 配置
Spring需要依赖spring-security-web和spring-security-config 模块。
接下来, 我们需要添加一个扩展WebSecurityConfigurerAdapter的类,并使用@EnableWebSecurity注解:
@Configuration
@EnableWebSecurity
public class CustomWebSecurityConfigurerAdapter extends WebSecurityConfigurerAdapter {
@Autowired
public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception {
auth.inMemoryAuthentication()
.withUser("admin")
.password(passwordEncoder()
.encode("password"))
.authorities("ROLE_ADMIN");
}
@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
.anyRequest().authenticated()
.and()
.httpBasic();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
} Spring Boot添加spring-boot-starter-security依赖就行了。
(6)Spring支持传统的web.xml,SpringBoot使用嵌入式容器来运行程序,Spring Boot使用main
法来启动嵌入式web服务器,它还负责将servlet、filter、ServletContextInitializer bean从应用程序上下文绑定到嵌入式servelet容器。
(7)打包和部署
Spring和Spring Boot都支持maven和Gradle通用打包管理技术。
Spring Boot相对Spring的一些优点:
- 提供嵌入式容器支持;
- 使用命令java -jar独立运行jar;
- 部署时可以灵活指定配置文件;
19、Spring Boot和Spring MVC有什么区别?
Spring框架有很多衍生产品,例如Spring Boot、Spring MVC、Spring Security等等,但是他们的基础都是Spring的IOC和AOP。
IOC提供了依赖注入的容器,AOP提供了面向切面编程,然后在这两者的基础上实现了其它延伸产品的高级功能。
Spring MVC是一种松耦合的方式开发web应用的框架。
通过Dispatcher Servlet, ModelAndView 和 View Resolver,开发web应用变得很容易。解决的问题领域是网站应用程序或者服务开发--url路由、session、模板引擎、静态web资源等等。
Spring Boot实现了自动配置,降低了项目搭建的复杂度。
Spring Boot主要为了解决Spring框架需要大量配置太麻烦的问题。同时集成了很多第三方库(例如JDBC、Redis等),Spring Boot中的第三方库基本都是零配置的开箱即用。
对于我们来说,换成Spring Boot之后,项目初始化方法变了,配置文件变了,不需要安装tomcat了,maven打包jar就能直接部署运行了,但你最核心的业务逻辑实现与业务流程实现没有任何变化。
20、websocket应用的是哪个协议
WebSocket是一个允许Web应用程序(通常指浏览器)与服务器进行双向通信的协议。HTML5的WebSocket API主要是为浏览器端提供了一个基于TCP协议实现全双工通信的方法。
WebSocket优势: 浏览器和服务器只需要要做一个握手的动作,在建立连接之后,双方可以在任意时刻,相互推送信息。同时,服务器与客户端之间交换的头信息很小。
21、Spring Boot如何访问不同的数据库
针对这个问题,我专门写过博客,这道题答得我最满意。
【Spring Boot 27】Springboot配置两个数据库(附代码+源码分析)
22、做过程序设计吗?
这道题我答的并不是很好
- 先进行系统设计,思考实现这个项目都需要什么技术,技术的选择很重要,既要考虑性能,又要考虑组员的学习成本。
- 进行概要设计,设计一下系统都有哪些模块,模块间是否需要通信。
- 进行数据库设计
- 进行API设计
也不知道我答得对不对,先这样吧。
23、说一下cookie、session、token有什么区别?
(1)session
session是服务端存储的一个对象,主要用来存储所有访问过该服务端的客户端的用户信息(也可以存储其他信息),从而实现保持用户会话状态。但是服务器重启时,内存会被销毁,存储的用户信息也就消失了。
不同的用户访问服务端的时候会在session对象中存储键值对,“键”用来存储开启这个用户信息的“钥匙”,在登录成功后,“钥匙”通过cookie返回给客户端,客户端存储为sessionId记录在cookie中。当客户端再次访问时,会默认携带cookie中的sessionId来实现会话机制。
① session是基于cookie的。
cookie的数据4k左右;
cookie存储数据的格式:字符串key=value
cookie存储有效期:可以自行通过expires进行具体的日期设置,如果没设置,默认是关闭浏览器时失效。
cookie有效范围:当前域名下有效。所以session这种会话存储方式方式只适用于客户端代码和服务端代码运行在同一台服务器上(前后端项目协议、域名、端口号都一致,即在一个项目下)
② session持久化
用于解决重启服务器后session消失的问题。在数据库中存储session,而不是存储在内存中。通过包:express-mysql-session。
当客户端存储的cookie失效后,服务端的session不会立即销毁,会有一个延时,服务端会定期清理无效session,不会造成无效数据占用存储空间的问题。
(2)token机制
适用于前后端分离的项目(前后端代码运行在不同的服务器下)
请求登录时,token和sessionid原理相同,是对key和key对应的用户信息进行加密后的加密字符,登录成功后,会在响应主体中将{token:“字符串”}返回给客户端。
客户端通过cookie都可以进行存储。再次请求时不会默认携带,需要在请求拦截器位置给请求头中添加认证字段Authorization携带token信息,服务器就可以通过token信息查找用户登录状态。
24、如何设计数据库
(1)数据库设计最起码要占用这个项目开发的40%以上的时间
(2)数据库设计不仅仅停留在页面demo的表面
页面内容所需字段,在数据库设计中只是一部分,还有系统运转、模块交互、中转数据、表之间的联系等等所需要的字段,因此数据库设计绝对不是简单的基本数据存储,还有逻辑数据存储。
(3)数据库设计完成后,项目80%的设计开发都要存在你的脑海中
每个字段的设计都要有他存在的意义,要清楚的知道程序中如何去运用这些字段,多张表的联系在程序中是如何体现的。
(4)数据库设计时就要考虑效率和优化问题
数据量大的表示粗粒度的,会冗余一些必要字段,达到用最少的表,最弱的表关系去存储海量的数据。大数据的表要建立索引,方便查询。对于含有计算、数据交互、统计这类需求时,还有考虑是否有必要采用存储过程。
(5)添加必要的冗余字段
像创建时间、修改时间、操作用户IP、备注这些字段,在每张表中最好都有,一些冗余的字段便于日后维护、分析、拓展而添加。
(6)设计合理的表关联
若两张表之间的关系复杂,建议采用第三张映射表来关联维护两张表之间的关系,以降低表之间的直接耦合度。
(7)设计表时不加主外键等约束关联,系统编码阶段完成后再添加约束性关联
(8)选择合适的主键生成策略
数据库的设计难度其实比单纯的技术实现难很多,他充分体现了一个人的全局设计能力和掌控能力,最后说一句,数据库设计,很重要,很复杂。

25、性别是否适合做索引
区分度不高的字段不适合做索引,因为索引页是需要有开销的,需要存储的,不过这类字段可以做联合索引的一部分。
26、如何查询重复的数据
(1)查询重复的单个字段(group by)
select 重复字段A, count(*) from 表 group by 重复字段A having count(*) > 1(2)查询重复的多个字段(group by)
select 重复字段A, 重复字段B, count(*) from 表 group by 重复字段A, 重复字段B having count(*) > 1(3)删除所有重复的数据
-- 慎重考虑后执行,后悔记得及时回滚。
delete from table group by 重复字段 having count(重复字段) > 127、查询网站在线人数
通过监听session对象的方式来实现在线人数的统计和在线人信息展示,并且让超时的自动销毁。
对session对象实现监听,首先必须继承HttpSessionListener类,该程序的基本原理就是当浏览器访问页面的时候必定会产生一个session对象,当关闭该页面的时候必然会删除session对象。所以每当产生一个新的session对象就让在线人数+1,当删除一个session对象就让在线人数-1。
还要继承一个HttpSessionAttributeListener,来实现对其属性的监听。分别实现attributeAdded方法,attributeReplace方法以及attributeRemove方法。
sessionCreated//新建一个会话的时候触发,也可以说是客户端第一次喝服务器交互时触发。
sessionDestroyed//销毁会话的时候,一般来说只有某个按钮触发进行销毁,或者配置定时销毁。
HttpSessionAttributeListener有三个方法需要实现
- attributeAdded//在session中添加对象时触发此操作 笼统的说就是调用setAttribute这个方法时候会触发的
- attributeRemoved//修改、删除session中添加对象时触发此操作 笼统的说就是调用 removeAttribute这个方法时候会触发的
- attributeReplaced//在Session属性被重新设置时
28、Redis取值存值问题
(1)先把Redis的连接池拿出来
JedisPool pool = new JedisPool(new JedisPoolConfig(),"127.0.0.1");
Jedis jedis = pool.getResource();(2)存取值
jedis.set("key","value");
jedis.get("key");
jedis.del("key");
//给一个key叠加value
jedis.append("key","value2");//此时key的值就是value + value2;
//同时给多个key进行赋值:
jedis.mset("key1","value1","key2","value2");(3)对map进行操作
Map<String,String> user = new HashMap();
user.put("key1","value1");
user.put("key2","value2");
user.put("key3","value3");
//存入
jedis.hmset("user",user);
//取出user中key1
List<String> nameMap = jedis.hmget("user","key1");
//删除其中一个键值
jedis.hdel("user","key2");
//是否存在一个键
jedis.exists("user");
//取出所有的Map中的值:
Iterator<String> iter = jedis.hkeys("user").iterator();
while(iter.next()){
jedis.hmget("user",iter.next());
}29、mybatis一级缓存、二级缓存
(1)一级缓存:指的是mybatis中sqlSession对象的缓存,当我们执行查询以后,查询的结果会同时存入sqlSession中,再次查询的时候,先去sqlSession中查询,有的话直接拿出,当sqlSession消失时,mybatis的一级缓存也就消失了,当调用sqlSession的修改、添加、删除、commit()、close()等方法时,会清空一级缓存。
(2)二级缓存:指的是mybatis中的sqlSessionFactory对象的缓存,由同一个sqlSessionFactory对象创建的sqlSession共享其缓存,但是其中缓存的是数据而不是对象。当命中二级缓存时,通过存储的数据构造成对象返回。查询数据的时候,查询的流程是二级缓存 > 一级缓存 > 数据库。
(3)如果开启了二级缓存,sqlSession进行close()后,才会把sqlSession一级缓存中的数据添加到二级缓存中,为了将缓存数据取出执行反序列化,还需要将要缓存的pojo实现Serializable接口,因为二级缓存数据存储介质多种多样,不一定只存在内存中,也可能存在硬盘中。
(4)mybatis框架主要是围绕sqlSessionFactory进行的,具体的步骤:
定义一个configuration对象,其中包含数据源、事务、mapper文件资源以及影响数据库行为属性设置settings。
通过配置对象,则可以创建一个sqlSessionFactoryBuilder对象。
通过sqlSessionFactoryBuilder获得sqlSessionFactory实例。
通过sqlSessionFactory实例创建qlSession实例,通过sqlSession对数据库进行操作。
(5)代码实例
mybatis-config.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 加载类路径下的属性文件 -->
<properties resource="db.properties"/>
<!-- 设置类型别名 -->
<typeAliases>
<typeAlias type="cn.itcast.javaee.mybatis.app04.Student" alias="student"/>
</typeAliases>
<!-- 设置一个默认的连接环境信息 -->
<environments default="mysql_developer">
<!-- 连接环境信息,取一个任意唯一的名字 -->
<environment id="mysql_developer">
<!-- mybatis使用jdbc事务管理方式 -->
<transactionManager type="jdbc"/>
<!-- mybatis使用连接池方式来获取连接 -->
<dataSource type="pooled">
<!-- 配置与数据库交互的4个必要属性 -->
<property name="driver" value="${mysql.driver}"/>
<property name="url" value="${mysql.url}"/>
<property name="username" value="${mysql.username}"/>
<property name="password" value="${mysql.password}"/>
</dataSource>
</environment>
<!-- 连接环境信息,取一个任意唯一的名字 -->
<environment id="oracle_developer">
<!-- mybatis使用jdbc事务管理方式 -->
<transactionManager type="jdbc"/>
<!-- mybatis使用连接池方式来获取连接 -->
<dataSource type="pooled">
<!-- 配置与数据库交互的4个必要属性 -->
<property name="driver" value="${oracle.driver}"/>
<property name="url" value="${oracle.url}"/>
<property name="username" value="${oracle.username}"/>
<property name="password" value="${oracle.password}"/>
</dataSource>
</environment>
</environments>
<!-- 加载映射文件-->
<mappers>
<mapper resource="cn/itcast/javaee/mybatis/app14/StudentMapper.xml"/>
</mappers>
</configuration> public class MyBatisTest {
public static void main(String[] args) {
try {
//读取mybatis-config.xml文件
InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-config.xml");
//初始化mybatis,创建SqlSessionFactory类的实例
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream);
//创建session实例
SqlSession session = sqlSessionFactory.openSession();
/*
* 接下来在这里做很多事情,到目前为止,目的已经达到得到了SqlSession对象.通过调用SqlSession里面的方法,
* 可以测试MyBatis和Dao层接口方法之间的正确性,当然也可以做别的很多事情,在这里就不列举了
*/
//插入数据
User user = new User();
user.setC_password("123");
user.setC_username("123");
user.setC_salt("123");
//第一个参数为方法的完全限定名:位置信息+映射文件当中的id
session.insert("com.cn.dao.UserMapping.insertUserInformation", user);
//提交事务
session.commit();
//关闭session
session.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}30、concurrentHashMap和HashTable有什么区别
concurrentHashMap融合了hashmap和hashtable的优势,hashmap是不同步的,但是单线程情况下效率高,hashtable是同步的同步情况下保证程序执行的正确性。
但hashtable每次同步执行的时候都要锁住整个结构,如下图:
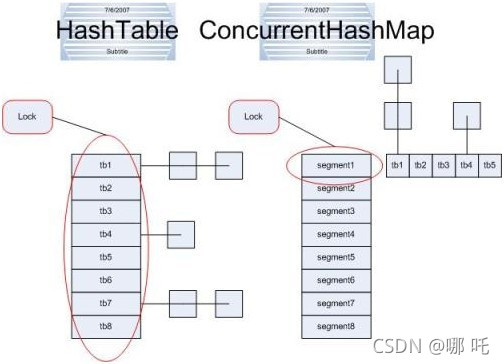
concurrentHashMap锁的方式是细粒度的。concurrentHashMap将hash分为16个桶(默认值),诸如get、put、remove等常用操作只锁住当前需要用到的桶。
concurrentHashMap的读取并发,因为读取的大多数时候都没有锁定,所以读取操作几乎是完全的并发操作,只是在求size时才需要锁定整个hash。
而且在迭代时,concurrentHashMap使用了不同于传统集合的快速失败迭代器的另一种迭代方式,弱一致迭代器。在这种方式中,当iterator被创建后集合再发生改变就不会抛出ConcurrentModificationException,取而代之的是在改变时new新的数据而不是影响原来的数据,iterator完成后再讲头指针替代为新的数据,这样iterator时使用的是原来的数据。
31、hashmap存储的数据结构
数组结构中有数组和链表,实现对数据的存储。
(1)数组
数组存储区间是连续的,占用内存严重,故空间复杂度大,但数组的二分查找时间复杂度小,为O(1);
数组的特点是:查找容易,插入和删除困难。
(2)链表
链表存储区间离散,暂用内存比较宽松,故空间复杂度小,但时间复杂度大,达到O(N)。
链表的特点:查找困难,插入和删除容易。
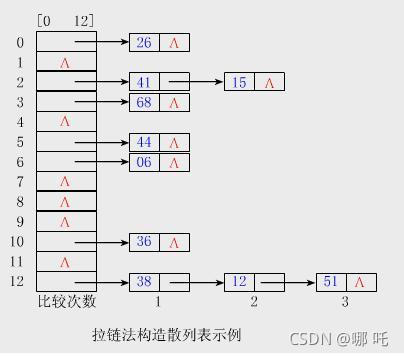
(3)哈希表
哈希表有多种不同的实现方法,现在介绍一种最常用的方法---拉链法,可以简单的理解为“链表的数组”,如图:
(4)HashMap其实就是一个线性的数组
首先HashMap中有一个静态内部类Entry,其重要的属性有key、value、next,key、value构成Entry[],next的指针指向下一个元素的引用,也就构成了链表。
32、HasmMap和HashSet的区别
(1)先了解一下HashCode
Java中的集合有两类,一类是List,一类是Set。
List:元素有序,可以重复;
Set:元素无序,不可重复;
要想保证元素的不重复,拿什么来判断呢?这就是Object.equals方法了。如果元素有很多,增加一个元素,就要判断n次吗?
显然不现实,于是,Java采用了哈希表的原理。哈希算法也称为散列算法,是将数据依特定算法直接指定到一根地址上,初学者可以简单的理解为,HashCode方法返回的就是对象存储的物理位置(实际上并不是)。
这样一来,当集合添加新的元素时,先调用这个元素的hashcode()方法,就一下子能定位到他应该放置的物理位置上。如果这个位置上没有元素,他就可以直接存储在这个位置上,不用再进行任何比较了。如果这个位置上有元素,就调用它的equals方法与新元素进行比较,想同的话就不存了,不相同就散列其它的地址。所以这里存在一个冲突解决的问题。这样一来实际上调用equals方法的次数就大大降低了,几乎只需要一两次。
简而言之,在集合查找时,hashcode能大大降低对象比较次数,提高查找效率。
Java对象的equals方法和hashCode方法时这样规定的:
- 相等的对象就必须具有相等的hashcode。
- 如果两个对象的hashcode相同,他们并不一定相同。
- 如果两个对象的hashcode相同,他们并不一定相同。
如果两个Java对象A和B,A和B不相等,但是A和B的哈希码相等,将A和B都存入HashMap时会发生哈希冲突,也就是A和B存放在HashMap内部数组的位置索引相同,这时HashMap会在该位置建立一个链接表,将A和B串起来放在该位置,显然,该情况不违反HashMap的使用规则,是允许的。当然,哈希冲突越少越好,尽量采用好的哈希算法避免哈希冲突。
equals()相等的两个对象,hashcode()一定相等;equals()不相等的两个对象,却并不能证明他们的hashcode()不相等。
(2)HashMap和HashSet的区别
| HashMap | HashSet |
| 实现了Map接口 | 实现了Set接口 |
| 存储键值对 | 存储对象 |
| 调用put()添加元素 | 调用add()添加元素 |
| HashMap使用key计算HashCode | HashSet使用成员对象计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false。 |
| HashMap比HashSet快 | HashSet比HashMap慢 |
33、synerchronized原理
(1)偏向锁
系统发现不存在线程竞争时,会使用偏向锁,实际上就是在对象头上标记当前线程id。
(2)自旋锁(也叫轻量级锁,无锁,乐观锁)
自旋锁的原理是CAS操作,CAS是原子性的,梓轩的线程会尝试着去获取值,如果获取到了,就会执行代码逻辑得到新值,再比较之前读到的值和当前的值是否一致,一致的话就把新值写到内存里面;不一致说明值被其他线程修改了,放弃当前修改操作,重新尝试着去获取值,再进行处理、比较、交换操作。
(3)重量级锁
默认自旋10次升级为重量级锁。
34、什么是CAS
(1)CAS实现原理
CAS是Compare And Swap的缩写,意思就是比较并交换。
它是无锁化的实现,是经典的乐观锁。
synchronized是一种悲观锁,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。
乐观锁就是不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁的机制就是CAS。
CAS操作很简单,它包含三个操作数:内存地址V、预期原值A、新值B。先比较内存地址V处的值和预期原值A是否相等,如果相等就将内存地址V处更新为新值B。在配合循环使用时,若CAS操作失败,会循环执行或到达某个终止处。此操作配合循环使用时,又称为自旋锁的实现方式。
(2)CAS存在的问题
① ABA问题
解决办法:
加时间戳
加版本号
② 循环开销大
CAS是乐观锁,如果线程比较多,资源抢占激烈,命中率低的情况下,不断的循环会不断的消耗资源。实际上,可以设置最大循环数,达到最大循环数还没有占有资源就自动放弃,避免无限的循环。
③ 只能保证一个共享变量的原子操作。

35、byte类型127+1等于多少
byte的范围是-128~127。
字节长度为8位,最左边的是符号位,而127的二进制为01111111,所以执行+1操作时,01111111变为10000000。
大家知道,计算机中存储负数,存的是补码的兴衰。左边第一位为符号位。
那么负数的补码转换成十进制如下:
一个数如果为正,则它的原码、反码、补码相同;一个正数的补码,将其转化为十进制,可以直接转换。
已知一个负数的补码,将其转换为十进制数,步骤如下:
- 先对各位取反;
- 将其转换为十进制数;
- 加上负号,再减去1;
例如10000000,最高位是1,是负数,①对各位取反得01111111,转换为十进制就是127,加上负号得-127,再减去1得-128;
36、数据库一般会采取什么样的优化方法?
(1)选取适合的字段属性
为了获取更好的性能,可以将表中的字段宽度设得尽可能小。
尽量把字段设置成not null
执行查询的时候,数据库不用去比较null值。
对某些省份或者性别字段,将他们定义为enum类型,enum类型被当做数值型数据来处理,而数值型数据被处理起来的速度要比文本类型块很多。
(2)使用join连接代替子查询
(3)使用联合union来代替手动创建的临时表
注意:union用法中,两个select语句的字段类型要匹配,而且字段个数要相同。
(4)事务
要么都成功,要么都失败。
可以保证数据库中数据的一致性和完整性。事务以begin开始,commit关键字结束。
如果出错,rollback命令可以将数据库恢复到begin开始之前的状态。
事务的另一个重要作用是当多个用户同时使用相同的数据源时,它可以利用锁定数据库的方式为用户提供一种安全的访问方式,这样就可以保证用户的操作不被其他的用户干扰。
(5)锁定表
尽管事务是维护数据库完整性的一个非常好的方法,但却因为它的独占性,有时会影响数据库的性能,尤其是在大应用中。
由于在事务执行的过程中,数据库会被锁定,因此其它用户只能暂时等待直到事务结束。
有的时候可以用锁定表的方法来获得更好的性能,
共享锁:其它用户只能看,不能修改
lock table person in share mode;
对于通过lock table 命令主动添加的锁来说,如果要释放它们,只需发出rollback命令即可。
(6)使用外键
锁定表的方法可以维护数据的完整性,但是它却不能保证数据的关联性,这个时候可以使用外键。
(7)使用索引
索引是提高数据库查询速度的常用方法,尤其是查询语句中包含max()、min()、order by这些命令的时候,性能提高更为显著。
一般来说索引应该建在常用于join、where、order by的字段上。尽量不要对数据库中含有大量重复的值得字段建立索引。
(8)优化的查询语句
在索引的字段上尽量不要使用函数进行操作。
尽量不要使用like关键字和通配符,这样做法很简单,但却是以牺牲性能为代价的。
避免在查询中进行自动类型转换,因为类型转换也会使索引失效。
37、说一下事务的隔离级别
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted 、Read committed 、Repeatable read 、Serializable 。
38、Object常用方法
getClass、equals、hashcode、clone、wait、notify、notifyAll、
39、beanFactory和factoryBean的区别
beanFactory是Spring关于容器的父接口,用来管理bean的接口,管理bean的注入和销毁;
factoryBean是Spring用来对beanFactory中的bean进行修饰的类,相当于装饰器模式;
40、索引怎么定义,分哪几种
- b-tree索引,如果不建立索引的情况下,oracle就自动给每一列都加一个B 树索引;
- normal:普通索引
- unique:唯一索引
- bitmap:位图索引,位图索引特定于只有几个枚举值的情况,比如性别字段;
- 基于函数的索引
41、简单介绍一下Java多线程
(1)线程的实现方式
- 继承Thread类;
- 实现Runnable接口;
该方式的优点:
可以避免由于java单继承带来的局限性,适合多个相同程序的代码去处理同一个资源的情况,把线程和程序的代码、数据有效分离,较好的体现了面向对象的设计思想。
(2)线程生命周期
创建、就绪、运行、阻塞、死亡
(3)线程控制
线程休眠sleep、线程加入join、线程礼让yield
42、easyExcel如何实现
异步读取
新建一个 ExcelModelListener 监听类出来,并且 继承 AnalysisEventListener 类
package com.zh.oukele.listener;
import com.alibaba.excel.context.AnalysisContext;
import com.alibaba.excel.event.AnalysisEventListener;
import com.zh.oukele.model.ExcelMode;
import java.util.ArrayList;
import java.util.List;
/***
* 监听器
*/
public class ExcelModelListener extends AnalysisEventListener<ExcelMode> {
/**
* 每隔5条存储数据库,实际使用中可以3000条,然后清理list ,方便内存回收
*/
private static final int BATCH_COUNT = 5;
List<ExcelMode> list = new ArrayList<ExcelMode>();
private static int count = 1;
@Override
public void invoke(ExcelMode data, AnalysisContext context) {
System.out.println("解析到一条数据:{ "+ data.toString() +" }");
list.add(data);
count ++;
if (list.size() >= BATCH_COUNT) {
saveData( count );
list.clear();
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData( count );
System.out.println("所有数据解析完成!");
System.out.println(" count :" + count);
}
/**
* 加上存储数据库
*/
private void saveData(int count) {
System.out.println("{ "+ count +" }条数据,开始存储数据库!" + list.size());
System.out.println("存储数据库成功!");
}
}43、ArrayList 和 Vector 的区别是什么?
Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
在不考虑并发问题的时候还是推荐使用Arraylist。
44、Array 和 ArrayList 有何区别?
- Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
- Array大小是固定的,ArrayList的大小是动态变化的。
- ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
- 对于基本类型数据,ArrayList 使用自动装箱来减少编码工作量;而当处理固定大小的基本数据类型的时候,这种方式相对比较慢,这时候应该使用Array。
45、除了 ReetrantLock,你还接触过 JUC 中的哪些并发工具?
juc下常用的五个高并发工具:
- CountDownLatch:同步计数器
- CyclicBarrier: 线程屏障的功能
- Exchanger:用来使两个线程交换数据。
- Semaphore:控制信号量的个数,构造时传入个数。总数就是控制并发的数量。
- Future:接口,FutureTask是它的实现类,配合线程池来一起工作,将任务交给线程池去处理。
46、请谈谈 ReadWriteLock 和 StampedLock。
(1)ReadWriteLock
ReadWriteLock 可以实现多个读锁同时进行,但是读与写和写于写互斥,只能有一个写锁线程在进行。
(2)StampedLock
StampedLock是Jdk在1.8提供的一种读写锁,相比较ReentrantReadWriteLock性能更好,因为ReentrantReadWriteLock在读写之间是互斥的,使用的是一种悲观策略,在读线程特别多的情况下,会造成写线程处于饥饿状态,虽然可以在初始化的时候设置为true指定为公平,但是吞吐量又下去了,而StampedLock是提供了一种乐观策略,更好的实现读写分离,并且吞吐量不会下降。
StampedLock包括三种锁:
(1)写锁writeLock:
writeLock是一个独占锁写锁,当一个线程获得该锁后,其他请求读锁或者写锁的线程阻塞, 获取成功后,会返回一个stamp(凭据)变量来表示该锁的版本,在释放锁时调用unlockWrite方法传递stamp参数。提供了非阻塞式获取锁tryWriteLock。
(2)悲观读锁readLock:
readLock是一个共享读锁,在没有线程获取写锁情况下,多个线程可以获取该锁。如果有写锁获取,那么其他线程请求读锁会被阻塞。悲观读锁会认为其他线程可能要对自己操作的数据进行修改,所以需要先对数据进行加锁,这是在读少写多的情况下考虑的。请求该锁成功后会返回一个stamp值,在释放锁时调用unlockRead方法传递stamp参数。提供了非阻塞式获取锁方法tryWriteLock。
(3)乐观读锁tryOptimisticRead:
tryOptimisticRead相对比悲观读锁,在操作数据前并没有通过CAS设置锁的状态,如果没有线程获取写锁,则返回一个非0的stamp变量,获取该stamp后在操作数据前还需要调用validate方法来判断期间是否有线程获取了写锁,如果是返回值为0则有线程获取写锁,如果不是0则可以使用stamp变量的锁来操作数据。由于tryOptimisticRead并没有修改锁状态,所以不需要释放锁。这是读多写少的情况下考虑的,不涉及CAS操作,所以效率较高,在保证数据一致性上需要复制一份要操作的变量到方法栈中,并且在操作数据时可能其他写线程已经修改了数据,而我们操作的是方法栈里面的数据,也就是一个快照,所以最多返回的不是最新的数据,但是一致性得到了保证。
47、说一下 tcp 粘包是怎么产生的?
- 发送方需要等缓冲区满才能发送出去,造成粘包;
- 接收方不及时接收缓冲区的包,造成粘包;
48、举一个用 Java 实现的装饰模式(decorator design pattern)?它是作用于对象层次还是类层次?
在Java IO中运用了装饰器模式,inputStream作为抽象类,其下有几个实现类,表示从不同的数据源输入:
- byteArrayInputStream
- fileInputStream
- StringBufferInputStream
- PipedInputStream,从管道产生输入;
- SequenceInputStream,可将其他流收集合并到一个流内;
FilterInputStream作为装饰器在JDK中是一个普通类,其下面有多个具体装饰器比如BufferedInputStream、DataInputStream等。
FilterInputStream内部封装了基础构件:
protected volatile InputStream in;而BufferedInputStream在调用其read()读取数据时会委托基础构件来进行更底层的操作,而它自己所起的装饰作用就是缓冲,在源码中可以很清楚的看到这一切。
49、请举例说明如何在 Spring 中注入一个 Java Collection?
Spring注入有四种方式,
- set注入;
- 构造器注入;
- 基于注解的注入;
- xml配置文件注入;
想要注入java collection,就是注入集合类:
- list
- set
- map
- props:该标签支持注入键和值都是字符串类型的键值对。
list和set都使用value标签;map使用entry标签;props使用prop标签;
50、什么是 Swagger?你用 Spring Boot 实现了它吗?
Swagger是用于生成RestFul Web服务的可视化表示工具,它使文档和服务器可视化更新;
当定义好Swagger后,可以调用服务端接口,来查看接口的返回值,验证返回数据的正确性;
51、什么是 Spring Profiles?
Spring Profiles允许用户根据配置文件(dev、test、prod)来判定加载哪些配置文件,完成注册bean;
52、在 hibernate 中使用 Integer 和 int 做映射有什么区别?
hibernate是面向对象的ORM,所以一般定义成封装类型,要看数据库中的定义,如果数据库中有对应字段存在null值,就要定义Integer。也可以定义基本类型,在配置文件中写清楚即可。
53、mysql 的内连接、左连接、右连接有什么区别?
内连接,显示两个表中有联系的所有数据;
左链接,以左表为参照,显示所有数据,右表中没有则以null显示
右链接,以右表为参照显示数据,,左表中没有则以null显示
54、Redis支持的数据类型有哪些?
String、hash、list、set、zset(sorted set:有序集合)
55、详细介绍一下 CMS 垃圾回收器?
CMS 垃圾回收器是Concurrent Mark Sweep,是一种同步的标记-清除,CMS分为四个阶段:
- 初始标记,标记一下GC Root能直接关联到的对象,会触发“Stop The World”;
- 并发标记,通过GC Roots Tracing判断对象是否在使用中;
- 重新标记,标记期间产生对象的再次判断,执行时间较短,会触发“Stop The World”;
- 并发清除,清除对象,可以和用户线程并发进行;
56、新生代垃圾回收器和老生代垃圾回收器都有哪些?有什么区别?
新生代回收器:Serial、ParNew、Parallel Scavenge
老年代回收器:Serial Old、Parallel Old、CMS
新生代回收器一般采用的是复制算法,复制算法效率较高,但是浪费内存;
老生代回收器一般采用标记清楚算法,比如最常用的CMS;
57、简述分代垃圾回收器是怎么工作的?
分代回收器分为新生代和老年代,新生代大概占1/3,老年代大概占2/3;
新生代包括Eden、From Survivor、To Survivor;Eden区和两个survivor区的 的空间比例 为8:1:1 ;
垃圾回收器的执行流程:
- 把 Eden + From Survivor 存活的对象放入 To Survivor 区;
- 清空 Eden + From Survivor 分区,From Survivor 和 To Survivor 分区交换;
- 每次交换后存活的对象年龄+1,到达15,升级为老年代,大对象会直接进入老年代;
- 老年代中当空间到达一定占比,会触发全局回收,老年代一般采取标记-清除算法;

往期精彩内容:
Java知识体系总结
【全栈最全Java框架总结】SSH、SSM、Springboot
超详细的springBoot学习笔记
常见数据结构与算法整理总结
Java设计模式:23种设计模式全面解析
10万字208道Java经典面试题总结(附答案,建议收藏)
MySql知识体系总结
Linux知识体系总结
【100天算法入门 - 每日三题 - Day1】二叉树的中序遍历、两数之和、整数反转