
目录
第一个爬虫程序:
Web请求的全过程剖析:
HTTP协议:
请求:
请求头中常见的重要内容:
请求方式:
响应:
Requests:
数据解析:
数据提取的三种解析方式:
正则表达式:
爬取案例:
获取数据结果:
安装bs4:
环境搭建:
安装Selenium
安装浏览器驱动程序:
EdgeDriver:
ChromeDriver:
Selenium元素定位:
Chrome Handless:
系统要求:
第一个爬虫程序:
爬虫:通过编写程序来获取互联网上的资源!
需求:用程序模拟浏览器,输入一个网址,从该网站中获取到资源或者内容!
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
with open("mybaidu.html", mode="w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8")) # 读取到网站页面源代码
print("over!")Web请求的全过程剖析:
- 服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器,在页面原代码中能看到数据。
- 客户端渲染:第一次请求只要一个html骨架,第二次请求拿到数据,进行数据展示。在页面源代码中,看不到数据
HTTP协议:
协议:就是把两个计算机之间为了能够流畅的进行沟通而设置的一个君子协定,常见的协议有TCP/IP,SOAP协议,HTTP协议,SMTP协议等等......
HTTP协议,Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议,就是浏览器和服务器之间的数据交互遵守的就是HTTP协议。
HTTP协议把一条消息分为三大块内容。无论是请求还是响应都应该是三大块内容:
请求:
请求行 -> 请求方式(get/post) 请求url地址 协议
请求头 -> 存放些服务器要使用的附加信息
请求体 -> 一般放一些请求参数请求头中常见的重要内容:
- User-Agent:请求载体的身份标识(用什么来发送的请求)
- Referer:防盗链(此次请求是从哪个页面进行获取,反爬使用)
- cookie:本地字符串数据信息(用户登录信息,反爬token)
请求方式:
- GET:显示请求
- POST:隐式请求
响应:
状态行 -> 协议 状态码
响应头 -> 存放一些客户端需要使用的附加信息
响应体 -> 服务器返回的真正客户端要使用的内容(HTML,JSON)等数据
Requests:
安装Requests:pip install requests
在PyCharm中点击Terminal打开命令窗口:

# 使用requests包,使用前需要通过命令行进行安装!!!
import requests
url = 'https://cn.bing.com/search?q=java' # url:浏览器请求地址,爬虫爬取数据地址
dic = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36 Edg/92.0.902.78'
}
resp = requests.get(url, headers=dic) # 添加请求载体,处理一个简单的反爬机制
print(resp.text) # 获取到网页源码数据解析:
在大多数的情况下,我们并不需要整个网页的内容,只是需要其中有效数据,这就涉及到了数据的提取。
数据提取的三种解析方式:
- re解析
- bs4解析
- xpath解析
这三种方式可以混合使用,完全以结果为导向,只要能获取需要的数据,用什么方法并不重要,当你掌握了这些之后,再考虑性能的问题!!!
正则表达式:
文章连接:一篇搞定正则表达式
爬取案例:
# 通过requests,拿到页面源代码
# 通过re来提取想要的有效信息
import requests
import re
# 数据存储格式模块
import csv
# 1.获取爬取站点的url地址,配置请求头:
url = 'https://movie.douban.com/top250'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome'
'/92.0.4515.159 Safari/537.36 Edg/92.0.902.78'
}
# 2.通过requests模块中的get方法,对该地址的服务器进行请求,返回响应rsp:
rsp = requests.get(url=url, headers=header)
# 3.请求结果:
page_content = rsp.text
# 解析数据(使用正则表达式):
obj = re.compile(r'<li>.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">(?P<director>.*?) '
r'(?P<performer>.*?)<br>.*?(?P<year>.*?) / .*?<span property="v:best" content="10.0">'
r'</span>.*?<span>(?P<comment>.*?)</span>.*?<span class="inq">'
r'(?P<direction>.*?)</span>',
re.S)
result = obj.finditer(page_content)
# 准备文件:
file = open('data.csv', mode='w', encoding='utf-8') # 设置文件字符编码为utf-8,默认是GBK,会导致文件编码和IDE(utf-8)写入编码不一致
# 准备CSV写入器(数据内容会写入到file文件中):
CSVWrite = csv.writer(file)
# 通过迭代器,写出数据到CSV文件:
for r in result:
# print(r.group('name').split())
# print(r.group('director').split())
# print(r.group('performer').split())
# print(r.group('year').split())
# print(r.group('comment').split())
# print(r.group('direction').split())
# print('\n')
dic = r.groupdict()
dic['name'] = dic['name'].strip()
dic['director'] = dic['director'].strip()
dic['performer'] = dic['performer'].strip()
dic['year'] = dic['year'].strip()
dic['comment'] = dic['comment'].strip()
dic['direction'] = dic['direction'].strip()
CSVWrite.writerow(dic.values())
# 关闭文件:
file.close()
# 打印结果:
print('over!')
# 4.关闭rsp:
rsp.close()获取数据结果:
肖申克的救赎,导演: 弗兰克·德拉邦特 Frank Darabont,主演: 蒂姆·罗宾斯 Tim Robbins /...,1994,2435461人评价,希望让人自由。
霸王别姬,导演: 陈凯歌 Kaige Chen,主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...,1993,1811073人评价,风华绝代。
阿甘正传,导演: 罗伯特·泽米吉斯 Robert Zemeckis,主演: 汤姆·汉克斯 Tom Hanks / ...,1994,1831357人评价,一部美国近现代史。
这个杀手不太冷,导演: 吕克·贝松 Luc Besson,主演: 让·雷诺 Jean Reno / 娜塔莉·波特曼 ...,1994,1997475人评价,怪蜀黍和小萝莉不得不说的故事。
泰坦尼克号,导演: 詹姆斯·卡梅隆 James Cameron,主演: 莱昂纳多·迪卡普里奥 Leonardo...,1997,1793280人评价,失去的才是永恒的。
美丽人生,导演: 罗伯托·贝尼尼 Roberto Benigni,主演: 罗伯托·贝尼尼 Roberto Beni...,1997,1122598人评价,最美的谎言。
千与千寻,导演: 宫崎骏 Hayao Miyazaki,主演: 柊瑠美 Rumi Hîragi / 入野自由 Miy...,2001,1911622人评价,最好的宫崎骏,最好的久石让。
辛德勒的名单,导演: 史蒂文·斯皮尔伯格 Steven Spielberg,主演: 连姆·尼森 Liam Neeson...,1993,934608人评价,拯救一个人,就是拯救整个世界。
盗梦空间,导演: 克里斯托弗·诺兰 Christopher Nolan,主演: 莱昂纳多·迪卡普里奥 Le...,2010,1761254人评价,诺兰给了我们一场无法盗取的梦。
忠犬八公的故事,导演: 莱塞·霍尔斯道姆 Lasse Hallström,主演: 理查·基尔 Richard Ger...,2009,1211124人评价,永远都不能忘记你所爱的人。
星际穿越,导演: 克里斯托弗·诺兰 Christopher Nolan,主演: 马修·麦康纳 Matthew Mc...,2014,1435042人评价,爱是一种力量,让我们超越时空感知它的存在。
楚门的世界,导演: 彼得·威尔 Peter Weir,主演: 金·凯瑞 Jim Carrey / 劳拉·琳妮 Lau...,1998,1356451人评价,如果再也不能见到你,祝你早安,午安,晚安。
海上钢琴师,导演: 朱塞佩·托纳多雷 Giuseppe Tornatore,主演: 蒂姆·罗斯 Tim Roth / ...,1998,1431659人评价,每个人都要走一条自己坚定了的路,就算是粉身碎骨。
三傻大闹宝莱坞,导演: 拉库马·希拉尼 Rajkumar Hirani,主演: 阿米尔·汗 Aamir Khan / 卡...,2009,1605312人评价,英俊版憨豆,高情商版谢耳朵。
机器人总动员,导演: 安德鲁·斯坦顿 Andrew Stanton,主演: 本·贝尔特 Ben Burtt / 艾丽...,2008,1129897人评价,小瓦力,大人生。
放牛班的春天,导演: 克里斯托夫·巴拉蒂 Christophe Barratier,主演: 热拉尔·朱尼奥 Gé...,2004,1114896人评价,天籁一般的童声,是最接近上帝的存在。
无间道,导演: 刘伟强 / 麦兆辉,主演: 刘德华 / 梁朝伟 / 黄秋生,2002,1098361人评价,香港电影史上永不过时的杰作。
疯狂动物城,导演: 拜伦·霍华德 Byron Howard / 瑞奇·摩尔 Rich Moore,主演: 金妮弗·...,2016,1588576人评价,迪士尼给我们营造的乌托邦就是这样,永远善良勇敢,永远出乎意料。
大话西游之大圣娶亲,导演: 刘镇伟 Jeffrey Lau,主演: 周星驰 Stephen Chow / 吴孟达 Man Tat Ng...,1995,1304007人评价,一生所爱。
熔炉,导演: 黄东赫 Dong-hyuk Hwang,主演: 孔侑 Yoo Gong / 郑有美 Yu-mi Jung /...,2011,790634人评价,我们一路奋战不是为了改变世界,而是为了不让世界改变我们。
教父,导演: 弗朗西斯·福特·科波拉 Francis Ford Coppola,主演: 马龙·白兰度 M...,1972,794767人评价,千万不要记恨你的对手,这样会让你失去理智。
当幸福来敲门,导演: 加布里尔·穆奇诺 Gabriele Muccino,主演: 威尔·史密斯 Will Smith ...,2006,1292846人评价,平民励志片。
龙猫,导演: 宫崎骏 Hayao Miyazaki,主演: 日高法子 Noriko Hidaka / 坂本千夏 Ch...,1988,1080655人评价,人人心中都有个龙猫,童年就永远不会消失。
怦然心动,导演: 罗伯·莱纳 Rob Reiner,主演: 玛德琳·卡罗尔 Madeline Carroll / 卡...,2010,1540956人评价,真正的幸福是来自内心深处。
控方证人,导演: 比利·怀尔德 Billy Wilder,主演: 泰隆·鲍华 Tyrone Power / 玛琳·...,1957,390934人评价,比利·怀德满分作品。安装bs4:
pip install bs4
环境搭建:
安装Selenium
打开IDEA的Terminal窗口,输入以下命令:
pip install selenium
安装浏览器驱动程序:
EdgeDriver:
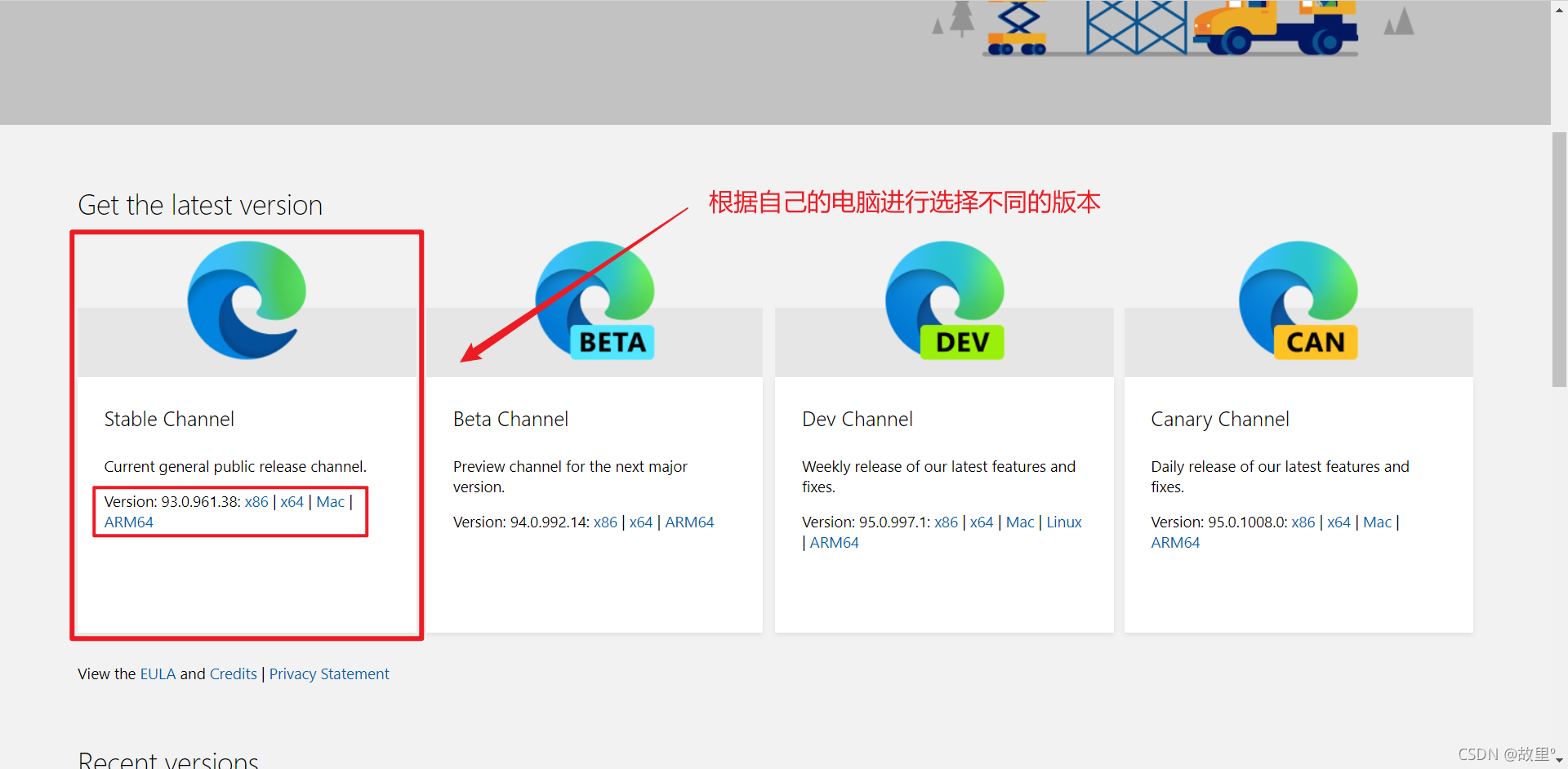
我这里使用的是Edge浏览器,需要在官网上去下载,Edge浏览器的驱动文件
官网传送口: Microsoft Edge Driver - Microsoft Edge Developer
from selenium import webdriver
driverpath = "C:\driver\msedgedriver.exe" # 我存放驱动文件地址
driver = webdriver.Edge(executable_path=driverpath) # 加载驱动
driver.get("https:www.bilibili.com") # 浏览器访问的路径
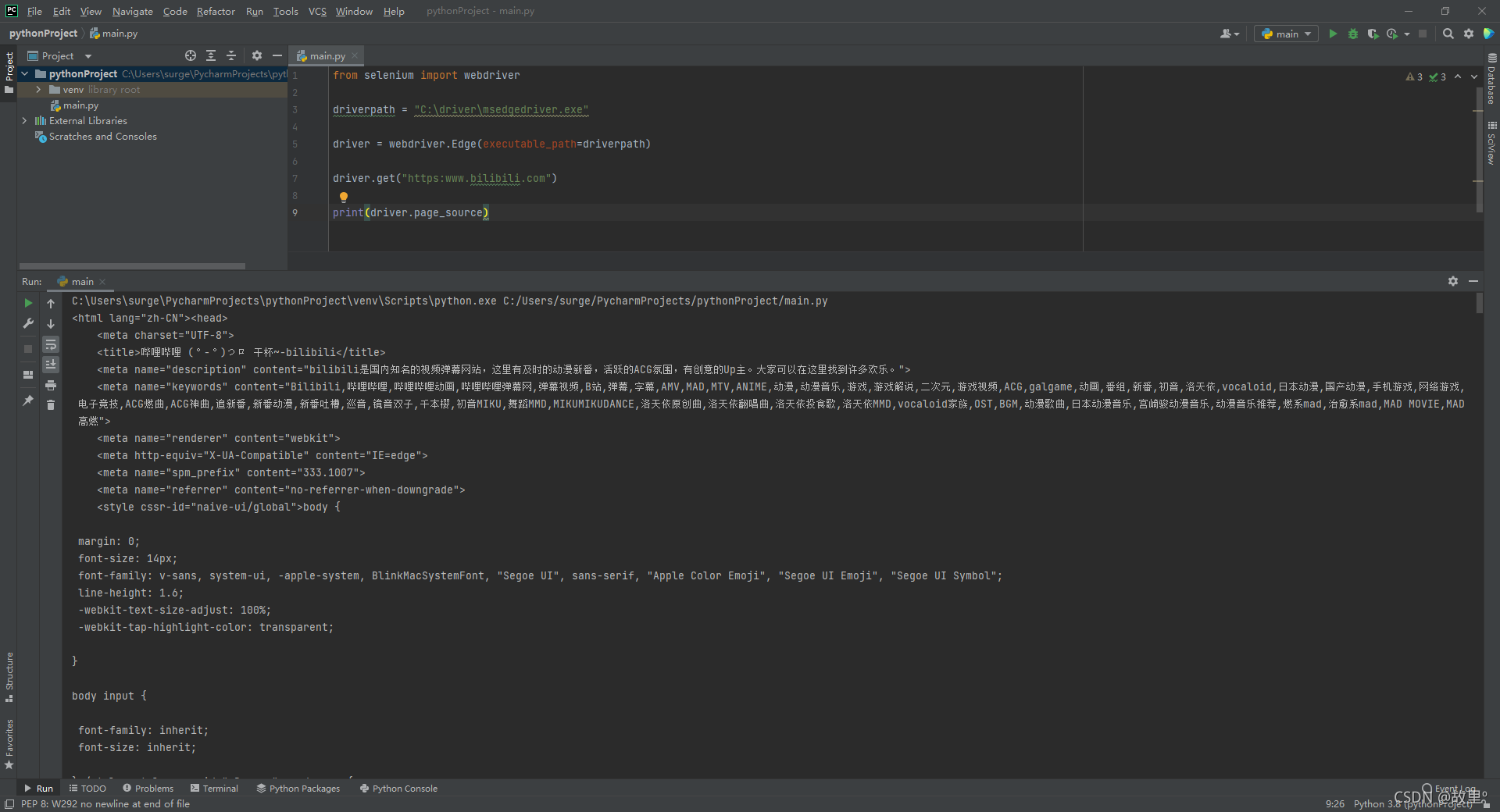
print(driver.page_source)程序执行成功后,电脑上的Edge浏览器会被测试程序(EdgeDriver)进行托管:
控制台打印出网页源码:
ChromeDriver:
谷歌浏览器驱动传送口:
ChromeDriver Mirror (taobao.org)
查看你安装的Chrome浏览器版本:
- 进入Chrome浏览器设置
- 找到关于Chrome
- 查看当前浏览器版本

这里的驱动程序一般都是向下兼容的,如果找不到对应的版本号的浏览器驱动,可以选择临近的新版本,不影响使用!
# 导入包依赖
from selenium import webdriver
# 指定Driver路径
driverPath = '../driver/chromedriver.exe'
# 创建浏览器实体
browser = webdriver.Chrome(driverPath)
# 指定访问网站
url = 'https://www.bilibili.com'
browser.get(url=url)
Selenium元素定位:
元素定位:自动化要做的就是模拟鼠标和键盘来操作这些元素,点击,输入等等。进行这些操作之前,首先需要找到他们,Webdriver提供了多种定位元素的方法:
| 方法 | EG |
|---|---|
| find_element_by_id | button = browser.find_element_by_id(' su ') |
| find_element_by_name | name = browser.find_element_by_name(' wd ') |
| find_element_by_xpath | xpathDemo = browser.find_element_by_xpath(' //imput[@id="su"] ') |
| find_element_by_tag_name | names = browser.find_elemnet_by_tag_name(' input ') |
| find_element_by_css_selector | my_input = browser.find_element_by_css_selecter(' #kw ')[0] |
| find_element_by_link_text | browser.find_element_by_link_text(' 新闻 ') |
定位到响应元素之后,我们可以通过以下几种方式获取元素中的信息:
| 方法 | 代码实现 |
| 获取元素属性 | .get_attribute(' class ') |
| 获取元素文本 | .text |
| 获取标签名 | .tag_name |
Selenium的交互:
| 事件 | 代码实现 |
| 点击 | click() |
| 输入 | send_keys() |
| 后退操作 | browser.back() |
| 前进操作 | browser.forword() |
| 模拟JS滚动 | JS = 'document.documentElement.scrollTop = 100000' browser.execute_script(JS) # 执行JS代码 |
| 获取网页源码 | page_source |
| 退出 | browser.quit() |
Chrome Handless:
简而言之,Headless Browser是没有图形用户界面(GUI)的web浏览器,通常是通过编程或命令行界面来控制的。Headless Browser的许多用处之一是自动化可用性测试或测试浏览器交互。
Chrome Handless 模式,Google针对Chrome浏览器 59版新增加的一种模式,可以让你不打开UI界面的情况下使用Chrome浏览器,所以运行效果与Chrome保持一致。
系统要求:
- Chrome浏览器版本 >= 60
- Python 3.6 以上
- Selenium 3.4 以上
- ChromeDriver 2.31 以上
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path:存放浏览器执行文件路径
path = 'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(options=chrome_options)
# 目标地址
url = 'https://www.bilibili.com'
browser.get(url=url)
browser.save_screenshot('bilibili.png')