面试经历
面试官:你说下什么是侵入式链表吧?
我:链表还分什么式?
面试官:是的
我:哦,从前面插入,从后面插入,对吧
面试官:eng?
我:哦,不对,侵入式,强行插入吧
面试官:停停停
旁边的人事小姐姐听了我的回答,面色红润,我心想我的回答应该不错,美滋滋😄
面试官:那个,你怎么来的呀?
我:开车
面试官:好的,你先回去等通知吧
我心想,这么简单,这么顺利。可,回去等了半个月也没见动静,忽然意识当时回答侵入式链表的时候估计有失偏颇,赶紧上网查了下什么是侵入式链表。这才明白,原来是这样。。。
链表
链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性表中的数据,存储单元不一定是连续的,
且链表的长度不是固定的,链表数据的这一特点使其可以非常的方便地实现节点的插入和删除操作。
链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构。
除了存储元素本身的信息外,还要存储其直接后继信息。因此,每个节点都包含两个部分,第一部分称为链表的数据域,用于存储元素本身的数据信息,这里用 data 表示,它不局限于一个成员数据,也可是多个成员数据。第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,这里用next表示,next的值实际上就是下一个节点的地址。
普通链表
struct foo_s {
int data;
struct foo_s *next;
};
链表 = 节点1 --> 节点2 -->… (前一个节点的指针域指向下一个节点的数据结构首地址)
节点 = data + next (每个节点都是使用的相同的数据结构)
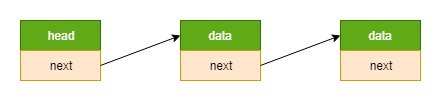
侵入式链表
struct list_s {
struct list_s *next;
} list_t;
struct foo_s {
int data;
struct list_s link;
};
链表 = 节点1 --> 节点2 --> … (前一个节点的指针域指向下一个节点的指针域)
节点 = data + next (节点可以使用不同的数据结构,如 struct foo_s、struct foo_s2,只要在它们内部都包含 struct list_s就可以了)
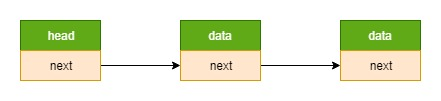
内核链表
内核中使用的链表大多数都是侵入式链表,不过要比上面的例子稍微复杂点,是侵入式双向循环链表,如下图
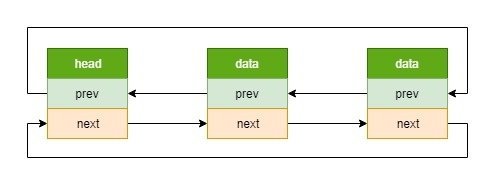
其数据结构如下,这里以 led_classdev 为例
struct list_head {
struct list_head *next, *prev;
};
struct led_classdev {
const char *name;
enum led_brightness brightness;
enum led_brightness max_brightness;
int flags;
...
struct list_head node; /* LED Device list */
...
}
从上面结构体可以看出,链表(list_head)是嵌(侵)入在其它宿主数据结构(led_classdev)中的,这些宿主数据结构可以不相同。并且,这些宿主数据结构中可以包含多个链表。
侵入式链表(内核链表)的好处
如果我们有一种数据结构 foo,并且需要维持一个这种数据结构的双链队列,最简单的、也是最常用的办法就是在这个数据结构的类型定义中加入两个指针,例如:
typedef struct foo {
struct foo *prev;
struct foo *next;
....
} foo;
然后为这种数据结构写一套用于各种队列操作的子程序。由于用来维持队列的这两个指针的类型是固定的(都指向 foo 数据结构),这些子程序不能用于其它数据结构的队列。换言之,需要维持多少种数据结构的队列,就得有多少套的队列操作子程序。对于使用队列较少的应用程序或许不是个大问题,但对于使用大量队列的内核就成问题了。所以,Linux 内核中采用了一套通用的、一般的、可以用到各种不同数据结构的队列操作。为此,代码的作者们把指针 prev 和 next 从具体的“宿主”数据结构中抽象出来成为一种数据结构 list_head,这种数据结构既可以“寄宿”在具体的宿主数据结构内部,成为该数据结构的一个“连接件”;也可以独立存在而成为一个队列的头。这个数据结构的定义在 include/linux/list.h 中
实例解析
我们以用于内存页面管理的 page 数据结构为例:
typedef struct page {
struct list_head list;
...
struct list_head lru;
...
} mem_map_t;
可见,在 page 数据结构中寄宿了两个 list_head 结构,或者说有两个队列操作的连接件,所以 page 结构可以同时存在于两个双链队列中。
一个疑问
有些小伙伴可能发问了:队列操作都是通过 list_head 进行的,但是那不过是个连接件,如果我们手上有宿主结构,那当然知道它的某个 list_head 在哪里,从而以此为参数调用 list_add() 或 list_del();可是,反过来,当我们顺着一个队列取得其中一项的 list_head 结构时,又怎样找到其宿主结构呢?在 list_head 结构中并没有指向宿主结构的指针啊。毕竟,我们真正关心的是宿主结构,而不是连接件。
这就要提到内核中 offsetof、container_of 这两个神奇的宏了,使用这两个宏,在给定链表结构地址时,我们能够获取其宿主结构的地址。这样就能开心地操作宿主结构了。这里我们只给出它们的定义,后面再专门写文章介绍他们。
include/linux/kernel.h
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })