前言
在上一篇文章中我们已经详细介绍了决策树模型,并且提到了ID3算法及其局限性,那么在本篇文章中,我们将会介绍基于ID3算法进行改良的C4.5算法以及决策树拟合度的优化问题。
目录
- 前言
- 1 C4.5 算法
- 1.1 修改局部最优化条件
- 1.2 连续变量处理手段
- 2 决策树的拟合度优化
- 2.1 决策树剪枝
- 2.2 CART 算法
- 2.2.1 分裂准则
- 2.2.2 二叉分裂的优点
- 2.2.3 利用测试集进行剪枝
- 2.2.3 测试集和验证集
- 结束语
1 C4.5 算法
C4.5 算法与 ID3 算法相似,C4.5 算法对 ID3 算法进行了改进,C4.5 在生成的过程中,用信息增益比准则来选择特征。
1.1 修改局部最优化条件
- 以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。
- 使用信息增益比(information gain ratio)可以对这一问题进行校正。
信息增益比定义为其信息增益与训练数据集关于某一特征的值的熵之比: G a i n _ r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain\_ratio(D,a)=\frac{Gain(D,a)}{IV(a)} Gain_ratio(D,a)=IV(a)Gain(D,a)其中 I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ IV(a)=-\sum_{v=1}^{V}{\frac{|D^v|}{|D|}log_2 \frac{|D^v|}{|D|}} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣称为属性 a 的 "固有值“(intrinsic value)。
属性 a 的可能取值越多(即 V 越大),则 IV(a) 的值通常会越大。
IV 值会随着叶节点上样本量的变小而逐渐变大,也就是说一个特征属性中如果标签分类太多,每个叶子上的 IV 值就会非常大。
值得注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一种启发式:先从候选划分属性中找出信息增益高于平均水平的属性, 再从中选择增益率最高的。
 我们可利用 Gain_ratio 代替 Gain 重新计算数据集中第 0 列的 Gain_ratio ,由于根据 accompany 字段切分后,2 个分支分别有 3 个和 2 个的样例数据,因此其 IV 指标计算过程如下:
I
V
(
′
a
c
c
o
m
p
a
n
y
′
)
=
−
3
5
l
o
g
2
3
5
−
2
5
l
o
g
2
2
5
=
0.971
G
a
i
n
_
r
a
t
i
o
(
′
a
c
c
o
m
p
a
n
y
′
)
=
G
a
i
n
(
′
a
c
c
o
m
p
a
n
y
′
)
I
V
(
′
a
c
c
o
m
p
a
n
y
′
)
=
0.42
0.971
=
0.432
IV('accompany')=-\frac{3}{5}log_2 \frac{3}{5}-\frac{2}{5}log_2 \frac{2}{5}=0.971\\Gain\_ratio('accompany')=\frac{Gain('accompany')}{IV('accompany')}=\frac{0.42}{0.971}=0.432
IV(′accompany′)=−53log253−52log252=0.971Gain_ratio(′accompany′)=IV(′accompany′)Gain(′accompany′)=0.9710.42=0.432然后可进一步计算其他各字段的 Gain_ratio ,并选取 Gain_ratio 最大的字段进行切分。
我们可利用 Gain_ratio 代替 Gain 重新计算数据集中第 0 列的 Gain_ratio ,由于根据 accompany 字段切分后,2 个分支分别有 3 个和 2 个的样例数据,因此其 IV 指标计算过程如下:
I
V
(
′
a
c
c
o
m
p
a
n
y
′
)
=
−
3
5
l
o
g
2
3
5
−
2
5
l
o
g
2
2
5
=
0.971
G
a
i
n
_
r
a
t
i
o
(
′
a
c
c
o
m
p
a
n
y
′
)
=
G
a
i
n
(
′
a
c
c
o
m
p
a
n
y
′
)
I
V
(
′
a
c
c
o
m
p
a
n
y
′
)
=
0.42
0.971
=
0.432
IV('accompany')=-\frac{3}{5}log_2 \frac{3}{5}-\frac{2}{5}log_2 \frac{2}{5}=0.971\\Gain\_ratio('accompany')=\frac{Gain('accompany')}{IV('accompany')}=\frac{0.42}{0.971}=0.432
IV(′accompany′)=−53log253−52log252=0.971Gain_ratio(′accompany′)=IV(′accompany′)Gain(′accompany′)=0.9710.42=0.432然后可进一步计算其他各字段的 Gain_ratio ,并选取 Gain_ratio 最大的字段进行切分。
1.2 连续变量处理手段
在 C4.5 中,同样还增加了针对连续变量的处理手段。如果输入特征字段是连续型变量,则算法首先会对这一列数进行从小到大的排序,然后选取相邻的两个数的中间数作为切分数据集的备选点,若一个连续变量有 N 个值,则在 C4.5 的处理过程中将产生 N-1 个备选切分点,并且每个切分点都代表着一种二叉树的切分方案,例如:
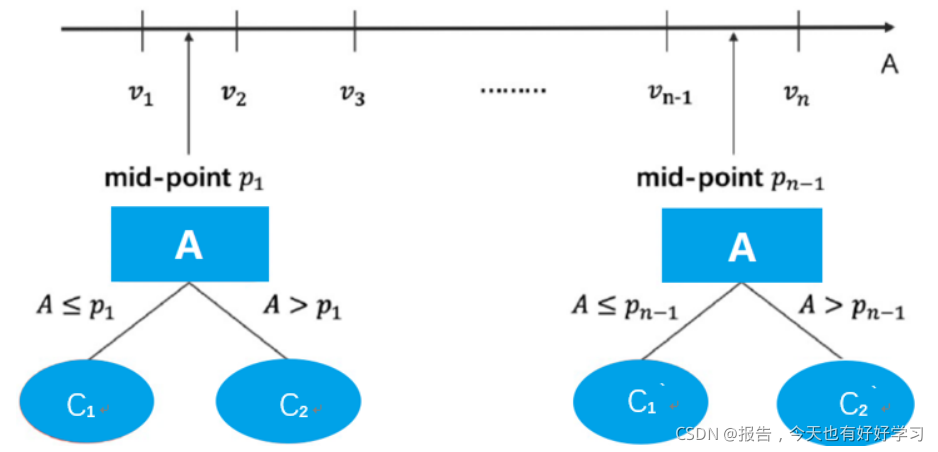
这里需要注意的是,此时针对连续变量的处理并非是将其转化为一个拥有 N-1 个分类水平的分类变量,而是将其转化成了 N-1 个二分方案,而在进行下一次的切分过程中,这 N-1 个方案都要单独带入考虑,其中每一个切分方案和一个离散变量的地位均相同(一个离散变量就是一个单独的多路切分方案)。 例如有如下数据集,数据集中只有两个字段,第一行代表年龄,是特征变量,第二行代表性别,是目标字段,则对年龄这一连续变量的切分方案如图所示:
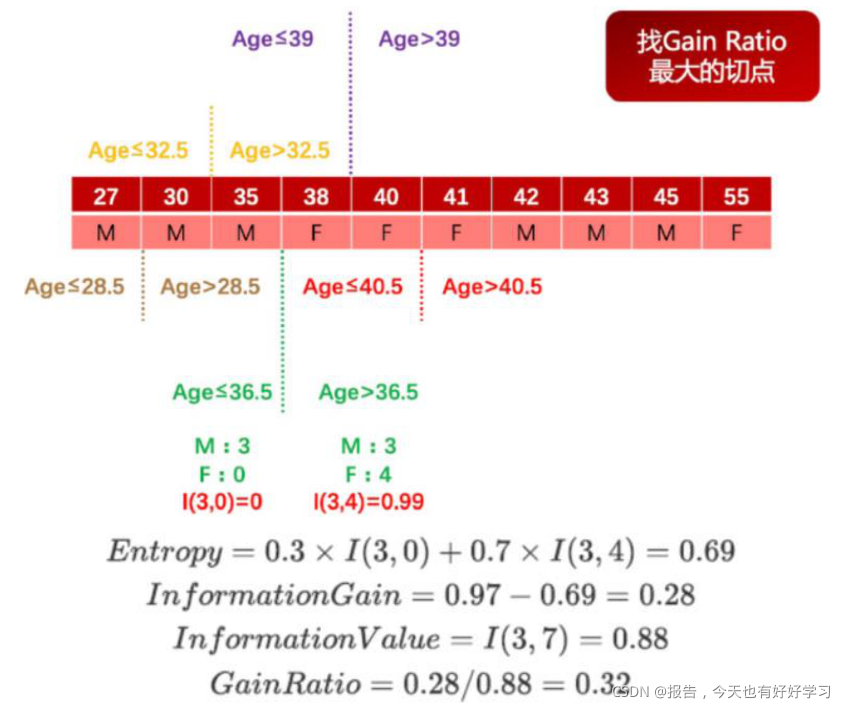
从上述论述能够看出,在对于包含连续变量的数据集进行树模型构建的过程中要消耗更多的运算资源。但与此同时,我们也会发现,当连续变量的某中间点参与到决策树的二分过程中,往往代表该点对于最终分类结果有较大影响,这也为我们连续变量的分箱压缩提供了指导性意见。 例如上述案例,若要对Age 列进行压缩,则可考虑使用 36.5 对其进行分箱,则分箱结果对于性别这一目标字段仍然具有较好的分类效果,这也是决策树的最常见用途之一,也是最重要的模型指导分箱的方法。
下面附上使用C4.5算法建立决策树的Python代码:
import numpy as np
import pandas as pd
# 定义信息熵
def calEnt(dataSet):
n = dataSet.shape[0] # 数据集总行数
iset = dataSet.iloc[:,-1].value_counts() # 统计标签的所有类别
p = iset/n # 统计每一类标签所占比
ent = (-p*np.log2(p)).sum() # 计算信息熵
return ent
# 选择最优的列进行切分
def bestSplit2(dataSet):
baseEnt = calEnt(dataSet) # 计算原始熵
bestGainRatio = 0 # 初始化信息增益
axis = -1 # 初始化最佳切分列,标签列
for i in range(dataSet.shape[1]-1): # 对特征的每一列进行循环
levels= dataSet.iloc[:,i].value_counts().index # 提取出当前列的所有取值
ents = 0 # 初始化子节点的信息熵
IV = 0 # 初始化子节点的属性分裂信息度量
for j in levels: # 对当前列的每一个取值进行循环
childSet = dataSet[dataSet.iloc[:,i]==j] # 某一个子节点的dataframe
ent = calEnt(childSet) # 计算某一个子节点的信息熵
p = childSet.shape[0]/dataSet.shape[0] # 计算当前取值的概率
ents += p*ent # 计算当前列的信息熵
IV += -(p*np.log(p)) # 计算当前列的分裂信息度量
print('第{}列的信息熵为{}'.format(i,ents))
infoGain = baseEnt-ents # 计算当前列的信息增益
print('第{}列的信息增益为{}'.format(i,infoGain))
gainRatio = infoGain / IV # 计算当前列的信息增益率
print('第{}列的信息增益率为{}\n'.format(i,gainRatio))
if (gainRatio > bestGainRatio):
bestGainRatio = gainRatio # 选择最大信息增益率
axis = i # 最大信息增益率所在列的索引
print("第{}列为最优切分列\n".format(axis))
return axis
#为决策树进一步划分去做准备
def mySplit(dataSet,axis,value):
col = dataSet.columns[axis]
redataSet = dataSet.loc[dataSet[col]==value,:].drop(col,axis=1)
return redataSet
"""
函数功能:基于最大信息增益率切分数据集,递归构建决策树
参数说明:
dataSet:原始数据集(最右一列是标签)
return:myTree:字典形式的树
"""
def createTree2(dataSet):
featlist = list(dataSet.columns) # 提取出数据集所有的列
classlist = dataSet.iloc[:,-1].value_counts() # 获取最后一列类标签
# 判断最多标签数目是否等于数据集行数,或者数据集是否只有一列
if classlist[0]==dataSet.shape[0] or dataSet.shape[1] == 1:
return classlist.index[0] # 如果是,返回类标签
axis = bestSplit2(dataSet) # 确定出当前最佳切分列的索引
bestfeat = featlist[axis] # 获取该索引对应的特征
myTree = {bestfeat:{}} # 采用字典嵌套的方式存储树信息
del featlist[axis] # 删除当前特征
valuelist = set(dataSet.iloc[:,axis]) # 提取最佳切分列所有属性值
for value in valuelist: # 对每一个属性值递归建树
myTree[bestfeat][value] = createTree(mySplit(dataSet,axis,value))
return myTree
row_data = {'是否陪伴' :[0,0,0,1,1],
'是否玩游戏':[1,1,0,1,1],
'渣男' :['是','是','不是','不是','不是']}
dataSet = pd.DataFrame(row_data)
createTree2(dataSet)
运行结果如下:
第0列的信息熵为0.5509775004326937
第0列的信息增益为0.4199730940219749
第0列的信息增益率为0.6240205253621535
第1列的信息熵为0.8
第1列的信息增益为0.17095059445466854
第1列的信息增益率为0.3416262320352702
第0列为最优切分列
第0列的信息熵为0.0
第0列的信息增益为0.9182958340544896
第0列的信息增益率为1.4426950408889636
第0列为最优切分列
{‘是否陪伴’: {0: {‘是否玩游戏’: {0: ‘不是’, 1: ‘是’}}, 1: ‘不是’}}
2 决策树的拟合度优化
在实际操作过程中,我们判断模型是否过拟合往往是从模型训练误差和泛化误差的比较中得出,而采用我们之前介绍的交叉验证可得到较为准确的训练误差和泛化误差,二者结合使用就能判断模型是否存在过拟合现象。虽然我们之前举例时并没有对数据集进行切分,但任何有监督学习算法建模过程中都需要进行训练集和测试集的划分,决策树也不例外,进而我们可用交叉验证计算训练误差和泛化误差,进而判断决策树是否存在过拟合。这是一套通用地判断有监督学习算法是否过拟合的方法,同时通用的方法中还有更高级的方法,我们将在后续进行逐步介绍。但对于决策树而言,有一套决策树独有的防止过拟合的解决方案——剪枝。
2.1 决策树剪枝
所谓剪枝是指在决策树中去除部分叶节点。
剪枝(Pruning)主要是用来防止过拟合,对于一般的数据集如果总是追求 ”纯的“ 叶节点,或者观测数较小的叶节点,很容易使得树过于庞杂,尤其是存在可以反复使用的连续变量的时候,此时就需要主动去掉一些分支来降低过拟合的风险。
常见的剪枝策略有 ”预剪枝“(Pre-Pruning)和 ”后剪枝“(Post-Pruning)。
- 预剪枝:在决策树生成的过程中,对每个节点在划分前先进行估计,如果当前的节点划分不能带来决策树泛化性能(预测性能)的提升,则停止划分并且将当前节点标记为叶节点。
- 后剪枝:先训练生成一颗完整的树,自底向上对非叶节点进行考察,如果将该节点对应的子树替换为叶节点能带来决策树泛化能力的提升,则将该子树替换为叶节点。
| \ | 预剪枝 | 后剪枝 |
|---|---|---|
| 分支数 | 很多分支都没有展开 | 保留了更多分支 |
| 拟合风险 | 降低过拟合风险,但是由于基于“贪心”算法的本质禁止后续分支展开,可能会导致模型欠拟合。 | 先生存决策树,自下而上逐一考察,欠拟合风险小,泛化能力更强 |
| 时间开销 | 训练开销和测试开销降低 | 后剪枝是从底往上进行裁剪的,因此其训练时间开销相对较大。 |
2.2 CART 算法
CART:分类回归树(Classification and Regression Tree)
- 分裂过程是一个二叉递归划分过程
- CART 预测变量 x 的类型既可以是连续型变量也可以是分类型变量
- 数据应以其原始形式处理,不需要离散化
- 用于数值型预测时,并没有使用回归,而是基于到达叶节点的案例的平均值做出预测
2.2.1 分裂准则
二叉递归划分:条件成立向左,反之向右
- 对于连续变量:条件是属性小于等于最优分裂点
- 对于分类变量:条件是属性属于若干类
2.2.2 二叉分裂的优点
相比多路分裂导致数据碎片化的速度慢,允许在一个属性上重复分裂,即可以在一个属性上产生足够多的分裂。两路分裂带来的树预测性能提升足以弥补其相应的树易读性损失。
对于属性不同的被预测变量 y 分裂准则不同:
- 分类树:Gini 准则。与之前的信息增益很类似,Gini 系数度量一个节点的不纯度。
- 回归树:一种常见的分割标准是标准偏差减少(Standard Deviation Reduction, SDR),类似于最小均方误差 LS(least squares,预测错误的平方和)准则。
2.2.3 利用测试集进行剪枝
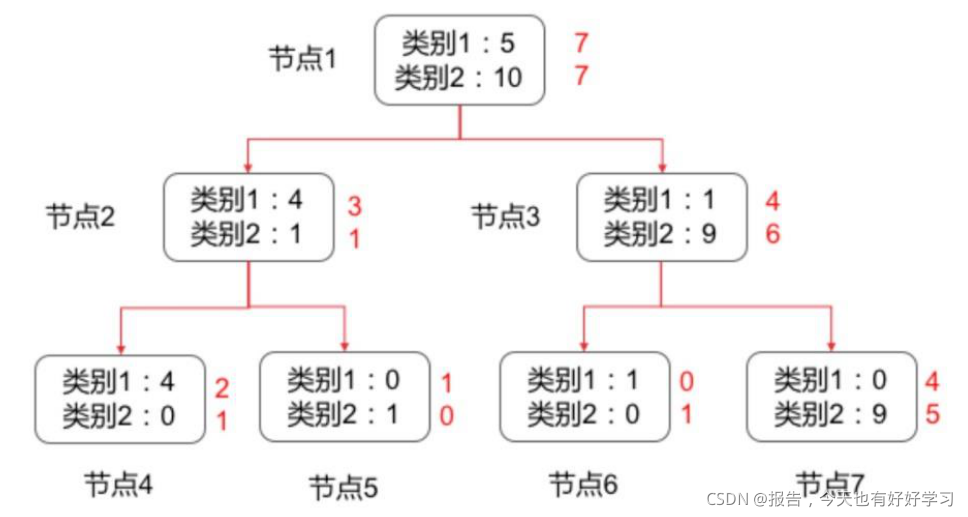
简单讨论 CART 算法剪枝过程,该过程也是测试集用于修正模型的最佳体现。例如,有如下在训练集中训练得到的树模型,黑色数字表示训练集上的分类情况,红色数字表示模型作用于验证集上的分类情况。
则 CART 算法利用验证集剪枝的过程如下:
- 判断每个叶节点在验证集上的错误率:
- 节点 4 的错误率 e ( 4 ) = 1 3 e(4)=\frac{1}{3} e(4)=31
- 节点 5 的错误率 e ( 5 ) = 1 e(5)=1 e(5)=1
- 节点 6 的错误率 e ( 6 ) = 1 e(6)=1 e(6)=1
- 节点 7 的错误率为 e ( 7 ) = 4 9 e(7)=\frac{4}{9} e(7)=94
计算子节点总加权平均错误率并和父节点进行比较,加权方法就是乘以该节点样本量占父节点样本总量的百分比(测试集):
如节点 2 的错误率为 e ( 2 ) = 1 4 e(2)=\frac{1}{4} e(2)=41,而节点 4 和节点 5 的加权平均错误率为 e ( 4 ) ∗ 3 4 + e ( 5 ) ∗ 1 4 = 2 4 e(4)*\frac{3}{4}+e(5)*\frac{1}{4}=\frac{2}{4} e(4)∗43+e(5)∗41=42,因此子节点错误率更高,考虑剪枝;
节点 3 的错误率 e ( 3 ) = 4 10 e(3)=\frac{4}{10} e(3)=104,而 e ( 6 ) ∗ 1 10 + e ( 7 ) ∗ 9 10 = 5 10 e(6)*\frac{1}{10}+e(7)*\frac{9}{10}=\frac{5}{10} e(6)∗101+e(7)∗109=105,因此考虑剪枝;
节点 2 和节点 3 的加权平均错误率为
e
(
2
)
∗
4
14
+
e
(
3
)
∗
10
14
=
5
14
e(2)*\frac{4}{14}+e(3)*\frac{10}{14}=\frac{5}{14}
e(2)∗144+e(3)∗1410=145,比父节点(节点 1)的错
误率
e
(
1
)
=
7
14
e(1)=\frac{7}{14}
e(1)=147要小,因此保留该节点,停止剪枝。
如果读到这里的朋友对上述操作仍有疑问,请详细查看下面内容。
上述剪枝的方法其实是叫做错误率降低剪枝(REP,Reduced-Error Pruning),它是一种较为简单的剪枝方法,它将预先准备好用于建模的数据分为训练集和验证集,训练集用来建立决策树模型,验证集用来评估这个决策树模型在未知数据上的精度,也就是用来评估是否修剪决策树。
其原理是即使学习过程中有可能会因为训练集中的随机情况所误导,但验证集不大可能表现出同样的随机波动,所以验证集可以用于优化其拟合程度。
该方法以树的每个节点为对象,删除的具体步骤如下:
- 删除以此结点为根的子树
- 使其成为叶子结点
- 赋予该结点关联的训练数据的最常见分类
- 当修剪后的树对于验证集合的性能不会比原来的树差时,才真正删除该结点(这就是为什么拿父节点错误率和子结点错误率权重和比较的原因)
REP是从底向上进行处理,直到进一步修剪有害为止(再剪枝会减低验证集合的精度)。
REP是最简单的后剪枝方法之一,不过由于使用独立的测试集,原始决策树相比,修改后的决策树可能偏向于过度修剪。
如果训练集较小,通常不考虑采用REP算法。
2.2.3 测试集和验证集
如果你不了解测试集和验证集的区别的话,可以详细查看下面内容。
对于大多数模型而言,测试集实际上的作用就是用来修正模型,为了提高修正的准确率,我们也可采用交叉验证的方法,反复判别模型修改条件(如是否要剪枝),并设置模型修改触发条件(如多数验证情况需要修改则对其进行修改),从而提高模型优化的可靠性。
而除了训练集和测试集之外,我们还常常会划分一个验证集,验证集数据不参与建模也不参与模型修改和优化,只用于测试最终优化后模型效力。
而训练集、测试集和验证集的划分通常遵照 6:2:2 的比例进行划分,当然也可根据实际需求适当调整划分比例,但无论如何,测试集和验证集数据数量都不宜过多也不宜过少,该二者数据集数据均不参与建模, 若占比太多,则会对模型构建过程造成较大影响(欠拟合),而若划分数据过少,训练集数据量较大, 则又有可能造成过拟合,数据集的划分也是影响拟合度的重要因素。
那朋友们,我们怎么区分数据量大还是小呢?
其实这个并没有明确的规定,通常意义上来讲,千位数级别以下的数据为小数据量,这个时候往往没有设置验证集的必要(会导致训练数据太少了),一般可以采用训练集:测试集=7:3的方式;而如果是几万条数据的话可以采用上述提到的训练集:验证集:测试集=6:2:2的划分方式,而数据达到了百万级别的话,就没必要采用这种划分方式了,可以采用训练集:验证集:测试集=98:1:1的划分方式。
当然,这都只是通常情况下,具体需要你自行调整。
结束语
下一篇文章我会接着介绍决策树模型,主要内容就是利用sklearn实现决策树模型。之所以要将决策树这一部分拆成好几部分是因为我觉得一口吃成大胖子的话还不如细嚼慢咽来得有用,也希望感兴趣的朋友能接着看下去,分享知识对其他人有所帮助或许也是一个创作者最大的乐趣吧。
机器学习系列往期回顾
💚 开始学习机器学习时你必须要了解的模型有哪些?机器学习系列之决策树基础篇
❤️ 以❤️简单易懂❤️的语言带你搞懂有监督学习算法【附Python代码详解】机器学习系列之KNN篇
💜 开始学习机器学习之前你必须要了解的知识有哪些?机器学习系列入门篇
往期内容回顾
🖤 我和关注我的前1000个粉丝“合影”啦!收集前1000个粉丝进行了一系列数据分析,收获满满
❤️ 分享一个超nice的数据分析实战案例 ⭐ “手把手”教学,收藏等于学会
💙 数据分析必须掌握的RFM模型是什么?一文搞懂如何利用RFM对用户进行分类【附实战讲解】
💚 MySQL必须掌握的技能有哪些?超细长文带你掌握MySQL【建议收藏】
💜 Hive必须了解的技能有哪些?万字博客带你掌握Hive❤️【建议收藏】
🧡 一文带你了解Hive【详细介绍】Hive与传统数据库有什么区别?
推荐关注的专栏
👨👩👦👦 机器学习:分享机器学习理论基础和常用模型讲解
👨👩👦👦 数据分析:分享数据分析实战项目和常用技能整理
CSDN@报告,今天也有好好学习