一 内存优化
1.1 内存模型与分布
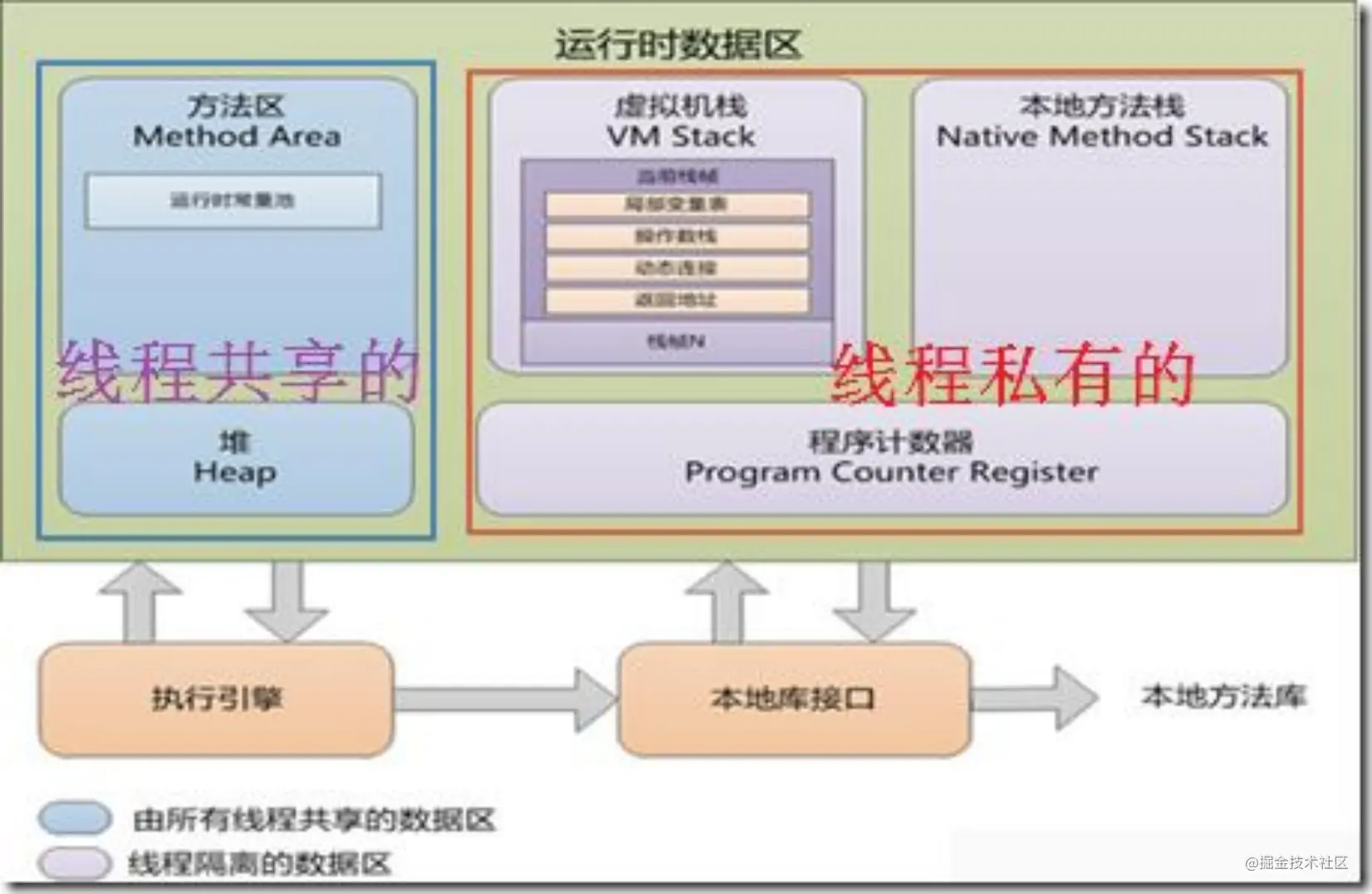
上图是常见的java虚拟机的内存分布图:
-
方法区:主要存储虚拟机加载的类信息,常量,静态变量,及时编译器编译后的代码等数据。内存优化时这一部分主要考虑是不是加载了很多不必要的第三方库。这部分的内存减少主要是常量池的回收和类的卸载(类卸载条件:无引用,类加载器可卸载)。
-
堆:几乎所有的对象都在这个区域产生,该区域属于线程共享的区域,所以写代码时更要注意多线程安全。这个内存区域的大小变化主要是对象的创建和回收,比如:如果短时间内有大量的对象创建和回收,可能会造成内存抖动,如果对象创建之后一直回收不掉,则会导致内存泄漏,严重的内存泄漏会导致频繁的gc,从而是界面卡顿。
-
虚拟机栈:这个区域描述的是java方法执行的内存模型,我们常说的方法栈的入栈就是将方法的栈帧存储到虚拟机栈,这个区域是线程私有的,其生命周期就是线程的生命周期。也就是说每个线程都会有,默认一个线程的线程栈大小是1M,这不包括在方法中产生的其他对象的大小。这一块我们能控制的就是线程的数量,特别是程序中没有使用线程池或者使用的多个第三方库都带有线程池的情况。
-
本地方法栈:同虚拟机栈的作用非常类似,是为虚拟机执行native方法服务的,所以需要注意的地方也和虚拟机栈一样,特别是使用了第三方so的情况。
-
程序计数器:当前线程执行的虚拟机字节码的行号记录器,占用的内存较小,可以不考虑。
1.2 内存限制
android是基于Linux系统的,android中的进程分为两种。
1.2.1 native进程
采用C/C++实现,不包含dalvik实例的linux进程,/system/bin/目录下面的程序文件运行后都是以native进程形式存在的。
1.2.2 java进程
实例化了dalvik虚拟机实例的linux进程,进程的入口main函数为java函数。dalvik虚拟机实例的宿主进程是fork()系统调用创建的linux进程,所以每一个android上的java进程实际上就是一个linux进程,只是进程中多了一个dalvik虚拟机实例。
手机操作系统对每个app进程的内存是有限制的,可以通过如下命令查看限制大小:
adb shell getprop | grep dalvik.vm.heapgrowthlimit可以在Androidmanifest文件中application节点加入android:largeHeap=“true”来增加其dalvik虚拟机中堆的大小
1.3 内存泄漏
常见的内存泄漏:
- 静态引用(自身代码和第三方代码)
- 集合内引用
- Handler消息未清除
- 非静态的内部类中持有外部内的应用。
- 匿名内部类/非静态内部类和异步线程
1.3.1 leakcanary
一般简单的内存泄漏可以直接在)中查到引用链路
1.3.2 MAT
MAT是Memory Analyzer的简称,它是一款功能强大的Java堆内存分析器。可以用于查找内存泄露以及查看内存消耗情况。MAT是基于Eclipse开发的,是一款免费的性能分析工具。 使用步骤:
- 首先通过Memory Profiler抓取hprof
- 使用命令转成MAT工具识别的文件
-
使用Eclipse打开hprof文件
-
工具加载成功后,会生成内存泄漏的可疑报告。然后点击Open Dominator Tree for entire Heaps,查询Heap的树形结构。
-
通过open query browser也就是图片的第二个红框进行条件查询。一般情况下是通过Path to Gc Root,去除所有软弱等引用,得到剩余的一些对象,这些对象基本上就是发生泄漏问题的对象。
或者可以直接搜索可疑的对象类名称,查询对应的引用。
1.3.3 Android Profiler
主要关心以下几个区域:
-
Java:从 Java 或 Kotlin 代码分配的对象的内存。
-
Native:从 C 或 C++ 代码分配的对象的内存。
即使您的应用中不使用 C++,您也可能会看到此处使用的一些原生内存,因为 Android 框架使用原生内存代表您处理各种任务,如处理图像资源和其他图形时,即使您编写的代码采用 Java 或 Kotlin 语言。 -
Graphics:图形缓冲区队列向屏幕显示像素(包括 GL 表面、GL 纹理等等)所使用的内存。(请注意,这是与 CPU 共享的内存,不是 GPU 专用内存。)
-
Stack:您的应用中的原生堆栈和 Java 堆栈使用的内存。这通常与您的应用运行多少线程有关。
-
Code:您的应用用于处理代码和资源(如 dex 字节码、经过优化或编译的 dex 代码、.so 库和字体)的内存。
-
Others:您的应用使用的系统不确定如何分类的内存。
-
Allocated:您的应用分配的 Java/Kotlin 对象数。此数字没有计入 C 或 C++ 中分配的对象。
1.4 优化实践
- 移除程序中多余的代码和引用,这里使用默认的lint检测再配合shrinkResources来删除无效资源。
- 优化图片,保证图片放置在合理的文件夹,根据View大小加载合适的图片大小,根据手机状态配置bitmap和回收策略。
- 优化对象创建,比如通过
Message.obtain()获取Message对象,而不是new Message()。 - 对象释放,比如进行io、数据库操作时,在合适的时机 关闭io流、游标释放。
- 注册与反注册:比如在
onCreate()注册广播registerReceiver(),也要在onDestory()调用unregisterReceiver()
二 IO优化
2.1 DataStore替换 SharedPreferences
DataStore是Jetpack近期新推出的组件,可以以下处理两种类型的数据持久化:
DataStore Type Description Preferences DataStore 像SharedPreferences一样,以键值对的形式进行基本类型的数据存储。
DataStore 基于 Flow 实现异步存储,避免因为阻塞主线程带来的ANR问题 Proto DataStore 基于Protobuf实现任意自定义类型的数据存储,需要定义Protobuf的IDL,但是可以保证类型安全的访问 DataStore相对于SharedPreferences优点更多,可以完全替代SP的使用:
基于Coroutine Flow 实现 保证数据访问一致性 异常处理机制 异步访问,避免同步阻塞 基于Protobuf,实现非基本型数据的存储 附上一张Google官方的对比表格:

2.2 Netty 的 ByteBuf
更高效的字节流操作,可以使用Netty 的 ByteBuf替换 JDK中的bytebuffer。 bytebuffer 是 Java NIO 里面提供的字节容器。有一个指针用于处理读写操作,每次读写的时候都需要调用 flip()或是 clear()方法,不然将会报异常。
- Netty 的 ByteBuf 采用了读写索引分离的策略(readerIndex 与 writerIndex),一个初始化(里面尚未有任何数据)的 ByteBuf 的 readerIndex 与 writerIndex 值都为 0
- 当读索引与写索引处于同一个位置时,如果继续读取,那么就会抛出 IndexOutOfBoundsException。
- ByteBuffer 只有一个标识位置的指针,读写的时候需要手动的调用 flip()和 rewind()等,否则很容易导致程序处理失败。而 ByteBuf 有两个标识位置的指针,一个写 writerIndex,一个读 readerIndex,读写的时候不需要调用额外的方法。
- ByteBuffer 必须自己长度固定,一旦分配完成,它的容量不能动态扩展和收缩;ByteBuf 默认容器大小为 256,支持动态扩容,在允许的最大扩容范围内(Integer.MAX_VALUE)。
- NIO 的 SocketChannel 进行网络读写时,操作的对象是 JDK 标准的 java.nio.byteBuffer。由于 Netty 使用统一的 ByteBuf 替代 JDK 原生的 java.nio.ByteBuffer,所以 ByteBuf 中定义了 ByteBuffer nioBuffer()方法将 ByteBuf 转换成 ByteBuffer。
三 网络优化
优化前先描述一下一条正常网络请求的流程:
- DNS 解析,请求DNS服务器,获取域名对应的IP地址;
- 与服务器建立连接,包括 TCP三次握手,安全协议同步流程;
- 连接建立完成,发送和接收数据,解码数据;
在了解了网络请求的流程后,针对上面这三步流程分别进行优化:
3.1 DNS 优化
在 Android APP 访问网络的时候,第一步就是 DNS 解析,默认使用运行商的 LocalDNS 服务,DNS 完整的解析流程很长,会先从本地系统缓存取,若没有就到最近的 DNS 服务器取,若没有再到主域名服 务器取,每一层都有缓存,但为了域名解析的实时性,每一层缓存都有过期时间。
目前各大云服务商,阿里云和腾讯云等都提供了自己的 HTTPDNS 服务,对于我们普通开发者,只需要付出少量的费用,在手机端嵌入支持 HTTPDNS 的客户端 SDK,即可使用。 在使用okhttp时默认使用系统的DNS服务,可以通过okhttp中的.dns()接口,配置HTTPDNS。
3.2 连接优化
优化方式:
- 启用keep-alive,okhttp中已默认打开,但需要服务器支持
- 通过http2来复用请求连接
3.3 数据传输优化
- 开启 gzip 压缩,okhttp默认支持接收gzip压缩
- 使用protoful格式代替json,xml
- 使用webp代替png/jpg
- 判断网络环境,下发不同图片
- http开启缓存/本地缓存
四 存储优化
4.1 ContentProvider
-
ContentProvider 的生命周期默认在 Application onCreate() 之前,而且都是在主线程创建的。我们自定义的 ContentProvider 类的构造函数、静态代码块、onCreate 函数都尽量不要做耗时的操作,会拖慢启动速度。
-
虽然 ContentProvider 为应用程序之间的数据共享提供了很好的安全机制,但是如果 ContentProvider 是 exported,当支持执行 SQL 语句时就需要注意 SQL 注入的问题。另外如果我们传入的参数是一个文件路径,然后返回文件的内容,这个时候也要校验合法性,不然整个应用的私有数据都有可能被别人拿到,在 intent 传递参数的时候可能经常会犯这个错误。
-
ContentProvider 这套方案实现相对比较笨重,适合传输大的数据。
4.2 Serializable
-
Serializable 是 Java 原生的序列化机制,在 Android 中也有被广泛使用。我们可以通过 Serializable 将对象持久化存储,也可以通过 Bundle 传递 Serializable 的序列化数据。
-
序列化过程使用了大量的反射和临时变量,而且在序列化对象的时候,不仅会序列化当前对象本身,还需要递归序列化对象引用的其他对象。
-
整个过程计算非常复杂,而且因为存在大量反射和 GC 的影响,序列化的性能会比较差。另外一方面因为序列化文件需要包含的信息非常多,导致它的大小比 Class 文件本身还要大很多,这样又会导致 I/O 读写上的性能问题。
4.3 Parcelable
- 由于 Java 的 Serializable 的性能较低,Android 需要重新设计一套更加轻量且高效的对象序列化和反序列化机制。Parcelable 正是在这个背景下产生的,它核心的作用就是为了解决 Android 中大量跨进程通信的性能问题。
- 在时间开销和使用成本的权衡上,Parcelable 机制选择的是性能优先。所以它在写入和读取的时候都需要手动添加自定义代码,使用起来相比 Serializable 会复杂很多。但是正因为这样,Parcelable 才不需要采用反射的方式去实现序列化和反序列化。
4.4 Room
在 SQLite 的基础上提供了一个抽象层,让用户能够在充分利用 SQLite 的强大功能的同时,获享更强健的数据库访问机制。 Room 包含 3 个重要部分:
- 数据库:包含数据库持有者,并作为应用已保留的持久关系型数据的底层连接的主要接入点。
- Entity:表示数据库中的表。
- DAO:包含用于访问数据库的方法。