之前两篇文章总结了HTTP 的一些基础知识,包括HTTP,HTTPS原理,密码学及登陆授权等等,但是在我们Android开发中目前用到的最多的还是Okhttp+Retrofit。下面就总结一下Okhttp和Retrofit的用法及核心原理。
OkHttp
OkHttp 使用方法简介OkHttp
OkHttp简介
OkHttps是一个处理网络请求的开源项目,是安卓端最火热的轻量级框架,由移动支付Square公司贡献(该公司还贡献了Picasso) [1]
用于替代HttpUrlConnection和Apache HttpClient(android API23 6.0里已移除HttpClient,现在已经打不出来)
OkHttp优势
1.允许连接到同一个主机地址的所有请求,提高请求效率
2.共享Socket,减少对服务器的请求次数
3.通过连接池,减少了请求延迟
4.缓存响应数据来减少重复的网络请求
5.减少了对数据流量的消耗
6.自动处理GZip压缩
OkHttp基本使用
1.创建一个OkHttp的实例
//提示:设置超时时间在OKhttp3.0以后,使用build的方式进行
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.connectTimeout(10, TimeUnit.SECONDS)
.readTimeout(10,TimeUnit.SECONDS)
.writeTimeout(10,TimeUnit.SECONDS)
.build();2.通过build来创建一个Request请求,没有设置get,而是直接设置一个url地址,默认就是一个get方式
final Request request = new Request.Builder()
url("https://xxxx.baidu.xxxxx")
.build();3.创建一个call对象,参数就是Request请求对象,发送请求
Call call = mOkHttpClient.newCall(request);
//04.请求加入调度
call.enqueue(new Callback()
{ //请求失败执行的方法
public void onFailure(Request request, IOException e){}
//请求成功执行的方法,response就是从服务器得到的参数,response.body()可以得到任意类型,字符串,字节
public void onResponse(final Response response) throws IOException {
//这段代码可以拿到服务器的字符串.(通过response.body还可以拿到多种数据类型)
//String htmlStr = response.body().string();
}
});4.get请求的步骤总结:首先构造一个Request对象,参数必须有个url参数,当然可以通过Request.Builder设置更多的参数比如:header、method等。
然后通过request的对象去构造得到一个Call对象,类似于将请求封装成了任务,既然是任务,就会有execute()和cancel()等方法。
最后,以异步的方式去执行请求,所以调用的是call.enqueue,将call加入调度队列,然后等待任务执行完成,在Callback中即可得到结果。
整体的写法还是比较长的,所以封装肯定是要做的。
okhttp注意:
onResponse回调的参数是response,一般情况下
-
获得返回的字符串,通过response.body().string()获取;
-
获得返回的二进制字节数组,则调用response.body().bytes();//通过二进制字节数组,可以转换为BItmap图片资源
-
获得返回的inputStream,则调用response.body().byteStream() ;这里支持大文件下载,有inputStream可以通过IO的方式写文件。
不过也说明一个问题,这个onResponse执行的线程并不是UI线程(主线程不能有耗时操作)。如果希望操作控件,还是需要使用handler等
基本的用法,网上有很多,也比较简单,就不多做赘述了。下面主要从源码上分析一下OkHttp的原理。
1、okhttp工作的大致流程
1.1、整体流程
(1)、当我们通过OkhttpClient创建一个Call,并发起同步或异步请求时;
(2)、okhttp会通过Dispatcher对我们所有的RealCall(Call的具体实现类)进行统一管理,并通过execute()及enqueue()方法对同步或异步请求进行处理;
(3)、execute()及enqueue()这两个方法会最终调用RealCall中的getResponseWithInterceptorChain()方法,从拦截器链中获取返回结果;
(4)、拦截器链中,依次通过RetryAndFollowUpInterceptor(重定向拦截器)、BridgeInterceptor(桥接拦截器)、CacheInterceptor(缓存拦截器)、ConnectInterceptor(连接拦截器)、CallServerInterceptor(网络拦截器)对请求依次处理,与服务的建立连接后,获取返回数据,再经过上述拦截器依次处理后,最后将结果返回给调用方。
提供两张图便于理解和记忆:
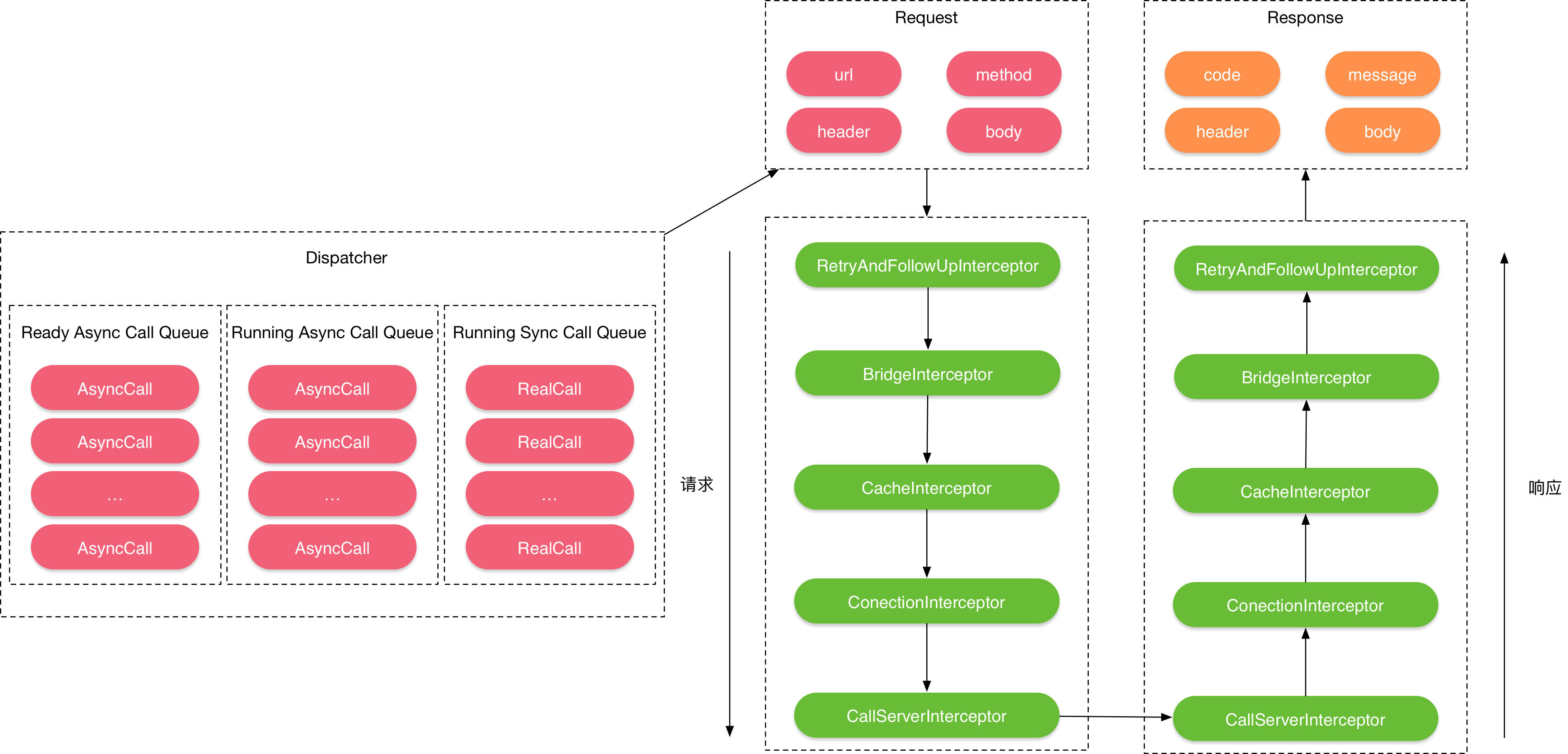

分发器
Dispatcher,分发器就是来调配请求任务的,内部会包含一个线程池。可以在创建OkHttpClient时,传递我们自己定义的线程池来创建分发器。
这个Dispatcher中的成员有:
//异步请求同时存在的最大请求
private int maxRequests = 64;
//异步请求同一域名同时存在的最大请求
private int maxRequestsPerHost = 5;
//闲置任务(没有请求时可执行一些任务,由使用者设置)
private @Nullable Runnable idleCallback;
//异步请求使用的线程池
private @Nullable ExecutorService executorService;
//异步请求等待执行队列
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
//异步请求正在执行队列
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
//同步请求正在执行队列
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();
同步请求
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
因为同步请求不需要线程池,也不存在任何限制。所以分发器仅做一下记录。
异步请求
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}
当正在执行的任务未超过最大限制64,同时runningCallsForHost(call) < maxRequestsPerHost同一Host的请求不超过5个,则会添加到正在执行队列,同时提交给线程池。否则先加入等待队列。
加入线程池直接执行没啥好说的,但是如果加入等待队列后,就需要等待有空闲名额才开始执行。因此每次执行完一个请求后,都会调用分发器的finished方法
//异步请求调用
void finished(AsyncCall call) {
finished(runningAsyncCalls, call, true);
}
//同步请求调用
void finished(RealCall call) {
finished(runningSyncCalls, call, false);
}
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
//不管异步还是同步,执行完后都要从队列移除(runningSyncCalls/runningAsyncCalls)
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();
//异步任务和同步任务正在执行的和
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
// 没有任务执行执行闲置任务
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
需要注意的是 只有异步任务才会存在限制与等待,所以在执行完了移除正在执行队列中的元素后,异步任务结束会执行promoteCalls()。很显然这个方法肯定会重新调配请求。
private void promoteCalls() {
//如果任务满了直接返回
if (runningAsyncCalls.size() >= maxRequests) return;
//没有等待执行的任务,返回
if (readyAsyncCalls.isEmpty()) return;
//遍历等待执行队列
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
//等待任务想要执行,还需要满足:这个等待任务请求的Host不能已经存在5个了
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
在满足条件下,会把等待队列中的任务移动到runningAsyncCalls并交给线程池执行。所以分发器到这里就完了。逻辑上还是非常简单的。
请求流程
用户是不需要直接操作任务分发器的,获得的RealCall中就分别提供了execute与enqueue来开始同步请求或异步请求。
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
try {
//调用分发器
client.dispatcher().executed(this);
//执行请求
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
//请求完成
client.dispatcher().finished(this);
}
}
异步请求的后续同时是调用getResponseWithInterceptorChain()来执行请求,而OkHttp最核心的工作是在getResponseWithInterceptorChain()中进行,在进入这个方法分析之前,我们先来了解什么是责任链模式,因为此方法就是利用的责任链模式完成一步步的请求。
责任链顾名思义就是由一系列的负责者构成的一个链条,类似于工厂流水线,你们懂的,很多同学的男朋友/女朋友就是这么来的。
责任链模式
为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。在这种模式中,通常每个接收者都包含对另一个接收者的引用。如果一个对象不能处理该请求,那么它会把相同的请求传给下一个接收者,依此类推。比如:
钉钉上请假的流程:请假消息先传给人事请假,然后接着传给部门领导请假,然后传给项目经理,然后传给xxx上级,一级一级的向上传递,假如中间某位拒绝了你的请假请求,那直接结束了你的请假想法。
而okhttp请求会被交给责任链中的一个个拦截器。默认情况下有五大拦截器:
RetryAndFollowUpInterceptor(负责重定向)
第一个接触到请求,最后接触到响应;负责判断是否需要重新发起整个请求
构建一个StreamAllocation对象,然后调用下一个拦截器获取结果,从返回结果中获取重定向的request,如果重定向的request不为空的话,并且不超过重定向最大次数的话就进行重定向,否则返回结果。注意:这里是通过一个while(true)的循环完成下一轮的重定向请求。
(1)、StreamAllocation为什么在第一个拦截器中就进行创建?
便于取消请求以及出错释放资源。
(2)、StreamAllocation的作用是什么?
StreamAllocation负责统筹管理Connection、Stream、Call三个实体类,具体就是为一个Call(Realcall),寻找( findConnection() )一个Connection(RealConnection),获取一个Stream(HttpCode)。
本拦截器是整个责任链中的第一个,这意味着它会是首次接触到Request与最后接收到Response的角色,在这个拦截器中主要功能就是判断是否需要重试与重定向。
重试的前提是出现了RouteException或者IOException。一但在后续的拦截器执行过程中出现这两个异常,就会通过recover方法进行判断是否进行连接重试。
重定向发生在重试的判定之后,如果不满足重试的条件,还需要进一步调用followUpRequest根据Response 的响应码(当然,如果直接请求失败,Response都不存在就会抛出异常)。followup最大发生20次。
BridgeInterceptor
补全请求,并对响应进行额外处理
负责将原始Requset转换给发送给服务端的Request以及将Response转化成对调用方友好的Response。
具体就是对request添加Content-Type、Content-Length、cookie、Connection、Host、Accept-Encoding等请求头以及对返回结果进行解压、保持cookie等。
桥接拦截器的执行逻辑主要就是以下几点
对用户构建的Request进行添加或者删除相关头部信息,以转化成能够真正进行网络请求Request
将符合网络请求规范的Request交给下一个拦截器处理,并获取Response
如果响应体经过了GZIP压缩,那就需要解压,再构建成用户可用的Response并返回
CacheInterceptor
请求前查询缓存,获得响应并判断是否需要缓存
CacheInterceptor:负责读取缓存以及更新缓存。
1、如果从缓存获取的Response是null,那就需要使用网络请求获取响应;
2、如果是Https请求,但是又丢失了握手信息,那也不能使用缓存,需要进行网络请求;
3、如果判断响应码不能缓存且响应头有no-store标识,那就需要进行网络请求;
4、如果请求头有no-cache标识或者有If-Modified-Since/If-None-Match,那么需要进行网络请求;
5、如果响应头没有no-cache标识,且缓存时间没有超过极限时间,那么可以使用缓存,不需要进行网络请求;
6、如果缓存过期了,判断响应头是否设置Etag/Last-Modified/Date,没有那就直接使用网络请求否则需要考虑服务器返回304;
并且,只要需要进行网络请求,请求头中就不能包含only-if-cached,否则框架直接返回504!

强制缓存:当客户端第一次请求数据是,服务端返回了缓存的过期时间(Expires与Cache-Control),没有过期就可以继续使用缓存,否则则不适用,无需再向服务端询问。
对比缓存:当客户端第一次请求数据时,服务端会将缓存标识(Etag/If-None-Match与Last-Modified/If-Modified-Since)与数据一起返回给客户端,客户端将两者都备份到缓存中 ,再次请求数据时,客户端将上次备份的缓存
标识发送给服务端,服务端根据缓存标识进行判断,如果返回304,则表示缓存可用,如果返回200,标识缓存不可用,使用最新返回的数据。
ETag是用资源标识码标识资源是否被修改,Last-Modified是用时间戳标识资源是否被修改。ETag优先级高于Last-Modified。
缓存拦截器本身主要逻辑其实都在缓存策略中,拦截器本身逻辑非常简单,如果确定需要发起网络请求,则下一个拦截器为
ConnectInterceptor
ConnectInterceptor
与服务器完成TCP连接
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
使用StreamAllocation.newStream来和服务端建立连接,并返回输入输出流(HttpCodec),实际上是通过StreamAllocation中的findConnection寻找一个可用的Connection,然后调用Connection的connect方法,使用socket与服务端建立连接。
CallServerInterceptor
与服务器通信;封装请求数据与解析响应数据(如:HTTP报文)主要的工作就是把请求的Request写入到服务端,然后从服务端读取Response。
(1)、写入请求头
(2)、写入请求体
(3)、读取响应头
(4)、读取响应体
OkHttp中的设计模式
责任链模式:拦截器链
单例模式:线程池
观察者模式:各种回调监听
策略模式:缓存策略
Builder模式:OkHttpClient的构建过程
外观模式:OkHttpClient封装了很对类对象
工厂模式:Socket的生产
OkHttp总结
1.源码总结
OkHttp 源码总结
OkHttpClient 相当于配置中心,所有的请求都会共享这些配置(例如出错是否重试、共享的连接池)。 OkHttpClient 中的配置主要有:
Dispatcher dispatcher:调度器,用于调度后台发起的网络请求,有后台总请求数和单主机总请求数的控制。
List<Protocol> protocols :支持的应用层协议,即 HTTP/1.1、HTTP/2 等。List<ConnectionSpec> connectionSpecs :应用层支持的 Socket 设置,即使用明文传输(用于 HTTP)还是某个版本的 TLS(用于 HTTPS)。
List<Interceptor> interceptors:大多数时候使用的 Interceptor 都应该配置到这里。
List<Interceptor> networkInterceptors:直接和网络请求交互的 Interceptor 配置到这里,例如如果你想查看返回的 301 报文或者未解压的 Response Body,需要在这里看。
CookieJar cookieJar:管理 Cookie 的控制器。OkHttp 提供了 Cookie 存取的判断支持(即什么时候需要存 Cookie,什么时候需要读取 Cookie,但没有给出具体的存取实现。如果需要存Cookie,你得自己写实现,例如用:1本地存储或者数据库
2存在内存里
3或者用别的方式存在
Cache cache:Cache 存储的配置。默认是没有,如果需要用,得自己配置出 Cache 存储的文件位置以及存储空间上限。
HostnameVerifier hostnameVerifier:属者是否和自己要访问的主机名一致。
CertificatePinner certificatePinner:用于验证 HTTPS 握手过程中下载到的证书所属者是否和自己要访问的主机名一致。
CertificatePinner certificatePinner:用于设置 HTTPS 握手过程中针对某个Host 的 Certificate Public Key Pinner,即把网站证书链中的每一个证书公钥直接拿来提前配置进 OkHttpClient 里去,以跳过本地根证书,直接从代码里进行认证。这种用法比较少见,一般用于防止网站证书被人仿制。
Authenticator authenticator :
用于自动重新认证。配置之后,在请求收到 401 状态码的响应时,会直接调用 authenticator ,手动加入Authorization header之后自动重新发起请求。
boolean followRedirects :遇到重定向的要求是,是否自动 follow。
boolean followSslRedirects 在重定向时,如果原先请求的是 http 而重定向的目标是https,或者原先请求的是 https 而重定向的目标是 http,是否依然自动 follow。(记得, 不是「是否自动 follow HTTPS URL 重定向的意思,而是是否自动 follow 在 HTTP 和 HTTPS 之间切换的重定向)
boolean retryOnConnectionFailure:在请求失败的时候是否自动重试。注意,大多数的请求失败并不属于 OkHttp 所定义的「需要重试」,这种重试只适用于「同一个域名的多个 IP 切换重试」「Socket 失效重试」等情况。
int connectTimeout :建立连接(TCP 或 TLS)的超时时间。
int readTimeout :发起请求到读到响应数据的超时时间。
int writeTimeout :发起请求并被目标服务器接受的超时时间。(为什么?因为有时候对方服务器可能由于某种原因而不读取你的 Request)
newCall(Request) 方法会返回一个 RealCall 对象,它是 Call 接口的实现。当调RealCall.execute() 的时候, RealCall.getResponseWithInterceptorChain() 会被调用,它会发起网络请求并拿到返回的响应,装进一个 Response 对象并作为返回值返回;RealCall.enqueue()被调用的时候大同小异,区别在于 enqueue() 会使用 Dispatcher的线程池来把请求放在后台线程进行,但实质上使用的同样也是getResponseWithInterceptorChain()方法。
getResponseWithInterceptorChain() : 方法做的事:把所有配置好的Interceptor放在一个 List 里,然后作为参数,创建一个 RealInterceptorChain 对象,并调用chain.proceed(request)来发起请求和获取响应。
在RealInterceptorChain中,多个Interceptor会依次调用自己的intercept()方法,这个方法会做三件事:
1.对请求进行预处理
2.预处理之后,重新调用RealIntercepterChain.proceed()把请求交给下一个Interceptor
3。在下一个Interceptor处理完成并返回之后,拿到 Response 进行后续处理
2.拦截器原理总结
整个OkHttp功能的实现就在这五个默认的拦截器中,所以先理解拦截器模式的工作机制是先决条件。这五个拦截器分别为: 重试拦截器、桥接拦截器、缓存拦截器、连接拦截器、请求服务拦截器。每一个拦截器负责的工作不一样,就好像工厂流水线,最终经过这五道工序,就完成了最终的产品。
但是与流水线不同的是,OkHttp中的拦截器每次发起请求都会在交给下一个拦截器之前干一些事情,在获得了结果之后又干一些事情。整个过程在请求向是顺序的,而响应向则是逆序。
当用户发起一个请求后,会由任务分发起Dispatcher将请求包装并交给重试拦截器处理。
1、重试拦截器在交出(交给下一个拦截器)之前,负责判断用户是否取消了请求;在获得了结果之后,会根据响应码判断是否需要重定向,如果满足条件那么就会重启执行所有拦截器。
2、桥接拦截器在交出之前,负责将HTTP协议必备的请求头加入其中(如:Host)并添加一些默认的行为(如:GZIP压缩);在获得了结果后,调用保存cookie接口并解析GZIP数据。
3、缓存拦截器顾名思义,交出之前读取并判断是否使用缓存;获得结果后判断是否缓存。
4、连接拦截器在交出之前,负责找到或者新建一个连接,并获得对应的socket流;在获得结果后不进行额外的处理。
5、请求服务器拦截器进行真正的与服务器的通信,向服务器发送数据,解析读取的响应数据。