您可能之前看到过我写的类似文章,为什么还要重复撰写呢?只是想更好地帮助初学者了解病毒逆向分析和系统安全,更加成体系且不破坏之前的系列。因此,我重新开设了这个专栏,准备系统整理和深入学习系统安全、逆向分析和恶意代码检测,“系统安全”系列文章会更加聚焦,更加系统,更加深入,也是作者的慢慢成长史。换专业确实挺难的,逆向分析也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前文从总结恶意代码检测技术,包括恶意代码检测的对象和策略、特征值检测技术、校验和检测技术、启发式扫描技术、虚拟机检测技术和主动防御技术。这篇文章将介绍基于机器学习的恶意代码检测技术,主要参考郑师兄的视频总结,包括机器学习概述与算法举例、基于机器学习方法的恶意代码检测、机器学习算法在工业界的应用。同时,我再结合自己的经验进行扩充,详细分享了基于机器学习的恶意代码检测技术,基础性文章,希望对您有所帮助~
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是关于安全工具和实践操作的在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习网络安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
文章目录
- 一.机器学习概述与算法举例
- 1.机器学习概念
- 2.机器学习算法举例
- 3.特征工程-特征选取与设计
- 二.基于机器学习方法的恶意代码检测
- 1.恶意代码的静态动态检测
- (1) 特征种类
- (2) 常见算法
- 2.静态特征设计举例
- 3.经典的图片特征举例
- 4.动态特征设计举例
- 5.深度学习静态检测举例
- 6.优缺点
- 7.静态分析和动态分析对比
- 三.机器学习算法在工业界的应用
- 四.总结
作者的github资源:
- 逆向分析:https://github.com/eastmountyxz/SystemSecurity-ReverseAnalysis
- 网络安全:https://github.com/eastmountyxz/NetworkSecuritySelf-study
从2019年7月开始,我来到了一个陌生的专业——网络空间安全。初入安全领域,是非常痛苦和难受的,要学的东西太多、涉及面太广,但好在自己通过分享100篇“网络安全自学”系列文章,艰难前行着。感恩这一年相识、相知、相趣的安全大佬和朋友们,如果写得不好或不足之处,还请大家海涵!
接下来我将开启新的安全系列,叫“系统安全”,也是免费的100篇文章,作者将更加深入的去研究恶意样本分析、逆向分析、内网渗透、网络攻防实战等,也将通过在线笔记和实践操作的形式分享与博友们学习,希望能与您一起进步,加油~
- 推荐前文:网络安全自学篇系列-100篇
前文分析:
- [系统安全] 一.什么是逆向分析、逆向分析基础及经典扫雷游戏逆向
- [系统安全] 二.如何学好逆向分析及吕布传游戏逆向案例
- [系统安全] 三.IDA Pro反汇编工具初识及逆向工程解密实战
- [系统安全] 四.OllyDbg动态分析工具基础用法及Crakeme逆向
- [系统安全] 五.OllyDbg和Cheat Engine工具逆向分析植物大战僵尸游戏
- [系统安全] 六.逆向分析之条件语句和循环语句源码还原及流程控制
- [系统安全] 七.逆向分析之PE病毒原理、C++实现文件加解密及OllyDbg逆向
- [系统安全] 八.Windows漏洞利用之CVE-2019-0708复现及蓝屏攻击
- [系统安全] 九.Windows漏洞利用之MS08-067远程代码执行漏洞复现及深度提权
- [系统安全] 十.Windows漏洞利用之SMBv3服务远程代码执行漏洞(CVE-2020-0796)复现
- [系统安全] 十一.那些年的熊猫烧香及PE病毒行为机理分析
- [系统安全] 十二.熊猫烧香病毒IDA和OD逆向分析(上)病毒初始化
- [系统安全] 十三.熊猫烧香病毒IDA和OD逆向分析(中)病毒释放机理
- [系统安全] 十四.熊猫烧香病毒IDA和OD逆向分析–病毒释放过程(下)
- [系统安全] 十五.Chrome浏览器保留密码功能渗透解析、蓝屏漏洞及某音乐软件漏洞复现
- [系统安全] 十六.PE文件逆向基础知识(PE解析、PE编辑工具和PE修改)
- [系统安全] 十七.Windows PE病毒概念、分类及感染方式详解
- [系统安全] 十八.病毒攻防机理及WinRAR恶意劫持漏洞(脚本病毒、自启动、定时关机、蓝屏攻击)
- [系统安全] 十九.宏病毒之入门基础、防御措施、自发邮件及APT28宏样本分析
- [系统安全] 二十.PE数字签名之(上)什么是数字签名及Signtool签名工具详解
- [系统安全] 二十一.PE数字签名之(中)Signcode、PEView、010Editor、Asn1View工具用法
- [系统安全] 二十二.PE数字签名之(下)微软证书漏洞CVE-2020-0601复现及Windows验证机制分析
- [系统安全] 二十三.逆向分析之OllyDbg动态调试复习及TraceMe案例分析
- [系统安全] 二十四.逆向分析之OllyDbg调试INT3断点、反调试、硬件断点与内存断点
- [系统安全] 二十五.WannaCry勒索病毒分析 (1)Python复现永恒之蓝漏洞实现勒索加密
- [系统安全] 二十六.WannaCry勒索病毒分析 (2)MS17-010漏洞利用及病毒解析
- [系统安全] 二十七.WannaCry勒索病毒分析 (3)蠕虫传播机制解析及IDA和OD逆向
- [系统安全] 二十八.WannaCry勒索病毒分析 (4)全网"最"详细的蠕虫传播机制解读
- [系统安全] 二十九.深信服分享之外部威胁防护和勒索病毒对抗
- [系统安全] 三十.CS逆向分析 (1)你的游戏子弹用完了吗?Cheat Engine工具入门普及
- [系统安全] 三十一.恶意代码检测(1)恶意代码攻击溯源及恶意样本分析
- [系统安全] 三十二.恶意代码检测(2)常用技术详解及总结
- [系统安全] 三十三.恶意代码检测(3)基于机器学习的恶意代码检测技术
声明:本人坚决反对利用教学方法进行犯罪的行为,一切犯罪行为必将受到严惩,绿色网络需要我们共同维护,更推荐大家了解它们背后的原理,更好地进行防护。该样本不会分享给大家,分析工具会分享。(参考文献见后)
随着互联网的繁荣,现阶段的恶意代码也呈现出快速发展的趋势,主要表现为变种数量多、传播速度快、影响范围广。在这样的形势下,传统的恶意代码检测方法已经无法满足人们对恶意代码检测的要求。比如基于签名特征码的恶意代码检测,这种方法收集已知的恶意代码,以一种固定的方式生成特定的签名,维护这样的签名库,当有新的检测任务时,通过在签名库中检索匹配的方法进行检测。暂且不说更新、维护签名库的过程需要耗费大量的人力物力,恶意代码编写者仅仅通过混淆、压缩、加壳等简单的变种方式便可绕过这样的检测机制。
为了应对上面的问题,基于机器学习的恶意代码检测方法一直是学界研究的热点。由于机器学习算法可以挖掘输入特征之间更深层次的联系,更加充分地利用恶意代码的信息,因此基于机器学习的恶意代码检测往往表现出较高的准确率,并且一定程度上可以对未知的恶意代码实现自动化的分析。下面让我们开始进行系统的介绍吧~
一.机器学习概述与算法举例
1.机器学习概念
首先介绍下机器学习的基本概念,如下图所示,往分类模型中输入某个样本特征,分类模型输出一个分类结果。这就是一个标准的机器学习检测流程。机器学习技术主要研究的就是如何构建中间的分类模型,如何构造一组参数、构建一个分类方法,通过训练得到模型与参数,让它在部署后能够预测一个正确的结果。
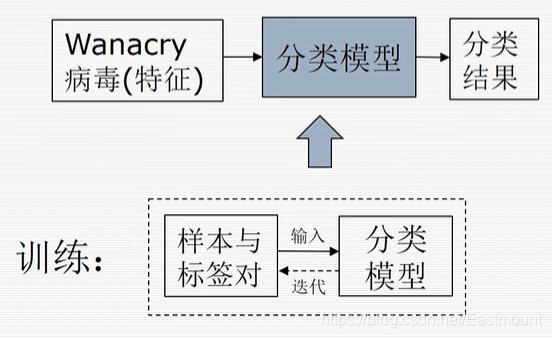
训练是迭代样本与标签对的过程,如数学表达式 y=f(x) ,x表示输入的样本特征向量,y表示标签结果,使用(x,y)对f进行一个拟合的操作,不断迭代减小 y’ 和 y 的误差,使得在下次遇到待测样本x时输出一致的结果。该过程也称为学习的过程。
构造分类方法
构造分类方法是机器学习中比较重要的知识,如何设计一种分类模型将f(x)表达出来。比如:
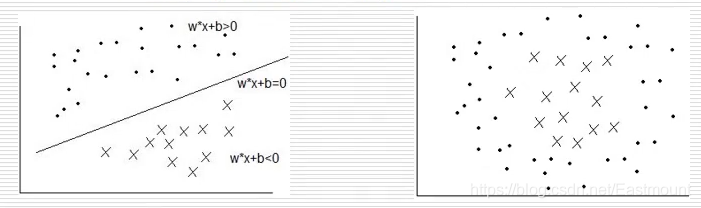
- 超平面(SVM)
在二维坐标轴中,可以设计一条直线将空间内分布的散点区分开来,如下图所示。 - softmax
另外一种方法是构造类别概率输出(softmax),比如归一化处理得到A+B=1,最后看A和B的概率,谁的概率大就属于哪一类,该方法广泛使用于神经网络的最后结果计算中。
2.机器学习算法举例
作者之前Python系列分享过非常多的机器学习算法知识,也推荐大家去学习:机器学习系列文章(共48篇)。
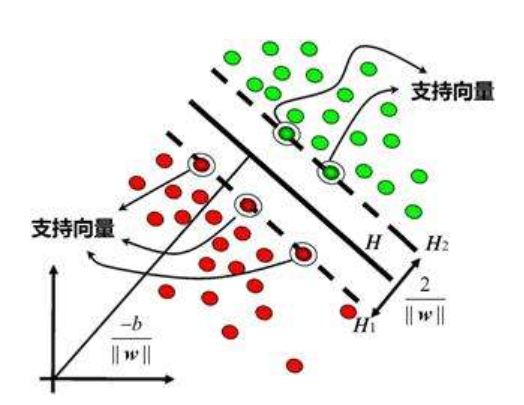
(1) 支持向量机(SVM)
首先存在很多训练数据点,包括直线上方和下方两个簇,支持向量机的方法是寻找这两个簇分类的超平面。如何寻找这个超平面呢?支持向量机先求解每个簇离对面最近的点,然后通过拟合方法计算出两边簇的边界,最终计算出中间的平面,其基本思路就是这样,而这些点就是支持向量。支持向量机往往用来处理超高维的问题,也不一定是类似直线的平面,也可能是圆形的分类边界。
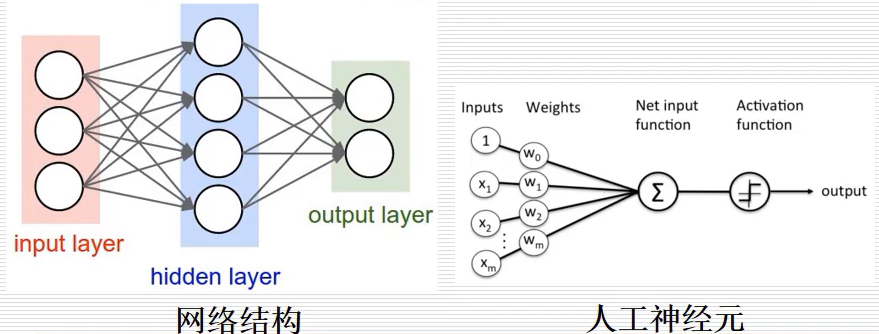
(2) 神经网络(Neural Network)
神经网络基本网络结构如下图所示,包括三个常用层:输入层、隐藏层、输出层。在神经网络中,最基本的单位是人工神经元,其基本原理是将输入乘以一个权重,然后将结果相加进行激活,最后得到一个概率的输出,其输出结果谁大就预测为对应的结果。推荐作者的文章:神经网络和机器学习基础入门分享
(3) 深度卷积神经网络
普通的神经网络通常只包括一个隐藏层,当超出之后可以称为深度神经网络。现在比较流行的包括CNN、RNN、RCNN、GRU、LSTM、BiLSTM、Attention等等。其中,卷积神经网络常用于处理图片,应用了卷积技术、池化技术,降低图片维度得到很好的结果。
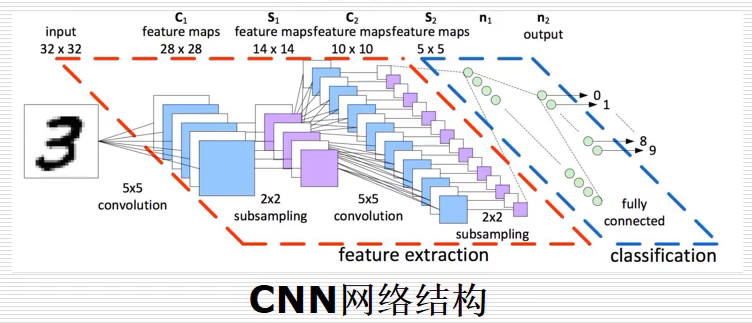
如上图所示,将手写数字“3”(32x32个像素)预测为最终的数字0-9的结果。模型首先使用了6个卷积核,对原始图片进行固定的计算,如下5x5的图像卷积操作后变成了 3x3 的图像。其原理是将特征提取的过程放至神经网络中训练,从而得到比较好的分类结果。卷积之后进行了一个2x2的下采样过程,将图片进一步变小(14x14),接着降维处理,一般采用平均池化或最大池化实现,选定一个固定区域,求取该区域的平均值或最大值,然后将向量进行组合,得到一个全连接网络,最终完成分类任务。
参考作者前文:[Python人工智能] 四.神经网络和深度学习入门知识
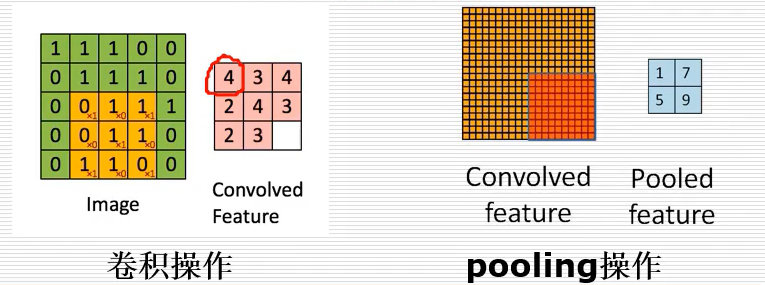
深度神经网络是深度学习中模型,它主要的一个特点是将特征提取的过程放入到真个训练中,之前对于图片问题是采用手工特征,而CNN让在训练中得到最优的特征提取。
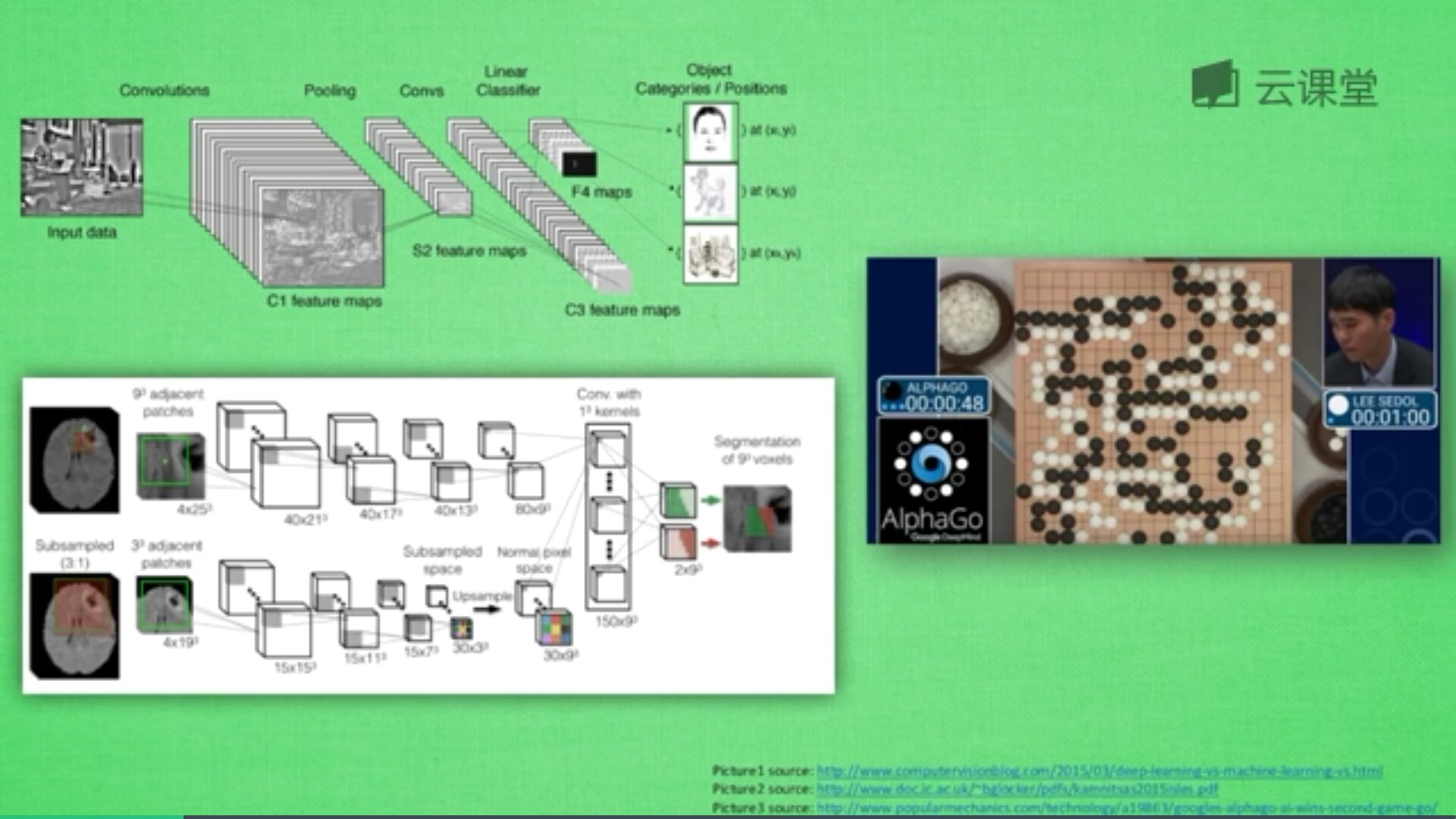
3.特征工程-特征选取与设计
上面介绍了机器学习和深度学习方法,但是这些方法往往是该研究领域的学者所提出,而在恶意代码检测中,往往我们的主要工作量是一些特征的提取和特征的设计,这里面涉及一个特征工程的概念。
特征工程:选取特征,设计特征的过程。
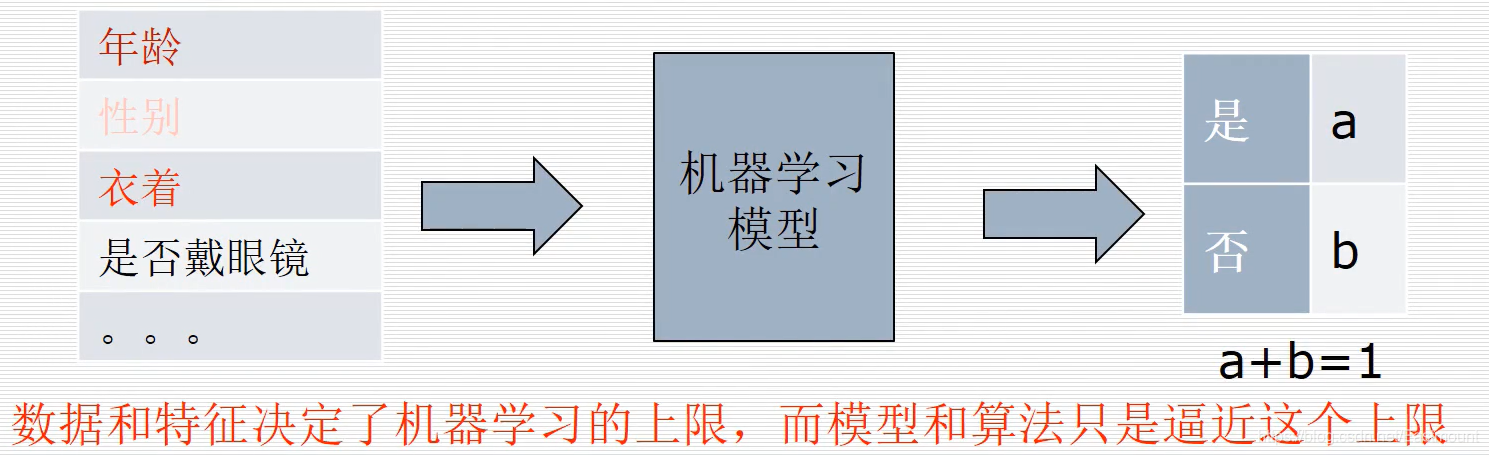
例如,在路边预测一个人是否是学生,假设我们不能去询问,只能通过外表去预测他是否是一个学生,包括:年龄(低于15岁就是学生)、性别(不影响学生)、衣着(穿着活泼年轻的可能是学生,如果穿着西装可能性就小)等等,然后根据这些特征输入机器学习模型,从而判断是否是学生。
在这些特征中,显然有些特征是非常重要的,比如年龄和衣着。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限,所以如何选取特征是机器学习的一个关键性因素。再比如淘宝的推荐系统,购买电脑推荐鼠标、键盘等。
当然,上面仅仅是一个比较简单的问题,当我们推广到恶意代码检测等复杂问题时,如果不了解这个领域,可能就会导致模型的结果不理想。
特征设计——人脸识别
局部二值特征(Local Binary Pattern),再举一个人脸识别例子,深度学习出来之前,图片分类都是使用一些特征算子提取特征的。比如存在一个3x3的窗口,我们取阈值5,比5小的窗口置为0,其他的置为1,然后顺时针转换为一个8位的二进制数字,对应的十进制就是19。显然,LBP特征进行了一个降维的操作,左边的图片显示了人脸识别不应该受光照影响,不同光照的图片进行LBP特征提取后,显示结果都一样。

该部分的最后,作者也推荐一些书籍供大家学习。
- 《统计学习方法》李航,数学理论较多
- 《机器学习》周志华,西瓜书,较通俗透彻
- 《Deep Learning》Ian Goodfellow,花书,深度学习内容全面
- 《精通特征工程》结合恶意代码特征学习,包括如何向量化
再看看我的桌面,这些都是作者最近看的一些安全、AI类书籍,希望也您喜欢~

二.基于机器学习方法的恶意代码检测
1.恶意代码的静态动态检测
(1) 特征种类
首先,特征种类如果按照恶意代码是否在用户环境或仿真环境中运行,可以划分为静态特征和动态特征。
- 静态特征: 没有真实运行的特征
– 字节码:二进制代码转换成了字节码,比较原始的一种特征,没有进行任何处理
– IAT表:PE结构中比较重要的部分,声明了一些函数及所在位置,便于程序执行时导入,表和功能比较相关
– Android权限表:如果你的APP声明了一些功能用不到的权限,可能存在恶意目的,如手机信息
– 可打印字符:将二进制代码转换为ASCII码,进行相关统计
– IDA反汇编跳转块:IDA工具调试时的跳转块,对其进行处理作为序列数据或图数据
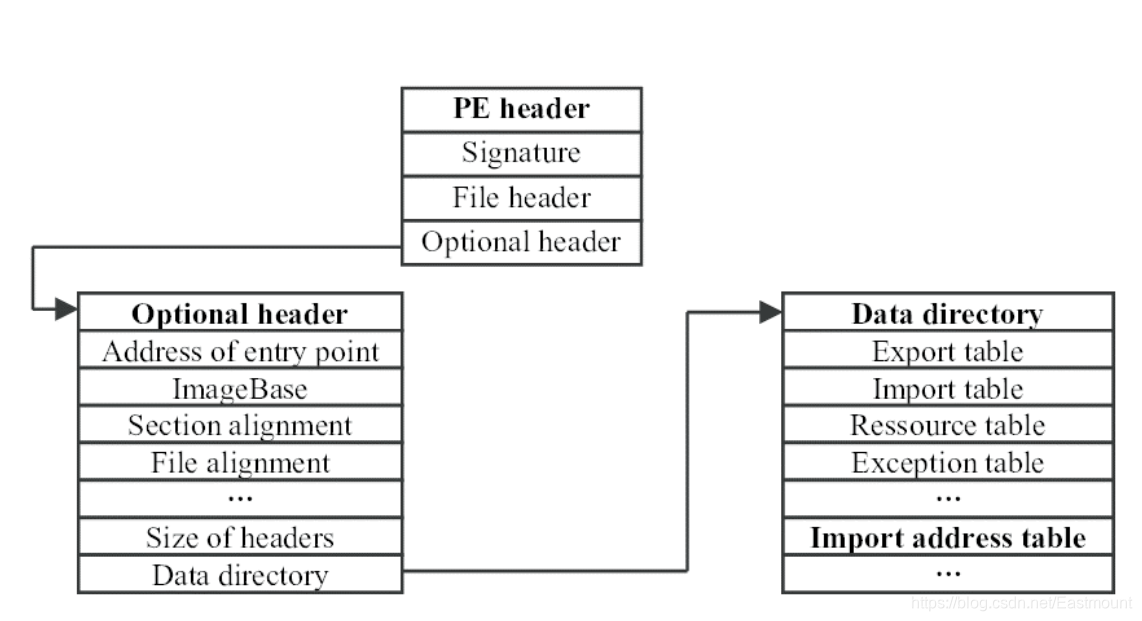
- 动态特征: 相当于静态特征更耗时,它要真正去执行代码
– API调用关系:比较明显的特征,调用了哪些API,表述对应的功能
– 控制流图:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
– 数据流图:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
举一个简单的控制流图(Control Flow Graph, CFG)示例。
if (x < y)
{
y = 0;
x = x + 1;
}
else
{
x = y;
}
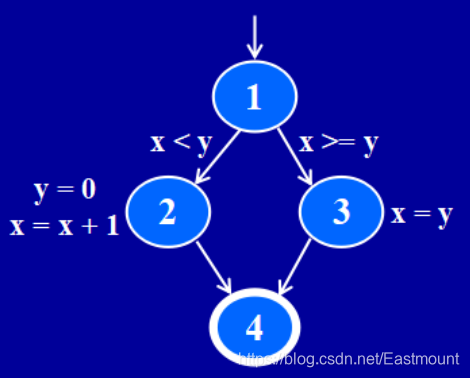
(2) 常见算法
普通机器学习方法和深度学习方法的区别是,普通机器学习方法的参数比较少,相对计算量较小。
- 普通机器学习方法(SVM支持向量机、RF随机森林、NB朴素贝叶斯)
- 深度神经网络(Deep Neural Network)
- 卷积神经网络(Convolution Neural Network)
- 长短时记忆网络(Long Short-Term Memory Network)
针对序列模型进行建模,包含上下文依赖关系,比如“我 是 一名 大学生”中的“我”和“是”前后出现的条件概率更高。广泛应用于文本分类、语音识别中,同样适用于恶意代码检测。 - 图卷积网络 (Graph Convolution Network)
比较新兴的方法,将卷积应用到图领域,图这种数据类型比较通用,非图数据比较容易转换成图数据,CCF论文中也已经应用到恶意代码检测中。。
2.静态特征设计举例
首先分享一个静态特征的例子,该篇文章发表在2015年,是一篇CCF C类会议文章。
- Saxe J,Berlin K. Deep neural network based malware detection using two dimensional binary program features[C] // 2015 10th International Conference on Malicious and Unwanted Software(MALWARE). IEEE, 2015: 11-20

文章的主要方法流程如下所示:
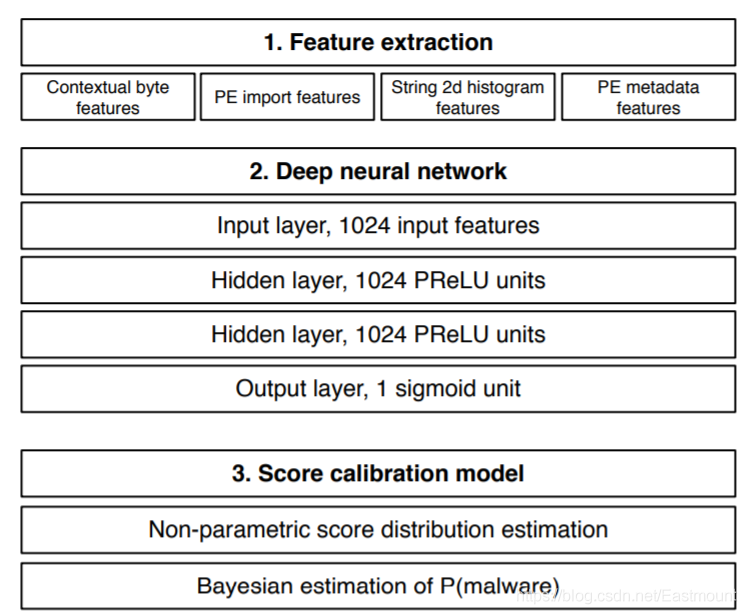
该模型包含三个步骤:
- 特征抽取
使用了四种特征 - 特征抽取输入到深度神经网络
包含两层隐含层的深度神经网络 - 分数校正
特征抽取
特征提取包括以下四种特征:

-
字节-熵对统计特征:统计滑动窗口的(字节,熵)对个数
在下图中,假设白框是一个二进制文件,其中红色框W是滑动窗口,二进制文件如果有100KB大小,每个滑动窗口是1024字节,那么滑动100次可以将整个二进制文件扫描完。如果对窗口内的数值进行计算,首先计算它的熵值,熵是信息论的概念(下图中的E),它描述了一个数组的随机性,熵越大其随机性越大。在图中,每一个滑动窗口都有固定的熵值,包含了1024字节,标记为(Bi,Ewi),最后滑动得到100x1024的字节熵对。
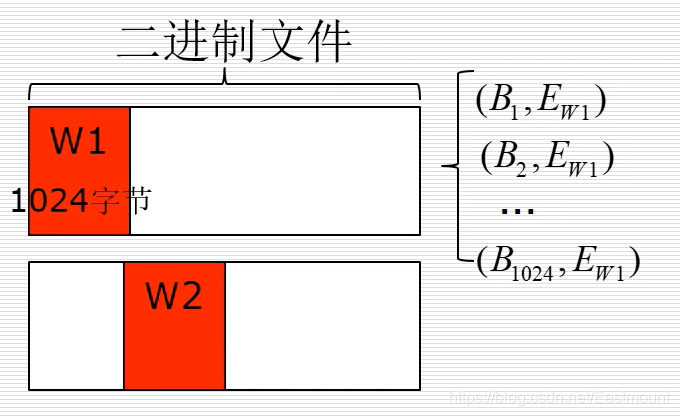
统计最后滑动得到100x1024的字节熵对个数,得到如下图所示的二维直方图结果,横坐标是熵值最小值到最大值的范围,纵坐标是一个字节转换成10进制的范围0-256,最终得到字节熵对分布的范围,再将16x16维的二维数组转换成1x256维的特征向量。
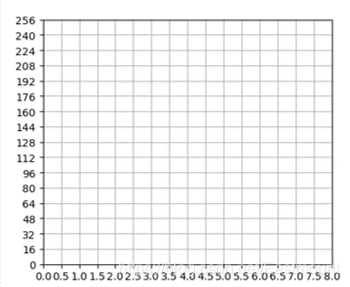
-
PE头IAT特征:hashDLL文件名与函数名为[0-255)范围
第二种特征是PE头IAT特征。它的计算工程是将PE头的IAT表里面的文件名和函数名hash到0到255范围,如果某个文件出现某个函数,就将该位置为1,当然每位对应表示的函数是固定的,最终得到256数组。 -
可打印字符:统计ASCII码的个数特征
可打印字符和字节熵对比较相似,这里推荐大家阅读原文。 -
PE元信息:将PE信息抽取出来组成256维数组,例如编译时间戳
PE元信息是将PE信息的数值型信息抽取出来,组成256维数组,每一个数组的位置表示了一个固定的信息种类,再信息种类将对应的信息填入到元素的位置,比如编译时间戳。
总共有上述四种特征,然后进行拼接得到4*256=1024维的数组,这个数组就代表一个样本的特征向量。假设有10000个样本,就有对应10000个特征向量。
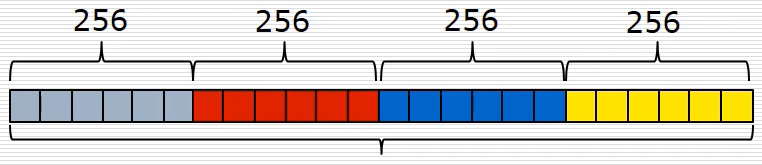
得到特征向量之后,就开始进行模型的训练和测试,一般机器学习任务事先都有一个数据集,并且会分为训练数据集和测试数据集,按照4比1或9比1的比例进行随机划分。训练会将数据集和标签对输入得到恶意和非恶意的结果,再输入测试集得到最终结果。
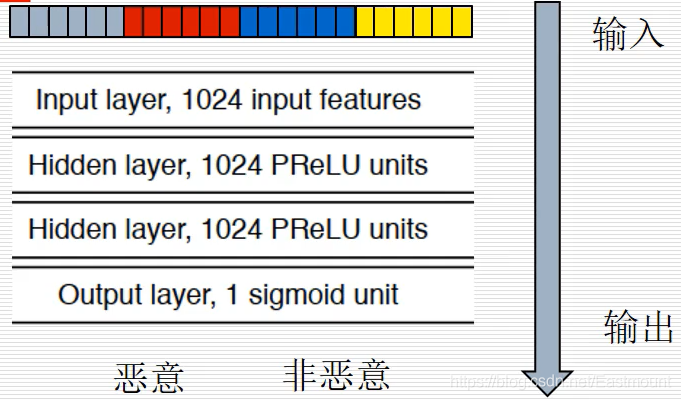
下面是衡量机器学习模型的性能指标,首先是一幅混淆矩阵的图表,真实类别中1代表恶意样本,0代表非恶意样本,预测类别也包括1和0,然后结果分为:
- TP:本身是恶意样本,并且预测识别为恶意样本
- FP:本身是恶意样本,然而预测识别为非恶意样本,这是误分类的情况
- FN:本身是非恶意样本,然而预测识别为恶意样本,这是误分类的情况
- TN:本身是非恶意样本,并且预测识别为非恶意样本
然后是Accuracy(准确率)、Precision(查准率)、Recall(查全率)、F1等评价指标。

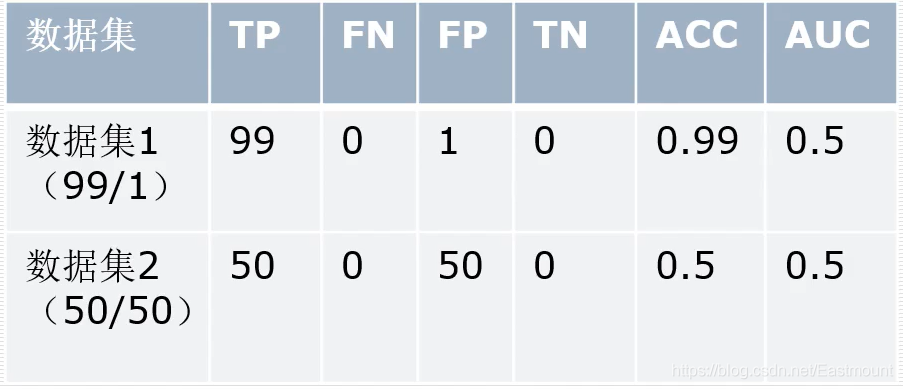
通常Accuracy是一个评价恶意代码分类的重要指标,但本文选择的是AUC指标,为什么呢?
假设我们模型的效果非常差,它会将所有本测试样本标记为恶意样本,这样我有两个数据集,一个样本包括100个数据(99个恶意样本、1个非恶意样本),另一个样本包括50个数据(50个恶意样本、50个非恶意样本),如果我单纯的计算ACC,第一个样本的结构是0.99,显然不符合客观的描述,不能用来评价性能高低的,并且这种情况是很容易产生的。所以论文中广泛采用AUC指标。
AUC指标包括TPRate和FPRate,然后得到一个点,并计算曲线以下所包围的面积即为AUC指标。其中,TPRate表示分类器识别出正样本数量占所有正样本数量的比值,FPRate表示负样本数量站所有负样本数量的比值。举个例子,我们撒网打鱼,一网下去,网中好鱼的数量占池子中所有好鱼的数量就是TPRate,而FPRate表示一网下去,坏鱼的数量占整个池子中所有坏鱼的数量比例,当然FPRate越小越好。最好的结果就是TPRate为1,而FPRate为0,此时全部分类预测正确。
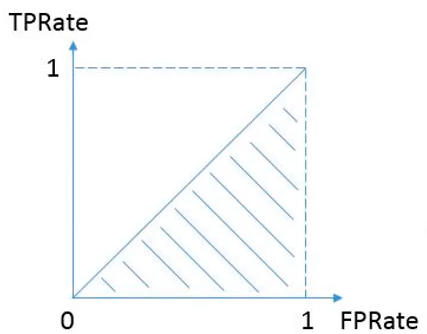
该论文测试了六种特征集合,其计算的TPR和AUC值如下所示。

3.经典的图片特征举例
下面介绍另一种比较新兴经典的方法,就是图片特征。但一些安全界的人士会认为这种特征不太好,但其方法还是比较新颖的。
它的基本方法是按照每8位一个像素点将恶意软件的二进制文件转换为灰度图片,图片通常分为R、G、B通道,每个8位像素点表示2^8,最终每隔8位生成一个像素点从而转换为如下图所示的灰度图片。图片分别为Obfuscator_ACY家族、Lolipop家族、ramnit家族恶意软件样例,这些样例由微软kaggle比赛公布的数据生成。
这是因为对于某些恶意样本作者来说,他只是使用方法简单的修改特征码,从而每个家族的图片比较相似,最终得到了较好的结果。

4.动态特征设计举例
接下来分享一个动态特征的例子,该篇文章发表在2016年,文章的会议一般,但比较有代表性。
- Kolosnjaji B,Zarras A,Webster G,et al. Deep learning for classification of malware system call sequences[C] // Australasian Joint Conference on Artificial Intelligence. Springer,Cham,2016:137-149.
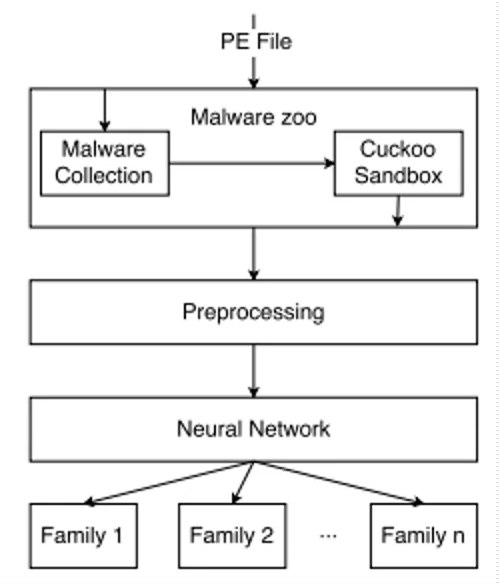
下图展示了该方法的整体流程图。PE文件进入后,直接进入Cuckoo沙箱中,它是一个开源沙箱,在学术论文中提取动态特征比较通用;接着进行进行预处理操作,将文本转换成向量表示的形式,比如提取了200个动态特征,可以使用200维向量表示,每个数组的位置表示对应API,再将所得到的序列输入卷积神经网络LSTM进行分类,最终得到家族分类的结构。
- Cuckoo沙箱
- LSTM

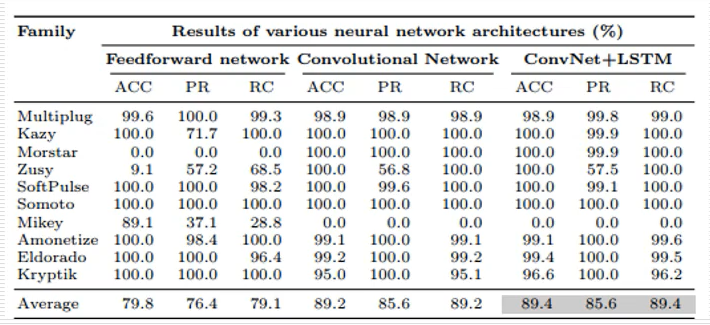
下图展示了实验的结构,其指标是高于单纯的神经网络和卷积网络的效果更好,这是一篇比较基础的文章。
5.深度学习静态检测举例
下面再看一个深度学习静态检测的文章。
- Coull S E,Gardner C. Activation Analysis of Byte-Based Deep Neural Network for Malware Classification[C] // 2019 IEEE Security and Privacy Workshops(SPW). IEEE,2019:21-27.
这篇文章是火眼公司的两名员工发布的,所使用的也是静态检测特征,其流程如下所示。
- 首先,原始的字节码特征直接输入一个Byte Embedding层(词嵌入),对单个元素进行向量化处理,将字节码中的每个字节表示成一个固定长度的向量,从而更好地将字节标记在一个空间维度中。词嵌入技术广泛应用于自然语言处理领域,比如“女人”和“女王”关系比较紧密,这篇文章的目的也是想要在恶意代码中达到类似的效果。
- 然后将矩阵输入到卷积和池化层中,比如存在一个100K字节的二进制文件,得到100102410矩阵输入卷积神经网络中,最后通过全连接层完成恶意和非恶意的分类任务。

Fireeye使用了三个数据集进行训练和测试,其训练的模型分类效果结果如下表所示,博客Small、Baseline、Baseline+Dropout模型,其网络结构是一样的,其中Small表示使用小的数据集,Baseline表示使用大的数据集,Dropout表示对训练好的神经网络中随机丢弃一些神经元,从而抑制过拟合现象,也是比较常用的深度学习技术。

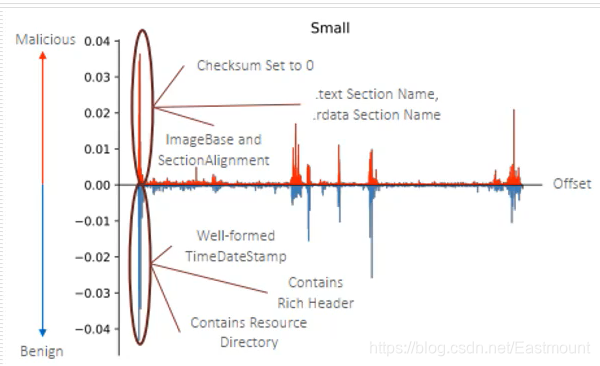
这篇文章的重点是对深度学习的解释性,就是解释深度学习是否能学习到恶意软件的本质特性。下图展示了不同特征对于分类结果的影响,横坐标是Offset偏移,通常用Offset记录字节,从0到右边也对应文件大小,前面可能就是PE头,中间有各种段。
它的横纵坐标分别表示了某些特征对于恶意性分类比较重要,还是非恶意性比较重要。如果它的校验和(CheckSum)是0,就对恶意性分类比较重要,这表示深度学习并没有学习到恶意软件为什么是恶意的,只是通过统计学去发现恶意软件和非恶意软件差别最大部分,以此进行数据建模。
深度学习进行恶意软件检测的问题:没有学习到恶意和非恶意特征,而是学习到区别的统计差异,而这种差异如果被黑客利用是可以被规避的。
6.优缺点
静态特征
- 优点
特征提取速度快
特征种类丰富,可以组合多种特征向量 - 缺点
易受加壳、加密、混淆干扰
无法防范无文件攻击,难以反映恶意软件行为的恶意性
动态特征
- 优点
提供恶意软件的动作,调用API
规避一些静态的混淆对抗方法 - 缺点
反虚拟化,延时触发等技术的对抗
测试时间较长,单个样本2-3分钟(Cuckoo)
最后给出推荐资料:
- 404notfound实验室总结的AI在安全领域应用
https://github.com/404notf0und/AI-for-Security-Learning - malware data science书籍
https://www.amazon.com/Malware-Data-Science-Detection-Attribution-ebook/dp/B077X1V9SY
7.静态分析和动态分析对比
下面简单总结静态分析和动态分析与深度学习结合的知识,该部分内容源自文章:深度学习在恶意代码检测 - mbgxbz,在此感谢作者,觉得非常棒,故引用至此!谢谢~
恶意代码的检测本质上是一个分类问题,即把待检测样本区分成恶意或合法的程序。基于机器学习算法的恶意代码检测技术步骤大致可归结为如下范式:
- 采集大量的恶意代码样本以及正常的程序样本作为训练样本;
- 对训练样本进行预处理,提取特征;
- 进一步选取用于训练的数据特征;
- 选择合适的机器学习算法训练分类模型;
- 通过训练后的分类模型对未知样本进行检测。
深度学习作为机器学习的一个分支,由于其可以实现自动化的特征提取,近些年来在处理较大数据量的应用场景,如计算机视觉、语音识别、自然语言处理时可以取得优于传统机器学习算法的效果。随着深度学习在图像处理等领域取得巨大的成功,许多人将深度学习的方法应用到恶意软件检测上来并取得了很好的成果。实际上就是用深度神经网络代替上面步骤中的人为的进一步特征提取和传统机器学习算法。根据步骤中对训练样本进行预处理的方式,可以将检测分为静态分析与动态分析:
- 静态分析不运行待检测代码,而是通过直接对程序(如反汇编后的代码)进行统计分析得到数据特征
- 动态分析则在虚拟机或沙箱中执行程序,获取程序执行过程中所产生的数据(如行为特征、网络特征),进行检测和判断。
(1) 静态分析
一般来说,在绝大部分情形下我们无法得到恶意程序的源代码。因此,常用的静态特征包括程序的二进制文件、从使用IDA Pro等工具进行反汇编得到的汇编代码中提取的汇编指令、函数调用等信息,另外基于字符串和基于API调用序列的特征也是比较常见的。文献[i]提出一种对PE文件的恶意程序检测方法,提取PE文件四个类型的特征:字节频率、二元字符频率、PE Import Table以及PE元数据特征,采用包含两个隐藏层的DNN作为分类模型,但是为了提取长度固定的输入数据,他们丢弃了PE文件中的大部分信息。文献[ii]使用CNN作为分类器,通过API调用序列来检测恶意软件,其准确率达到99.4%,远高于传统的机器学习算法。然而,当恶意代码存在混淆或加壳等情形时,对所选取的静态特征具有较大的影响,因此静态分析技术本身具有一定的局限性。
(2) 动态分析
利用虚拟机或沙箱执行待测程序,监控并收集程序运行时显现的行为特征,并根据这些较为高级的特征数据实现恶意代码的分类。一般来讲,行为特征主要包括以下几个方面:文件的操作行为;注册表键值的操作行为;动态链接库的加载行为;进程访问的操作行为;系统服务行为;网络访问请求;API调用。文献[iii]通过API调用序列记录进程行为,使用RNN提取特征向量,随后将其转化为特征图像使用CNN进行进一步的特征提取,提取其可能包含的局部特征并进行分类。文献[iv]提出了一个基于动态分析的2层架构的恶意软件检测系统:第1层是RNN,用于学习API事件的特征表示;第2层是逻辑回归分类器,对RNN学习的特征进行分类,然而这种方法的误报率较高。文献[v]提出了用LSTM和GRU代替传统RNN进行特征的提取,并提出了使用CNN的字符级别的检测方案。文献[vi]提出在恶意软件运行的初期对其进行恶意行为的预测,他们使用RNN进行PE文件检测,根据恶意代码前4秒的运行行为,RNN对恶意软件的预测准确率是91%,随着观察的运行时间的增长,RNN的预测准确率也随之提高。可以看到,相对于静态分析,动态分析的过程更加复杂耗时,相对而言采用了较高层次的特征,因此可解释性也较差。
在网络攻击趋于精细化、恶意代码日新月异的今天,基于深度学习算法的恶意代码检测中越来越受到学术界和众多安全厂商的关注。但这种检测技术在现实应用中还有很多尚未解决的问题。例如上面提到的静态分析与动态分析存在的不足,现在发展的主流方向是将静态、动态分析技术进行结合,使用相同样本的不同层面的特征相对独立地训练多个分类器,然后进行集成,以弥补彼此的不足之处。
除此之外,深度学习算法的可解释性也是制约其发展的一个问题,当前的分类模型一般情况下作为黑盒被加以使用,其结果无法为安全人员进一步分析溯源提供指导。我们常说攻防是息息相关的,螺旋上升的状态。既然存在基于深度学习的恶意代码检测技术,那么自然也有基于深度学习的或者是针对深度学习的恶意代码检测绕过技术,这也是近年来研究的热点问题,那么如何提高模型的稳健性,防止这些定制化的干扰项对我们的深度学习算法产生不利的影响,对抗生成网络的提出或许可以给出答案。
三.机器学习算法在工业界的应用
首先普及一个概念——NGAV。NGAV(Next-Gen AntiVirus)是下一代反病毒软件简称,它是一些厂商提出来的新的病毒检测概念,旨在用新技术弥补传统恶意软件检测的短板。
- 多家杀毒引擎厂商将机器学习视作NGAV的重要技术,包括McAfee[11], Vmware[9], CrowdStrike[10], Avast[6]
- 越来越多的厂商开始关注机器学习技术,并发表相关的研究(卡巴斯基[7],火眼[8]),火眼还是用机器学习技术对APT进行分析(组织相似度溯源)
越来越多的安全厂商将机器学习视为反病毒软件的一个关键技术,但需要注意,NGAV并不是一个清晰的定义,你没法去界定一个反病毒软件是上一代产品还是下一代产品。衡量反病毒软件的性能只有对恶意软件的检测率、计算消耗、误报率等,我们只是从现状分析得到越来越多安全领域结合了机器学习。
作为安全从业人员或科研人员,机器学习技术也是我们必须要关注的一个技术。

机器学习算法需要解决的问题如下:
-
算力问题
机器学习和深度学习算法需要大量的算力,如果我们在本地部署还需要GPU的支持,这样就带来了一个硬件配置问题,所以如何减小模型的size及提升模型的检测能力是一个关键性的问题。 -
大规模的特征数据
特征对于分类训练非常关键,如何抽取这些数据特征呢? -
训练的模型是可解释的
这个问题可以说是机器学习算法和深度学习算法在反病毒软件应用中最关键的一个问题,病毒的对抗是黑客与安全从业人员的对抗的前线,如果我们训练的模型是不可解释的,那么一旦被黑客发现某些规则存在的弱点,他们就可以针对这些弱点设计免杀方法,从而绕过造成重大安全隐患。另一方面,如果机器学习算法是不可解释黑盒的,用户他也是不可接受的,难以起到保护重要。 -
误报需要维持极度的低水平
误报是反病毒软件用户体验的一个重要指标,传统的特征码技术、主动防御技术都具有误报低的特性,而机器学习是一个预测技术,会存在一些误报,如何避免这些误报并且提高检测的查全率也是重要的问题。 -
算法需要根据恶意软件作者的变化快速适应新的检测特征
这也是关键性问题,在机器学习模型应用中,恶意软件是不断变化的,而机器学习算法部署到本地中,它的参数是不变的,所以在长时间的恶意演化中其模型或参数不再适用,其检测结果会有影响。目前,云沙箱、在线更新病毒库特征是一些解决方法。
最后作者总结下机器学习算法的优势,具体如下:
(1) 传统方法
- 优点:速度快,消耗计算资源少
只需要将特征码提取出来,上传至云端进行检测;相对于机器学习大量的矩阵计算,其计算资源消耗少。 - 缺点:容易绕过,对于未知恶意软件检出率低
使用加壳、加密、混淆容易绕过,对于未知软件不知道其特征码,只能通过启发式方法、主动防御济宁检测,相对于机器学习检测率要低。
(2) 机器学习方法
- 优点:能够建立专家难以发现的规则与特征
发现的规则和特征很可能是统计学特征,而不是恶意和非恶意的特征,所以这些特征很容易被黑客进行规避,这既是优点也是缺点,虽然有缺陷,但也能发现恶意样本的关联和行为。 - 缺点:资源消耗大,面临漂移问题,需要不断更新参数
四.总结
写到这里,这篇文章就介绍完毕,希望对您有所帮助,最后进行简单的总结:
- 机器学习方法与传统方法不是取代与被取代的关系,而是相互补充,好的防御系统往往是多种技术方法的组合。
- 机器学习的检测方法研究还不充分,安全领域的专有瓶颈与人工智能研究的共有瓶颈均存在、
- 机器学习算法本身也面对一些攻击方法的威胁,比如对应抗本。
对抗样本指的是一个经过微小调整就可以让机器学习算法输出错误结果的输入样本。在图像识别中,可以理解为原来被一个卷积神经网络(CNN)分类为一个类(比如“熊猫”)的图片,经过非常细微甚至人眼无法察觉的改动后,突然被误分成另一个类(比如“长臂猿”)。再比如无人驾驶的模型如果被攻击,Stop标志可能被汽车识别为直行、转弯。


学安全一年,认识了很多安全大佬和朋友,希望大家一起进步。这篇文章中如果存在一些不足,还请海涵。作者作为网络安全初学者的慢慢成长路吧!希望未来能更透彻撰写相关文章。同时非常感谢参考文献中的安全大佬们的文章分享,感谢师傅、师兄师弟、师姐师妹们的教导,深知自己很菜,得努力前行。

《珈国情》
明月千里两相思,
清风缕缕寄离愁。
燕归珞珈花已谢,
情满景逸映深秋。
最感恩的永远是家人的支持,知道为啥而来,知道要做啥,知道努力才能回去。
夜已深,虽然笨,但还得奋斗。
欢迎大家讨论,是否觉得这系列文章帮助到您!任何建议都可以评论告知读者,共勉。
(By:Eastmount 2020-07-24 星期六 夜于东西湖 http://blog.csdn.net/eastmount/ )
参考文献:
-
[1] Saxe J, Berlin K. Deep neural network based malware detection using two dimensional binary program features[C]//2015 10th International Conference on Malicious and Unwanted Software (MALWARE). IEEE, 2015: 11-20.
-
[2] https://www.kaggle.com/c/malware-classification
-
[3] https://www.fireeye.com/blog/threat-research/2018/12/what-are-deep-neural-networks-learning-about-malware.html
-
[4]Kolosnjaji B, Zarras A, Webster G, et al. Deep learning for classification of malware system call sequences[C]//Australasian Joint Conference on Artificial Intelligence. Springer, Cham, 2016: 137-149.
-
[5] Wüchner T, Cisłak A, Ochoa M, et al. Leveraging compression-based graph mining for behavior-based malware detection[J]. IEEE Transactions on Dependable and Secure Computing, 2017, 16(1): 99-112.
-
[6]https://www.avast.com/technology/malware-detection-and-blocking
-
[7] https://media.kaspersky.com/en/enterprise-security/Kaspersky-Lab-Whitepaper-Machine-Learning.pdf
-
[8] https://www.fireeye.com/blog/threat-research/2019/03/clustering-and-associating-attacker-activity-at-scale.html
-
[9] https://www.carbonblack.com/resources/definitions/what-is-next-generation-antivirus/
-
[10] https://www.crowdstrike.com/epp-101/next-generation-antivirus-ngav/
-
[11] https://www.mcafee.com/enterprise/en-us/security-awareness/endpoint/what-is-next-gen-endpoint-protection.html
-
[i] Saxe, J., & Berlin, K. (2015, October). Deep neural network-based malware detection using two-dimensional binary program features. In 2015 10th International Conference on Malicious and Unwanted Software (MALWARE) (pp. 11-20). IEEE.
-
[ii] Nix, R., & Zhang, J. (2017, May). Classification of Android apps and malware using deep neural networks. In 2017 International joint conference on neural networks (IJCNN) (pp. 1871-1878). IEEE.
-
[iii] Tobiyama, S., Yamaguchi, Y., Shimada, H., Ikuse, T., & Yagi, T. (2016, June). Malware detection with deep neural network using process behavior. In 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC) (Vol. 2, pp. 577-582). IEEE.
-
[iv] Pascanu, R., Stokes, J. W., Sanossian, H., Marinescu, M., & Thomas, A. (2015, April). Malware classification with recurrent networks. In 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1916-1920). IEEE.
-
[v] Athiwaratkun, B., & Stokes, J. W. (2017, March). Malware classification with LSTM and GRU language models and a character-level CNN. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2482-2486). IEEE.
-
[vi] Athiwaratkun, B., & Stokes, J. W. (2017, March). Malware classification with LSTM and GRU language models and a character-level CNN. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2482-2486). IEEE.