前言
爬虫,全称网络爬虫,就是通过技术手段从网络获取数据的程序或者脚本
人生苦短,我选python。本次就用python来进行实现对一个壁纸网站的图片下载
本篇文章就是直接爬虫实战。通过本文,带你了解requests库的基本使用,并且完成壁纸网站的图片爬取
声明:博主攻城狮白玉的本篇博文只用于对于爬虫技术的学习交流。如果侵犯到相关网站利益,请联系我删除博文。造成不便还请见谅。希望各位同学在学习的时候不要过于频繁的去请求。
一、requests库介绍
Requests库是python一个很好用的http请求库。封装得很好~在我们爬虫的时候常常也会用到。
Requests的官方介绍说到,让HTTP服务人类。有一说一,这是个非常容易使用的库。本次咱们的爬虫也会用到这个库。
关于requests库的介绍,可以看一下官方文档
Requests: 让 HTTP 服务人类 - Requests 2.18.1 文档
使用前记得安装requests库
pip install requests
二、网站分析
进入目标网站
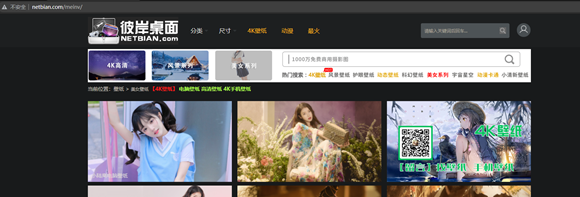
随便点开一张图,查看它的url,http://www.netbian.com/desk/23744.htm
先留意一下这个网址,后面会用到

回到浏览器,打开F12,通过目标元素检查工具,点击刚刚我们点过的图片。通过它的元素我们可以知道a标签里的属性值href的链接就是上面我们访问图片的链接地址
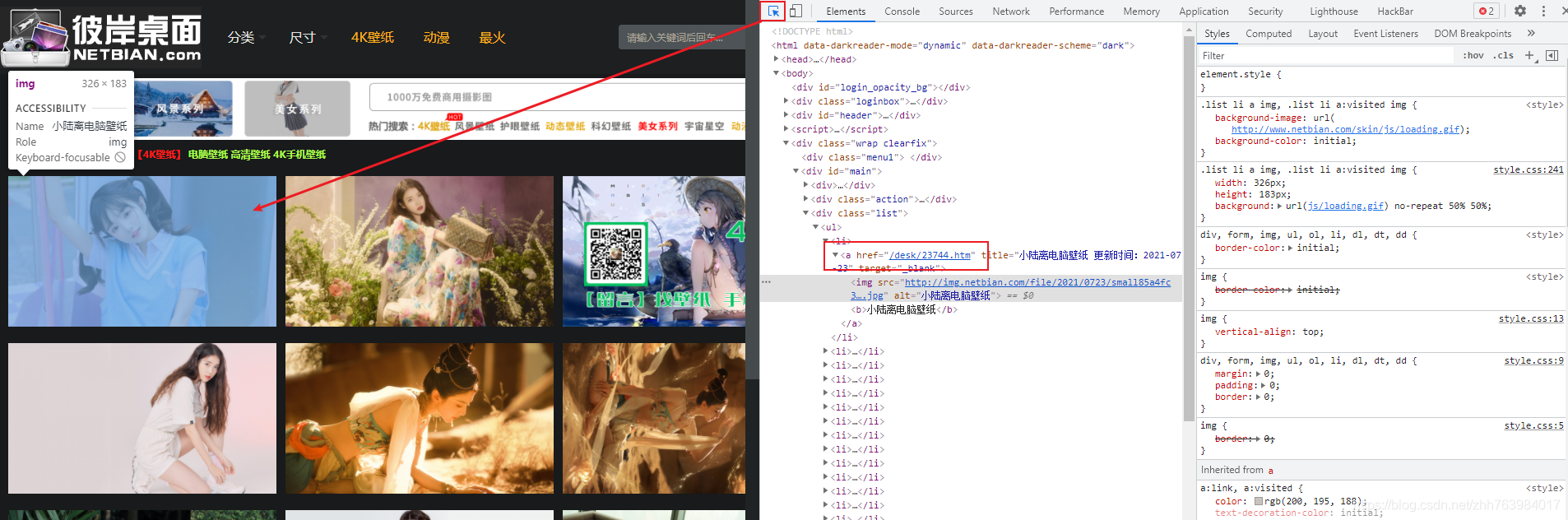
我们在大图的页面,同样用f12点击一下,找到图片的链接地址
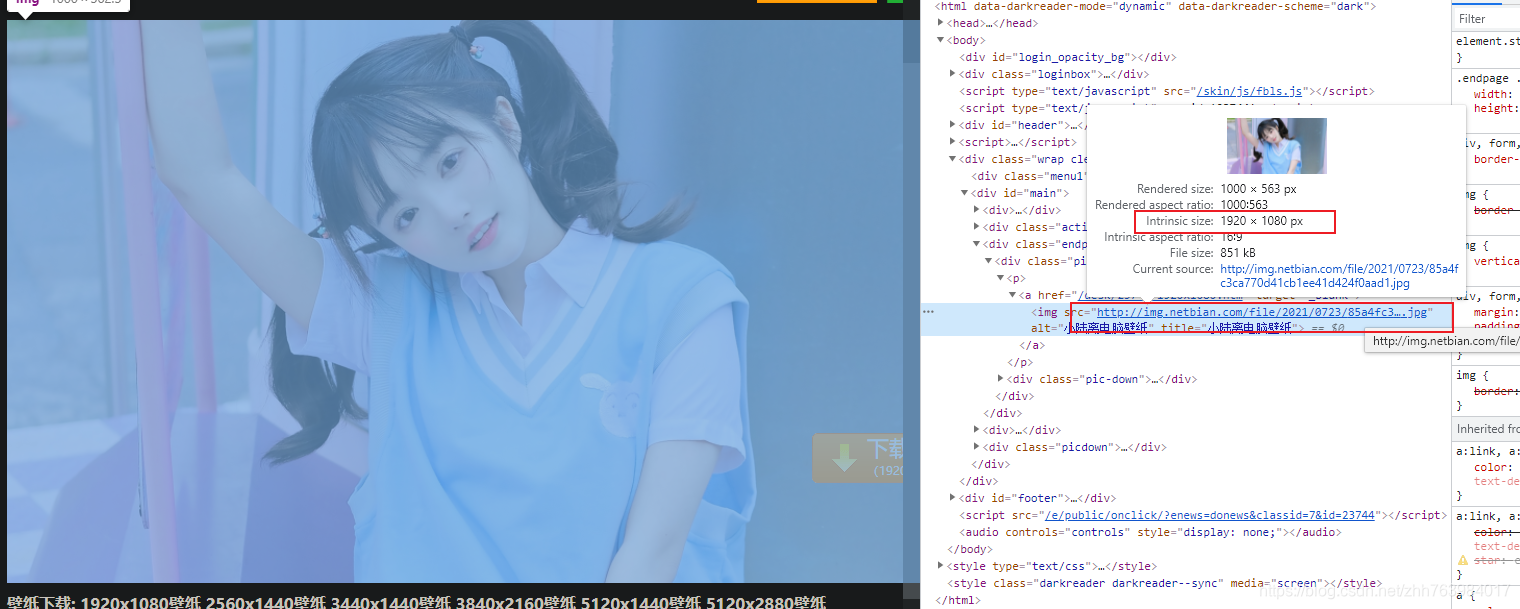
访问图片链接发现是咱们要的大图。至此,对于网站的分析完毕。

三、任务分析
综上所述,咱们目标网站是一个壁纸图片网站,编程做到的步骤如下:
- 访问首页
- 定位到每个图片的详情链接
- 访问详情链接
- 定位到图片对应的大图链接。下载,保存图片
看起来是不是很容易,开干
四、编程实现
4.1 访问首页
import requests
url = 'http://www.netbian.com/meinv/'
resp = requests.get(url)
resp.encoding = 'gbk'
#
with open('index.html', 'wb') as f:
f.write(resp.content)通过requests库发起get请求,请求壁纸网站的首页。并把结果保存在index.html文件里面
打开保存的文件一看,我们把首页给下载下来了。

4.2 定位元素
这里我们通过xpath方式。这里用到的是lxml库。不懂lxml库的话,参考下文
【Python】爬虫解析利器Xpath,由浅入深快速掌握(附源码例子)
PS:谷歌渲染的页面的xpath和requests请求回来的xpath会有不一样。有时需要保存下来进行xpath分析
对于元素进行定位。把a标签的href值全部拿出来,而且也把对应的名称取出来

tree = etree.HTML(resp.content)
node_list = tree.xpath('/html/body/div[2]/div[2]/div[3]/ul/li')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/@href')) > 0:
sub_url = node.xpath('./a/@href')[0]
if len(node.xpath('./a/@href')) > 0:
title = node.xpath('./a/b/text()')[0]
sub_url_list.append((sub_url, title))4.3 访问详情页
base_url = 'http://www.netbian.com/'
for sub_url, title in sub_url_list:
s_page = base_url + sub_url
s_resp = requests.get(s_page)
with open('s.html', 'wb') as f:
f.write(s_resp.content)4.4 定位图片链接并下载
img = s_tree.xpath('/html/body/div[2]/div[2]/div[3]/div/p/a/img/@src')[0]
suffix = img.split('.')[-1]
img_content = requests.get(img).content
with open(f'./image/{title}.{suffix}', 'wb') as f:
f.write(img_content)
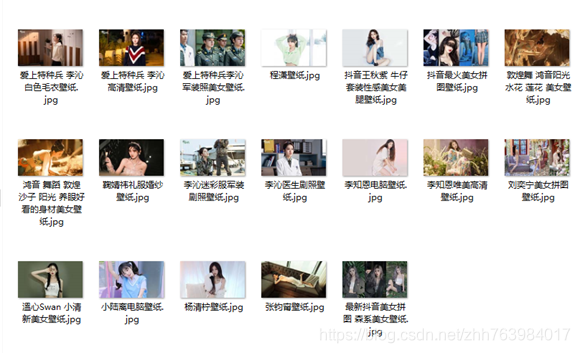
f.close()下载完效果图
4.5 完整源码
import requests
from lxml import etree
import time
'''
目标网站是一个图片网站
1.访问首页
2.定位到每个图片的下载链接
3.定位到每个图片对应的大图链接
4.下载,保存图片
'''
if __name__ == '__main__':
t1 = time.time()
url = 'http://www.netbian.com/meinv/'
resp = requests.get(url)
resp.encoding = 'gbk'
with open('index.html', 'wb') as f:
f.write(resp.content)
tree = etree.HTML(resp.content)
node_list = tree.xpath('/html/body/div[2]/div[2]/div[3]/ul/li')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/@href')) > 0:
sub_url = node.xpath('./a/@href')[0]
if len(node.xpath('./a/@href')) > 0:
title = node.xpath('./a/b/text()')[0]
sub_url_list.append((sub_url, title))
#
base_url = 'http://www.netbian.com/'
for sub_url, title in sub_url_list:
s_page = base_url + sub_url
s_resp = requests.get(s_page)
s_tree = etree.HTML(s_resp.content)
img = s_tree.xpath('/html/body/div[2]/div[2]/div[3]/div/p/a/img/@src')[0]
suffix = img.split('.')[-1]
img_content = requests.get(img).content
with open(f'./image/{title}.{suffix}', 'wb') as f:
f.write(img_content)
f.close()
t2 = time.time()
print(t2-t1)总结
妈妈再也不用担心我的学习了。
写在后面
如果觉得有用的话,麻烦一键三连支持一下攻城狮白玉,并把本文分享给更多的小伙伴。你的简单支持,我的无限创作动力