零、初章

欢迎大家踊跃评论,优秀的评论更能引起大家的共鸣,评论超过20字,或有内涵,或点赞前十名,都将获得 《夜深人静写算法》 和 《C语言入门100例》的 5 折优惠券(各一张) ,三天为限,记得主动联系博主。



一、开端

- C语言是一种高级语言,运行效率仅次于汇编,支持跨平台,所以被广泛的应用于软件开发、系统开发、嵌入式系统、游戏开发等场景。
二、一个C语言程序

1、编程环境
- ( 1 ) (1) (1) 百度搜索 “c语言在线编译”,如图四-1-1所示:
-
(
2
)
(2)
(2) 任意选择一个在线编译工具,我选择的是菜鸟工具,如图四-1-2所示:
图四-1-2
2、写代码

- 先给出代码,然后根据行尾的标号,一行一行进行解释;
#include <stdio.h> // (1)
int main() // (2)
{
/* 我的第一个 C 程序 */ // (3)
printf("Hello, World! \n"); // (4)
return 0; // (5)
}
这段代码只做了一件事情,就是向屏幕上输出一行字:
Hello, World!。
( 1 ) (1) (1)stdio.h是一个头文件 (标准输入输出头文件) ,#include是一个预处理命令,用来引入头文件。当编译器遇到printf()函数时,如果没有找到stdio.h头文件,就会发生编译错误。
( 2 ) (2) (2)main()作为这个程序的入口函数,代码都是从这个函数开始执行的。
( 3 ) (3) (3) 被/*和*/包围起来的代表注释,是给人看到,不进行代码的解析和执行。
( 4 ) (4) (4)printf代表将内容输出到控制台上。其中\n代表换行符。
( 5 ) (5) (5) 作为函数的返回值。

- 你可能对 头文件、预处理命令、函数、换行符、返回值 这些都没有概念,没有关系,刚开始我们不去理解这些概念,你只需要知道:通过改一些代码以后,能够看到想要看到的结果 就行。
3、修改代码
- 我们把 Hello, World 改成 光天化日学C语言 后,再来看看效果:
#include <stdio.h> // (1)
int main() // (2)
{
/* 我的第一个 C 程序 */ // (3)
printf("光天化日学C语言! \n"); // (4)
return 0; // (5)
}

三、编译运行

1、编译
- 编译就是把高级语言变成计算机可以识别的二进制语言,因为计算机只认识 1 和 0,你需要把一大堆复杂的语言词法、语法全部转换成 0 和 1。
2、运行
- 运行就是执行可执行程序啦。就是我们通常 Windows 上的双击 exe 干的事情。

四、为什么要搭建本地环境

- 1)联网:在线编译环境毕竟涉及到联网,如果没有网的情况下,我们就不能写代码了,真是听者伤心,闻者流泪啊;
- 2)定制化:写代码是一辈子的事情,界面当然要搞得赏心悦目才能持久,本地环境可以配置字体和背景,支持定制化,觉得什么界面好看就配成什么样的;
- 3)代码补全:字体高亮,代码补全 这些好用的功能,能够帮助你减少很多不必要编码错误;
- 4)多文件:当代码量比较大以后,涉及到多个文件时,在线编译环境就无能为力了;

五、下载 Dev C++
- Dev C++ 是一个轻量级的 C/C++ 集成编译环境,正因为是轻量级,所以还是有很多不太好用的地方,不过不用担心,对于教学来说已经足够了。
- 相比 Visual Studio 20XX 来说,安装快了不少,所以我打算用这个工具来进行后续文章的讲解。
- 可以选择以下任何一个链接进行下载,下载后解压出 DevCpp_v6.5.exe 即可。
百度网盘下载
- 链接:C语言轻量级编译调试工具 Dev C++ v6.5
- 提取码:dd22
CSDN下载
- 链接:C语言轻量级编译调试工具 Dev C++ v6.5
六、安装 Dev C++
1、语言选择
- 双击 DevCpp 的 exe 文件,会跳出如下对话框,初学者建议直接用中文。如图五-1所示:

2、我接受
- 同意安装,如图五-2所示:

3、下一步
- 点击下一步,如图五-3所示:
4、选择安装位置
- 选择一个你钟意的安装路径,点击安装,如图五-4所示:

5、看他装完
- 看他安装完,大概 7 秒左右,如图五-5-1所示:
七、配置
1、选择语言
- 选择一个你钟意的语言,推荐用中文,强我国威,壮我河山!点击 Next,如图六-1所示:
2、选择配色
- 选择一个你看着舒服的配色方案,推荐 VS Code,如图六-1所示:
八、写一段代码
1、新建文件
- 点击界面左上角的 【新建】 按钮,选择【源代码】菜单栏,如图七-1所示;

图七-1
2、写代码
- 把我们第一章中写过的代码,写到这个文件中。建议自己一行一行写哦,复制粘贴 和 自己敲出来的感觉是不一样的。
#include <stdio.h>
int main() {
printf("光天化日写C语言!\n");
return 0;
}
3、保存文件
- 点击菜单栏的【保存】按钮,或者 Ctrl + S 快捷键保存文件。
4、编译运行
- 点击菜单栏的【编译运行】或者 F11 按钮,就会跳出一个控制台,如图七-4所示:
九、变量


1、变量的定义
对于一个变量而言,有三部分组成:
1)变量类型;
2)变量名;
3)变量地址;
- 在C语言中,我们可以通过如下的方式定义一个变量:
int Iloveyou;
1)变量类型
int表示变量类型,是英文单词 Integer 的缩写,意思是整数。

2)变量名
Iloveyou表示变量名,也可以叫其它名字,例如:WhereIsHeroFrom、ILoveYou1314等等。- 这个语句的含义是:在内存中找一块区域,命名为
Iloveyou,用它来存放整数。 - 需要注意的是,最后有一个分号,
int Iloveyou表达了一个语句,要用分号来结束。需要注意的是,最后有一个分号,int Iloveyou表达了一个语句,要用分号来结束。

3)变量地址

2、变量的赋值
- C语言中可以用以下语句把
520
520
520 这个整数存储到
Iloveyou这个变量里:
Iloveyou = 520;

=在数学中叫 “等于号”,例如1 + 1 = 2,但在C语言中,这个过程叫做变量的赋值,简称赋值。赋值是指把数据放到内存的过程。
3、变量的初始化
- 把上面的两个语句连起来,得到:
int Iloveyou;
Iloveyou = 520;
- 当然,我们也可以写成如下形式:
int Iloveyou = 520;

- 两段代码的执行结果相同,都是把
Iloveyou的值变成 520 520 520;

4、变量的由来
- 如果我们需要,可以随时改变它的值,如下代码所示:
int Iloveyou = 520;
Iloveyou = 521;
Iloveyou = 522;
Iloveyou = 523;
- 代码执行完毕以后,它的值以最后一次赋值为准,正因为可以不断修改,是可变的,所以才叫变量。
- 简单总结一下就是:数据是放在内存中的,变量是给这块内存起的名字,有了变量就可以找到并使用这份数据。
5、多变量的定义
- 如果几个变量的类型一致,我们可以写在一行上进行定义,如下:
int x, y, z = 5;
- 这段代码代表一次性定义了三个整型类型的变量,并且将
z初始化为 5,等价于如下代码:
int x;
int y;
int z = 5;
6、变量间的赋值
- 变量不能赋值给数字,但是变量可以赋值给变量。
int a, b;
520 = a; // 错误
a = b; // 正确

【例题1】给出如下代码,求输出结果是什么。
#include <stdio.h>
int main()
{
int a = 1314, b = 520;
b = a;
a = b;
printf("a=%d b=%d\n", a, b);
return 0;
}
十、数据类型

- 接下来我们展开来讲一下变量类型,更加确切的讲,应该叫数据类型,C语言中有如下一些系统内置数据类型。
1、内置数据类型
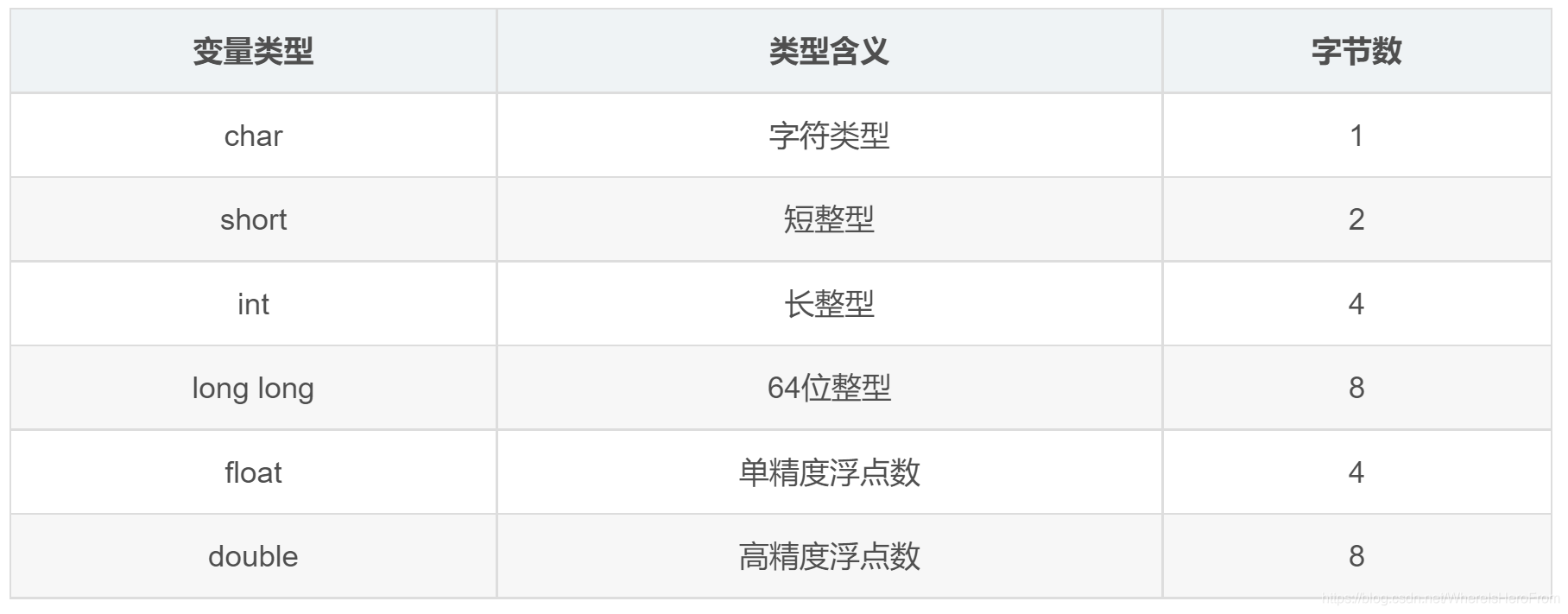
- 从上面这个表,我们可以看到,有表示字符的,有表示整数的,也有表示浮点数的。

- 先来简单看下每种内置类型是如何进行定义的:
char a = 'a';
short b, c, d = 1314, e, f;
int g = 5201314;
long long h = 123456789;
float i = 4.5;
double j = 4.50000;
2、数据的大小

- 字节是计算机中的一种基本单位,英文名为 Byte,计算机中所有的数据都是由字节组成的。
- 我们通常在计算机中看到的文件单位 B 、K、M 、G、T 和字节的关系如下:

- 一个字节在计算机里面是有 8 个位组成,一个位有 0 和 1 两种状态,所以一个字节能表示的状态数就是
2
8
=
256
2^8 = 256
28=256。如图四-2-1,代表的是一个字节的状态,白色代表0,灰色代表1,它的二进制表示就是
(
00001101
)
2
(00001101)_2
(00001101)2。

图四-2-1
3、整数的表示范围
- 这样一来,上面提到的几种整数类型,能够表示的整数就显而易见了,假设字节数为 n n n,那么能够表示的整数个数就是能够表示的状态个数,即: 2 8 n 2^{8n} 28n 。
- 由于我们需要表示负数 和 零,实际的每种整数数据类型能够表示的数字范围如下表所示:


十一、变量名
1、标识符
- 定义变量时,我们使用了诸如
love、Iloveyou这样的名字,为了表达变量的作用,这就叫 标识符,即 Identifier。 - 标识符就是程序员自己起的名字,除了变量名,后面还会讲到函数名、常量名、宏名、结构体名等,它们都是标识符。
2、关键字
- 关键字(Keywords)是由C语言规定的具有特定意义的字符串,通常也称为保留字,例如
int、char、long、int、unsigned int等。 - 程序自己定义的标识符不能与关键字相同,否则会出现错误。
- 后续会对各个关键字进行一一讲解。
3、命名规则
-
(
1
)
(1)
(1) 必须由字母、数字 或者下划线构成,如
_aa,a123,_都是合法的变量,?*、a a、#、都是非法的变量; -
(
2
)
(2)
(2) 不能以数字开头,如
123abc不是一个合法的变量名; -
(
3
)
(3)
(3) 大小写敏感,即大小写看成不同,即
o和O不是同一个变量; - ( 4 ) (4) (4) 不能将变量名和C语言的语法保留关键字同名;
- ( 5 ) (5) (5) C语言虽然不限制标识符的长度,但是它受到 编译器 和 操作系统 的限制。例如在某个编译器中规定标识符前 256 位有效,当两个标识符前 256 位相同时,则被认为是同一个标识符。
- ( 6 ) (6) (6) 标识符命名时还是最好遵循 min-length-max-infomation 的原则,即以最小的长度表达最全的信息,不过这个是规范上的,语言层面是不会做过多的限制的。

【例题2】给出一段程序,请回答这段程序的运行结果。
#include <stdio.h>
int main()
{
int IloveYou = 0;
ILoveYou = 1314;
ILoveYou = ILoveYou;
ILoveYou = 520;
printf("%d\n", ILoveYou);
return 0;
}
- 建议先看代码,心里想着一个答案,然后再去 光天化日学C语言(01)- 第一个C语言程序 中提到的在线编译环境中将代码一行一行敲出来,看看和你自己想的结果是否一致。
十二、概念简介
1、输出的含义
2、标准输出
在C语言中,有三个函数可以用来在屏幕上输出数据,它们分别是:
1)puts() :只能输出字符串,并且输出结束后会自动换行;
2)putchar() :只能输出单个字符;
3)printf():可以输出各种类型的数据,作为最灵活、最复杂、最常用的输出函数,可以完全替代全面两者,所以是必须掌握的,今天我们就来全面了解一下这个函数。
3、格式化

- 我们在进行输出的时候,对于小数而言,可能需要输出小数点后一位,亦或是两位,这个计算机自己是不知道规则的,需要写代码的人告诉它,这个告诉它如何输出的过程就被称为格式化。
十三、格式化输出
printf前几个章节都有提及,这个函数的命名含义是:Print(打印) 和 Format (格式) ,即 格式化输出。
1、数据类型格式化
1)整数
#include <stdio.h>
int main()
{
int a = 520;
long long b = 1314;
printf("a is %d, b is %lld!\n", a, b);
return 0;
}
- 对于
int而言,我们利用%d将要输出的内容进行格式化,然后输出,简单的理解就是把%d替换为对应的变量,%lld用于对long long类型的变量进行格式化,所以这段代码的输出为:
a is 520, b is 1314!

2)浮点数
#include <stdio.h>
int main()
{
float f = 1.2345;
double df = 123.45;
printf("f is %.3f, df is %.0lf\n", f, df);
return 0;
}
- 对于浮点数而言,我们利用
%f来对单精度浮点数float进行格式化;用%lf来对双精度浮点数进行格式化,并且用.加 “数字” 来代表要输出的数精确到小数点后几位,这段代码的输出为:
f is 1.235, df is 123
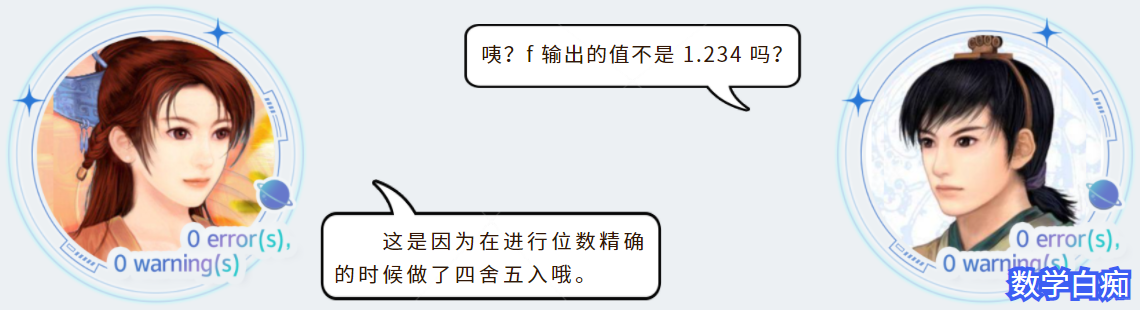
- 另外,单精度 和 双精度 的区别就是双精度的精度更高一点,也就是能够表示的小数的范围更加精准,这个会在介绍浮点数的存储方式时详细介绍。
3)字符
#include <stdio.h>
int main()
{
char ch = 'A';
printf("%c\n", ch);
return 0;
}
- 对于字符而言,我们利用
%c来进行格式化;C语言中的字符是用单引号引起来的,当然,字符这个概念扯得太远,会单独开一个章节来讲,具体可以参考 ASCII 码。 - 顺便我们来解释一下一直出现但是我闭口不提的换行符
\n,这个符号是一个转义符,它代表的不是两个字符(反斜杠\和字母n),而是换行的意思; - 这段代码的输出就是一个字符 A;
A
- 我们通过一个例题来理解这个换行符的含义;

【例题1】第1行输出1个1,第2行输出2个2,第3行输出3个3,第4行输出4个4。
#include <stdio.h>
int main()
{
printf("1\n");
printf("22\n");
printf("333\n");
printf("4444\n");
return 0;
}
- 我们也可以用一条语句解决,如下:
#include <stdio.h>
int main()
{
printf("1\n22\n333\n4444\n");
return 0;
}

4)字符串
- 字符串,是由多个字符组合而成,用双引号引起来,这一章我不打算讲得太细,只需要知道用
%s进行格式化的即可,代码如下:
#include <stdio.h>
int main()
{
char str[100] = "I love you!";
printf("%s\n", str);
return 0;
}
- 这段代码,聪明的你应该很容易看懂啦!输出的就是:
I love you!
- 作者:我了个擦,字体颜色都变了……
2、对齐格式化
- 我们发现,上文中所有的格式化,都有一个
%和一个字母,事实上,在百分号和字母之间,还有一些其它的内容。
主要包含如下内容:
1)负号:如果有,则按照左对齐输出;
2)数字:指定字段最小宽度,如果不足则用空格填充;
3)小数点:用与将最小字段宽度和精度分开;
4)精度:用于指定字符串重要打印的而最大字符数、浮点数小数点后的位数、整型最小输出的数字数目;

【例题2】给定如下一段代码,求它的输出内容。
#include <stdio.h>
int main()
{
double x = 520.1314;
int y = 520;
printf("[%10.5lf]\n", x);
printf("[%-10.5lf]\n", x);
printf("[%10.8d]\n", y);
printf("[%-10.8d]\n", y);
return 0;
}

- 输出答案如下:
[ 520.13140]
[520.13140 ]
[ 00000520]
[00000520 ]
- 我们发现,首先需要看小数点后面的部分,将要输出的内容实际要输出多少的长度确定下来,然后再看字段最小宽度,最后再来看左对齐还是右对齐。
- 然后,我们来看看把不同类型的变量组合起来是什么效果;
#include <stdio.h>
int main()
{
char name[100] = "Zhou";
int old = 18;
double meters = 1.7;
char spostfix = 's';
printf("My name is %s, %d years old, %.2lf meter%c.\n",
name, old, meters, spostfix);
return 0;
}
- 它的输出结果如下:
My name is Zhou, 18 years old, 1.70 meters.

十四、输入概念简介
1、输入的含义

2、标准输入
在C语言中,有三个函数可以用来在键盘上输入数据,它们分别是:
1)gets() :用于输入一行字符串;
2)getchar() :用于输入单个字符;
3)scanf():可以输入各种类型的数据,作为最灵活、最复杂、最常用的输入函数,虽然无法完全替代前面两者,但是却是必须掌握的,今天我们就来全面了解一下这个函数。
3、格式化

- 我们在进行输入的时候,其实都是一个字符串,但是这个字符串被输入后有可能当成整数来用,也有可能还是字符串,这个计算机自己是不知道规则的,需要写代码的人告诉它,这个告诉它如何输入的过程就被称为格式化。
十五、整数的格式化输入
scanf的函数的命名含义是:Scan(扫描) 和 Format (格式) ,即 格式化输入。- 和输出一样,输入的时候,也根据数据类型的不同,分为 整数、浮点数、字符、字符串等等。
- 但是这里会有很多问题,拿整数的输入为例,我们一个一个来看。
1、单个数据的输入
- 对于单个数据的输入,如下代码所示:
#include <stdio.h>
int main()
{
int a;
scanf("%d", &a);
printf("%d\n", a);
return 0;
}
- 这段代码的执行结果如下:
1314↙
1314
其中
↙代表回车,即我们通过键盘输入1314,按下回车后,在屏幕上输出1314。
类比输出,我们发现,输入和输出的差别在于:
( 1 ) (1) (1) 函数名不同;
( 2 ) (2) (2) 输入少了换行符\n;
( 3 ) (3) (3) 输入多了取地址符&;

- 我们会在后面指针的章节来围绕对这个符号进行展开的。
2、多个数据的输入
- 类比单个数据的输入,我们来看看两个数据的输入:
#include <stdio.h>
int main()
{
int a, b;
scanf("%d", &a);
scanf("%d", &b);
printf("%d %d\n", a, b);
return 0;
}
- 这段代码的执行结果如下:
520↙
1314↙
520 1314
其中
↙代表回车,即我们通过键盘输入520,按下回车,再输入1314,按下回车后,在屏幕上输出520 1314。
- 这个很好理解,那么我们同样可以把输入放在一行上进行输入,类比输出的格式,如下:
#include <stdio.h>
int main()
{
int a, b;
scanf("%d %d", &a, &b);
printf("%d %d\n", a, b);
return 0;
}
- 这段代码的执行结果如下:
520 1314↙
520 1314
其中
↙代表回车,即我们通过键盘输入520、空格、1314,按下回车后,在屏幕上输出520 1314。
- 所以,多个数据的输入,我们可以放在一个
scanf语句来完成。
3、空格免疫
- 然后我们来看下,对于输入的数据之间有一个空格和多个空格的情况,代码如下:
#include <stdio.h>
int main()
{
int a, b;
scanf("%d %d", &a, &b);
printf("%d %d\n", a, b);
return 0;
}
520 1314↙
520 1314
其中
↙代表回车,即我们通过键盘输入520、n个空格、1314,按下回车后,在屏幕上输出520 1314。
- 也就是说,虽然文中要求是1个空格,但是我们输入多个也不影响我们输入,再来看下一种情况:
#include <stdio.h>
int main()
{
int a, b;
scanf("%d %d", &a, &b);
printf("%d %d\n", a, b);
return 0;
}
520 1314↙
520 1314
其中
↙代表回车,即我们通过键盘输入520、1个空格、1314,按下回车后,在屏幕上输出520 1314。
- 也就是说,虽然文中要求多个空格,但是我们输入1个也不影响我们输入。

4、回车结算
- 通过以上的几个例子,我们发现,
scanf()是以回车来结算一次输入的。 - 用户每次按下回车键,计算机就会认为完成一次输入操作,
scanf()开始读取用户输入的内容,并根据我们定义好的格式化内容从中提取有效数据,只要用户输入的内容和格式化内容匹配,就能够正确提取。

十六、输入缓冲区
- 在讲输入缓冲区之前,我们先来看个例子:
#include <stdio.h>
int main()
{
int a, b, c, d;
scanf("%d %d %d %d", &a, &b, &c, &d);
printf("%d %d %d %d\n", a, b, c, d);
return 0;
}
- 接下里我们将围绕这段代码进行展开。
1 2 3 4↙
1 2 3 4
- 以上是我们的期望输入。
1、少输入
- 我们尝试少输入1个数,按下回车后,发现程序并没有任何的输出,当我们再次输入下一个数的时候,产生了正确的输出,如下:
1 2 3↙
4↙
1 2 3 4
2、多输入
- 我们尝试多输入1个数,按下回车后,发现输出了前四个我们输入的数,如下:
1 2 3 4 5↙
1 2 3 4
3、再次尝试
- 我们增加一行代码,就是在输出四个数以后,再调用一次
scanf(),如下:
#include <stdio.h>
int main()
{
int a, b, c, d, e;
scanf("%d %d %d %d", &a, &b, &c, &d);
printf("%d %d %d %d\n", a, b, c, d);
scanf("%d", &e);
printf("%d\n", e);
return 0;
}
- 然后我们采用上述的一次性输入5个数的方式,如下:
1 2 3 4 5↙
1 2 3 4
5
- 这时候,我们发现程序正常运行了。
- 这是因为:我们从键盘输入的数据并没有直接交给
scanf(),而是放入了输入缓冲区中,当我们按下回车键,scanf()才到输入缓冲区中读取数据。如果缓冲区中的数据符合scanf()给定的格式要求,那么就读取结束;否则,继续等待用户输入,或者读取失败。 - 关于输入缓冲区的内容,比较复杂,属于进阶内容,就不在这个章节继续展开啦。

【例题1】给定一段代码,如下,并且给出一个输入,请问输出是什么。
#include <stdio.h>
int main()
{
int a = 9, b = 8, c = 7, d = 6, e = 5;
scanf("%d %d %d %d", &a, &b, &c, &d);
printf("%d %d %d %d\n", a, b, c, d);
scanf("%d", &e);
printf("%d\n", e);
return 0;
}
- 输入如下:
1 2b 3 4 5↙

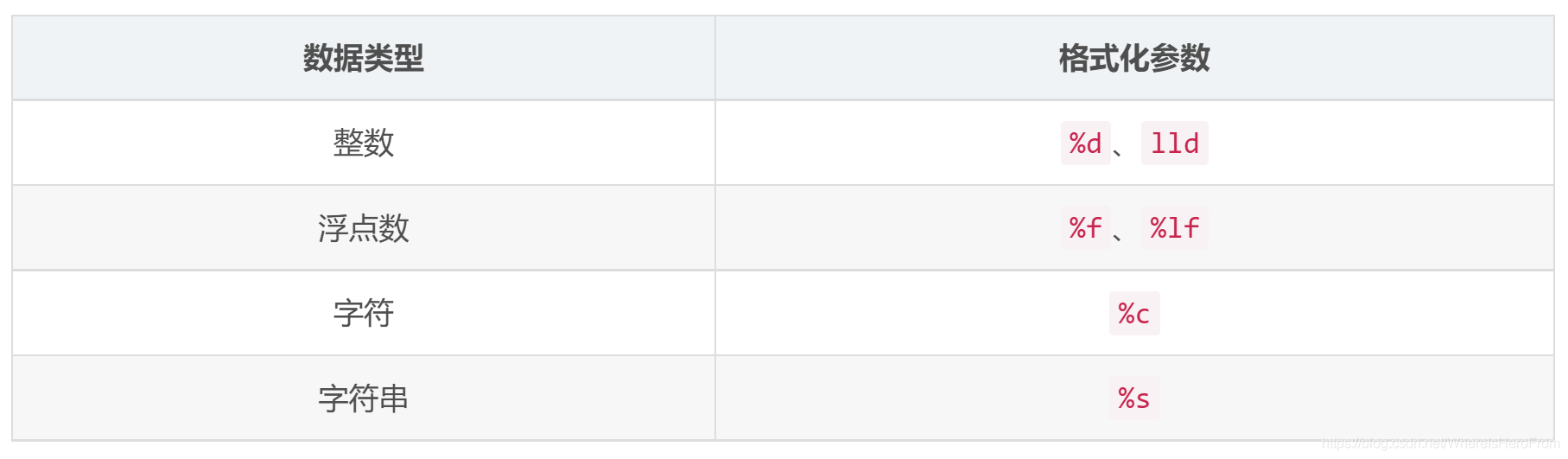
十七、其他数据类型的格式化输入
- 其它数据类型,例如浮点数、字符、字符串的格式化参数类似
printf,如下:
1、字符串的输入
- 关于字符串,后面在讲完数组以后,还会着重讲,也有很多匹配算法是应用于字符串上的,也是一个很重要的内容,所以这里不作太多介绍,只需要记住,字符串输入时
&可以不加,如下:
#include <stdio.h>
int main()
{
char str[100];
scanf("%s", str); // (1)
printf("%s\n", str);
scanf("%s", &str); // (2)
printf("%s\n", str);
return 0;
}
- ( 1 ) (1) (1) 和 ( 2 ) (2) (2) 的方式都是可以的,但是我们一般采用 ( 1 ) (1) (1) 的方式;
2、做个简单的游戏吧

- 这是一个算命游戏,要求根据输入的姓名,得到这个人的算命信息。
- 我们先来看看效果:

- 好啦,代码实现如下:
#include <stdio.h>
int main()
{
char str[100];
int height;
printf("请大侠输入姓名:");
scanf("%s", str);
printf("请大侠输入身高(cm):");
scanf("%d", &height);
printf("%s大侠,身高%dcm,骨骼惊奇,是百年难得一遇的人才,只要好好学习C语言,日后必成大器!\n", str, height);
return 0;
}
- 你学废了吗?评论区留下你的算命结果哦 ~~
十八、何为进制

- 进制也就是 进位计数制 的简称,是人为定义的带进位的计数方法。
- 对于任何一种进制 —— X进制,表示每一个数位上的数运算时都是逢 X 进一位。
- 例如:十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,八进制是逢八进一,以此类推,X进制就是 逢X进一。
- 如图三-1所示,代表的则是十进制的进位演示:

十九、常用进制
1、二进制

- 我们从定义出发:逢二进一。
两只鞋子 = 1双鞋子;
二个抓手 = 1双手;
2、三进制
- 同样,什么是逢三进一呢?
3个月 = 1个季度;
3、四进制
- 好了接下来,你能举出四进制的例子吗?

4个季度 = 1年
5、十进制
- 当然,现实生活中遇到的最多的数字都是十进制表示。例如:0、1、2、3、… 、9、10、…
4、其它进制

七进制:7天 = 1周;
十二进制:12瓶啤酒 = 1打;
二十四进制:24小时 = 1天;
六十进制:60秒 = 1分钟;60分钟 = 1小时;
二十、计算机中的进制
- 在计算机中常用的进制有哪些呢?
1、二进制
- C语言中,我们如果想表示一个二进制数,可以用
0b作为前缀,然后跟上0和1组成的数字,我们来看一段代码:
#include <stdio.h>
int main() {
int a = 0b101;
printf("%d\n", a);
return 0;
}
- 这段代码中,输出的结果如下:
5
- 因为
%d代表输出的数是十进制,所以我们需要将二进制转换成十进制以后输出,0b101的数学表示如下: ( 101 ) 2 (101)_2 (101)2 - 它在十进制下的值为 5。
- 因为数字比较小,所以我们可以简单列出二进制和十进制的对应关系如下:
| 进制 | 零 | 一 | 二 | 三 | 四 | 五 |
|---|---|---|---|---|---|---|
| 二进制 | 0 | 1 | 10 | 11 | 100 | 101 |
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 |
- 也就是二进制下
101对应于十进制下的 5。
2、八进制
- 讲八进制之前,我们还是先来看一段代码:
#include <stdio.h>
int main() {
int a = 0123;
printf("%d\n", a);
return 0;
}
🙉饭不食,水不饮,题必须刷🙉
还不会C语言,和我一起打卡! 🌞《光天化日学C语言》🌞
LeetCode 太难?上简单题! 🧡《C语言入门100例》🧡
LeetCode 太简单?大神盘他! 🌌《夜深人静写算法》🌌
- 那么,这段代码的输出值为多少呢?

83
- 为什么呢?参考二进制的表示法,八进制的表示法是前缀1个
0,然后跟上0-7的数字; - 换言之,我们需要把
123这个八进制数转换成十进制后再输出。而转换结果就是83,由于这里数字较大,我们已经无法一个一个数出来了,所以需要进行进制转换,关于进制转换,在第四节进制转换初步里再来讲解。
3、十六进制
- 同样的,对于十六进制数,表示方式为:以
0x或者0X作为前缀,跟上0-9、a-f、A-F的数字,其中大小写字母的含义相同,分别代表从10到15的数字。如下表所示:
| 小写字母 | 大写字母 | 代表数字 |
|---|---|---|
a | A | 10 |
b | B | 11 |
c | C | 12 |
d | D | 13 |
e | E | 14 |
f | F | 15 |
- 我们看看这段代码的输出:
#include <stdio.h>
int main() {
int a = 0X123;
printf("%d\n", a);
return 0;
}
- 对于这段代码,输出的是:
291

二十一、进制转换初步
1、X进制 转 十进制
对于 X 进制的数来说,我们定义以下几个概念:
【概念1】对于数字部分从右往左编号为 0 到 n n n,第 i i i 个数字位表示为 d i d_i di,这个数字就是 d n . . . d 1 d 0 d_{n}...d_1d_0 dn...d1d0;
【概念2】每个数字位有一个权值;
【概念3】第 i i i 个数字位的权值为 X i X^i Xi;
- 基于以上几个概念, X进制 转 十进制的值为 每一位数字 和 它的权值的乘积的累加和,如下:
- ∑ i = 0 n X i d i \sum_{i=0}^{n} X^id_i i=0∑nXidi
- ∑ \sum ∑ 是个求和符号,不必惊慌!
- 举个例子,对于上文提到的八进制的数
0123,转换成十进制,只需要套用公式: - ∑ i = 0 n X i d i = ∑ i = 0 2 8 i d i = 8 2 × 1 + 8 1 × 2 + 8 0 × 3 = 64 + 16 + 3 = 83 \begin{aligned}\sum_{i=0}^{n} X^id_i &= \sum_{i=0}^{2} 8^id_i \\ &= 8^2 \times 1 + 8^1 \times 2 + 8^0 \times 3 \\ &= 64 + 16 + 3 \\ &= 83\end{aligned} i=0∑nXidi=i=0∑28idi=82×1+81×2+80×3=64+16+3=83
- 再如,上文提到的十六进制数
0X123,转换成十进制,套用同样的公式,如下: - ∑ i = 0 n X i d i = ∑ i = 0 2 1 6 i d i = 1 6 2 × 1 + 1 6 1 × 2 + 1 6 0 × 3 = 256 + 32 + 3 = 291 \begin{aligned}\sum_{i=0}^{n} X^id_i &= \sum_{i=0}^{2} 16^id_i \\ &= 16^2 \times 1 + 16^1 \times 2 + 16^0 \times 3 \\ &= 256 + 32 + 3 \\ &= 291\end{aligned} i=0∑nXidi=i=0∑216idi=162×1+161×2+160×3=256+32+3=291
2、十进制 转 X进制
- 对于 十进制 转 X进制 的问题,我们可以这么来考虑:
- 从 X进制 转 十进制 的原理可知,任何一个十进制数字都是由 X进制 的幂的倍数累加而成。所以,一个数一定有 X 0 X^0 X0 这部分,而这部分,可以通过原数除上 X X X 的余数得到。然后我们把原数除上 X X X 后得到的数,肯定又有 X 0 X^0 X0 的部分,就这样重复的试除,直到得到的商为 零 时结束,过程中的余数,逆序一下就是对应进制的数了。
- 还是一上文的例子来说,对于
291我们可以通过如下方式,转换成 十六进制。
291 除 16 ========== 余 3
18 除 16 =========== 余 2
1 除 16 ============ 余 1
- 而对于十进制的83,我们可以通过如下方式,转换成 八进制。
83 除 8 ============ 余 3
10 除 8 ============ 余 2
1 除 8 ============= 余 1
- 那么,等我们后面学习了循环语句以后,就可以教大家如何用计算机来实现进制转换了,目前阶段只需要了解下进制转换的基本原理即可。
二十二、ASCII 码简介

1、ASCII 码的定义
- ASCII 码(即 American Standard Code for Information Interchange),翻译过来是美国信息交换标准代码。
- 我们一般念成 ask 2 马。

2、ASCII 码的起源
- 它是一套编码系统。
- 由于计算机用 高电平 和 低电平 分别表示 1 和 0,所以,在计算机中所有的数据在存储和运算时都要使用二进制数表示,例如,像
a-z、A-Z这样的52个字母以及0-9的数字还有一些常用的符号(例如?*#@!@#$%^&*()等)在计算机中存储时也要使用二进制数来表示,具体用哪些二进制数字表示哪个符号,每个人都可以约定自己的一套规则,这就叫编码。 - 即 一个数字 和 一个字符 的一一映射。
- 为了通信而不造成混淆,所以需要所有人都使用相同的规则。
3、ASCII 码的表示方式
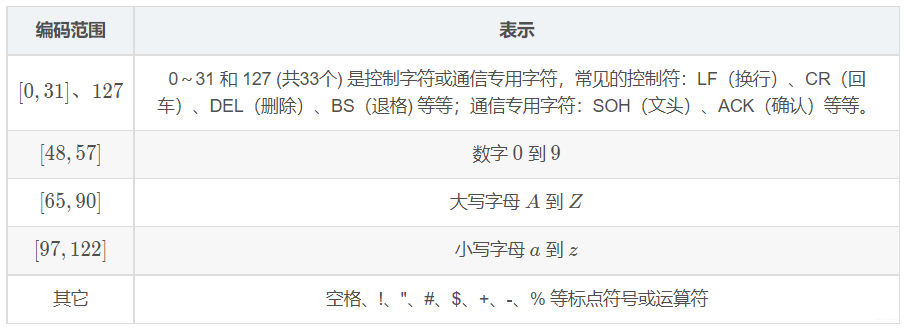
- 标准ASCII 码,使用 7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字
0到9、标点符号,以及在英语中使用的特殊控制字符。 - 简单的就可以认为:一个数字对应一个字符。具体如下表所示:
二十三、ASCII 码的输出
- ASCII 码对应的字符用单引号括起来,并且是可以按照两种方式来输出的,分别为:字符形式 和 整数形式。
1、字符
- 当成字符用的时候,用格式化输出
%c来控制,如下:
#include <stdio.h>
int main() {
printf("%c\n", '0');
printf("%c\n", 'A');
printf("%c\n", 'a');
printf("%c\n", '$');
return 0;
}
- 得到的输出结果如下:
0
A
a
$

2、整数
- 当成整数用的时候,用格式化输出
%d来控制,如下:
#include <stdio.h>
int main() {
printf("%d\n", '0');
printf("%d\n", 'A');
printf("%d\n", 'a');
printf("%d\n", '$');
return 0;
}
- 得到的输出结果如下:
48
65
97
36
- 这是因为一个字符代表的是一个整数到符号的映射,它本质上还是一个整数,所以我们可以用整数的形式来输出。字符
'0'的整数编码为48,字符'1'的整数编码为49,以此类推。

二十四、ASCII 码的运算
- 既然当成了整数,那么就可以进行简单的四则运算了。
- 我们简单来看下下面这段代码:
#include <stdio.h>
int main() {
printf("%c\n", '0' + 5);
printf("%c\n", 'A' + 3);
printf("%c\n", 'a' + 5);
printf("%c\n", '$' + 1);
return 0;
}
- 它的输出如下:
5
D
f
%
- 字符加上一个数字,我们可以认为是对字符编码进行了一个对应数字的偏移,字符
'0'向右偏移 5 个单位,就是字符'5';同样的,'A'向右偏移3个单位,就是字符'D'。 - 有加法当然也有减法,接下来让我们看个例题。

【例题1】给出如下代码,给出它的输出结果。
#include <stdio.h>
int main() {
printf("%c\n", 'A' - 10);
return 0;
}
- 建议先想想,然后再敲代码看看结果,是否和你想的一致。
二十五、ASCII 码的比较
- ASCII 码既然可以和整数无缝切换,那么自然也可以进行比较了。
- 通过上一节,我们了解到了
'0'加上1以后等于'1',那么顺理成章可以得出:'0' < '1'。 - 同样可以知道:
'a' < 'b'、'X' < 'Y'。 - 那么,我们再来看个问题。

【例题2】请问
'a' < 'A'还是'a' > 'A'。

二十六、常量简介

- C语言中的常量,主要分为以下几种类型:

二十七、数值常量
- 数值常量分为整数和浮点数,整数一般称为整型常量,浮点数则称为实型常量。
1、整型常量
- 整型常量分为二进制、八进制、十进制 和 十六进制。
- 每个整型常量分为三部分:前缀部分、数字部分、后缀部分。
- 如下表所示:

- 关于前缀这部分,在 光天化日学C语言(06)- 进制转换入门 已经讲到过,就不再累述了。
- 这里着重提一下后缀,
u(unsigned)代表无符号整数,l(long)代表长整型,ll代表long long。

- 换言之,无符号整型就是非负整数。
- 待时机成熟,我会对整数的存储结构进行一个非常详细的介绍。

【例题1】说出以下整型常量中,哪些是非法的,为什么非法。
1314
520u
0xFoooooL
0XFeeeul
018888
0987UU
0520
0x4b
1024llul
30ll
030ul
2、实型常量
- 实型常量又分为 小数形式 和 指数形式。
1)小数形式
- 小数形式由三部分组成:整数部分、小数点、小数部分。例如:
3.1415927
4.5f
.1314
- 其中
f后缀代表float,用于区分double。 .1314等价于0.1314。
2)指数形式
- 指数形式的典型格式为
xey,如下:
1e9
5.2e000000
5.2e-1
1.1e2
- 它表示的数值是:
- x × 1 0 y x \times 10^{y} x×10y
- 其中
y
y
y 代表的是数字
10的指数部分,所以是支持负数的。
二十八、字符常量
- 字符常量可以是一个普通的字符、一个转义序列,或一个通用的字符。
- 每个字符都对应一个 ASCII 码值。
1)普通字符
- 普通字符就是用单引号括引起来的单个字符,如下:
'a'
'Q'
'8'
'?'
'+'
' '
- 包含 26 个小写字母,26 个大写字母,10 个数字,几个标点符号,运算符等等。
- 具体参见:光天化日学C语言(07)- ASCII码。
2)转义字符
- 转义字符是用引号引起来,并且内容为 斜杠 + 字符,例如我们之前遇到的用
'\n'代表换行,\t代表水平制表符(可理解为键盘上的 tab 键),'\\'代表一个反斜杠,等等; - 当然还可以用
'\ooo'来代替一个字符,其中一个数字o代表一个八进制数;也可以用'\xhh'来代表一个字符,具体见如下代码:
#include <stdio.h>
int main() {
char a = 65;
char b = '\101';
char c = '\x41';
printf("%c %c %c\n", a, b, c);
return 0;
}

- 以上的代码输出结果为:
A A A
- 这是因为八进制下的
101和十六进制的41在十进制下都是65,代表的是大写字母'A'的ASCII 码值。


【例题1】请问如何输出一个单引号?
二十九、字符串常量
- 字符串常量,又称为字符串字面值,是括在双引号
""中的。一个字符串包含类似于字符常量的字符:普通字符、转义序列。
1、单个字符串常量
#include <stdio.h>
int main() {
printf( "光天化日学\x43语言!\n" );
return 0;
}
- 我们可以用转义的
'\x43'代表'C'和其它字符组合,变成一个字符串常量。以上代码输出为:
光天化日学C语言!

【例题2】如果我想要如下输出结果,请问,代码要怎么写?
"光天化日学C语言!"
2、字符串常量分行
- 两个用
""引起来的字符串,是可以无缝连接的,如下代码:
#include <stdio.h>
int main() {
printf(
"光天化日学"
"C语言!\n"
);
return 0;
}
- 这段代码的结果也是:
光天化日学C语言!
三十、符号常量
1、#define
- 利用
#define预处理器可以定义一个常量如下:
#include <stdio.h>
#define TIPS "光天化日学\x43语言!\n"
#define love 1314
int main() {
printf( TIPS );
printf("%d\n", love);
return 0;
}
- 以上这段代码,会将所有
TIPS都原文替换为"光天化日学\x43语言!\n";将所有love替换为1314。

2、const
const的用法也非常广泛,而且涉及到很多概念,这里只介绍最简单的用法,后面会开辟一个新的章节专门来讲它的用法。
#include <stdio.h>
const int love = 1314;
int main() {
printf( "%d\n", love );
return 0;
}
- 我们可以在普通变量定义前加上
const,这样就代表它是个常量了,在整个运行过程中都不能被修改。

【例题3】下面这段代码会发生什么情况,自己编程试一下吧。
#include <stdio.h>
const int love = 1314;
int main() {
love = 520;
printf( "%d\n", love );
return 0;
}
三十一、算术运算符

- 算术运算符主要包含以下几个:
- 1)四则运算符,也就是数学上所说的加减乘除;
- 2)取余符号;
- 3)自增和自减。

- 那么接下来让我们一个一个来看看吧。
1、四则运算符
- 数学上的加减乘除和C语言的加减乘除的含义类似,但是符号表示方法不尽相同,对比如下:
| / | 加法 | 减法 | 乘法 | 除法 |
|---|---|---|---|---|
| 数学 | + | - | × \times × | ÷ |
| C语言 | + | - | * | / |
1)加法
a + b代表两个操作数相加,代码如下:
#include <stdio.h>
int main() {
int a = 1, b = 2;
double c = 1.005, d = 1.995;
printf("a + b = %d\n", a + b );
printf("c + d = %.3lf\n", c + d);
printf("a + c = %.3lf\n", a + c);
return 0;
}
- 这段代码的输出为:
a + b = 3
c + d = 3.000
a + c = 2.005

2)减法
a - b代表从第一个操作数中减去第二个操作数,代码如下:
#include <stdio.h>
int main() {
int a = 1, b = 2;
double c = 1.005, d = 1.995;
printf("a - b = %d\n", a - b );
printf("c - d = %.3lf\n", c - d);
printf("a - c = %.3lf\n", a - c);
return 0;
}
- 这段代码的输出为:
a - b = -1
c - d = -0.990
a - c = -0.005

3)乘法
a * b代表两个操作数相乘,代码如下:
#include <stdio.h>
int main() {
int a = 1, b = 2;
double c = 1.005, d = 1.995;
printf("a * b = %d\n", a * b);
printf("c * d = %.3lf\n", c * d);
printf("a * c = %.3lf\n", a * c);
return 0;
}
- 这段代码的输出为:
a * b = 2
c * d = 2.005
a * c = 1.005

4)除法

不同类型的除数和被除数会导致不同类型的运算结果。
1)当 除数 和 被除数 都是整数时,运算结果也是整数;
1.a)如果能整除,结果就是它们相除的商;
1.b)如果不能整除,那么就直接丢掉小数部分,只保留整数部分,即数学上的 取下整;
2)除数和被除数中有一个是小数,那么运算结果也是小数,并且是 double 类型的小数。
- 我们来看一段代码:
#include <stdio.h>
int main() {
int a = 6, b = 3, c = 4;
double d = 4;
printf("a / b = %d\n", a / b );
printf("a / c = %d\n", a / c);
printf("a / d = %.3lf\n", a / d);
return 0;
}
- 输出结果如下:
a / b = 2
a / c = 1
a / d = 1.500
a能被整除b,所以第一行输出它们的商,即2;a不能被整除c,所以第二行输出它们相除的下整,即1;a和d中,d为浮点数,所以相除得到的也是浮点数;

#include <stdio.h>
int main() {
int a = 5, b = 0;
int c = a / b;
return 0;
}
- 这里会触发一个异常,即 除零错。这种情况在 C语言中是不允许的,但是由于变量的值只有在运行时才会确定,编译器是没办法帮你把这个错误找出来的,平时写代码的时候一定要注意。

2、取余符号
- 取余,也就是求余数,使用的运算符是
%。C语言中的取余运算只能针对整数,也就是说,%两边都必须是整数,不能出现小数,否则会出现编译错误。 - 例如:
5 % 3 = 2、7 % 2 = 1。
当然,余数可以是正数也可以是负数,由
%左边的整数决定:
1)如果%左边是正数,那么余数也是正数;
2)如果%左边是负数,那么余数也是负数。
- 我们继续来看一段代码:
#include <stdio.h>
int main()
{
printf(
"9%%4=%d\n"
"9%%-4=%d\n"
"-9%%4=%d\n"
"-9%%-4=%d\n",
9%4,
9%-4,
-9%4,
-9%-4
);
return 0;
}
- 在 光天化日学C语言(08)- 常量 这一章中,我们提到的两个用
""引起来的字符串是可以无缝连接的,所以这段代码里面四个字符串相当于一个。而%在printf中是用来做格式化的,所以想要输出到屏幕上,需要用%%。于是,我们得到输出结果如下:
9%4=1
9%-4=1
-9%4=-1
-9%-4=-1
- 印证了最后的符号是跟着左边的数走的。
3、自增和自减
- 自增和自减的情况类似,所以我们只介绍自增即可。

x = x + 1;
- 我们也可以写成:
x++;
- 当然,也可以写成:
++x;
- 这两者的区别是什么呢?我们来看一段代码:
#include <stdio.h>
int main()
{
int x = 1;
printf( "x = %d\n", x++ );
printf( "x = %d\n", x );
return 0;
}
- 输出结果是:
x = 1
x = 2
- 这是因为
x在自增前,就已经把值返回了,所以输出的是原值。我们再来看另一种情况:
#include <stdio.h>
int main()
{
int x = 1;
printf( "x = %d\n", ++x );
printf( "x = %d\n", x );
return 0;
}
- 输出结果是:
x = 2
x = 2
- 这是因为
x先进行了自增,再把值返回,所以输出的是自增后的值。 - 当然,自减也是同样的道理,大家可以自己写代码实践一下。
三十二、关系运算符

1、概览
- 关系运算符是用来判断符号两边的数据的大小关系的。
- C语言中的关系运算符主要有六个,如下:

2、表示方式
- C语言中的关系运算符和数学中的含义相同,但是表示方法略有不同,区别如下:
| 关系运算符释义 | C语言表示 | 数学表示 |
|---|---|---|
| 大于 | > | > |
| 大于等于 | >= | ≥ |
| 等于 | == | = |
| 不等于 | != | ≠ |
| 小于 | < | < |
| 小于等于 | <= | ≤ |
- 关系运算符的两边可以是变量、数值 或 表达式,例如:
1)变量
- a > b
- a != b
2)数值
- 3 > 5
- a == 6
3)表达式
- a + b > 4
- a > a + b
三十三、关系运算符的应用
1、运算结果
- 关系运算符的运算结果只有 0 或 1。当条件成立时结果为 1,条件不成立结果为 0。
- 我们来看一段代码,如下:
#include <stdio.h>
int main() {
printf("%d\n", 1 > 2);
printf("%d\n", 1 < 2);
return 0;
}
- 得到的输出结果为:
0
1
- 原因就是
1 > 2在数学上是不成立的,所以结果为0;而1 < 2在数学上是不成立的,所以结果为1;
2、运算符嵌套
- 关系运算符是允许嵌套使用的,即运算的结果可以继续作为关系运算符的运算参数,例如以下代码:
#include <stdio.h>
int main() {
printf("%d\n", 1 > 2 > -1);
return 0;
}
- 输出结果是多少呢?
- 由于
1 > 2的结果为0,所以1 > 2 > -1等价于0 > -1,显然是成立的,所以输出的结果为:
1

- 有关于结合性的内容,会在运算符的内容都讲完后,就运算符优先级和运算符结合性进行一个统一讲解,现在这个阶段,你只需要知道,关系运算符都是左结合,即存在多个运算符,有没有括号的情况下,一律从左往右计算。
【例题1】给出以下代码,问输出的结果是什么。
#include <stdio.h>
int main() {
printf("%d\n", 1 < 2 > 1);
printf("%d\n", 3 > 2 > 1);
return 0;
}
3、运算符优先级
!=和==的优先级低于>,<,>=,<=。- 优先级是什么呢?
- 看个例子就能明白。
#include <stdio.h>
int main() {
printf("%d\n", 1 < 2 == 1);
return 0;
}
- 我们可以做出两种假设:
- 假设1:
==优先级低于<;1 < 2优先计算,则表达式等价于1 == 1,成立,输出1。 - 假设2:
==优先级高于<;2 == 1优先计算,则表达式等价于1 < 0,不成立,输出0。 - 实际上,这段代码的结果为:
1
- 即
==的优先级低于<,当然,同学们可以试下!=和其它符号的关系。
- 另外,关系表达式会进场用在条件判断
if语句中,例如:
if(a < b) {
// TODO
}
- 我们会在将
if语句的时候继续复习关系运算符相关的知识哦~ - 不过写到这里,这个打字时真的卡!
4、== 和 =
- 初学者最容易犯的错是把
==和=搞混,前者是判断相等与否,而后者是赋值。 - 看一段代码,就能知道:
#include <stdio.h>
int main() {
int a = 0;
printf("%d\n", a = 0);
printf("%d\n", a == 0);
return 0;
}
- 以上这段代码的输出结果是:
0
1
- 神不神奇,意不意外?!
三十四、逻辑运算符

1、概览
- 逻辑运算符是用来做逻辑运算的,也就是我们数学中常说的 “与或非”。
- C语言中的逻辑运算符主要有三个,如下:

2、表示方式
- C语言中的逻辑运算符和数学中的含义类似,但是表示方法截然不同,对应关系如下:
| 逻辑运算符释义 | 操作数个数 | C语言表示 | 数学表示 |
|---|---|---|---|
| 与 | 二元操作符 | && | ∧ \land ∧ |
| 或 | 二元操作符 | || | ∨ \lor ∨ |
| 非 | 一元操作符 | ! | ¬ \lnot ¬ |
- 二元操作符的操作数是跟在符号两边的,而一元操作符的操作数则是跟在符号右边的。
- 逻辑运算符的操作数可以是变量、数值 或 表达式。例如:
1)变量
- a && b
- a || b
- !a
2)数值
- a && 520
- 1314 || 520
- !0
3)表达式
- a + b && c + d
- a + b || c + d
- !(a + b)
三十五、逻辑运算符的应用
1、运算结果

1)与运算(&&)
对于与运算,参与运算的操作数都为 “真” 时,结果才为 “真”,否则为 “假”。
#include <stdio.h>
int main() {
printf("%d\n", 0 && 0); // 0
printf("%d\n", 5 && 0); // 0
printf("%d\n", 0 && 5); // 0
printf("%d\n", 5 && 9); // 1
return 0;
}
- 注释中的内容,就是实际输出的内容。
- 我们发现,无论操作数原本是什么,程序只关心它是 “零” 还是 “非零”。然后根据
&&运算符自身的运算规则进行运算。

2)或运算(||)
对于或运算,参与运算的操作数都为“假”时,结果才为“假”,否则为“真”。
#include <stdio.h>
int main() {
printf("%d\n", 0 || 0); // 0
printf("%d\n", 5 || 0); // 1
printf("%d\n", 0 || 5); // 1
printf("%d\n", 5 || 9); // 1
return 0;
}
- 注释中的内容,就是实际输出的内容。
- 我们同样发现,无论操作数原本是什么,程序只关心它是 “零” 还是 “非零”。然后根据
||运算符自身的运算规则进行运算。

3)非运算(!)
对于非运算,操作数为 “真”,运算结果为 “假”;操作数为 “假”,运算结果为 “真”;
#include <stdio.h>
int main() {
printf("%d\n", !0); // 1
printf("%d\n", !5); // 0
return 0;
}
- 注释中的内容,就是实际输出的内容。
- 八个字概括:非真即假,非假即真。
2、运算符嵌套
- 和 关系运算符 一样,逻辑运算符也是可以支持嵌套的,即运算结果可以继续作为逻辑运算符的操作数,例如如下代码:
#include <stdio.h>
int main() {
int a = !( (5 > 4) && (7 - 8) && (0 - 1) );
printf("%d\n", a);
return 0;
}
(5 > 4)和(7 - 8)这两个表达式进行与运算,等价于:1 && 1,结果为1。1和(0 - 1)继续进行与运算,等价于1 && 1,结果为1。- 对
1进行非运算,得到结果为0。 - 所以这段代码最后输出的结果为:
0
3、运算符优先级
- 接下来,我们看下三个运算符混合运用的情况,对于如下代码:
#include <stdio.h>
int main() {
int a = !( 1 || 1 && 0 );
printf("%d\n", a);
return 0;
}

- 这个问题的答案是:
0

- 我们再来看个例子,区别只是在
1 || 1的两边加上一个括号。
#include <stdio.h>
int main() {
int a = !( (1 || 1) && 0 );
printf("%d\n", a);
return 0;
}
- 现在输出的答案变成了:
1
- 这是为什么呢?
- 因为
&&的优先级是比||要高的,所以在没有任何括号的情况下,&&会优先计算,简而言之,对于刚才的( 1 || 1 && 0 ),我们把它等价成( 1 || (1 && 0) ),这样是不是就好理解了。 - 用类似的方法,我们可以得到
!的优先级是最高的,所以这三个符号的优先级排序如下: - ∣ ∣ < & & < ! || \ < \ \&\& \ < \ ! ∣∣ < && < !

- 当然,后面的章节,我们会对 算术运算符、关系运算符、逻辑运算符 等等所有的运算符的优先级 和 结合性 进行一个梳理,尽情期待 ~~

通过这一章,我们学会了:
1)与运算:有假必假;
2)或运算:有真必真;
3)非运算:非真即假,非假即真;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题

- 【第01题】A + B | 四种输入方式,开启刷题的序章
- 【第04题】给定 a 和 b,问 a 能否被 b 整除 | && 的应用
- 【第11题】给出四个数,输出四个数的和 | && 的应用
三十六、再谈二进制
- 我们在学习 光天化日学C语言(06)- 进制转换入门 的时候,曾经提到过二进制。

- 在计算机中,非零即一。
1、二进制数值表示
- 例如,在计算机中,我们可以用单纯的 0 和 1 来表示数字。
1、101、1100011、100101010101 都是二进制数。
123、423424324、101020102101AF 则不是,因为有 0 和 1 以外的数字位。
- 一般为了不产生二义性,我们会在数字的右下角写上它的进制,例如:
- 101 0 ( 10 ) 1010_{(10)} 1010(10)
- 代表的是十进制下的 1010,也就是十进制下的 “一千零一十”。
- 101 0 ( 2 ) 1010_{(2)} 1010(2)
- 代表的是二进制下的 1010,也就是十进制下的 “十”。
2、二进制加法
二进制加法采用从低到高的位依次相加,当相加的和为2时,则向高位进位。
- 例如,在二进制中,加法如下: 1 ( 2 ) + 1 ( 2 ) = 1 0 ( 2 ) 1 ( 2 ) + 0 ( 2 ) = 1 ( 2 ) 0 ( 2 ) + 1 ( 2 ) = 1 ( 2 ) 0 ( 2 ) + 0 ( 2 ) = 0 ( 2 ) 1_{(2)} + 1_{(2)} = 10_{(2)} \\ 1_{(2)} + 0_{(2)} = 1_{(2)} \\ 0_{(2)} + 1_{(2)} = 1_{(2)} \\ 0_{(2)} + 0_{(2)} = 0_{(2)} 1(2)+1(2)=10(2)1(2)+0(2)=1(2)0(2)+1(2)=1(2)0(2)+0(2)=0(2)
3、二进制减法
二进制减法采用从低到高的位依次相减,当遇到 0 减 1 的情况,则向高位借位。
- 例如,在二进制中:减法如下: 1 ( 2 ) − 1 ( 2 ) = 0 ( 2 ) 1 ( 2 ) − 0 ( 2 ) = 1 ( 2 ) 1 0 ( 2 ) − 1 ( 2 ) = 1 ( 2 ) 0 ( 2 ) − 0 ( 2 ) = 0 ( 2 ) 1_{(2)} - 1_{(2)} = 0_{(2)} \\ 1_{(2)} - 0_{(2)} = 1_{(2)} \\ 10_{(2)} - 1_{(2)} = 1_{(2)} \\ 0_{(2)} - 0_{(2)} = 0_{(2)} 1(2)−1(2)=0(2)1(2)−0(2)=1(2)10(2)−1(2)=1(2)0(2)−0(2)=0(2)
- 而我们今天要讲的位运算正是基于二进制展开的。
三十七、位运算简介
- 位运算可以理解成对二进制数字上的每一个位进行操作的运算。
- 位运算分为 布尔位运算符 和 移位位运算符。
- 布尔位运算符又分为 位与(&)、位或(|)、异或(^)、按位取反(~);移位位运算符分为 左移(<<) 和 右移(>>)。
- 如图所示:

- 接下来几天,每天都会更新一篇,对每个位运算符的详细解读,并且配有例题。

🙉饭不食,水不饮,题必须刷🙉
还不会C语言,和我一起打卡! 🌞《光天化日学C语言》🌞
LeetCode 太难?上简单题! 🧡《C语言入门100例》🧡
LeetCode 太简单?大神盘他! 🌌《夜深人静写算法》🌌
三十八、位运算概览
- 今天,我们先来对位运算进行一个初步的介绍。后面会对每个运算符的应用做详细介绍,包括刷题的时候如何运用位运算来加速等等。
1、布尔位运算
- 对于布尔位运算,总共有四个,如下表所示:
| C语言运算符表示 | 含义 | 示例 |
|---|---|---|
& | 位与 | x & y |
| | 位或 | x | y |
^ | 异或 | x ^ y |
~ | 按位取反 | x ~ y |
1)位与
- 位与就是对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况,所以组合出来总共 2 2 = 4 2^2 = 4 22=4 种情况。
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |

#include <stdio.h>
int main() {
int a = 0b1010; // (1)
int b = 0b0110; // (2)
printf("%d\n", (a & b) ); // (3)
return 0;
}
-
(
1
)
(1)
(1) 在C语言中,以
0b作为前缀,表示这是一个二进制数。那么a的实际值就是 ( 1010 ) 2 (1010)_2 (1010)2。 -
(
2
)
(2)
(2) 同样的,
b的实际值就是 ( 0110 ) 2 (0110)_2 (0110)2; -
(
3
)
(3)
(3) 那么这里
a & b就是对 ( 1010 ) 2 (1010)_2 (1010)2 和 ( 0110 ) 2 (0110)_2 (0110)2 的每一位做表格中的&运算。 - 所以最后输出结果为:
2
- 因为输出的是十进制数,它的二进制表示为: ( 0010 ) 2 (0010)_2 (0010)2。
- 注意:这里的 前导零 可有可无,作者写上前导零只是为了对齐以及让读者更加清楚位与的运算方式。
2)位或
- 位或的运算结果如下:
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |

- 我们来看以下这段程序:
#include <stdio.h>
int main() {
int a = 0b1010;
int b = 0b0110;
printf("%d\n", (a | b) );
return 0;
}
- 以上程序的输出结果为:
14
- 即二进制下的 ( 1110 ) 2 (1110)_2 (1110)2 。
3)异或
- 异或的运算结果如下:
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |

- 我们来看以下这段程序:
#include <stdio.h>
int main() {
int a = 0b1010;
int b = 0b0110;
printf("%d\n", (a ^ b) );
return 0;
}
- 以上程序的输出结果为:
12
- 即二进制下的 ( 1100 ) 2 (1100)_2 (1100)2 。
4)按位取反
- 按位取反其实就是 0 变 1, 1 变 0。
- 同样,我们来看一段程序。
#include <stdio.h>
int main() {
int a = 0b1;
printf("%d\n", ~a );
return 0;
}
- 这里我想卖个关子,同学们可以自己试一下运行结果。
- 至于为什么会输出这个结果,我会在 光天化日学C语言(17)- 位运算 ~ 的应用 (待更新) 中进行详细讲解,敬请期待。
2、移位位运算
- 对于移位位运算,总共有两个,如下表所示:
| C语言运算符表示 | 含义 | 示例 |
|---|---|---|
<< | 左移 | x << y |
>> | 右移 | x >> y |
1)左移
- 其中
x << y代表将二进制的 x x x 的末尾添加 y y y 个零,就好比向左移动了 y y y 位。 - 比如 ( 1011 ) 2 (1011)_2 (1011)2 左移三位的结果为: ( 1011000 ) 2 (1011000)_2 (1011000)2。
2)右移
- 其中
x >> y代表将二进制的 x x x 从右边开始截掉 y y y 个数,就好比向右移动了 y y y 位。 - 比如 ( 101111 ) 2 (101111)_2 (101111)2 右移三位的结果为: ( 101 ) 2 (101)_2 (101)2。
通过这一章,我们学会了:
1)位与 & ;
2)位或 |
3)异或 ^;
4)按位取反 ~;
5)左移 <<;
6)右移 >>;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第39题】位与 & 的应用 | 一句话消除末尾连续的 1
- 【第40题】位或 | 的应用 (更新中)
三十九、位与运算符
- 位与运算符是一个二元的位运算符,也就是有两个操作数,表示为
x & y。 - 位与运算会对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况,所以组合出来总共 2 2 = 4 2^2 = 4 22=4 种情况。
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
- 通过这个表,我们得出一些结论:
- 1)无论是 0 或 1,只要位与上 1,还是它本身;
- 2)无论是 0 或 1,只要位与上 0,就变成 0;
#include <stdio.h>
int main() {
int a = 0b1010; // (1)
int b = 0b0110; // (2)
printf("%d\n", (a & b) ); // (3)
return 0;
}
-
(
1
)
(1)
(1) 在C语言中,以
0b作为前缀,表示这是一个二进制数。那么a的实际值就是 ( 1010 ) 2 (1010)_2 (1010)2。 -
(
2
)
(2)
(2) 同样的,
b的实际值就是 ( 0110 ) 2 (0110)_2 (0110)2; -
(
3
)
(3)
(3) 那么这里
a & b就是对 ( 1010 ) 2 (1010)_2 (1010)2 和 ( 0110 ) 2 (0110)_2 (0110)2 的每一位做表格中的&运算。 - 所以最后输出结果为:
2
- 因为输出的是十进制数,它的二进制表示为: ( 0010 ) 2 (0010)_2 (0010)2。
- 注意:这里的 前导零 可有可无,作者写上前导零只是为了对齐以及让读者更加清楚位与的运算方式。
四十、位与运算符的应用
1、奇偶性判定
- 我们判断一个数是奇数还是偶数,往往是通过取模
%来判断的,如下:
#include <stdio.h>
int main() {
if(5 % 2 == 1) {
printf("5是奇数\n");
}
if(6 % 2 == 0) {
printf("6是偶数\n");
}
return 0;
}
- 然而,我们也可以这么写:
#include <stdio.h>
int main() {
if(5 & 1) {
printf("5是奇数\n");
}
if( (6 & 1) == 0 ) {
printf("6是偶数\n");
}
return 0;
}
- 哇,好神奇!
- 这是利用了奇数和偶数分别的二进制数的特性,如下表所示:
| - | 二进制末尾位 |
|---|---|
| 奇数 | 1 |
| 偶数 | 0 |
- 所以,我们对任何一个数,通过将它和
0b1进行位与,结果为零,则必然这个数的二进制末尾位为0,根据以上表就能得出它是偶数了;否则,就是奇数。 - 注意,由于
if语句我们还没有实际提到过,所以这里简单提一下,后面会有系统的讲解:
if( expr ) { body }
- 对于以上语句,
expr代表的是一个表达式,表达式的值最后只有 零 或 非零,如果值为非零,才会执行body中的内容。
2、取末五位
【例题1】给定一个数,求它的二进制表示的末五位,以十进制输出即可。

- 这个问题的核心就是:我们只需要末五位,剩下的位我们是不需要的,所以可以将给定的数 位与上
0b11111,这样一来就直接得到末五位的值了。 - 代码实现如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", (x & 0b11111) );
return 0;
}

【例题2】如果是想得到末七位、末九位、末十四位、末 K 位,应该如何实现呢?
3、消除末尾五位
【例题3】给定一个 32 位整数,要求消除它的末五位。
- 还是根据位与的性质,消除末五位的含义,有两层:
- 1)末五位,要全变成零;
- 2)剩下的位不变;
- 那么,根据位运算的性质,我们需要数,它的高27位都为1,低五位都为 0,则这个数就是:
- ( 11111111111111111111111111100000 ) 2 (11111111111111111111111111100000)_2 (11111111111111111111111111100000)2
- 但是如果要这么写,代码不疯掉,人也会疯掉,所以一般我们把它转成十六进制,每四个二进制位可以转成一个十六进制数,所以得到十六进制数为
0xffffffe0。 - 代码实现如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", (x & 0xffffffe0) );
return 0;
}

4、消除末尾连续1

【例题4】给出一个整数,现在要求将这个整数转换成二进制以后,将末尾连续的1都变成0,输出改变后的数(以十进制输出即可)。
- 我们知道,这个数的二进制表示形式一定是:
- . . . 0 11...11 ⏟ k ...0\underbrace{11...11}_{\rm k} ...0k 11...11
- 如果,我们把这个二进制数加上1,得到的就是:
- . . . 1 00...00 ⏟ k ...1\underbrace{00...00}_{\rm k} ...1k 00...00
- 我们把这两个数进行位与运算,得到:
- . . . 0 00...00 ⏟ k ...0\underbrace{00...00}_{\rm k} ...0k 00...00
- 所以,你学会了吗?
通过这一章,我们学会了:
1)用位运算 & 来做奇偶性判定;
2)用位运算 & 获取一个数的末五位,末七位,末K位;
3)用位运算 & 消除某些二进制位;
4)用位运算 & 消除末尾连续 1;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第39题】位与 & 的应用 | 一句话消除末尾连续的 1
四十一、位与运算符
- 位与运算符是一个二元的位运算符,也就是有两个操作数,表示为
x & y。 - 位与运算会对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况,所以组合出来总共 2 2 = 4 2^2 = 4 22=4 种情况。
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
- 通过这个表,我们得出一些结论:
- 1)无论是 0 或 1,只要位与上 1,还是它本身;
- 2)无论是 0 或 1,只要位与上 0,就变成 0;
#include <stdio.h>
int main() {
int a = 0b1010; // (1)
int b = 0b0110; // (2)
printf("%d\n", (a & b) ); // (3)
return 0;
}
-
(
1
)
(1)
(1) 在C语言中,以
0b作为前缀,表示这是一个二进制数。那么a的实际值就是 ( 1010 ) 2 (1010)_2 (1010)2。 -
(
2
)
(2)
(2) 同样的,
b的实际值就是 ( 0110 ) 2 (0110)_2 (0110)2; -
(
3
)
(3)
(3) 那么这里
a & b就是对 ( 1010 ) 2 (1010)_2 (1010)2 和 ( 0110 ) 2 (0110)_2 (0110)2 的每一位做表格中的&运算。 - 所以最后输出结果为:
2
- 因为输出的是十进制数,它的二进制表示为: ( 0010 ) 2 (0010)_2 (0010)2。
- 注意:这里的 前导零 可有可无,作者写上前导零只是为了对齐以及让读者更加清楚位与的运算方式。
四十二、位与运算符的应用
1、奇偶性判定
- 我们判断一个数是奇数还是偶数,往往是通过取模
%来判断的,如下:
#include <stdio.h>
int main() {
if(5 % 2 == 1) {
printf("5是奇数\n");
}
if(6 % 2 == 0) {
printf("6是偶数\n");
}
return 0;
}
- 然而,我们也可以这么写:
#include <stdio.h>
int main() {
if(5 & 1) {
printf("5是奇数\n");
}
if( (6 & 1) == 0 ) {
printf("6是偶数\n");
}
return 0;
}
- 哇,好神奇!
- 这是利用了奇数和偶数分别的二进制数的特性,如下表所示:
| - | 二进制末尾位 |
|---|---|
| 奇数 | 1 |
| 偶数 | 0 |
- 所以,我们对任何一个数,通过将它和
0b1进行位与,结果为零,则必然这个数的二进制末尾位为0,根据以上表就能得出它是偶数了;否则,就是奇数。 - 注意,由于
if语句我们还没有实际提到过,所以这里简单提一下,后面会有系统的讲解:
if( expr ) { body }
- 对于以上语句,
expr代表的是一个表达式,表达式的值最后只有 零 或 非零,如果值为非零,才会执行body中的内容。
2、取末五位
【例题1】给定一个数,求它的二进制表示的末五位,以十进制输出即可。
- 这个问题的核心就是:我们只需要末五位,剩下的位我们是不需要的,所以可以将给定的数 位与上
0b11111,这样一来就直接得到末五位的值了。 - 代码实现如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", (x & 0b11111) );
return 0;
}
【例题2】如果是想得到末七位、末九位、末十四位、末 K 位,应该如何实现呢?
3、消除末尾五位
【例题3】给定一个 32 位整数,要求消除它的末五位。
- 还是根据位与的性质,消除末五位的含义,有两层:
- 1)末五位,要全变成零;
- 2)剩下的位不变;
- 那么,根据位运算的性质,我们需要数,它的高27位都为1,低五位都为 0,则这个数就是:
- ( 11111111111111111111111111100000 ) 2 (11111111111111111111111111100000)_2 (11111111111111111111111111100000)2
- 但是如果要这么写,代码不疯掉,人也会疯掉,所以一般我们把它转成十六进制,每四个二进制位可以转成一个十六进制数,所以得到十六进制数为
0xffffffe0。 - 代码实现如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", (x & 0xffffffe0) );
return 0;
}
4、消除末尾连续1
【例题4】给出一个整数,现在要求将这个整数转换成二进制以后,将末尾连续的1都变成0,输出改变后的数(以十进制输出即可)。
- 我们知道,这个数的二进制表示形式一定是:
- . . . 0 11...11 ⏟ k ...0\underbrace{11...11}_{\rm k} ...0k 11...11
- 如果,我们把这个二进制数加上1,得到的就是:
- . . . 1 00...00 ⏟ k ...1\underbrace{00...00}_{\rm k} ...1k 00...00
- 我们把这两个数进行位与运算,得到:
- . . . 0 00...00 ⏟ k ...0\underbrace{00...00}_{\rm k} ...0k 00...00
- 所以,你学会了吗?
通过这一章,我们学会了:
1)用位运算 & 来做奇偶性判定;
2)用位运算 & 获取一个数的末五位,末七位,末K位;
3)用位运算 & 消除某些二进制位;
4)用位运算 & 消除末尾连续 1;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第39题】位与 & 的应用 | 一句话消除末尾连续的 1
- 目前这个系列还在更新中……,更多教程尽请关注:《光天化日学C语言》。
四十三、位或运算符
- 位或运算符是一个二元的位运算符,也就是有两个操作数,表示为
x | y。 - 位或运算会对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况,所以组合出来总共 2 2 = 4 2^2 = 4 22=4 种情况。
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
- 通过这个表,我们得出一些结论:
- 1)无论是 0 或 1,只要位或上 1,就变成1;
- 2)只有当两个操作数都是0的时候,才变成 0;
#include <stdio.h>
int main() {
int a = 0b1010; // (1)
int b = 0b0110; // (2)
printf("%d\n", (a | b) ); // (3)
return 0;
}
-
(
1
)
(1)
(1) 在C语言中,以
0b作为前缀,表示这是一个二进制数。那么a的实际值就是 ( 1010 ) 2 (1010)_2 (1010)2。 -
(
2
)
(2)
(2) 同样的,
b的实际值就是 ( 0110 ) 2 (0110)_2 (0110)2; -
(
3
)
(3)
(3) 那么这里
a | b就是对 ( 1010 ) 2 (1010)_2 (1010)2 和 ( 0110 ) 2 (0110)_2 (0110)2 的每一位做表格中的|运算。 - 所以最后输出结果为:
14
- 因为输出的是十进制数,它的二进制表示为: ( 1110 ) 2 (1110)_2 (1110)2。
四十四、位或运算符的应用
1、设置标记位
【例题1】给定一个数,判断它二进制低位的第 5 位,如果为 0,则将它置为 1。
- 这个问题,我们很容易联想到位或。
- 我们分析一下题目意思,如果第 5 位为 1,不用进行任何操作;如果第 5 位为 0,则置为 1。言下之意,无论第五位是什么,我们都直接置为 1即可,代码如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", x | 0b10000);
return 0;
}
2、置空标记位
【例题2】给定一个数,判断它二进制低位的第 5 位,如果为 1,则将它置为 0。
- 这个问题,我们在学过 光天化日学C语言(14)- 位运算 & 的应用 以后,很容易得出这样一种做法:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", x & 0b11111111111111111111111111101111);
return 0;
}
- 其它位不能变,所以位与上1;第5位要置零,所以位与上0;
- 这样写有个问题,就是这串数字太长了,一点都不美观,而且容易写错,当然我们也可以转换成 十六进制,转换的过程也有可能出错。
- 而我们利用位或,只能将第5位设置成1,怎么把它设置成0呢?

我们可以配合减法来用。分成以下两步:
1)首先,强行将低位的第5位置成1;
2)然后,强行将低位的第5位去掉;
- 第 ( 1 ) (1) (1) 步可以采用位或运算,而第 ( 2 ) (2) (2) 步,我们可以直接用减法即可。
- 代码实现如下:
#include <stdio.h>
int main() {
int x;
int a = 0b10000;
scanf("%d", &x);
printf("%d\n", (x | a) - a );
return 0;
}
- 注意:直接减是不行的,因为我们首先要保证那一位为 1,否则贸然减会产生借位,和题意不符。
3、低位连续零变一
【例题3】给定一个整数 x x x,将它低位连续的 0 都变成 1。
- 假设这个整数低位连续有 k k k 个零,二进制表示如下:
- . . . 1 00...00 ⏟ k ...1\underbrace{00...00}_{\rm k} ...1k 00...00
- 那么,如果我们对它进行减一操作,得到的二进制数就是:
- . . . 0 11...11 ⏟ k ...0\underbrace{11...11}_{\rm k} ...0k 11...11
- 我们发现,只要对这两个数进行位或,就能得到:
- . . . 1 11...11 ⏟ k ...1\underbrace{11...11}_{\rm k} ...1k 11...11
- 也正是题目所求,所以代码实现如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", x | (x-1) ); // (1)
return 0;
}
-
(
1
)
(1)
(1)
x | (x-1)就是题目所求的 “低位连续零变一” 。
4、低位首零变一

【例题4】给定一个整数 x x x,将它低位第一个 0 变成 1。
- 记得在评论区留下你的答案哦 ~
通过这一章,我们学会了:
1)用位运算 | 来做标记位的设置;
2)用位运算 | 来做标记位的清除;
3)用位运算 | 将低位连续的零变成一;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第40题】位或 | 的应用 | 低位首零变一
四十五、异或运算符
- 异或运算符是一个二元的位运算符,也就是有两个操作数,表示为
x ^ y。 - 异或运算会对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况,所以组合出来总共 2 2 = 4 2^2 = 4 22=4 种情况。
| 左操作数 | 右操作数 | 结果 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
- 通过这个表,我们得出一些结论:
- 1)两个相同的十进制数异或的结果一定为零。
- 2)任何一个数和 0 的异或结果一定是它本身。
- 3)异或运算满足结合律和交换律。

#include <stdio.h>
int main() {
int a = 0b1010; // (1)
int b = 0b0110; // (2)
printf("%d\n", (a ^ b) ); // (3)
return 0;
}
-
(
1
)
(1)
(1) 在C语言中,以
0b作为前缀,表示这是一个二进制数。那么a的实际值就是 ( 1010 ) 2 (1010)_2 (1010)2。 -
(
2
)
(2)
(2) 同样的,
b的实际值就是 ( 0110 ) 2 (0110)_2 (0110)2; -
(
3
)
(3)
(3) 那么这里
a ^ b就是对 ( 1010 ) 2 (1010)_2 (1010)2 和 ( 0110 ) 2 (0110)_2 (0110)2 的每一位做表格中的^运算。 - 所以最后输出结果为:
12
- 因为输出的是十进制数,它的二进制表示为: ( 1100 ) 2 (1100)_2 (1100)2。
四十六、异或运算符的应用
1、标记位取反
【例题1】给定一个数,将它的低位数起的第 4 位取反,0 变 1,1 变 0。
- 这个问题,我们很容易联想到异或。
- 我们分析一下题目意思,如果第 4 位为 1,则让它异或上
0b1000就能变成 0;如果第 4 位 为 0,则让它异或上0b1000就能变成 1,也就是无论如何都是异或上0b1000,代码如下:
#include <stdio.h>
int main() {
int x;
scanf("%d", &x);
printf("%d\n", x ^ 0b1000);
return 0;
}
2、变量交换
【例题2】给定两个数 a a a 和 b b b,用异或运算交换它们的值。
- 这个是比较老的面试题了,直接给出代码:
#include <stdio.h>
int main() {
int a, b;
while (scanf("%d %d", &a, &b) != EOF) {
a = a ^ b; // (1)
b = a ^ b; // (2)
a = a ^ b; // (3)
printf("%d %d\n", a, b);
}
return 0;
}
- 我们直接来看
(
1
)
(1)
(1) 和
(
2
)
(2)
(2) 这两句话,相当于
b等于a ^ b ^ b,根据异或的几个性质,我们知道,这时候的b的值已经变成原先a的值了。 - 而再来看第
(
3
)
(3)
(3) 句话,相当于
a等于a ^ b ^ a,还是根据异或的几个性质,这时候,a的值已经变成了原先b的值。 - 从而实现了变量
a和b的交换。
3、出现奇数次的数
【例题3】输入 n n n 个数,其中只有一个数出现了奇数次,其它所有数都出现了偶数次。求这个出现了奇数次的数。
- 根据异或的性质,两个一样的数异或结果为零。也就是所有出现偶数次的数异或都为零,那么把这 n n n 个数都异或一下,得到的数就一定是一个出现奇数次的数了。
#include <stdio.h>
int main() {
int n, x, i, ans;
scanf("%d", &n);
ans = 0;
for(i = 0; i < n; ++i) {
scanf("%d", &x);
ans = (ans ^ x);
}
printf("%d\n", ans);
return 0;
}
4、丢失的数
【例题4】给定一个 n − 1 n-1 n−1 个数,分别代表 1 到 n n n 的其中 n − 1 n-1 n−1 个,求丢失的那个数。
- 记得在评论区留下你的答案哦 ~
5、简单加密
- 基于 两个数异或为零,任何数和零异或为其本身 这两个特点,异或还可以用来做简单的加密。
- 将明文异或上一个固定的数变成密文以后,可以通过继续异或上这个数,再将密文转变成明文。
通过这一章,我们学会了:
1)用位运算 ^ 来做标记位的取反;
2)用位运算 ^ 来做变量交换;
3)用位运算 ^ 找出出现奇数次的数;
4)用位运算 ^ 的加密解密;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第41题】异或 ^ 的应用 | 丢失的那个数
四十七、取反运算符
- 取反运算符是一个单目位运算符,也就是只有一个操作数,表示为
~x。 - 取反运算会对操作数的每一位按照如下表格进行运算,对于每一位只有 0 或 1 两种情况。
| 操作数 | 取反结果 |
|---|---|
| 0 | 1 |
| 1 | 0 |
#include <stdio.h>
int main() {
int a = 0b1;
printf("%d\n", ~a );
return 0;
}
- 这里
~a代表的是对二进制数 1 进行取反,直观感受应该是 0。 - 但是实际输出的却是:
-2
- 这是为什么呢?
- 那是因为,这是一个 32 位整数,实际的取反操作是这样的:
~ 00000000 00000000 00000000 00000001
--------------------------------------
11111111 11111111 11111111 11111110
- 32位整数的二进制表示,前导零也要参与取反。
- 而对于一个有符号的 32 位整数,我们需要用最高位来代表符号位,即最高位为 0,则代表正数;最高位为 1,则代表负数;
- 这时候我们就需要引入补码的概念了。
1、补码
- 在计算机中,二进制编码是采用补码的形式表示的,补码定义如下:
正数的补码是它本身,符号位为 0;负数的补码为正数数值二进制位取反后加一,符号位为一;
2、补码举例
- 根据补码的定义,
-2的补码计算,需要经过两步: - 1)对 2 的二进制进行按位取反,如下:
~ 00000000 00000000 00000000 00000010
--------------------------------------
11111111 11111111 11111111 11111101
- 2)然后加上 1,如下:
11111111 11111111 11111111 11111101
+ 00000000 00000000 00000000 00000001
--------------------------------------
11111111 11111111 11111111 11111110
- 结果正好为我们开始提到的
~1的结果。
3、补码的真实含义
- 补码的真实含义,其实体现在 “补” 这个字上,在数学上,两个互为相反数的数字相加等于 0,而在计算机中,两个互为相反数的数字相加等于 2 n 2^n 2n。
- 换言之,互为相反数的两个数互补,补成 2 n 2^n 2n。
- 对于 32位整型, n = 32 n = 32 n=32;对于 64位整型, n = 64 n = 64 n=64。所以补码也可以表示成如下形式:
- [ x ] 补 = { x ( 0 ≤ x < 2 n − 1 ) 2 n + x ( − 2 n − 1 ≤ x < 0 ) [x]_补 = \begin{cases}x & (0 \le x \lt 2^{n-1})\\ 2^{n} + x & (-2^{n-1} \le x \lt 0)\\ \end{cases} [x]补={x2n+x(0≤x<2n−1)(−2n−1≤x<0)
- 于是,对于
int类型,就有: - x + ( − x ) = 2 32 x + (-x) = 2^{32} x+(−x)=232
- 因此, − 2 = 2 32 − 2 -2 = 2^{32} - 2 −2=232−2。
- 于是,我们开始数数……
2^32 = 1 00000000 00000000 00000000 00000000
2^32 - 1 = 11111111 11111111 11111111 11111111
2^32 - 2 = 11111111 11111111 11111111 11111110
...
- 近一步了解了
-2的二进制表示。 - 关于补码的深入内容,详细可以参考这篇文章:《C/C++ 面试 100 例》(九)补码全网最全总结。
四十八、取反运算符的应用
1、0 的取反
【例题1】0 的取反结果为多少呢?
- 首先对源码进行取反,得到:
~ 00000000 00000000 00000000 00000000
--------------------------------------
11111111 11111111 11111111 11111111
- 这个问题,我们刚讨论完,这个答案为
2
32
−
1
2^{32}-1
232−1。但是实际输出时,你会发现,它的值是
-1。 - 这是为什么?
- 搞得我一头雾水。
- 原因是因为在C语言中有两种类型的
int,分别为unsigned int和signed int,我们之前讨论的int都是signed int的简称。
1)有符号整型
- 对于有符号整型
signed int而言,最高位表示符号位,所以只有31位能表示数值,能够表示的数值范围是: − 2 31 ≤ x ≤ 2 31 − 1 -2^{31} \le x \le 2^{31}-1 −231≤x≤231−1 - 所以,对于有符号整型,输出采用
%d,如下:
#include <stdio.h>
int main() {
printf("%d\n", ~0 );
return 0;
}
- 结果为:
-1
2)无符号整型
- 对于无符号整型
unsigned int而言,由于不需要符号位,所以总共有32位表示数值,数值范围为: - 0 ≤ x ≤ 2 32 − 1 0 \le x \le 2^{32}-1 0≤x≤232−1
- 对于无符号整型,输出采用
%u,如下:
#include <stdio.h>
int main() {
printf("%u\n", ~0 );
return 0;
}
- 结果为:
4294967295
- 即 2 32 − 1 2^{32}-1 232−1。
2、相反数
【例题2】给定一个
int类型的正数 x x x,求 x x x 的相反数(注意:不能用负号)。
- 这里,我们可以直接利用补码的定义,对于正数
x
x
x,它的相反数的补码就是
x
x
x 二进制取反加一。即:
~x + 1。
#include <stdio.h>
int main() {
int x = 18;
printf("%d\n", ~x + 1 );
return 0;
}
- 运行结果如下:
-18
3、代替减法
【例题3】给定两个
int类型的正数 x x x 和 y y y,实现 x − y x - y x−y(注意:不能用减号)。
- 这个问题比较简单,如果上面的相反数已经理解了,那么,
x - y其实就可以表示成x + (-y),而-y又可以表示成~y + 1,所以减法x - y就可以用x + ~y + 1来代替。 - 代码实现如下:
#include <stdio.h>
int main() {
int a = 8;
int b = 17;
printf("%d\n", a + ~b + 1 );
return 0;
}
- 运行结果为:
-9
4、代替加法
【例题4】给定两个
int类型的正数 x x x 和 y y y,实现 x + y x + y x+y(注意:不能用加号)。
- 我们可以把
x + y变成x - (-y),而-y又可以替换成~y + 1; - 所以
x + y就变成了x - ~y - 1,不用加号实现了加法运算。
#include <stdio.h>
int main() {
int x = 18;
int y = 7;
printf("%d\n", x - ~y - 1 );
return 0;
}
- 运行结果为:
25
通过这一章,我们学会了:
1)按位取反运算符;
2)补码的运算;
3)有符号整型和无符号整型;
4)相反数、加法、减法、等于判定的另类解法;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第42题】按位取反~的应用 | 相反数
四十九、左移运算符
1、左移的二进制形态
- 左移运算符是一个二元的位运算符,也就是有两个操作数,表示为
x << y。其中x和y均为整数。 x << y念作:“将 x x x 左移 y y y 位”,这里的位当然就是二进制位了,那么它表示的意思也就是:先将 x x x 用二进制表示,然后再左移 y y y 位,并且在尾部添上 y y y 个零。- 举个例子:对于二进制数
2
3
10
=
(
10111
)
2
23_{10} = (10111)_2
2310=(10111)2 左移
y
y
y 位的结果就是:
( 10111 0...0 ⏟ y ) 2 (10111\underbrace{0...0}_{\rm y})_2 (10111y 0...0)2
2、左移的执行结果
x << y的执行结果等价于:- x × 2 y x \times 2^y x×2y
- 如下代码:
#include <stdio.h>
int main() {
int x = 3;
int y = 5;
printf("%d\n", x << y);
return 0;
}
- 输出结果为:
96
- 正好符合这个左移运算符的实际含义:
- 96 = 3 × 2 5 96 = 3 \times 2^5 96=3×25
最常用的就是当 x = 1 x = 1 x=1 时,
1 << y代表的就是 2 y 2^y 2y,即 2 的幂。
3、负数左移的执行结果
- 所谓负数左移,就是
x << y中,当x为负数的情况,代码如下:
#include <stdio.h>
int main() {
printf("%d\n", -1 << 1);
return 0;
}
- 它的输出如下:
-2
- 我们发现同样是满足
x
×
2
y
x \times 2^y
x×2y 的,这个可以用补码来解释,
-1的补码为: - 11111111 11111111 11111111 11111111 11111111 \ 11111111 \ 11111111 \ 11111111 11111111 11111111 11111111 11111111
- 左移一位后,最高位的 1 就没了,低位补上 0,得到:
- 11111111 11111111 11111111 11111110 11111111 \ 11111111 \ 11111111 \ 11111110 11111111 11111111 11111111 11111110
- 而这,正好是
-2的补码,同样,继续左移 1 位,得到: - 11111111 11111111 11111111 11111100 11111111 \ 11111111 \ 11111111 \ 11111100 11111111 11111111 11111111 11111100
- 这是
-4的补码,以此类推,所以负整数的左移结果同样也是 x × 2 y x \times 2^y x×2y。
可以理解成
- (x << y)和(-x) << y是等价的。
4、左移负数位是什么情况
- 刚才我们讨论了 x < 0 x < 0 x<0 的情况,那么接下来,我们试下 y < 0 y < 0 y<0 的情况会是如何?
- 是否同样满足: x × 2 y x \times 2^y x×2y 呢?
- 如果还是满足,那么两个整数的左移就有可能产生小数了。
- 看个例子:
#include <stdio.h>
int main() {
printf("%d\n", 32 << -1); // 16
printf("%d\n", 32 << -2); // 8
printf("%d\n", 32 << -3); // 4
printf("%d\n", 32 << -4); // 2
printf("%d\n", 32 << -5); // 1
printf("%d\n", 32 << -6); // 0
printf("%d\n", 32 << -7); // 0
return 0;
}
- 虽然能够正常运行,但是结果好像不是我们期望的,而且会报警告如下:
[Warning] left shift count is negative [-Wshift-count-negative]
- 实际上,编辑器告诉我们尽量不用左移的时候用负数,但是它的执行结果不能算错误,起码例子里面对了,结果不会出现小数,而是取整了。
- 左移负数位其实效果和右移对应正数数值位一致,右移相关的内容,我们会在 光天化日学C语言(19)- 位运算 >> 的应用 中讲到。
5、左移时溢出会如何
- 我们知道,
int类型的数都是 32 位的,最高位代表符号位,那么假设最高位为 1,次高位为 0,左移以后,符号位会变成 0,会产生什么问题呢? - 举个例子,对于 − 2 31 + 1 -2^{31}+1 −231+1 的二进制表示为:最高位和最低位为1,其余为零。
#include <stdio.h>
int main() {
int x = 0b10000000000000000000000000000001;
printf("%d\n", x); // -2147483647
return 0;
}
- 输出结果为:
-2147483647
- 那么,将它进行左移一位以后,得到的结果是什么呢?
#include <stdio.h>
int main() {
int x = 0b10000000000000000000000000000001;
printf("%d\n", x << 1);
return 0;
}

- 我们盲猜一下,最高位的 1 被移出去,最低位补上 0,结果应该是
0b10。 - 实际输出的结果,的确是:
2
- 但是如果按照 x × 2 y x \times 2^y x×2y 答案应该是 ( − 2 31 + 1 ) × 2 = − 2 32 + 2 (-2^{31}+1) \times 2 = -2^{32}+2 (−231+1)×2=−232+2
- 这里又回到了补码的问题上,事实上,在计算机中,
int整型其实是一个环,溢出以后又会回来,而环的长度正好是 2 32 2^{32} 232,所以 − 2 32 + 2 = 2 -2^{32}+2 = 2 −232+2=2,这个就有点像同余的概念,这两个数是模 2 32 2^{32} 232 同余的。更多关于同余的知识,可以参考我的算法系列文章:夜深人静写算法(三)- 初等数论入门(学生党记得找我开试读)。
五十、左移运算符的应用
1、取模转化成位运算
- 对于 x x x 模上一个 2 的次幂的数 y y y,我们可以转换成位与上 2 y − 1 2^y-1 2y−1。
- 即在数学上的:
- x m o d 2 y x \ mod \ 2^y x mod 2y
- 在计算机中就可以用一行代码表示:
x & ((1 << y) - 1)。
2、生成标记码
我们可以用左移运算符来实现标记码,即
1 << k作为第 k k k 个标记位的标记码,这样就可以通过一句话,实现对标记位置 0、置 1、取反等操作。
1)标记位置1
【例题1】对于 x x x 这个数,我们希望对它二进制位的第 k k k 位(从0开始,从低到高数)置为 1。
- 置 1 操作,让我们联想到了 位或 运算。
- 它的特点是:位或上 1,结果为 1;位或上0,结果不变。
- 所以我们对标记码的要求是:第
k
k
k 位为 1,其它位为 0,正好是
(1 << k),那么将 第 k k k 位 置为 1 的语句可以写成:x | (1 << k)。 - 有关位或运算的更多内容,可以参考:光天化日学C语言(15)- 位运算 | 的应用。
2)标记位置0
【例题2】对于 x x x 这个数,我们希望对它二进制位的第 k k k 位(从0开始,从低到高数)置为 0。
- 置 0 操作,让我们联想到了 位与 运算。
- 它的特点是:位与上 0,结果为 0;位与上 1,结果不变。
- 所以在我们对标记码的要求是:第
k
k
k 位为 0,其它位为 1,我们需要的是
(~(1 << k)),那么将 第 k k k 位 置为 0 的语句可以写成:x & (~(1 << k))。 - 有关位与运算的更多内容,可以参考:光天化日学C语言(14)- 位运算 & 的应用。
- 有关 按位取反 运算的更多内容,可以参考:光天化日学C语言(17)- 位运算 ~ 的应用。
3)标记位取反
【例题3】对于 x x x 这个数,我们希望对它二进制位的第 k k k 位(从0开始,从低到高数)取反。
- 取反操作,联想到的是 异或 运算。
- 它的特点是:异或上 1,结果取反;异或上 0,结果不变。
- 所以我们对标记码的要求是:第
k
k
k 位为1,其余位为 0,其值为
(1 << k)。那么将 第 k k k 位 取反的语句可以写成:x ^ (1 << k)。 - 有关 异或 运算的更多内容,可以参考:光天化日学C语言(16)- 位运算 ^ 的应用。
3、生成掩码
- 同样,我们可以用左移来生成一个掩码,完成对某个数的二进制末 k k k 位执行一些操作。
- 对于
(1 << k)的二进制表示为:1 加上 k 个 0,那么(1 << k) - 1的二进制则代表 k k k 个 1。 - 把末尾的
k
k
k 位都变成 1,可以写成:
x | ((1 << k) - 1)。 - 把末尾的
k
k
k 为都变成 0,可以写成:
x & ~((1 << k) - 1)。 - 把末尾的
k
k
k 位都取反,可以写成:
x ^ ((1 << k) - 1)。
通过这一章,我们学会了:
1)位运算 << 的用法;
2)用 << 来生成标记位;
3)用 << 来生成掩码;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第43题】左移的应用 | 一句话判断一个数是否是 2 的幂
五十一、右移运算符
1、右移的二进制形态
- 右移运算符是一个二元的位运算符,也就是有两个操作数,表示为
x >> y。其中x和y均为整数。 x >> y念作:“将 x x x 右移 y y y 位”,这里的位当然就是二进制位了,那么它表示的意思也就是:先将 x x x 用二进制表示,对于正数,右移 y y y 位;对于负数,右移 y y y 位后高位都补上 1。- 举个例子:对于二进制数
8
7
10
=
(
1010111
)
2
87_{10} = (1010111)_2
8710=(1010111)2 左移
y
y
y 位的结果就是:
( 1010 ) 2 (1010)_2 (1010)2
2、右移的执行结果
x >> y的执行结果等价于:- ⌊ x 2 y ⌋ \lfloor \frac x {2^y} \rfloor ⌊2yx⌋
- 其中 ⌊ a ⌋ \lfloor a\rfloor ⌊a⌋ 代表对 a a a 取下整。
- 如下代码:
#include <stdio.h>
int main() {
int x = 0b1010111;
int y = 3;
printf("%d\n", x >> y);
return 0;
}
- 输出结果为:
10
- 正好符合这个右移运算符的实际含义:
- 10 = ⌊ 87 2 3 ⌋ 10 = \lfloor \frac {87} {2^3} \rfloor 10=⌊2387⌋
由于除法可能造成不能整除,所以才会有 取下整 这一步运算。
3、负数右移的执行结果
- 所谓负数右移,就是
x >> y中,当x为负数的情况,代码如下:
#include <stdio.h>
int main() {
printf("%d\n", -1 >> 1);
return 0;
}
- 它的输出如下:
-1
- 我们发现同样是满足
⌊
x
2
y
⌋
\lfloor \frac x {2^y} \rfloor
⌊2yx⌋ 的(注意,负数的 取下整 和 正数 是正好相反的),这个可以用补码来解释,
-1的补码为: - 11111111 11111111 11111111 11111111 11111111 \ 11111111 \ 11111111 \ 11111111 11111111 11111111 11111111 11111111
- 右移一位后,由于是负数,高位补上 1,得到:
- 11111111 11111111 11111111 11111111 11111111 \ 11111111 \ 11111111 \ 11111111 11111111 11111111 11111111 11111111
- 而这,正好是
-1的补码,同样,继续右移 1 位,得到:
可以理解成
- (x >> y)和(-x) >> y是等价的。

【例题1】要求不运行代码,肉眼看出这段代码输出多少。
#include <stdio.h>
int main() {
int x = (1 << 31) | (1 << 30) | 1;
int y = (1 << 31) | (1 << 30) | (1 << 29);
printf("%d\n", (x >> 1) / y);
return 0;
}
4、右移负数位是什么情况
- 刚才我们讨论了 x < 0 x < 0 x<0 的情况,那么接下来,我们试下 y < 0 y < 0 y<0 的情况会是如何?
- 是否同样满足: ⌊ x 2 y ⌋ \lfloor \frac x {2^y} \rfloor ⌊2yx⌋ 呢?
- 如果还是满足,那么两个整数的左移就有可能产生小数了。
- 看个例子:
#include <stdio.h>
int main() {
printf("%d\n", 1 >> -1); // 2
printf("%d\n", 1 >> -2); // 4
printf("%d\n", 1 >> -3); // 8
printf("%d\n", 1 >> -4); // 16
printf("%d\n", 1 >> -5); // 32
printf("%d\n", 1 >> -6); // 64
printf("%d\n", 1 >> -7); // 128
return 0;
}
- 虽然能够正常运行,但是结果好像不是我们期望的,而且会报警告如下:
[Warning] right shift count is negative [-Wshift-count-negative]
- 实际上,编辑器告诉我们尽量不用右移的时候用负数,但是它的执行结果不能算错误,起码例子里面对了。
- 右移负数位其实效果和左移对应正数数值位一致。
- 左移相关的内容,可以参考:光天化日学C语言(18)- 位运算 << 的应用。
五十二、右移运算符的应用
1、去掉低 k 位
【例题2】给定一个数 x x x,去掉它的低 k k k 位以后进行输出。
- 这个问题,可以直接通过右移来完成,如下:
x >> k。
2、取低位连续 1
【例题3】获取一个数 x x x 低位连续的 1 并且输出。
- 对于一个数 x x x,假设低位有连续 k k k 个 1。如下:
- ( . . . 0 1...1 ⏟ k ) 2 (...0\underbrace{1...1}_{\rm k})_2 (...0k 1...1)2
- 然后我们将它加上 1 以后,得到的就是:
- ( . . . 1 0...0 ⏟ k ) 2 (...1\underbrace{0...0}_{\rm k})_2 (...1k 0...0)2
- 这时候将这两个数异或结果为:
- ( 1...1 ⏟ k + 1 ) 2 (\underbrace{1...1}_{\rm {k+1}})_2 (k+1 1...1)2
- 这时候,再进行右移一位,就得到了 连续 k k k 个 1 的值,也正是我们所求。
- 所以可以用以下语句来求:
(x ^ (x + 1)) >> 1。
3、取第k位的值
【例题4】获取一个数 x x x 的第 k ( 0 ≤ k ≤ 30 ) k(0 \le k \le 30) k(0≤k≤30) 位的值并且输出。
- 对于二进制数来说,第 k k k 位的值一定是 0 或者 1。
- 而 对于 1 到
k
−
1
k-1
k−1 位的数字,对于我们来说是没有意义的,我们可以用右移来去掉,再用位与运算符来获取二进制的最后一位是 0 还是 1,如下:
(x >> k) & 1。
通过这一章,我们学会了:
1)位运算 >> 的用法;
2)用 >> 来取低位连续 1;
3)用 >> 取第 k k k 位的值;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第44题】右移的应用 | (更新中)
五十三、赋值运算符概览
1、赋值运算符
- 今天我们来讲一下赋值运算符。
- 对于赋值运算符,主要分为两类:简单赋值运算符 和 复合赋值运算符。如下图所示:

- 简单赋值运算符,我们之前在讲 光天化日学C语言(03)- 变量 的时候就已经遇到了,它的表示形式如下: 变 量 = 常 量 变 量 = 表 达 式 \begin{aligned}变量 &= 常量 \\ 变量 &= 表达式\end{aligned} 变量变量=常量=表达式
- 即将赋值符号
=右边的操作数的值赋值给左边的操作数。
2、赋值表达式
- 类似这样的表达式,我们称之为 赋值表达式。
- 例如:
a = 10189;
a = a + 5;
- 任何表达式都是有值的,赋值表达式也不例外,它的值就是
=右边的值。 - 试想一下这段代码的输出是多少?
#include <stdio.h>
int main() {
int a = 5;
int b = (a = 5);
printf("%d\n", b);
return 0;
}

- 运行结果为:
5
- 原因就是因为表达式
a = 5的值为5,从而等价于b = 5。
3、赋值运算的自动类型转换
- 赋值运算符会进行自动类型转换,转换类型就是左边操作数的类型。
#include <stdio.h>
int main() {
int a = 0;
a = a + 1.5;
printf("%d\n", a);
return 0;
}
- 输出的结果为:
1
- 有关类型转换的内容,可以参考 光天化日学C语言(12)- 类型转换。
4、连续赋值
- 我们来看一个例子,如下:
#include <stdio.h>
int main() {
int a, b, c, d = 0;
a = b = c = d = d == 0;
printf("%d\n", a);
return 0;
}
- 这段代码的运行结果为:
1
- 为什么呢?
- 它其实等价于:
#include <stdio.h>
int main() {
int a, b, c, d = 0;
a = ( b = (c = ( d = (d == 0) ) ) );
printf("%d\n", a);
return 0;
}
- 这里涉及到两个概念:运算符优先级、运算符结合性。
- 具体的内容,我们会在后续内容中详细讲解。现在你只需要知道 赋值运算符
=的优先级低于关系运算符==,所以d = d == 0等价于d = (d == 0);而赋值运算符=的结合性是从右到左,所以a = b = c等价于a = (b = c)。
五十四、复合赋值运算符
- 首先来看一个赋值语句,如下:
int love;
love = love + 1314;
- 像这种表达式左边的变量重复出现在表达式的右边,则可以缩写成:
int love;
love += 1314;
- 而这里的
+=就是复合赋值运算符,类似的复合赋值运算符还有很多,总共分为两大类:算术赋值运算符、位赋值运算符。
1、算术赋值运算符
- 算术运算符我们之前已经了解过了,具体可以参考这篇文章:光天化日学C语言(09)- 算术运算符。
- 而算术赋值运算符就是先进行算术运算,再进行赋值。算术赋值运算符的表格如下:
| 运算符 | 简称 | 描述 | 举例 |
|---|---|---|---|
+= | 加且赋值运算符 | 将 右边操作数 加上 左边操作数 的结果赋值给 左边操作数 | a += b等价于a = a + b |
-= | 减且赋值运算符 | 将 左边操作数 减去 右边操作数 的结果赋值给 左边操作数 | a -= b等价于a = a - b |
*= | 乘且赋值运算符 | 将 右边操作数 乘以 左边操作数 的结果赋值给 左边操作数 | a *= b等价于a = a * b |
/= | 除且赋值运算符 | 将 左边操作数 除以 右边操作数 的结果赋值给 左边操作数 | a /= b等价于a = a / b |
%= | 求模且赋值运算符 | 求 两个操作数的模,并将结果赋值给 左边操作数 | a %= b等价于a = a % b |
2、位赋值运算符
- 位运算符我们之前已经了解过了,具体可以参考这篇文章:光天化日学C语言(13)- 位运算概览。
- 而位赋值运算符就是先进行位运算,再进行赋值。位赋值运算符的表格如下:
| 运算符 | 简称 | 描述 | 举例 |
|---|---|---|---|
&= | 按位与且赋值运算符 | 将 左边操作数 按位与上 右边操作数 的结果赋值给 左边操作数 | a &= b等同于a = a & b |
|= | 按位或且赋值运算符 | 将 左边操作数 按位或上 右边操作数 的结果赋值给 左边操作数 | a |= b等同于a = a | b |
^= | 按位异或且赋值运算符 | 将 左边操作数 按位异或上 右边操作数 的结果赋值给 左边操作数 | a ^= b等同于a = a ^ b |
<<= | 左移且赋值运算符 | 将 左边操作数 左移 右边操作数 的位数后的结果赋值给 左边操作数 | a <<= b等同于a = a << b |
>>= | 右移且赋值运算符 | 将 左边操作数 右移 右边操作数 的位数后的结果赋值给 左边操作数 | a >>= b等同于a = a >> b |
五十五、复合赋值表达式
- 对于两个表达式 e 1 e_1 e1 和 e 2 e_2 e2,有复合赋值表达式:
- e 1 o p = e 2 e_1 \ _{op=} \ e_2 e1 op= e2
- 等价于:
- e 1 = ( e 1 ) o p ( e 2 ) e_1 = (e_1) \ _{op} \ (e_2) e1=(e1) op (e2)
- 其中 o p op op 就是上文提到的那 10 个 复合赋值运算符。
这样写的好处有三个:
1)前一种形式, e 1 e_1 e1 只计算一次;第二种形式要计算两次。
2)前一种形式,不需要加上圆括号;第二种形式的圆括号不可少。
3)看起来简洁清晰;
- 举个极端的例子:
a.b.c.d.e.f[ 1024 + g.h.i.j.k.l ] = a.b.c.d.e.f[ 1024 + g.h.i.j.k.l ] + 5炸裂的🤣🤣🤣!!! - 利用复合赋值表达式,我们就可以写成:
a.b.c.d.e.f[ 1024 + g.h.i.j.k.l ] += 5(当然,这个例子比较极端,实际编码中千万不要写出这样的代码哦)。
通过这一章,我们学会了:
1)赋值运算符;
2)赋值表达式;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第15题】给定一个整数,对它进行逆序输出 | 完美的栈思想
🙉饭不食,水不饮,题必须刷🙉
还不会C语言,和我一起打卡! 🌞《光天化日学C语言》🌞
LeetCode 太难?上简单题! 🧡《C语言入门100例》🧡
LeetCode 太简单?大神盘他! 🌌《夜深人静写算法》🌌
五十六、逗号运算符
- 今天,我们就来看下逗号运算符和逗号表达式吧。
- 在 C语言 中,可以把多个表达式用逗号连接起来,构成一个更大的表达式。其中的逗号称为 逗号运算符,所构成的表达式称为 逗号表达式。逗号表达式中用逗号分开的表达式分别求值,以最后一个表达式的值作为整个表达式的值。
简单来说,逗号表达式遵循两点原则:
1)以逗号分隔的表达式单独计算;
2)逗号表达式的值为最后一个表达式的值;
四、逗号运算符的应用
1、连续变量定义
- 逗号运算通常用于变量的连续定义,如下:
#include <stdio.h>
int main() {
int a = 1, b = 2, c = 3, d = 1 << 6, e;
printf("%d\n", a + b + c + d);
return 0;
}
- 这里的
int a = 1, b = 2, c = 3, d = 1 << 6, e就是逗号表达式。
2、循环语句赋初值
- 逗号运算通常用于
for结构的括号内的第一个表达式,用于给多个局部变量赋值。 - 一段对
1到10的数求立方和的代码,如下:
#include <stdio.h>
int main() {
int i, s;
for(i = 1, s = 0; i <= 10; ++i) {
s += i*i*i;
}
printf("%d\n", s);
return 0;
}
- 这里的
i = 1, s = 0就是逗号表达式。 - 有关于
for的内容,会在后面的章节来介绍,暂时只需要知道可以使用逗号表达式来对一些变量赋予初值。
3、交换变量
- 我们在实现交换变量的时候,往往需要三句话:
int tmp;
tmp = a;
a = b;
b = tmp;
- 有了逗号表达式,我们就可以这么写:
int tmp;
tmp = a, a = b, b = tmp;

五十七、逗号运算符注意事项
- 需要注意的是,逗号运算符的优先级非常低,甚至比赋值运算符还要低,所以当它和赋值运算符相遇时,是优先计算赋值运算的,如下代码所示:
#include <stdio.h>
int main() {
int x, y, a, b;
a = (1, x = 2, y = 3);
b = 1, x = 9, y = 3;
printf("%d %d\n", a, b);
return 0;
}
- 这段代码中
a和b的的赋值,只差了一个括号,但是结果截然不同。 - 输出的结果为:
3 1
- 原因是因为
(1, x = 2, y = 3)表达式的值为以逗号分隔的最后一个表达式的值,即3;而在b = 1, x = 9, y = 3中,由于逗号运算符的优先级很低,导致表达式分成了三部分:b = 1、x = 9、y = 3,所以才有 a = 3 a=3 a=3, b = 1 b=1 b=1。
通过这一章,我们学会了:
1)逗号运算符;
2)逗号表达式;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第32题】给定一个字符串,原地对它进行翻转并输出
📢博客主页:https://blog.csdn.net/WhereIsHeroFrom
📢欢迎各位 👍点赞 ⭐收藏 📝评论,如有错误请留言指正,非常感谢!
📢本文由 英雄哪里出来 原创,转载请注明出处,首发于 🙉 CSDN 🙉
作者的专栏:
👉C语言基础专栏《光天化日学C语言》
👉C语言基础配套试题详解《C语言入门100例》
👉算法进阶专栏《夜深人静写算法》
五十八、运算符简介
- 运算符用于执行程序代码运算,会针对一个、两个或多个操作数来进行运算。例如:1 + 2,其操作数是 1 和 2,而运算符则是 “+”(加号)。
- C语言把除了 控制语句 和 输入输出 以外的几乎所有的基本操作都作为运算符处理,可见一斑。
五十九、运算符分类
- 将按功能分类,可以分为:后缀运算符、单目运算符、算术运算符、关系运算符、位运算符、逻辑运算符、条件运算符、赋值运算符、逗号运算符。

- 在之前的章节也有介绍了很多运算符,这里简单做个总结:
| 运算符类型 | 运算符举例 | 参考文章 |
|---|---|---|
| 后缀运算符 | []下标运算 | 会在数组章节讲解,待更新 |
| 单目运算符 | (type)强制转换 | 光天化日学C语言(12)- 类型转换 |
| 算术运算符 | +加号 | 光天化日学C语言(09)- 算术运算符 |
| 移位运算符 | <<左移 | 光天化日学C语言(18)- 位运算 << 的应用 |
| 关系运算符 | <小于 | 光天化日学C语言(10)- 关系运算符 |
| 双目位运算符 | &位与 | 光天化日学C语言(14)- 位运算 & 的应用 |
| 双目逻辑运算符 | && | 光天化日学C语言(11)- 逻辑运算符 |
| 条件运算符 | ? : | 会在if语句章节讲解,待更新 |
| 赋值运算符 | <<=左移后赋值 | 光天化日学C语言(20)- 赋值运算符与赋值表达式 |
| 逗号运算符 | ,逗号 | 光天化日学C语言(21)- 逗号运算符 |
六十、运算符的优先级和结合性
1、运算符优先级表 (建议收藏)
| 优先级 | 运算符 | 名称 | 形式 | 举例 |
|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | a[2] |
| 1 | () | 圆括号 | (表达式) 或 函数名(形参表) | (a+1) |
| 1 | . | 对象的成员选择 | 对象.成员名 | a.b |
| 1 | -> | 指针的成员选择 | 指针.成员名 | a->b |
| 2 | + | 正号 | +表达式 | +5 |
| 2 | - | 负号 | -表达式 | -5 |
| 2 | (type) | 强制类型转换 | (数据类型)表达式 | (int)a |
| 2 | ++ | 自增运算符 | ++变量名 / 变量名++ | ++i |
| 2 | -- | 自增运算符 | –变量名 / 变量名– | --i |
| 2 | ! | 逻辑非 | !表达式 | !a[0] |
| 2 | ~ | 按位取反 | ~表达式 | ~a |
| 2 | & | 取地址 | &变量名 | &a |
| 2 | * | 解引用 | *指针变量名 | *a |
| 2 | sizeof | 取长度 | sizeof(表达式) | sizeof(a) |
| 3 | * | 乘 | 表达式 * 表达式 | 3 * 5 |
| 3 | / | 除 | 表达式 / 表达式 | 3 / 5 |
| 3 | % | 模 | 整型表达式 % 整型非零表达式 | 3 % 5 |
| 4 | + | 加 | 表达式 + 表达式 | a + b |
| 4 | - | 减 | 表达式 - 表达式 | a - b |
| 5 | << | 左移 | 变量<<表达式 | 1<<5 |
| 5 | >> | 右移 | 变量>>表达式 | x>>1 |
| 6 | < | 小于 | 表达式<表达式 | 1 < 2 |
| 6 | <= | 小于等于 | 表达式<=表达式 | 1 <= 2 |
| 6 | > | 大于 | 表达式>表达式 | 1 > 2 |
| 6 | >= | 大于等于 | 表达式>=表达式 | 1 >= 2 |
| 7 | == | 等于 | 表达式==表达式 | 1 == 2 |
| 7 | != | 不等于 | 表达式!=表达式 | 1 != 2 |
| 8 | & | 等于 | 表达式&表达式 | 1 & 2 |
| 9 | ^ | 等于 | 表达式^表达式 | 1 ^ 2 |
| 10 | | | 等于 | 表达式\表达式 | 1 | 2 |
| 11 | && | 逻辑与 | 表达式&&表达式 | a && b |
| 12 | || | 逻辑与 | 表达式||表达式 | a || b |
| 13 | ?: | 条件运算符 | 表达式1? 表达式2: 表达式3 | a>b?a:b |
| 14 | = | 赋值 | 变量=表达式 | a = b |
| 14 | += | 加后赋值 | 变量+=表达式 | a += b |
| 14 | -= | 减后赋值 | 变量-=表达式 | a -= b |
| 14 | *= | 乘后赋值 | 变量*=表达式 | a *= b |
| 14 | /= | 除后赋值 | 变量/=表达式 | a /= b |
| 14 | %= | 模后赋值 | 变量%=表达式 | a %= b |
| 14 | >>= | 右移后赋值 | 变量>>=表达式 | a >>= b |
| 14 | <<= | 左移后赋值 | 变量<<=表达式 | a <<= b |
| 14 | &= | 位与后赋值 | 变量&=表达式 | a &= b |
| 14 | ^= | 异或后赋值 | 变量^=表达式 | a ^= b |
| 14 | |= | 位或后赋值 | 变量|=表达式 | a |= b |
| 15 | , | 逗号运算符 | 表达式1,表达式2,… | a+b,a-b |
2、结合性
结合方向只有 3 个是 从右往左,其余都是 从左往右(比较符合人的直观感受)。
(1)一个是单目运算符;
(2)一个是双目运算符中的 赋值运算符;
(3)一个条件运算符,也就是C语言中唯一的三目运算符。
3、优先级
后缀运算符和单目运算符优先级一般最高,逗号运算符的优先级最低。快速记忆如下:
单目逻辑运算符 > 算术运算符 > 关系运算符 > 双目逻辑运算符 > 赋值运算符
六十一、运算符的优先级和结合性举例
#include <stdio.h>
int main() {
int a = 1, b = 2, c = 3;
a <<= b <<= c;
printf("%d\n", a );
return 0;
}
【运行结果】65536
【结果答疑】a <<= b <<= c的计算方式等价于a = (a << (b << c)),结果为1 << 16。
#include <stdio.h>
int main() {
int a = 1, b = 2;
printf("%d\n", a > b ? a + b : a - b );
return 0;
}
【运行结果】-1
【结果答疑】条件运算符的优先级较低,低于关系运算符和算术运算符,所以a > b ? a + b : a - b等价于1 > 2 ? 3 : -1。
#include <stdio.h>
int main() {
int a = 1;
--a && --a;
printf("%d\n", a);
return 0;
}
【运行结果】0
【结果答疑】这个例子是展示逻辑与运算符&&从左往右计算过程中,一旦遇到 0 就不再进行运算了,所以--a实际上只执行了一次。
#include <stdio.h>
int main() {
int x = 0b010000;
printf("%d\n", x | x - 1 );
return 0;
}
【运行结果】31
【结果答疑】这个例子是是将低位连续的零变成一,但是一般这样的写法会报警告,因为编译程序并不知道你的诉求,到底是想先计算 | 还是先计算-,由于这个问题我们实际要计算的是x | (x - 1),并且减法运算符-优先级高于位或运算符 | ,所以括号是可以省略的。
#include <stdio.h>
int main() {
int a = 0b1010;
int b = 0b0101;
int c = 0b1001;
printf("%d\n", a | b ^ c );
return 0;
}
【运行结果】14
【结果答疑】这个例子表明了异或运算符^高于位或运算符 | 。
#include <stdio.h>
int main() {
int a = 0b1010;
int b = 0b0110;
printf("%d\n", a & b == 2);
return 0;
}
【运行结果】0
【结果答疑】延续【例题59】继续看,之前a & b输出的是2,那为什么加上等于==判定后,输出结果反而变成0了呢?原因是因为==的优先级高于位与&,所以相当于进行了a & 0的操作,结果自然就是0了。
通过这一章,我们学会了:
1)运算符的优先级;
2)运算符的结合性;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第13题】给定三个数 a,b,c,从小到大输出这三个数
六十二、整数简介
1、符号位 和 数值位
- 我们知道 整数 分为 有符号整型 和 无符号整型。
- 有符号整型,程序需要区分 符号位 和 数值位。
- 对我们人类来说,很容易分辨;而对计算机而言,就要设计专门的电路,这就增加了硬件的复杂性,从而增加了计算的时间。
所以,如果能够将 符号位 和 数值位 联合起来,让它们共同参与运算,不再加以区分,这样硬件电路就会变得更加简单。
2、整型的加减运算
- 其次,加法 和 减法 的引入,也将问题变得复杂。而由于减去一个数相当于加上这个数的相反数,例如:
1 - 2等价于1 + (-2),1 - (-2)等价于1 + 2。
所以,它们可以合并为一种运算,即只保留加法运算。
- 相反数是指 数值位 相同,符号位 不同的两个数,例如,1 和 -1 就是一对相反数。
- 所以,我们需要做的就是设计一种简单的、不用区分符号位和数值位的加法电路,就能同时实现加法和减法运算。首先让我们看几个计算机中的概念。

六十三、机器数和真值
1、机器数
- 我们知道计算机是内部由 0 和 1 组成的编码,无论是整数还是浮点数,都会涉及到负数,对于机器来说是不知道正负的,而 “正” 和 “负” 正好是两种对立的状态,所以规定用 “0” 表示 “正”,“1” 表示 “负”,这样符号就被数字化了,并且将它放在有效数字的前面,就成了有符号数;
- 把符号 “数字化” 的数称为 机器数;
2、真值
- 而带有 “+” 或者 “-” 的数称为 真值;
- 然而,当符号位和数值部分放在一起后,如何让它一起参与运算呢?那就要涉及到接下来要讲的计算机的各种编码了。
六十四、计算机编码

1、原码
1)定义
- 这里的原码并不是源码(源代码)的意思,而是机器数中最简单的一种表示形式;为了快速理解,这里只介绍 32位整数;
【定义】 符号位 为 0 代表 正数,符号位 为 1 代表 负数,数值位 为 真值的绝对值。
2)举例
- 1)对于十进制数 37,它的 真值 和 原码 关系如下:
真值:+ 00000000 00000000 00000000 00100101
原码: 00000000 00000000 00000000 00100101
- 2)对于十进制数 -37,它的 真值 和 原码 的关系如下:
真值:- 00000000 00000000 00000000 00100101
原码: 10000000 00000000 00000000 00100101
- 我们发现,对于负数的情况,原码 加上 真值(注意,这里真值为负数)后,二进制数正好等于 1 ( 0...0 ⏟ 31 ) 2 1(\underbrace{0...0}_{31})_2 1(31 0...0)2, 即 2 31 2^{31} 231,表示成公式如下: [ x ] 原 + x = 2 31 [x]_原 + x = 2^{31} [x]原+x=231
3)公式
- 因此,我们可以通过移项,得出原码的十进制计算公式如下:
[ x ] 原 = { x ( 0 ≤ x < 2 n − 1 ) 2 n − 1 − x ( − 2 n − 1 < x ≤ 0 ) [x]_原 = \begin{cases} x & (0 \le x < 2^{n-1})\\ 2^{n-1} - x & (-2^{n-1} < x \le 0) \end{cases} [x]原={x2n−1−x(0≤x<2n−1)(−2n−1<x≤0) 这里 x x x 代表真值,而 n n n 的取值是 8 、 16 、 32 、 64 8、16、32、64 8、16、32、64,我们通常说的整型
int都是 32位 的,本文就以 n = 32 n = 32 n=32 的情况进行阐述;
- 原码是最贴近人类的编码方式,并且很容易和真值进行转换,但是让计算机用原码进行加减运算过于繁琐,如果两个数符号位不同,需要先判断绝对值大小,然后用绝对值大的减去绝对值小的,并且符号以绝对值大的数为准,本来是加法却需要用减法来实现。
2、反码

1)定义
【定义】 正数 的 反码 就是它的 原码;负数 的 反码 为 原码 的每一位的 0变1、1变0(即位运算中的按位取反);
2)举例
- 1)对于十进制数 37,它的 真值 和 反码 关系如下:
真值:+ 00000000 00000000 00000000 00100101
反码: 00000000 00000000 00000000 00100101
- 2)对于十进制数 -37,它的 真值 和 反码 的关系如下:
真值:- 00000000 00000000 00000000 00100101
反码: 11111111 11111111 11111111 11011010
- 我们发现,对于负数的情况,反码 减去 真值(注意,这里真值为负数)后,负负得正,转换成二进制位相加正好等于 ( 1...1 ⏟ 32 ) 2 (\underbrace{1...1}_{32})_2 (32 1...1)2, 即 2 32 − 1 2^{32}-1 232−1,表示成公式如下: [ x ] 反 − x = 2 32 − 1 [x]_反 - x = 2^{32}-1 [x]反−x=232−1
3)公式
- 因此,通过移项,我们可以得出反码的十进制计算公式如下:
[ x ] 反 = { x ( 0 ≤ x < 2 n − 1 ) 2 n − 1 + x ( − 2 n − 1 < x ≤ 0 ) [x]_反 = \begin{cases} x & (0 \le x < 2^{n-1})\\ 2^{n}-1 + x & (-2^{n-1} < x \le 0) \end{cases} [x]反={x2n−1+x(0≤x<2n−1)(−2n−1<x≤0) 这里 x x x 代表真值,而 n n n 的取值是 8 、 16 、 32 、 64 8、16、32、64 8、16、32、64,我们通常说的整型
int都是 32位 的,本文就以 n = 32 n = 32 n=32 的情况进行阐述;
- 反码有个很难受的点,就是 ( 0 0...0 ⏟ 31 ) 2 (0\underbrace{0...0}_{31})_2 (031 0...0)2 和 ( 1 0...0 ⏟ 31 ) 2 (1\underbrace{0...0}_{31})_2 (131 0...0)2 都代表零,就是我们常说的 正零 和 负零。正如公式中看到的,当真值为 0 的时候,有两种情况,这就产生了二义性,而且浪费了一个整数表示形式。
3、补码

1)定义
【定义】 正数 的 补码 就是它的 原码;负数 的 补码 为 它的反码加一;
2)举例
- 1)对于十进制数 37,它的 真值 和 补码 关系如下:
真值:+ 00000000 00000000 00000000 00100101
补码: 00000000 00000000 00000000 00100101
- 2)对于十进制数 -37,它的 真值 和 反码 的关系如下:
真值:- 00000000 00000000 00000000 00100101
补码: 11111111 11111111 11111111 11011011
- 我们发现,对于负数的情况,反码 减去 真值(注意,这里真值为负数)后,负负得正,转换成二进制位相加正好等于 1 ( 0...0 ⏟ 32 ) 2 1(\underbrace{0...0}_{32})_2 1(32 0...0)2, 即 2 32 2^{32} 232,表示成公式如下: [ x ] 补 − x = 2 32 [x]_补 - x = 2^{32} [x]补−x=232
3)公式
- 因此,通过移项,我们可以得出补码的十进制计算公式如下:
[ x ] 补 = { x ( 0 ≤ x < 2 n − 1 ) 2 n + x ( − 2 n − 1 ≤ x < 0 ) [x]_补 = \begin{cases} x & (0 \le x < 2^{n-1})\\ 2^{n} + x & (-2^{n-1} \le x < 0) \end{cases} [x]补={x2n+x(0≤x<2n−1)(−2n−1≤x<0) 这里 x x x 代表真值,而 n n n 的取值是 8 、 16 、 32 、 64 8、16、32、64 8、16、32、64,我们通常说的整型
int都是 32位 的,本文就以 n = 32 n = 32 n=32 的情况进行阐述;
4、编码总结
对于三种编码方式,总结如下:
1)这三种机器数的最高位均为符号位;
2)当真值为正数时,原码、反码、补码的表示形式相同,符号位用 “0” 表示,数值部分真值相同;
3)当真值为负数时,原码、反码、补码的表示形式不同,但是符号位都用 “1” 表示,数值部分:反码是原码的 “按位取反”,补码是反码加一;
正数
真值:+ 00000000 00000000 00000000 00100101
原码: 00000000 00000000 00000000 00100101
反码: 00000000 00000000 00000000 00100101
补码: 00000000 00000000 00000000 00100101
负数
真值:- 00000000 00000000 00000000 00100101
原码: 10000000 00000000 00000000 00100101
反码: 11111111 11111111 11111111 11011010
补码: 11111111 11111111 11111111 11011011
六十五、为什么要引入补码

- 最后,我们来讲一下引入补码的真实意图是什么。
1、主要目的
- 计算机的四则运算希望设计的尽量简单。但是引入 符号位 的概念,对于计算机来说还要考虑正负数相加,等于引入了减法,所以希望是计算机底层 只设计一个加法器,就能把加法和减法都做了。
2、原码运算
- 对于原码的加法,两个正数相加的情况如下:
+1 的原码:00000000 00000000 00000000 00000001
+1 的原码:00000000 00000000 00000000 00000001
----------------------------------------------
+2 的原码:00000000 00000000 00000000 00000010
- 好像没有什么问题?于是人们开始探索减法,但是起初设计的人的初衷是希望不用减法,只用加法运算就能够将加法和减法都包含进来,于是,我们尝试用原码的负数表示来做运算;
- 将
1 - 2表示成1 + (-2),然后用原码相加得到:
+1 的原码:00000000 00000000 00000000 00000001
-2 的原码:10000000 00000000 00000000 00000010
----------------------------------------------
-3 的原码:10000000 00000000 00000000 00000011
- 我们发现
1 + (-2) = -3,计算结果明显是错的,所以为了解决减法问题,引入了反码;
3、反码运算
- 对于正数的加法,两个正数反码相加的情况和原码相加一致,不会有问题。
- 对于正数的减法,转换成一正一负两数相加。
- 将
1 - 2表示成1 + (-2),情况如下:
+1 的反码:00000000 00000000 00000000 00000001
-2 的反码:11111111 11111111 11111111 11111101
----------------------------------------------
-1 的反码:11111111 11111111 11111111 11111110
- 没有什么问题?但是某种情况下,反码会有歧义,当两个相同的数相减时,即
1 - 1表示成1 + (-1),情况 如下:
+1 的反码:00000000 00000000 00000000 00000001
-1 的反码:11111111 11111111 11111111 11111110
---------------------------------------------
-0 的反码:11111111 11111111 11111111 11111111
- 这里出现了一个奇怪的概念,就是 “负零”,反码运算过程中会出现有两个编码表示零这个数值。
- 为了解决正负零的问题引入了补码的概念。
4、补码运算
1)两个正数的补码相加。
- 其和等于 它们的原码相加,已经验证过,不会有问题;
2)一正一负两个数相加,且 答案非零 。
+1 的补码:00000000 00000000 00000000 00000001
-2 的补码:11111111 11111111 11111111 11111110
----------------------------------------------
-1 的补码:11111111 11111111 11111111 11111111
- 结果正确;
3)一正一负两个数相加,且 答案为零。
+1 的补码 00000000 00000000 00000000 00000001
-1 的补码: 11111111 11111111 11111111 11111111
----------------------------------------------
0 的补码:1 00000000 00000000 00000000 00000000
- 两个互为相反数的数相加后,得到的数的补码为 2 n 2^n 2n(可以认为是是溢出了),所以那个 1 根本不会被存进计算机中,也就是表现出来的结果就是 零!
- 而且,补码的这个运算,和我们之前提到的定义吻合。
- 综上所述,补码解决了整数加法带来的所有问题。
通过这一章,我们学会了:
1)原码的表示形式;
2)反码的表示形式;
3)补码的表示形式;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第11题】给出四个数,输出四个数的和 | 溢出了怎么办?
六十六、浮点数简介
1、数学中的小数
- 数学中的小数分为整数部分和小数部分,它们由点号
.分隔,我们将它称为 十进制表示。例如 0.0 0.0 0.0、 1314.520 1314.520 1314.520、 − 1.234 -1.234 −1.234、 0.0001 0.0001 0.0001 等都是合法的小数,这是最常见的小数形式。 - 小数也可以采用 指数表示,例如 1.23. × 1 0 2 1.23.\times 10^2 1.23.×102、 0.0123 × 1 0 5 0.0123 \times 10^5 0.0123×105、 1.314 × 1 0 − 2 1.314 \times 10^{-2} 1.314×10−2 等。
2、C语言中的小数
- 在 C语言 中的小数,我们称为浮点数。
- 其中,十进制表示相同,而指数表示,则略有不同。
- 对于数学中的 a × 1 0 n a \times 10^n a×10n。在C语言中的指数表示如下:
aEn 或者 aen
- 其中 a a a 为尾数部分,是一个十进制数; n n n 为指数部分,是一个十进制整数; E E E、 e e e 是固定的字符,用于分割 尾数部分 和 指数部分。
| 数学 | C语言 |
|---|---|
| 1.5 1.5 1.5 | 1.5 E 1 1.5E1 1.5E1 |
| 1990 1990 1990 | 1.99 e 3 1.99e3 1.99e3 |
| − 0.054 -0.054 −0.054 | − 0.54 e − 1 -0.54e-1 −0.54e−1 |
3、浮点数类型
- 常用浮点数有两种类型,分别是
float和double; float称为单精度浮点型,占 4 个字节;double称为双精度浮点型,占 8 个字节。
4、浮点数的输出
- 我们可以用
printf对浮点数进行格式化输出,如下表格所示:
| 控制符 | 浮点类型 | 表示形式 |
|---|---|---|
%f | float | 十进制表示 |
%e | float | 指数表示,输出结果中的 e小写 |
%E | float | 指数表示,输出结果中的 E大写 |
%lf | double | 十进制表示 |
%le | double | 指数表示,输出结果中的e小写 |
%lE | double | 指数表示,输出结果中的E大写 |
- 来看一段代码加深理解:
#include <stdio.h>
int main() {
float f = 520.1314f;
double d = 520.1314;
printf("%f\n", f);
printf("%e\n", f);
printf("%E\n", f);
printf("%lf\n", d);
printf("%le\n", d);
printf("%lE\n", d);
return 0;
}
- 这段代码的输出如下:
520.131409
5.201314e+02
5.201314E+02
520.131400
5.201314e+02
5.201314E+02
- 1)
%f和%lf默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。 - 2)以指数形式输出浮点数时,输出结果为科学计数法。也就是说,尾数部分的取值为:
- 0 ≤ 尾 数 < 10 0 \le 尾数 \lt 10 0≤尾数<10
- 3)以上六个输出,对应的是表格中的六种输出方式,但是我们发现第一种输出方式中,并不是我们期望的结果,这是由于这个数超出了
float能够表示的范围,从而产生了精度误差,而double的范围更大一些,所以就能正确表示,所以平时编码过程中,如果对效率要求较高,对精度要求较低,可以采用float;反之,对效率要求一般,但是对精度要求较高,则需要采用double。
六十七、浮点数的存储
1、科学计数法
- C语言中,浮点数在内存中是以科学计数法进行存储的,科学计数法是一种指数表示,数学中常见的科学计数法是基于十进制的,例如 5.2 × 1 0 11 5.2 × 10^{11} 5.2×1011;计算机中的科学计数法可以基于其它进制,例如 1.11 × 2 7 1.11 × 2^7 1.11×27 就是基于二进制的,它等价于 ( 11100000 ) 2 (11100000)_2 (11100000)2。
- 科学计数法的一般形式如下:
- v a l u e = ( − 1 ) s i g n × f r a c t i o n × b a s e e x p o n e n t value = (-1)^{sign} \times fraction \times base^{exponent} value=(−1)sign×fraction×baseexponent
v a l u e value value:代表要表示的浮点数;
s i g n sign sign:代表 v a l u e value value 的正负号,它的取值只能是 0 或 1:取值为 0 是正数,取值为 1 是负数;
b a s e base base:代表基数,或者说进制,它的取值大于等于 2;
f r a c t i o n fraction fraction:代表尾数,或者说精度,是 b a s e base base 进制的小数,并且 1 ≤ f r a c t i o n < b a s e 1 \le fraction \lt base 1≤fraction<base,这意味着,小数点前面只能有一位数字;
e x p o n e n t exponent exponent:代表指数,是一个整数,可正可负,并且为了直观一般采用 十进制 表示。
1)十进制的科学计数法
- 以 14.375 14.375 14.375 这个小数为例,根据初中学过的知识,想要把它转换成科学计数法,只要移动小数点的位置。如果小数点左移一位,则指数 e x p o n e n t exponent exponent 加一;如果小数点右移一位,则指数 e x p o n e n t exponent exponent 减一;
- 所以它在十进制下的科学计数法,根据上述公式,计算结果为:
- ( 14.375 ) 10 = 1.4375 × 1 0 1 (14.375)_{10} = 1.4375 \times 10^1 (14.375)10=1.4375×101
- 其中 v a l u e = 14.375 value = 14.375 value=14.375、 s i g n = 0 sign = 0 sign=0、 b a s e = 10 base = 10 base=10、 f r a c t i o n = 1.4375 fraction = 1.4375 fraction=1.4375、 e x p o n e n t = 1 exponent = 1 exponent=1;
- 这是我们数学中最常见的科学计数法。
2)二进制的科学计数法
- 同样以 14.375 14.375 14.375 这个小数为例,我们将它转换成二进制,按照两部分进行转换:整数部分和小数部分。
- 整数部分:整数部分等于 14,不断除 2 取余数,转换成 2 的幂的求和如下:
- ( 14 ) 10 = 1 × 2 3 + 1 × 2 2 + 1 × 2 1 + 0 × 2 0 (14)_{10} = 1 \times 2^3 + 1 \times 2^2 + 1 \times 2^1 + 0 \times 2^0 (14)10=1×23+1×22+1×21+0×20
- 所以 14 的二进制表示为 ( 1110 ) 2 (1110)_2 (1110)2。
- 小数部分:小数部分等于 0.375,不断乘 2 取整数部分的值,转换成 2 的幂的求和如下:
- ( 0.375 ) 10 = 0 × 2 − 1 + 1 × 2 − 2 + 1 × 2 − 3 (0.375)_{10} = 0 \times 2^{-1} + 1 \times 2^{-2} +1 \times 2^{-3} (0.375)10=0×2−1+1×2−2+1×2−3
- 所以 0.375 的二进制表示为 ( 0.011 ) 2 (0.011)_2 (0.011)2
- 将 整数部分 和 小数部分 相加,得到的就是它的二进制表示:
- ( 1110.011 ) 2 (1110.011)_2 (1110.011)2
- 同样,我们参考十进制科学计数法的表示方式,通过移动小数点的位置,将它表示成二进制的科学计数法,对于这个数,我们需要将它的小数点左移三位。得到:
- ( 1110.011 ) 2 = ( 1.110011 ) 2 × 2 3 (1110.011)_2 = (1.110011)_2 \times 2^3 (1110.011)2=(1.110011)2×23
- 其中 v a l u e = 14.375 value = 14.375 value=14.375、 s i g n = 0 sign = 0 sign=0、 b a s e = 2 base = 2 base=2、 f r a c t i o n = ( 1.110011 ) 2 fraction = (1.110011)_2 fraction=(1.110011)2、 e x p o n e n t = 3 exponent = 3 exponent=3;
- 我们发现,为了表示成科学计数法,小数点的位置发生了浮动,这就是浮点数的由来。

2、浮点数存储概述
- 计算机中的浮点数表示都是采用二进制的。上面的科学计数法公式中,除了 b a s e base base 确定是 2 以外,符号位 s i g n sign sign、尾数位 f r a c t i o n fraction fraction、指数位 e x p o n e n t exponent exponent 都是未知数,都需要在内存中体现出来。还是以 14.375 14.375 14.375 为例,我们来看下它的几个关键数值的存储。
1)符号的存储
- 符号位的存储类似存储整型一样,单独分配出一个比特位来,用 0 表示正数,1 表示负数。对于 14.375 14.375 14.375,符号位的值是 0。
2)尾数的存储
- 根据科学计数法的定义,尾数部分的取值范围为 1 ≤ f r a c t i o n < 2 1 \le fraction \lt 2 1≤fraction<2
- 这代表尾数的整数部分一定为 1,是一个恒定的值,这样就无需在内存中提现出来,可以将其直接截掉,只要把小数点后面的二进制数字放入内存中即可,这个设计可真是省(扣)啊。
- 对于
(
1.110011
)
2
(1.110011)_2
(1.110011)2,就是把
110011放入内存。我们将内存中存储的尾数命名为 f f f,真正的尾数命名为 f r a c t i o n fraction fraction,则么它们之间的关系为: f r a c t i o n = 1. f fraction = 1.f fraction=1.f - 这时候,我们就可以发现,如果 b a s e base base 采用其它进制,那么尾数的整数部分就不是固定的,它有多种取值的可能,以十进制为例,尾数的整数部分可能是 1 → 9 1 \to 9 1→9 之间的任何一个值,如此一来,尾数的整数部分就无法省略,必须在内存中表示出来。但是将 b a s e base base 设置为 2,就可以节省掉一个比特位的内存,这也是采用二进制的优势。
3)指数的存储
- 指数是一个整数,并且有正负之分,不但需要存储它的值,还得能区分出正负号来。所以存储时需要考虑到这些。
- 那么它是参照补码的形式来存储的吗?
- 答案是否。
- 指数的存储方式遵循如下步骤:
- 1)由于
float和double分配给指数位的比特位不同,所以需要分情况讨论; - 2)假设分配给指数的位数为 n n n 个比特位,那么它能够表示的指数的个数就是 2 n 2^n 2n;
- 3)考虑到指数有正负之分,并且我们希望正负指数的个数尽量平均,所以取一半, 2 n − 1 2^{n-1} 2n−1 表示负数, 2 n − 1 2^{n-1} 2n−1 表示正数。
- 4)但是,我们发现还有一个 0,需要表示,所以负数的表示范围将就一点,就少了一个数;
- 5)于是,如果原本的指数位 x x x,实际存储到内存的值就是: x + 2 n − 1 − 1 x + 2^{n-1} - 1 x+2n−1−1
- 接下来,我们拿具体
float和double的实际位数来举例说明实际内存中的存储方式。
3、浮点数存储内存结构
- 浮点数的内存分布主要分成了三部分:符号位、指数位、尾数位。浮点数的类型确定后,每一部分的位数就是固定的。浮点数的类型,是指它是
float还是double。 - 对于
float类型,内存分布如下:

- 对于
double类型,内存分布如下:

- 1)符号位:只有两种取值:0 或 1,直接放入内存中;
- 2)指数位:将指数本身的值加上 2 n − 1 − 1 2^{n-1}-1 2n−1−1 转换成 二进制,放入内存中;
- 3)尾数位:将小数部分放入内存中;
| 浮点数类型 | 指数位数 | 指数范围 | 尾数位数 | 尾数范围 |
|---|---|---|---|---|
float | 8 8 8 | [ − 2 7 + 1 , 2 7 ] [-2^7+1,2^7] [−27+1,27] | 23 23 23 | [ ( 0 ) 2 , ( 1...1 ⏟ 23 ) 2 ] [(0)_2, (\underbrace{1...1}_{23})_2] [(0)2,(23 1...1)2] |
double | 11 11 11 | [ − 2 10 + 1 , 2 10 ] [-2^{10}+1,2^{10}] [−210+1,210] | 52 52 52 | [ ( 0 ) 2 , ( 1...1 ⏟ 52 ) 2 ] [(0)_2, (\underbrace{1...1}_{52})_2] [(0)2,(52 1...1)2] |
4、内存结构验证举例
- 以上文求得的 14.375 14.375 14.375 为例,我们将它转换成二进制,表示成科学计数法,如下:
- ( 1110.011 ) 2 = ( 1.110011 ) 2 × 2 3 (1110.011)_2 = (1.110011)_2 \times 2^3 (1110.011)2=(1.110011)2×23
- 其中 值 v a l u e = 14.375 value = 14.375 value=14.375、符号位 s i g n = 0 sign = 0 sign=0、基数 b a s e = 2 base = 2 base=2、尾数 f r a c t i o n = ( 1.110011 ) 2 fraction = (1.110011)_2 fraction=(1.110011)2、指数 e x p o n e n t = 3 exponent = 3 exponent=3;
1)float 的内存验证
- 为了方便阅读,我采用了颜色来表示数字,橙色代表符号位,蓝色代表指数位,红色代表尾数,绿色代表尾数补齐位;并且 八位一分隔,增强可视化。
- 符号位的内存:0
- 指数的内存(加上127后等于130,再转二进制):10000010
- 尾数的内存(不足23位补零):1100110 00000000 00000000
- 按顺序组织到一起后得到:01000001 01100110 00000000 00000000
#include <stdio.h>
int main() {
int value = 0b01000001011001100000000000000000; // (1)
printf("%f\n", *(float *)(&value) ); // (2)
return 0;
}
运算结果如下:
( 1 ) (1) (1) 第一步,就是把上面那串二进制的 01串 直接拷贝下来,然后在前面加上0b前缀,代表了 v a l u e value value 这个四字节的内存结构就是这样的;
( 2 ) (2) (2) 第二步,分三个小步骤:
( 2. a ) (2.a) (2.a)&value代表取value这个值的地址;
( 2. b ) (2.b) (2.b)(float *)&value代表将这个地址转换成float类型;
( 2. c ) (2.c) (2.c)*(float *)&value代表将这个地址里的值按照float类型解析得到一个float数;
- 运行结果为:
14.375000
- (有关取地址和指针相关的内容,由于前面章节还没有涉及,如果读者看不懂,也没有关系,后面在讲解指针时会详细讲解这块内容,敬请期待)。
2)double 的内存验证
- 为了方便阅读,我采用了颜色来表示数字,橙色代表符号位,蓝色代表指数位,红色代表尾数,绿色代表尾数补齐位;并且 八位一分隔,增强可视化。
- 符号位的内存:0
- 指数的内存(加上1023后等于1026,再转二进制):100 00000010
- 尾数的内存(不足52位补零):1100 11000000 00000000 00000000 00000000 00000000 00000000
- 按顺序组织到一起后得到:01000000 00101100 11000000 00000000 00000000 00000000 00000000 00000000
#include <stdio.h>
int main() {
long long value = 0b0100000000101100110000000000000000000000000000000000000000000000; // (1)
printf("%lf\n", *(double *)(&value) ); // (2)
return 0;
}
运算结果如下:
( 1 ) (1) (1) 第一步,就是把上面那串二进制的 01串 直接拷贝下来,然后在前面加上0b前缀,代表了 v a l u e value value 这个八字节的内存结构就是这样的;
( 2 ) (2) (2) 第二步,分三个小步骤:
( 2. a ) (2.a) (2.a)&value代表取value这个值的地址;
( 2. b ) (2.b) (2.b)(double *)&value代表将这个地址转换成double类型;
( 2. c ) (2.c) (2.c)*(double *)&value代表将这个地址里的值按照double类型解析得到一个double数;
- 没错,运行结果也是:
14.375000
- 这块内容,如果你看的有点懵,没有关系,等我们学了指针的内容以后,再来回顾这块内容,你就会如茅塞一样顿开了!
- 你学废了吗?🤣
通过这一章,我们学会了:
浮点数的科学计数法和内存存储方式;
- 希望对你有帮助哦 ~ 祝大家早日成为 C 语言大神!
课后习题
- 【第06题】给定两个点的坐标 (x1, y1) 和 (x2, y2),求两点间的距离
🙉饭不食,水不饮,题必须刷🙉
还不会C语言,和我一起打卡! 🌞《光天化日学C语言》🌞
LeetCode 太难?上简单题! 🧡《C语言入门100例》🧡
LeetCode 太简单?大神盘他! 🌌《夜深人静写算法》🌌