【万物皆可 GAN】给马儿换皮肤
- 概述
- 真假斑马
- 实现流程
- 代码
- 执行流程
- 执行结果
概述
CycleGAN (Cycle Generative Adversarial Network) 即循环对抗生成网络. CycleGAN 可以帮助我们实现图像的互相转换.

真假斑马
我们先来看一组图片, 大家来猜一猜图上的动物是什么:



你觉得图里面是斑马么? 其实你错了, 他们都是马. 惊不惊喜, 意不意外.
原图:



实现流程
CycleGAN 由左右两个 GAN 网络组成. G(AB) 负责把 A 类物体 (斑马) 转换成 B 类物体 (正常的马). G(BA) 负责把 B 类物体 (正常的马) 还原成 A 类物体 (斑马).
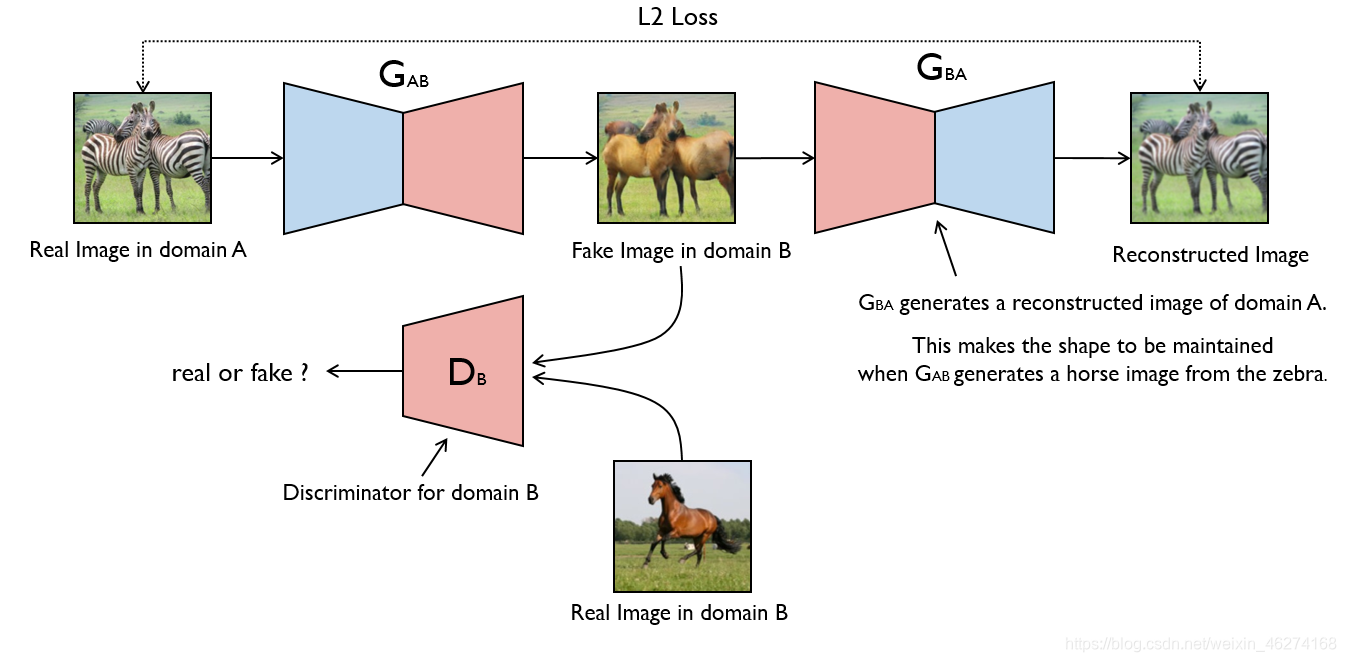
代码
我们需要修改的参数有:
- dataroot: 数据集路径
- name: 运行试验的名称
- batch-size: 批次大小, 默认为 1
- n_epochs: 正常学习率迭代次数
- n_epochs_decay: 学习率衰减至 0 的迭代次数
base_options.py:
import argparse
import os
from util import util
import torch
import models
import data
class BaseOptions():
"""This class defines options used during both training and test time.
It also implements several helper functions such as parsing, printing, and saving the options.
It also gathers additional options defined in <modify_commandline_options> functions in both dataset class and model class.
"""
def __init__(self):
"""Reset the class; indicates the class hasn't been initailized"""
self.initialized = False
def initialize(self, parser):
"""Define the common options that are used in both training and test."""
# basic parameters
parser.add_argument('--dataroot', type=str, default="./datasets/horse2zebra", help='path to images (should have subfolders trainA, trainB, valA, valB, etc)')
parser.add_argument('--name', type=str, default='maps_cyclegan', help='name of the experiment. It decides where to store samples and models')
parser.add_argument('--gpu_ids', type=str, default='-1', help='gpu ids: e.g. 0 0,1,2, 0,2. use -1 for CPU')
parser.add_argument('--checkpoints_dir', type=str, default='./checkpoints', help='models are saved here')
# model parameters
parser.add_argument('--model', type=str, default='cycle_gan', help='chooses which model to use. [cycle_gan | pix2pix | test | colorization]')
parser.add_argument('--input_nc', type=int, default=3, help='# of input image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--output_nc', type=int, default=3, help='# of output image channels: 3 for RGB and 1 for grayscale')
parser.add_argument('--ngf', type=int, default=64, help='# of gen filters in the last conv layer')
parser.add_argument('--ndf', type=int, default=64, help='# of discrim filters in the first conv layer')
parser.add_argument('--netD', type=str, default='basic', help='specify discriminator architecture [basic | n_layers | pixel]. The basic model is a 70x70 PatchGAN. n_layers allows you to specify the layers in the discriminator')
parser.add_argument('--netG', type=str, default='resnet_9blocks', help='specify generator architecture [resnet_9blocks | resnet_6blocks | unet_256 | unet_128]')
parser.add_argument('--n_layers_D', type=int, default=3, help='only used if netD==n_layers')
parser.add_argument('--norm', type=str, default='instance', help='instance normalization or batch normalization [instance | batch | none]')
parser.add_argument('--init_type', type=str, default='normal', help='network initialization [normal | xavier | kaiming | orthogonal]')
parser.add_argument('--init_gain', type=float, default=0.02, help='scaling factor for normal, xavier and orthogonal.')
parser.add_argument('--no_dropout', action='store_true', help='no dropout for the generator')
# dataset parameters
parser.add_argument('--dataset_mode', type=str, default='unaligned', help='chooses how datasets are loaded. [unaligned | aligned | single | colorization]')
parser.add_argument('--direction', type=str, default='AtoB', help='AtoB or BtoA')
parser.add_argument('--serial_batches', action='store_true', help='if true, takes images in order to make batches, otherwise takes them randomly')
parser.add_argument('--num_threads', default=4, type=int, help='# threads for loading data')
parser.add_argument('--batch_size', type=int, default=1, help='input batch size')
parser.add_argument('--load_size', type=int, default=286, help='scale images to this size')
parser.add_argument('--crop_size', type=int, default=256, help='then crop to this size')
parser.add_argument('--max_dataset_size', type=int, default=float("inf"), help='Maximum number of samples allowed per dataset. If the dataset directory contains more than max_dataset_size, only a subset is loaded.')
parser.add_argument('--preprocess', type=str, default='resize_and_crop', help='scaling and cropping of images at load time [resize_and_crop | crop | scale_width | scale_width_and_crop | none]')
parser.add_argument('--no_flip', action='store_true', help='if specified, do not flip the images for data augmentation')
parser.add_argument('--display_winsize', type=int, default=256, help='display window size for both visdom and HTML')
# additional parameters
parser.add_argument('--epoch', type=str, default='latest', help='which epoch to load? set to latest to use latest cached model')
parser.add_argument('--load_iter', type=int, default='0', help='which iteration to load? if load_iter > 0, the code will load models by iter_[load_iter]; otherwise, the code will load models by [epoch]')
parser.add_argument('--verbose', action='store_true', help='if specified, print more debugging information')
parser.add_argument('--suffix', default='', type=str, help='customized suffix: opt.name = opt.name + suffix: e.g., {model}_{netG}_size{load_size}')
self.initialized = True
return parser
def gather_options(self):
"""Initialize our parser with basic options(only once).
Add additional model-specific and dataset-specific options.
These options are defined in the <modify_commandline_options> function
in model and dataset classes.
"""
if not self.initialized: # check if it has been initialized
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser = self.initialize(parser)
# get the basic options
opt, _ = parser.parse_known_args()
# modify model-related parser options
model_name = opt.model
model_option_setter = models.get_option_setter(model_name)
parser = model_option_setter(parser, self.isTrain)
opt, _ = parser.parse_known_args() # parse again with new defaults
# modify dataset-related parser options
dataset_name = opt.dataset_mode
dataset_option_setter = data.get_option_setter(dataset_name)
parser = dataset_option_setter(parser, self.isTrain)
# save and return the parser
self.parser = parser
return parser.parse_args()
def print_options(self, opt):
"""Print and save options
It will print both current options and default values(if different).
It will save options into a text file / [checkpoints_dir] / opt.txt
"""
message = ''
message += '----------------- Options ---------------\n'
for k, v in sorted(vars(opt).items()):
comment = ''
default = self.parser.get_default(k)
if v != default:
comment = '\t[default: %s]' % str(default)
message += '{:>25}: {:<30}{}\n'.format(str(k), str(v), comment)
message += '----------------- End -------------------'
print(message)
# save to the disk
expr_dir = os.path.join(opt.checkpoints_dir, opt.name)
util.mkdirs(expr_dir)
file_name = os.path.join(expr_dir, '{}_opt.txt'.format(opt.phase))
with open(file_name, 'wt') as opt_file:
opt_file.write(message)
opt_file.write('\n')
def parse(self):
"""Parse our options, create checkpoints directory suffix, and set up gpu device."""
opt = self.gather_options()
opt.isTrain = self.isTrain # train or test
# process opt.suffix
if opt.suffix:
suffix = ('_' + opt.suffix.format(**vars(opt))) if opt.suffix != '' else ''
opt.name = opt.name + suffix
self.print_options(opt)
# set gpu ids
str_ids = opt.gpu_ids.split(',')
opt.gpu_ids = []
for str_id in str_ids:
id = int(str_id)
if id >= 0:
opt.gpu_ids.append(id)
if len(opt.gpu_ids) > 0:
torch.cuda.set_device(opt.gpu_ids[0])
self.opt = opt
return self.opt
train_options.py:
from .base_options import BaseOptions
class TrainOptions(BaseOptions):
"""This class includes training options.
It also includes shared options defined in BaseOptions.
"""
def initialize(self, parser):
parser = BaseOptions.initialize(self, parser)
# visdom and HTML visualization parameters
parser.add_argument('--display_freq', type=int, default=400, help='frequency of showing training results on screen')
parser.add_argument('--display_ncols', type=int, default=4, help='if positive, display all images in a single visdom web panel with certain number of images per row.')
parser.add_argument('--display_id', type=int, default=1, help='window id of the web display')
parser.add_argument('--display_server', type=str, default="http://localhost", help='visdom server of the web display')
parser.add_argument('--display_env', type=str, default='main', help='visdom display environment name (default is "main")')
parser.add_argument('--display_port', type=int, default=8097, help='visdom port of the web display')
parser.add_argument('--update_html_freq', type=int, default=1000, help='frequency of saving training results to html')
parser.add_argument('--print_freq', type=int, default=100, help='frequency of showing training results on console')
parser.add_argument('--no_html', action='store_true', help='do not save intermediate training results to [opt.checkpoints_dir]/[opt.name]/web/')
# network saving and loading parameters
parser.add_argument('--save_latest_freq', type=int, default=5000, help='frequency of saving the latest results')
parser.add_argument('--save_epoch_freq', type=int, default=5, help='frequency of saving checkpoints at the end of epochs')
parser.add_argument('--save_by_iter', action='store_true', help='whether saves model by iteration')
parser.add_argument('--continue_train', action='store_true', help='continue training: load the latest model')
parser.add_argument('--epoch_count', type=int, default=1, help='the starting epoch count, we save the model by <epoch_count>, <epoch_count>+<save_latest_freq>, ...')
parser.add_argument('--phase', type=str, default='train', help='train, val, test, etc')
# training parameters
parser.add_argument('--n_epochs', type=int, default=100, help='number of epochs with the initial learning rate')
parser.add_argument('--n_epochs_decay', type=int, default=100, help='number of epochs to linearly decay learning rate to zero')
parser.add_argument('--beta1', type=float, default=0.5, help='momentum term of adam')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate for adam')
parser.add_argument('--gan_mode', type=str, default='lsgan', help='the type of GAN objective. [vanilla| lsgan | wgangp]. vanilla GAN loss is the cross-entropy objective used in the original GAN paper.')
parser.add_argument('--pool_size', type=int, default=50, help='the size of image buffer that stores previously generated images')
parser.add_argument('--lr_policy', type=str, default='linear', help='learning rate policy. [linear | step | plateau | cosine]')
parser.add_argument('--lr_decay_iters', type=int, default=50, help='multiply by a gamma every lr_decay_iters iterations')
self.isTrain = True
return parser
执行流程
我们先打开 cmd 命令行:
输入命令:
python -m visdom.server # 激活visdom
打开网页http://localhost:8097/:
然后 cd 到文件夹路径:
cd 路径
输入命令 (大家请根据自己设备自行更改参数):
python train.py --name experiment --batch_size 16 --n_epochs 20 --gpu_ids 0, 1
输出结果:
----------------- Options ---------------
batch_size: 16 [default: 1]
beta1: 0.5
checkpoints_dir: ./checkpoints
continue_train: False
crop_size: 256
dataroot: ./datasets/horse2zebra
dataset_mode: unaligned
direction: AtoB
display_env: main
display_freq: 400
display_id: 1
display_ncols: 4
display_port: 8097
display_server: http://localhost
display_winsize: 256
epoch: latest
epoch_count: 1
gan_mode: lsgan
gpu_ids: -1
init_gain: 0.02
init_type: normal
input_nc: 3
isTrain: True [default: None]
lambda_A: 10.0
lambda_B: 10.0
lambda_identity: 0.5
load_iter: 0 [default: 0]
load_size: 286
lr: 0.0002
lr_decay_iters: 50
lr_policy: linear
max_dataset_size: inf
model: cycle_gan
n_epochs: 20 [default: 100]
n_epochs_decay: 100
n_layers_D: 3
name: experiment [default: maps_cyclegan]
ndf: 64
netD: basic
netG: resnet_9blocks
ngf: 64
no_dropout: True
no_flip: False
no_html: False
norm: instance
num_threads: 4
output_nc: 3
phase: train
pool_size: 50
preprocess: resize_and_crop
print_freq: 100
save_by_iter: False
save_epoch_freq: 5
save_latest_freq: 5000
serial_batches: False
suffix:
update_html_freq: 1000
verbose: False
----------------- End -------------------
C:\Users\Windows\Anaconda3\lib\site-packages\torchvision\transforms\transforms.py:258: UserWarning: Argument interpolation should be of type InterpolationMode instead of int. Please, use InterpolationMode enum.
"Argument interpolation should be of type InterpolationMode instead of int. "
dataset [UnalignedDataset] was created
The number of training images = 1334
initialize network with normal
initialize network with normal
initialize network with normal
initialize network with normal
model [CycleGANModel] was created
---------- Networks initialized -------------
[Network G_A] Total number of parameters : 11.378 M
[Network G_B] Total number of parameters : 11.378 M
[Network D_A] Total number of parameters : 2.765 M
[Network D_B] Total number of parameters : 2.765 M
-----------------------------------------------
WARNING:root:Setting up a new session...
执行结果
损失变换:

部分结果:


