近来工作上接收到一项任务,实现c++后台服务器程序,要求它能承载千万级别的DAU读写请求。目前实现千万级高并发海量数据请求的服务器设计在”套路“上比较成熟,基本做法是形成服务器集群,然后将海量请求分发到集群中的各个服务器,使得服务器面对的请求数量不再“海量”,本质上就是采用分而治之,各个击破的思维来破解高并发的数据请求。
后台服务器实现的难点之一在于,当服务器程序运行在不同机器上时,服务器之间的数据通信则成为技术难点。假设客户端要上传一张图片,它会将图片数据发送给API服务器程序,后者从数据库服务器集群中选择一台,然后将图片数据发送给数据库服务器进行存储,此时API服务器和数据库服务器之间就发生了相互通讯的需求。在处理海量级别的高并发请求时,例如在微信上一秒钟内,用户可能会上传几十万张图片,于是服务器集群中,不同服务器程序之间的通讯的量级同样也是一秒内几十万分发,因此实现服务器进程间的高并发通讯是让后台能承载海量级请求的关键。
还在于满足这种需求的中间件也很成熟,目前有很多高并发消息队列组件就用于承担这种责任,其中阿帕奇的kafka就是其中佼佼者。消息队列的使用除了能够满足服务器进程之间的高并发通讯外,它还能够实现不同进程之间的解耦合,于是不同后台进程之间在实现时根本无需考虑对方的实现机制,只要确定双方通讯的消息或数据格式即可,这点很类似于面向对象中的接口机制。
我们先从感性上认识kafka的基本功能,也就是跑一次基于kafka的"hello world"。这里我们看的是kafka在mac上的运行。首先从https://kafka.apache.org/downloads下载kafka中间件的运行脚本,下载到本地后是一个tgz压缩包,解压后打开控制台,通过cd命令进入解压的文件路径。kafka的运行要基于服务器集群的控制程序叫zookeeper,因此我们先通过如下命令行启动它:
sh bin/zookeeper-server-start.sh config/zookeeper.properties
接下来要做得就是启动kafka的服务器进程,重新打开新的控制台窗口,cd到指定目录,然后执行下面命令:
sh bin/kafka-server-start.sh config/server.properties
执行上面命令后,kafka消息队列中间件就启动了。现在我们需要做得是让一个进程往队列里发送消息,然后另一个进程从队列中获取消息从而完成不同进程之间的数据通信。发消息的进程叫做生产者,获取或接收消息的进程叫消费者,如果你看过操作系统原理这类书,你一定了解到所谓的生产者-消费者模型。
首先我们启动生产者进程:
sh bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
这个命令的大概意思是,生产者进程启动了一个消息队列叫“test", 这个队列的数据将从端口9092发出,消费者要想获得生产者放入到队列中的数据,它就必须跟生产者通过端口9092建立连接,上面命令执行后,控制台会出现字符"<",也就是进入等待输入状态,这时候我们就可以通过键盘输入字符串信息。我们看消费者的启动命令:
sh bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
通过该命令,消费者就与生产者在端口9092建立连接,我们可以想象消费者和生产者在河岸的两端,队列就是在两岸建立起一座桥梁,汽车从河岸一段上桥后抵达另一端就等同于消息从生产者进程推送到消费者进程,此时我们在生产者进程的控制台窗口输入信息:
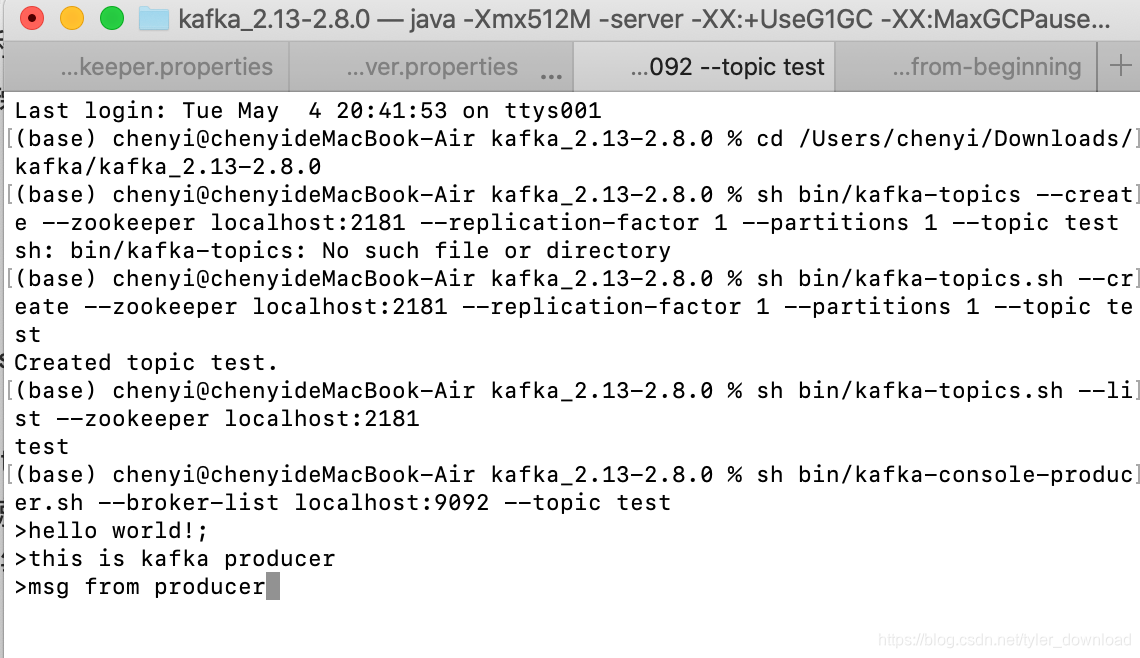
然后按下回车后,我们在消费者进程对应的控制台窗口就可以接收到相应的内容:
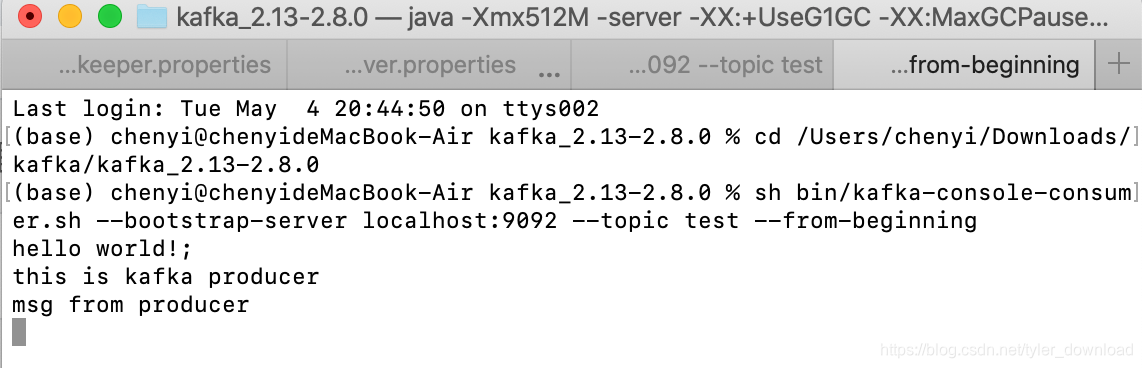
接下来我们看看如何通过python代码的方式实现上面功能,首先要安装相应的python程序库:
pip install kafka-python
然后我们先看生产者对应代码:
from kafka import KafkaProducer
from time import sleep
def start_producer():
producer = KafkaProducer(bootstrap_servers='localhost:9092')
for i in range(0,100000):
msg = 'msg is ' + str(i)
producer.send('my_favorite_topic2', msg.encode('utf-8'))
print('send: ', msg)
sleep(3)
if __name__ == '__main__':
start_producer()
代码很简单,但是有几点需要注意,kafka队列中间件服务器的端口默认是9092,我原来以为任何端口都可以,于是改成9091结果代码运行就错误,类似的我们完成消费者代码如下:
from kafka import KafkaConsumer
import time
def start_consumer():
print('run kafka consumer...')
consumer = KafkaConsumer('my_favorite_topic2', bootstrap_servers = 'localhost:9092')
for msg in consumer:
print(msg)
print("topic = %s" % msg.topic) # topic default is string
print("partition = %d" % msg.offset)
print("value = %s" % msg.value.decode()) # bytes to string
print("timestamp = %d" % msg.timestamp)
print("time = ", time.strftime("%Y-%m-%d %H:%M:%S", time.localtime( msg.timestamp/1000 )) )
if __name__ == '__main__':
start_consumer()
完成代码后,先运行生产者就可以得到如下输出:
topic = my_favorite_topic2
partition = 62
value = msg is 3
timestamp = 1620183897409
time = 2021-05-05 11:04:57
ConsumerRecord(topic='my_favorite_topic2', partition=0, offset=63, timestamp=1620183900412, timestamp_type=0, key=None, value=b'msg is 4', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=8, serialized_header_size=-1)
输出结果中有不少参数,例如partition之类的可以先不用关心。类似kafka这里消息队列中间件除了实现高并发的消息发送外,还采取了很多机制来保证消息必须发送成功,机制之一就是把发送的消息写入到文件或数据库中,发送方必须确认接收方收到消息后才将写入的数据擦除,同时它还能保证消息只会被对方接收一次。
同理运行消费者对应的代码后,所得结果如下:
ConsumerRecord(topic='my_favorite_topic2', partition=0, offset=62, timestamp=1620183897409, timestamp_type=0, key=None, value=b'msg is 3', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=8, serialized_header_size=-1)
topic = my_favorite_topic2
partition = 62
value = msg is 3
timestamp = 1620183897409
time = 2021-05-05 11:04:57
ConsumerRecord(topic='my_favorite_topic2', partition=0, offset=63, timestamp=1620183900412, timestamp_type=0, key=None, value=b'msg is 4', headers=[], checksum=None, serialized_key_size=-1, serialized_value_size=8, serialized_header_size=-1)
这些消息队列中间件的诞生,其实跟当下云后台的开发模式有关。当前后台开发喜欢采用所谓的“微服务”模式,我搜索过这个概念发现其没有明确的定义,各家各有说法,莫衷一是。我的理解是,所谓微服务就是把原来服务器程序所实现的各个功能分解开来,独立形成一个服务器小程序,当模块间需要相互配合时,就可以通过消息队列的机制把数据发送给对方。
例如在微信中发送附件给别人时,用户在手机上将文件上传到服务器,此时有一个服务器小程序A来接收用户要上传文件的消息,然后它用消息通知数据库服务器程序B,让后者把附件存储到数据库中,接着接着A又发送一个消息给服务器程序C,让C通知对应的接受者有文件传递给他,这种机制的最大优点就是能将原本衔接在一起的功能模块解耦合,使得每个模块各自为政,于是增强了后台的可扩展性和鲁棒性。