CRNN
本项目是PaddlePaddle 2.0动态图实现的CRNN文字识别模型,可支持长短不一的图片输入。CRNN是一种端到端的识别模式,不需要通过分割图片即可完成图片中全部的文字识别。CRNN的结构主要是CNN+RNN+CTC,它们分别的作用是,使用深度CNN,对输入图像提取特征,得到特征图。使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布。使用 CTC Loss,把从循环层获取的一系列标签分布转换成最终的标签序列。

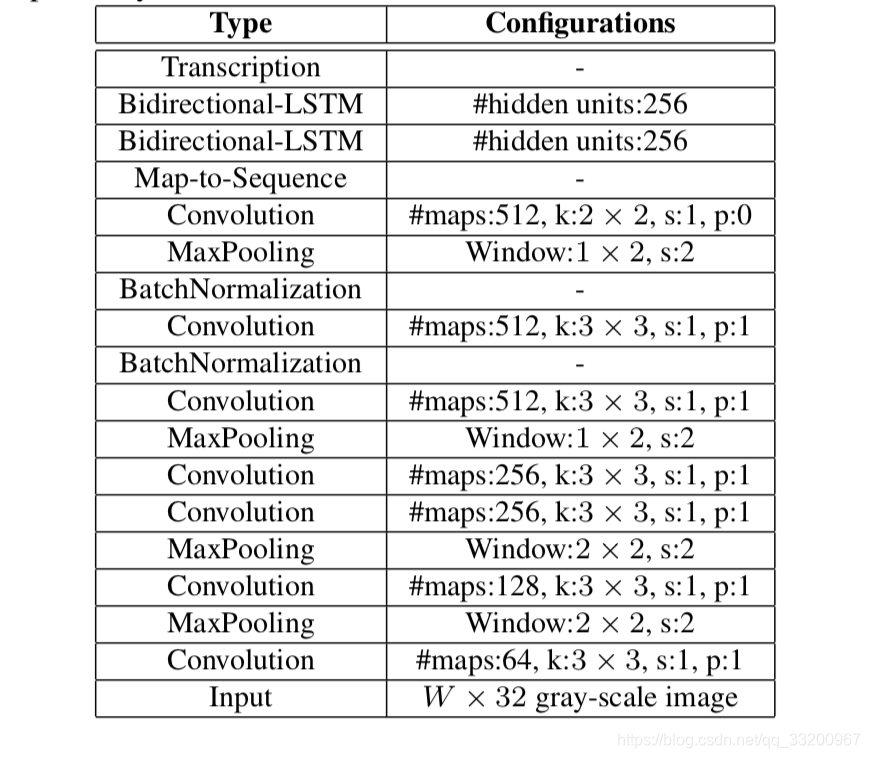
CRNN的结构如下,一张高为32的图片,宽度随意,一张图片经过多层卷积之后,高度就变成了1,经过paddle.squeeze()就去掉了高度,也就说从输入的图片BCHW经过卷积之后就成了BCW。然后把特征顺序从BCW改为WBC输入到RNN中,经过两次的RNN之后,模型的最终输入为(W, B, Class_num)。这恰好是CTCLoss函数的输入。
使用环境:
- PaddlePaddle 2.0.1
- Python 3.7
源码地址:https://github.com/yeyupiaoling/PaddlePaddle-CRNN
在线运行一下:https://aistudio.baidu.com/aistudio/projectdetail/1751953
准备数据集
- 贴心的笔者准备了一个生成长度不一的验证码图片作为数据集,该程序可以自动生成图片以及数据列表和数据词汇表,需要读者修改自己字体文件的路径
font_path,网上下载一搜一大把,笔者用的是这个字体点击下载 。
python create_image.py
执行上面程序生成的图片会放在dataset/images目录下,生成的训练数据列表和测试数据列表分别放在dataset/train_list.txt和dataset/test_list.txt,最后还有个数据词汇表dataset/vocabulary.txt。
数据列表的格式如下,左边是图片的路径,右边是文字标签。
dataset/images/1617420021182_c1dw.jpg c1dw
dataset/images/1617420021204_uvht.jpg uvht
dataset/images/1617420021227_hb30.jpg hb30
dataset/images/1617420021266_4nkx.jpg 4nkx
dataset/images/1617420021296_80nv.jpg 80nv
以下是数据集词汇表的格式,一行一个字符,第一行是空格,不代表任何字符。
f
s
2
7
3
n
d
w
训练自定义数据,参考上面的格式即可。
训练
不管你是自定义数据集还是使用上面生成的数据,只要文件路径正确,即可开始进行训练。该训练支持长度不一的图片输入,但是每一个batch的数据的数据长度还是要一样的,这种情况下,笔者就用了collate_fn()函数,该函数可以把数据最长的找出来,然后把其他的数据补0,加到相同的长度。同时该函数还要输出它其中每条数据标签的实际长度,因为损失函数需要输入标签的实际长度。
python train.py
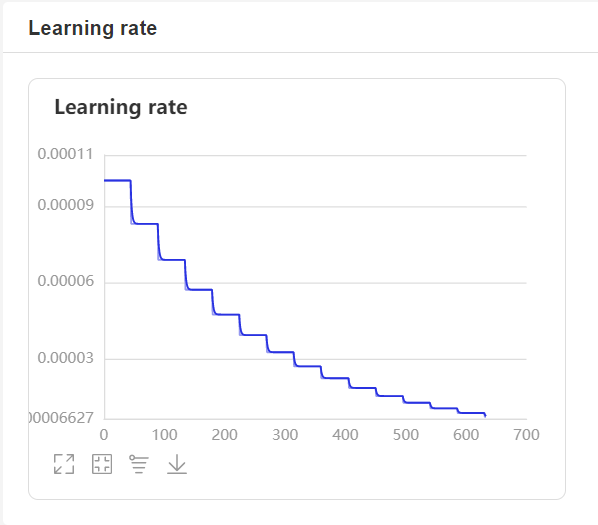
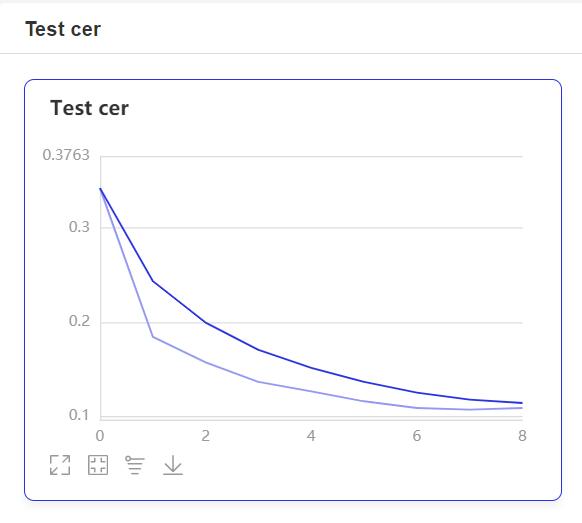
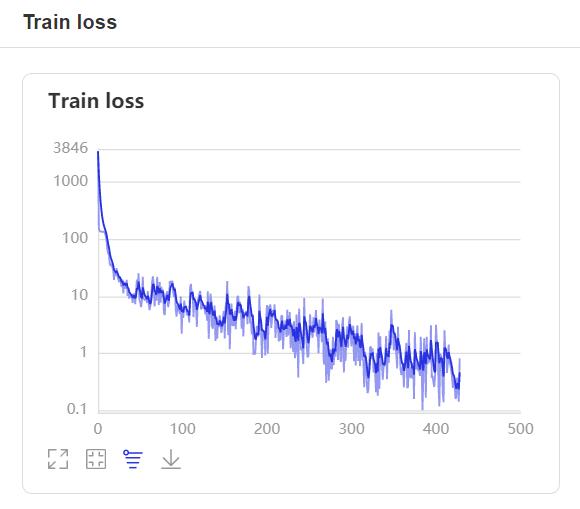
- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host=0.0.0.0
- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
预测
训练结束之后,使用保存的模型进行预测。通过修改image_path指定需要预测的图片路径,解码方法,笔者使用了一个最简单的贪心策略。
python infer.py
输出如下:
预测结果:2gmnt93e