百度飞桨顶会论文复现营DETR解读笔记
目标检测两个关键子任务:目标分类和目标定位。
DETR模型是将目标检测视为集合预测(set prediction)的方式,将训练和预测做到真正的端对端,不需要NMS的后处理,也不需要人为设置anchor。核心是1.set-based的全局Loss,使用二分图匹配生成唯一的预测;2.基于encoder-decoder的transformer。

CNN代表图像特征编码的backbone,transformer后面的输出是最终预测的结果集合,transformer会对集合后的每一个结果都做一个分类和回归,每个集合都会输出表示预测框位置的4个坐标长度信息和C+1个类别信息(背景也算一个信息,没有目标的背景也会有相应的预测框和类别)。
DETR在decoder后会输出N个预测集合,每个都会有相应的预测框位置和类别,这个数量N要远远大于实际目标的数量。如何将输出的N个预测集合与实际groundtruth目标的位置对应起来呢?DETR采用了二分图匹配,找到N个预测集合中最优匹配groundtruth的那个解。
二分图匹配:对于没有实际类别的集合,将其类别设置为no object,这样实际有目标的预测集合与类别为no object的集合数量加起来就是N了,接下来学习参数使得预测集合与groundtruth之家的loss最小,根据下图公式(1)计算,该公式求解使用的是Hungarian算法,同时考虑类别损失,框回归损失和交并比损失,最终定义了(2)中的公式。
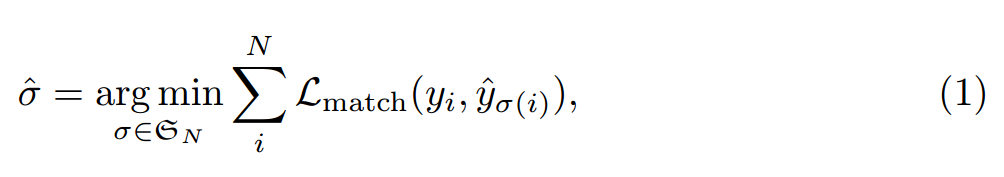
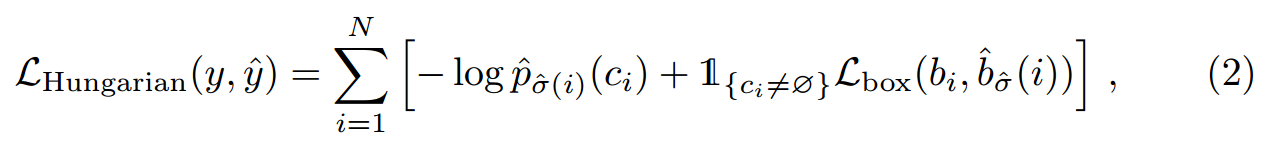
公式意思就是如果预测和标注都是是no object那该预测就不计算损失值,如果预测和标注的类别与包围框都是吻合情况下损失值是最小的,如果类别和包围框没有完全吻合,损失值是最高的。
通过公式(1)的二分图匹配使得总体的损失值最小,公式(2)用来计算具体损失。公式(2)中的两项分别计算类别损失和包围框损失,分类损失使用了交叉熵损失函数,包围框损失是L1损失和IOU损失的加权和,加上IOU损失是为了让损失函数不依赖于包围框的大小,两种损失都是回归损失,为了计算两个包围框的重合程度。
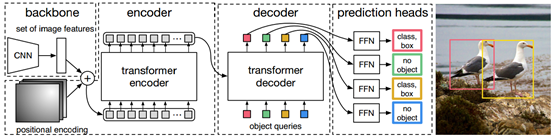
DETR结构:包括三个部分1.提取图像特征的CNN backbone,可以用主流的图像编码网络例如ResNet50等;2.编码-解码的transformer,编码区常带有position encoding,解码器中输入了object queries;3.用来预测最终目标的前馈网络FFN是一个简单的三层前馈网络。
CNN处理后图像的尺寸变少为H×W,但是通道会增加到C,提取了特征,将提取得到的特征输入到transformer中。得到的CNN特征后首先需要将尺寸为C×H×W二维feature map变换为一维形式,因此会得到C个长度为H×W的一维embedding,将这些特征送入encoder中。
由于transformer中用到attention机制,因此输入的每一个embedding都会获得其他所有embedding的信息。encoder的输出会送入到decoder中,encoder也可以理解为特征映射,将CNN得到的特征空间映射到另一个特征空间中。decoder中还有输入object queries,这个可以看作是decoder的位置表达。
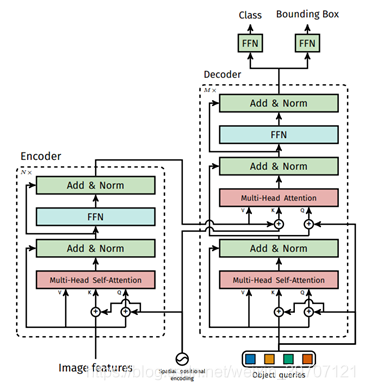
DETR中transformer的详解结构解释:损失值方面使用了辅助的decoding loss,即在每个decoder层之后添加预测FFN和Hungarian损失。所有预测FFN均共享参数。object queries是N个随机初始化的向量然后通过训练得到,抽象理解算是传统模型中anchor的作用。本文将object query进行了可视化,如下图是可视化了其中20个object query,可以认为是每个object query都学到了一些东西,理解为每个object query都是一个人在不同角度提问,关注图像中不同的位置,例如图中绿色的区域就表示询问了图像中这个位置是什么物体,这个也就是注意力机制的影响,使用注意力机制关注图像中某一区域,然后得到该区域的信号,将这些信号和自己本身的信号合并,发送query向量,在encoder得到的embedding中进行查询获得value向量。经过以上部分,这几个query就会学会对整个数据集进行提问,输出对于他们感兴趣区域的最佳预测。通过训练可以从不同角度关注图像同的不同区域。encoder中输入和输出都是CNN得到的feature map的通道数量,而object query数量是自己设定的。

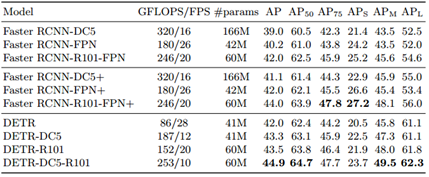
最终的实验结果在大目标检测中提升很明显,在小目标中比Faster R-CNN差一些。

还有不同transformer-encoder层数对结果的影响。

对注意力矩阵进行可视化,得到transformer-encoder的热图。看得出图中的所有目标都被transformer注意到了,这也是注意力机制带来的优势。
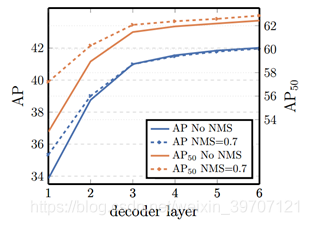
还探究了在decoder输出结果添加NMS对于结果的影响,可以发现DETR使用结合预测的方式在不进行后处理的情况下就达到很好的效果。

对decoder部分也做了注意力热图。

还有损失值对于结果的影响。分类损失这里是交叉熵损失函数计算softmax得到概率分布,回归损失是IOU和L1损失的加权和,看得出使用两种损失的加权和效果最好。

应用在全景分割效果也很好。