
PS:大司马金轮,技术教程:点击查看
大家好,我是 Jack。
承诺的图解 AI 算法系列教程,今天咱们继续!
这个系列一直写的比较随性,想写哪个算法就写了哪个,毫无章法。
「修炼开始」一文带你入门深度学习
保姆级教程:硬核图解Transformer
嘿,来聚个类!
好在,文章质量都还不错,虽然硬核了点,但从各方面的反馈来看,还是有不少朋友喜欢看的。
今天,聊一聊人工智能,计算机视觉方向的重头戏。
我们都知道,CV 领域最常规的三大任务是:图像分类、目标检测、图像分割。
图像的分类和分割算法实战教程,我在2019年就出过了,想看可以往前翻一翻。
目前,就差目标检测还没写过,虽迟但到,今天它来了!
目标检测
目标检测,应用非常广,是非常重要的技术储备。
目标检测落地场景丰富,可用度非常高,人脸识别、智能安防系统、无人驾驶、无人机等各个领域,目标检测都是核心技术。
举个例子,无人机领域,画面中的车辆、行人等目标的检测。

军事上,目标的精准打击,也都有目标检测的身影。
生活上,我们也可以利用检测做很多事情,随手一拍。

目标检测检测出物体,车辆、树木,可能有些人会问,这个检测出来有啥用?
那要是在此基础上,再识别出这些是什么车、什么树?
宝马,奥迪,还是比亚迪?
杨树,柳树,还是白杨树?
再比如,什么品种的猫猫狗狗,什么品牌的衣帽鞋袜。
万物皆可识别,只需随手一拍。这就是很多做视觉的公司,都在做的重点方向。
这也是,目标检测+细分类的技术应用的场景之一。先检测出画面中的目标,再将检测出的目标送入更细粒度的分类网络,识别出堪比人,甚至远超人的精细水平。
目标检测,专业一点的概念就是:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。

基于深度学习的目标检测算法主要分为两类:
-
Two Stage:两阶段目标检测
-
One Stage:端到端目标检测
Two Stage
Two Stage 是2013年到2015年的主流算法,后来逐渐发展为 One Stage 端到端的目标检测算法。
Two Stage 算法是先进行区域生成,该区域称之为 region proposal(简称RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。
任务流程:特征提取 --> 生成RP --> 分类/定位回归。
常见 Two Stage 目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN 和 R-FCN 等。
One Stage
不用 RP,直接在网络中提取特征来预测物体分类和位置。
任务流程:特征提取–> 分类/定位回归。
常见的 One Stage 目标检测算法有:YOLO 系列、SSD 系列、Anchor Free 系列等。
如今,比较常用、实用的目标检测算法都是 One Stage 的。
从前,一般讲解目标检测都是从两阶段的 R-CNN 系列开始,但说实话,有些老了,一阶段的 YOLO 从 v1 都发展到 v5 了。
但并不代表 Faster R-CNN 这些就没有学的必要,目标检测的基础,还是很有必要学习一番的,并且不少公司其实还在用这些算法。
现在,一般公司面试,都爱问 YOLO 系列的算法,YOLO v4、YOLO v5 这些。
今天,先来个比较基础的,我们从 YOLO v1 谈起。
YOLO v1
YOLO 的名字还是很霸气的:You Only Look Once。
YOLO 之父是 Joseph Redmon,v1 - v3 是他的作品,篇篇顶会,性能也是,开源口碑非常好。

可惜,发布完 v3 就退圈了,后续的 v4 - v5 ,都是其他团队接手了。
在讲解 YOLO v1 之前,重申一下我们的任务:在一张图片中找出物体,并给出它的类别和位置。

YOLO v1 的核心思想是:采用利用整张图作为网络的输入,直接在输出层回归 bounding box 的位置和 bounding box 所属的类别。
为了照顾新人,这里解释下 bounding box ,即检测框,就是目标外围带颜色的框框,一般简称 bbox。
YOLO v1 的实现,是将一幅图像分成 SxS 个网格(grid cell)。
哪个目标物体的中心落在这个网格中,则这个网格负责预测这个目标。

论文中,是将图像分为 7x7 的网格,即上文中的 S=7。如上图所示,红色的点,就是负责检测狗的。
网络结构
YOLO v1目标检测一共三个步骤:

-
resize图片尺寸
-
输入网络,出结果
-
NMS
第一步,resize 很好理解,属于深度学习的常规操作,就是为了将不同尺寸的图片适配到统一的网络结构中,需要 resize 到相同的尺寸。
论文提出的这个网络结构,输入层的尺寸是 448x448,因此在将图片送入网络前,需要将图片 resize 到 448x448。
我们直接看下网络结构,精髓都在这里:
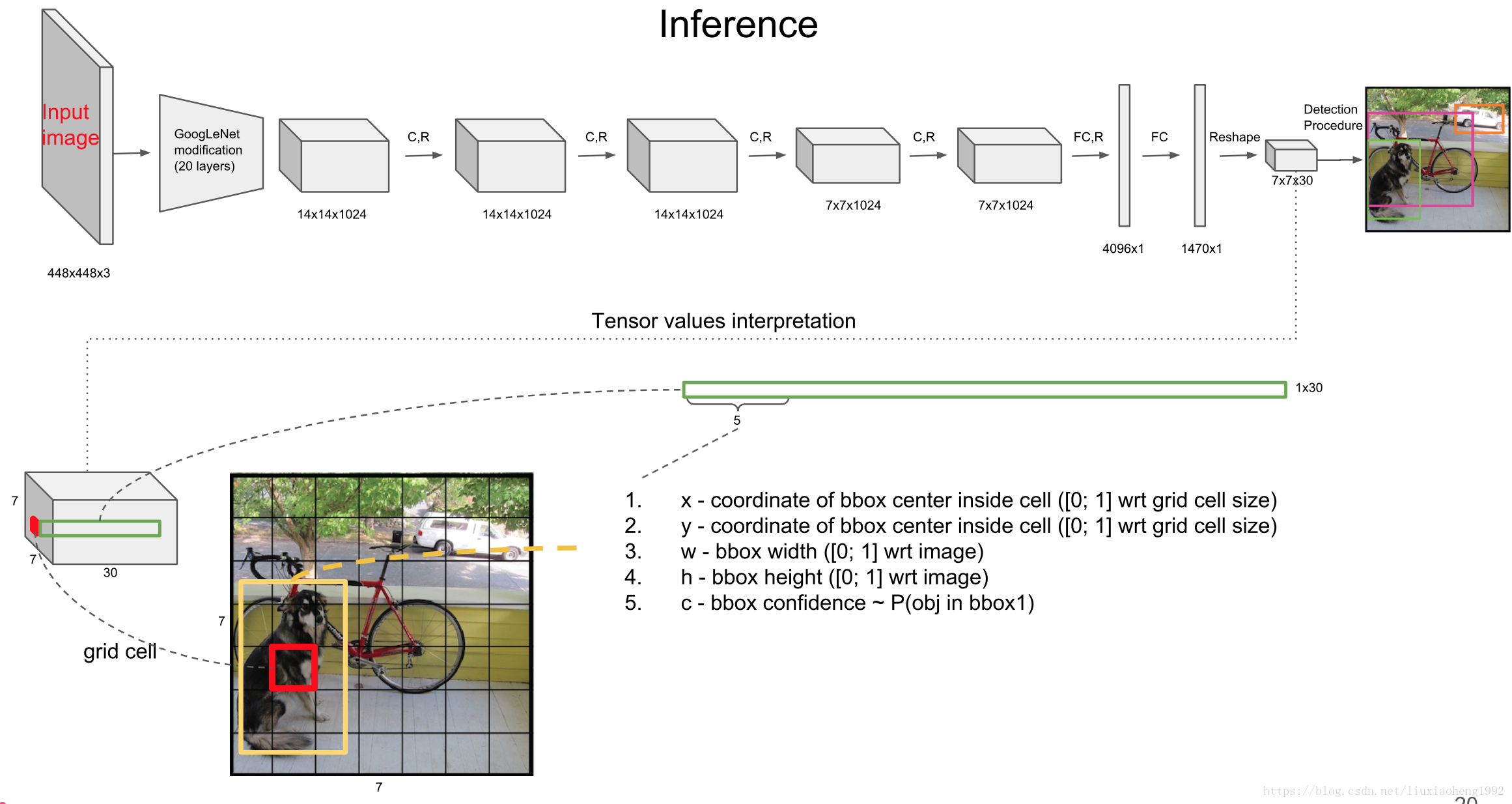
这里设计得很巧妙,可以看到网络的最终输出是 7×7×30。还是以这个狗为例,7x7 很好理解,图像分为 7x7 个区域进行预测。
最终输出 tensor 的前五个数值,分别是 bbox 的 x,y,w,h,c,即 bbox 的中心坐标 x,y,bbox 的宽高 w,h,bbox 的置信度。
置信度就是算法的自信心得分,越高表示越坚信这个检测的目标没错。
而一个中心点,会检测 2 个 bbox ,这个操作可以减少漏检,因为可以适应不同形状的 bbox,进而提高bbox 的准确率。

2 个 bbox 都会保留,最后通过 NMS 选择出最佳的 bbox,这个操作最后再讲。
而后面的 20 个,就是类别的概率,YOLO v1 是在 VOC 数据集上训练的,因此一共 20 个类。
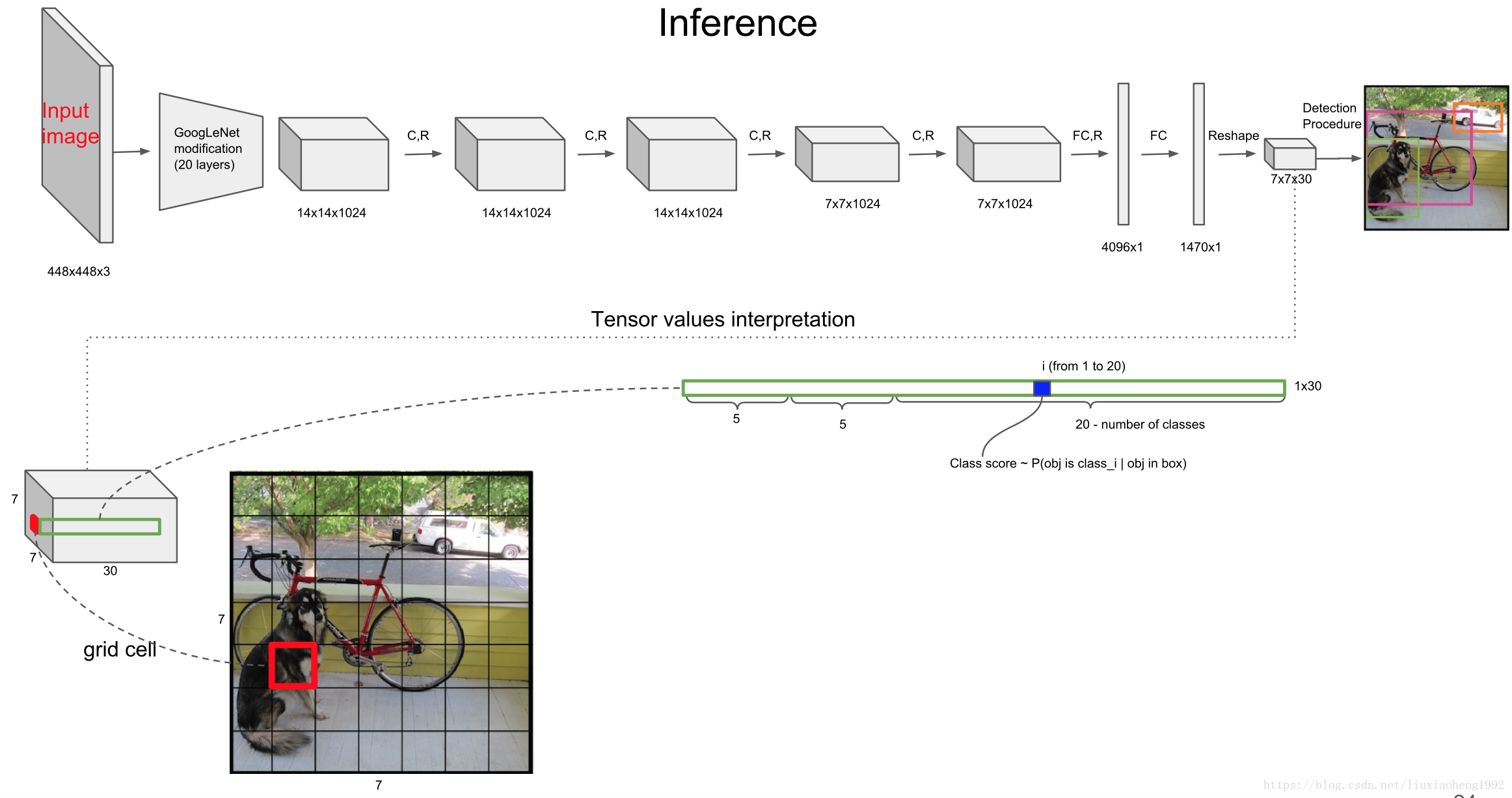
因此,tensor 总共加起来就是 7×7×(2×5+20),写成公式就是:SxSx(Bx5+C)。
这里的问题,可以当作回归问题来解决的。所有的输出包括坐标和宽高都定义在0到1之间。
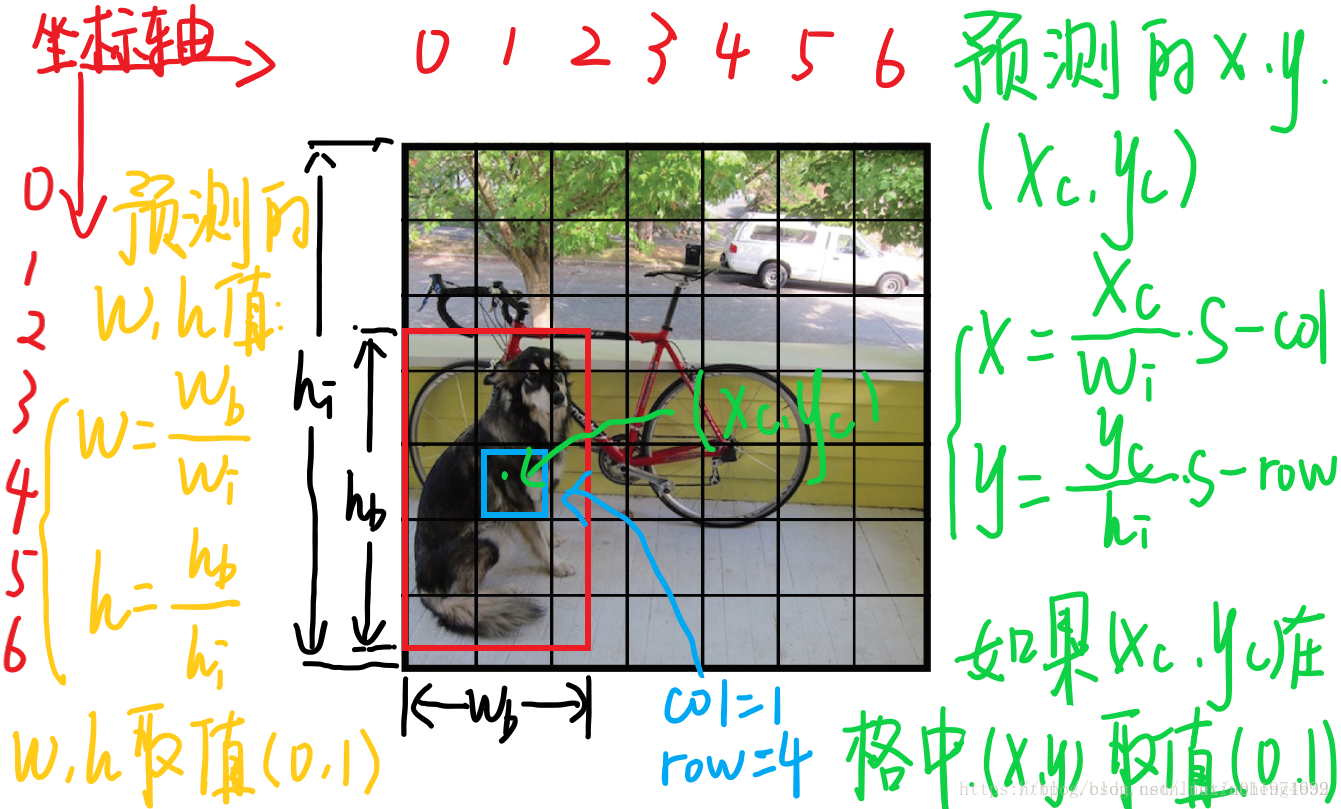
来看一下每个单元格预测的B个(x,y,w,h,confidence)的向量和C的条件概率中,每个参数的含义(假设图片宽为高为,将图片分为:
(x,y)是bbox的中心相对于单元格的offset
对于下图中蓝色框的那个单元格坐标为,假设它预测的输出是红色框的bbox,设bbox的中心坐标为,那么最终预测出来的是经过归一化处理的,表示的是中心相对于单元格的offset,计算公式如下:
(w,h)是bbox相对于整个图片的比例
预测的 bbox 的宽高为 ,表示的是 bbox 的是相对于整张图片的占比,计算公式如下:
confidence
这个置信度是由两部分组成,一是格子内是否有目标,二是bbox的准确度。定义置信度为 Object 。
这里,如果格子内有物体,则 Object ,此时置信度等于IoU。如果格子内没有物体,则 Object ,此时置信度为0。
C类的条件概率
条件概率定义为 Class Object ,表示该单元格存在物体且属于第 i 类的概率。
在测试的时候每个单元格预测最终输出的概率定义为:
NMS
经过网络处理后,将 的结果送入 NMS ,最后即可得到最终的输出框结果。
NMS,即非极大值抑制,就是将一些冗余框去掉,示意图如下:

NMS 别看简单,面试常考题,比如动手实现一个 NMS 代码之类的。
这个概念千万不要懵懵懂懂,细节决定成败。省着被嘲讽:NMS都不会,做什么Detection!

学 NMS ,先要理解 IOU。
IOU 即Intersection over Union,也就是两个box区域的交集比上并集,下面的示意图就很好理解,用于确定两个框的位置像素距离。

-
首先计算两个box左上角点坐标的最大值和右下角坐标的最小值
-
然后计算交集面积
-
最后把交集面积除以对应的并集面积
就这简单,NMS 就是通过计算 IOU 来去除冗余框的,具体的实现思路如下。
以下图为例,进行说明:

就像上面的图片一样,定位一个车辆,最后算法就找出了一堆的方框,我们需要判别哪些矩形框是没用的。
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于车辆的概率 分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
代码实现:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
#x1、y1、x2、y2、以及score赋值
x1 = dets[:, 0] # pred bbox top_x
y1 = dets[:, 1] # pred bbox top_y
x2 = dets[:, 2] # pred bbox bottom_x
y2 = dets[:, 3] # pred bbox bottom_y
scores = dets[:, 4] # pred bbox cls score
#每一个检测框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1) # pred bbox areas
order = scores.argsort()[::-1] # 对pred bbox按score做降序排序,对应step-2
#保留的结果框集合
keep = []
while order.size > 0:
i = order[0] # top-1 score bbox
keep.append(i) #保留该类剩余box中得分最高的一个
#得到相交区域,左上及右下
xx1 = np.maximum(x1[i], x1[order[1:]]) # top-1 bbox(score最大)与order中剩余bbox计算NMS
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积,不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算IoU:重叠面积 /(面积1+面积2-重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#保留IoU小于阈值的box
inds = np.where(ovr <= thresh)[0] # 这个操作可以对代码断点调试理解下,结合step-3,我们希望剔除所有与当前top-1 bbox IoU > thresh的冗余bbox,那么保留下来的bbox,自然就是ovr <= thresh的非冗余bbox,其inds保留下来,作进一步筛选
#因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位
order = order[inds + 1] # 保留有效bbox,就是这轮NMS未被抑制掉的幸运儿,为什么 + 1?因为ind = 0就是这轮NMS的top-1,剩余有效bbox在IoU计算中与top-1做的计算,inds对应回原数组,自然要做 +1 的映射,接下来就是step-4的循环
return keep # 最终NMS结果返回
if __name__ == '__main__':
dets = np.array([[100,120,170,200,0.98],
[20,40,80,90,0.99],
[20,38,82,88,0.96],
[200,380,282,488,0.9],
[19,38,75,91, 0.8]])
py_cpu_nms(dets, 0.5)
LOSS
从图片 resize 到网络结构,再到 NMS 都讲完了,最后再说下算法的重中之重,损失函数。
损失函数是一个复合损失函数,一共是 5 项相加:
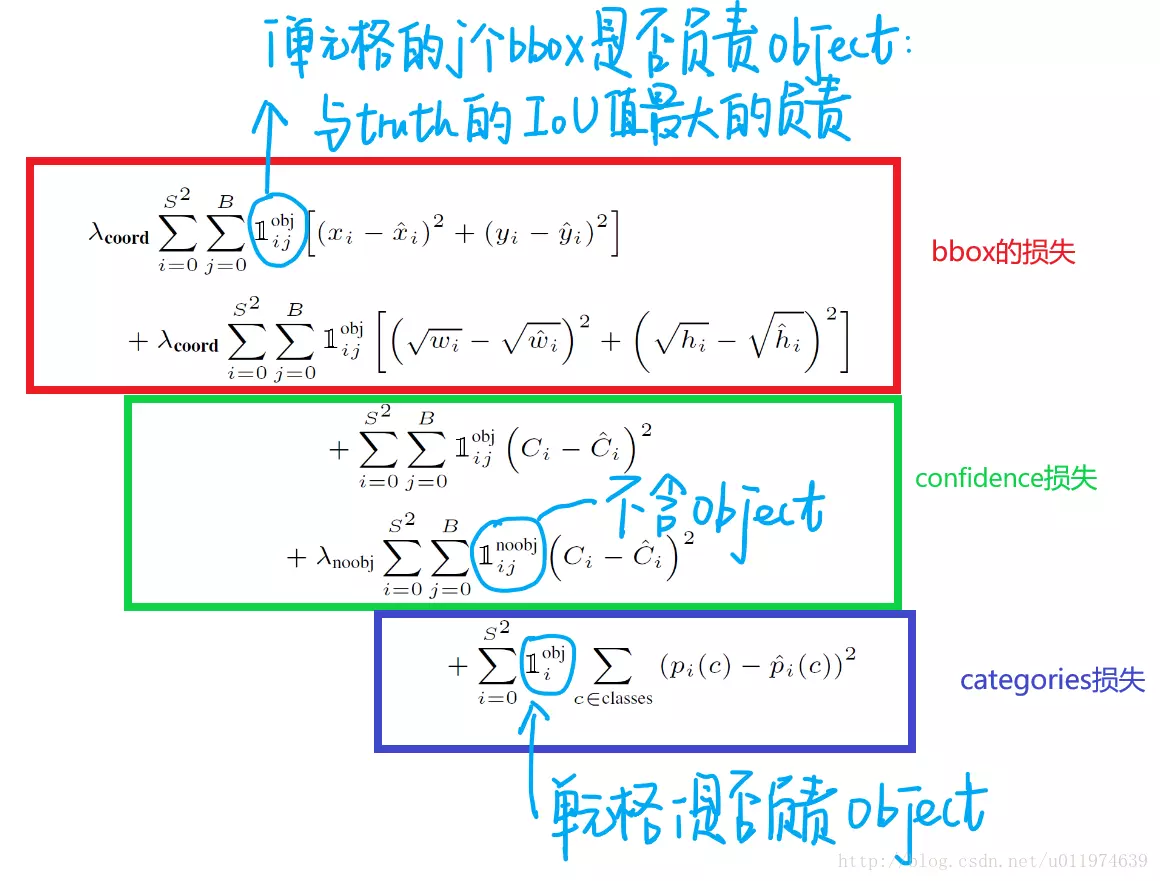
更详细的注释,可以看这张图:
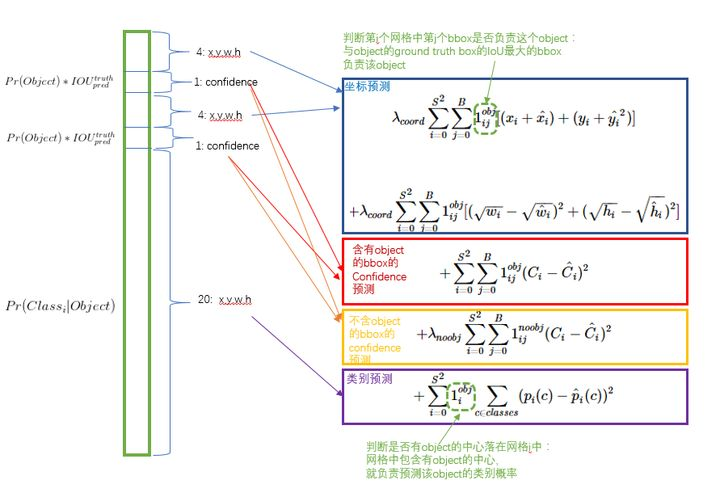
简单解释下:
所有的损失都是使用平方和误差公式,暂时先不看公式中的 与 ,输出的预测数值以及所造成的损失有:
-
预测框的中心点 。造成的损失是图五中的第一行。其中 为控制函数,在标签中包含物体的那些格点处,该值为 1 ;若格点不含有物体,该值为 0。也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。 数值与标签用简单的平方和误差。
-
预测框的宽高 。造成的损失是图五的第二行。 的含义一样,也是使得只有真实物体所属的格点才会造成损失。这里对 在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20 个像素点的偏差,对于 800x600 的预测框几乎没有影响,此时的IOU数值还是很大,但是对于 30x40 的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
-
第三行与第四行,都是预测框的置信度C。当该格点不含有物体时,即 =1, 该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(IOU计算公式为:两个框交集的面积除以并集的面积)。
-
第五行为物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
此时再来看 与 ,YOLO 面临的物体检测问题,是一个典型的类别数目不均衡的问题。其中 49 个格点,含有物体的格点往往只有 3、4 个,其余全是不含有物体的格点。此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。 与 的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。在论文中, 与 的取值分别为 5 与 0.5 。
最后
YOLO v1 的代码实现,有很多,Pytorch 和 Tensorflow 等各种版本都有,因为毕竟属于出名算法。
Github 一搜,找个 Star 高的即可。
最后再送大家一本,帮助我拿到 BAT 等一线大厂 offer 的数据结构刷题笔记,是一位 Google 大神写的,对于算法薄弱或者需要提高的同学都十分受用:
谷歌和阿里大佬的Leetcode刷题笔记
以及我整理的 BAT 算法工程师学习路线,书籍+视频,完整的学习路线和说明,对于想成为算法工程师的,绝对能有所帮助(提取码:jack):
我是如何成为算法工程师的,超详细的学习路线
PS:大司马金轮,技术教程:点击查看
别光收藏,来个赞哦,笔芯~
我是 Jack,我们下期见~