一、前言
深度学习系列文章陆陆续续已经发了两篇,分别是激活函数篇和卷积篇,纯干货分享,想要入门深度学习的童鞋不容错过噢!书接上文,该篇文章来给大家介绍“ 选择对象的标准 ”-- 损失函数,损失函数种类繁多,各式各样,不仅包括单损失函数,而且也包括多损失函数,但是最常使用的还是经典的均方误差损失函数和交叉熵损失函数,所以本篇文章重点介绍这两种损失函数,至于其余单损失函数和多损失函数,我也会简单介绍一下,并提供相应的经典论文供大家自行阅读!

二、什么是损失函数、为什么使用损失函数
其实,我们在现实生活中会在无形之中已经为某些事情制作了判定标准,比如如果有人问你现在有多幸福,你会如何回答呢?一般的人可能会给出诸如“还可以吧”或者“不是那么幸福”等笼统的回答。如果有人回答“我现在的幸福指数是10.23”的话,可能会把人吓一跳吧。因为他用一个数值指标来评判自己的幸福程度。这里的幸福指数只是打个比方,实际上神经网络的学习也在做同样的事情。
神经网络的学习通过某个指标表示现在的状态。然后,以这个指标为基准,寻找最优权重参数。和刚刚那位以幸福指数为指引寻找“最优人生”的人一样,神经网络以某个指标为线索寻找最优权重参数。神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。以“性能的恶劣程度”为指标可能会使人感到不太自然,但是如果给损失函数乘上一个负值,就可以解释为“在多大程度上不坏”,即“性能有多好”。并且,“使性能的恶劣程度达到最小”和“使性能的优良程度达到最大”是等价的,不管是用“恶劣程度”还是“优良程度”,做的事情本质上都是一样的。
三、单损失函数
3.1 均方误差损失函数
可以用作神经网络损失函数的函数有很多,其中最有名的莫过于均方误差了,均方误差如下式所示:
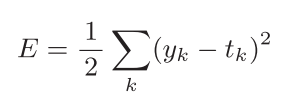
yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。
3.2、交叉熵损失函数
相较于均方误差损失函数,交叉熵损失函数在实际应用中用的会更多,在这一年的学习研究深度学习过程中,看过的论文中,若使用单损失函数,绝大多数都会用到交叉熵损失;即使是多损失函数,交叉熵函数也会是其中一部分,这足以说明交叉熵函数在深度学习领域的重要地位。交叉熵损失函数如下式表示:
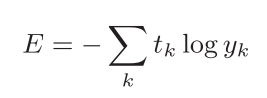
log表示以e为底数的自然对数(log e)。yk是神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为0。
当然,另一种表示形式会将交叉熵损失解释的更加直白一些,另一种表示形式如下:
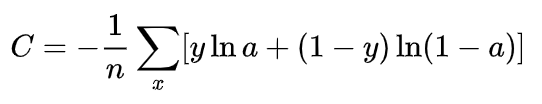
Note:(如何理解交叉熵损失,这很重要)
-
当y=1时,C = -loga。我们肯定是想让-loga尽可能地小,这就意味着,loga要尽可能地大,这也意味着a要足够大,但a再大也不可能大于1,所以,我们想要a尽可能地接近1。
-
当y=0时,C = -log(1-a)。我们肯定是想让-log(1-a)尽可能地小,这就意味着,log(1-a)要尽可能地大,这也意味着a要足够小,但a再小也不可能小于0,所以,我们想要a尽可能地接近0。
3.3 绝对值损失函数
绝对值损失函数是计算预测值与目标值的差的绝对值,该损失函数在深度神经网络中用的非常少,基本可以忽略不记了。
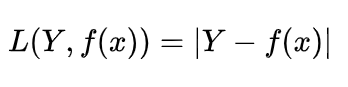
3.4 对数损失函数
对数损失函数的标准形式如下:
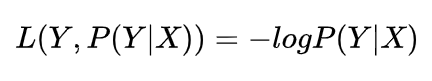 ‘
‘
(1) log对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合。
(2) 健壮性不强,相比于hinge loss对噪声更敏感。
(3) 逻辑回归的损失函数就是log对数损失函数。
引用
3.5 指数损失函数
指数损失函数的定义如下:
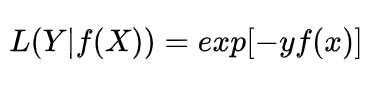
该损失函数地特征是对离群点、噪声非常敏感。但经常用在AdaBoost算法中。
推荐论文
推荐的论文都是深度学习方面的经典论文,非常适合深度学习入门。论文的写法,如何做消融实验都值得大家去学习。这些论文中使用的损失函数绝大多数都是交叉熵损失函数,从这里足以看出交叉熵损失函数的重要之处。
《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
《Network In Network》
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
《Dense Fully Convolutional Network for Skin Lesion Segmentation》
四、多损失函数
多损失函数常用于多分枝的网络模型中。这些模型中,大多数都设计了两个分支,例如一个分支用来提取上下文特征信息,另一分支用于提取边缘信息,两者信息显然是不同的,所以需要设计两个损失函数分别来对网络模型进行计算。在这里,我会分享一些前沿的论文供大家参考阅读。
推荐论文
《Skin lesion segmentation via generative adversarial networks with dual discriminators》
《MATTHEWS CORRELATION COEFFICIENT LOSS FOR DEEP CONVOLUTIONAL NETWORKS: APPLICATION TO SKIN LESION SEGMENTATION》
参考文献
《深度学习入门 - 基于Python的理论与实现》
https://zhuanlan.zhihu.com/p/58883095
《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》
《Network In Network》
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
《Dense Fully Convolutional Network for Skin Lesion Segmentation》
《Skin lesion segmentation via generative adversarial networks with dual discriminators》
《MATTHEWS CORRELATION COEFFICIENT LOSS FOR DEEP CONVOLUTIONAL NETWORKS: APPLICATION TO SKIN LESION SEGMENTATION》
计划 – 深度学习系列
都2021年了,不会还有人连深度学习还不了解吧?(一)-- 激活函数篇
都2021年了,不会还有人连深度学习还不了解吧?(二)-- 卷积篇
都2021年了,不会还有人连深度学习还不了解吧?(三)-- 损失函数篇
都2021年了,不会还有人连深度学习还不了解吧?(四)-- 上采样篇
都2021年了,不会还有人连深度学习还不了解吧?(五)-- 下采样篇
都2021年了,不会还有人连深度学习还不了解吧?(六)-- Padding篇
都2021年了,不会还有人连深度学习还不了解吧?(七)-- 评估指标篇
都2021年了,不会还有人连深度学习还不了解吧?(八)-- 优化算法篇
都2021年了,不会还有人连深度学习还不了解吧?(九)-- 注意力机制篇
都2021年了,不会还有人连深度学习还不了解吧?(十)-- 数据归一化篇
觉得写的不错的话,欢迎点赞+评论+收藏,这对我帮助很大!
