《基于深度强化学习的紧急订单生产控制方法研究》
#基于深度强化学习的紧急订单生产控制方法研究[D]. 刘民毅.东南大学 . 2018
这篇文章结合深度强化学习在智能学习和决策上的优势,在柔性作业车间环境下探究多工件智能体通过探索学习,以总体奖励为强化信号,实现协作生产的可行性,为紧急订单的生产调度问题提供新的智能化求解思路。
研究工作如下:
(1)对智能体的动作探索策略进行了研究,并针对柔性作业车间环境调整了贪婪策略和Softmax策略,实现了多智能体在学习过程中对于探索和利用的权衡。
(2)针对简单和复杂柔性作业车间环境下的单工件加工路径的寻优问题,分别使用了深度强化学习中的DQN算法和Actor Critic算法进行求解,将工件智能体在作业车间中的状态和动作进行了编码定义,并针对不同的作业环境设置了相应的奖罚函数,DQN算法使用了经验回放的方式进行更新学习,A才通人C日提出算法使用了但不更新的方式。实现了工件智能体通过自学习,掌握加工路径寻优的最佳策略。
(3)在柔性作业车间环境下,针对紧急订单调度问题,设计了区间调度策略。通过调度区间的划分,将紧急订单调度问题转化为传统的柔性作业车间调度问题,并设计了离散动作输出的多智能体Actor Critic方法,以工件平均奖励期望作为强化信号,实现了工件智能体之间的协作生产,从分体现了方法的良好学习能力,级工件智能体可以在不受指导的情况下,通过搜索实现彼此的协作生产,为企业的智能生产调度提供了理论基础。
1 强化学习与深度学习
1.1强化学习概述
1.1.1智能体的概念
Agent是驻留于环境中的实体,它可以解释从环境中获得的反映环境中所发生事件的数据,并执行对环境产生影响的行动。
1.1.2强化学习的基本概念
强化学习(Reinforcement Learning,RL)又称再励学习、评价学习,是马尔可夫决策过程(Markov Decision Process,MDP)和动态优化方法的一个分支。同时也是机器学习的一个重要领域。强化学习的灵感来源于心理学中的行为主义理论,即个体如何在环境给予的奖励或惩罚刺激下,逐渐形成对刺激的预期,从而产生能获得最大奖励的习惯行为,是一个“交互-试错”的学习方法。
强化学习系统的基本框架主要由两部分构成,即环境和智能体。智能体不断利用环境中的反馈信息来改善其性能,同时从经验中获取状态动作规则。试错搜索和延迟回报是强化学习的两个最显著的特征,该系统具有以下特点:
(1)适应性,智能体不断利用环境中的反馈信息来改善其性能。
(2)反应性,智能体可以从经验中直接获取状态动作规则。

强化学习的主要方法有:蒙特卡洛方法、时序差分方法、Sarsa、Q学习、策略梯度等,可以从以下角度进行分类:

强化学习算法基本都是针对离散状态和行为空间马尔可夫决策过程,即状态的值函数或者行为的值函数采用表格的形式存储和迭代计算。但实际工程中的许多优化决策问题都具有大规模和连续的状态和行为空间,因此表格型强化学习也存在类似动态规划的维数灾难。
强化学习与其他机器学习的比较:

1.2 深度强化学习概述
1.2.1 深度强化学习基本概念
在深度强化学习中,深度学习负责表示马尔可夫决策过程的状态,强化学习负责把控学习的方向。同时,深度学习将强化学习扩展到之前难以处理的决策问题上,即具有高维度状态和动作空间的环境。
深度强化学习的学习过程可以描述为;
(1)在每个时刻智能体与环境交互得到一个高维度的观察,并利用深度学习方法来感知观察,以得到具体的状态特诊表示。
(2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作。
(3)环境对此动作做出反应,并得到下一个观察,通过不断循环以上流程,最终可以得到实现目标的最优策略。


1.2.2 Deep Q-Network
扩展文献:Ronghua,Chen,Bo等.A self-learning genetic algorithm based on reinforcement learning for flexible job-shop scheduling problem[J].COMPUTERS AND INDUSTRIAL ENGINEERING,2020,149.
Deep Q-network 是强化学习中Q-learning与神经网络相结合的方法,简称DQN,对应算法流程:


为缓解非线性网络表示值函数出现不稳定等问题,DQN主要对传统的Q学习做了3处改进。
(1)DQN在训练过程中使用经验回放机制,在每个时间步,将智能体与环境交互得到的转移样本存储到回放记忆单元中。训练时,每次从记忆存储单元随机抽取小批量的转移样本,并使用随机梯度下降算法更新网络参数。在训练深度网络时,通常要求样本之间是相互独立的,这种随机采样的方式,大大降低了样本之间的相关性,从而提升了算法的稳定性。
(2)DQN除了使用深度卷积网络近似表示当前的值函数外,还单独使用了另一个网络来产生目标Q值。当前Q网络用来评估当前状态动作对的值函数,目标Q网络近似地表示值函数的优化目标。当前Q网络的参数是实时更新的,目标网络的更新是通过每经过固定的时间步,将当前Q网络的参数
复制给目标Q网络
‘来获得。通过最小化Q值和目标Q值之间的均方误差来更新网络参数,误差函数为:

对参数求偏导,得到:

引入目标网络后,在一段时间内目标Q值是保持不变的,一定程度上降低了当前Q值和目标Q值之间的相关性,提升了算法的稳定性。
(3)DQN将奖励值和误差缩小到有限的区域内,保证了Q值和梯度值都处于合理的范围内,提高了算法的稳定性。
1.2.3 Policy Gradient(策略梯度方法)
它通过不断计算策略期望总奖励关于策略参数的梯度来更新策略参数,最终收敛于最优策略。因此,在深度强化学习方法中,可以使用参数为的深度神经网络来对策略进行参数化表示,并利用策略梯度方法优化策略。
优点:
(1)基于策略的学习可能会具有更好的收敛性,这是因为基于策略的学习虽然每次只做微小的改善,但总是朝着好的方向在改善;
(2)在对于具有高维度或连续状态空间来说,基于策略的学习更加高效;
(3)能够学到一些随机策略,但是基于价值函数的学习通常是学不到随机策略的;
(4)策略梯度的计算相对价值函数的计算更加简单。
缺点:
(1)整个学习比较平滑,但不够高效;
(2)有时计算朝着梯度方向改变的增量会有较高的变异性,以至拖累了整个算法速度,但是通过一些修饰,可以改进;
(3)容易陷入局部最优;
1.2.4 Actor Critic(演员评论家法)
演员评论家方法结合了策略梯度和值函数模拟的方法。演员基于概率选择行为,评论家基于演员的行为进行打分,演员根据评论的评分修改行为的概率。相对于传统的策略梯度算法,演员评论家方法可以单步更新,学习更快。Actor网络的输入是状态,输出是行动,采用深度神经网咯进行函数拟合,对于车间调度问题的离散动作以softmax作为输出层达到概率输出的目的。

DDPG,Actor网络的输是状态,输出动作,以深度神经网络进行函数拟合,对于连续动作神经网络输出层可以用tanh或sigmod,离散动作以softmax作为输出层达到概率输出的效果。Critic网络的输入为状态和行动,输出为Q值。其对应的具体流程

其中目标网络的更新采用缓慢更新的方式,以参数t进行控制,这种方式的好处在于,进一步切断了数据样本的相关性,同时目标网络也更加稳定。
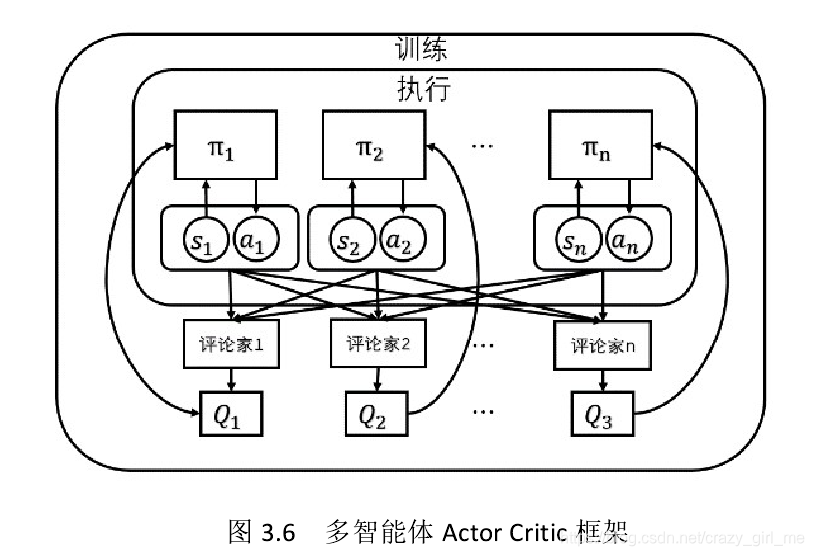
1.2.5 多智能体Actor-Critic
多智能体环境具有两个实用的属性:
(1)存在一个自然的全套考验,环境的难度取决于对手竞争者的能力;
(2)多智能体环境没有稳定的平衡态,无论一个智能体有多聪明,总会有让它变得更智能的压力。
在柔性作业车间中,将每个工件智能体作为Actor,并从Critic处获取建议,来帮助工件智能决定哪些动作在训练过程中应该被强化。
2 基于深度强化学习的工件加工路径寻优策略
2.1 智能体动作探索策略
在强化学习中,探索
与利用是一个非常基础但十分重要的概念。探索是指智能体尝试先前没有选择的动作,以期望获得更高的奖励回报;利用是指智能体选择当前认知下能产生最大奖励的动作。强化学习中的各类动作探索策略的统一思想便是寻求探索和利用之间的权衡,实现最大化利益。常用的动作探索策略有贪婪算法和softmax算法,他们对应的控制参数分别为
和
。
2.1.1  贪婪算法
贪婪算法

一般设置为(0,1)间较小的值。
优点:
(1)能应对变化:如果动作的奖励发生变化,能够及时改变策略,避免困在次优状态;
(2)可以有效控制智能体对于探索和利用的偏好程度:越大,模型灵活性也越高,能够更快地探索潜在高收益的动作,适应变化,收敛速度更快。
越小,模型具有的稳定性就越好,收敛速度相对较慢。
缺点:
(1)设置最优困难
(2)利用的机会损失:智能体执行策略一段时间后,对于动作的好坏的认知确定型增强,但仍然会花费固定的精力去探索,浪费了更多本应执行利用的几乎;
(3)信息利用度不够:随着执行策略的持续,智能体仍然不做仍和区分地随即探索,没有利用过程中获取和学习的信息。
为弥补上诉不足,主要通过将作为变量来优化策略。
2.1.2 Softmax算法
softmax算法是依据当前每个动作地平均奖励值来探索和利用进行折中的,softmax函数将一组值转为一组概率,值越大对应的概率也越高。因此,当前平均奖励越高的动作被选中的几率也越大。
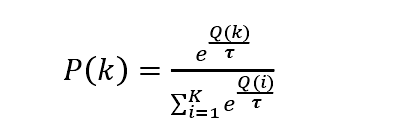
其中K为行动数,为温度参数(
>0),Q(i)记录的是当前行动的平均奖励。
越小,平均奖励高的动作被选取得概率越高,
->0,Softmax将趋于仅利用,
趋于无穷大时,将趋于仅探索。Softmax策略利用softmax函数对各个动作的回报期望概率进行排序,进而在选择动作时考虑该信息,减少探索过程中低回报动作的选择机会,收敛相对于
贪婪算法更快。
缺点:
(1)没有考虑预估动作回报期望的置信度信息,因而选择的高回报动作未必可靠。
(2)值大小难确定。
2.2 工件加工路径寻优的DQN算法
以柔性作业车间环境下单工件路径寻优问题为例,采用深度强化学习中的DQN算法,对案例进行求解分析。首先通过对状态空间的编码定义,表示车间环境下工件智能体状态特征,同时以及其编号作为动作的编码。然后根据工件智能体在学习过程中到达的状态进行奖罚设置,并将工件智能体的每一步经验以统一的形式存入经验池,用于之后样本学习时的随机采样。以此,探究工件智能体在简单柔性作业车间环境下,通过对加工任务的探索,实现寻优策略学习的过程,并对学习效果进行分析,检验工件智能体的学习能力。
2.2.1问题

2.2.2 状态编码
在柔性作业车间中,系统特征主要包括了及其、工件、时间三要素。因此,工件智能体的状态可以采用如下编码方式:

即下图例子:

2.2.3 动作编码
在加工过程中,工件智能体的行动是从等待和各机器之间做出选择,是离散的。
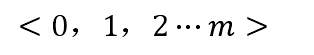
其中,0表示等待,工件进入缓存区,其余整数为机器编号。在工件智能体在某一工序持续加工过程中,其无需进行任何动作选择,只要保持当前动作至该工序完工,且该完工时间为工件智能体的下一个状态时刻。
2.2.4 奖罚函数设置

2.2.5 经验存储及回放
DQN算法不仅是把Q学习中的价值函数用深度神经网络来近似,还在学习方法上做出了改进:
DQN算法采用经验回放的方式来帮助智能体实现强化学习。工件智能体在每一步行动后都将获得相应的奖励,并到达下一个状态,但是工件智能体并不是立刻进行学习,而是将其探索作业车间环境得到的数据以统一形式存储起来,然后每次训练时从经验池中随机采样样本更新深度神经网络的参数,达到学习效果。工件智能体的经验记录形式如下:
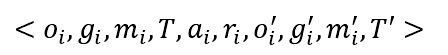

DQN算法使用经验回放的原因是:深度神经网络作为监督学习模型,要求数据满足独立同分布。为了打破数据之间的相关性,经验回放通过存储-采样的方法避免了数据前后的依赖关系,同时也避免了智能体受近期动作影响过大而遗忘之前动作选择的效果。
优点:
(1)提高了数据利用率,经验数据在随机采样过程中可能会被多次使用;
(2)降低了样本之间的相关性,连续样本的相关性会使得参数更新的方差较大。

