1 <form id="myForm" onsubmit="return false;"<input type="text" id="name"name="name" /><input type="text" id="age" name="age" /><!-- ... 其他表单元素 ...--><button type="submit" onclick="handleValidation()"Submit</button</form1 // ⼀个假设的表单验证函数function validateInput(inputId) {// 调⽤此处的校验逻辑,返回是否存在错误// 这⾥以ID "inputId"来获取对应的DOM对象var el =document.getElementById(inputId);// 此处只是⽰例, 实际上应根据具体的校验逻辑返回⼀个布尔类型return el.value === "预期值";2 }34 function handleValidation() {var valid = true;5 ["name", "age"].forEach((key) => {// 进⾏校验判断if (!validateInput(key)){console.error(`Validation failed for: ${key}`);6 // 标记校验失败7 valid = false;8 // 滚动到出现问题的元素位置var element = document.getElementById(key);9 element.scrollIntoView({ block: "center", behavior: "smooth" });10 // 增加⼀些提⽰效果, ⽐如错误边框, 可按需实现// element.classList.add('errorhighlight');11 }12 });13 // 检查是否验证失败,如果失败则不提交表单return valid;14 }1516 // 处理表单提交事件,与HTML中的onclick绑定document.getElementById("myForm").addEventListener("submit", (e) => {17 e.preventDefault(); // 阻⽌表单默认提交⾏为18 handleValidation();19 });1 const total = 100000;2 let ul = document.getElementById("container");3 let once = 20;4 let page = total / once;56 function loop(curTotal) {if (curTotal <= 0) return;7 let pageCount = Math.min(curTotal, once);8 window.requestAnimationFrame(() => {for (let i = 0; i < pageCount; i++) {letli = document.createElement("li");9 li.innerHTML = ~~(Math.random() * total);10 ul.appendChild(li);11 }12 loop(curTotal - pageCount);13 });14 }15 loop(total);1 const total = 100000;2 let ul = document.getElementById("container");3 let once = 20;4 let page = total / once;56 function loop(curTotal) {if (curTotal <= 0) return;7 let pageCount = Math.min(curTotal, once);8 window.requestAnimationFrame(() => {let fragment =document.createDocumentFragment(); // 创建⼀个虚拟⽂档碎⽚for (let i = 0; i <pageCount; i++) {let li = document.createElement("li");9 li.innerHTML = ~~(Math.random() * total);10 fragment.appendChild(li); // 挂到fragment上11 }12 ul.appendChild(fragment); // 现在才回流13 loop(curTotal - pageCount);14 });15 }16 loop(total); 这会将输出的⽂件名设置为⼊⼝名称加上基于每个 chunk 内容的 hash。在使⽤ webpack-dev server 或者 webpack --watch 时,不会⽣成实际的⽂件,所以这些 hash 值是在内存中计算并 关联的。 64. 如何从 0 到 1 搭建前端基建【热度: 404】 如何从 0 到 1 搭建前端基建 有⼀个⾮常经典的⽂章, 直接参考即可: ⾮⼤⼚的我们,要如何去搞前端基建? 这⾥简单总结⼀下⽂章⾥⾯的要点 1.什么是基建? 2.为什么要做前端基建? 业务复⽤; 提升研发效率; 规范研发流程; 团队技术提升; 团队的技术影响⼒; 开源建设; 3.前端基建如何推动落地? • 要合适的同学(资源) • 要解决的问题(问题) • 要解决问题⽅案计划书(⽅案) • 要具体执⾏的步骤(执⾏) 技术基建四⼤特性(切记) • 技术的健全性 • 基建的稳定性 • 研发的效率性 • 业务的体验性 4.前端基建都有什么? • 前端规范(Standard) • 前端⽂档(Document) • 前端项⽬模板管理(Templates) • 前端脚⼿架(CLI) • 前端组件库(UI Design) • 前端响应式设计 or ⾃适应设计 • 前端⼯具库(类 Hooks / Utils) • 前端⼯具⾃动化(Tools) • 接⼝数据聚合(BFF) • 前端 SSR 推进 • 前端⾃动化构建部署(CI/CD) • 全链路前端监控/数据埋点系统 • 前端可视化平台 • 前端性能优化 • 前端低代码平台搭建 • 微前端(Micro App) 65. 你在开发过程中, 使⽤过哪些 TS 的特性或者能⼒?【热度: 670】 直接上⼲货: 1. Utility Types(⼯具类型): ◦ Partial<T>: 将类型 T 的所有属性变为可选。 ◦ Required<T>: 将类型 T 的所有属性变为必选。 ◦ Readonly<T>: 将类型 T 的所有属性变为只读。 ◦ Record<K, T>: 创建⼀个具有指定键类型 K 和值类型 T 的新对象类型。 ◦ Pick<T, K>: 从类型 T 中选择指定属性 K 形成新类型。 ◦ Omit<T, K>: 从类型 T 中排除指定属性 K 形成新类型。 ◦ Exclude<T, U>: 从类型 T 中排除可以赋值给类型 U 的类型。 ◦ Extract<T, U>: 从类型 T 中提取可以赋值给类型 U 的类型。 ◦ NonNullable<T>: 从类型 T 中排除 null 和 undefined 类型。 ◦ ReturnType<T>: 获取函数类型 T 的返回类型。 ◦ Parameters<T>: 获取函数类型 T 的参数类型组成的元组类型。 2. 条件判定类型: ◦ Conditional Types(条件类型): 根据类型关系进⾏条件判断⽣成不同的类型。 ◦ Distribute Conditional Types(分布式条件类型): 分发条件类型,允许条件类型在联合类型上 进⾏分发。 3. Mapped Types(映射类型):根据已有类型创建新类型,通过映射类型可以⽣成新的类型结构。 4. Template Literal Types(模板⽂字类型):使⽤字符串模板创建新类型。 5. 类型推断关键字: ◦ keyof 关键字:关键字允许在泛型条件类型中推断类型变量。 ◦ instanceof:运算符⽤于检查对象是否是特定类的实例。 ◦ in:⽤于检查对象是否具有特定属性。 ◦ type guards:类型守卫是⾃定义的函数或条件语句,⽤于在代码块内缩⼩变量的类型范围。 ◦ as:⽤于类型断⾔,允许将⼀个变量断⾔为特定的类型。 66. JS 的加载会阻塞浏览器渲染吗?【热度: 243】 JavaScript 的加载、解析和执⾏默认情况下会阻塞浏览器的渲染过程。这是因为浏览器渲染引擎和 JavaScript 引擎是单线程的,并且⼆者共享同⼀个线程。JavaScript 在执⾏时会阻⽌ DOM 构建,因为 JavaScript 可能会修改 DOM 结构(例如添加、修改或删除节点)。出于这个原因,浏览器必须暂停 DOM 的解析和渲染,直到 JavaScript 执⾏完成。 默认情况下,当浏览器遇到⼀个 <script> 标签时,会⽴即停⽌解析 HTML,转⽽下载和执⾏脚本, 然后再继续 HTML 的解析和渲染。这意味着在 HTML ⽂档中的 JavaScript 脚本的下载和执⾏过程中,⻚⾯的渲染是被阻塞的。 不过,你可以⽤下⾯⼏种⽅法调整脚本的加载和执⾏⾏为,以减少对浏览器渲染过程的阻塞: 1. 异步脚本(async): 在 <script> 标签中使⽤ async 属性可以使得脚本的加载变成异步操作。当使⽤ async 属性 时,浏览器会在后台进⾏下载,但脚本的执⾏还是会阻塞 DOM 渲染。
这会将输出的⽂件名设置为⼊⼝名称加上基于每个 chunk 内容的 hash。在使⽤ webpack-dev server 或者 webpack --watch 时,不会⽣成实际的⽂件,所以这些 hash 值是在内存中计算并 关联的。 64. 如何从 0 到 1 搭建前端基建【热度: 404】 如何从 0 到 1 搭建前端基建 有⼀个⾮常经典的⽂章, 直接参考即可: ⾮⼤⼚的我们,要如何去搞前端基建? 这⾥简单总结⼀下⽂章⾥⾯的要点 1.什么是基建? 2.为什么要做前端基建? 业务复⽤; 提升研发效率; 规范研发流程; 团队技术提升; 团队的技术影响⼒; 开源建设; 3.前端基建如何推动落地? • 要合适的同学(资源) • 要解决的问题(问题) • 要解决问题⽅案计划书(⽅案) • 要具体执⾏的步骤(执⾏) 技术基建四⼤特性(切记) • 技术的健全性 • 基建的稳定性 • 研发的效率性 • 业务的体验性 4.前端基建都有什么? • 前端规范(Standard) • 前端⽂档(Document) • 前端项⽬模板管理(Templates) • 前端脚⼿架(CLI) • 前端组件库(UI Design) • 前端响应式设计 or ⾃适应设计 • 前端⼯具库(类 Hooks / Utils) • 前端⼯具⾃动化(Tools) • 接⼝数据聚合(BFF) • 前端 SSR 推进 • 前端⾃动化构建部署(CI/CD) • 全链路前端监控/数据埋点系统 • 前端可视化平台 • 前端性能优化 • 前端低代码平台搭建 • 微前端(Micro App) 65. 你在开发过程中, 使⽤过哪些 TS 的特性或者能⼒?【热度: 670】 直接上⼲货: 1. Utility Types(⼯具类型): ◦ Partial<T>: 将类型 T 的所有属性变为可选。 ◦ Required<T>: 将类型 T 的所有属性变为必选。 ◦ Readonly<T>: 将类型 T 的所有属性变为只读。 ◦ Record<K, T>: 创建⼀个具有指定键类型 K 和值类型 T 的新对象类型。 ◦ Pick<T, K>: 从类型 T 中选择指定属性 K 形成新类型。 ◦ Omit<T, K>: 从类型 T 中排除指定属性 K 形成新类型。 ◦ Exclude<T, U>: 从类型 T 中排除可以赋值给类型 U 的类型。 ◦ Extract<T, U>: 从类型 T 中提取可以赋值给类型 U 的类型。 ◦ NonNullable<T>: 从类型 T 中排除 null 和 undefined 类型。 ◦ ReturnType<T>: 获取函数类型 T 的返回类型。 ◦ Parameters<T>: 获取函数类型 T 的参数类型组成的元组类型。 2. 条件判定类型: ◦ Conditional Types(条件类型): 根据类型关系进⾏条件判断⽣成不同的类型。 ◦ Distribute Conditional Types(分布式条件类型): 分发条件类型,允许条件类型在联合类型上 进⾏分发。 3. Mapped Types(映射类型):根据已有类型创建新类型,通过映射类型可以⽣成新的类型结构。 4. Template Literal Types(模板⽂字类型):使⽤字符串模板创建新类型。 5. 类型推断关键字: ◦ keyof 关键字:关键字允许在泛型条件类型中推断类型变量。 ◦ instanceof:运算符⽤于检查对象是否是特定类的实例。 ◦ in:⽤于检查对象是否具有特定属性。 ◦ type guards:类型守卫是⾃定义的函数或条件语句,⽤于在代码块内缩⼩变量的类型范围。 ◦ as:⽤于类型断⾔,允许将⼀个变量断⾔为特定的类型。 66. JS 的加载会阻塞浏览器渲染吗?【热度: 243】 JavaScript 的加载、解析和执⾏默认情况下会阻塞浏览器的渲染过程。这是因为浏览器渲染引擎和 JavaScript 引擎是单线程的,并且⼆者共享同⼀个线程。JavaScript 在执⾏时会阻⽌ DOM 构建,因为 JavaScript 可能会修改 DOM 结构(例如添加、修改或删除节点)。出于这个原因,浏览器必须暂停 DOM 的解析和渲染,直到 JavaScript 执⾏完成。 默认情况下,当浏览器遇到⼀个 <script> 标签时,会⽴即停⽌解析 HTML,转⽽下载和执⾏脚本, 然后再继续 HTML 的解析和渲染。这意味着在 HTML ⽂档中的 JavaScript 脚本的下载和执⾏过程中,⻚⾯的渲染是被阻塞的。 不过,你可以⽤下⾯⼏种⽅法调整脚本的加载和执⾏⾏为,以减少对浏览器渲染过程的阻塞: 1. 异步脚本(async): 在 <script> 标签中使⽤ async 属性可以使得脚本的加载变成异步操作。当使⽤ async 属性 时,浏览器会在后台进⾏下载,但脚本的执⾏还是会阻塞 DOM 渲染。 1 <script async src="script.js"</script1 <script defer src="script.js"</script1. 使⽤ defer ,脚本的执⾏顺序将按照它们在 DOM 中出现的顺序执⾏。
2. 动态脚本加载: 你可以使⽤ JavaScript 动态创建 <script> 元素并添加到 DOM 中,这允许你控制脚本的加载和 执⾏时机。1 var script = document.createElement("script");2 script.src = "script.js";3 document.body.appendChild(script); 1. 这种⽅法简单直接,但要记住,由于这些资源不会被 Webpack 处理,它们不会被包含在 Webpack 的依赖图中,并且也不会享受到 Webpack 的各种优化。 2. 使⽤ Webpack 管理: 如果想要 Webpack 来处理这些通过 <script> 引⼊的资源,可以使⽤⼏种插件和加载器: ◦ html-webpack-plugin 可以帮助你⽣成⼀个 HTML ⽂件,并在⽂件中⾃动引⼊ Webpack 打包后的 bundles。 ◦ externals 配置允许你将⼀些依赖排除在 Webpack 打包之外,但还是可以通过 require 或 import 引⽤它们。 ◦ script-loader 可以将第三⽅全局变量注⼊的库当作模块来加载使⽤。 3. 例如,使⽤ html-webpack-plugin 和 externals ,你可以将⼀个库配置为 external,然后 通过 html-webpack-plugin 将其引⼊:
1. 这种⽅法简单直接,但要记住,由于这些资源不会被 Webpack 处理,它们不会被包含在 Webpack 的依赖图中,并且也不会享受到 Webpack 的各种优化。 2. 使⽤ Webpack 管理: 如果想要 Webpack 来处理这些通过 <script> 引⼊的资源,可以使⽤⼏种插件和加载器: ◦ html-webpack-plugin 可以帮助你⽣成⼀个 HTML ⽂件,并在⽂件中⾃动引⼊ Webpack 打包后的 bundles。 ◦ externals 配置允许你将⼀些依赖排除在 Webpack 打包之外,但还是可以通过 require 或 import 引⽤它们。 ◦ script-loader 可以将第三⽅全局变量注⼊的库当作模块来加载使⽤。 3. 例如,使⽤ html-webpack-plugin 和 externals ,你可以将⼀个库配置为 external,然后 通过 html-webpack-plugin 将其引⼊: 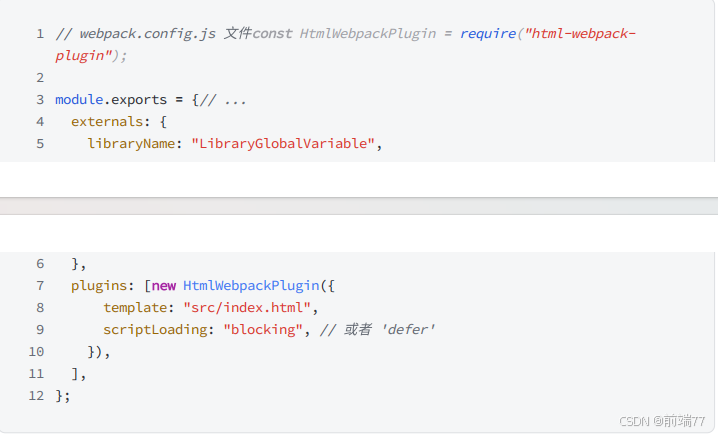
1. 然后,在你的 index.html 模板⽂件中可以这样引⼊资源:
1 <script src="https://cdn.example.com/library.js"</script1 // 你的 JavaScript 代码⽂件中import Library from "libraryName"; // 虽然定义了external,Webpack依然会处理这个import1 xxx.1.0.0.html --> vender.hash_1.js、 vender.hash_2.js、 vender.hash_3.js、vender.hash_1.css2 xxx.1.0.1.html --> vender.hash_a.js、 vender.hash_b.js、 vender.hash_c.js、vender.hash_d.css