目录
前言一、HAI二、应用场景三、构建 Stable Diffusion 模型1、新建HAI应用2、StableDiffusionWebUI(1)功能介绍(2)页面转中文(3)AI绘图① 正向提示词语② 反向提示词③ “+” 、“ AND”、“|” 用法④ 权重⑤ Euler a 取样方法⑥ DPM++ 2M Karras 取样方法⑦ 新增提示词案例 四、总结
前言
一直以来想部署一个自己的 StableDiffusion 模型,但是在构建模型过程中遇到许多问题,后来发现可以用 HAI 可以快速构建并且部署,给我带来了极大的便利,省去了许多麻烦事。
高性能应用服务(Hyper Application Inventor,HAI)是一款面向 AI 和科学计算的 GPU/NPU 应用服务产品,提供即插即用的强大算力和常见环境。它可以帮助中小企业和开发者快速部署语言模型、AI 绘图、数据科学等高性能应用,原生集成配套的开发工具和组件,大大提升应用层的开发生产效率。
如果你想快速构建一套AI模型,比如Stable Diffusion、ChatGLM2 6B、Llama2 7B、Llama2 13B,又或者是想搭建一套AI框架,比如Pytorch2.0.0、Tensorflow2.9.0,HAI 可成为你的首选。本文通过构建Stable Diffusion模型进行二次元AI绘画,主要利用深度学习算法进行创作绘图,应用场景也是十分广泛。
一、HAI
高性能应用服务 HAI 以应用为中心,匹配GPU云算力资源,助力中小企业及开发者快速部署LLM、AI作画、数据科学等高性能应用。其优势十分显著:
1、简单易用。通过简化计算、网络和存储等基础设施的配置流程,大幅降低了云服务操作和管理的复杂度。
2、应用环境快速部署。支持多种 AI 环境快速部署,如 ChatGLM-6B、StableDiffusion 等,使用户可专注业务及应用场景创新。
3、高灵活性。支持用户登录实例,对 AI 模型及实例环境进行灵活配置。可进行内部开发、业务测试,或对外提供业务服务。
4、多种登录方式。除传统连接方式外,支持通过 jupyterlab、WebUI 等方式一键启动,提供更贴合使用场景的登录方式。
5、算力种类丰富。提供多种算力套餐选择,未来还将加入更多种类供用户选择。
二、应用场景
HAI 应用场景十分广泛,可以应用于AI 作画/设计、AI 对话/写作、AI 开发测试以及数据科学等方面。
在AI 作画/设计方面,设计师和开发者可以使用高性能应用服务快速地部署和优化 AI 绘画模型。高性能应用服务预置 Stable Diffusion 等主流 AI 作画模型及常用插件,提供 GUI 图形化界面即开即用,大幅降低上手门槛。在AI 对话/写作方面,研究者和开发者可以使用高性能应用服务快速部署和运行大型语言模型,如 LLAMA2、ChatGLM 等,进行自然语言处理任务,如文本生成、情感分析、文本分类等。高性能应用服务提供的算力支持和优化环境确保了语言模型可以在最短的时间内进行部署,同时还能保持高稳定性和可靠性。在AI 开发测试方面,高性能应用服务的预配置环境支持大多数流行的 AI 框架和工具,如 TensorFlow、PyTorch 等,使得开发者可以专注于算法设计和模型优化。AI 研究者可以在高性能应用服务上进行模型的开发、训练、测试和优化,无需担心硬件兼容性和软件配置问题。如新算法的原型开发、模型微调与迁移学习、深度学习框架的交叉测试等。在数据科学方面,数据科学家们可使用高性能应用服务,快速进行数据分析和图标处理。高性能应用服务预置了 Notebook、Python 环境,以及主流分析软件。
三、构建 Stable Diffusion 模型
上面讲解了HAI的优势以及应用场景,那么接下来就开始使用 HAI 构建 Stable Diffusion 模型。Stable Diffusion,直接从字面意思翻译是稳定的扩散,当然这也将图像生成模型的工作原理点出来了。它是一种生成模型,可用于生成高质量的图像,其原理是将噪声添加懂真实图像,然后通过神经网络将噪声去除掉,随着噪声逐渐去除,真实图像便逐渐恢复。那么怎么使用 HAI 构建 Stable Diffusion 模型呢
1、新建HAI应用
首先在算力管理页面点击新建,这就是构建HAI应用的入口了。

在AI模型中选择Stable Diffusion,这就是我们需要的模型,然后点击购买。
购买完成后HAI应用就会自动创建,创建过程大概需要3-8分钟,静候即可。
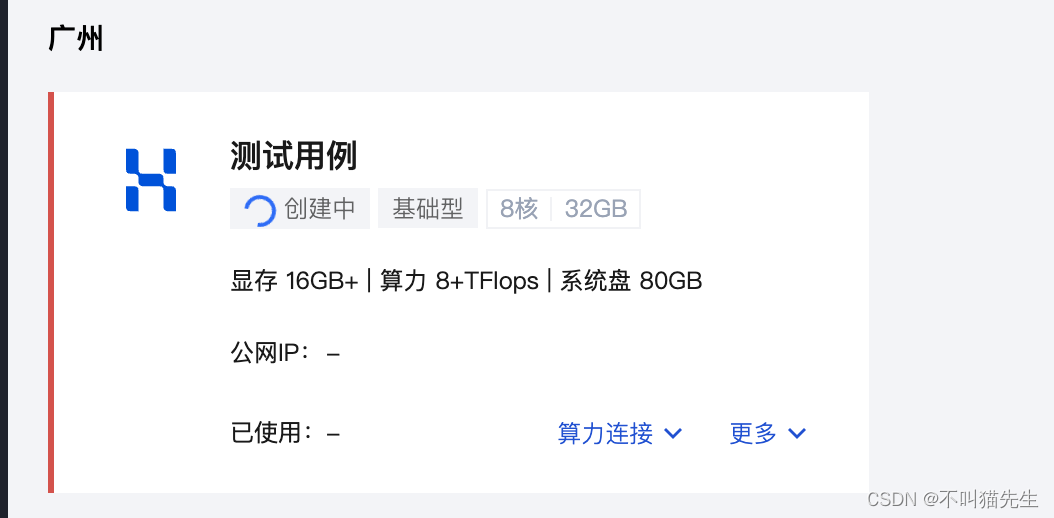
创建完成之后,点击算力连接,在下拉中选择stable_diffusion_webui。
2、StableDiffusionWebUI
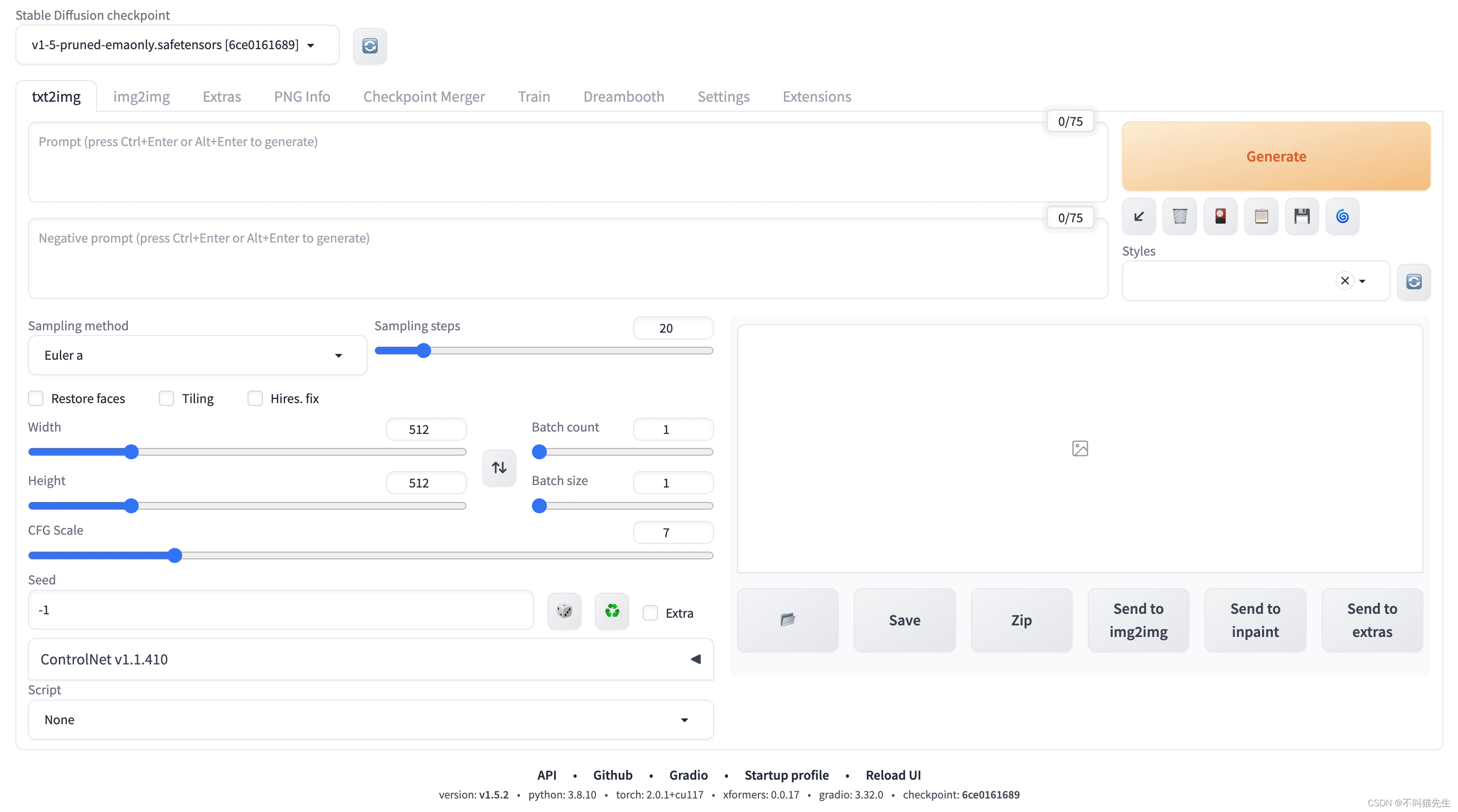
我们可以看到StableDiffusionWebUI 主页面,具体如下图所示:
(1)功能介绍
StableDiffusionWebUI是基于StableDiffusion开源模型开发的,具有以下功能:
文生图
根据描述生成任何图像
智能识别:Stable Diffusion 可以智能识别用户上传的图片,并自动调整图片质量和色彩,让图片更加清晰、饱满。
风格转换:Stable Diffusion 可以将用户上传的图片转换成不同的艺术风格,如印象派、后印象派、立体派等等,让图片更加艺术化。
人像修复:Stable Diffusion 可以自动识别人像并进行修复,去除皱纹、瑕疵等不良痕迹,让人像更加美观自然。
图像融合:Stable Diffusion 可以将多张图片进行融合,生成全新的图像,让用户可以尝试不同的创意和设计。
图像去噪:Stable Diffusion 可以自动去除图片中的噪点,让图片更加干净、清晰。
(2)页面转中文
首先我们先把页面换成中文。选择页面中Extensions菜单中的Available菜单,然后取消localization勾选,勾选script,之后点击 Load from,大概需要等30-60s。
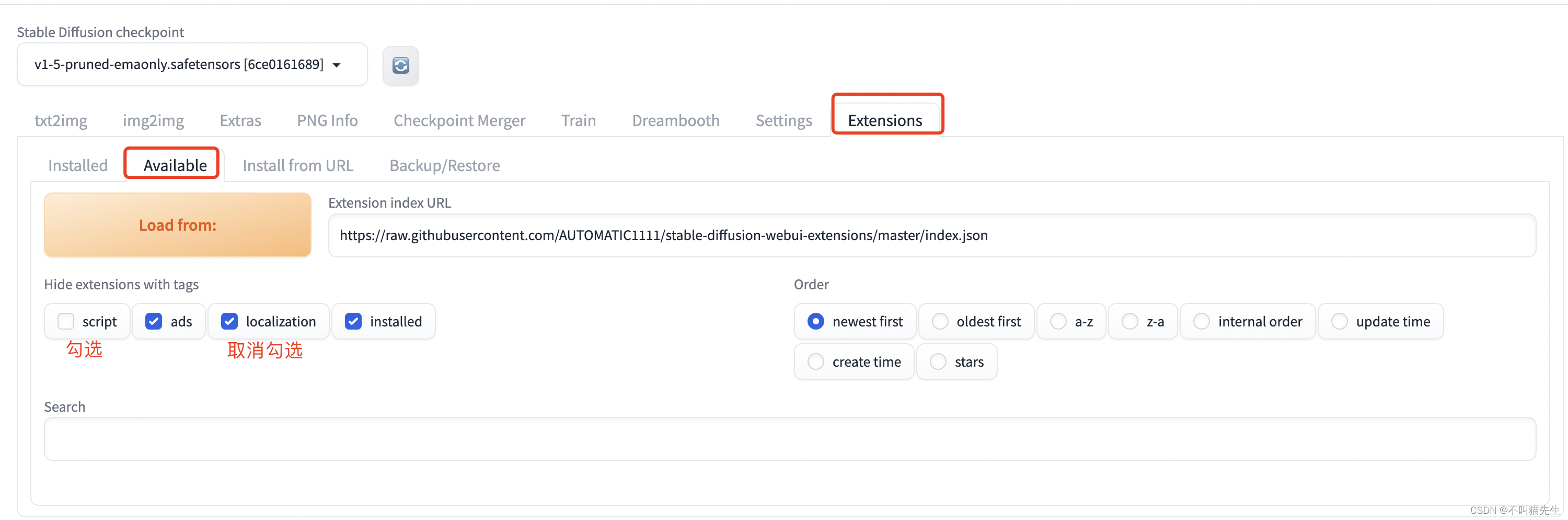
然后在搜索框中搜索:zh_CN,

点击Install进行安装。
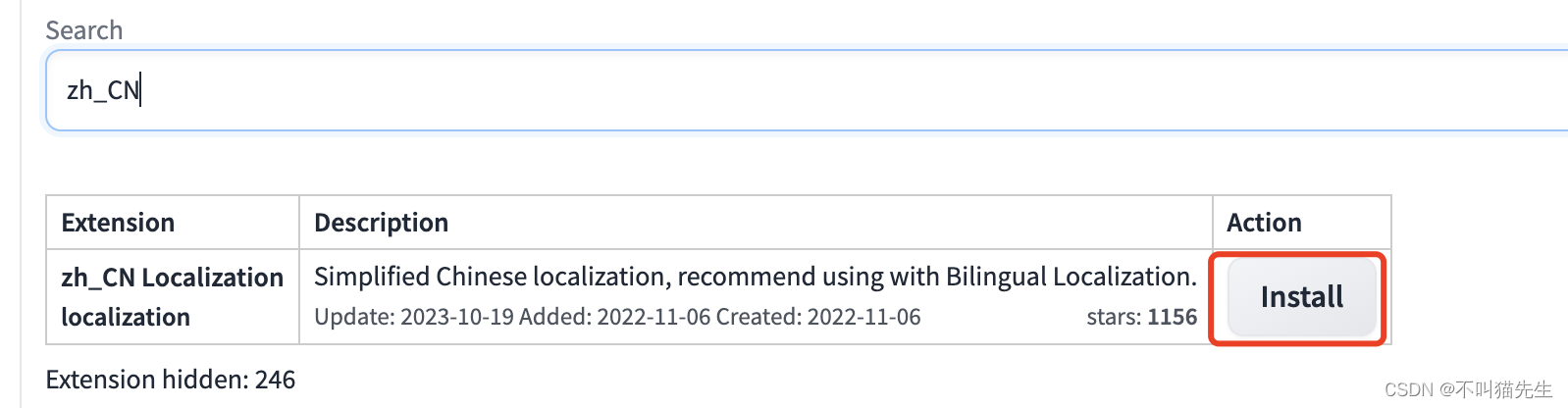
安装成功后,我们可以在Extensions菜单中的Installed菜单看到安装的stable-diffusion-webui-localization-zh_CN
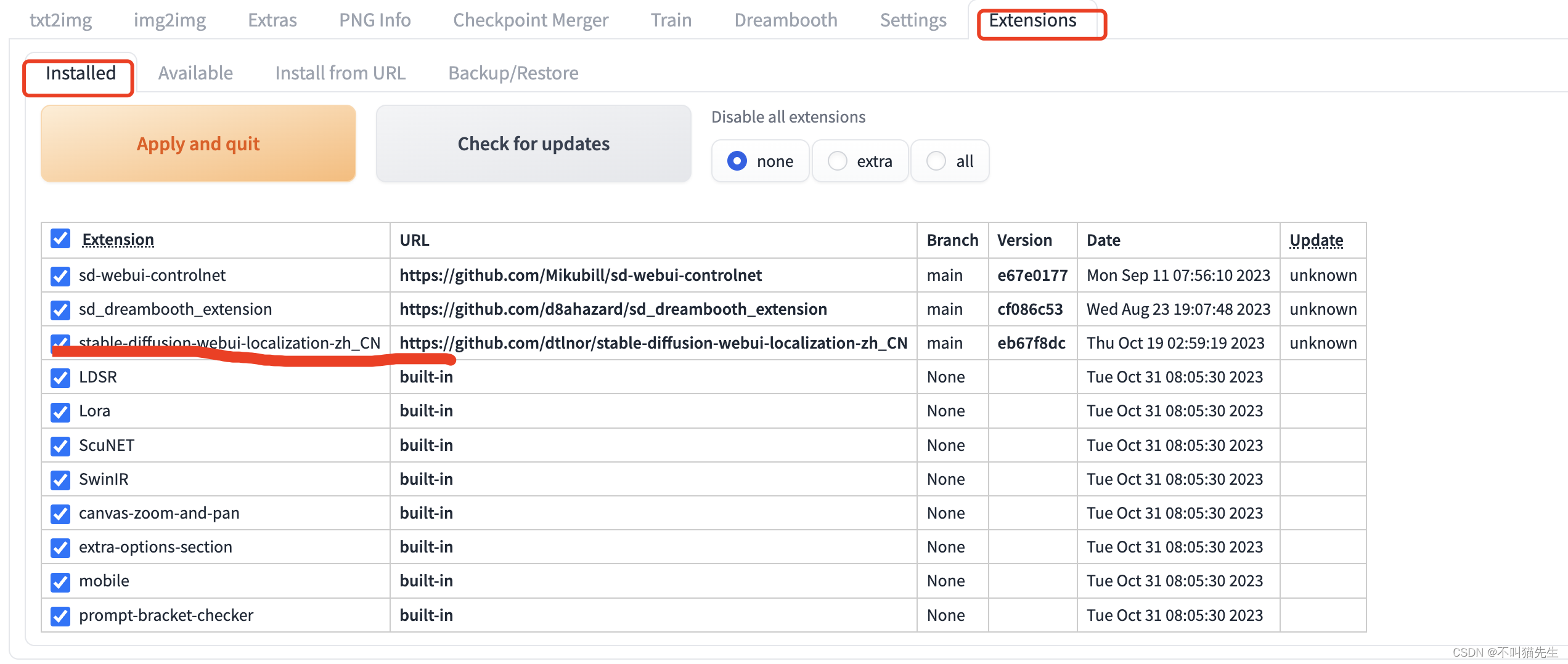
最后在Setting菜单中选择User interface,在Localization (requires restart) 下拉菜单中选择zh_CN
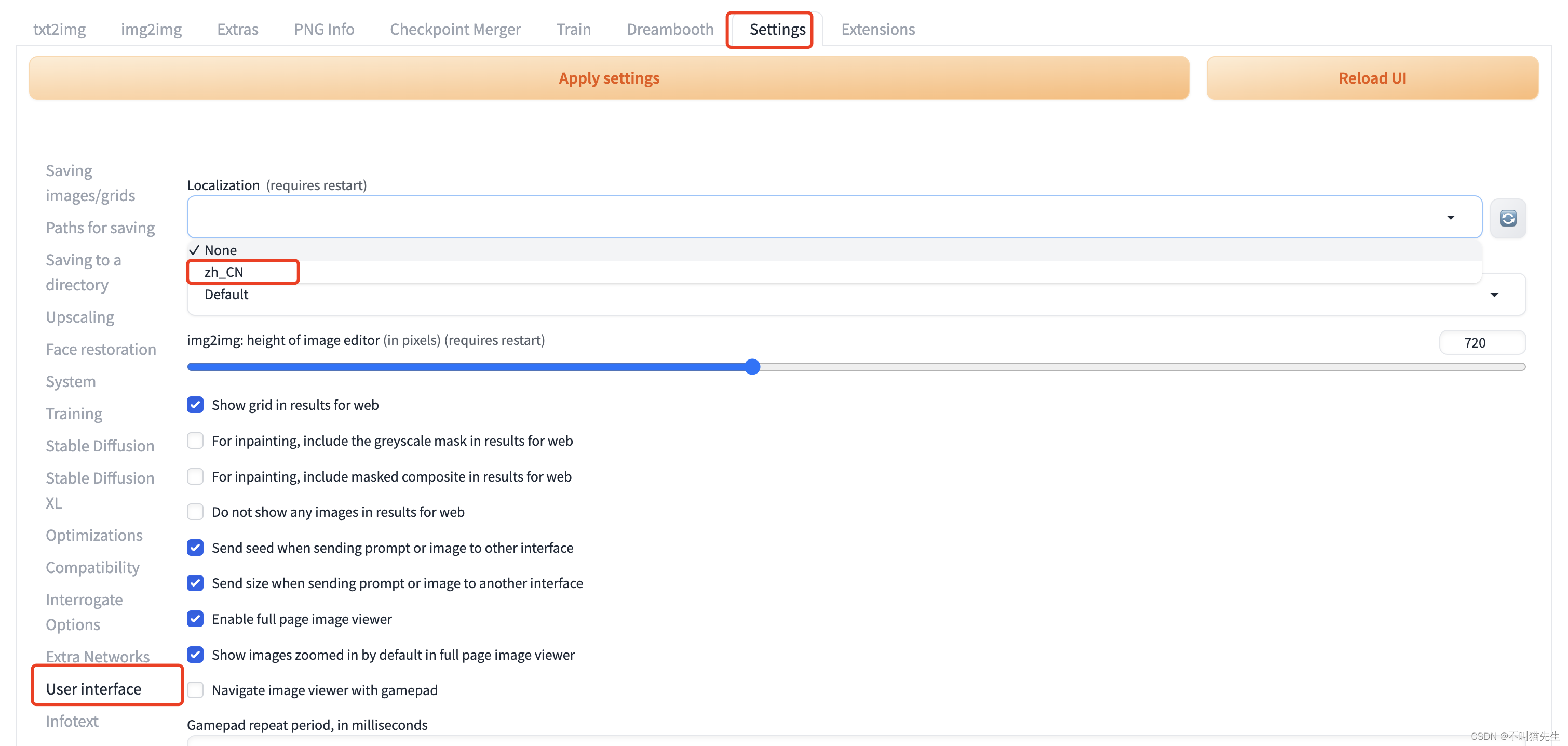
最后先点击Apply setting,然后再点击Reload UI,页面就变成中文了。
(3)AI绘图
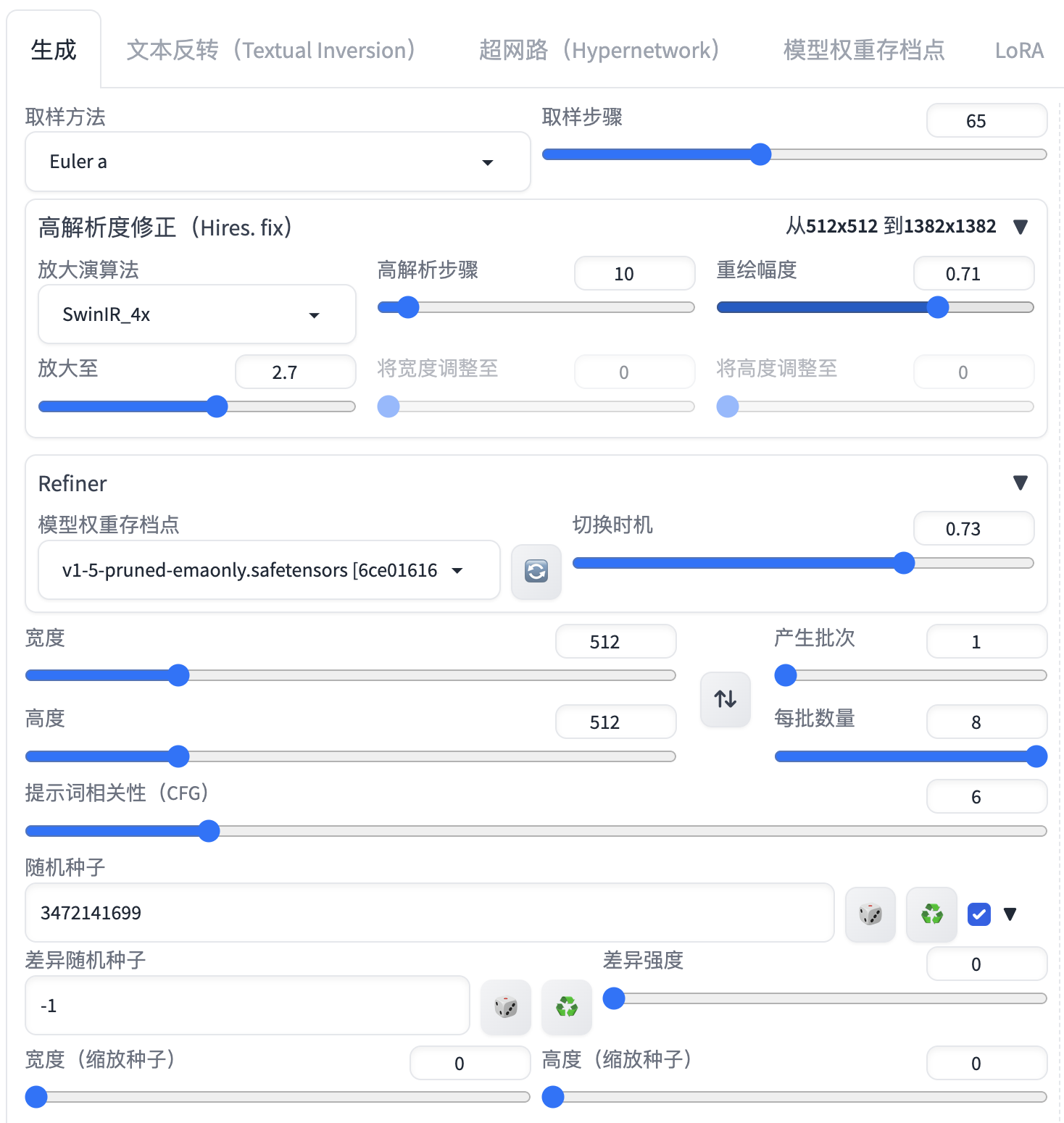
Stable Diffusion可以根据你输入的提示词(prompt)来绘制出想象中的画面。在进行文生图之前,先讲解一下StableDiffusionWebUI主页面的基本属性,相关配置属性解释如下:
| 属性 | 描述 |
|---|---|
| 提示词 | 主要描述图像,包括内容风格等信息,原始的webui会对这个地方有字数的限制,可以安装一些插件突破字数的限制。简单来说就是你想要生成一副什么样的图片,包含主体、风格、色彩、质量要求等等。 |
| 反向提示词 | 告诉模型我们不需要的风格,表示你不想要什么,比如不想要图片出现什么,不想图片质量差,不想人物模糊或者多手多脚等 |
| 提示词相关性(CFG scale) | 分类器自由引导尺度,图像与提示符的一致程度越低的值产生的结果越有创意,数值越大成图越贴近描述文本。一般设置为7 |
| 采样方法(Sampling method) | 扩散算法的去噪声采样模式会影响其效果,不同的采样模式的结果会有很大差异 |
| 采样迭代步数(Sampling steps) | 在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。需要注意的是,更高的迭代步数会消耗更多的计算时间和成本,但并不意味着一定会得到更好的结果。然而,如果迭代步数过少,一般不少于50,则图像质量肯定会下降 |
| 随机种子(Seed) | 生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。-1表示不基于图片种子进行绘制,完全基于你的prompt生成,如果填写一个图片的种子值,则会参考你填写的图片种子,在此图片基础上进行二次绘制。 |
| 高清修复 | 将生成的图片进行高清放大,提升分辨率,显存不够的宝子们慎用 |
| 生成批次 | 表示本次绘制时通过几个批次进行绘画,显存低的宝子们可以调大,以时间换空间 |
| 每批数量 | 表示每批生成几张图片,也是看显存大小进行设置 |
其中提示词是非常重要的,是生成图像最基本的要求。提示词(prompt)由多个词缀构成。提示词分为正向提示词(positive prompt)和反向提示词(negative prompt),用来告诉AI哪些需要,哪些不需要。反向提示词听起来有些耐人寻味,其实就是我们不想出现什么的描述。提示词与反提示词实际上看你的想象力,当初也要转换成英文描述的术语才能更好地生效,个人认为没有什么定格公式,会限制人的想象力,总之你想什么就填上去,尽情发挥想象力。
① 正向提示词语
这里提供一些正向提示词语,可以斟酌添加到模型中。
| prompt | 描述 |
|---|---|
| HDR, UHD, 64K | (HDR、UHD、4K、8K和64K)这样的质量词可以带来巨大的差异提升照片的质量 |
| Highly detailed | 画出更多详细的细节 |
| Studio lighting | 添加演播室的灯光,可以为图像添加一些漂亮的纹理 |
| Professional | 加入该词可以大大改善图像的色彩对比和细节 |
| Vivid Colors | 给图片添加鲜艳的色彩,可以为你的图像增添活力 |
| Bokeh | 虚化模糊了背景,突出了主体,像iPhone的人像模式 |
| High resolution scan | 让你的照片具有老照片的样子赋予年代感 |
| Sketch | 素描 |
| Painting | 绘画 |
② 反向提示词
一些返向提示词案例,针对你要生成的图像,通过反向提示,避免出现不符合预期的图片
| Negative Prompt | Description |
|---|---|
| Mutated hands and fingers | 变异的手和手指 |
| Deformed | 畸形的 |
| Bad anatomy | 解剖不良 |
| Disfigured | 毁容 |
| Poorly drawn face | 脸部画得不好 |
| Mutated | 变异的 |
| Extra limb | 多余的肢体 |
| Ugly | 丑陋 |
| Poorly drawn hands | 手部画得很差 |
| Missing limb | 缺少的肢体 |
| Floating limbs | 漂浮的四肢 |
| Disconnected limbs | 肢体不连贯 |
| Malformed hands | 畸形的手 |
| Out of focus | 脱离焦点 |
| Long neck | 长颈 |
| Long body | 身体长 |
③ “+” 、“ AND”、“|” 用法
“+”和“AND”:这两个符号都用于连接短标签或关键词。使用“+”或者“AND”来将标签连接在一起。要注意的是,在使用“AND”连接标签时,两端需要加上空格。此外,“+”可以大致等同于“AND”。
“|”:这是用作循环绘制符号或融合符号。在这种上下文中,它可能表示一种绘图操作,可以用来融合或循环绘制某些元素或标签。
④ 权重
使用括号和不同格式来调整单词的权重:
(PromptA:权重):调整权重比例为给定的权重。(PromptA):默认权重为1.1,等同于(PromptA:1.1)。{PromptB}:默认权重为1.05,等同于(PromptB:1.05)。[PromptC]:默认权重为0.952,等同于(PromptC:0.952)。((PromptD)):权重为1.21,等于(PromptD:1.1*1.1)。{{PromptE}}:权重为1.1025,等于(PromptE:1.05*1.05)。[[PromptF]]:权重为0.905504,等于(PromptF:0.952*0.952)。 此外,根据标签的位置,权重也会受到影响。比如,如果景色标签在前,人物可能会被缩小;反之,人物可能会变大或显示为半身。
⑤ Euler a 取样方法
使用Euler a取样方法生成图像,本文案例使用下面的配置:
正向提示词:((studio ghibli)), (1cute girl) walking in street, half body,
反向提示词:easynegative
取样方法:Euler a
取样步骤:65
高解析度修正(Hires.fix):放大演算算法选择SwinIR_4x,高解析步骤为10,重绘幅度为0.71
提示次相关性(CFG):7
随机种子:3472141699
产生批次:1
每批数量:8
然后生成如下图,宫崎骏动漫里的夏天真的太好看啦
 |  |  |
 |  |  |
 |  |
Euler a的优势
适用性:欧拉采样方法在生成二次元图像中可能不是首选,因为它主要用于模拟物理系统或动态系统的数值积分,对于艺术风格的图像生成并不是其主要应用。
特点:
欧拉方法更适用于模拟动态系统中的物体运动或相机路径等,对于艺术性较高的二次元图像可能无法提供所需的效果和细节。
⑥ DPM++ 2M Karras 取样方法
之后了解到DPM++ 2M Karras基于深度学习和神经网络技术,能够生成高质量、细节丰富的图像。Euler采样方法主要用于模拟物理系统或动态系统的数值积分,对于艺术风格的图像生成并不是其主要应用。因此将取样方法修改为DPM++ 2M Karras,并对其他属性做了调整,如下:
正向提示词:((studio ghibli)), (1cute girl) walking in street, half body,
反向提示词:easynegative
取样方法:DPM++ 2M Karras
取样步骤:60
高解析度修正(Hires.fix):放大演算算法选择SwinIR_4x,高解析步骤为10,重绘幅度为0.4
提示次相关性(CFG):7
随机种子:3472141699
产生批次:1
每批数量:8
 |  |  |
 |  |  |
 |  |
很明显可以看出来两个取样方法生成的图片有很大的不同,用DPM++ 2M Karras方法生成的图片色彩更鲜艳,人物形象也更生动。
DPM++ 2M Karras 的优势
适用性: DPM++ 2M Karras可能更适合生成二次元图像,因为它基于深度学习和神经网络技术,能够生成高质量、细节丰富的图像。
特点:这种方法能够更好地保持模型的细节,并且可以更快速地生成需要的图像。它适用于生成二次元风格的图像,特别是在处理角色造型、背景细节等方面有着较好的效果。
⑦ 新增提示词案例
依旧使用上面的DPM++ 2M Karras方法取样,新增一些正向提示词和反向提示词,看看与上面生成的图片有什么不同,本次配置提示词更丰富,限制的要求比较多。
| 提示词 | 描述 |
|---|---|
| prompt | ((studio ghibli)), (1cute girl) walking in street, half body, 64K, Professional,Makoto Shinkai, Katsuhiro Otomo, Masashi Kishimoto, Kentaro Miura |
| negative prompt | (low quality, worst quality:1.4), (bad_prompt:0.8), (monochrome:1.1), (greyscale), username, watermark, signature, text, logo, nsfw |
 |  |  |
 |  |  |
 |  |
可以看到生成的图片虽然使用了DPM++ 2M Karras取样方法,但是新添加的提示词(64K, Professional,Makoto Shinkai, Katsuhiro Otomo, Masashi Kishimoto, Kentaro Miura)的作用也是非常明显,生的的图像色彩对比更明显,图像的细节也更多了。并且图像的面部、肢体也和正常人物形象没有什么很大差别,并没有出现多余的肢体、畸形的手等变异的地方。
四、总结
StableDiffusionWebUI 的出神入化让我十分震惊,HAI不仅可以构建应用,而且也提供了部署的功能,这让我一个嫌麻烦的人似乎找到了归宿。本来自己构建模型的话就挺复杂了,HAI 彻底解决了我的问题。在体验过程中,对 HAI 构建应用有一些自己的看法:
缺陷以及优化建议:
1、构建HAI应用地域的选择有点少,像北京这样的一线城市选项竟然么有,有一些诧异。
2、生成图像过程中会出现卡顿现象,虽然显示图像在生成中,但是进度一直不动,卡的时间比较长,只能重启应用来解决问题,如果能监控到图像生成的问题并给予提示就更好了。个人认为是算力不够,在处理更大尺寸的图像、采样步数过大等问题,会有限制。
3、对于有经验的使用者,对目标图像生成时,配置参数有自己的着重点。但是对于新手使用,提示词积累比较少,生成图像可能跟自己的预期大相径庭,能提供一些提示词案例就更好了。
优点:
1、HAI 提供了简单易用的API接口和友好的开发工具,方便用户开发和调试。
2、快速构建和部署,我觉得这是很多使用者都能看到的优点,真的很方便。
3、HAI 使用先进的架构和算法,能够处理大量并发请求,并提供高吞吐量和低延迟的服务,这让使用者在使用应用过程中体验更好。
4、可以搭建一套服务,让多个应用一起使用,这样不仅节约了经费,还节省了时间。
附:HAI官方地址:https://cloud.tencent.com/product/hai