目录
一、两个学派
1.1 频率学派:
1.2 贝叶斯学派
二、朴素贝叶斯
2.1 简介
2.2 相关公式
2.2.1 贝叶斯公式
2.2.2 朴素贝叶斯公式
三、案例分析(西瓜集)
四、Python实现NB代码解读
4.1 西瓜集手写代码
4.2 鸢尾花手写代码
4.3 鸢尾花第三方库
五、Python实现NB代码汇总
5.1 不使用sklearn中方法
5.1.1 数据集:西瓜集3.0(来自西瓜书《机器学习 周志华》84页)
5.1.2 数据集:鸢尾花iris(来自sklearn提供的数据集)
5.2 使用sklearn中的方法
5.2.1 数据集:鸢尾花iris(来自sklearn提供的数据集)
【写在前面】
本篇文章介绍了朴素贝叶斯分类器(Naive Bayes,NB)的工作原理以及使用Python实现NB,这里介绍了3种代码:使用西瓜集3.0手写NB、使用鸢尾花数据集手写NB、使用鸢尾花数据集使用机器学习第三方库实现NB。如有错误欢迎指正。
一、两个学派
概率模型的训练过程就是参数估计过程。对于参数估计,统计学界的两个学派(频率学派、贝叶斯学派)提供了不同的解决方案。
1.1 频率学派:
核心思想:认为参数真值是固定的、未知的一个常数,而观察到的数据是随机的。其着眼点是样本空间。
解决方法:最大似然估计(MLE)。
1.2 贝叶斯学派
核心思想:认为参数真值是未观察到的随机变量,其本身也可有分布,而观察到的数据是固定的。其着眼点是参数空间,重视参数的分布。利用参数的先验信息估计后验概率,即先验概率P(c)+样本信息(条件概率)P(x|c)->后验概率P(c|x)。
解决方法:最大后验估计(MAP)。
频率学派的观点是对总体分布做适当的假定,结合样本信息对参数进行统计推断,这里涉及总体信息和样本信息;而贝叶斯学派的观点认为除了上述两类信息之外,统计推断还应引入先验信息。
一般来说,先验信息来源于经验和历史资料。频率学派不假设任何的先验信息,不参照过去的经验,只按照当前已有的数据进行概率推断;贝叶斯学派会假设先验信息的存在。
二、朴素贝叶斯
2.1 简介
贝叶斯分类的分类原理就是利用贝叶斯公式根据某特征的先验概率计算出后验概率,然后选择具有最大后验概率的类别作为该特征所属的类别。
朴素贝叶斯之所以称为“朴素”,是因为假设了各个特征之间是相互独立的。
2.2 相关公式
对于待分类样本S:
特征集合X={x1,x2,…,xn}
类标签集合C={c1,c2,…,cm}
表示样本S具有n个特征,可能会有m中不同的分类结果。
2.2.1 贝叶斯公式
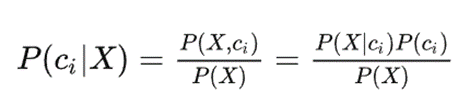
其中:
ci:表示一种预测类别结果;
X:表示样本S的一组特征观测数据;
P(ci):表示ci的先验概率,即在未观察到X之前S属于ci的概率;
P(ci|X):表示ci的后验概率;即在观察到X后S属于ci的概率;
P(X|ci)/ P(X):可能性函数,表示调整因子,使预测概率更加接近真实概率;
所以,贝叶斯公式:后验概率=先验概率*调整因子。
调整因子>1,则表示先验概率被增强,事件ci发生的可能性变大。调整因子=1,则表示数据X对判断事件ci发生的概率没有帮助。调整因子<1,则表示先验概率被削弱,事件ci发生的可能性变小。2.2.2 朴素贝叶斯公式
根据“朴素”中的特征独立假设,有:
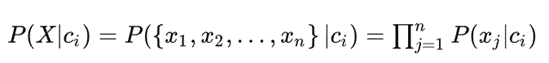
其中,n表示特征数目,xj表示S在第j个特征上的取值;
对于所有类别来说,P(X)相同,所以,根据贝叶斯公式可写出朴素贝叶斯公式为:
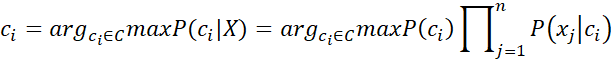
很显然,我们需要根据训练集D求出两个值:
先验概率P(c);每个特征xi的条件概率P(xi|c);下面给出计算方法。
(1)计算P(c):
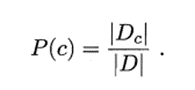
Dc:表示训练集中第c类样本组成的集合;
(2)计算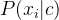 :
:
a、对于离散属性而言
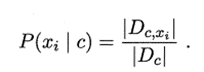
Dc,xi:表示Dc中在第i个属性上取值为xi的样本组成的集合;
b、对于连续属性而言
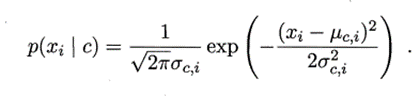
假定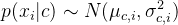 ;
;
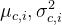 :分别是第c类样本在第i个属性上取值的均值和方差;
:分别是第c类样本在第i个属性上取值的均值和方差;
ps:朴素贝叶斯的3种算法(根据特征的类型):
(1)GaussianNB(高斯分类器):样本特征值的分布是连续值,假设正态分布;
(2)BernoulliNB(伯努利分类器):样本特征值的分布是二元离散值;
(3)MultinomialNB(多项式分类器):样本特征值的分布是多元离散值;
三、案例分析(西瓜集)
数据集:
待测集:

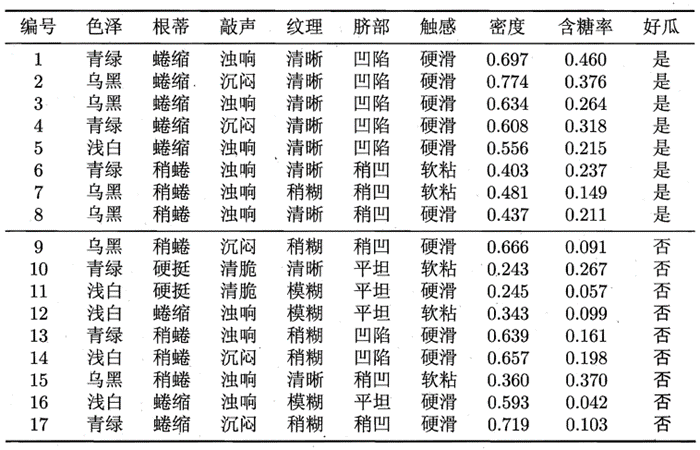
(1)计算先验概率:
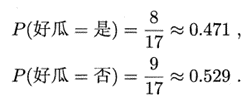
(2)计算每个属性的条件概率:
a、离散属性:
b、连续属性:

(3)计算后验概率:

因为0.038>6.80*10^(-5),所以朴素贝叶斯分类器将待测样本判别为“好瓜”。
四、Python实现NB代码解读
4.1 西瓜集手写代码
(1)加载第三方模块
import numpy as npimport mathimport pandas as pd(2) 定义加载数据集函数
def loadDataSet(): dataSet=[['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'], ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'], ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'], ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'], ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'], ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'], ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'], ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'], ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'], ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'], ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']] testSet= ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 待测集 labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'] # 特征 return dataSet, testSet, labelsdataSet:训练集;
testSet:待测集;
labels:样本所具有的特征的名称;
(3)计算连续属性的均值和标准差
#? 计算(不同类别中指定连续特征的)均值、标准差def mean_std(feature, cla): dataSet, testSet, labels = loadDataSet() lst = [item[labels.index(feature)] for item in dataSet if item[-1]==cla] # 类别为cla中指定特征feature组成的列表 mean = round(np.mean(lst), 3) # 均值 std = round(np.std(lst), 3) # 标准差 return mean, stdfeature:传入指定将要计算其均值的标准差的特征名称;
cla:传入条件概率的条件,计算指定分类cla下该特征的条件概率;
函数返回计算结果:均值mean、标准差std;
(4)计算先验概率
#? 计算先验概率P(c)def prior(): dataSet = loadDataSet()[0] # 载入数据集 countG = 0 # 初始化好瓜数量 countB = 0 # 初始化坏瓜数量 countAll = len(dataSet) for item in dataSet: # 统计好瓜个数 if item[-1] == "好瓜": countG += 1 for item in dataSet: # 统计坏瓜个数 if item[-1] == "坏瓜": countB += 1 # 计算先验概率P(c) P_G = round(countG/countAll, 3) P_B = round(countB/countAll, 3) return P_G,P_BcountG:统计训练集中好瓜的数量;
countB:统计训练集中坏瓜的数量;
countAll:训练集中所有样本的数量;
P_G:好瓜的先验概率;
P_B:坏瓜的先验概率;
函数返回计算出的先验概率P_G、P_B;
(5)计算离散属性的条件概率
#? 计算离散属性的条件概率P(xi|c)def P(index, cla): dataSet, testSet, labels = loadDataSet() # 载入数据集 countG = 0 # 初始化好瓜数量 countB = 0 # 初始化坏瓜数量 for item in dataSet: # 统计好瓜个数 if item[-1] == "好瓜": countG += 1 for item in dataSet: # 统计坏瓜个数 if item[-1] == "坏瓜": countB += 1 lst = [item for item in dataSet if (item[-1] == cla) & (item[index] == testSet[index])] # lst为cla类中第index个属性上取值为xi的样本组成的集合 P = round(len(lst)/(countG if cla=="好瓜" else countB), 3) # 计算条件概率 return Pindex:用于根据待测集样本中特征值的索引位置在训练集中样本的对应索引位置上进行遍历;
cla:用于在训练集中限定样本的类别,便于计算离散属性各特征的条件概率;
countG:统计训练集中好瓜的数量;
countB:统计训练集中坏瓜的数量;
lst:为cla类别中第index个属性上取值为xi的样本组成的集合;
P:离散属性的条件概率;
函数返回计算出的条件概率P;
(6)计算连续属性的条件概率
#? 计算连续属性的条件概率p(xi|c)def p(): dataSet, testSet, labels = loadDataSet() # 载入数据集 denG_mean, denG_std = mean_std("密度", "好瓜") # 好瓜密度的均值、标准差 denB_mean, denB_std = mean_std("密度", "坏瓜") # 坏瓜密度的均值、标准差 sugG_mean, sugG_std = mean_std("含糖率", "好瓜") # 好瓜含糖率的均值、标准差 sugB_mean, sugB_std = mean_std("含糖率", "坏瓜") # 坏瓜含糖率的均值、标准差 # p(密度|好瓜) p_density_G = (1/(math.sqrt(2*math.pi)*denG_std))*np.exp(-(((testSet[labels.index("密度")]-denG_mean)**2)/(2*(denG_std**2)))) p_density_G = round(p_density_G, 3) # p(密度|坏瓜) p_density_B = (1/(math.sqrt(2*math.pi)*denB_std))*np.exp(-(((testSet[labels.index("密度")]-denB_mean)**2)/(2*(denB_std**2)))) p_density_B = round(p_density_B, 3) # p(含糖率|好瓜) p_sugar_G = (1/(math.sqrt(2*math.pi)*sugG_std))*np.exp(-(((testSet[labels.index("含糖率")]-sugG_mean)**2)/(2*(sugG_std**2)))) p_sugar_G = round(p_sugar_G, 3) # p(含糖率|坏瓜) p_sugar_B = (1/(math.sqrt(2*math.pi)*sugB_std))*np.exp(-(((testSet[labels.index("含糖率")]-sugB_mean)**2)/(2*(sugB_std**2)))) p_sugar_B = round(p_sugar_B, 3) return p_density_G, p_density_B, p_sugar_G, p_sugar_BdenG_mean:好瓜密度的均值;
denG_std:好瓜密度的标准差;
denB_mean:坏瓜密度的均值;
denB_std:坏瓜密度的标准差;
sugG_mean:好瓜含糖率的均值;
sugG_std:好瓜含糖率的标准差;
sugB_mean:坏瓜含糖率的均值;
sugB_std:坏瓜含糖率的标准差;
p_density_G:好瓜条件下对于密度这一特征的条件概率;
p_density_B:坏瓜条件下对于密度这一特征的条件概率;
p_sugar_G:好瓜条件下对于含糖率这一特征的条件概率;
p_sugar_B:坏瓜条件下对于含糖率这一特征的条件概率;
函数返回连续属性的条件概率;
(7)计算后验概率
#? 预测后验概率P(c|xi)def bayes(): #? 计算类先验概率 P_G, P_B = prior() #? 计算离散属性的条件概率 P0_G = P(0, "好瓜") # P(青绿|好瓜) P0_B = P(0, "坏瓜") # P(青绿|坏瓜) P1_G = P(1, "好瓜") # P(蜷缩|好瓜) P1_B = P(1, "坏瓜") # P(蜷缩|好瓜) P2_G = P(2, "好瓜") # P(浊响|好瓜) P2_B = P(2, "坏瓜") # P(浊响|好瓜) P3_G = P(3, "好瓜") # P(清晰|好瓜) P3_B = P(3, "坏瓜") # P(清晰|好瓜) P4_G = P(4, "好瓜") # P(凹陷|好瓜) P4_B = P(4, "坏瓜") # P(凹陷|好瓜) P5_G = P(5, "好瓜") # P(硬滑|好瓜) P5_B = P(5, "坏瓜") # P(硬滑|好瓜) #? 计算连续属性的条件概率 p_density_G, p_density_B, p_sugar_G, p_sugar_B = p() #? 计算后验概率 isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * p_density_G * p_sugar_G # 计算是好瓜的后验概率 isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * p_density_B * p_sugar_B # 计算是坏瓜的后验概率 return isGood,isBad调用prior()函数计算先验概率;
调用P()函数计算离散属性的条件概率;
调用p()函数计算连续属性的条件概率;
isGood:好瓜的后验概率;
isBad:坏瓜的后验概率;
函数返回后验概率的计算结果isGood、isBad;
(8)主函数调用上述函数模块
if __name__=='__main__': dataSet, testSet, labels = loadDataSet() testSet = [testSet] df = pd.DataFrame(testSet, columns=labels, index=[1]) print("=======================待测样本========================") print(f"待测集:\n{df}") isGood, isBad = bayes() print("=======================后验概率========================") print("后验概率:") print(f"P(好瓜|xi) = {isGood}") print(f"P(好瓜|xi) = {isBad}") print("=======================预测结果========================") print("predict ---> 好瓜" if (isGood > isBad) else "predict ---> 坏瓜")运行结果:
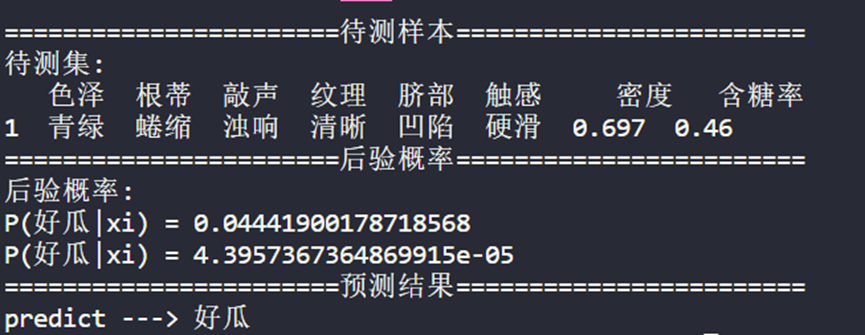
从上图的终端输出结果可以看到待测样本的各个属性值,然后可以看到后验概率的计算结果,最后是预测结果,此样本的预测结果为“好瓜”。
此训练集与待测样本是“朴素贝叶斯西瓜集分类案例”的数据,通过比较最终的两个预测结果一致,也可表明朴素贝叶斯分类器编写代码基本正确。
4.2 鸢尾花手写代码
参考4.1
运行结果:

4.3 鸢尾花第三方库
(1)加载第三方模块
import pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.naive_bayes import GaussianNBfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score因为鸢尾花数据集中各特征为连续特征值,所以需要导入sklearn库中的高斯朴素贝叶斯分类器GaussianNB;
下面通过定义了一个bayes_model类
#? 定义朴素贝叶斯分类器class bayes_model(): def __int__(self): pass(2)定义加载数据函数
#? 加载数据 def load_data(self): data = load_iris() iris_data = data.data iris_target = data.target iris_featureNames = data.feature_names iris_features = pd.DataFrame(data=iris_data, columns=iris_featureNames) train_x, test_x, train_y, test_y = train_test_split(iris_features, iris_target, test_size=0.3, random_state=123) return train_x, test_x, train_y, test_ydata:加载sklearn库中的鸢尾花数据集;
iris_data:加载鸢尾花数据集的属性值;
iris_target:加载鸢尾花数据集的分类标签;
iris_featureNames:加载数据的特征名称;
train_test_split()函数:将数据集划分为训练集和测试集;
函数返回划分好的训练集和测试集;
(3)训练高斯朴素贝叶斯分类器
#? 训练高斯朴素贝叶斯模型 def train_model(self, train_x, train_y): clf = GaussianNB() clf.fit(train_x, train_y) return clfclf:定义一个高斯朴素贝叶斯分类器(因为鸢尾花数据集中特征值为连续值);
clf.fit():表示对高斯朴素贝叶斯分类器进行训练;
函数返回一个训练好的高斯朴素贝叶斯分类器;
(4)处理预测数据,进行终端输出
#? 处理预测的数据 def proba_data(self, clf, test_x, test_y): y_predict = clf.predict(test_x) # 返回待预测样本的预测结果(所属类别) y_proba = clf.predict_proba(test_x) # 返回预测样本属于各标签的概率 accuracy = accuracy_score(test_y, y_predict) * 100 # 计算predict预测的准确率 return y_predict, y_proba, accuracyy_predict:对测试样本进行类别预测,预测结果是一个确定的分类类别;
y_proba:预测测试样本属于各类别的概率,预测结果是一个概率序列;
accuracy:计算训练好的高斯朴素贝叶斯分类器对测试集的分类准确率;
(5)训练数据
#? 训练数据 def exc_p(self): train_x, test_x, train_y, test_y = self.load_data() # 加载数据 clf = self.train_model(train_x, train_y) # 训练 高斯朴素贝叶斯 模型clf y_predict, y_proba, accuracy = self.proba_data(clf, test_x, test_y) # 利用训练好的模型clf对测试集test_x进行结果预测分析 return train_x, test_x, train_y, test_y, y_predict, y_proba, accuracy调用load_data()函数:加载数据,训练集和测试集;
调用train_model()函数:根据巡礼那及训练一个高斯朴素贝叶斯分类器;
调用proba_data()函数:利用训练好的分类器对测试集进行分类;
(6)主函数调用上述模块
if __name__ == '__main__': train_x, test_x, train_y, test_y, y_predict, y_proba, accuracy = bayes_model().exc_p() # 训练集与其标签 df1 df1_1 = pd.DataFrame(train_x).reset_index(drop=True) df1_2 = pd.DataFrame(train_y) df1 = pd.merge(df1_1, df1_2, left_index=True, right_index=True) df1.columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)', 'train classify'] print("=============================================训练集==============================================") print(f'The train dataSet is:\n{df1}\n') # 测试集与其标签 df2 df2_1 = pd.DataFrame(test_x).reset_index(drop=True) df2_2 = pd.DataFrame(test_y) df2 = pd.merge(df2_1, df2_2, left_index=True, right_index=True) df2.columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)', 'test classify'] print("=============================================测试集==============================================") print(f'The test dataSet is:\n{df2}\n') # 预测结果 tot1 = pd.DataFrame([test_y, y_predict]).T tot2 = pd.DataFrame(y_proba).applymap(lambda x: '%.2f' % x) tot = pd.merge(tot1, tot2, left_index=True, right_index=True) tot.columns=['y_true', 'y_predict', 'predict_0', 'predict_1', 'predict_2'] print("============================================预测结果==============================================") print('The result of predict is: \n', tot) print("=============================================准确率==============================================") print(f'The accuracy of Testset is: {accuracy:.2f}%')df1:训练集的二维结构;
df2:测试集的二维结构;
tot:预测结果的二维结构;
运行结果:
终端输出的训练集:
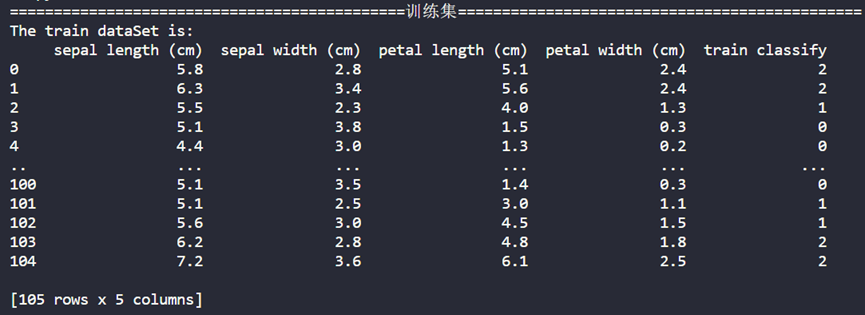
训练集中有105的样本,第1~5列数值分别表示为花萼长度、花萼宽度、花瓣长度、花瓣宽度、所属类别。
终端输出的测试集:

测试集中共有45个样本。
终端输出的准确率和预测结果:
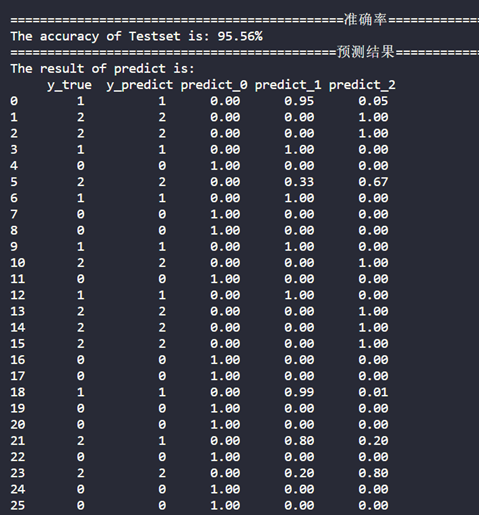
从上图可以看到最终训练好的高斯朴素贝叶斯分类器对测试集中45个样本的分类准确率高达95%,也就是说45个样本中只有2个样本分类错误,其余全部分类正确。
预测结果是一个二维矩阵的呈现形式,每一行代表一个样本的预测信息,第1列表示测试集中样本的正确标签,第2列为预测的标签,第3~5列表示预测结果为三个类别的可能概率(概率和为1);
五、Python实现NB代码汇总
5.1 不使用sklearn中方法
5.1.1 数据集:西瓜集3.0(来自西瓜书《机器学习 周志华》84页)
#! 朴素贝叶斯分类器_西瓜集分类import numpy as npimport mathimport pandas as pd#? 加载数据集def loadDataSet(): dataSet=[['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460, '好瓜'], ['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.774, 0.376, '好瓜'], ['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.634, 0.264, '好瓜'], ['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', 0.608, 0.318, '好瓜'], ['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.556, 0.215, '好瓜'], ['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.403, 0.237, '好瓜'], ['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', 0.481, 0.149, '好瓜'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', 0.437, 0.211, '好瓜'], ['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', 0.666, 0.091, '坏瓜'], ['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', 0.243, 0.267, '坏瓜'], ['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', 0.245, 0.057, '坏瓜'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', 0.343, 0.099, '坏瓜'], ['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', 0.639, 0.161, '坏瓜'], ['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', 0.657, 0.198, '坏瓜'], ['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', 0.360, 0.370, '坏瓜'], ['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', 0.593, 0.042, '坏瓜'], ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', 0.719, 0.103, '坏瓜']] testSet= ['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460] # 待测集 labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'] # 特征 return dataSet, testSet, labels#? 计算(不同类别中指定连续特征的)均值、标准差def mean_std(feature, cla): dataSet, testSet, labels = loadDataSet() lst = [item[labels.index(feature)] for item in dataSet if item[-1]==cla] # 类别为cla中指定特征feature组成的列表 mean = round(np.mean(lst), 3) # 均值 std = round(np.std(lst), 3) # 标准差 return mean, std#? 计算先验概率P(c)def prior(): dataSet = loadDataSet()[0] # 载入数据集 countG = 0 # 初始化好瓜数量 countB = 0 # 初始化坏瓜数量 countAll = len(dataSet) for item in dataSet: # 统计好瓜个数 if item[-1] == "好瓜": countG += 1 for item in dataSet: # 统计坏瓜个数 if item[-1] == "坏瓜": countB += 1 # 计算先验概率P(c) P_G = round(countG/countAll, 3) P_B = round(countB/countAll, 3) return P_G,P_B#? 计算离散属性的条件概率P(xi|c)def P(index, cla): dataSet, testSet, labels = loadDataSet() # 载入数据集 countG = 0 # 初始化好瓜数量 countB = 0 # 初始化坏瓜数量 for item in dataSet: # 统计好瓜个数 if item[-1] == "好瓜": countG += 1 for item in dataSet: # 统计坏瓜个数 if item[-1] == "坏瓜": countB += 1 lst = [item for item in dataSet if (item[-1] == cla) & (item[index] == testSet[index])] # lst为cla类中第index个属性上取值为xi的样本组成的集合 P = round(len(lst)/(countG if cla=="好瓜" else countB), 3) # 计算条件概率 return P#? 计算连续属性的条件概率p(xi|c)def p(): dataSet, testSet, labels = loadDataSet() # 载入数据集 denG_mean, denG_std = mean_std("密度", "好瓜") # 好瓜密度的均值、标准差 denB_mean, denB_std = mean_std("密度", "坏瓜") # 坏瓜密度的均值、标准差 sugG_mean, sugG_std = mean_std("含糖率", "好瓜") # 好瓜含糖率的均值、标准差 sugB_mean, sugB_std = mean_std("含糖率", "坏瓜") # 坏瓜含糖率的均值、标准差 # p(密度|好瓜) p_density_G = (1/(math.sqrt(2*math.pi)*denG_std))*np.exp(-(((testSet[labels.index("密度")]-denG_mean)**2)/(2*(denG_std**2)))) p_density_G = round(p_density_G, 3) # p(密度|坏瓜) p_density_B = (1/(math.sqrt(2*math.pi)*denB_std))*np.exp(-(((testSet[labels.index("密度")]-denB_mean)**2)/(2*(denB_std**2)))) p_density_B = round(p_density_B, 3) # p(含糖率|好瓜) p_sugar_G = (1/(math.sqrt(2*math.pi)*sugG_std))*np.exp(-(((testSet[labels.index("含糖率")]-sugG_mean)**2)/(2*(sugG_std**2)))) p_sugar_G = round(p_sugar_G, 3) # p(含糖率|坏瓜) p_sugar_B = (1/(math.sqrt(2*math.pi)*sugB_std))*np.exp(-(((testSet[labels.index("含糖率")]-sugB_mean)**2)/(2*(sugB_std**2)))) p_sugar_B = round(p_sugar_B, 3) return p_density_G, p_density_B, p_sugar_G, p_sugar_B#? 预测后验概率P(c|xi)def bayes(): #? 计算类先验概率 P_G, P_B = prior() #? 计算离散属性的条件概率 P0_G = P(0, "好瓜") # P(青绿|好瓜) P0_B = P(0, "坏瓜") # P(青绿|坏瓜) P1_G = P(1, "好瓜") # P(蜷缩|好瓜) P1_B = P(1, "坏瓜") # P(蜷缩|好瓜) P2_G = P(2, "好瓜") # P(浊响|好瓜) P2_B = P(2, "坏瓜") # P(浊响|好瓜) P3_G = P(3, "好瓜") # P(清晰|好瓜) P3_B = P(3, "坏瓜") # P(清晰|好瓜) P4_G = P(4, "好瓜") # P(凹陷|好瓜) P4_B = P(4, "坏瓜") # P(凹陷|好瓜) P5_G = P(5, "好瓜") # P(硬滑|好瓜) P5_B = P(5, "坏瓜") # P(硬滑|好瓜) #? 计算连续属性的条件概率 p_density_G, p_density_B, p_sugar_G, p_sugar_B = p() #? 计算后验概率 isGood = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G * p_density_G * p_sugar_G # 计算是好瓜的后验概率 isBad = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B * p_density_B * p_sugar_B # 计算是坏瓜的后验概率 '''print(P_G) print(P_B) print(P0_G) print(P0_B) print(P1_G) print(P1_B) print(P2_G) print(P2_B) print(P3_G) print(P3_B) print(P4_G) print(P4_B) print(P5_G) print(P5_B) print(p_density_G) print(p_density_B) print(p_sugar_G) print(p_sugar_B)''' return isGood,isBadif __name__=='__main__': dataSet, testSet, labels = loadDataSet() testSet = [testSet] df = pd.DataFrame(testSet, columns=labels, index=[1]) print("=======================待测样本========================") print(f"待测集:\n{df}") isGood, isBad = bayes() print("=======================后验概率========================") print("后验概率:") print(f"P(好瓜|xi) = {isGood}") print(f"P(好瓜|xi) = {isBad}") print("=======================预测结果========================") print("predict ---> 好瓜" if (isGood > isBad) else "predict ---> 坏瓜")5.1.2 数据集:鸢尾花iris(来自sklearn提供的数据集)
#! 朴素贝叶斯分类器_鸢尾花分类import numpy as npfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_scoreiris = load_iris()X = iris.datay = iris.targetX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)#? 计算先验概率p(c)# 存储在p_c列表内p_c=[p(0), p(1), p(2)]def prior(): p_c = [] for c in np.unique(y_train): tmp = [x for x in y_train if x==c] p_c.append(len(tmp) / len(y_train)) return p_c#? 计算条件概率p(xi|c)# 存储在p_xc列表内p_xc=[p(x1|c), p(x2|c), p(x3|c), p(x4|c)]def p_xc(x, cla): tar = [X_train[i] for i, c in enumerate(y_train) if c==cla] mean = np.mean(tar,axis=0) # 均值 var = np.var(tar,axis=0) # 方差 p_xc = np.exp(-(x-mean)**2 / (2*var)) / np.sqrt(2*np.pi*var) return p_xc#? 根据后验概率p(ci|x)预测结果# 后验概率存储在proba列表内proba=[p(0|x), p(1|x), p(2|x)]def predict(): pred = [] # 存放预测结果 for x in X_test: proba = [] # 存放属于各个类的概率(后验概率) for i,c in enumerate(np.unique(y_train)): P_c = prior() P_xc = p_xc(x,c) proba.append(P_c[i]*np.prod(P_xc)) res = np.unique(y_train)[proba.index(max(proba))] pred.append(res) return np.array(pred)y_pred = predict()accuracy = accuracy_score(y_test, y_pred) # 计算准确率print(f'y_test: {y_test}')print(f'y_pred: {y_pred}')print("准确率:", accuracy)5.2 使用sklearn中的方法
5.2.1 数据集:鸢尾花iris(来自sklearn提供的数据集)
#! 高斯朴素贝叶斯分类器_鸢尾花分类import pandas as pdfrom sklearn.datasets import load_irisfrom sklearn.naive_bayes import GaussianNBfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score#? 定义朴素贝叶斯分类器class bayes_model(): def __int__(self): pass #? 加载数据 def load_data(self): data = load_iris() iris_data = data.data iris_target = data.target iris_featureNames = data.feature_names iris_features = pd.DataFrame(data=iris_data, columns=iris_featureNames) train_x, test_x, train_y, test_y = train_test_split(iris_features, iris_target, test_size=0.3, random_state=123) return train_x, test_x, train_y, test_y #? 训练高斯朴素贝叶斯模型 def train_model(self, train_x, train_y): clf = GaussianNB() clf.fit(train_x, train_y) return clf #? 处理预测的数据 def proba_data(self, clf, test_x, test_y): y_predict = clf.predict(test_x) # 返回待预测样本的预测结果(所属类别) y_proba = clf.predict_proba(test_x) # 返回预测样本属于各标签的概率 accuracy = accuracy_score(test_y, y_predict) * 100 # 计算predict预测的准确率 return y_predict, y_proba, accuracy #? 训练数据 def exc_p(self): train_x, test_x, train_y, test_y = self.load_data() # 加载数据 clf = self.train_model(train_x, train_y) # 训练 高斯朴素贝叶斯 模型clf y_predict, y_proba, accuracy = self.proba_data(clf, test_x, test_y) # 利用训练好的模型clf对测试集test_x进行结果预测分析 return train_x, test_x, train_y, test_y, y_predict, y_proba, accuracy if __name__ == '__main__': train_x, test_x, train_y, test_y, y_predict, y_proba, accuracy = bayes_model().exc_p() # 训练集与其标签 df1 df1_1 = pd.DataFrame(train_x).reset_index(drop=True) df1_2 = pd.DataFrame(train_y) df1 = pd.merge(df1_1, df1_2, left_index=True, right_index=True) df1.columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)', 'train classify'] print("=============================================训练集==============================================") print(f'The train dataSet is:\n{df1}\n') # 测试集与其标签 df2 df2_1 = pd.DataFrame(test_x).reset_index(drop=True) df2_2 = pd.DataFrame(test_y) df2 = pd.merge(df2_1, df2_2, left_index=True, right_index=True) df2.columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)', 'test classify'] print("=============================================测试集==============================================") print(f'The test dataSet is:\n{df2}\n') # 预测结果 tot1 = pd.DataFrame([test_y, y_predict]).T tot2 = pd.DataFrame(y_proba).applymap(lambda x: '%.2f' % x) tot = pd.merge(tot1, tot2, left_index=True, right_index=True) tot.columns=['y_true', 'y_predict', 'predict_0', 'predict_1', 'predict_2'] print("============================================预测结果==============================================") print('The result of predict is: \n', tot) print("=============================================准确率==============================================") print(f'The accuracy of Testset is: {accuracy:.2f}%')