
文章目录
前言
背景介绍
C28x内核
浮点单元(FPU)
快速整数除法单元(FINTDIV)
三角数学单元(TMU)
VCRC单元
CPU总线
指令流水线
总结
参考资料
前言
见《【研发日记】嵌入式处理器技能解锁(一)——多任务异步执行调度的三种方法》
见《【研发日记】嵌入式处理器技能解锁(二)——TI C2000 DSP的SCI(串口)通信》
背景介绍
C28x CPU是一个32位的定点处理器,该器件借鉴了DSP的最佳特性、精简指令集计算(RISC)、MCU架构、固件和工具集。其在TI C2000 DSP芯片的整体架构中,所处的位置如下:
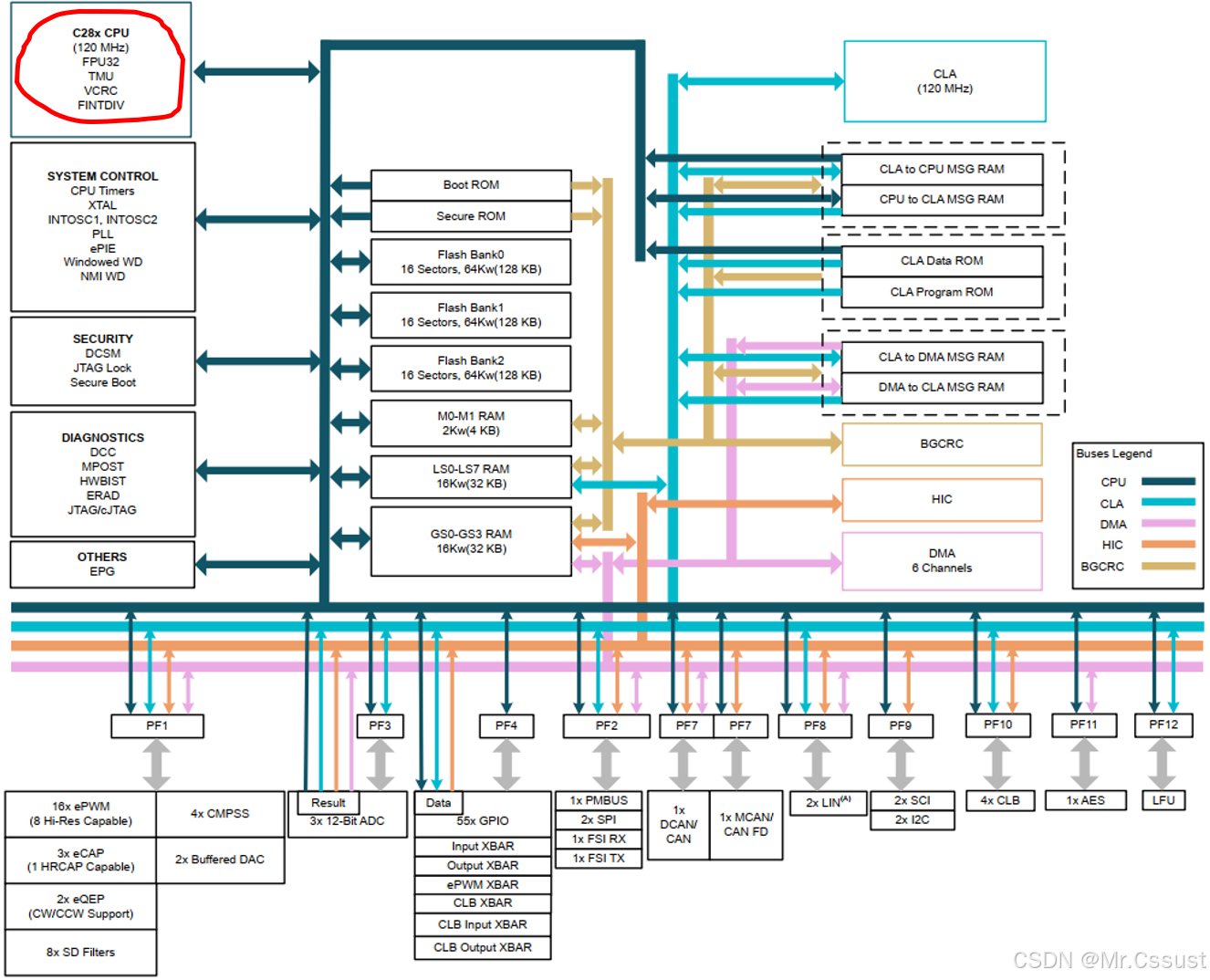
C28x内核
C28x CPU使用改进后Harvard架构和循环寻址。改进后的Harvard架构使指令和数据获取能够并行执行。CPU可以在读取指令和数据时,同时写入数据,以在整个流水线中保持单周期指令操作。CPU通过六条独立的地址/数据总线完成此操作。RISC特性包括:指令单周期执行、寄存器到寄存器操作和改进后的Harvard架构。MCU特性包括:通过直观的指令集、字节打包和解包以及位操作来实现易用性。C28x CPU的的组成结构如下:
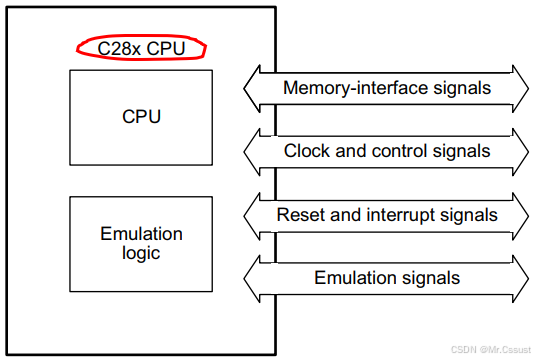
CPU Block用于程序存储器寻址、提取数据;解码和执行指令(8级流水线);执行算术、逻辑和移位运算;以及控制CPU寄存器、数据存储器和程序存储器之间的数据传输。
Emulation logic Block用于监测和控制DSP的各种部件和功能,用于芯片Debug和Test。
Signals Block用于与提供一个CPU对外的接口,连接到memory、外围设备,对CPU和Emulation logic进行计时和控制,显示CPU和仿真逻辑状态,以及interrupts的应用。
浮点单元(FPU)
C28x通过增加浮点处理器(FPU)——支持IEEE单精度浮点运算的寄存器和指令,来扩展C28x原本定点CPU的功能。C28x+FPU,包含标准C28x寄存器集以及一组额外的浮点单元寄存器。额外的浮点单元寄存器如下:
• 八个浮点Result寄存器,RnH(其中n=0~7)
• 浮点Status寄存器(STF)
• 重复Block寄存器(RB)
Tips:除RB寄存器外,所有浮点寄存器都采用shadowed技术。这种影子化技术可用于更高优先级任务的中断,以实现浮点寄存器的快速上下文保存和恢复。
快速整数除法单元(FINTDIV)
C28x CPU的快速整数除法单元(Fast Integer Division, FINTDIV)独特地支持三种类型的整数除法(Truncated, Modulo, and Euclidean),这些整数除法具有不同的数据类型大小(16/16、32/16、32/32、64/32、64/64),采用无符号或有符号格式。
• C语言天然支持Truncated整数除法(/、% 算符)。
• Modulo除法和Euclidean除法是更高效的控制算法,并受C内在函数支持。
所有三种类型的整数除法都会产生商和余数分量,具有可截断特性,并在最少的系统周期内执行(32/32除法为10个周期)。此外,C28x CPU的快速除法功能,独特地支持浮点32位(5个周期内)和64位(20个周期内)除法的快速执行,。
三角数学单元(TMU)
三角函数加速器(trigonometric math unit, TMU),利用现有的C28x+FPU增加指令,加速执行常见三角函数和下表中所列的算术运算,以此来扩展C28x+FPU的功能。

TMU已添加指数指令IEXP2F32和对数指令LOG2F32,可支持计算浮点幂函数,用于C2000 Digital Control Library中的非线性比例积分微分控制(NLPID)组件。添加的这两条指令,可以将幂函数计算周期,从使用library emulation时的典型300个周期减少到不到10个周期。
Tips:TMU对现有指令、流水线和内存总线架构均未做任何更改。所有TMU指令都使用现有的FPU寄存器集(R0H至R7H)来执行运算。
VCRC单元
循环冗余校验(CRC)算法提供了一种简单的方法来验证大型数据块、通信数据包或代码段的数据完整性。C28x+VCRC可执行8 位、16位、24位和32位的CRC。例如,VCRC可以在10个系统周期内计算出10字节数据块的CRC。CRC Result寄存器包含当前CRC,每次执行CRC指令时,该CRC都会更新。
以下是VCRC的CRC计算逻辑使用的CRC多项式:
• CRC8 多项式 = 0x07
• CRC16 多项式1 = 0x8005
• CRC16 多项式2 = 0x1021
• CRC24 多项式 = 0x5d6dcb
• CRC32 多项式1 = 0x04c11db7
• CRC32 多项式2 = 0x1edc6f41
该模块可以在单个周期内为一个字节的数据计算CRC。CRC8、CRC16、CRC24和CRC32的CRC计算,是按字节完成的(而不是C28x内核计算CRC时读取完整的16位或32位数据),以便与各种标准规定的按字节计算要求保持一致。
VCRC单元还允许用户提供自己多项式(1b-32b)来满足自定义CRC要求。使用自定义多项式时,CRC执行时间会增加到三个系统周期。
CPU总线
CPU最大的作用就是寻址和读写数据。寻址就是ARAU(Address register arithmetic unit)要干的事情,即在Memory(包括RAM、ROM和寄存器)中找到当前想用的Address,比如program space(program counter PC指针)、data space和register space中的某个地址。读写数据就是在这个Address上提取Bytes或者放入Bytes。这些操作都需要通过CPU总线来完成,如下图所示:
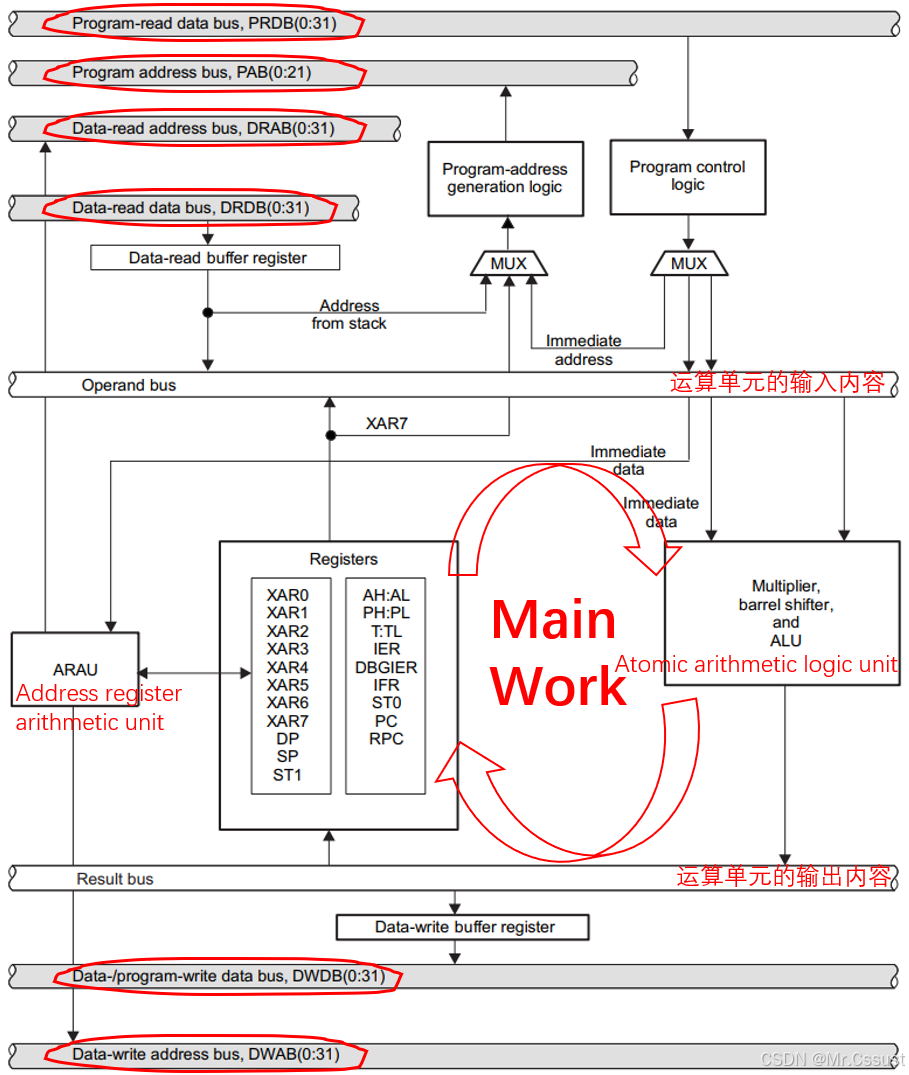
Address总线是传输Address的,比如program space的22bit address,data space的32bit address,register space的映射地址。
Data总线是传输Bytes的,比如program space的程序指令,data space的变量值,register space的寄存器值。
C28x的6条独立CPU总线,互相之间的工作关系,如下表所示:

Tips:上述6条总线是独立的,所以可以同时运行,互不影响。但是PAB和DWDB这两个总线是复用的,比如Read program和Write program这两件事都需要用PAB总线,那么这两件事就不能同时执行,需要先执行一个然后再执行另一个。DWDB也同理。
指令流水线
C28x每条指令的执行都要经过8个独立的阶段,形成一个指令流水线(pipeline)。在任何时刻,最多可以有8条指令处于运行状态,这8条指令都处于不同的运行阶段。如下图所示:
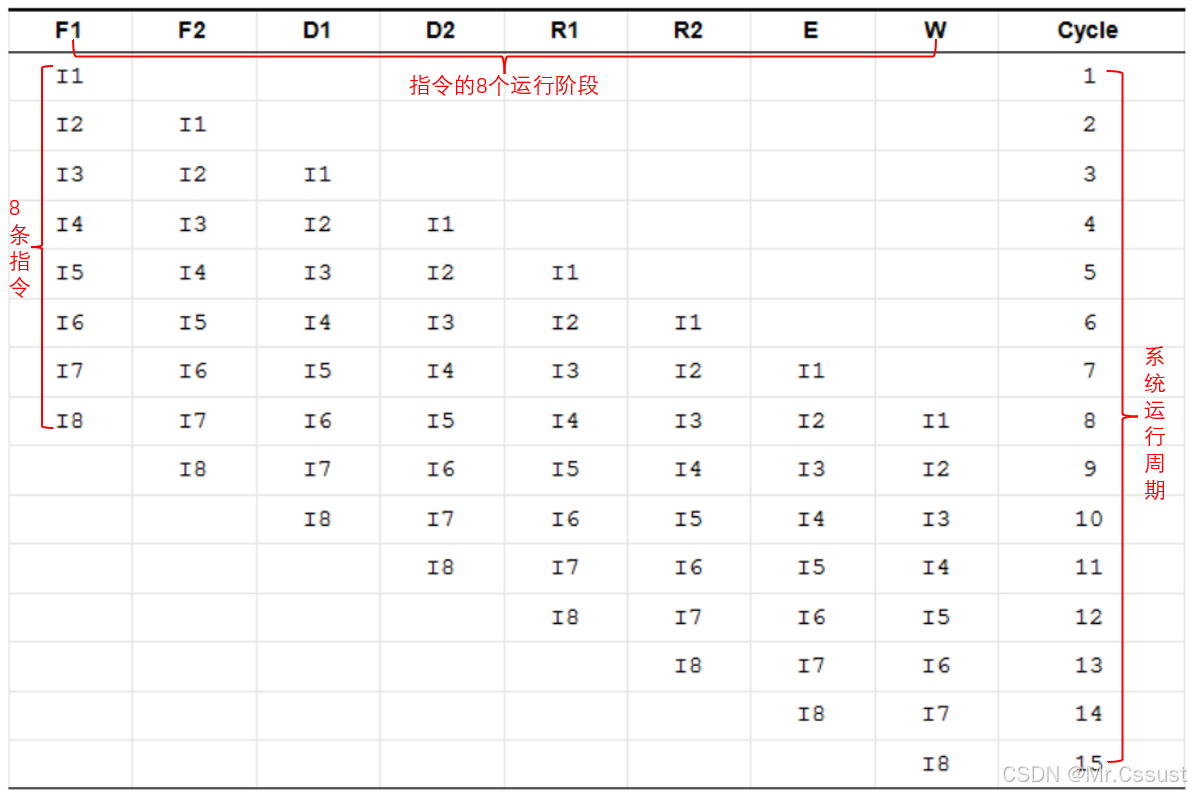
Fetch 1 (F1):从Memory抓取指令的第一步,CPU在program address bus上发出指令所在的地址(22-bit);
Fetch 2 (F2):从Memory抓取指令的第二步,CPU在program read data bus上获取指令内容(32-bit);
Decode 1 (D1):指令解码第一步,识别和判定指令是否合法;
Decode 2 (D2):指令解码第二步,加载到指令寄存器中,完成解码;
Read 1 (R1):从Memory抓取Bytes的第一步,CPU在data read address bus上发出Bytes所在的地址(32-bit);
Read 2 (R2):从Memory抓取Bytes的第二步,CPU在data read data bus上获取Bytes内容(32-bit);
Execute (E):运行指令,CPU运行各种原始的multiplier、shifter、logic和ALU操作,把运算结果写入CPU的result寄存区;
Write (W):向Memory中写入Bytes,CPU在data write address bus上发出Bytes所在的地址(32-bit),在data write data bus上发出Bytes内容(32-bit)。
Tip1:指令不同阶段的读写可能会对同一位置进行操作,但流水线的保护机制会根据需要暂停某些指令,以确保对同一位置的读写按照编程顺序正确进行。
Tip2:一旦指令到达Decode 2阶段,即使有中断发生,也会先把这条指令运行到最后阶段完成。
Tip3:不同的指令会有不一样的执行过程,上述8个运行阶段不是一定都要运行,有的指令只需要运行其中的几个。
总结
以上就是本人在研发中使用嵌入式处理器的C28x内核时,一些个人理解和分析的总结,主要介绍了C28x内核的工作原理,展示了具体的使用方法,并对比分析了它的特点和适用场景。
后续还会分享另外几个最近解锁的嵌入式处理器新技能,欢迎评论区留言、点赞、收藏和关注,这些鼓励和支持都将成文本人持续分享的动力。
另外,上述例程使用的Demo工程,可以到笔者的主页查找和下载。
参考资料
TMS320F28003x Real-Time Microcontrollers datasheet.pdf版权声明,原创文章,转载和引用请注明出处和链接,侵权必究!
