Preface:Implementing path analysis
1.Data source analysis
1. Identify the requirements:
Website:https://sz.lianjia.com/ershoufang/
Target acquisition variables: Location, Street, Total price, Price per square meter, House type, Square meter, Direction, Decorate situation, Floor situation, Floor number, House structure.
2. Data capture analysis
Need to turn on the website developer mode(Command+Option+I)
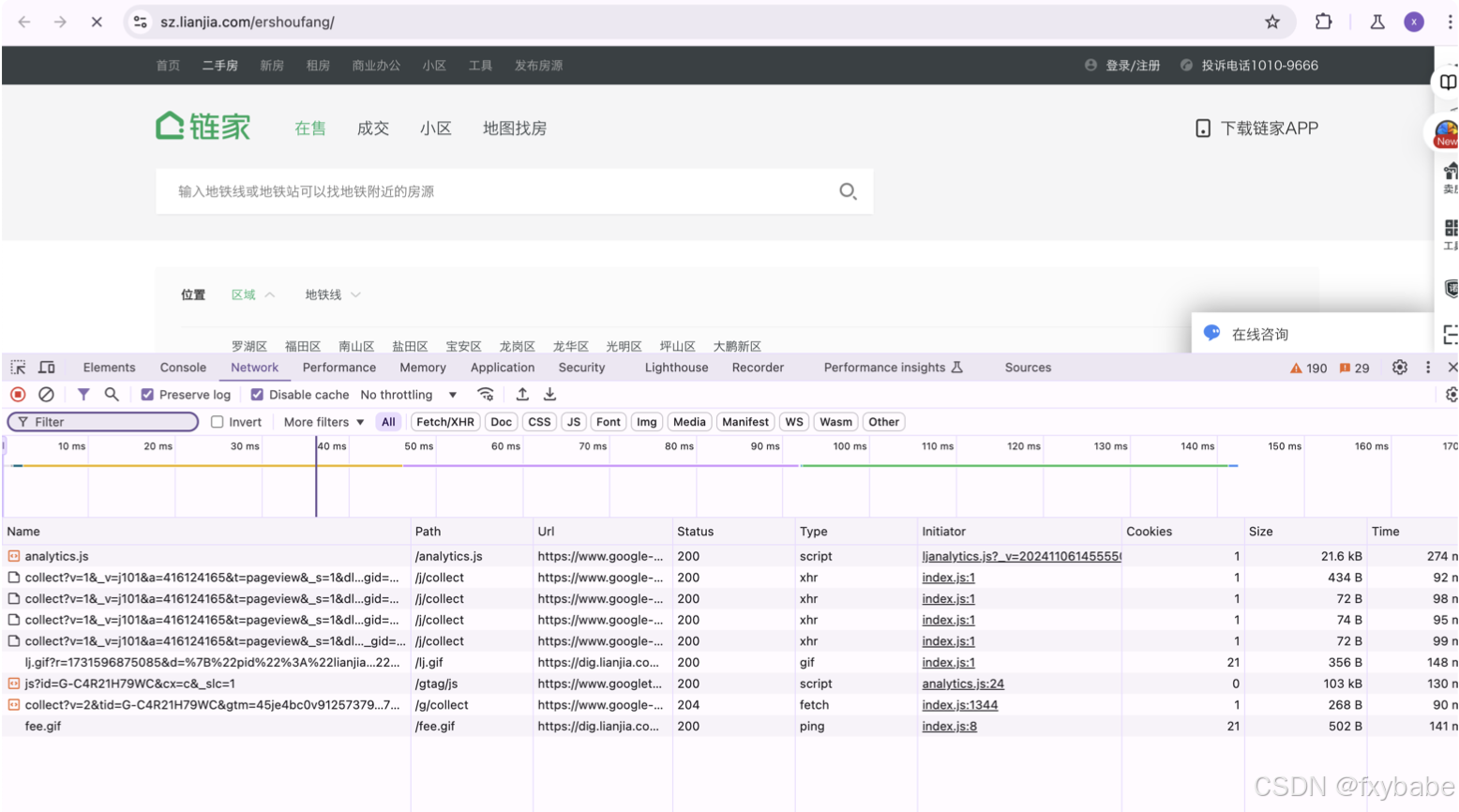
Retrieve the corresponding data packet by keywords
2.Code implementation steps
1. Send data request
Simulate browser to send request to URL address
2. Acquire data
Get the server and return the response data
Using developer tools get the whole data from website
3. Parsing data
Extract the required data content
4. Save data in CSV format
Execute step by step according to the design ideas
1. Send data request to the website:https://sz.lianjia.com/ershoufang/
1. Simulate browser
The browser's User-Agent contains information about the browser type, version, etc. If crawler wants to obtain the content of a specific version of the web page , it needs to set the appropriate User-Agent.
2.Set data request command
The requests library is a tool for sending HTTP requests to the target website to obtain web page content
Similarly, Developer mode - network - select names - Headers list to query Request URL
3.Send data request
requests.get() is a function in the requests library that sends an HTTP GET request to a specified URL
The headers parameter is used to pass request header information
4.Result of executing the program is<Response [200]>,which is the response object, indicating that the request was successful
import requestsheaders={ 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36'}url='https://sz.lianjia.com/ershoufang/'
response=requests.get(url=url,headers=headers)print(response)
2. Acquire text data(Web raw data)
1. Extract the text content from the response object obtained by the request method,
and assign it to the html_data variable
html_data=response.text
print(html_data)
3. Parse and extract the data
1. General parsing methods:Regular Expression, CSS Selector, XPath Node
Extraction, BeautifulSoup, JavaScript Object Notation
2. Here I would use 2 methods ——CSS selector and BeautifulSoup to parse data
4. Part 1: Usage of CSS selector:
Introduction of CSS selector
The CSS selector can extract data content based on tag attributes and its syntax is relatively simple and intuitive. Through flexible combination selectors, we can accurately locate the elements that need to be extracted
Parsel is a Python library for parsing HTML and XML. It can locate HTML elements using CSS selector syntax. Import it
Selector could convert the HTML text content from the obtained web into a parseable object so that the required data can be extracted
Determine the area where to be extracted
3. In developer mode, select the area and click the corresponding label to view its CSS syntax
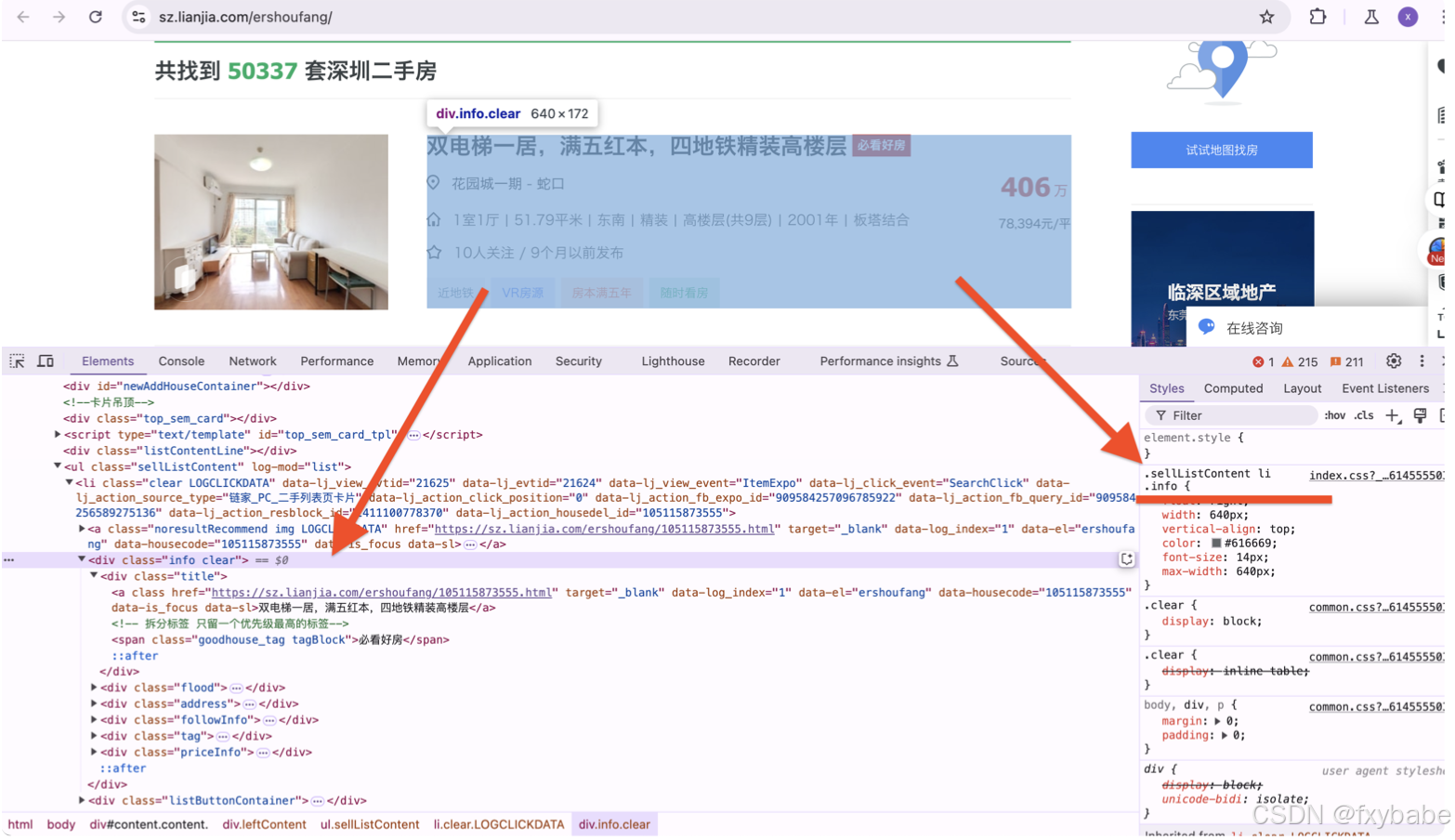
4.Extract the label according to the syntax. 'divs' is a list containing 30 pieces of labels from the house data on this web page
5.Extract specific data, including title, community name, street, total price, price per square meter, and other descriptive information.
import parselselector=parsel.Selector(html_data)print(selector)
divs=selector.css('.sellListContent li .info')print(selector)print(divs) for div in divs: title=div.css('.title a::text').get() total_price=div.css('.totalPrice span::text').get() area_list=div.css('.positionInfo a::text').getall() unit_price=div.css('.unitPrice span::text').get().replace('元/平','') house_info=div.css('.houseInfo::text').get().split('|') 5. Part 2: Usage of BeautifulSoup
Introduction of BeautifulSoup
Beautiful Soup is a library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree
Similarly, from the given HTML data (html_data), the BeautifulSoup library is used to extract content such as the house title, area, unit price, total price, and house details, and store them in the corresponding variables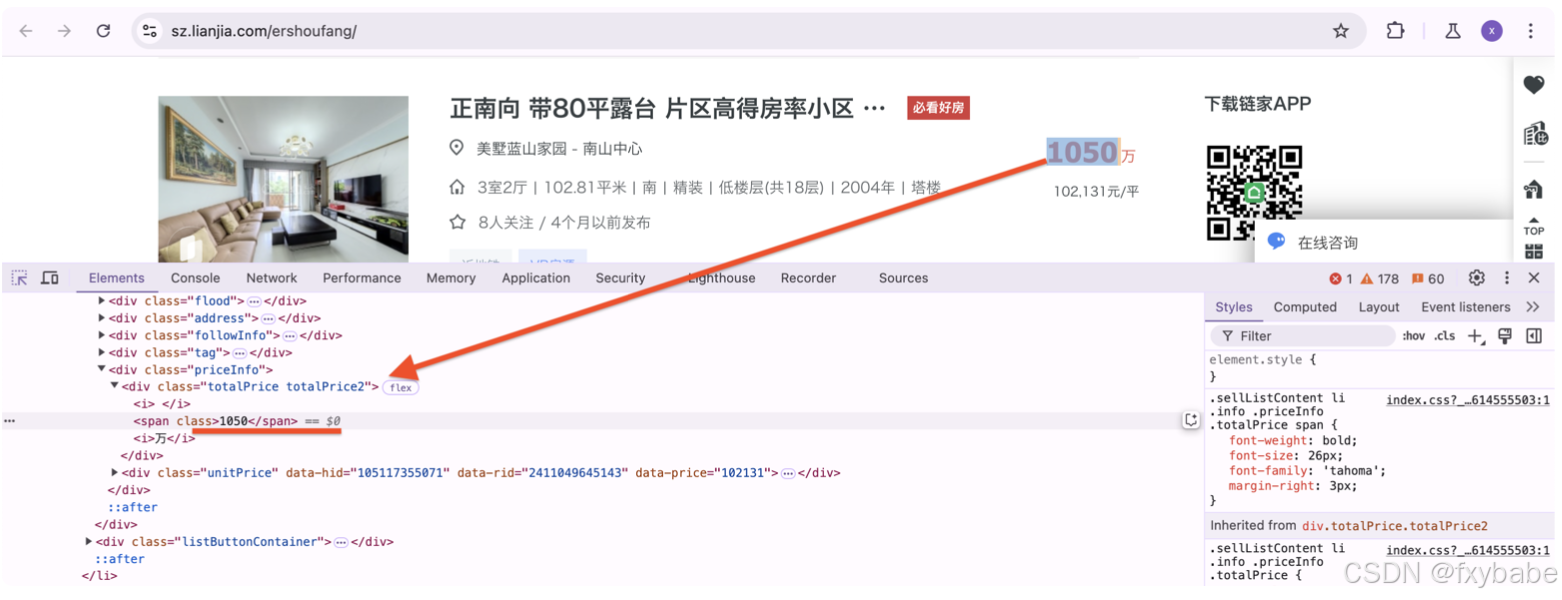
from bs4 import BeautifulSoupsoup=BeautifulSoup(html_data,'html.parser')
title = [tag.text for tag in soup.select("div[class='title']")[:30]]area_list = [tag.text for tag insoup.select("div[class='positionInfo']")]unit_price = [tag.text for tag in soup.select("div[class='unitPrice']")]total_price = [tag.text for tag in soup.select("div[class='totalPricetotalPrice2']")] house_info = [tag.text for tag in soup.select("div[class='houseInfo']")] print(unit_price)print(total_price)print(title)
print(area_list)print(house_info)
6. Organizing the data
1. Categorize the crawled data into areas, streets, house types, squares, orientations, decorations, floors, and house structures
2.Using Regular Expression sort out the floor height data. '\d+' means matching numeric characters, so that the individual floor values can be sorted out
3.Using logical language sort out house age because some information doesn't contain age data
4.The result of these programs is a dictionary storing 30 pieces of house information from page 1. Here are the screenshots of the first 10 results.
import re #Regular Expression
area=area_list[0]area_1=area_list[1]house_type=house_info[0]house_square=house_info[1]house_direction=house_info[2]house_decorate=house_info[3]house_floor=house_info[4]floor_type=house_info[4][1]floor_num=re.findall('\d+',house_floor)[0]house_structure=house_info[-1] if len(house_info)==7: house_age=house_info[5]
else: house_age='NA'
dict={'title':title,'name':area,'street':area_1,'totalprice':total_price,'unitprice':unit_price,'type':house_type,'square':house_square,'direction':house_direction,'decorate':house_decorate,'floor':house_floor,'floor_type':floor_type,'floor_num':floor_num,'structure':house_structure,'age':house_age}print(dict) 7. So far, we have crawled the data from page 1. Let us crawl more data from the subsequent pages (for example, from page 1 to 101).
for page in range(1,102): print(f'=====collecting data from the page {page}======') #notice to modify the url format! url=f'https://sz.lianjia.com/ershoufang/pg{page}/' ...... #The following procedures must be indented!
8. Save data in CSV format
import csvf=open('second_hand_house.csv',mode='w',encoding='utf-8',newline='')csv_writer=csv.DictWriter(f,fieldnames=[ 'title' 'name', 'street', 'totalprice', 'unitprice', 'type', 'square', 'direction', 'decorate', 'floor', 'floor_type', 'floor_num', 'structure', 'age'
])csv_writer.writeheader()#All the programs above should be entered here!csv_writer.writerow(dict)