?个人主页:我们的五年
?系列专栏:Linux课程学习
?追光的人,终会万丈光芒
?欢迎大家点赞?评论?收藏⭐文章


Linux学习笔记:
https://blog.csdn.net/djdjiejsn/category_12669243.html
前言:
在本篇文章中,站在操作系统的角度看待文件,对于文件,操作系统会进行怎么样的处理。重定向,缓冲区(语言级,内核级)。
目录
本篇重点知识点:
一.理解一切皆文件
1.1先描述,再组织
1.1.1那么管理外设,是怎么管理的呢?------先描述,再组织
1.1.2描述的结构体中,有对应的操作方法
1.2在进程角度,一切皆文件
二.文本写入和二进制文件
2.1为什么要有printf这样的函数?
2.2伟大的C语言
三.内核级缓冲区
3.1他们是如何提高效率的呢?
3.2如何看待内核级缓冲区?
3.3如何让内核级缓冲区进行刷新?
3.4如何读取,修改文件?
3.5内存块
本篇重点知识点:
1.语言级的缓冲区设计的目的是减少系统调用,以提高效率。内核级的缓冲区是为了减少与外设的交流,提高效率。这两个设计都是为了提高效率。
2.理解外部设备对于进程而言也是文件。struct file中会有操作符表(函数指针的集合),它可以屏蔽不同设备直接的操作方法。也相当于文件。理解刷新,写入缓冲区本质是拷贝。
3.
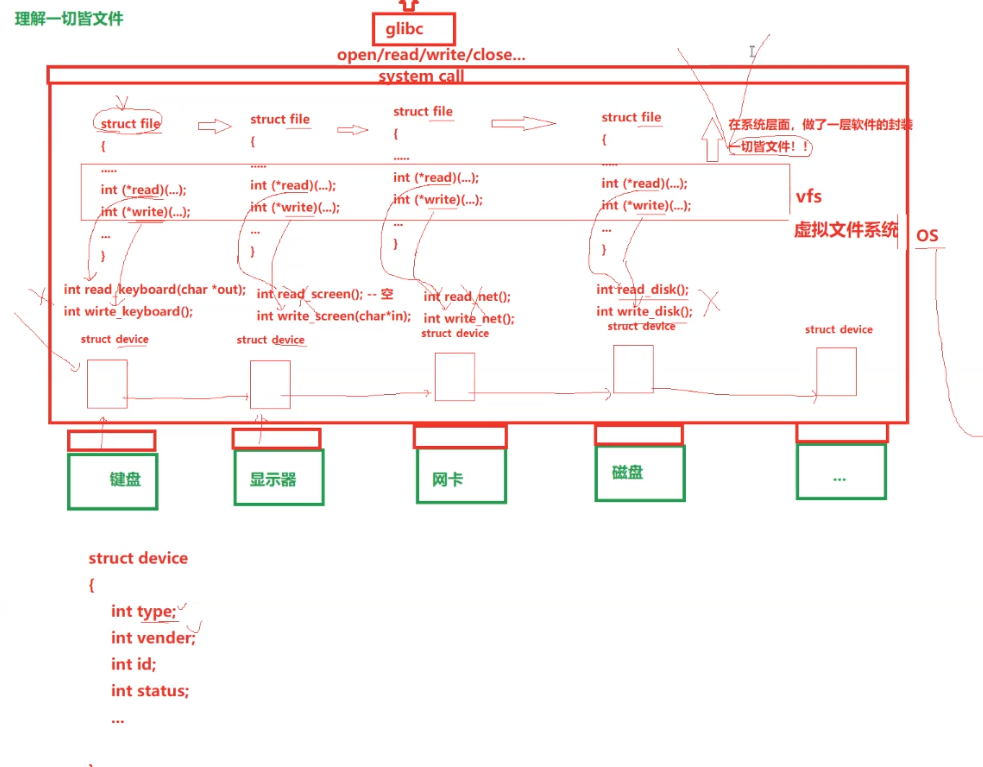
一.理解一切皆文件
其他的文件对于进程而言是文件,这个点很好理解。但是外部设备,比如键盘,显示器,网卡……,这些外设对于进程而言也是文件,这该如何理解呢?
1.1先描述,再组织
操作系统OS对下要管理外设,对上要提供对应的接口,让用户进行操作。在系统调用这个层面,又给我封装了语言层的函数。fopen,fclose……
1.1.1那么管理外设,是怎么管理的呢?------先描述,再组织
对外部设备的描述,会定义一个结构体,里面包含这外设的类型,工作状态,id值,还有其他很多的属性。-----这样对设备进行了描述。
每一个设备都会有结构体描述起来,他们的大方向是差不多的,有很多对应的属性,比如名称。只是他们的值不一样。每个设备会串在一个链表中,那么到后面,我们对设备的管理,就到了对链表的增删查改。
每一个外设,都有自己的驱动程序,是提供设备的厂商给我们提供的。
1.1.2描述的结构体中,有对应的操作方法
Linux系统是C语言写的,C语言结构体中,不能封装方向,那么它是怎么控制对应的设备进行运作的呢?C语言中可以封装函数指针。
比如键盘有写入的函数,输出的函数。显示器也有输入的函数,也有输出的函数。但是对应键盘来说,输入函数是没有意义的,所以就设置为空。对于显示器来说,输入函数是无效的,所以也设置为空。所以这样就能保证能共用一套结构体结构。后面操作系统要进行对应的操作,也可以统一。

1.2在进程角度,一切皆文件
VFS(virtual File System Switch):虚拟文件系统。
对于普通的文件,有对应的文件描述:struct file。里面包含文件的属性和方法。但是从上面来看,底层在进行处理以后,也是有struct file,里面包含这属性和方法,让不同的设备一同样的方式描述起来,这就和文件一样了。所以外部设备也可以理解为文件了。
我们的所以行为,全部都会被转换为进程。当进程找到对应的文件,就可以有对应的方法,该可以调用函数进行执行了。
多个设备提供的方法就是多态。
二.文本写入和二进制文件
显示器是字符设备,我们输出1234(一千两百三十四),其实是在显式器上输出了‘1’字符,‘2’字符,‘3’字符,‘4’字符。
2.1为什么要有printf这样的函数?
对于write系统调用而言,它要输出的字符串是void*类型的,它没有所谓的文本和二进制。那为什么我们还要去printf指明所对应的类型呢,比如要打印整数,我们在printf中写%d,打印浮点数%f。就能直接打印,不然直接用write时,我们先要把整数转化为字符串,才能打印。
所以printf是方便了我们用户的。
在底层是不区分文件文件和二进制文件的。字符其实有对应的ACSII码,是一个一个的二进制数字表示的字符。所以只有二进制文件。
2.2伟大的C语言
不同系统的系统调用会不一样,但是我们在写代码的时候,在不同的平台基本没有变化。不同的操作系统的底层接口是不一样的,C语言帮我们封装以后,让我们不要去担心底层,C语言在不同操作系统会有不同的处理。
提高代码的可移植性。
C语言的库:
一款语言,会实现不同操作系统的兼容,不同的操作系统的底层实现是不一样的。所以就有了语言的可移植性。这也是为了增加用户群体。
三.内核级缓冲区
在操作系统有内核级缓冲区,在语言级有语言级的缓冲区。他们两个是不同的,但是他们两个的实现的目的就是为了提高效率。
3.1他们是如何提高效率的呢?
如果每个我们每次输出都进行一次output,就会有很大的成本,他们一般设置的是行刷新,或者是当缓冲区满的时候,再刷新(fflush)。
对于显示器这样的特殊设备,一般用的是行刷新,即遇到换行就会刷新。对于其他的文件,那么可能就是当缓冲区满的时候,才会进行刷新。
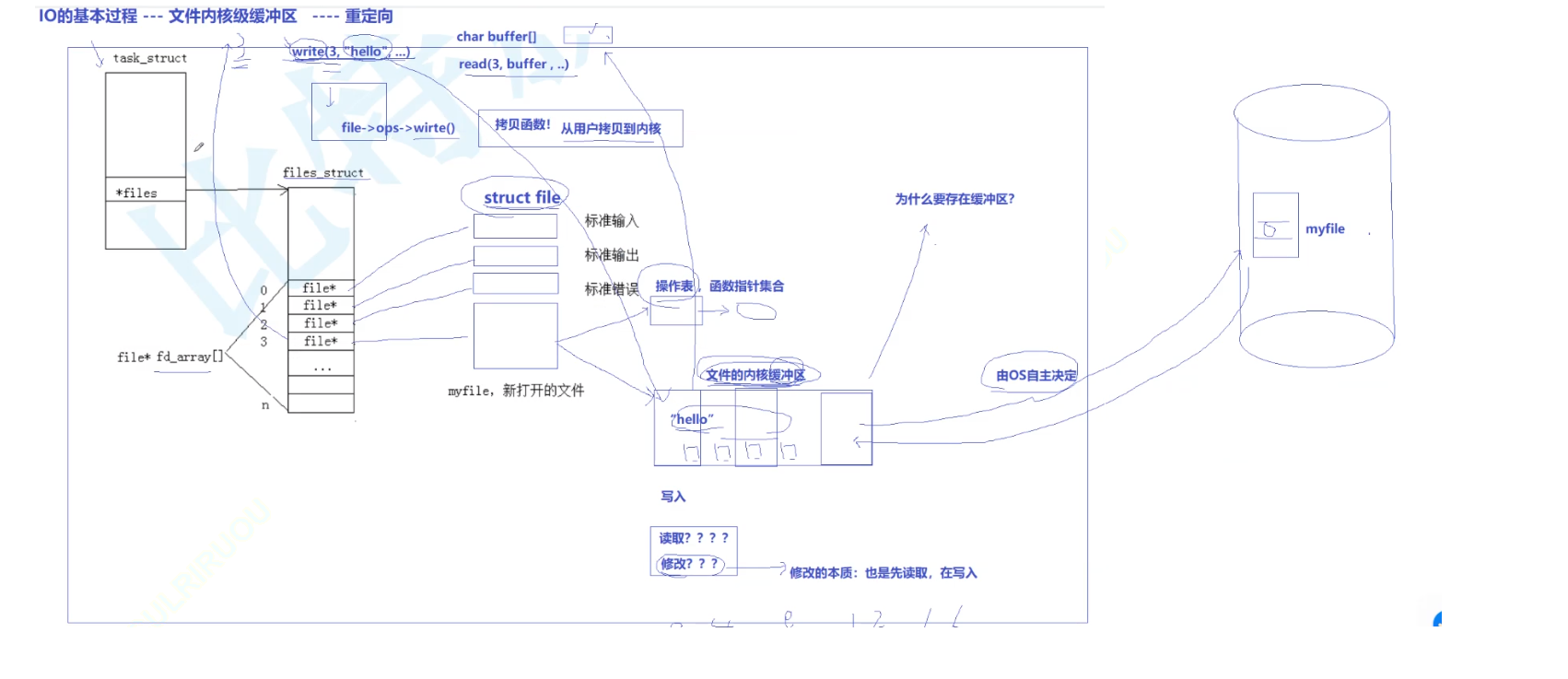
3.2如何看待内核级缓冲区?
当我们调用write接口对于文件进行写入时,不是直接写到文件,而是写到文件的缓冲区。具体多久写到文件中,由操作系统决定。所以不是每使用一次write,就会进行一次IO。而是有几次,当缓冲区中的内容到达一定的数量时,才进行刷新。
语言级的缓存区差不多也是这样的设计。当我们使用printf时,不会直接把我们输出的内容直接输出到内核级缓冲区。而是把要输出的内容拷贝到FILE结构体的buf数组中。在满足一定条件的时候,才会把buf数组中的调用系统调用接口,把FILE结构体中的内容拷贝到内核级缓冲区。
内核级缓冲区多久进行IO,由操作系统决定。
3.3如何让内核级缓冲区进行刷新?
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
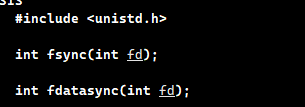
fd是文件描述符。要进行写入,这个文件肯定被打开,被打开,就肯定在文件描述符表中,fd就表示的是文件描述符表的下标。
3.4如何读取,修改文件?
上面所说的是写入,读取就是相反的过程。而修改就包含了读入和修改。
读取就包含了打开文件(如何找到文件,磁盘中的文件时如何,是文件系统的内容,在后面的文件,会进行讲解),把文件的内容加载到缓冲中,然后上层从缓冲中读取,这就形成了读取。
而修改就是先读取,然后把指定的内容进行修改以后,再进行写入就可以了。
3.5内存块
缓冲区是有内存块组成的,内存块一般是4KB。