找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏: Python
目录
函数的定义及调用
函数的概念
函数的定义
函数的调用
水仙花数等自幂数的练习
函数相关参数的概念
函数的返回值
变量的作用域
匿名函数:lambda
函数递归
常用的内置函数
数据类型转换函数
数学函数
迭代器操作函数
其他函数
课后练习(实战四)
函数的定义及调用
函数的概念
函数是将一段实现功能的完整代码,使用函数名称进行封装,通过函数名称进行调用。以此达到一次编写,多次调用的目的。
函数分为两种:一种是Python的开发人员将带有某些特殊功能的代码封装成函数,这也叫内置函数;另一种是咱们在写代码的时候,自己定义的函数来实现某种功能,这也叫自定义函数。
常见的内置函数:Input、print、eval、math...
函数的定义
语法:
def 函数名(参数列表): # 函数名要符合定义标识符的规范 // 函数体 ... // 函数的功能 [return 返回值列表] // []内的内容可有可无代码演示:
# 对1-100进行求和def get_sum(): sum = 0 for i in range(1, 101): sum += i i += 1 return sumdef get_sum2(): sum = 0 i = 1 while i <= 100: sum += i i += 1 return sum注意:我们自定义的函数并不是直接就可以运行的,要在定义函数的外面去调用它才行。
函数的调用
函数的调用就只需要在 定义函数的外面,去写上该函数的函数名+参数列表即可。
语法:
# 当函数没有参数时,我们也不需要去传参函数名([参数1, 参数2, ...])代码演示:
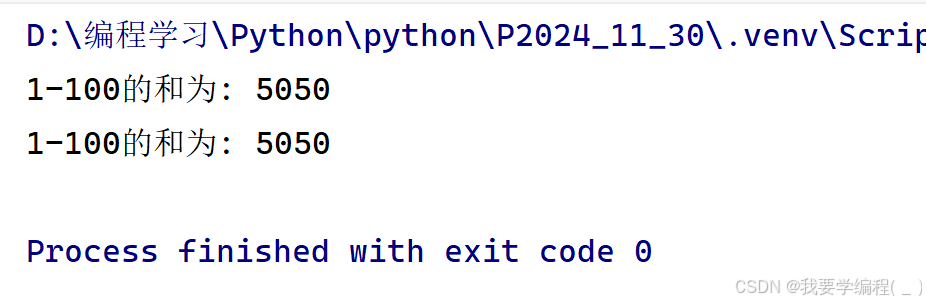
print(f'1-100的和为: {get_sum()}')print('1-100的和为: {0}'.format(get_sum2()))运行结果:
水仙花数等自幂数的练习
有了上述知识,我们可以来写一个稍微复杂一点的函数:
要求:求出所有的水仙花数。
水仙花数:是指一个 3 位数,它的每个数位上的数字的 3次幂之和等于它本身。例如:1^3 + 5^3+ 3^3 = 153。
代码实现:
# 定义一个函数计算水仙花数def get_water_flower(): lst = [] for i in range(100, 1000): # 三位数 # 拿出每一位:注意使用整数除法:// a = i % 10 # 个位 b = i // 10 % 10 # 十位 c = i // 100 # 百位 if a**3 + b**3 + c**3 == i: lst.append(i) return lstprint(f'水仙花数为: {get_water_flower()}')当然如果想要拓展的话,可以在原函数的基础上进行传参,从而求出更多的自幂数。
代码实现:
def get_water_flower2(num): lst = [] # 计算出num的位数 count = 0 while num > 0: count += 1 num //= 10 # 根据位数计算出1-对应位数的自幂数 for i in range(10 ** count): # 1-10^count # 拿出每一位:注意使用整数除法:// # 这里不是三位就不能直接使用 // % 的方式了 # 并且上述方式也比较low,可以换一种写法 # 先求出i的位数 j = i size = 0 while j > 0: size += 1 j //= 10 # 循环 size 次进行对应位数的求和 sum = 0 countOfValue = size j = i while countOfValue > 0: sum += (j % 10) ** size countOfValue -= 1 j //= 10 # 判断是否为自幂数 if sum == i: lst.append(i) return lsttry: num = int(input('请输入待求的自幂数范围:')) if num < 0: raise Exception('请输入合法的整数,再重试!') print(f'{num}范围内的自幂数为: {get_water_flower2(num)}')except ValueError as e: print('请输入整数,再重试!')except Exception as e: print(e)运行结果:

函数相关参数的概念
注意:在Python中,有下面这几个关于参数的概念:
1、形式参数:定义函数时参数列表中的参数,简称:形参;
2、实际参数:在调用函数时,所传输的真实参数,简称:实参;
3、位置参数:调用函数时的参数个数与顺序必须与定义的参数个数和顺序一致;
例如:
def send(form, to, string): print(f'{form}给{to}发送了一条消息: {string}')def happy_birthday(name, age): print('祝'+name+'生日快乐') print(str(age)+'岁生日快乐')# 调用函数# 下面的 true、false 是指结果对不对,而不是输出结果send("I", "You", "I love you") # truesend("You", "I", "I love you") # truehappy_birthday("张三", 18) # true# happy_birthday(18, "张三") # false最后一行代码之所以报错,就是位置参数在作怪,我们传入的参数默认是对应传输的,即按照 name,age 的顺序,如果我们打乱了,就可能会导致代码报错,但是如果参数全部是 字符串类型的话,就不会报错,但是代码的逻辑会出错。 如果我们执意不按顺序传呢?要用到关键字参数。
4、关键字参数:是在函数调用时,使用 "形参名称=值" 的方式进行传参,传递参数顺序可以与定义时参数的顺序不同。因为这相当于是直接对形参赋予相应的值了。还要注意的是,当位置传参与关键字传参一起使用时,得遵循 "位置参数在前,关键字参数在后" 的原则。并且 使用关键字传参时,一定是赋值给形参,因此得写形参的名称,不能写别的。
5、默认值参数:是在函数定义时,直接对形式参数进行赋值,在调用时如果该参数不传值,将使用默认值,如果该参数传值,则使用传递的值。
代码演示:
def happy_birthday(name='张三', age=18): print('祝'+name+'生日快乐') print(str(age)+'岁生日快乐')# 不传参数,使用默认值,给name与age赋值happy_birthday() # true# 传一个参数:使用位置参数# 当只传入一个参数时,默认是将该参数赋值给最前面的形参happy_birthday("李四") # true# happy_birthday(20) # false# 传一个参数:使用关键字传参# 由于关键字参数指定了固定的形参,因此不存在顺序问题了happy_birthday(name='李四') # truehappy_birthday(age=20) # true# 传两个参数:使用位置参数# 不能颠倒顺序# happy_birthday(20, "李四") # false# 传两个参数:使用关键字参数# 同样指定了固定的形参,便不再要求顺序了happy_birthday(age=20, name='李四') # truehappy_birthday(name='李四', age=20) # true既然传参时,有这些顾虑,那在定义函数时,是否也有这些顾虑呢?答案是有的。
代码演示:
# 普通参数def fun1(a, b): pass# 默认值参数与普通参数混用def fun2(a=18, b): # Error,这里会有错误 passdef fun3(a, b=18): pass# 默认值参数def fun4(a=18, b=20): pass从上面的代码来看,我们可以得出一个结论:当普通形参与带有默认值的形参,一起使用时,默认值形参要放到后面,得让普通形参往前放。因为在赋值时,是按照从前到后的方式赋值的,如果前面已经有默认值的话,再赋值可能并不是我们想要的结果,我们可能只是想给普通形参赋值。
6、可变参数:又分为个数可变的位置参数和个数可变的关键字参数两种,其中个数可变的位置参数是在参数前加一颗星(*para),para形式参数的名称,函数调用时可接收任意个数的实际参数,并放到一个元组中。个数可变的关键字参数是在参数前加两颗星(**para),在函数调用时可接收任意多个“参数=值”形式的参数,并放到一个字典中。
位置参数:代码演示:
def fun(*args): # args是一个元组 print(type(args)) for i in args: print(i,end='\t')fun(1,2,3,4,5)fun('张三')fun(['张三', 18, 180]) # 这是传了一个列表,作为一个位置参数# 若想要序列将其中的元素作为参数传递,需要用到解包操作:*fun(*['张三', 18, 180])运行结果:
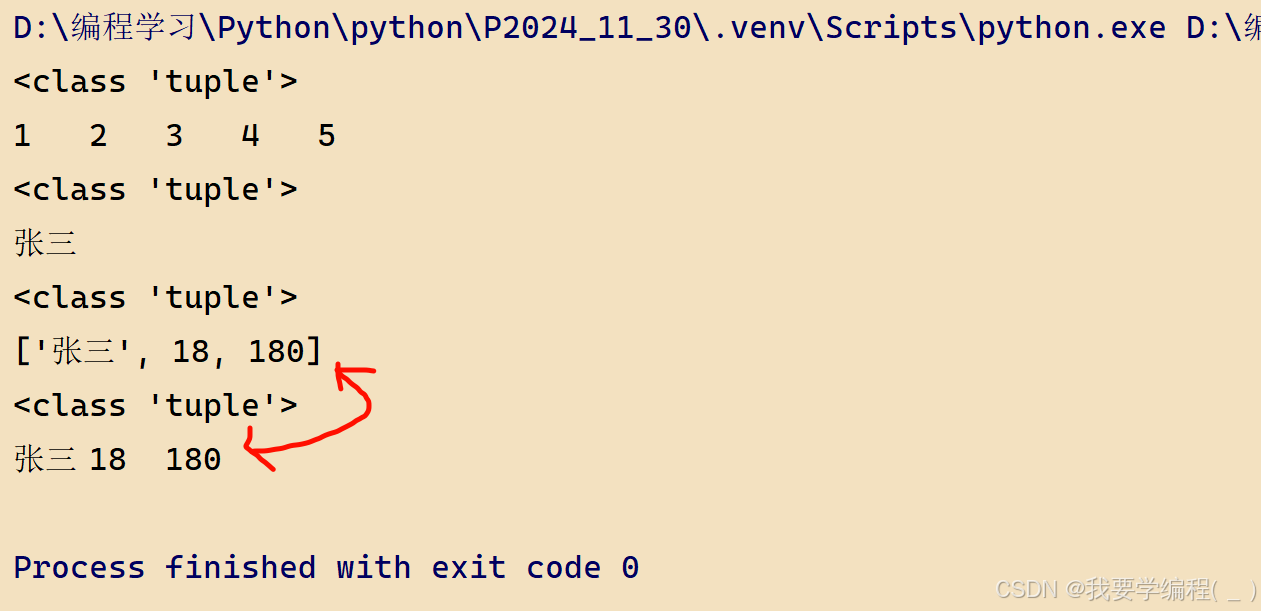
关键字参数:代码演示:
def fun(**kwargs): # kwargs是一个字典 print(type(kwargs)) for key, value in kwargs.items(): print(key, value, end='\t') print()fun(name='张三', age='18')fun(name='李四')d = {'张三':18, '李四':20, '王五':25}# 一定要是关键字参数# 下面这种写法,key为kwargs, value为dfun(kwargs=d)# 还可以解包操作:**fun(**d) # 这就是把字典中的元素传了过去运行结果:
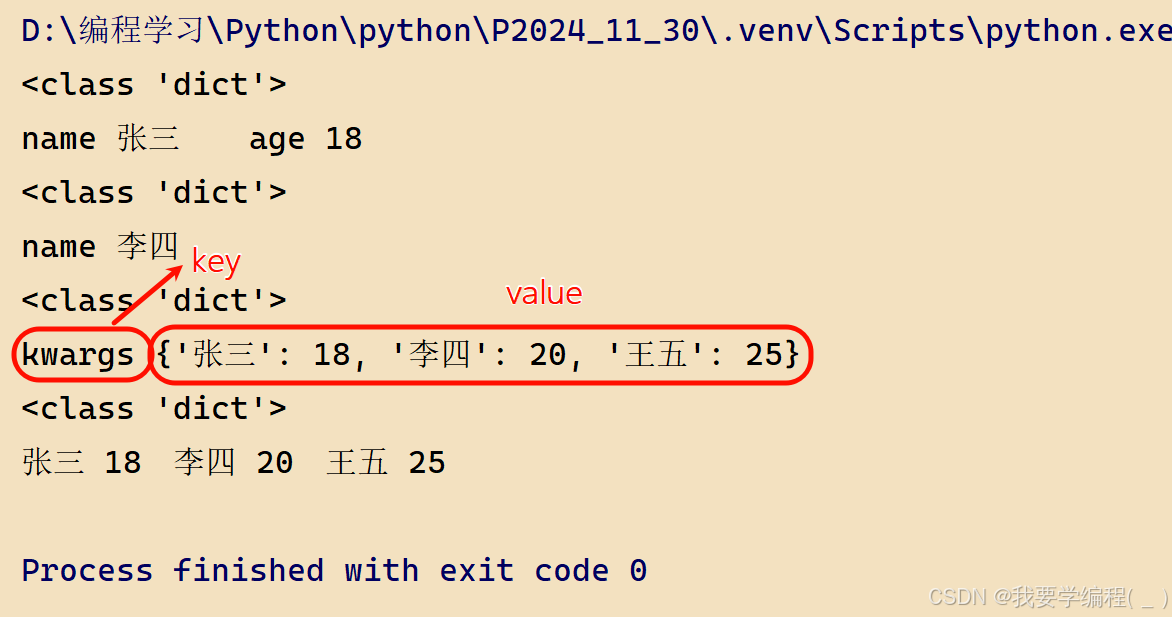
注意:只有和字典一样的表示形式,才可以使用可变参数中的关键字参数

函数的返回值

前面我们已经简单的学习了函数的定义,并且也为部分函数写了返回值,但是前面的返回值都是单个的返回值,现在我们来学习多变量返回值的实现。
代码演示:
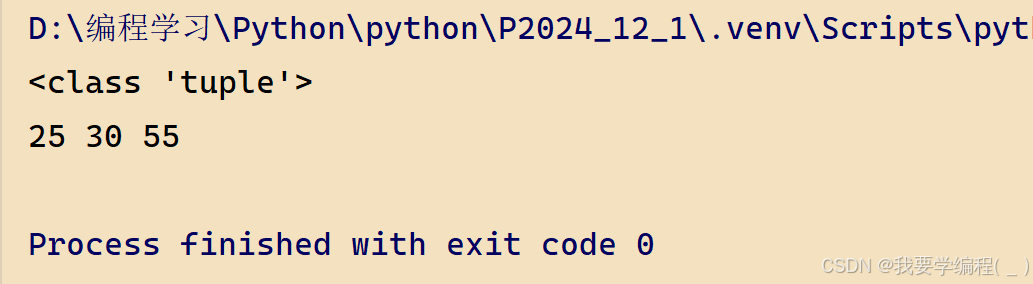
def get_sum(num): # 计算奇数和、偶数和、总和 sum = 0 odd_sum = 0 even_sum = 0 for i in range(1, num+1): if i % 2 == 0: # 偶数 even_sum += i else: # 奇数 odd_sum += i # 总和 sum += i return odd_sum, even_sum, sumresult = get_sum(10)print(type(result)) # 元组类型# 使用多变量赋值操作(解包)a,b,c = resultprint(a,b,c)运行结果:
变量的作用域
变量的作用域是指变量其作用的范围,根据范围作用的大小可分为局部变量 与 全局变量。
局部变量:在函数定义处的参数与函数内部定义的变量。作用的范围:仅仅在函数内部,函数执行结束,局部变量的生命周期也随之结束。
全局变量:在函数外部定义的变量或者函数内部使用 global 关键字修饰的变量。作用的范围:整个程序,当程序运行结束,全局变量的生命周期才结束。
生命周期:是指某个变量存活的范围内。例如,在函数内部定义的局部变量,其生命周期就是在该函数内部。
代码演示:
# 局部变量:函数的参数、函数内定义的变量def fun(a): b = 10 a = b# print(a) # error# print(b) # error# 全局变量:函数外定义+函数内定义时,使用global关键字声明def fun2(a): # 参数不能使用global声明 global b # 不能在声明时,去赋值 b = 100c = 200fun2(1) # 在打印b的值之前得调用fun函数去初始化b的值才行print(b) # 不能在别的函数中出现同名的变量print(c)当全局变量与局部变量同名时,遵循局部变量优先的原则,即 地头蛇原则:当两个变量同名时,且被调用时,看谁定义的近,谁就其作用。
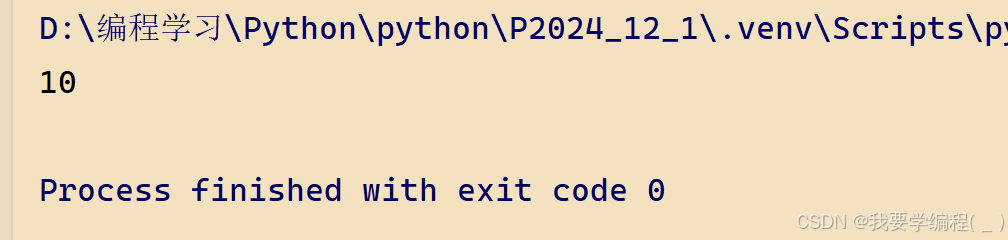
代码演示:
# 全局变量与局部变量同名,遵循局部变量优先def fun(): a = 10 print(a) a = 100fun()运行结果:
注意:全局变量在函数内部直接访问是没问题,但是如果想要在函数内部实现修改的话,就需要在修改其的地方加上 global 关键字。如下所示:

修改后的代码:
i = 0def fun1(): print(i) # 普通访问操作def fun2(): # 声明这是一个全局变量(如果确实存在,就拿到所有权限;反之,则创建一个全局变量) global i i += 1 # 修改操作 print(i)fun1()fun2()这里的 global 相当于 是让 全局变量,对这个函数开放其所有权限。
匿名函数:lambda
匿名函数,是指没有名字的函数,这种函数只能使用一次,一般是在函数的函数体只有一行代码且只有一个返回值时,可以使用匿名函数来简化。
语法:
# lambda 是一个关键字,表明后面是一个匿名函数# result 是一个函数# 将匿名函数赋值给了result,可以把result当成一个函数去调用result = lambda 参数:函数体(执行的操作)代码演示:
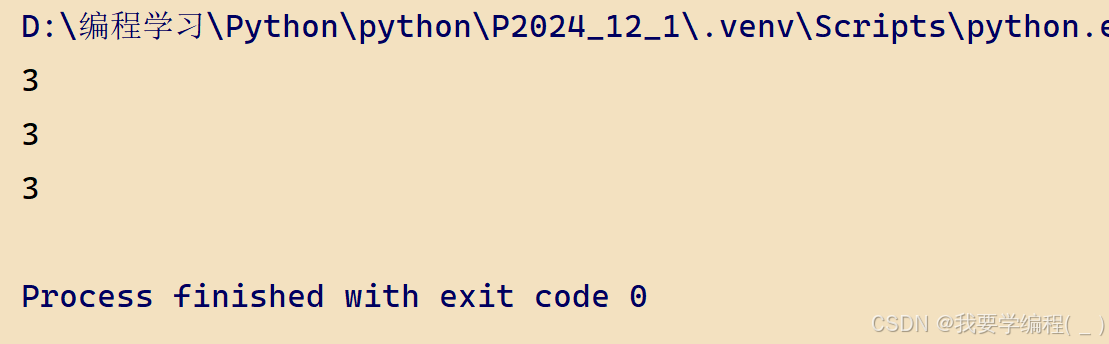
# 使用普通的函数:def fun(a, b): return a+bprint(fun(1,2))# 使用匿名函数:lambda# a,b 是参数,a+b是函数体result = lambda a,b:a+b# result是一个函数,可以去调用它print(result(1,2))# 因为这里是将这个匿名函数赋值给了result# result可以反复使用,但是匿名函数却只能使用一次print(result(1,2))运行结果:
代码演示:
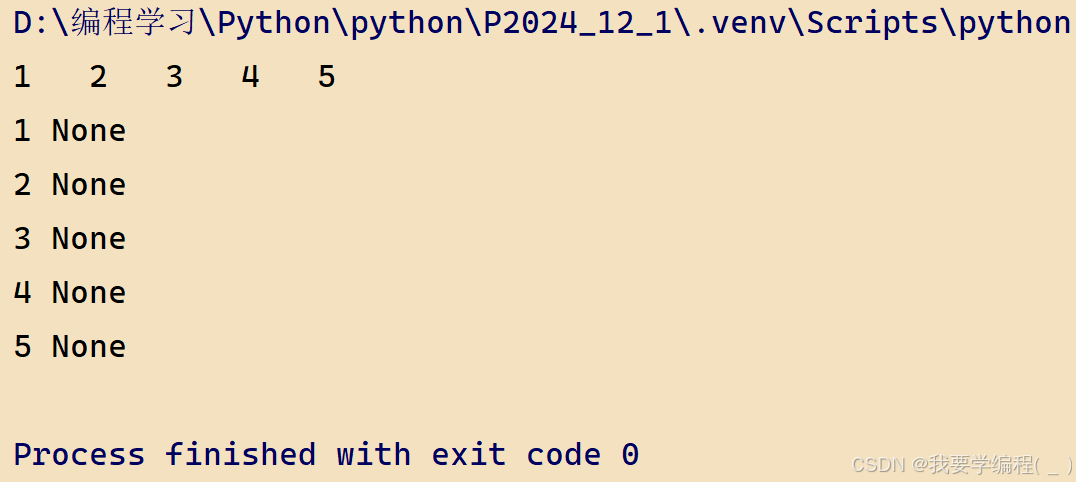
lst = [1,2,3,4,5]for i in range(len(lst)): print(lst[i],end='\t')print()# 使用匿名函数for i in range(len(lst)): # 参数是lst,函数体是print(lst[i]) result = lambda lst: print(lst[i],end=' ') print(result(lst))运行结果:
注意:使用匿名函数时,lambda 会根据 函数体的具体实现来决定是否存在返回值。像,x+1这种函数体,这就是返回了 x+1,但是像,print(x),这种函数体,就没有返回值(或者说为None)。
函数递归
函数递归是指,在调用函数体的过程中,出现了自己调用自己的情况。例如,下面这种情况:
i = 1def fun(): global i # 声明这是一个全局变量(与上面的i相呼应) print('这是第{0}次调用fun()函数'.format(i)) i += 1 fun() # 自己调用自己(外部fun调用内部fun)fun()如果我们去尝试运行上面的代码的话,就会出现下面这种情况:
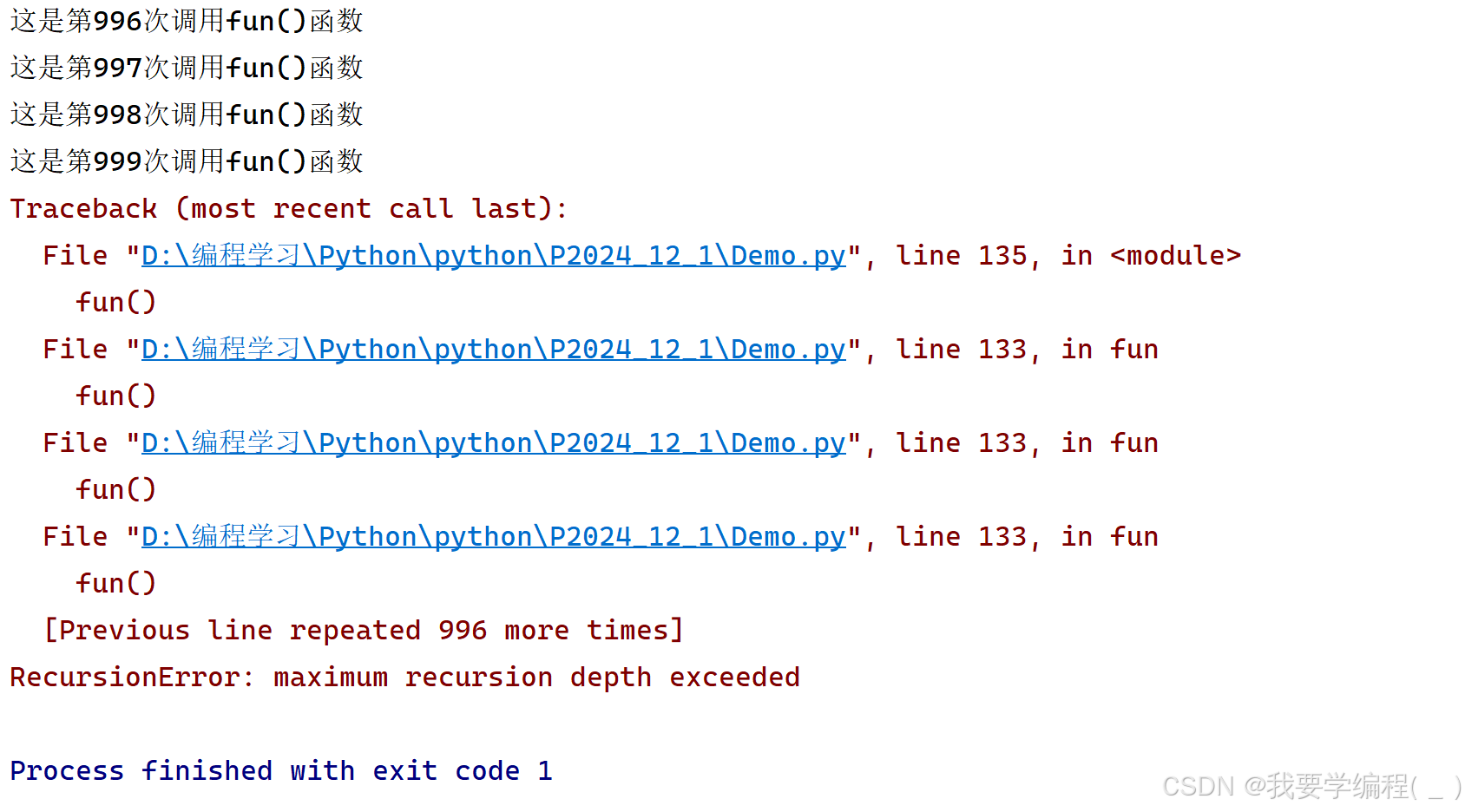
如果有学过别的编程语言的小伙伴,应该对这个不陌生。这是 "栈溢出",因为函数每一次调用都需要创建与之对应的栈帧,用于存储当前函数的执行情况(变量的值,执行到哪里了等) ,这份空间是有限的,与内存一样,不可能无限使用。因此当函数调用过多时,就会发生栈溢出的情况。而内存不足,则是会使当前程序启动失败。(这些了解即可)
那怎么解决上述问题呢?只需要写出一个正确的递归函数,即需要一个递归的截止条件与递推公式。当函数递归到某个临界点时,不需要再递归了,而是可以直接回退了,这就是递归的截止条件;递推公式,则是需要我们自己去推测出来,后面有例子解释。
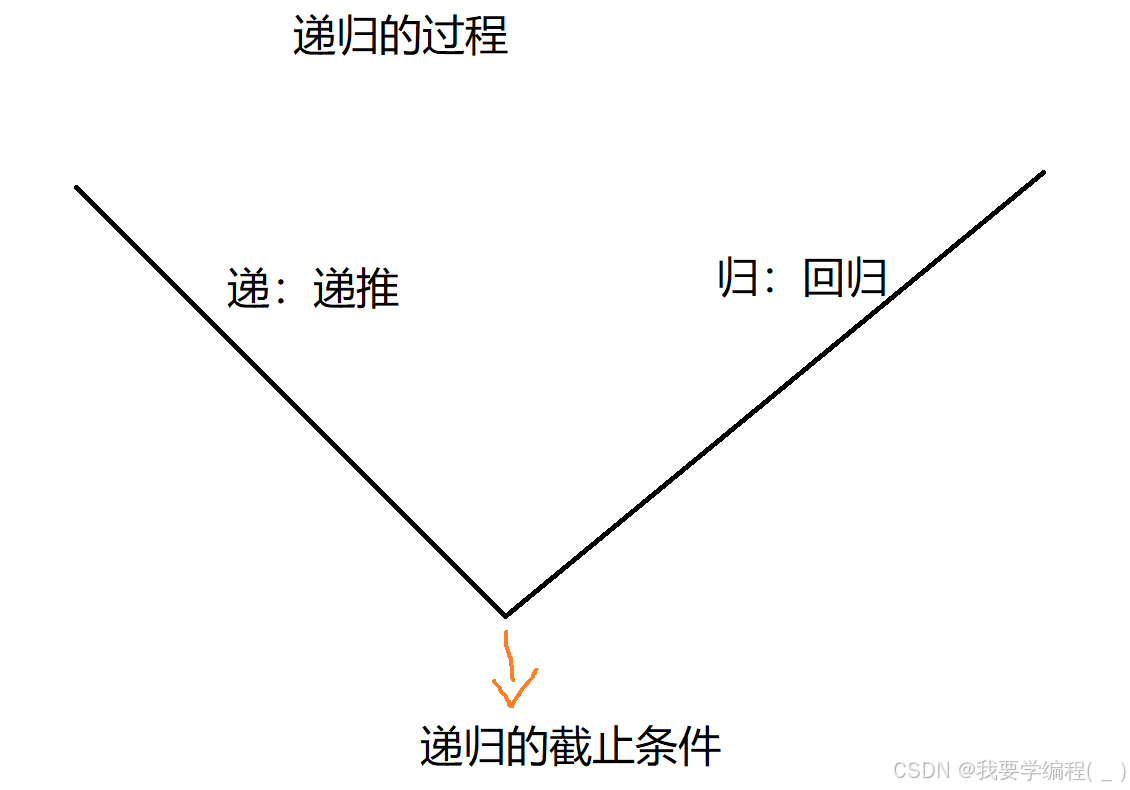
递归的两个经典案例:1、阶乘;2、斐波那契数列。
我们先来看阶乘的计算:5! = 5 * 4!,4! = 4 * 3! ... 1! = 1,这里的 1! = 1就是函数递归的截止条件,因为到这里已经无需计算了,而 5! = 5 * 4! 就是函数的递推公式,即 n! = n * (n-1)!。
代码实现:
# 阶乘的计算def fac(n): # 当 n == 1时,已经知道了其阶乘的值了,可以不用继续计算了 # 因此直接返回其值即可,而其余情况,则是 n! = n * (n-1)! if n == 1: return 1 return n*fac(n-1)print(fac(5))我们可以推演一下上述的递归过程。

上图就是计算5的阶乘的全部过程了,大家也可以自己画图来理解递归的过程。
接着来学习 斐波那契数列,相信这个大家都不陌生,我们在数学中是学过这个的。是以兔子繁殖为例子而引入,故又称为“兔子数列",指的是这样—个数列:1、1、2、3、5、8、13、21、34、……从第三项开始,每项都等于前两项之和,这里其实就已经给出了我们斐波那契数列的递推公式了:n <= 2,fib(n) = 1;n >= 3,fib(n) = fib(n-1) + fib(n-2)。
注意:可能有小伙伴见过是0、1、1、2、3、5 .... 这样的说法,这两者都算正确的,但是我们这里讨论的是 1、1 开头的。
代码实现:
# 斐波那契数列def fib(n): # 当 n==1 或者 n==2时,我们已经知道了值为1 # 因此直接返回即可,但 n是其他值时,我们需要递归计算 if n == 1 or n == 2: return 1 return fib(n-1) + fib(n-2)print(fib(10))这里的递推过程就不演示了,感兴趣的小伙伴可以自己去画图推演。
可能有小伙伴,对递归是在是学不明白,没关系,递归最终是为了计算出结果,而能用递归计算出来的结果,都是可以使用循环计算出来的。下面我们来对阶乘与斐波那契数列进行改版。
代码实现:
# 阶乘def fac(n): sum = 1 # 这里初始化的结果一定不能是0 for i in range(1, n+1): sum *= i return sumprint(fac(5))# 斐波那契数列# 因为当计算的斐波那契数超出2时,需要用到前面的斐波那契数# 因此将全部的数都存储起来,易于计算# 这也就是优化计算斐波那契数列的方法def fib(n): lst = [1,1] if n == 1 or n == 2: if n == 1: return lst[0] else: return lst # 循环计算 for i in range(2, n): # 这里的i是列表的索引,因此第三项的索引是2 # fib(i) = fib(i-1)+fib(i-2) sum = (lst[i-1]+lst[i-2]) lst.append(sum) return lstprint(fib(10))运行结果:

常用的内置函数
Python中常用的内置函数,根据功能分类有四种:数据类型转换函数、数学函数、迭代器操作函数、其他函数。
数据类型转换函数
| 函数名 | 描述 |
| bool(obj) | 获取指定对象obj的布尔值 |
| str(obj) | 将指定对象obj转为字符串类型 |
| int(x) | 将 x 转为 int 类型 |
| float(x) | 将 x 转为 float 类型 |
| list(seqence) | 将序列转成列表类型 |
| tuple(sequence) | 将序列转成元组类型 |
| set(sequence) | 将序列转成集合类型 |
上述的函数,我们在前面学习的时候,基本上都是用过的,这里就不再演示了。
注意:当字符串的字面值为浮点数时,不能转为 int 类型。int() 在针对 字符串 时,可以理解为只将字符串的引号去掉了,其余的就不管了,因此当字面值为浮点数时,就会转换失败。
数学函数
| 函数 | 说明 |
| abs(x) | 获取 x 的绝对值 |
| divmod() | 获取 x 与 y 的商和余数 |
| max(sequence) | 获取 sequence 的最大值 |
| min(sequence) | 获取 sequence 的最小值 |
| sum(iter) | 对可迭代对象进行求和运算 |
| pow(x,y) | 获取 x 的 y 次幂 |
| round(x,d) | 对 x 进行保留 d 位小数,结果是四舍五入 |
代码演示:
# 内置数学函数的使用# 1、abs():绝对值print(abs(100), abs(-100), abs(0))# 2、divmod():商、模# 10 // 3 => 3 10 % 3 => 1print(divmod(10, 3))# 3、max():最大值print(max([1,2,3,4,5]))# 对于字符串的比较,就是比较首字母的最大值# 对于在ASCII码值之内的,就是比较ASCII码值# 对于不在ASCII码值的,就是比较Unicode编码print(max(['hello', 'python', 'java', 'c']))# 4、min():最小值print(min([1,2,3,4,5]))print(min(['hello', 'python', 'java', 'c']))# 5、sum():求和print(sum([1,2,3,4,5]))print(sum((1,2,3,4,5)))# 不能对除数字之外的进行sum# print(sum('hello')) # error# 6、pow():x**yprint(pow(2,3))# 7、round():精确数值print(round(3.1415926535, 2))print(round(3.146, 2))# 当第二个参数为不写时,默认为保留整数位:同样四舍五入# 但如果写成0的话,就是在取整的基础上保留一位小数print(round(3.146, 0))print(round(3.6, 0))print(round(3.146))print(round(3.6))# 当第二个参数为负数时,就是整数部分进行取舍操作# -1 是指对个位进行四舍五入,且保留一位小数print(round(314.15, -1))运行结果:

迭代器操作函数
| 函数 | 说明 |
| sorted(iter) | 对可迭代对象进行排序 |
| reversed(sequence) | 反转序列生成新的迭代器对象 |
| zip(iter1,iter2) | 将iter1与iter2打包成元组并返回一个可迭代的zip对象 |
| enumerate(iter) | 根据iter对象创建一个enumerate对象 |
| all(iter) | 判断可迭代对象iter中所有元素的布尔值是否都为True。如果都为True,则返回True;反之,则返回False |
| any(iter) | 判断可迭代对象iter中所有元素的布尔值是否都为False。如果都为False,则返回False;反之,则返回True |
| next(iter) | 获取迭代器的下一个元素 |
| filter(function,iter) | 通过函数function过滤序列并返回一个迭代器对象 |
| map(function,iter) | 通过函数function对可迭代对象iter的操作返回一个迭代器对象 |
代码演示:
lst1 = [10,2,30,4,50]lst2 = [1,20,3,40,5]# sorted()# 是在新的可迭代对象的基础上排序的,不会影响原来的对象new_lst1 = sorted(lst1)print('对lst1进行升序排序:',new_lst1)new_lst2 = sorted(lst2,reverse=True) # 升序完后转置就变成了降序print('对lst2进行升序排序:',new_lst2)# reversed()# 对序列反转,并生成新的迭代器对象new_lst1 = reversed(lst1)# 需要将迭代器对象转换才行print(list(new_lst1))# zip()# 将参数组成元组并返回zip对象# 参数谁的长度短,以谁为基准obj_zip = zip(lst1, lst2)# 同样需要转换print(list(obj_zip))# enumerate()# 根据参数生成一个enumerate对象# 也是一个元组,默认初始值从0开始(可设置)obj_enum = enumerate(lst1)print(list(obj_enum))# all()lst3 = [1,2,'']# 元素的布尔值都为True时,返回True;有False,返回Falseprint(all(lst3))# any()# 元素的布尔值都为False时,返回False;有True,返回Trueprint(any(lst3))# next()# 生成一个迭代器对象obj_iter = iter(lst2)# 在配合while循环遍历while True: try: # 打印迭代器中的值,当迭代器中没有值时,就会报错 print(next(obj_iter), end=' ') except StopIteration: print() break # 没有值了,就停止循环# filter()def fun(n): return n%2 == 1# 对lst2中的元素进行fun处理,满足条件的添加到迭代器中# 即 lst2中所有满足 使fun函数返回True的元素,组成一个迭代器对象# 再将迭代器对象转为列表print(list(filter(fun, lst2)))# map()lst4 = ['hello', 'python', 'java', 'c']def upper(s): return s.upper()# 将lst4中的元素进行upper处理,将处理后的结果放到迭代器对象中# 再将迭代器对象转换为列表print(list(map(upper, lst4)))运行结果:

注意:
1、filter 函数 与 map 函数 的第一个参数都是 函数名,这里只需要写函数名,而不需要在后面加上(),加上() 属于调用函数了,不符合要求。
2、可能有小伙伴对最后map的地方有疑惑。有两个 upper ,map是怎么判断使用哪个呢?其实这里涉及到我们后面将要学习的类与对象的知识。我们自己定义的upper 是属于函数的范畴,但是 s.upper 这是属于方法的范畴,虽然两者干的事差不多,但是两者的含义不同。
方法是依附于类而存在的,我们使用方法要么是通过类是调用,要么是通过类的实例去调用。而函数就不一样了,其不依赖于谁,直接使用即可,只需要传参。
upper(s) —> 这是一个函数,调用只需传参。 s.upper() —> 这是一个方法,调用需要通过实例(这里将s理解为实例)。这里不理解没关系,后面我们会学到的。
其他函数
其他函数是指这些函数不属于上述分类中的函数。常用的有下面这几种:
| 函数 | 说明 |
| format(value,format_spec) | 将value以format_spec格式进行显示 |
| len(s) | 获取s的长度或者s元素的个数 |
| id(obj) | 获取对象的内存地址 |
| type(x) | 获取x的数据类型 |
| eval(s) | 取出s字符串所对应的字面值 |
上面的函数除了 format 与 id 之外,其余的都在前面的学习过程中,接触并且使用过,因此这里就不再赘述了。 这里的format函数是对 字符串的format方法的一个补充扩展,为了更好的格式化数据,前面在学习字符串时,format方法只能针对字符串其效果,而这里的format函数是可以对任意数据其作用的。下面这是简单演示一下,具体请看字符串章节。
代码演示:
# format():可以和格式化字符串一样,格式化这些数据# 对数值型数据进行格式化时,默认是右对齐# 同样超出格式长度,就不再进行格式了print(format(3.14,'20'))# 对字符串数据进行格式化时,默认是左对齐print(format('hello python', '20'))# id()# 对象在内存中的地址是固定的print(id(10))print(id(10))print(id('python'))print(id('python'))运行结果:

课后练习(实战四)
要求:编写函数实现操作符in的功能。使用input()从键盘获取一个字符串,判断这个字符串在列表中是否存在(函数体不能使用in),返回结果为True或False。
注意:整个函数中不能出现in操作符。
思路:判断字符串是否在列表中存在,肯定是需要去遍历列表的,但是由于不能使用 in 操作符,因此这里就需要用到 while循环。
代码实现:
lst = ['hello', 'python', 'java', 'c']def fun(x): i = 0 while True: try: if lst[i] == x: # 找到了,返回 return '存在' i += 1 except Exception: # 说明找不到 return '不存在's = input('请输入您要判断的字符串:')print(fun(s))好啦! 本期 初始Python篇(9)—— 函数 的学习之旅就到此结束啦!我们下一期再一起学习吧!