目录
- 背景
- 什么是一致性?
- B端业务场景
- 重试
- 幂等
- 并发
- 小结
- 总结
背景
已经好久没写博客了,看了下最近的一篇已经是去年的了,由于工作一直忙,没有抽时间来写(其实就是懒)。加上也没有觉得非常有收获的事情,所以就干脆没写了。
最近在思考分布式一致性的理论与实现时,感觉自己有所收获,这里分享分享一下自己的经验。
什么是一致性?
至于原理什么的,这里就不赘述了,总的来说目前的分布式系统实现起来基本上都是基于BASE理论的,业务需要保持最终的一致性,说白了了是可以允许 中间过程的短暂不一致,只需要最后一致就好。
一说到这个,很多人马上就能想到XA和TCC这两种分布式事务的实现,而且也有很多人针对这两种思想设计出了很好的实现,比如:tcc-lcn:https://github.com/codingapi/tx-lcn 还有很多的实现,去github上一搜就能找到。
但是基于XA需要有强大的事务管理器来协调事务操作,TCC的方式需要第三方协调者,多一个中间件就多一分维护,同时业务难度也就上升很多 。当然如果公司中有非常牛逼的中间件团队这个就基本可以忽略了,基本能保持最少4个9的可靠性(https://blog.csdn.net/varyall/article/details/82592970)。
B端业务场景
通常业务系统B端非常重视一致性,C端则更加重视高可用,在B端数据配置的时候通常都是需要调用好几个系统才能完成一个数据的创建,如商品创建基本都需要
- 创建商品基础数据
- 创建凭证模板
- 创建适用门店库
- 创建xxx关联数据
- 落本地数据
在这里的每一步都可能会失败,比如网络超时,db抖动等等常见的失败原因。每一步失败都意味着整个流程需要重试(更恐怖的是有的业务需要回滚前面的步骤)。回滚基本不在业务考虑范围内,因为本来业务就是要做好创建的工作,而且在校验阶段都是符合创建条件的,那么业务上肯定是希望能够完整的建好业务数据,回滚只是作为非常规运维手段来使用。
可以需要通过以下几个点来实现最终一致性.
重试
就像上面说的,在这种可重试的失败需要系统能够自动重试,重试的方法有很多,可以基于任何有定时任务功能的系统或框架来实行,如
- linux的crontab
- quartz
- schedulerx
- xxl-job
等都符合重试的要求,处理业务的时候本地落一条流水数据,失败后设置可重试状态,等待定时任务来执行。
注意:
- 重试的时候记录好trace,这对排查问题非常有帮助
- 需要考虑好幂等性
- 需要考虑好并发
- 重试次数
幂等
在任务进行重试执行的时候,如何保证重复执行的幂等性呢? 首先:底层接口需要支持幂等,每次重试的时候业务流水id都保持一致,这样通过流水id来实现幂等,防止数据重复创建。
但是如果底层接口不支持幂等呢?(这种肯定有的,反正有各种历史原因) 那么就需要业务自己来保证幂等了,在接口执行的时候落一条流水记录,执行完成后更新流水,在执行前先判断流水是否已经执行成功,如果成功了就幂等返回,不做业务操作。
通过本地落流水只能保证99%以上幂等,如果完全依赖这个做幂等那就想的太简单了,思考下,如果在调用某个接口的时候返回了超时的异常,此时流水状态设置的还是失败状态,等待重试的时候还是会进行重复请求,这样还是会重复创建数据。
所以如果底层不支持流水幂等,而是支持业务幂等的话,如创建的时候有相同的id则会查询一下本地DB,已经有数据就返回指定的错误码,那么业务上还可以根据这个错误码进行幂等处理。
如果底层业务幂等都不支持,那这个就只能在处理的时候先查一次,再决定是否调用这个接口了(还是有风险的)。
并发
做好幂等其实还不够,还需要做好并发处理,比如我的业务在处理的时候如果失败了任务重复调度导致两个任务一起执行了,或者任务执行的时候手动触发了任务执行等,这些问题都是存在的。
要做好并发处理,优先考虑使用分布式锁,在业务处理前先获取锁,获取锁失败则说明已经有任务在执行了,当前任务执行结束,等待之前的任务执行完成。
加个分布式锁就可以了? 那也还是想的太简单了,考虑下这个场景
第一次用户编辑的时候,在执行第三步的时候网络超时失败了,落了重试任务,此时任务还没开始调度,用户又开始编辑数据,此时执行的时候获取到了锁,执行成功了。然后定时任务调度拉起之前重试的任务,继续执行第三步的操作,然后数据就被覆盖了。。。
这时聪明的你已经想到了长锁+可重入锁的方式了:
业务执行的时候先落一条长锁,只有执行成功的时候才会释放锁,同时通过请求id作为可重入的判断条件,业务失败后任务拉起来执行的时候还是相同的流水ID,这时任务是可以正常执行的。此时用户想要编辑数据,则会获取锁失败,用户无法进行编辑,此时给个友好的提示。
这种方式还要注意一个点,分布式锁改为了分布式可重入锁,那么并发问题又来了,如果任务同时执行了都是相同的流水id,都能正常执行。 可以通过如下的方式来避免这个
- 通过限制可重入个数为1
- 在业务内部再加一个锁
小结
考虑好幂等,并发,重试这几个问题后,整个业务系统就可以非常健壮的跑起来了。
那么问题来了,为什么只要重试而不需要做回滚呢?
会进入任务执行的时候,需要基础校验都已经完成了,校验通过后说明数据是允许执行的,既然已经拿到了执行的门票,那么我们的任务就是要保证创建成功,至于回滚等操作只会在底层数据出现问题,无法执行完整的创建流程,需要回滚之前的操作。
实际业务上使用的时候基本不会去写回滚的逻辑的,首先加重了开发的任务,其次回滚这种逻辑更适合作为运维手段来执行,这里可以考虑下原因哦。
总结
总结下来的流程图如下,欢迎给出宝贵的意见和建议!!!
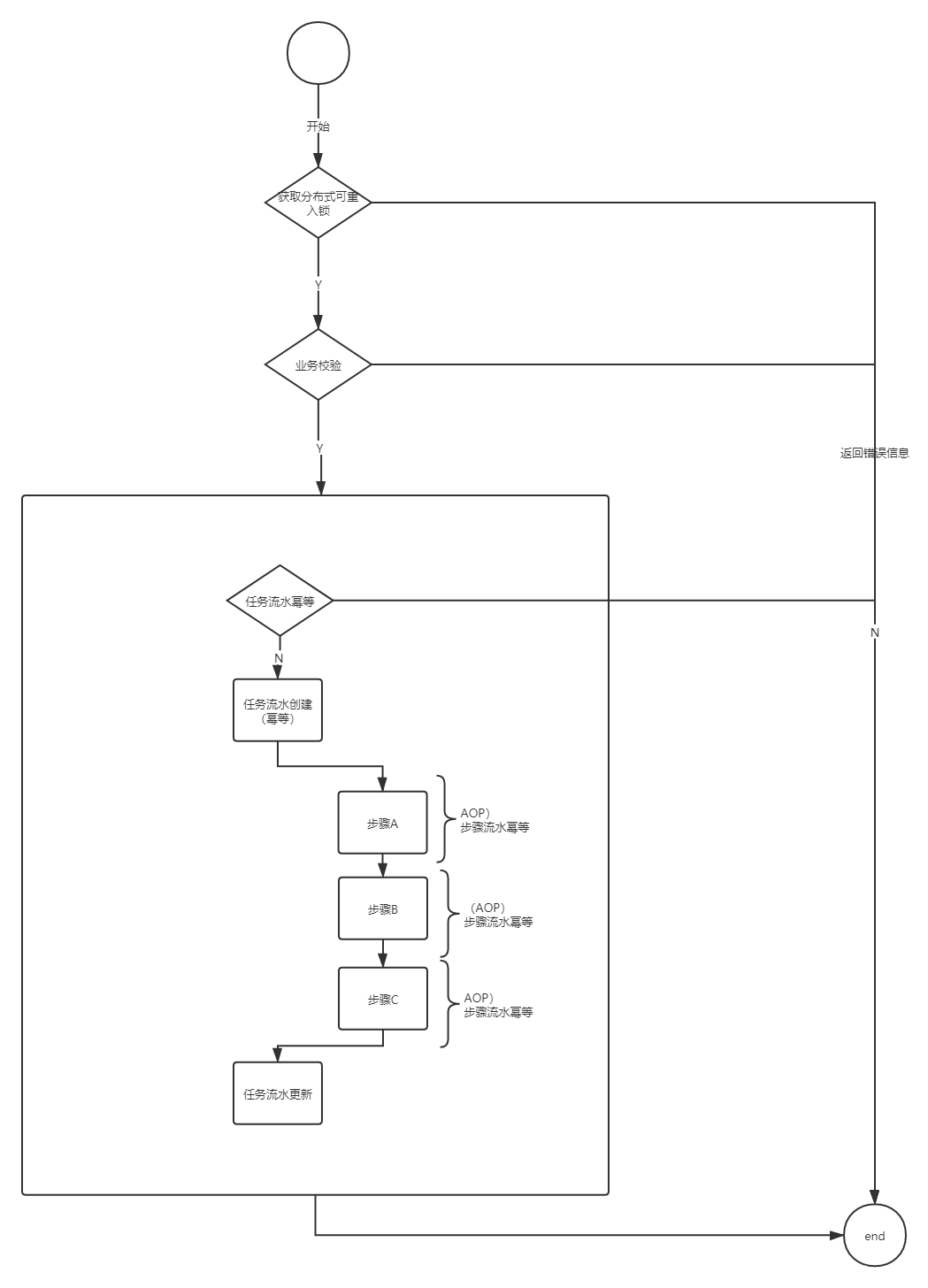
目前接触下来的开发团队,几乎没人使用分布式事务来保证数据的一致性,那么问题来了,
1 你在用么?
2 自建还是直接用开源的?