上周我在博客发布了一篇《龙芯自主指令集到底强在何处》的文章,虽然这只是一篇临时起意之作,信息有限的拙作,不过最近整个半导体行业实在风起云涌,上周四IBM推出了2nm的芯片,苹果春季发布会上这次苹果发布会上搭建M1的IPad Pro再度炸场、四月中旬ARM推出了新一代的ARMv9、英特尔也拿出了最的至强三代Ice Lake-SP,四月初英伟达推出号称能将AI算力提升10倍的CPU芯片Grace,年初AMD的ZEN3系列芯片也正式亮相,接下来笔者就带大家解读一下半导体的巨头们到底打的什么技术牌。
指令集-RISC vs CISC宿命的对决
我们在上一篇聊龙芯的时候,有热心的读者就说希望把CISC的X86指令与龙芯LoongArch进行对比,这次我们就来详细聊一下这方面的话题,目前RISC阵营的最强处理器苹果M1其之所以性能如此劲爆,8路的译码器提供了强大的助力作用。我们根据代码来看一下这方面的情况。
Int a;
Int test(void){
Return a;
}上述代码在X86的处理上,反编译之后得到的汇编语言如下,具体反编译的过程请大家参考《龙芯自主指令集到底强在何处》这里不加赘述了。
test o: file format elf64-x 86-64
Disassembly of section. text:
0000000000000000<test>:
Int a;
int test(void)(
0:55 push %rbp
1:48 89 e5 mov %rsp %rb
return a:
4:8b 05 00 00 00 00 mov 0x0(%rip),%eax #a <test+Oxa>
}
a: c9 leaveq
b: c3 retq对应ARM平台的汇编指令如下:
00000000 <test>:
int a;
int test(void)
{return a;}
0: e52db004 push {fp} ; (str fp, [sp, #-4]!)
4: e28db000 add fp, sp, #0
8: e59f3010 ldr r3, [pc, #16] ; 20 <test+0x20>
c: e5933000 ldr r3, [r3]
10: e1a00003 mov r0, r3
14: e28bd000 add sp, fp, #0
18: e49db004 pop {fp} ; (ldr fp, [sp], #4)
1c: e12fff1e bx lr
20: 00000000 .word 0x00000000
可以看到X86的汇编语言相对比较短,因为CISC一条指令可以完成比较复杂的任务,不过本质上讲这段程序在X86的执行过程就是由push %rbp来构造栈,然后就可以把%eax赋值给结果就完成了。
但是X86这样的做法也有着反噬,我们可以把push move这些指令左边的数字简单为机器指令,可以看到X86为代表的RISC是不定长的,而龙芯LA64和ARM是定长的,对比CISC的来构造直其实对应来现代的CPU一般都是以流水线机制运行。像AMD最新的ZEN3系列CPU,也只配备了4个译码器,因为不定长长所以X86的CPU必须对可能的编码开始位置同时进行译码,并处理很多的错误,我们在前文也介绍过计算机的运行就怕分支预测,一旦预测不准,就会在流水线上产生气泡,这所带来的惩罚效应惊人。
多路译码的关键在于以ARM为代表的RISC指令集基本上是定长的,这也是苹果M1能有8路译码器的原因,当然从结果上看ZEN3还是要比M1略强一点的,但是ZEN3的译码器主频是5Ghz,而M1只有3.2Ghz,个人认为苹果之所以没有将M1的主频调教的很高还是出于控制能耗原因,而不代表他不能这么做。因此从这个角度来看未来在桌面领域X86为代表的CISC恐怕前景不妙。
多方安全计算-软硬结合才是趋势?
之前笔者曾经写过一篇《ARM V9到底强在哪》曾经指出过ARM V9的有一项重要的新特性就是安全计算指令集,但是当时笔者并不太看好这项技术,上周笔者的博客中《为什么谷歌被骂上热搜一点也不冤,详解FloC背后联邦计算》也指出FloC其实是一种联邦计算技术。
说起安全计算这项技术,他的历史已经非常久远了,简单来讲安全计算可以百万富翁问题来表述,假如两个百万富翁街头邂逅,他们都想炫一下富,比比谁更有钱,但是出于隐私,都不想让对方知道自己到底拥有多少财富,如何在不借助第三方的情况下,让他们知道彼此之间到底谁更有钱?针对这个问题,在上世纪80年代,清华大学的姚期智院士提出了解决方案,并因此获取了图灵奖,从理论层面证明了多方可信计算问题的可行性。
其实英特尔安全计算指令集的SGX技术早在几年前就已经实现了,这是一种从硬件角度打消用户疑虑的技术,安全计算指令集实际是给计算机加了一个安全密室,即使拥有最高权限的特权管理员也不能进入安全密室,更无法在安全密室前布放监控。安全密室与外界的一切交互全部要经过加密并进行完整性校验。
但当时SGX能创建的内存空间只有128M,而目前的AI机器学习模型动辙要上百M,大的甚至要几十上百个G,当时的SGX根本放不下这样的模型,无法在多方安全计算中使用。不过这次英特尔至强三代的Ice Lake-SP和即将到来的ARM V9中都可以支持TB级的安全空间,可见安全计算也是巨头们的一个重要发展方向。但在实践层面多方安全计算依然困扰业界,如果两个富翁只比一次那么一切好说,但是如果有恶意假扮者,不断和同一个富翁A比富,那么富翁A的信息泄漏是迟早的事。
笔者看到目前比如像蓝象智联的GAIA CUBE等联邦计算平台,就有将区块链技术与硬件安全计算结合的方案,避免同一用户的信息被不断的碰撞学习,保障数据安全性,做到最终数据可用不可见,最终打破数据孤岛,发挥数据价值。软硬结合实现安全联邦计算可能是一个今后业界发展的重要趋势之一。
AI算力-可变长SIMD VS 内存-显存通道提速
我们看到最近亮相的英特尔的至强三代Ice Lake-SP和安谋的ARM v9以及英伟达的首款CPU处理器Grace,都把宝押在了AI算方面。不过显然英伟达选择的技术路线与英特尔以及ARM不同,虽然Grace是基于ARM的,但是黄教主的方案是打通内存与显存之间的数据交换瓶颈。
正如我们刚才所说ARM等RISC处理器在指令预测等方面同天然比 X86 更有优势,能耗也比 X86 更低。当然这些都是 ARM 相对于 X86 的传统优势,本次 Grace 最大的创新点在于把 CPU 与 GPU 之间的通信速度提升了近 10 倍。根据黄仁勋的说法,“这是一万名工程人员历经几年的研发成果,旨在满足当前世界最先进应用程序的计算需求,其具备的计算性能和吞吐速率是以往任何架构所无法比拟的。”
CPU 和 GPU 的通信速度的重要性,也可以用苹果 M1 的例子来加以说明,我们知道苹果 M1 显卡与内存加在一起只有 16 个 G,对比上一代 Mac PRO 内存128G,光是显存都有 16G,不过搭载 M1 的入门版 Mac 在进行图像处理等需要 CPU 与 GPU 进行协同的运算任务时,至少比上一代顶配的 Mac 性能高出近一倍。其中的秘决就是将内存与显卡进行统一管理,从而大大提高了 CPU 与 GPU 的通信效率。 Grace 体系中 GPU 核心与 CPU 核心之间的通信不需要 CPU 的调度,也不需要占用数据总线的带宽,之前 CPU 必须将数据从其内存的区域复制到 GPU 使用的区域,而在 Grace 的加持下,CPU 只需要告诉GPU在内存的某位置有 30MB 的向量数据,然后就可以去做其它事了,GPU 则可以通过 Grace 复制通道迅速开始计算任务。
而ARM V9的SVE2和英特尔的至强三代的技术路线是可变长SIMD,这个我在前文《ARMv9到底强在强》中有过介绍了这里不加赘述。
同时我们也要关键到在Grace发布上,英伟达还拿出了很多软件产品,比如Transformers训练框架NVIDIA Megatron、Morpheus 数据中心安全平台、新一代人工智能对话机器人NVIDIA Jarvis、推荐系统是NVIDIA Merlin、隐私保护加强的AI辅助套件NVIDIA TAO,今后软硬结合的一体化计算框架可能也会成为趋势。
云计算的激烈争夺
其实笔者在前文《英特尔火线换帅、苹果搅动乾坤,国芯路在何方》就曾指出,在英伟达发起了收购ARM的要约之后,必然预示云计算市场将是各大巨头重要的争夺方向。
在云计算这种多租户的场景下,可能有很多用户依靠虚拟化技术使用同一CPU工作,这就要求不同用户使用的内存要严格隔离,因此苹果M1以及英伟达Grace将内存与显存混用打通CPU与GPU的方式不利于虚拟化的加速。基于上述原因目前英伟达和苹果M1的算力提升还暂时影响不到云计算市场,目前英特尔在云计算方面还是占据不少优势。据笔者了解到的情况看,在最新的至强三代Ice Lake-SP系列中中有两款专为云计算虚拟机和容器进行优化的型号,其中
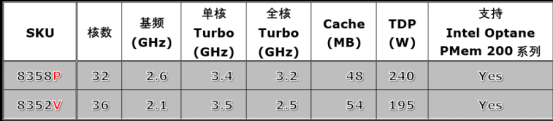
P后缀:专为虚拟化层提供优化,为虚拟机提供更高的频率。
V后缀:代表为SaaS优化,针对高密度、低功耗容器环境,提高编排效率。
我们看到P后缀的8358P系列其能耗指标TDP是240W,这对于风冷服务器来说压力是不低的,不过这对于已经大规模推广液冷技术,能够给服务器泡澡的阿里云来讲就不是什么问题了,因此我们看到阿里云是目前使用至强三代比较多的国内云厂商之一。阿里云与英特尔同步发布的第七代ECS云产品,搭载的就是这款Ice Lack,如果笔者所料不错的话,其小型号就应该是我们刚刚提到的8358P系列的芯片。据阿里云的介绍,第七代ECS相较于上一代整体算力提升了40%。在MySQL、Redis、Nginx等互联网典型场景中,第七代ECS最大性能提升了50%。
在Ice Lack的加持下,阿里云在容器部署密度最大可以提升到6倍,存储云盘挂载密度最高提升1倍。第七代ECS还能在3分钟内交付50万核VCPU,单实例10秒可拉起,要知道笔者目前所亲眼见到的最快VCPU交付也只能达到每分钟万核的速度,这种3分钟内交付50万核的供给效率令人赞叹。
站直了别趴下
以上就是笔者对于最近半导体行业最新进展的一些解读,而个人认为龙芯通过二进制翻译的方式使LooongArch兼容其它指令集的做法也是我国半导体企业的正确策略,目前整个行业的外部环境的确是纷乱复杂,在这种情况下我们要做的就是先别下牌桌,只要游戏还在继续我们就有机会。