?快来参与讨论?,点赞?、收藏⭐、分享?,共创活力社区。 ?

目录
?前言
?Stack 类
(一)Stack 类的概念与特点
(二)Stack 类的使用
(三)Stack 类的内部实现(手动实现)
(四)Stack 类的应用场景
?Queue 类
(一)Queue 类的概念与特点
(二)Queue 类的使用
(三)Queue 类的内部实现(手动实现)
(四)Queue 类的应用场景
?总结
?前言
在 C++ 编程领域,数据结构的合理运用是构建高效、可靠程序的关键因素之一。Stack(栈)和 Queue(队列)作为两种基础且重要的数据结构,在众多编程场景中发挥着不可或缺的作用。深入理解它们的原理、特性、操作方式以及内部实现机制,对于提升编程技能、优化程序性能以及解决复杂问题具有深远意义。
✍接下来,我们将详细解析 Stack 类和 Queue 类,并手动实现它们,以深入探究其内部奥秘。
?Stack 类
(一)Stack 类的概念与特点
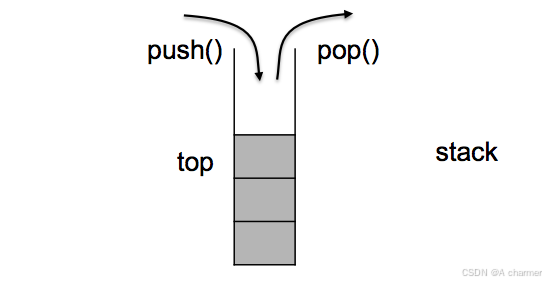
后进先出(LIFO)原则
Stack 类遵循后进先出的规则,类似于一叠盘子,最后放置的盘子最先被取出。这种特性使得 Stack 在处理具有嵌套结构或需要回溯的问题时表现出色。例如,在函数调用过程中,每次函数调用时的局部变量、参数等信息会依次压入栈中,当函数返回时,这些信息按照后进先出的顺序依次弹出,从而恢复到调用前的状态。
操作受限性Stack 类主要提供了入栈(push)、出栈(pop)、获取栈顶元素(top)、判断栈是否为空(empty)和获取栈的大小(size)等操作。与其他数据结构相比,其操作相对简单且受限,但这也使得它在特定场景下的使用更加高效和便捷。例如,在表达式求值中,我们只需关注当前操作符和操作数,通过栈来存储和处理它们,避免了复杂的遍历和搜索操作。
(二)Stack 类的使用
1.包含头文件与创建对象
要使用 Stack 类,需包含<stack>头文件(在我们手动实现的示例中暂不涉及该头文件)。然后可以通过以下方式创建一个 Stack 对象(在手动实现部分会有不同的创建方式):
#include <iostream>#include <stack>using namespace std;int main() { stack<int> myStack; // 后续操作... return 0;}2.基本操作示例
入栈操作(push):将元素压入栈顶。myStack.push(10);myStack.push(20);myStack.push(30);myStack.pop();cout << "栈顶元素: " << myStack.top() << endl;true,否则返回false。 if (myStack.empty()) { cout << "栈为空" << endl;} else { cout << "栈不为空" << endl;}cout << "栈的大小: " << myStack.size() << endl;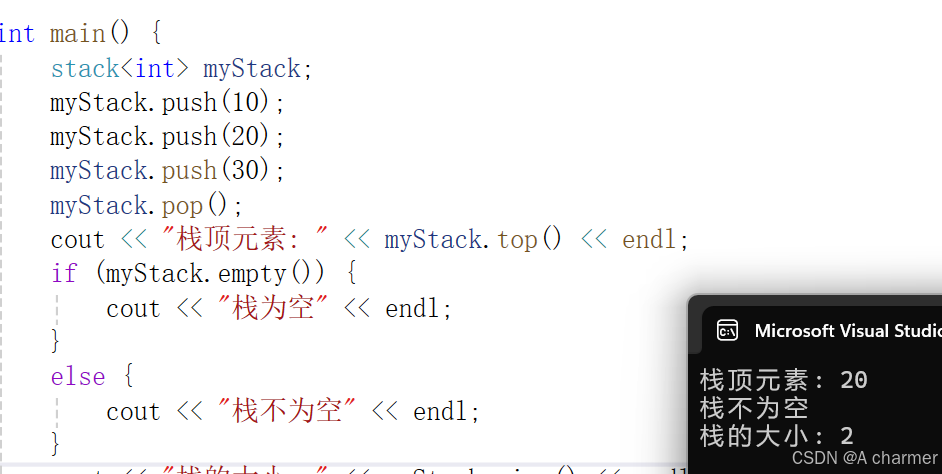
(三)Stack 类的内部实现(手动实现)
数据结构选择
为了手动实现 Stack 类,我们可以选择使用数组或链表来存储元素。这里我们以数组为例进行实现。类定义与成员变量
template<typename T>class MyStack {private: T* data; int topIndex; int capacity;public: // 构造函数 MyStack() { capacity = 10; data = new T[capacity]; topIndex = -1; } // 析构函数 ~MyStack() { delete[] data; }入栈操作(push)实现
void push(const T& value) { if (topIndex == capacity - 1) { // 栈已满,需要扩容 capacity *= 2; T* newData = new T[capacity]; for (int i = 0; i <= topIndex; i++) { newData[i] = data[i]; } delete[] data; data = newData; } topIndex++; data[topIndex] = value;}出栈操作(pop)实现
void pop() { if (topIndex >= 0) { topIndex--; }}获取栈顶元素(top)实现
T& top() { return data[topIndex];}判断栈是否为空(empty)实现
bool empty() const { return topIndex == -1;}获取栈的大小(size)实现
int size() const { return topIndex + 1; }};
(四)Stack 类的应用场景
函数调用栈 在程序执行过程中,函数的调用和返回顺序通过栈来管理。每当一个函数被调用时,系统会为其分配一个栈帧,用于存储函数的局部变量、参数、返回地址等信息。?当函数执行完毕返回时,栈帧被弹出,恢复之前的执行环境。这种机制保证了函数调用的嵌套和递归能够正确执行。 表达式求值 对于中缀表达式的求值,通常需要将其转换为后缀表达式,然后利用栈来计算。在计算后缀表达式时,操作数依次入栈,遇到运算符时弹出栈顶的操作数进行计算,并将结果再次压入栈中。最终栈顶元素即为表达式的值。 括号匹配检查 在处理包含括号的表达式或代码结构时,栈可用于检查括号是否匹配。例如,在编译器中,用于检查代码中的括号是否成对出现,?通过将左括号入栈,遇到右括号时与栈顶左括号匹配,若匹配成功则弹出栈顶左括号,否则表示括号不匹配。
?Queue 类
(一)Queue 类的概念与特点
先进先出(FIFO)原则
Queue 类遵循先进先出的规则,就像人们在排队等候,最先进入队列的元素最先被取出。这种特性使得 Queue 在处理需要按照顺序处理的任务或数据时非常有用。例如,在任务调度系统中,任务按照提交的顺序依次进入队列,然后按照先进先出的顺序被执行,保证了任务处理的公平性和顺序性。
操作特性Queue 类主要提供了入队(enqueue)、出队(dequeue)、获取队首元素(front)、判断队列是否为空(empty)和获取队列的大小(size)等操作。它专注于在⭐队尾添加元素和在队首删除元素,确保了元素的顺序性。例如,在广度优先搜索算法中,队列用于存储待访问的节点,按照先进先出的顺序依次访问节点,从而实现对图或树的广度优先遍历。
(二)Queue 类的使用
包含头文件与创建对象
要使用 Queue 类,需包含<queue>头文件(在手动实现示例中暂不涉及)。然后可以通过以下方式创建一个 Queue 对象(手动实现部分会有不同创建方式):
#include <iostream>#include <queue>using namespace std;int main() { queue<int> myQueue; // 后续操作... return 0;}基本操作示例 入队操作(enqueue):将元素添加到队尾。
myQueue.push(10);myQueue.push(20);myQueue.push(30);出队操作(dequeue):删除队首元素。
myQueue.pop();获取队首元素(front):返回队首元素的值,但不删除元素。
cout << "队首元素: " << myQueue.front() << endl; 判断队列是否为空(empty):如果队列为空,返回true,否则返回false。
if (myQueue.empty()) { cout << "队列为空" << endl;} else { cout << "队列不为空" << endl;}获取队列的大小(size):返回队列中元素的数量。
cout << "队列的大小: " << myQueue.size() << endl;
(三)Queue 类的内部实现(手动实现)
数据结构选择
同样,我们可以使用数组或链表来手动实现 Queue 类。这里我们以链表为例进行实现。类定义与节点结构体
template<typename T>class MyQueue {private: struct Node { T data; Node* next; Node(const T& value) : data(value), next(nullptr) {} }; Node* frontNode; Node* rearNode; int size;public: // 构造函数 MyQueue() : frontNode(nullptr), rearNode(nullptr), size(0) {} // 析构函数 ~MyQueue() { while (frontNode) { Node* next = frontNode->next; delete frontNode; frontNode = next; } }入队操作(enqueue)实现
void push(const T& value) { Node* newNode = new Node(value); if (rearNode) { rearNode->next = newNode; } else { frontNode = newNode; } rearNode = newNode; size++;}出队操作(dequeue)实现
void pop() { if (frontNode) { Node* next = frontNode->next; delete frontNode; frontNode = next; if (!frontNode) { rearNode = nullptr; } size--; }}获取队首元素(front)实现
T& front() { return frontNode->data;}判断队列是否为空(empty)实现
bool empty() const { return size == 0;}获取队列的大小(size)实现
int size() const { return size; }};
(四)Queue 类的应用场景
任务调度 在操作系统或任务管理系统中,任务通常按照提交的顺序依次进入队列,然后由处理器按照先进先出的顺序从队列中取出任务进行执行。这种方式确保了任务的公平处理,避免了某些任务长时间等待而得不到执行的情况。 广度优先搜索(BFS)算法 在对图或树进行广度优先搜索时,队列用于存储待访问的节点。?从起始节点开始,将其相邻节点依次入队,然后按照先进先出的顺序取出节点进行访问,并将访问过的节点标记。接着将已访问节点的未访问相邻节点入队,重复这个过程,直到队列为空或找到目标节点。通过队列的先进先出特性,实现了对图或树的层次遍历。 消息队列 在分布式系统或异步编程中,消息队列用于存储和传递消息。消息按照发送的顺序依次进入队列,接收方按照先进先出的顺序从队列中获取消息进行处理。?这种方式保证了消息处理的顺序性,避免了消息乱序导致的问题。
?总结
✍Stack 类和 Queue 类是 C++ 编程中极为重要的数据结构,它们各自独特的特性和操作方式使其在不同编程场景中发挥着关键作用。通过深入理解它们的概念、使用方法、内部实现机制(尤其是手动实现过程)以及应用场景,我们能够在编程时更加灵活地运用它们解决复杂问题,提高程序效率和可读性。在实际编程中,应根据具体需求选择合适的数据结构,充分发挥其优势,构建高效、健壮的程序。同时,深入了解其底层实现原理有助于在遇到性能瓶颈或特殊需求时对程序进行优化和定制。?希望本文能帮助读者更好地掌握 Stack 类和 Queue 类,助力 C++ 编程之旅。
觉得本文有用?欢迎关注我呀,更多编程干货持续分享哦。
?【A Charmer】 