
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥
♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥
♥♥♥我们一起努力成为更好的自己~♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥
✨✨✨✨✨✨ 个人主页✨✨✨✨✨✨前面的博客已经学习了C语言以及使用C语言来实现一些数据结构~这一篇博客我们将启航C++,去领略更加深层次计算机语言的魅力~准备好了吗?我们发车了~
目录
C++发展历史
C++版本更新
C++的第一个程序
命名空间
namespace的价值
namespace的定义及注意点
namespace的使用
C++输入&输出
缺省参数
函数重载
引用
引用的概念和定义
引用的特性
引用的使用
const引用
指针和引用的关系
nullptr
inline
C++发展历史
C++的起源可以追溯到1979年,当时Bjarne Stroustrup(本贾尼·斯特劳斯特卢普(C++祖师爷)(这里翻译的名字不同的地方可能有差异) 在贝尔实验室从事计算机科学和软件工程的研究工作。面对项目中复杂的软件开 发任务,特别是模拟和操作系统的开发工作,他感受到了现有语言(如C语言)在表达能力、可维护性 和可扩展性方面的不足。 1983年,Bjarne Stroustrup在C语言的基础上添加了面向对象编程的特性,设计出了C++语言的雏形, 这个时候C++已经有了类、封装、继承等核心概念,为后来的面向对象编程奠定了基础。这⼀年该语言被 正式命名为C++。 (不得不说,祖师爷就是祖师爷,直接自己创建了一个新的计算机语言) 在随后的几年中,C++在学术界和工业界的应用也就逐渐增多。一些大学和研究所开始将C++作为教学和研 究的首选语言,而⼀些公司也开始在产品开发中尝试使用C++。这⼀时期,C++的标准库和模板等特性 也得到了进⼀步的完善和发展。 C++的标准化工作于1989年开始,并成立了⼀个ANSI和ISO(International Standards Organization)国际标准化组织的联合标准化委员会。1994年标准化委员会提出了第⼀个标准化草 案。在该草案中,委员会在保持斯特劳斯特卢普最初定义的所有特征的同时,还增加了部分新特征。在完成C++标准化的第⼀个草案后不久,STL(Standard Template Library)是惠普实验室开发的⼀系 列软件的统称。它是由Alexander Stepanov、Meng Lee和David R Musser在惠普实验室⼯作时所开发 出来的。在通过了标准化第⼀个草案之后,联合标准化委员会投票并通过了将STL包含到C++标准中的 提议。STL对C++的扩展超出C++的最初定义范围。虽然在标准中增加STL是个很重要的决定,但也因 此延缓了C++标准化的进程。1997年11月14日,联合标准化委员会通过了该标准的最终草案。1998年,C++的ANSI/IS0标准被投入使用~后来经历了多次重要的版本更新和标准修订,这些标准和修订不断扩展和完善了C++的功能和性能,使其在软件开发中得到了更广泛的应用。
 放上一张祖师爷照片~
放上一张祖师爷照片~ C++版本更新
C++经过几十年的发展,不断地在更新完善~
可以看看下面的图片来了解一下C++的版本更新~
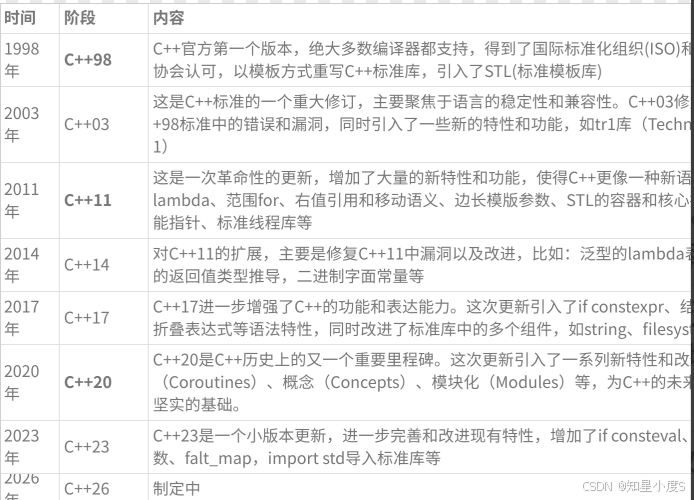
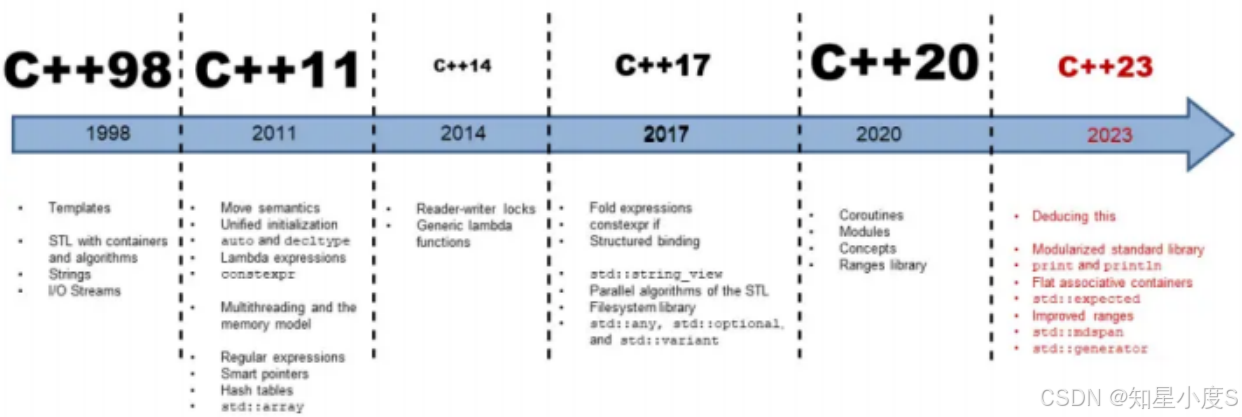
这里呢~加粗的就是改动比较大的版本~
可以看出来现在的C++基本上三年会有一次更新和修订~这些标准和修订不断扩展和完善了C++的功能和性能,使其在软件开发中得到了更广泛的应用~
已经说了C++的发展历史和它的版本更新,接下来我们就开始C++这一门计算机语言~
C++的第一个程序
以前我们C语言阶段使用VS创建源文件的时候,是以.c为后缀的源文件,这里我们需要使用C++的语法和库的话就需要使用.cpp为后缀.这样的话,VS编译器看到是.cpp就会调用C++编译器编译,linux下要用g++编译,不再是gcc。
前面我们学到C语言第一个程序打印hello world,事实上,C++兼容C语言绝大多数的语法,所以C语言实现的hello world依旧可以在当前文件下运行。
C语言版:
//C语言版#include<stdio.h>int main(){printf("hello world\n");return 0;}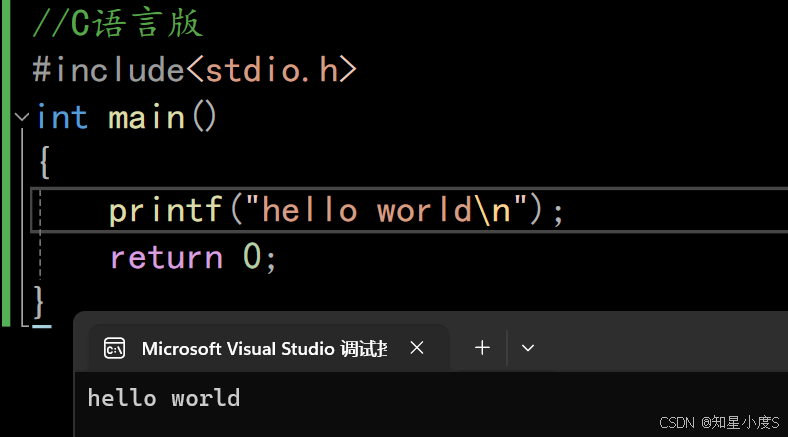
但是C++有⼀套自己的输⼊输出,严格说C++版本的hello world应该是这样写。
C++版:
//C++版#include<iostream>using namespace std;int main(){cout << "hello world\n" << endl;return 0;}
这一段C++代码可能看着有点懵逼,没关系,接下来跟我一起开启C++的美妙之旅~
命名空间
命名空间也叫名字空间,我们会使用namespace关键字
namespace的价值
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。我们使用命名空间的目的是对标识符的名称进行本地化,以 避免命名冲突或名字污染 。 我们来看看下面C语言版本命名冲突的例子://命名冲突#include <stdio.h>#include <stdlib.h>int rand = 10;int main(){// 编译报错:error C2365: “rand”: 重定义;以前的定义是“函数”printf("%d\n", rand);return 0;}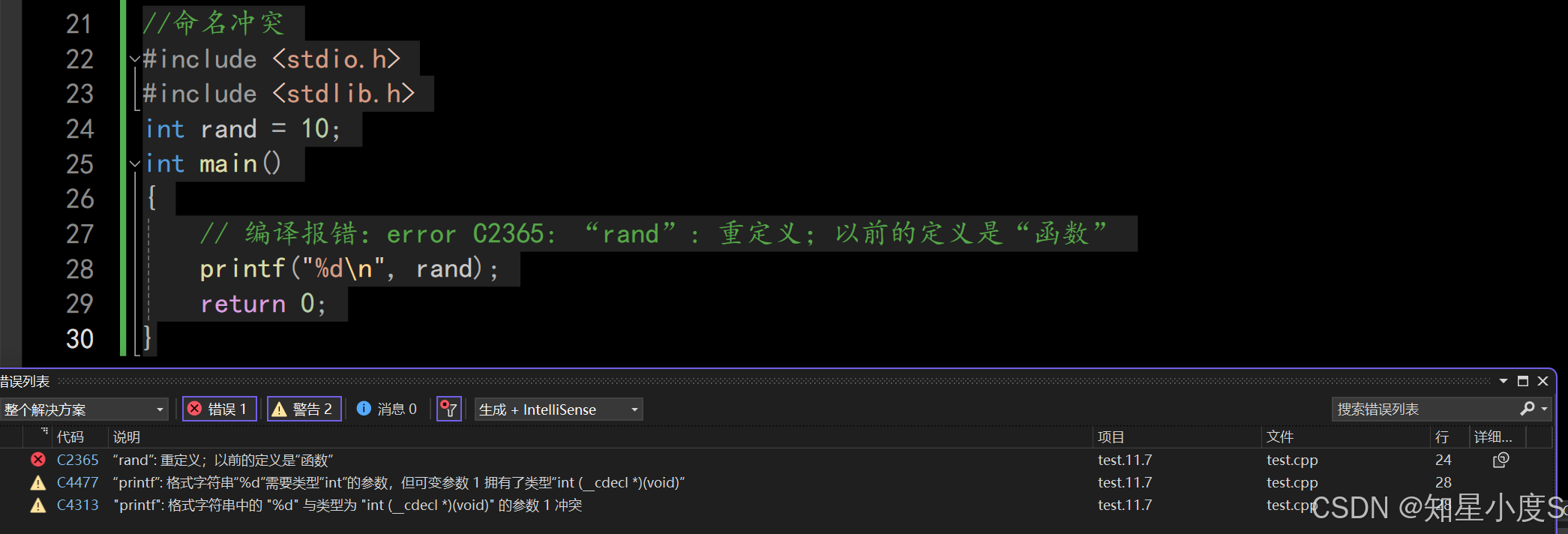
我们可以看到编译报错,这是因为在在stdlib头文件中,包含了rand这样一个函数,在预编译阶段会把这个头文件进行展开,那么在全局域这个范围内就有两个rand,那么也就造成了rand重复定义,进而报错~
如果我们注释掉#include <stdlib.h>就不会出现这个问题~
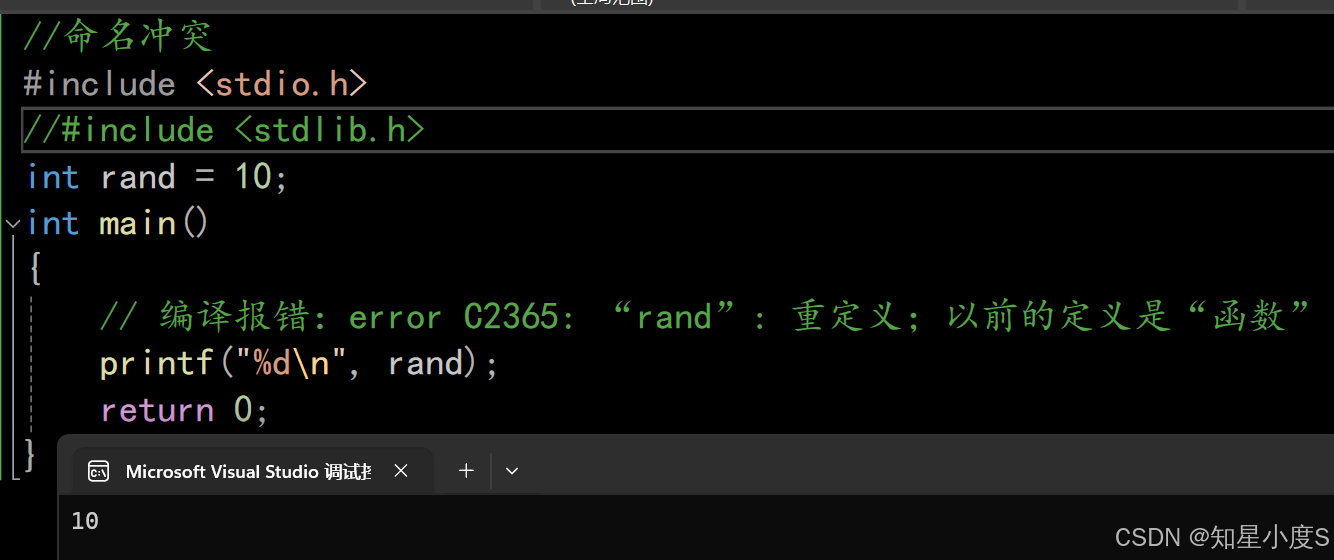
这个时候我们就需要需要使用namespace来解决这个问题了~
namespace的定义及注意点
1.定义命名空间,需要使用namespace关键字,后面跟命名空间的名字,然后接⼀对{}即可,{}中即为命名空间的成员,命名空间中可以定义变量/函数/类型等。
例:
namespace xiaodu{//定义变量int rand = 10;//定义函数int Mul(int a, int b){return a * b;}//定义类型struct Node{int data;struct Node* next;};//结构体后面有分号}//这里没有分号这里需要特别注意的是使用namespace来定义一个域,{ }后面是没有分号的,与我们前面学习的结构体进行一个区分~
2.namespace本质是定义出⼀个域,这个域跟全局域各自独立,不同的域可以定义同名变量 ,这样就可以解决前面的代码命名冲突的问题~int main(){//这里访问全局的rand也就是一个函数,应该打印出来一个地址printf("%d\n", rand);printf("%p\n", rand);return 0;}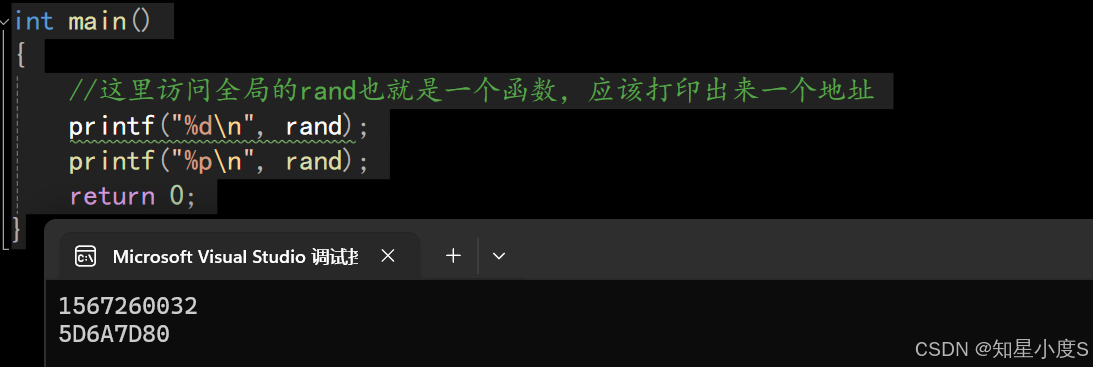
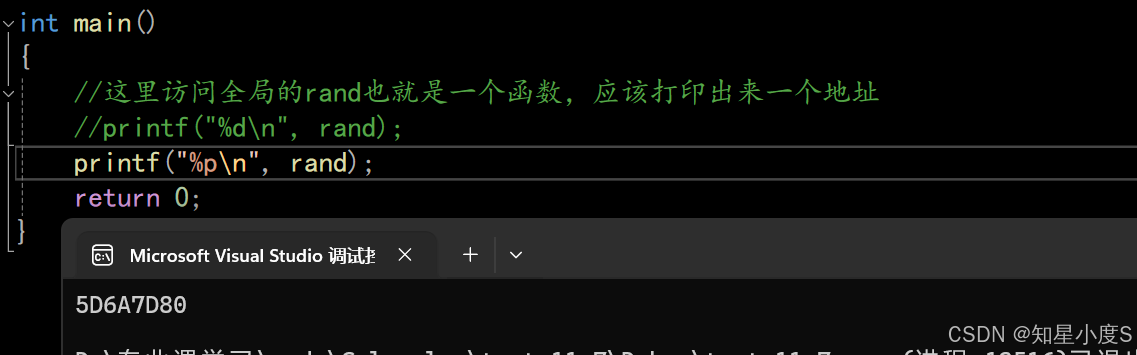
#include<stdio.h>#include<stdlib.h>namespace xiaodu{//定义变量int rand = 10;//定义函数int Mul(int a, int b){return a * b;}//定义类型struct Node{int data;struct Node* next;};//结构体后面有分号}//这里没有分号int main(){//这里访问全局的rand也就是一个函数,应该打印出来一个地址printf("%p\n", rand);//访问域里面的randprintf("xiaodu::rand = %d\n", xiaodu::rand);//访问域里面的Mul函数printf("xiaodu::Mul(2,4) = %d\n", xiaodu::Mul(2, 4));return 0;}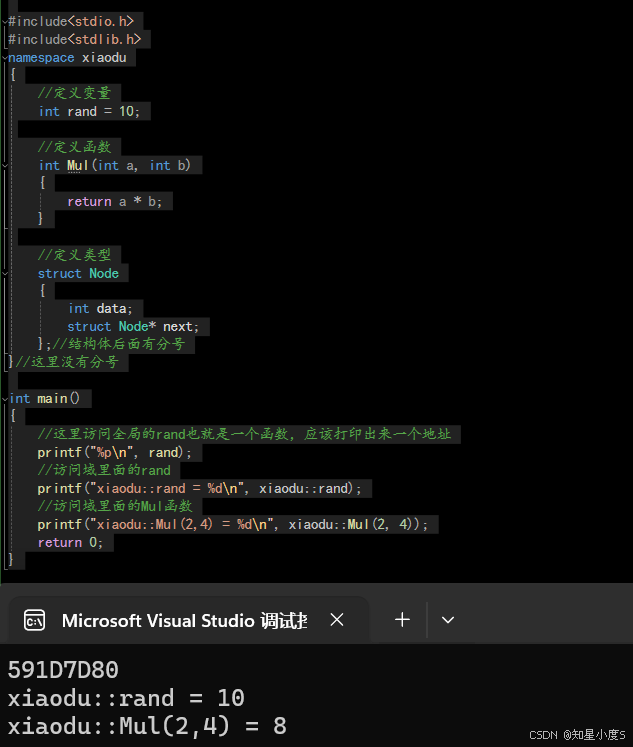

我们可以看出namespace是不可以定义在局部的,但是可以嵌套定义~就像有多个公司,每一个公司内部又会有不同的部门~
例:
#include<stdio.h>#include<stdlib.h>namespace B{//namespace可以嵌套定义namespace data{int rand = 10;int Mul(int a, int b){return a * b;}}//不同的域可以定义同名变量namespace st{int rand = 1;struct Node{int data;struct Node* next;};}}//这里没有分号int main(){printf("%p\n", rand);//打印地址,全局域的函数randprintf("B :: data :: rand = %d\n", B::data::rand);printf("B :: st :: rand = %d\n", B::st::rand);return 0;}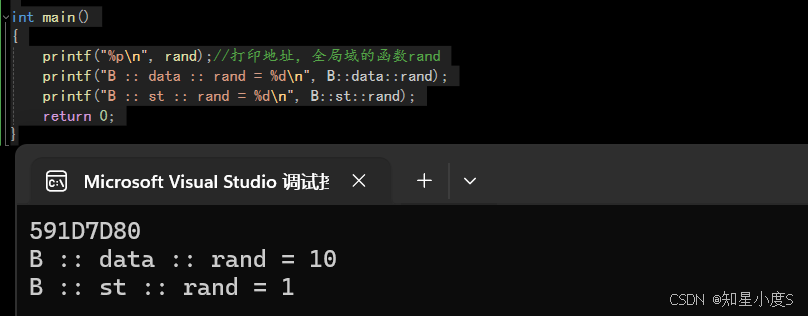
 Stack.cpp
Stack.cpp  test.cpp
test.cpp #include"Stack.h"// 全局定义了⼀份单独的Stacktypedef struct Stack{int a[10];int top;}ST;void STInit(ST* ps) {}void STPush(ST* ps, int x) {}int main(){// 调用全局的ST st1;STInit(&st1);STPush(&st1, 1);STPush(&st1, 2);printf("sizeof(st1) = %d\n", sizeof(st1));// 调用命名空间域的MyStack::Stack st2;printf("sizeof(st2) = %d\n", sizeof(st2));MyStack::StackInit(&st2);MyStack::StackPush(&st2, 3);MyStack::StackPush(&st2, 4);return 0;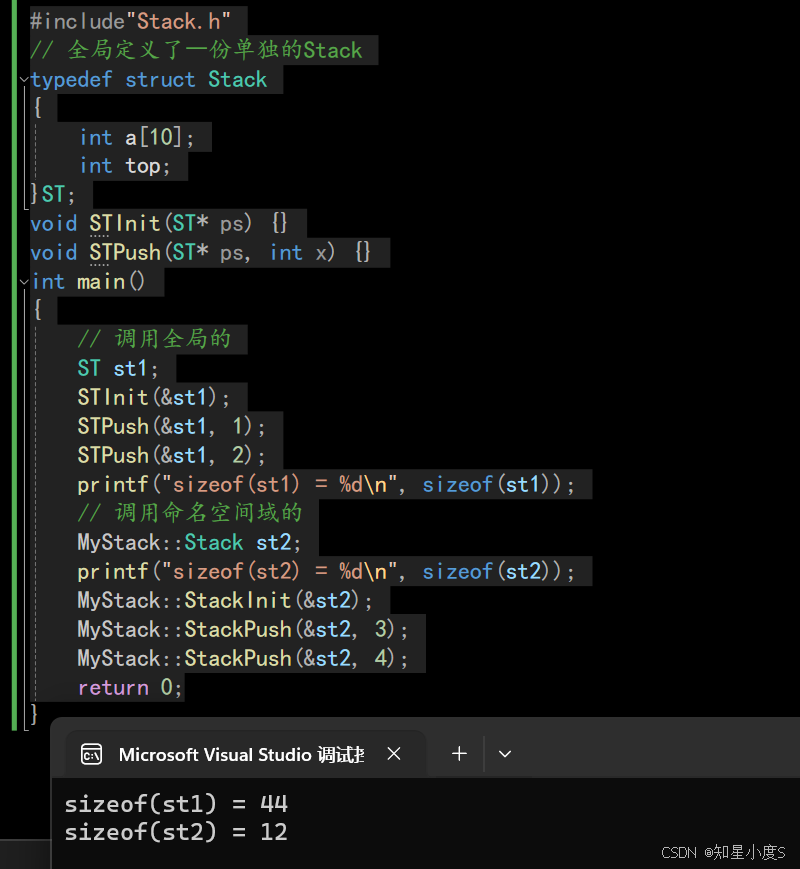
结合结构体部分的知识,我们也就可以知道这两个的大小~不清楚的可以看看这一篇博客~C语言——自定义类型
结合上面的测试,我们可以看出 编译器会自动将不同文件中同名的namespace合并在一起,不会发生冲突~ 8.C++标准库都放在⼀个叫std(standard)的命名空间中namespace的使用
编译 默认只会在局部或者全局查找⼀个变量的声明/定义 ,而不会到命名空间里面去查找 所以下面程序会编译报错#include<stdio.h>namespace xiaodu{int a = 10;int b = 100;}int main(){// 编译报错:error C2065: “a”: 未声明的标识符printf("%d\n", a);return 0;}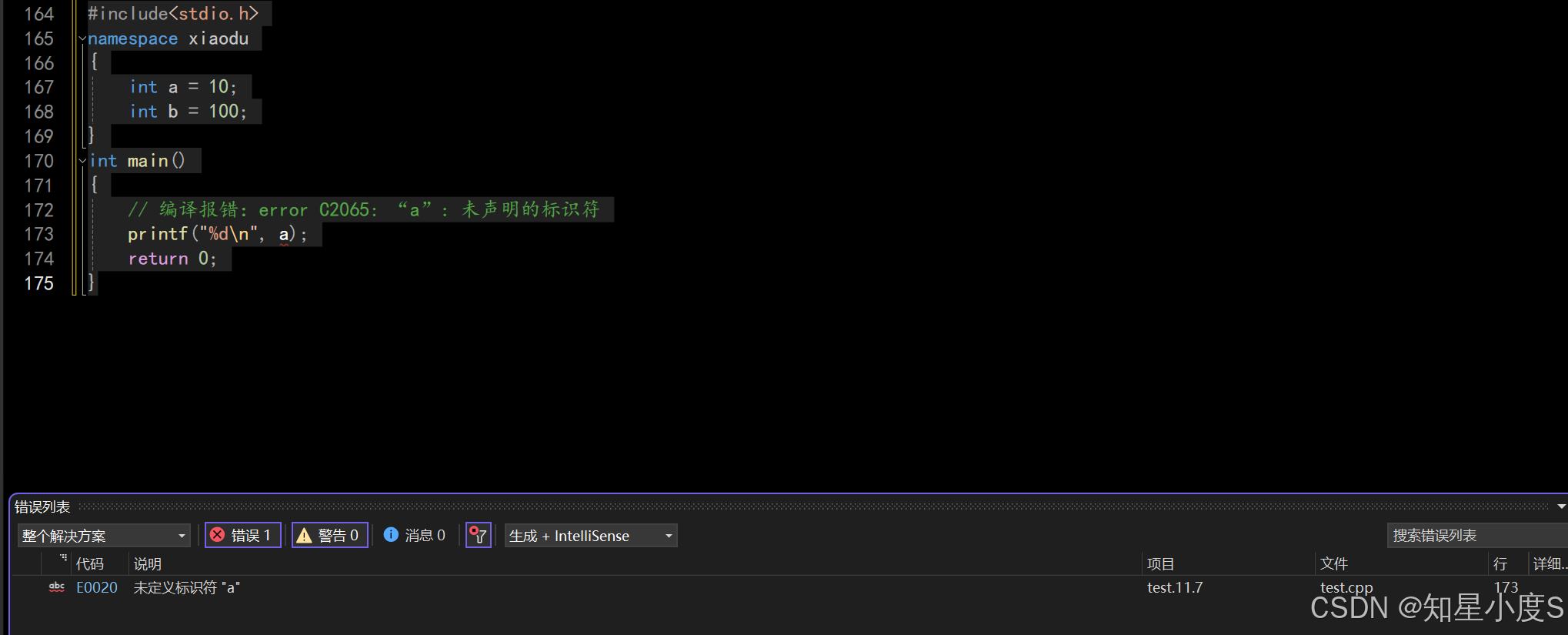
#include<stdio.h>namespace xiaodu{int a = 10;int b = 100;}int main(){printf("xiaodu::a = %d\n", xiaodu::a);printf("xiaodu::b = %d\n", xiaodu::b);return 0;}
但是我们要使用很多次命名空间域里面的变量或者函数时,每一次都加上命名空间域名就会很麻烦~所以就有了第二个方法
2. 使用using展开命名空间中全部成员 ,这样就可以直接使用命名空间域的成员,但是在项目中不推荐,冲突风险很大,日常小练习程序为了方便推荐使用 例:#include"Stack.h"//使用using展开命名空间中全部成员using namespace MyStack;int main(){Stack st;StackInit(&st);StackPush(&st, 1);StackPush(&st, 2);StackPush(&st, 3);StackPush(&st, 4);StackPush(&st, 5);StackPush(&st, 6);StackPush(&st, 7);printf("StackTop = %d\n", StackTop(&st));StackDestory(&st);return 0;}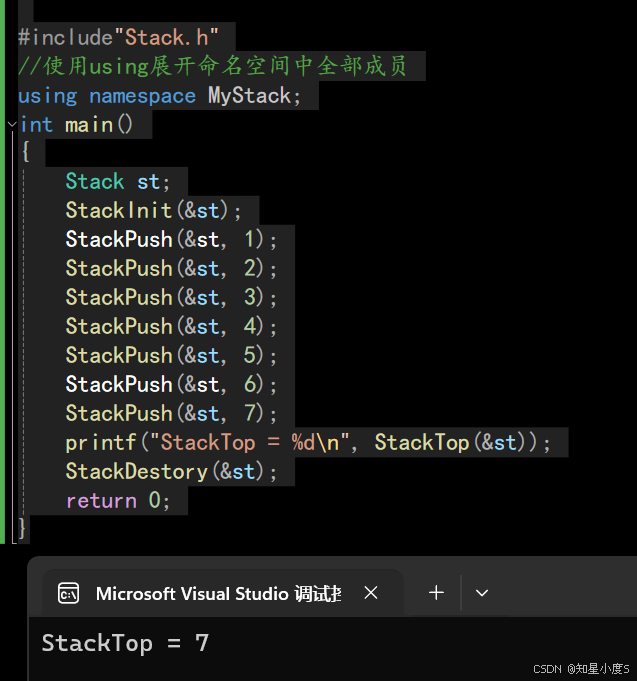
这种方法也有缺陷,相当于原来封装好的域又给他展开了,所以在项目中不推荐~来看看下一个方式~
3. using将命名空间中某个成员展开 ,当项目中经常访问的不存在冲突的成员推荐这种方式。 例:#include"Stack.h"//使用using展开部分命名空间中成员//展开StackPush//这里不需要关键字namespace(展开部分命名空间中成员)using MyStack::StackPush;int main(){MyStack::Stack st;MyStack::StackInit(&st);//StackPush经常使用StackPush(&st, 1);StackPush(&st, 2);StackPush(&st, 3);StackPush(&st, 4);StackPush(&st, 5);StackPush(&st, 6);StackPush(&st, 7);printf("StackTop = %d\n", MyStack::StackTop(&st));MyStack::StackDestory(&st);return 0;}
这三种方式,我们可以根据自己实际需要进行使用~
C++输入&输出
1.<iostream> 是 Input Output Stream 的缩写,是标准的输入、输出流库,定义了标准的输入输 出对象。 2. std::cin 是 istream 类的对象,它主要面向窄字符(narrow characters (of type char))的标准输入 流。 3. std::cout 是 ostream 类的对象,它主要面向窄字符的标准输出流。 4. std::endl 是一个函数,流插入输出时,相当于插入⼀个换行字符加刷新缓冲区 。(它表现出来的效果约等于 ’\n' ,但是它是一个函数,更加复杂~) 我们可以在Cplusplus网站上找到它~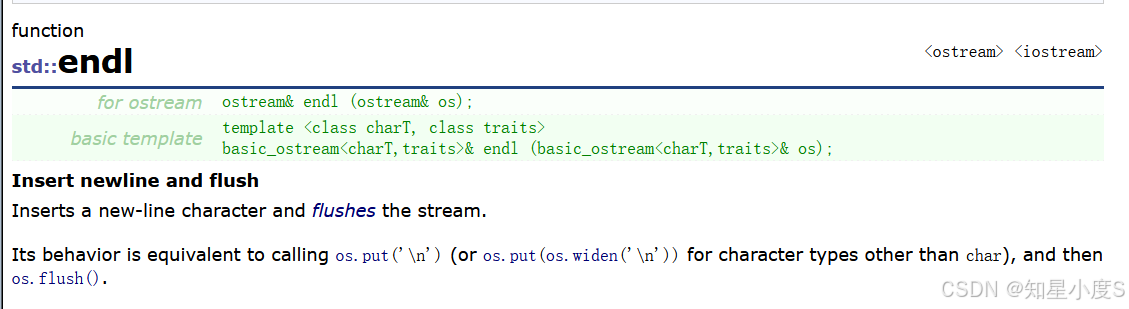 5.<<是流插入运算符,>>是流提取运算符(前面C语言还用这两个运算符做位运算左移/右移) 6. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动指定格式(同时它们只能输入输出内置类型) C++的输入输出可以自动识别变量类型 (本质是通过函数重载实现的),最重要的是 C++的流能更好的支持自定义类型对象的输入输出。 7.IO流涉及类和对象,运算符重载、继承等很多面向对象的知识,这里我们先简单认识⼀下C++ IO流的用法,后面我们逐步深入~ cout/cin/endl等都属于C++标准库, C++标准库都放在⼀个叫std(standard)的命名空间中 ,所以我们可以 通过命名空间的使用方式来使用它们~ 8.在⼀般日常练习中我们可以using namespace std,实际项目开发中不建议using namespace std(又容易造成命名冲突) 9. 我们没有包含<stdio.h>,也可以使用printf和scanf,因为<iostream>间接包含它。vs系列 编译器是这样的,其他编译器可能会出现报错的情况,到时候加上就好了~
5.<<是流插入运算符,>>是流提取运算符(前面C语言还用这两个运算符做位运算左移/右移) 6. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动指定格式(同时它们只能输入输出内置类型) C++的输入输出可以自动识别变量类型 (本质是通过函数重载实现的),最重要的是 C++的流能更好的支持自定义类型对象的输入输出。 7.IO流涉及类和对象,运算符重载、继承等很多面向对象的知识,这里我们先简单认识⼀下C++ IO流的用法,后面我们逐步深入~ cout/cin/endl等都属于C++标准库, C++标准库都放在⼀个叫std(standard)的命名空间中 ,所以我们可以 通过命名空间的使用方式来使用它们~ 8.在⼀般日常练习中我们可以using namespace std,实际项目开发中不建议using namespace std(又容易造成命名冲突) 9. 我们没有包含<stdio.h>,也可以使用printf和scanf,因为<iostream>间接包含它。vs系列 编译器是这样的,其他编译器可能会出现报错的情况,到时候加上就好了~ 说了这么多,是不是还是更加云里雾里~我们结合下面的例子来看看~
例:
//标准的输入、输出流库#include<iostream>//不包含<stdio.h>,因为vs系列编译器<iostream>间接包含它//C++标准库都放在⼀个叫std(standard)的命名空间中//使用using进行展开using namespace std;int main(){int a = 0;double b = 0;//C++的输入输出可以自动识别变量类型//同时可以连续输入输出//cout ——输出, cin——输入cout << "enter a、b:";cin >> a >> b;//std::endl 是一个函数,流插入输出时,相当于插入⼀个换行字符加刷新缓冲区cout << "a = " << a << '\n' << "b = " << b << endl;return 0;}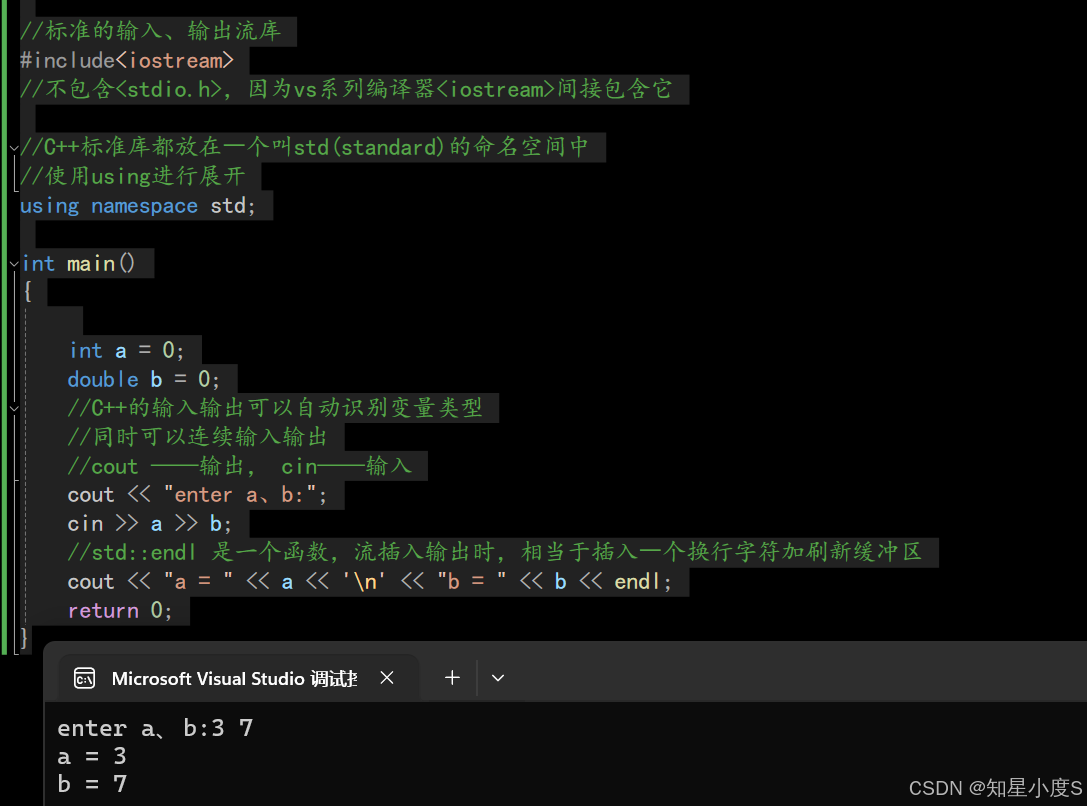
这样看起来,C++的输入输出比我们的C语言简单多了,有没有体会到C++的魅力呢?
缺省参数
什么是缺省参数呢?看这个名字,我们可以知道它是一个参数~我们一起来看看它的定义和使用~
》缺省参数是声明或定义函数时为函数的参数指定⼀个缺省值,在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。缺省参数也可以叫默认参数,函数的参数给了一个默认值~
知道了概念,来看看下面代码的简单使用~
#include<iostream>using namespace std;//缺省参数void func(int a = 10){cout << "a = " << a << endl << endl;}int main(){func();//没有实参,使用缺省参数10func(100);//有实参,使用实参100return 0;}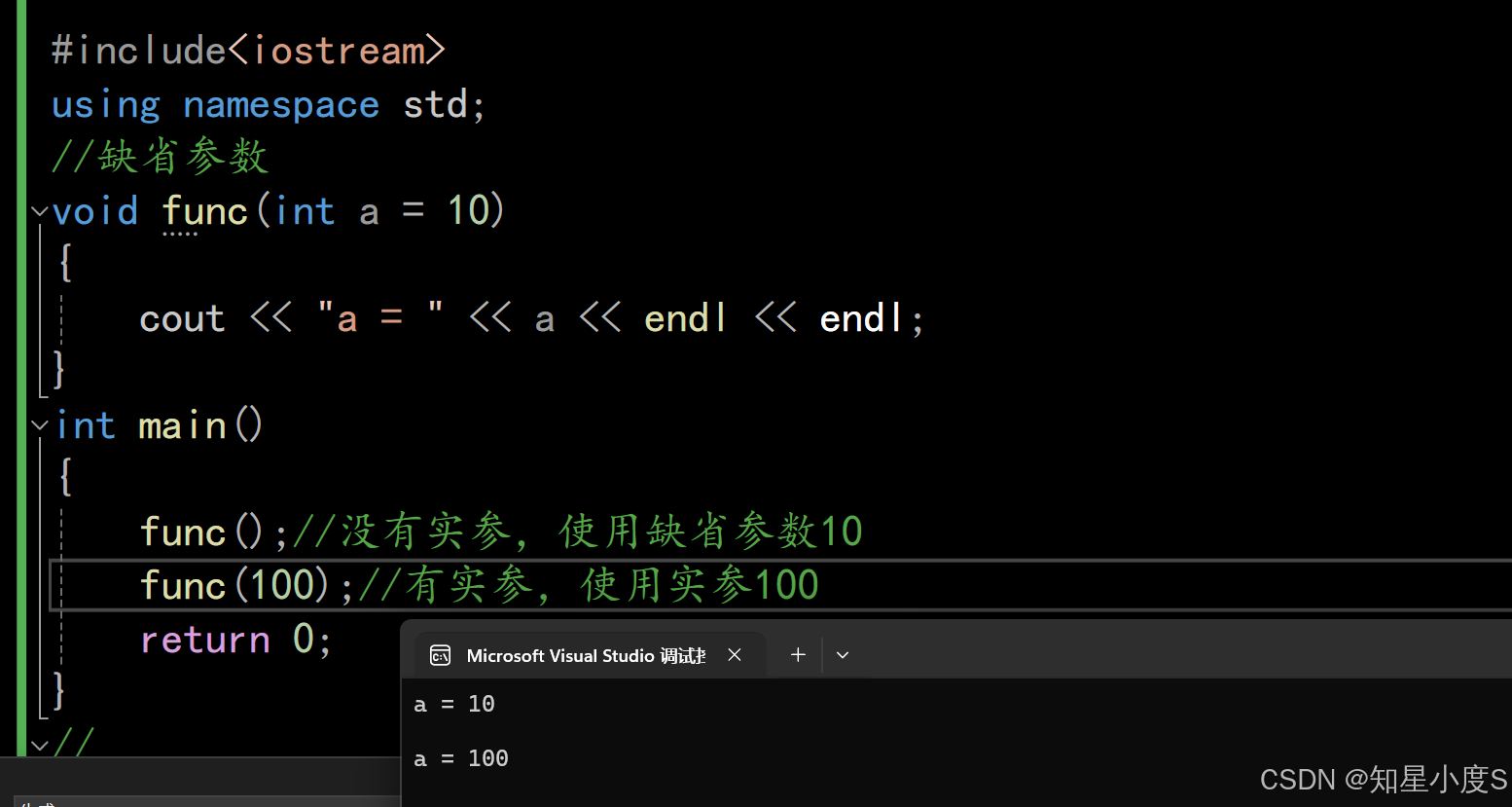
》缺省参数分为全缺省和半缺省参数
》全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值
#include<iostream>using namespace std;//缺省参数// 全缺省void Func1(int a = 1, int b = 2, int c = 3){cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}//半缺省(部分缺省)void Func2(int a, int b = 20, int c = 30){cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}int main(){// 全缺省调用Func1();//不传参,为默认缺省值Func1(11);//传一个参,第一个为传的实参值,其他的为默认缺省值Func1(11,22);//传两个参,前面两个为传的实参值,其他的为默认缺省值Func1(11,22,33);//传三个参,都为传的实参值// 半缺省调用//Func2两个参数是缺省参数,至少传一个参数Func2(100);//传一个参,第一个为传的实参值,其他的为默认缺省值Func2(100, 200);//传两个参,前面两个为传的实参值,其他的为默认缺省值Func2(100, 200, 300);//传三个参,都为传的实参值return 0;}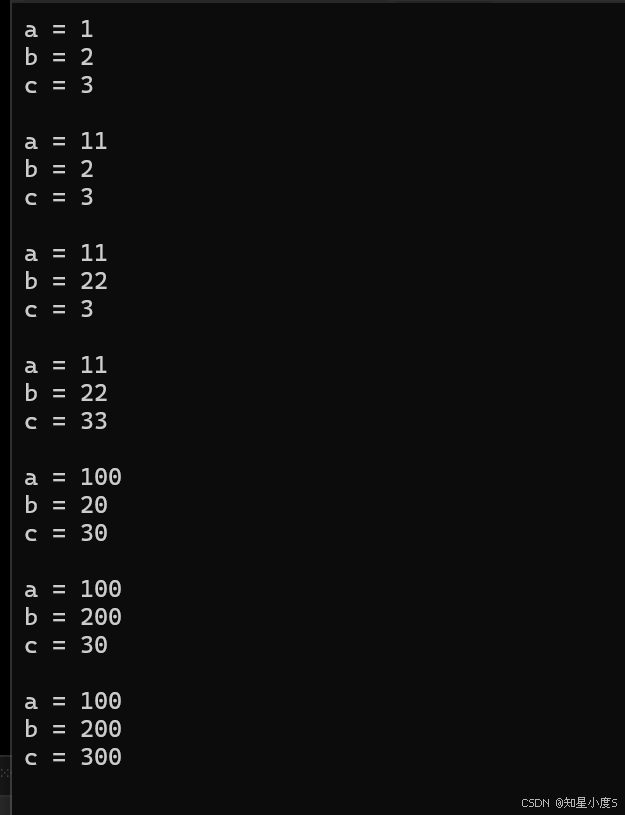
像我们的顺序表初始化的时候,就可以给定一个大小n,创建相应大小的空间~这样也就可以提高效率~这就是我们缺省参数的妙处所在~但是使用缺省参数需要注意下面几个点
》C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值。
比如下面的代码就会报错:
void Func(int a = 10,int b,int c = 30)//err//C++规定半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}
》带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。
比如下面的代码就会报错:
void Func(int a = 10, int b = 20, int c = 30){cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}int main(){Func();Func(1, , 3);//err//想直接给第一个和第三个传参是找不到的//带缺省参数的函数调用,C++规定必须从左到右依次给实参,不能跳跃给实参。 return 0;}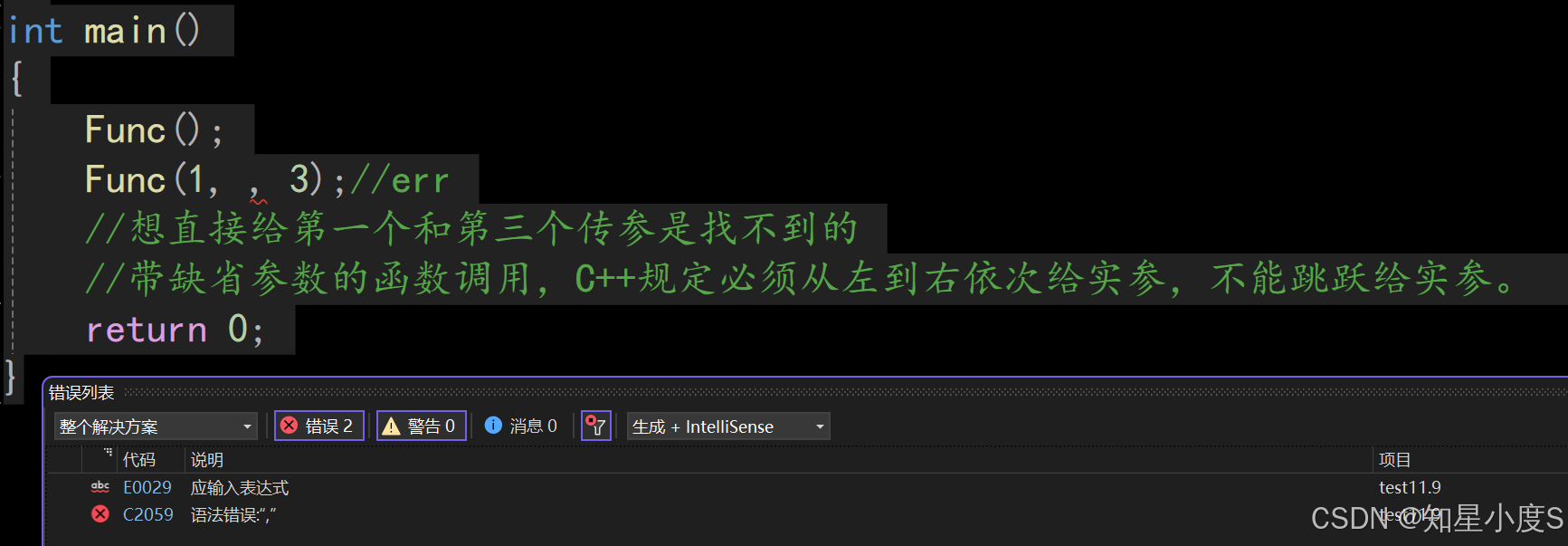
》函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值。
比如下面的代码就会报错:
#include<iostream>using namespace std;//函数声明void Func(int a = 10, int b = 20, int c = 30);int main(){Func(1, 2);return 0;}//函数定义//err//函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值void Func(int a = 10, int b = 20, int c = 30){cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}
正确代码:函数声明的地方给缺省值
#include<iostream>using namespace std;//函数声明//函数声明给缺省值void Func(int a = 10, int b = 20, int c = 30);int main(){Func(1, 2);return 0;}//函数定义void Func(int a, int b, int c){cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;}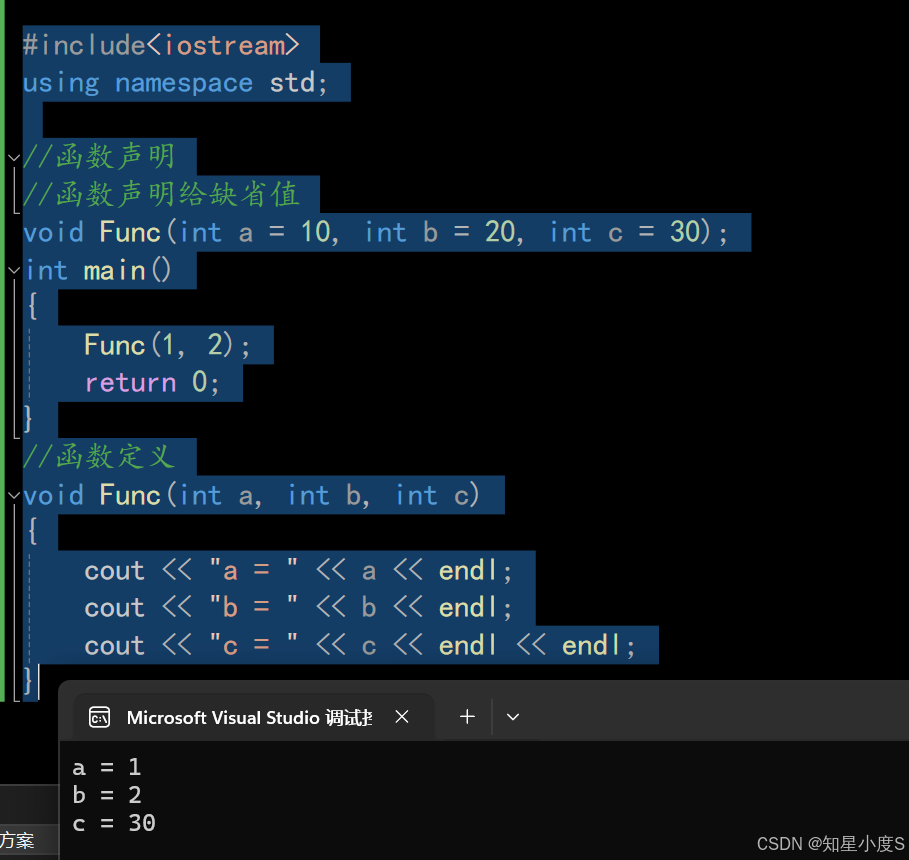
函数重载
》前面我们学习到的C语言是不支持同⼀作用域中出现同名函数的
》为了弥补这一个缺陷,C++支持在同⼀作用域中出现同名函数,但是要求这些同名函数的形参不同(参数个数不同或者类型不同),参数顺序不同,本质上是参数类型不同。函数调用时自动匹配找到应该调用的函数
》C++函数调用就表现出了多态行为,使用更灵活。
例:
#include<iostream>using namespace std;//1.形参参数类型不同int Add(int a, int b){cout << "int Add(int a, int b)" << endl;return a + b;}double Add(double a, double b){cout << "double Add(double a, double b)" << endl;return a + b;}//2.形参参数个数不同void func(int a){cout << "void func(int a)" << endl;}void func(int a, int b){cout << "void func(int a, int b)" << endl;}int main(){//形参参数类型不同测试Add(1, 2);Add(1.1, 2.2);//形参参数个数不同测试func(1);func(1, 2);return 0;}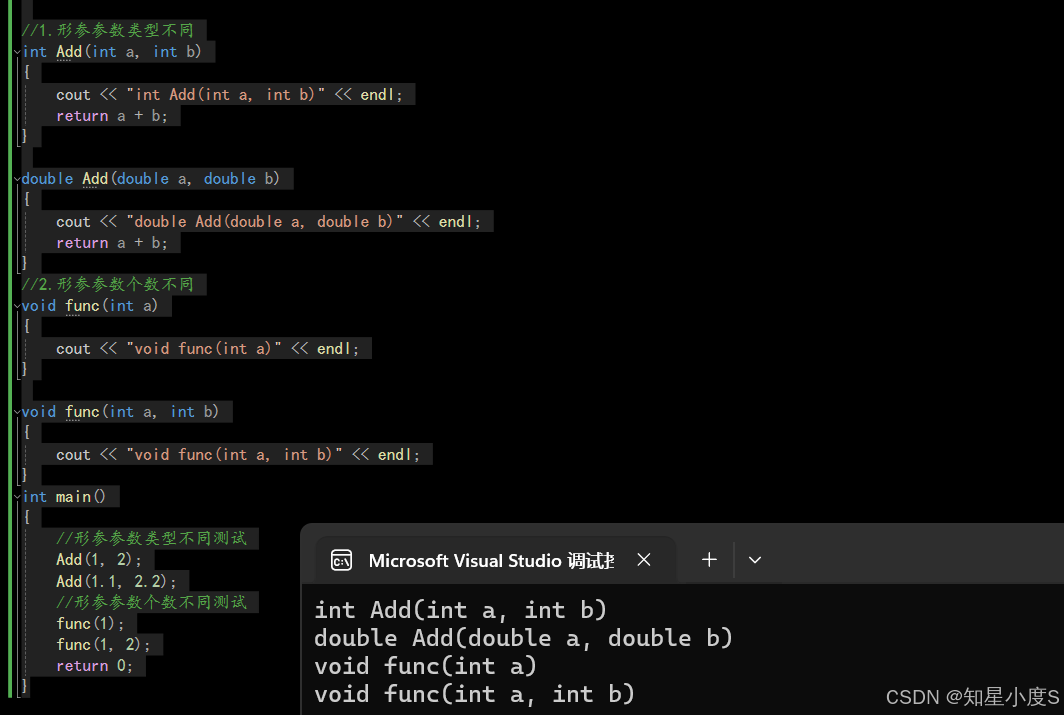
前面的使用没有问题,我们来看看下面的代码~
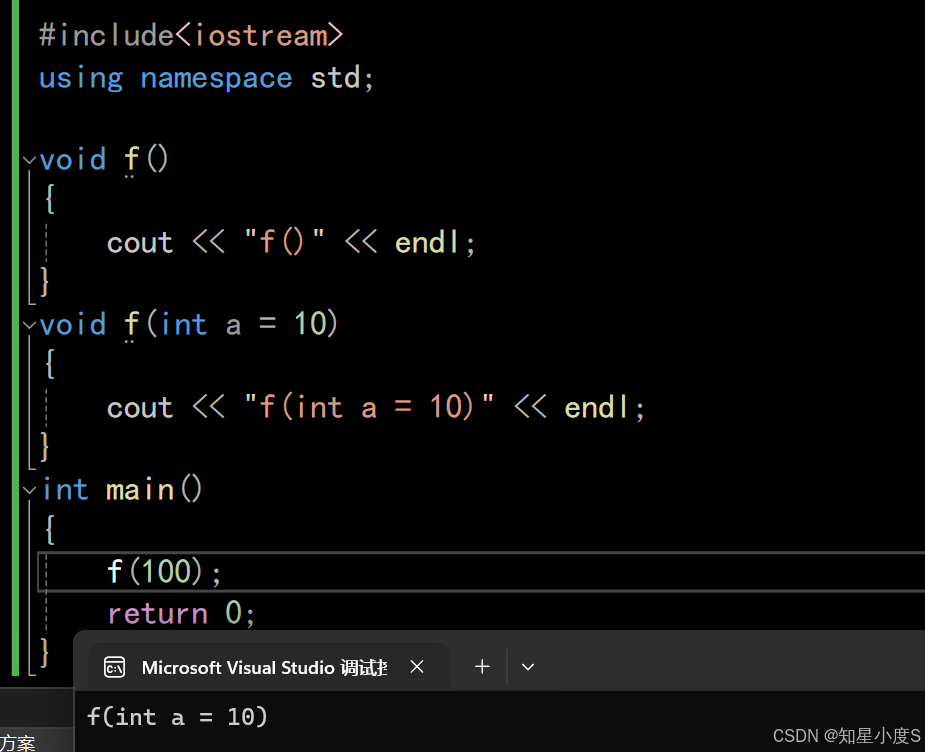
#include<iostream>using namespace std;void f(){cout << "f()" << endl;}void f(int a = 10){cout << "f(int a = 10)" << endl;}int main(){f();return 0;}上面的f是函数重载吗?它的输入结果是什么?
事实上,两个函数构成重载
但是f()调用时,会报错,存在歧义,因为第二个函数参数是缺省参数(可以给参数,也可以不给参数),那么编译器不知道调用谁~
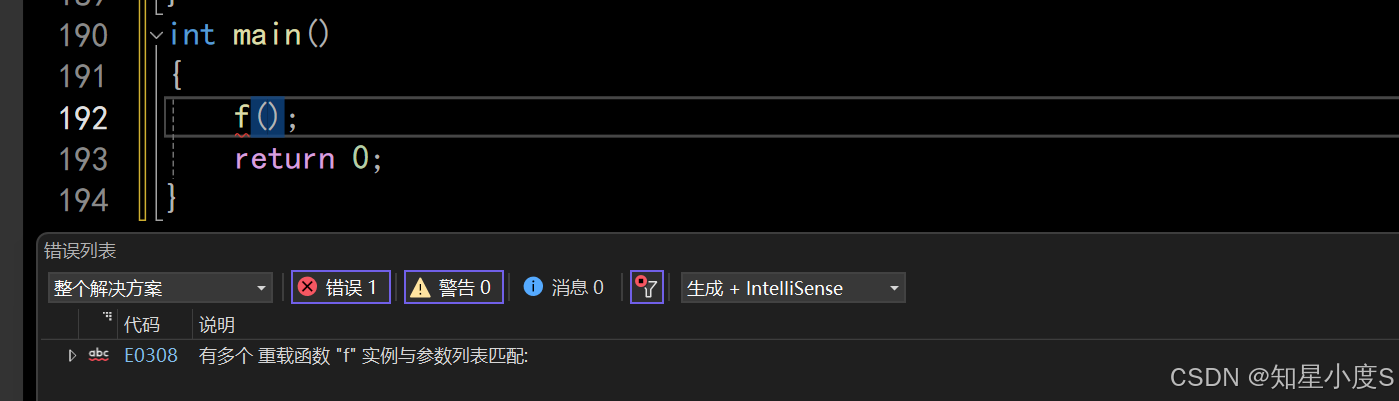
如果给了一个实参,那么就会调用第二个函数~
引用
接下来就是重头戏了~引用~
引用的概念和定义
》 引用不是新定义一个变量,而是 给已存在变量取一个别名 ,编译器不会为引用变量开辟内存空间, 它和它引用的变量共用同一块内存空间。 》 就相当于我们生活中除了有自己的名字,还有外号一样,事实上都是指同一个人~这里 已存在变量和它引用的变量共用同一块内存空间 。 》 比如:水浒传里面的林冲,外号豹子头;》定义:类型& 引用别名 = 引用对象;
》这里用到了&这个运算符,我们前面使用它来取地址,这是因为C++中为了避免引入太多的运算符,会复用C语言的⼀些符号,还有比如前面的<< 和 >>。
#include<iostream>using namespace std;int main(){int a = 1;// 引用:b和c是a的别名int& b = a;int& c = a;++c;// 同时也可以给别名b取别名,d相当于还是a的别名int& d = b;++d;cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;cout << "d = " << d << endl;// 取地址我们看到是⼀样的//已存在变量和它引用的变量共用同一块内存空间cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;}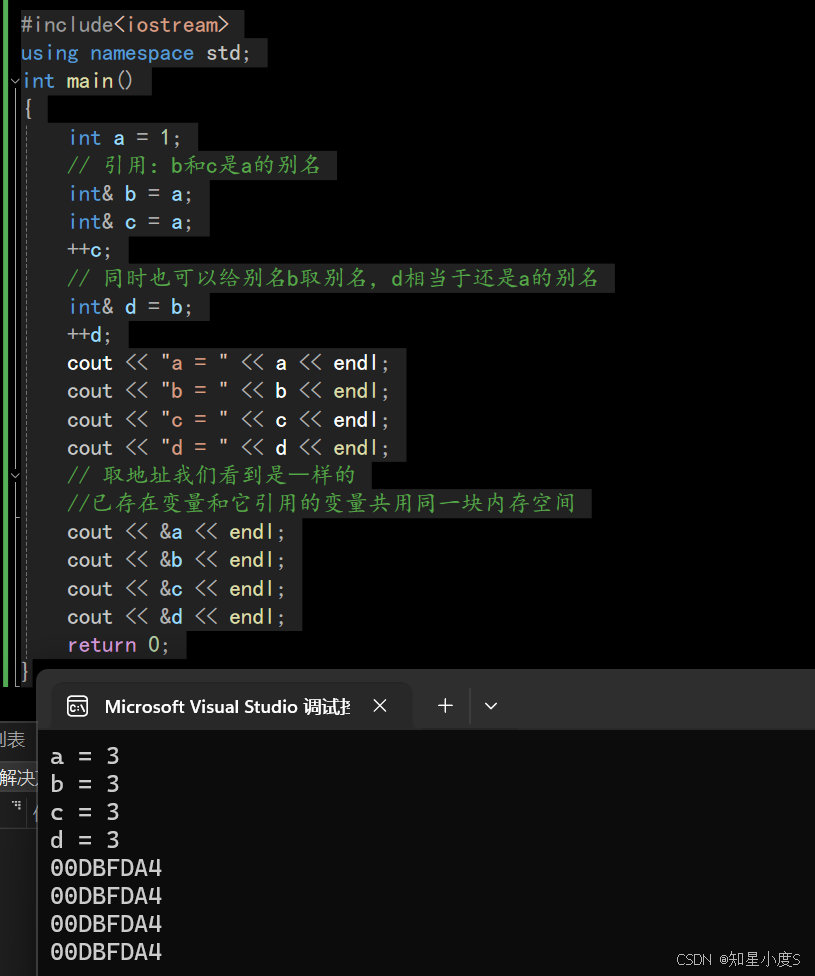
所以,引用就是给已存在变量取一个别名,已存在变量和它引用的变量共用同一块内存空间。
上面的代码中a、b、c、d共用同一块内存空间
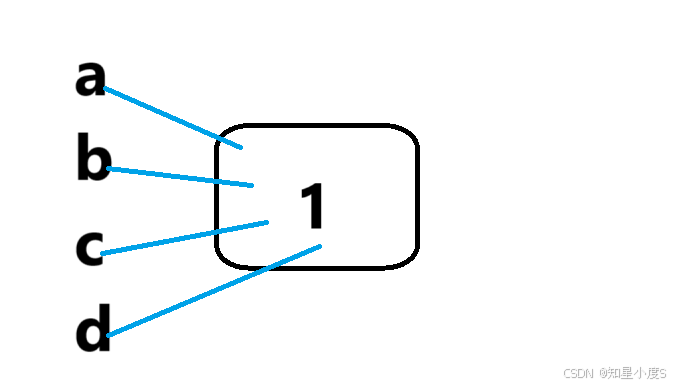
引用的特性
》 引用在定义时必须初始化 (与普通变量不同) 》 ⼀个变量可以有多个引用 (想、像前面代码的a、b、c、d) 》 引用⼀旦引用⼀个实体,再不能引用其他实体(专一性)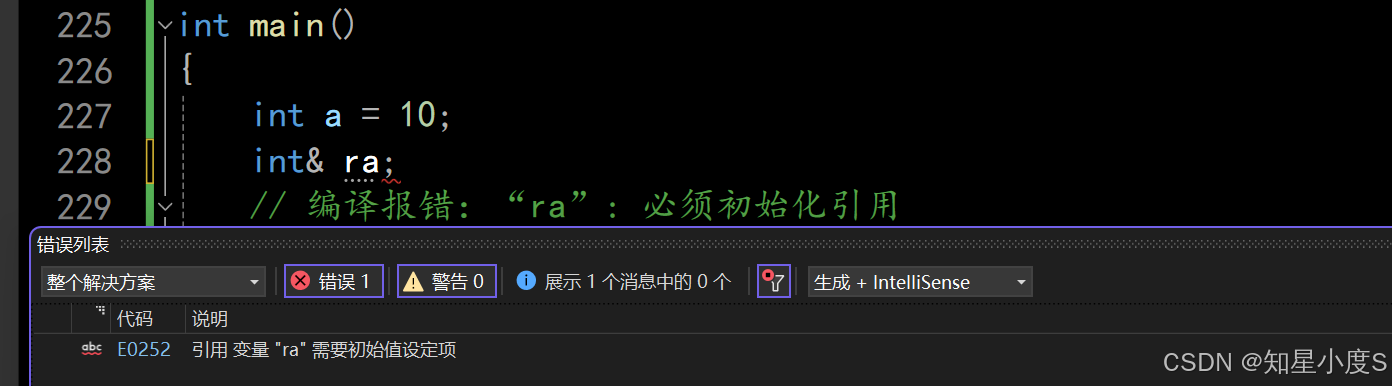
例:
#include<iostream>using namespace std;int main(){int a = 10;//int& ra;// 编译报错:“ra”: 必须初始化引用//正确引用int& b = a;//a,b共用一块内存空间int c = 20;b = c;// 不是让b引用c,因为C++引用不能改变指向// 这里是正常的赋值cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;cout << &a << endl;cout << &b << endl;cout << &c << endl;return 0;}代码结果:
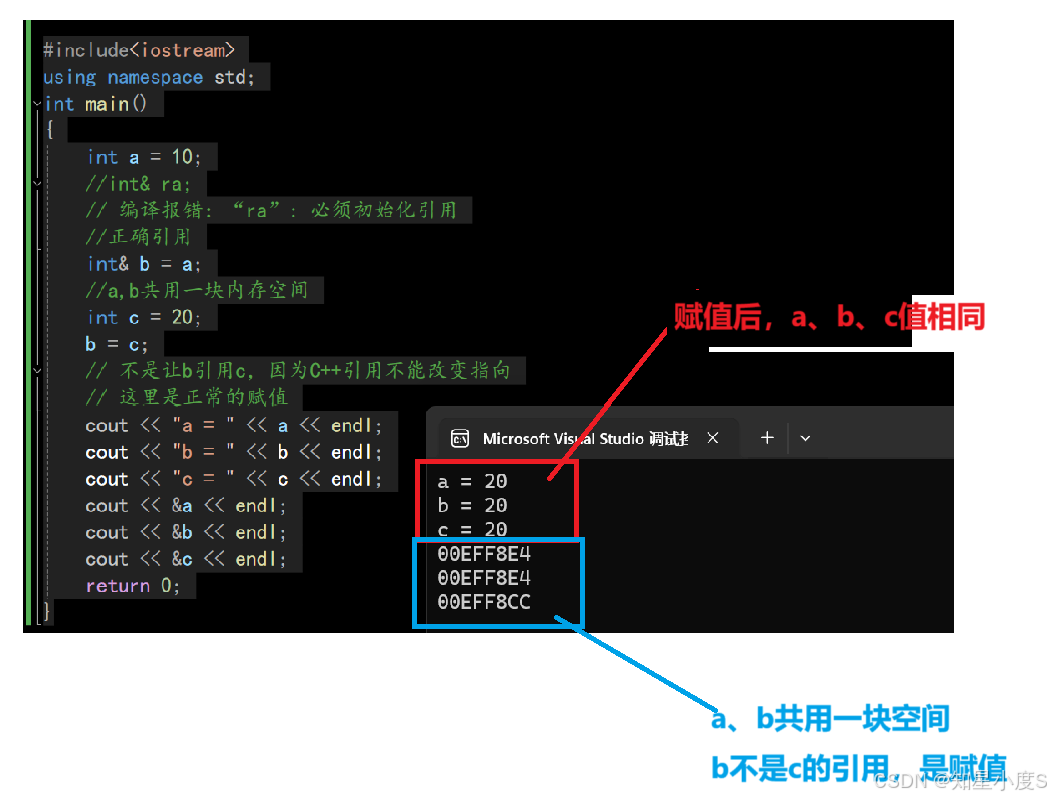
引用的使用
》 引用在实践中主要是于 引用传参 和 引用做返回值 ,这样可以 减少拷贝提高效率 以及 改变引用对象时同时改变被引用对象 。 引用传参跟指针传参功能类似 ,引用传参相对更方便 引用传参:#include<iostream>using namespace std;//引用传参//x,y是a,b的别名void Swap1(int& x, int& y){int tmp = x;x = y;;y = tmp;}//指针版本void Swap2(int* x, int* y){int tmp = *x;*x = *y;*y = tmp;}int main(){int a = 10;int b = 20;Swap1(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;int c = 1;int d = 2;Swap2(&c, &d);cout << "c = " << c << endl;cout << "d = " << d << endl;return 0;}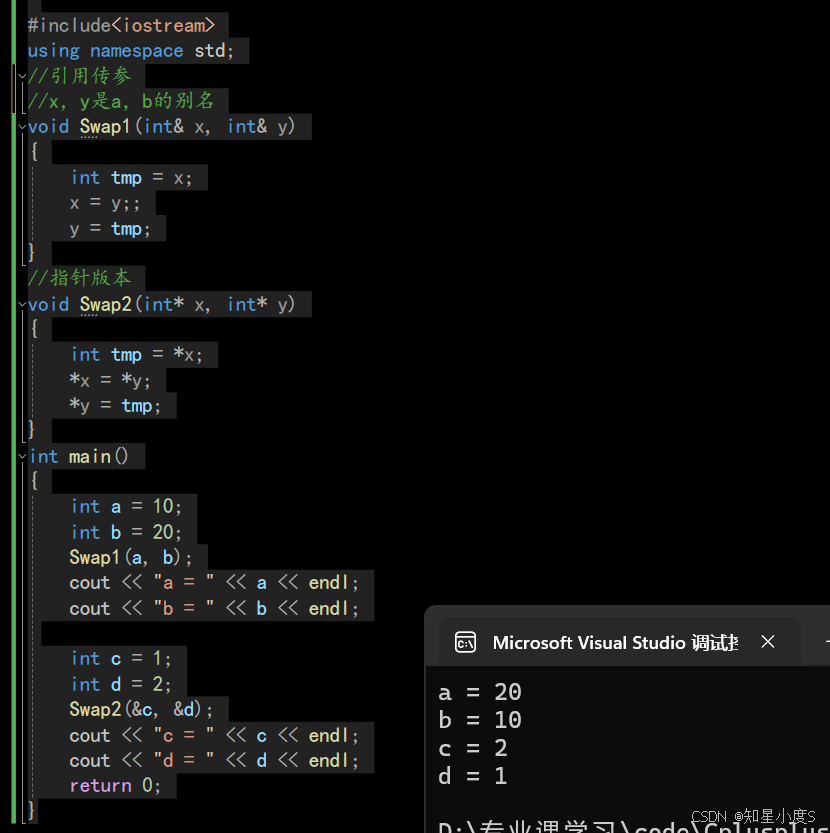
知道了引用,我们来看看下面有趣的代码
#include<iostream>using namespace std;typedef struct ListNode{int val;struct ListNode* next;}LTNode, * PNode;//LTNode就是结构体,这里PNode也就是一个指针变量——LTNode*类型// 指针变量也可以取别名,LTNode*& phead就是给指针变量取别名// 这样就不需要使用二级指针,简化了程序// 转换过程//void ListPushBack(LTNode** phead, int x)//void ListPushBack(LTNode*& phead, int x)void ListPushBack(PNode& phead, int x){PNode newnode = (PNode)malloc(sizeof(LTNode));if (newnode == NULL){perror("malloc fail");exit(1);}newnode->val = x;newnode->next = NULL;if (phead == NULL){phead = newnode;}else{//...}}int main(){PNode plist = NULL;ListPushBack(plist, 1);return 0;}分析:
》LTNode就是结构体,这里PNode也就是一个指针变量——LTNode*类型
》指针变量也可以取别名,LTNode*& phead就是给指针变量取别名
》这样就不需要使用二级指针,简化了程序
》转换过程:
》void ListPushBack(LTNode** phead, int x)
》void ListPushBack(LTNode*& phead, int x)
》void ListPushBack(PNode& phead, int x)
这样使用引用也就方便了很多,这也就是引用的妙处所在~
const引用
》 我们可以 引用⼀个const对象,但是必须用const引用(权限平移) 。 》 const引用也可以引用普通对象(权限缩小)—— 》 对象的 访问权限在引用过程中可以缩小、平移 ,但是 权限不能放大 ,指针也是这样~ 例:#include<iostream>using namespace std;int main(){const int a = 10;//int& ra = a;// 编译报错:error C2440: “初始化”: 无法从“const int”转换为“int &”// 这里引用是对a访问权限的放大//正确写法:权限平移(引用⼀个const对象,必须用const引用)const int& ra = a;//a++;// 编译报错:error C3892: “a”: 不能给常量赋值//ra++;// 编译报错:error C3892: “ra”: 不能给常量赋值//正常的赋值拷贝,不涉及到权限的放大缩小int rra = a;rra++;cout << "a = " << a << endl;cout << "ra = " << ra << endl;cout << "rra = " << rra << endl;int b = 20;const int& rb = b;// 这里引用是对b访问权限的缩小// 编译报错:error C3892: “rb”: 不能给常量赋值//rb++;//rb const修饰b++;//正常,b没有被const修饰cout << "b = " << b << endl;cout << "rb = " << rb << endl;return 0;}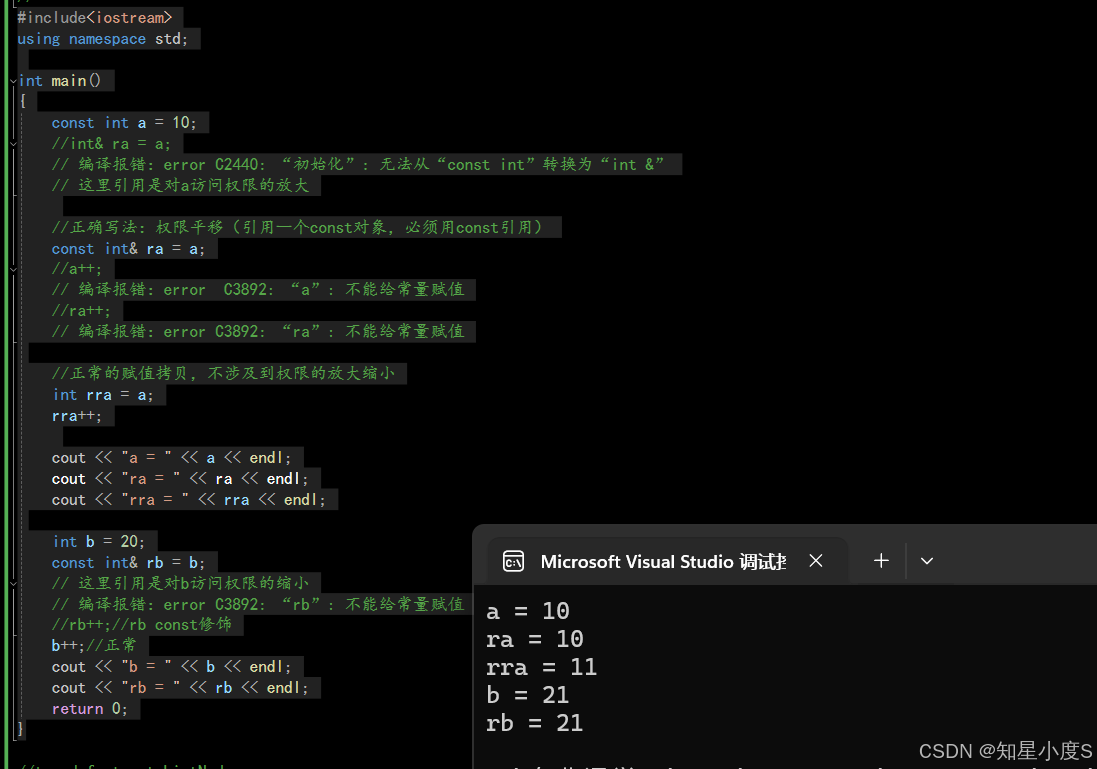
例:
#include<iostream>using namespace std;int main(){int a = 10;const int& ra = 30;// 编译报错: “初始化”: 无法从“int”转换为“int &”//int& rb = a * 3; //(a*3)结果保存在⼀个临时对象中,临时对象具有常性(不能被修改)//正确使用:const修饰const int& rb = a * 3;double d = 12.34;// 编译报错:“初始化”: 无法从“double”转换为“int &”//int& rd = d; //类型转换产生临时对象,临时对象具有常性(不能被修改)//正确使用:const修饰const int& rd = d;//不进行类型转换double& rdd = d;return 0;}指针和引用的关系
》 指针和引用在实践中他们相辅相成,功 能有重叠性,但是各有自己的特点,互相不可替代 》 语法概念上引用是⼀个变量的取别名不开空间; 指针是存储⼀个变量地址,要开空间。 》 引用在定义时必须初始化; 指针建议初始化,语法上不是必须的。 》 引用在初始化时引用⼀个对象后,就不能再引用其他对象; 而指针可以在不断地改变指向对象。 》 引用可以直接访问指向对象; 指针需要解引用才是访问指向对象。 》 sizeof中含义不同,引用结果为引用类型的大小; 指针始终是地址空间所占字节个数(32位平台下占4个字节,64位下是8个字节) 》 指针很容易出现空指针和野指针的问题,引用很少出现,引用使用起来相对更安全⼀些我们来看看下面代码的反汇编:
#include<iostream>using namespace std;int main(){int a = 10;int& ra = a;int b = 100;int* rb = &b;return 0;}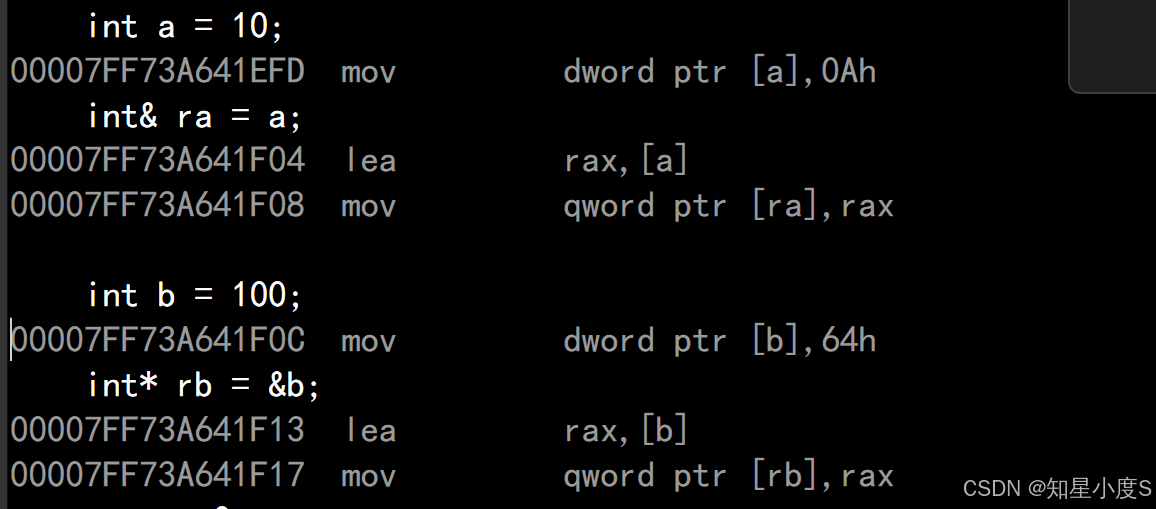
我们可以看到指针和引用汇编层是一样的,所以汇编指令层并没有引用的概念,上层引用的语法,在底层/汇编层依然是指针实现的~
nullptr
在C语言阶段,我们认为空指针是NULL,但是NULL实际是⼀个宏,在传统的C头⽂件(stddef.h)中,可以看到如下代码:
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif#endif#include<iostream>using namespace std;void f(int x){cout << "f(int x)" << endl;}void f(int* ptr){cout << "f(int* ptr)" << endl;}int main(){f(0);//调用f(int x)f(NULL);//我们认为NULL是空指针// 本想通过f(NULL)调用指针版本的f(int*)函数// 但是由于在C++中,NULL被定义成0,调用了f(int x),因此与程序的初衷相悖。 //f((void*)NULL);// 编译报错:error C2665: “f”: 2 个重载中没有⼀个可以转换所有参数类型//正确调用指针版本:f((int*)NULL);//强制类型转换 f(nullptr);//使用特殊关键字nullptr,nullptr可以转换成任意其他类型的指针类型return 0;}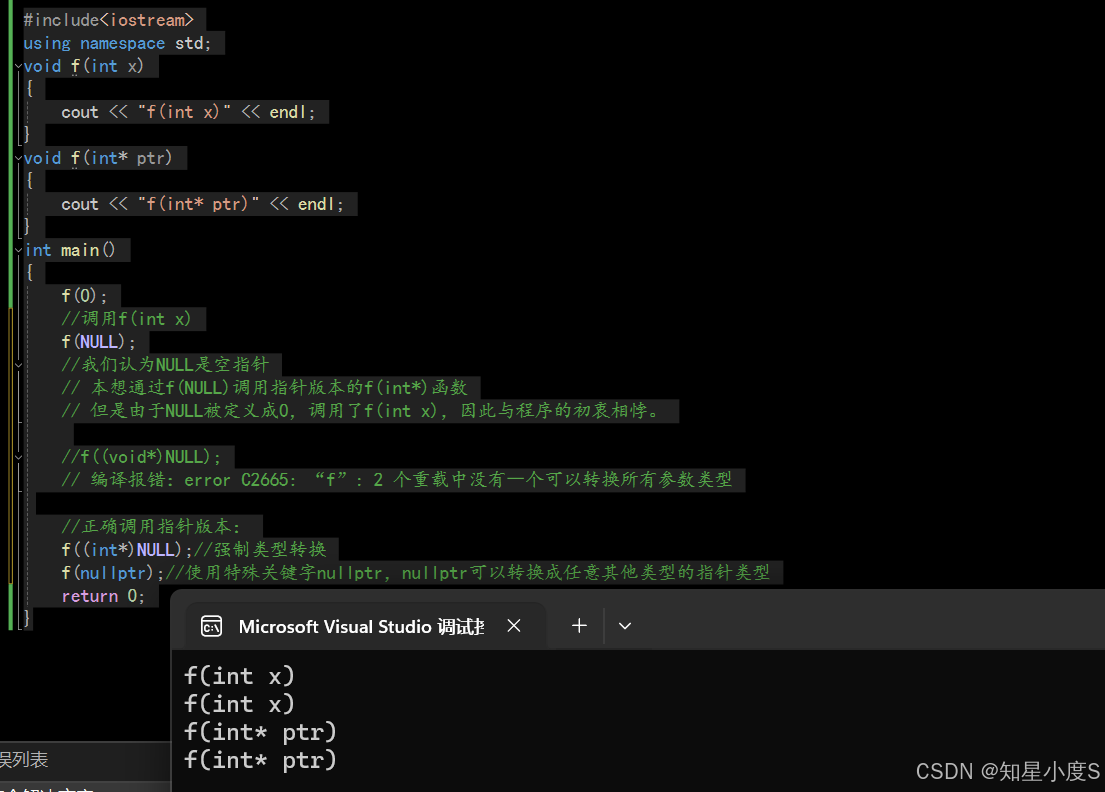
inline
》 使用inline修饰的函数叫做内联函数 ,编译时C++编译器会 在调用函数的地方展开内联函数 ,这样调用内联 函数就 不需要建立栈帧,进而提高效率 。 》 这与我们前面学习的使用宏函数是类似的,我们知道 C语言实现的宏函数也会在预处理进行替换展开 ,但是宏函数实现很复杂很容易出错的,且不方便调 试,C++设计了inline就是为了替代C的宏函数。#include<iostream>using namespace std;//使用宏定义一个函数#define Add1(a,b) ((a)+(b))//不加分号!!避免空语句和编译报错!!//使用宏定义不要舍不得括号,考虑运算符优先级问题inline int Add2(int a, int b){return a + b;}int main(){//1.使用宏函数int ret1 = Add1(2, 3);cout << "a + b = " << ret1 << endl;//预处理进行宏替换//cout << "a + b = " << ((2)+(3)) << endl;//2.使用inline函数int ret2 = Add2(2, 3);cout << "a + b = " << ret2 << endl;return 0;}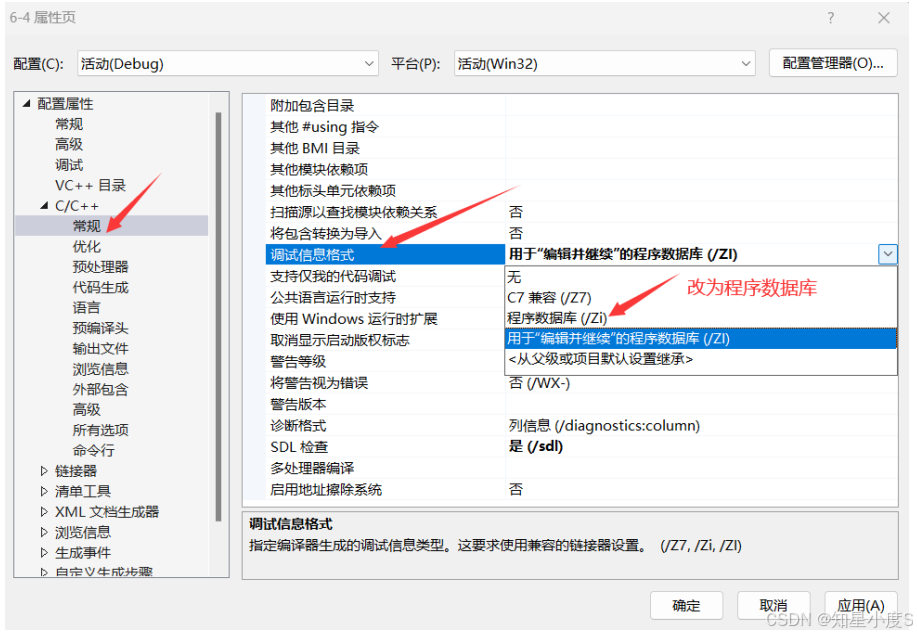
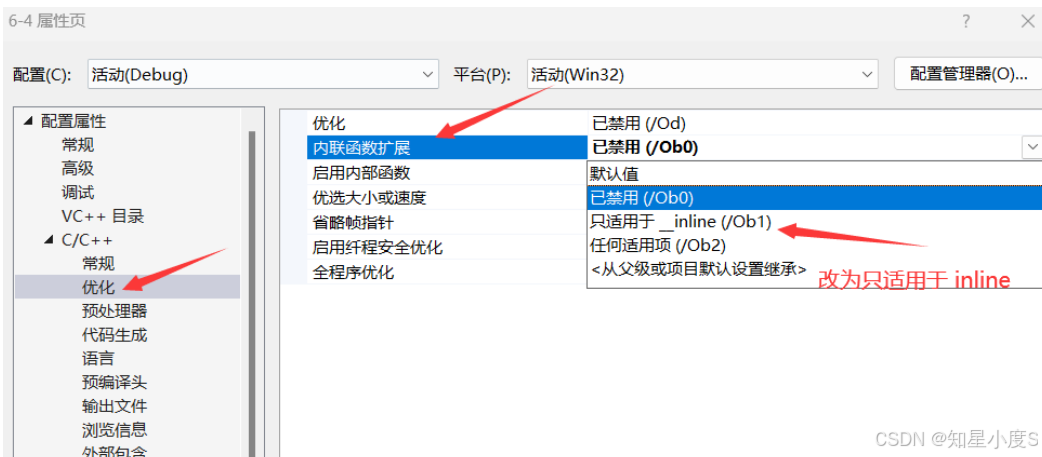 1.我们进行了如果修改,那么反汇编就是下面的样子,没有call Add2语句,就是展开了inline函数~
1.我们进行了如果修改,那么反汇编就是下面的样子,没有call Add2语句,就是展开了inline函数~ 
 2.不进行修改,有call Add2语句,就是没有展开了inline函数,去调用了Add2
2.不进行修改,有call Add2语句,就是没有展开了inline函数,去调用了Add2 
 》 inline不建议声明和定义分离到两个文件 ,分离会导致链接错误,因为inline已经被展开,就没有函数地 址,链接时会出现报错。 例:
》 inline不建议声明和定义分离到两个文件 ,分离会导致链接错误,因为inline已经被展开,就没有函数地 址,链接时会出现报错。 例: // F.h#include <iostream>using namespace std;inline void f(int i);// F.cpp#include "F.h"void f(int i){cout << i << endl;}// main.cpp#include "F.h"int main(){// 链接错误:无法解析的外部符号 "void __cdecl f(int)" (?f@@YAXH@Z)f(100);return 0;} 正确使用:在头文件里面声明定义一起写
正确使用:在头文件里面声明定义一起写 // F.h#include <iostream>using namespace std;inline void f(int i){cout << i << endl;}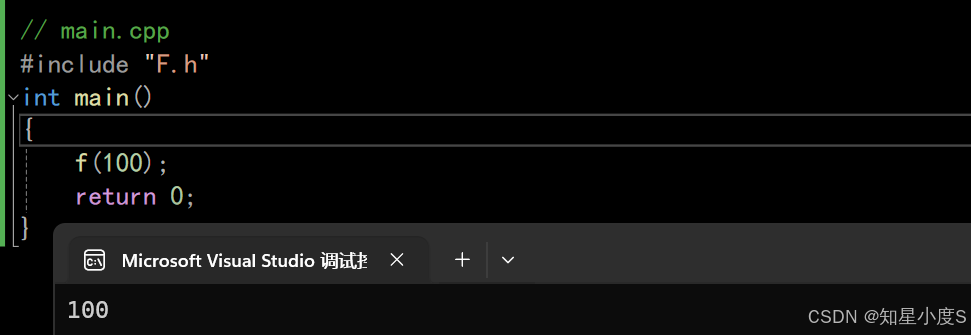
》另外补充一点:
普通函数我们不能在头文件中就进行操作,因为这样当多个cpp文件包含这个头文件,经过预处理就会出现重定义的情况~编译器不知道使用哪一个就会报错~
例:
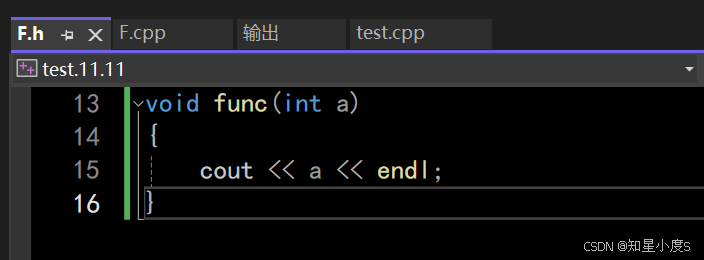
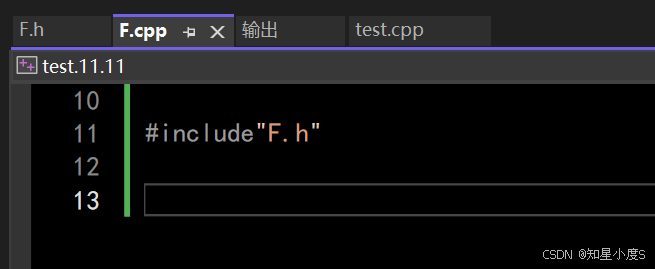
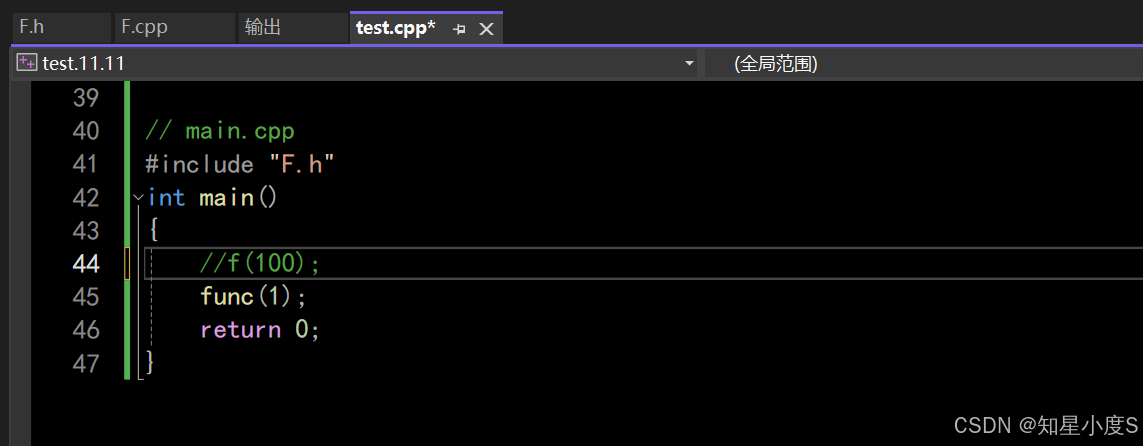

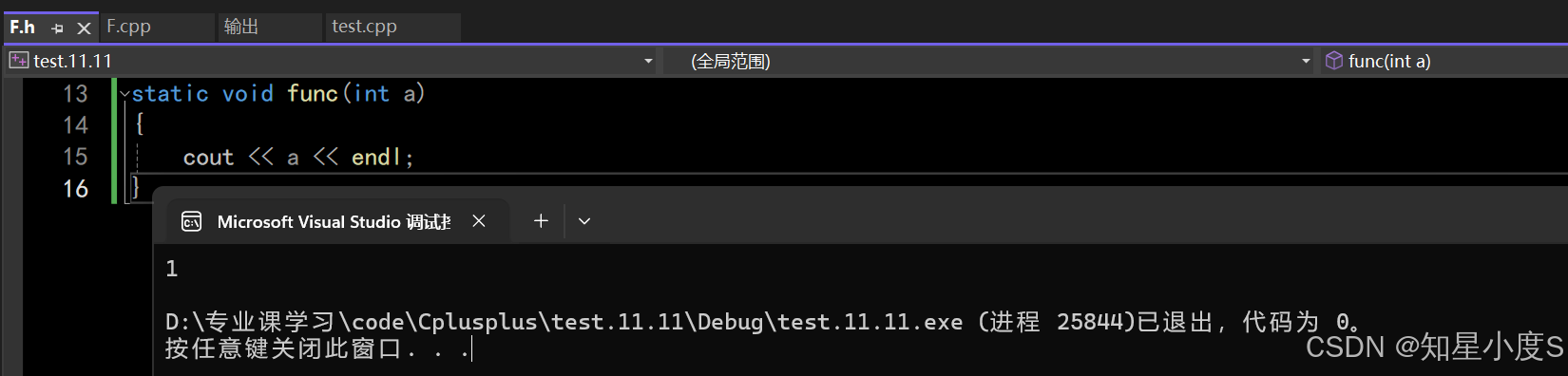
正确使用:使用 static 修饰普通函数
♥♥♥本篇博客内容结束,期待与各位优秀程序员交流,有什么问题请私信♥♥♥
♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥
✨✨✨✨✨✨个人主页✨✨✨✨✨✨