本文将介绍8个常用的Python脚本,帮助你轻松应对Excel的日常操作。那话不多说,开始吧!
1. 安装所需的Python库
在开始之前,我们需要安装一些Python库来操作Excel文件。以下是需要安装的库:
pandas:用于数据处理和分析
openpyxl:读取和写入Excel xlsx/xlsm/xltx/xltm文件
xlrd 和 xlwt:用于读取和写入xls格式的Excel文件
你可以通过以下命令安装这些库:
pip install pandas openpyxl xlrd xlwt 2. 批量修改文件名
场景描述
假设我们有一个文件夹,里面有许多Excel文件,现在需要将这些文件名统一修改为某种格式,以便管理和查找。
详细步骤
导入必要的库
获取文件夹中的所有文件
遍历每个文件,修改文件名
代码示例
import os# 文件夹路径folder_path = 'your_folder_path'# 修改文件名的函数def rename_files(folder_path): for filename in os.listdir(folder_path): if filename.endswith('.xlsx') or filename.endswith('.xls'): new_name = 'new_' + filename os.rename(os.path.join(folder_path, filename), os.path.join(folder_path, new_name)) print("文件名修改完成!")# 执行函数rename_files(folder_path)3. 合并多个Excel文件的数据
场景描述
我们有多个Excel文件,每个文件中都有相同格式的数据表,现在需要将这些数据合并到一个总的Excel文件中。
详细步骤
导入必要的库
获取文件夹中的所有Excel文件
读取每个文件中的数据并合并
将合并后的数据写入一个新的Excel文件
代码示例
import pandas as pdimport os# 文件夹路径folder_path = 'your_folder_path'# 存储合并数据的列表merged_data = []# 合并Excel文件的函数def merge_excel_files(folder_path): for filename in os.listdir(folder_path): if filename.endswith('.xlsx') or filename.endswith('.xls'): file_path = os.path.join(folder_path, filename) data = pd.read_excel(file_path) merged_data.append(data) # 合并所有数据 merged_df = pd.concat(merged_data, ignore_index=True) merged_df.to_excel(os.path.join(folder_path, 'merged_data.xlsx'), index=False) print("数据合并完成!")# 执行函数merge_excel_files(folder_path)4. 读取特定文件夹中的所有Excel文件
场景描述
假设我们有一个文件夹,里面存放了多个Excel文件,现在需要读取每一个文件并进行一定的处理。
详细步骤
导入必要的库
获取文件夹中的所有Excel文件
定义处理每个文件的操作
代码示例
import pandas as pdimport os# 文件夹路径folder_path = 'your_folder_path'# 处理Excel文件的函数def process_excel_files(folder_path): for filename in os.listdir(folder_path): if filename.endswith('.xlsx') or filename.endswith('.xls'): file_path = os.path.join(folder_path, filename) df = pd.read_excel(file_path) # 在这里进行你的处理操作,例如打印数据框的前5行 print(f"Processing {filename}") print(df.head())# 执行函数process_excel_files(folder_path)5. 创建新的Excel文件并写入数据
场景描述
假设我们需要生成一份新的Excel报表,里面包含一些统计数据,并将这份报表保存到指定的文件夹中。
详细步骤
导入必要的库
创建一个DataFrame,填充数据
将DataFrame写入新的Excel文件
代码示例
import pandas as pd# 创建一个DataFramedata = { 'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'City': ['New York', 'Chicago', 'San Francisco']}df = pd.DataFrame(data)# 将DataFrame写入Excel文件output_path = 'your_folder_path/new_report.xlsx'df.to_excel(output_path, index=False)print("新的Excel文件已创建并写入数据!")6. 根据特定条件筛选数据并导出
场景描述
假设我们有一个大的Excel文件,里面包含多个月的销售记录,我们需要筛选出某个月份的数据并导出。
详细步骤
导入必要的库
读取Excel文件
根据条件筛选数据
将筛选后的数据写入新的Excel文件
代码示例
import pandas as pd# 读取Excel文件file_path = 'your_folder_path/sales_data.xlsx'df = pd.read_excel(file_path)# 根据条件筛选数据(筛选月份为2023年5月的记录)filtered_df = df[df['Date'].dt.month == 5]# 将筛选后的数据写入新的Excel文件output_path = 'your_folder_path/filtered_data.xlsx'filtered_df.to_excel(output_path, index=False)print("筛选的数据已导出!")7. 对数据进行排序并保存
场景描述
比如,我们有一份员工工资表,需要按工资从高到低进行排序,并保存结果。
详细步骤
导入必要的库
读取Excel文件
对数据进行排序
将排序后的数据写入新的Excel文件
代码示例
import pandas as pd# 读取Excel文件file_path = 'your_folder_path/salary_data.xlsx'df = pd.read_excel(file_path)# 对数据进行排序(按工资从高到低)sorted_df = df.sort_values(by='Salary', ascending=False)# 将排序后的数据写入新的Excel文件output_path = 'your_folder_path/sorted_salary_data.xlsx'sorted_df.to_excel(output_path, index=False)print("数据已排序并保存!")8. 批量处理Excel数据中的格式问题
场景描述
假设我们有一个文件夹,里面有多个Excel文件,每个文件中都可能存在一些多余的空行,我们需要批量删除这些空行。
详细步骤
导入必要的库
获取文件夹中的所有Excel文件
读取每个文件并删除空行
将处理后的数据重新保存
代码示例
import pandas as pdimport os# 文件夹路径folder_path = 'your_folder_path'# 删除空行的函数def remove_empty_rows(folder_path): for filename in os.listdir(folder_path): if filename.endswith('.xlsx') or filename.endswith('.xls'): file_path = os.path.join(folder_path, filename) df = pd.read_excel(file_path) # 删除空行 df.dropna(how='all', inplace=True) # 保存处理后的文件 df.to_excel(file_path, index=False) print("空行已删除并保存!")# 执行函数remove_empty_rows(folder_path)9. 生成数据透视表和图表
数据透视表和图表是Excel中常用的分析工具,以下脚本示范了如何在Python中生成数据透视表和图表。
场景描述
假设我们有一份销售数据表,现在需要生成一个数据透视表来总结每个月的销售情况,并绘制相应的图表。
详细步骤
导入必要的库
读取Excel文件
创建数据透视表
绘制图表
代码示例
import pandas as pdimport matplotlib.pyplot as plt# 读取Excel文件file_path = 'your_folder_path/sales_data.xlsx'df = pd.read_excel(file_path)# 创建数据透视表(按月份汇总销售额)pivot_table = pd.pivot_table(df, values='Sales', index='Month', aggfunc='sum')# 绘制柱状图pivot_table.plot(kind='bar')plt.xlabel('Month')plt.ylabel('Total Sales')plt.title('Monthly Sales Summary')plt.savefig('your_folder_path/pivot_table_chart.png')plt.show()print("数据透视表和图表已生成!")10. 结论
通过以上8个Python脚本,我们可以极大地简化和自动化日常的Excel操作。从批量修改文件名、合并数据,到格式处理和数据分析,Python都能帮我们轻松应对。
希望这篇文章能启发你在实际工作中更多地应用Python,提高效率。如果你有任何问题或建议,欢迎留言交流。

由于文章篇幅有限,文档资料内容较多,需要这些文档的朋友,可以加小助手微信免费获取,【保证100%免费】,中国人不骗中国人。

**(扫码立即免费领取)**全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
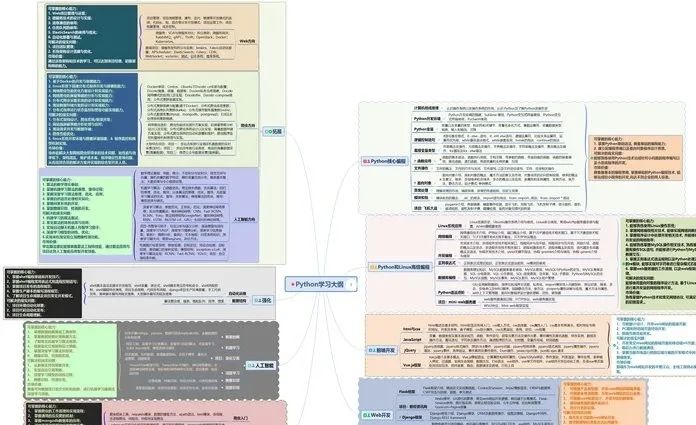

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。