
这张图片展示了一个关于Java程序初始化顺序的单选题。题目是:“以下关于Java程序初始化顺序的描述,正确的是( )”。选项D被标记为正确答案。
选项D的内容是:“父类先于子类进行初始化”。
解释:
在Java中,当创建一个对象时,其构造过程遵循一定的顺序。具体来说,父类的静态代码块和静态变量会首先执行,然后是非静态变量,最后是构造函数。如果存在继承关系,那么父类的构造过程会在子类之前完成。因此,正确的描述是“父类先于子类进行初始化”。

第一个问题是关于类修饰符final和abstract关键字的说法,要求选择不正确的陈述。选项C被标记为正确答案。
abstract和final。选项B: “final关键字可以应用于类,也可以应用于方法” - 这个说法也是正确的,final关键字既可以用于修饰类,表示该类不能被继承;也可以用于修饰方法,表示该方法不能被重写。选项C: “一个方法可以既是abstract又是final” - 这个说法是错误的,因为abstract方法必须有子类实现它,而final方法不允许被重写,所以一个方法不可能同时是abstract和final。选项D: “final关键字应用于方法时,表明任何子类不能重写该方法” - 这个说法是正确的,final方法禁止被子类覆盖。 第二个问题关于Java程序初始化顺序的描述,要求选择不正确的陈述。选项C被标记为正确答案。
选项A: “静态对象先于非静态对象初始化” - 这个说法是正确的,在Java中,静态成员(如静态变量和静态代码块)会在类加载时初始化,而普通成员(非静态)在对象实例化时初始化。选项B: “非静态对象可能会初始化得很慢” - 这个说法也是正确的,非静态对象的初始化速度取决于其构造过程的复杂性。选项C: “父类先于子类进行初始化” - 这个说法是错误的,实际上应该是父类的构造过程在子类之前完成,但这个表述不够准确。选项D: “父类静态代码块先于父类静态变量” - 这个说法是正确的,父类的静态代码块会在父类的静态变量之后执行。总结起来,这两个问题分别考察了对final和abstract关键字的理解以及Java程序初始化顺序的知识点。

这张图片展示了一个关于Java方法重载的单选题。题目是:“关于下列代码说法正确的是( )”,并给出了一个包含三个方法签名的Java类示例:
public class Test { public void a() {} public void a(int i) {} public int a() {}}选项C被标记为正确答案。选项C的内容是:“上述三个a方法是方法重载”。
解释:
在Java中,方法重载是指在一个类中可以有多个同名的方法,只要这些方法具有不同的参数列表即可。参数列表的不同可以通过参数的数量、类型或顺序来区分。
在这个例子中,我们有一个名为Test的类,其中包含了三个名为a的方法。这三个方法的签名如下:
public void a() {}public void a(int i) {}public int a() {} 前两个方法都是void类型的返回值,并且都只有一个参数,但是第二个方法的参数类型是int。第三个方法没有参数,但它的返回类型是int。
由于这些方法的名字相同,但参数列表不同,因此它们构成了方法重载。这意味着在调用a()方法时,编译器将根据传递给方法的实际参数来决定调用哪个版本的a()方法。
综上所述,选项C的描述是正确的,即这三种情况下的a()方法确实是方法重载的例子。

这张图片展示了一道关于Java语句的单选题,题目问的是“以下关于Java语句,描述不正确的是( )”,并且提供了四个选项供选择。选项B被标记为正确答案。
让我们逐一分析每个选项:
A. assert是断言,用于进行程序调试。
解释:assert是一个Java的关键字,用于插入断言语句到程序中。当assert后面的表达式计算结果为false时,程序会抛出AssertionError异常。主要用于开发阶段的测试和调试目的。B. continue用来提前跳出一个块。
解释:continue并不是用来跳出整个块的,而是跳过当前循环体内的剩余部分,直接进入下一次迭代。因此,这个描述是不正确的。C. final用来说明最终属性。
解释:final是一个Java的关键字,它可以用于修饰类、方法和变量。对于变量而言,一旦被声明为final,就不能再改变其值。因此,这个描述是正确的。D. catch用来捕获异常。
解释:catch是try-catch结构的一部分,用于处理可能发生的异常。当try块内发生异常时,控制权会被转移到匹配的catch块中,从而允许程序员编写特定的代码来处理该异常。因此,这个描述是正确的。综上所述,选项B的描述是不正确的,因为它误解了continue的作用。其他选项的描述都是正确的。

这张图片展示了一个关于Java异常类的单选题。题目是:“以下关于异常类的描述,不正确的是( )。选项D被标记为正确答案。
选项D的内容是:“Exception也称为致命性异常类。”
解释:
在Java中,异常分为两大类:Error和Exception。Error通常是系统级别的严重错误,比如虚拟机错误(VirtualMachineError),这类错误通常是由JVM自身的问题引起的,程序本身无法处理这种错误。
Exception则是程序运行时可能出现的各种异常情况,例如空指针异常(NullPointerException)、数组越界异常(ArrayIndexOutOfBoundsException)等。这些异常是可以被捕获和处理的,通过使用try-catch语句可以在程序中处理这些异常。
因此,选项D的描述是不正确的,因为Exception并不被称为“致命性异常类”。相反,Error才是那些可能导致程序崩溃的严重错误。

这张图片展示了一个关于Java异常捕获机制的单选题。题目是:“以下关于异常捕获机制的描述,正确的是( )”。选项D被标记为正确答案。
选项D的内容是:“catch子句后如果没有一个语句,可以不使用花括号开始和结束。”
解释:
在Java中,try-catch-finally语句块是用来处理异常的一种方式。try块包含可能引发异常的代码,catch块用于捕获并处理从try块抛出的异常,finally块则无论是否发生异常都会被执行。
对于catch子句,如果只有一条语句,那么可以省略花括号。也就是说,如果catch块里只有一个语句,可以直接写在catch后面,不需要使用大括号包围。例如:
try { // 可能抛出异常的代码} catch (IOException e) { System.out.println("An IOException occurred.");}在这种情况下,即使catch块里只有一个输出语句,也不需要使用大括号。这就是为什么选项D被认为是正确的描述。

题目是:“设i, j, k, l均为int型的变量,并已赋值,下列表达式的结果属于非逻辑值的是( )。”选项C被标记为正确答案。
选项C的内容是:“++i * j + ++k”。
解释:
在Java中,运算符++是一个自增操作符,它可以放在变量前面(前缀形式)或后面(后缀形式)。前缀形式++x会立即增加变量x的值,而后缀形式x++则会先使用x的原始值,然后再增加x的值。
在这个表达式中,++i和++k都是前缀形式的自增操作符,意味着它们会立即增加i和k的值。因此,这个表达式的结果将是i、j和k的某个组合的乘积加上另一个数,而不是一个布尔值或逻辑值。
相比之下,其他选项涉及的操作要么是赋值(=, +=),要么是比较(>),要么是逻辑运算(!=, &%),这些都会产生逻辑值或布尔值作为结果。只有选项C的结果不属于逻辑值范畴。

这张图片展示了一个关于Java文件命名规则的选择题。题目要求阅读给出的代码段,并选出正确的文件名。
代码段如下:
class Student{ void method1(){ ... }}public class Teacher{ void method2(){ ... } public static void main(String[] args){ System.out.println("main()"); }}根据Java的命名约定,源代码文件应该以.java结尾,并且文件名应与公共类(public class)的名称保持一致。在这段代码中,有两个类:Student和Teacher。然而,只有Teacher是公共类(public class),因此对应的源代码文件名应该是Teacher.java。
选项C被标记为正确答案,即Teacher.java。这是因为Teacher是这段代码中的公共类,符合Java文件命名规则的要求。

题目要求分析以下程序段的输出结果:
String Seq_1 = "abc" + "def";String Seq_2 = new String(Seq_1);if (Seq_1.equals(Seq_2)) { System.out.println("equals()");}if (Seq_1 == Seq_2) { System.out.println("==");}我们需要分别分析 equals() 和 == 的比较结果。
equals() 比较:
equals() 方法用于比较两个字符串的内容是否相等。在本例中,Seq_1 和 Seq_2 都是 "abcdef",因此它们的内容相同。因此,Seq_1.equals(Seq_2) 为 true,会输出 "equals()"。 == 比较:
== 运算符用于比较两个对象的引用是否指向同一个内存地址。在本例中,Seq_1 是通过字符串字面量拼接得到的,而 Seq_2 是通过 new String(Seq_1) 创建的新对象。这意味着 Seq_1 和 Seq_2 虽然内容相同,但它们在内存中的位置不同。因此,Seq_1 == Seq_2 为 false,不会输出任何内容。 综上所述,程序的输出结果只有 "equals()"。
所以正确答案是:D. 输出为 equals()
Java中的类、接口以及继承的概念。
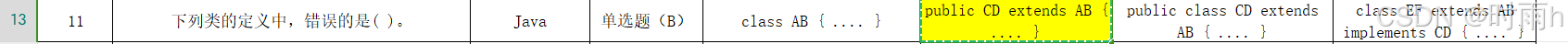
这道题考察的是Java类和继承的相关知识。我们来逐一分析每个选项:
A. public class CD extends AB { ... }
CD 继承自类 AB。这是正确的语法结构。 B. class EF implements AB { ... }
EF 实现接口 AB。然而,在Java中,extends 关键字用于实现类之间的继承关系,而不是实现接口。如果要实现接口,应该使用 implements 关键字。因此,这个定义是错误的 C. public class CD extends AB { ... }
CD 继承自类 AB。这也是正确的语法结构。 D. class EF extends AB { ... }
EF 继承自类 AB。这也是正确的语法结构。 综上所述,选项 B 中的定义是错误的,因为它试图用 extends 来实现接口,而实际上应该是用 implements。因此,正确答案是 B。
Java中的类、接口以及继承的概念。
类(Class)
在面向对象编程中,类是一种创建对象的蓝图。它封装了数据成员(属性)和成员方法(行为)。例如:
public class Car { // 属性 private String brand; private int year; // 构造器 public Car(String brand, int year) { this.brand = brand; this.year = year; } // 行为 public void drive() { System.out.println("The car is driving."); }}接口(Interface)
接口是一种完全抽象的类,它只包含常量和抽象方法。在Java中,一个类可以通过实现接口来获得特定的行为。接口主要用于定义一组行为规范,而不关心这些行为的具体实现。例如:
public interface Flyable { void fly();}继承(Inheritance)
继承是面向对象编程的一个重要特性,它允许一个类(子类)继承另一个类(父类)的方法和属性。这样可以提高代码的复用性和可维护性。在Java中,使用 extends 关键字来实现继承。例如:
public class Animal { public void eat() { System.out.println("This animal eats food."); }}public class Dog extends Animal { public void bark() { System.out.println("The dog barks."); }}实现接口(Implementing Interfaces)
一个类可以通过使用 implements 关键字来实现一个或多个接口。实现接口时,类必须提供接口中所有抽象方法的具体实现。例如:
public class Bird extends Animal implements Flyable { @Override public void fly() { System.out.println("The bird can fly."); } public void sing() { System.out.println("The bird sings."); }}多重继承与接口
多重继承:Java 不支持一个类直接从多个类继承。也就是说,一个类只能有一个直接的父类。多重接口实现:但是,一个类可以实现多个接口。例如:public interface Swimmable { void swim();}public class Duck extends Animal implements Flyable, Swimmable { @Override public void fly() { System.out.println("The duck can fly."); } @Override public void swim() { System.out.println("The duck can swim."); } public void quack() { System.out.println("The duck quacks."); }}总结
extends 关键字用于类之间的单继承,一个类只能继承一个父类。implements 关键字用于类实现接口,一个类可以实现多个接口。Java 不支持多继承,但允许类实现多个接口,以达到类似的效果。 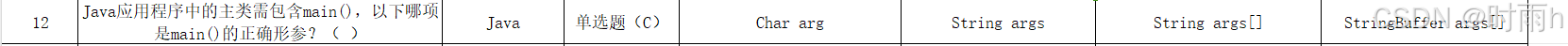
Java应用程序的主类需要包含一个名为main的方法,该方法作为程序执行的入口点。main方法的签名如下所示:
public static void main(String[] args)其中:
public:表明这是一个公共方法,可以从其他包访问。static:表明这是一个静态方法,可以直接通过类名调用,不需要实例化对象。void:表明该方法没有返回值。String[] args:是一个字符串数组参数,用于接收命令行传入的参数。 根据上述描述,我们可以看到main方法的形参部分应为String[] args。因此,正确答案是:
String args[] 其他选项不正确的原因如下:
A.Char arg:arg不是数组形式,并且类型为Char而非String。B. String args:缺少数组符号[]。D. StringBuffer args[]:虽然包含了数组符号[],但类型为StringBuffer而非String。 综上所述,正确答案是C。

Java Application源程序的主类是指包含有main()方法的类。这是因为main()方法是Java应用程序的入口点,当运行Java应用程序时,JVM首先查找并执行main()方法。
在这个表格中,选项B是main(),它是Java应用程序的主方法。因此,正确答案是B。

这段代码展示了如何使用不同的构造函数来创建A类的对象。A类有两个构造函数,一个是接受一个int类型的参数,另一个是接受两个int类型的参数。在Java中,当我们想要创建一个新的对象时,我们必须使用new关键字,然后跟着类的名字和括号内的参数列表。如果我们尝试使用一个不存在的构造函数或者使用错误的数据类型,那么编译器就会报错。在这四个选项中,第一个选项A a = new A("lpf");是不正确的,因为A类并没有一个接受String类型参数的构造函数。所以,正确答案是B。
这段代码展示了一个名为A的类,它具有三个构造函数:
String类型的参数。第二个构造函数接受一个int类型的参数。第三个构造函数接受两个int类型的参数。 在Java中,当我们想要创建一个新的对象时,我们必须使用new关键字,然后跟着类的名字和括号内的参数列表。如果我们尝试使用一个不存在的构造函数或者使用错误的数据类型,那么编译器就会报错。
在这四个选项中:
第一个选项A a = new A("lpf");是不正确的,因为A类并没有一个接受String类型参数的构造函数。第二个选项A a = new A();是正确的,因为A类有一个无参构造函数。第三个选项A a = new A(4);是正确的,因为A类有一个接受一个int类型参数的构造函数。第四个选项A a = new A(1,2);也是正确的,因为A类有一个接受两个int类型参数的构造函数。 因此,正确答案是B。

在Java中,类的继承有一些重要的规则和限制。其中一个关键点就是单一继承原则,即一个类只能有一个直接的超类(父类),不能同时继承多个类。这就是为什么选项D“在Java中类只允许单一继承”是正确的。
另一方面,Java允许一个类实现多个接口,这就提供了某种程度上的多重继承的能力。因此,选项A“在Java中一个类不能同时继承一个类和实现一个接口”的说法是不准确的。
此外,Java中的接口确实只允许单一继承,也就是一个接口只能扩展一个其他的接口。所以,选项C“在Java中接口只允许单一继承”也是正确的。
最后,选项B“在Java中一个类只能实现一个接口”是不正确的,因为在Java中,一个类可以实现多个接口。
总结来说,关于类的继承属性叙述正确的是选项D:“在Java中类只允许单一继承”。
异常类型

在Java中,IOException是一个非常常见的异常类型,通常发生在输入/输出操作过程中出现问题的时候。比如文件读写失败,网络连接中断等等。由于网络通信本质上也是一种I/O操作,所以网络相关的问题也可能导致IOException的发生。
ClassNotFoundException是在加载类的过程中发生的异常,通常是找不到指定的类文件。FileNotFoundException则是在打开文件进行读取或写入操作时,发现文件不存在的情况下抛出的异常。
UnknownHostException是在处理网络请求时遇到的一种特殊情况,通常是因为无法找到对应的主机名。这种情况下,系统会抛出UnknownHostException异常。
所以,对于这个问题,最有可能由网络原因引起的异常是IOException。因此,正确答案是D。
在Java中,异常处理是非常重要的一部分,它可以用来捕获和处理程序运行期间可能出现的各种错误情况。Java中有两种类型的异常:检查型异常和非检查型异常。
检查型异常包括所有的Exception类及其子类,除了RuntimeException及其子类之外的所有异常都属于这一类。这类异常的特点是编译器会在编译阶段就对其进行检查,如果没有妥善处理,编译将无法通过。例如,IOException就是一个典型的检查型异常。
非检查型异常主要包括RuntimeException及其子类,如NullPointerException、ArrayIndexOutOfBoundsException等。这类异常的特点是编译器不会对其做任何检查,即使没有处理也不会影响到程序的编译过程。一般来说,这类异常都是由于程序员的疏忽造成的逻辑错误,所以在编写代码时应当尽量避免出现这样的异常。
在实际开发中,我们应该合理利用异常机制,对可能发生的异常情况进行预判和处理,从而提升程序的健壮性和稳定性。

在Java语言中,try-catch-finally语句块是用来处理异常的。try语句块后可以存在不限数量的catch语句块,每个catch语句块都会捕获一种特定类型的异常。finally语句块则是无论是否有异常发生都会被执行的部分,通常用于释放资源等操作。所以,选项B"try语句块后可以存在不限数量的catch语句块"是正确的。
抽象类

**在Java中,抽象类是一种特殊的类,它的主要特点是不能被实例化。**换句话说,你不能创建一个抽象类的对象。这是因为抽象类的设计目的是为了提供一个模板或者基类,供其他具体的类去继承和实现其功能。
抽象类的关键字是abstract,并且可以在声明类的同时声明其为抽象类,也可以在类内部声明某个方法为抽象方法。抽象方法是没有具体实现的,只是给出了一个方法的声明,具体的实现留给子类去完成。
抽象类的主要用途在于提供了一种设计模式,使得开发者能够定义一些通用的功能,然后由具体的子类去实现这些功能。这种方式有助于代码的复用和模块化,提高了软件的灵活性和可维护性。
需要注意的是,尽管抽象类不能被实例化,但它仍然可以拥有构造函数。这是因为抽象类可能会被其他类所继承,而构造函数正是用于初始化对象状态的。不过,由于抽象类本身不能生成对象,所以它的构造函数并不会真正执行,而是由子类在创建对象时调用。
总的来说,抽象类是Java中非常重要的一种概念,它为面向对象编程提供了一种强大的工具,可以帮助我们更好地组织和管理代码。
在Java中,抽象类和接口都可以用来定义一组方法,但它们之间还是有很多区别的。
抽象类可以有构造函数,而接口不可以。抽象类可以有字段,而接口不可以。抽象类可以有非抽象方法,而接口中的方法默认都是抽象的。一个类只能继承一个抽象类,但可以实现多个接口。在Java 8之前,接口中的方法必须是抽象的,但从Java 8开始,接口可以有默认方法和静态方法。抽象类和接口的选择取决于你的需求。如果你想定义一个模板类,其中的一些方法已经被实现了,那么你应该选择抽象类。如果你想定义一组方法,这些方法将在多个不相关的类中实现,那么你应该选择接口。
另外,Java还有一种特殊的类叫做枚举类,它既是一种特殊的类,也是一种特殊的接口。枚举类可以有自己的方法和字段,而且它隐式地继承了Enum接口。

在Java中,default关键字用于switch语句中表示默认分支,这是正确的。import关键字用于导入类或者包,这也是正确的。super关键字用于引用当前对象的父类,这同样是正确的。
然而,extends关键字不仅可以作用于类,还可以作用于接口在Java中,一个类可以继承一个类并实现多个接口。因此,选项B “extends只能作用于类,不能作用于接口” 是错误的。所以,正确答案应该是B。
堆 队列数据存储

**在Java虚拟机中,Java堆是所有线程共享的一块内存区域,主要用于存放对象实例。每当创建新对象时,Java虚拟机会从堆中分配一块内存给这个对象。**因此,Java堆是所有线程共享的数据区。所以,正确答案是A。
在Java虚拟机(JVM)中,内存被划分为几个不同的区域,每种区域都有自己的用途。以下是这些区域的基本概述:
程序计数器:是一块较小的内存空间,用于记录当前线程正在执行哪条指令。如果线程正在执行的是本地方法,则PC寄存器的值为空。
Java栈:每个线程都有自己独立的Java栈,用于保存局部变量、方法参数以及方法调用的状态信息。当线程调用一个方法时,JVM会为这个方法创建一个新的栈帧(stack frame),并将它压入栈顶;当方法结束时,JVM会弹出这个栈帧。
本地方法栈:与Java栈类似,但是专门用于保存本地方法的调用状态。在HotSpot VM中,本地方法栈和Java栈合二为一。
Java堆(heap):是所有线程共享的一块内存区域,用于存放对象实例。每当创建新对象时,JVM会从堆中分配一块内存给这个对象。垃圾回收器(Garbage Collector)负责清理不再使用的对象以释放内存空间。
方法区(method area):也称为永久代(permanent generation),用于存放已加载类的信息、常量池、静态变量等数据。在HotSpot VM中,这部分内存被称为元空间(metaspace)。
直接内存(direct memory):不属于Java堆或方法区,而是由NIO库分配的内存区域。这部分内存不在JVM的管理范围内,因此不受垃圾回收的影响。
在Java虚拟机中,Java堆是最核心的一个内存区域,因为它存储着所有对象的实例。Java堆是由所有线程共享的,这意味着所有线程都可以访问堆中的对象。Java堆的大小可以通过JVM启动参数来设置,例如 -Xms 和 -Xmx 参数分别用于设置初始堆大小和最大堆大小。
Java堆被进一步细分为新生代(new generation)和老年代(old generation)两部分。新生代又分为Eden区和Survivor区(S0和S1)。大部分对象都在新生代中创建,只有经过多次垃圾收集后依然存活的对象才会被移动到老年代。这样做的好处是可以提高垃圾收集效率,因为大多数对象在其生命周期内会被快速回收掉。
当新生代的空间不足时,会发生一次Minor GC(minor garbage collection),仅清理新生代中的对象。如果老年代也满了,那么会触发Full GC(full garbage collection),清理整个堆空间。Full GC通常比Minor GC耗时更长,因为它涉及到更多的对象。
除了Java堆外,还有其他一些重要的内存区域:
程序计数器(Program Counter Register): 每个线程都有一个独立的程序计数器,用于指示当前线程正在执行的字节码指令的位置。
Java栈(Stack): 同样是每个线程私有的,用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每次方法调用都会在线程的Java栈中创建一个新的栈帧(frame),用于保存该方法的相关信息。
方法区(Method Area): 存储已被加载的类信息、常量、静态变量、即时编译器产生的代码缓存等数据。在HotSpot VM中,这部分内存被称为Metaspace。
直接内存(Direct Memory): 不受Java堆大小限制,由Native方法直接申请的内存空间。主要用于NIO操作的大缓冲区。
了解这些内存区域的工作原理对于理解和解决Java应用程序中的性能问题至关重要。

Java虚拟机(JVM)的核心组件包括类加载器、字节码校验器、解释器、即时编译器(JIT)、垃圾回收器等。类加载器负责加载.class文件,字节码校验器验证字节码是否合法,解释器逐行解释执行字节码,即时编译器将热点代码编译成本地机器码以提高执行速度,垃圾回收器自动回收不再使用的对象占用的内存。而码流分析器并不是JVM的标准组成部分,因此选C。
Java虚拟机(JVM)是一个抽象计算机,它位于硬件平台和操作系统之上,为Java程序提供了一个统一的运行环境。JVM的主要任务是将Java字节码转换成目标机器的具体指令,并且保证Java程序能够在各种平台上正常运行。
JVM的构成主要有以下几个部分:
类加载器(Class Loader):负责加载Java类文件到JVM中。JVM支持多种类加载器,包括引导类加载器、扩展类加载器和应用程序类加载器等。
字节码校验器(Bytecode Verifier):在类加载完成后,会对字节码进行校验,确保其符合Java语言规范,防止恶意代码的攻击。
解释器(Interpreter):负责解释执行字节码。解释器的优点是跨平台性强,缺点是执行效率较低。
即时编译器(Just-In-Time Compiler,简称JIT):在程序运行过程中,将频繁执行的热点代码编译成本地机器码,以提高执行效率。
垃圾回收器(Garbage Collector):负责自动回收不再使用的对象占用的内存空间,减轻程序员手动管理内存的压力。
运行时常量池(Runtime Constant Pool):用于存储类结构信息,如字段描述符、方法符号引用等。
内存管理器(Memory Manager):负责管理JVM的内存空间,包括堆、栈、方法区等。
线程调度器(Thread Scheduler):负责调度JVM中的多线程并发执行。
安全管理器(Security Manager):提供安全策略,保护Java程序免受非法访问和其他潜在威胁。
调试器(Debugger):提供调试功能,帮助开发者查找和修复程序中的bug。
综上所述,码流分析器并不是JVM的标准组成部分,因此选C。
Java虚拟机(JVM)是一个抽象的概念,它是Java程序的运行环境。JVM的主要职责是将Java字节码转换为机器码并在不同平台上运行。JVM包含许多组件,每个组件都有其独特的功能。
类加载器(Class Loader):负责加载Java类文件到JVM中。JVM支持多种类加载器,包括引导类加载器、扩展类加载器和应用程序类加载器等。
字节码校验器(Bytecode Verifier):在类加载完成后,会对字节码进行校验,确保其符合Java语言规范,防止恶意代码的攻击。
解释器(Interpreter):负责解释执行字节码。解释器的优点是跨平台性强,缺点是执行效率较低。
即时编译器(Just-In-Time Compiler,简称JIT):在程序运行过程中,将频繁执行的热点代码编译成本地机器码,以提高执行效率。
垃圾回收器(Garbage Collector):负责自动回收不再使用的对象占用的内存空间,减轻程序员手动管理内存的压力。
运行时常量池(Runtime Constant Pool):用于存储类结构信息,如字段描述符、方法符号引用等。
内存管理器(Memory Manager):负责管理JVM的内存空间,包括堆、栈、方法区等。
线程调度器(Thread Scheduler):负责调度JVM中的多线程并发执行。
安全管理器(Security Manager):提供安全策略,保护Java程序免受非法访问和其他潜在威胁。
调试器(Debugger):提供调试功能,帮助开发者查找和修复程序中的bug。
综上所述,码流分析器并不是JVM的标准组成部分,因此选C。
java执行过程

Java程序的执行流程大致如下:
编写源代码:首先,你需要使用文本编辑器或者其他IDE(集成开发环境)编写Java源代码。
编译:然后,你需要使用Java编译器(javac)将源代码编译成字节码。字节码是一种中间格式,它不是针对特定的操作系统或处理器架构的,而是针对Java虚拟机(JVM)的。
加载:接下来,JVM会加载字节码。在这个过程中,JVM会检查字节码的有效性,确保它遵循Java语言的规则。
执行:最后,JVM会执行字节码。在这个过程中,JVM会将字节码翻译成机器码,然后让CPU执行这些机器码。
注意,上述步骤并不总是按顺序进行的。例如,在某些情况下,JVM可能会在执行字节码的过程中将其编译成机器码,而不是先完全加载再执行。这种技术称为“即时编译”(Just In Time, JIT)。此外,JVM也可能在执行字节码的过程中对其进行优化,以便更快地执行。
至于为什么Java编译器会将代码源转换为字节码而不是直接转换为机器代码,原因有两个:一是字节码是与平台无关的,这意味着同一个Java程序可以在任何安装了JVM的平台上运行,这就是所谓的“一次编写,到处运行”的理念;二是字节码提供了额外的安全层,因为在加载字节码的时候,JVM可以检查它是否遵守Java语言的规则,从而防止恶意代码的执行
Java程序的执行流程大致如下:
编写源代码:首先,你需要使用文本编辑器或者其他IDE(集成开发环境)编写Java源代码。
编译:然后,你需要使用Java编译器(javac)将源代码编译成字节码。字节码是一种中间格式,它不是针对特定的操作系统或处理器架构的,而是针对Java虚拟机(JVM)的。
加载:接下来,JVM会加载字节码。在这个过程中,JVM会检查字节码的有效性,确保它遵循Java语言的规则。
执行:最后,JVM会执行字节码。在这个过程中,JVM会将字节码翻译成机器码,然后让CPU执行这些机器码。
注意,上述步骤并不总是按顺序进行的。例如,在某些情况下,JVM可能会在执行字节码的过程中将其编译成机器码,而不是先完全加载再执行。这种技术称为“即时编译”(Just In Time, JIT)。此外,JVM也可能在执行字节码的过程中对其进行优化,以便更快地执行。
至于为什么Java编译器会将代码源转换为字节码而不是直接转换为机器代码,原因有两个:一是字节码是与平台无关的,这意味着同一个Java程序可以在任何安装了JVM的平台上运行,这就是所谓的“一次编写,到处运行”的理念;二是字节码提供了额外的安全层,因为在加载字节码的时候,JVM可以检查它是否遵守Java语言的规则,从而防止恶意代码的执行。
默认值

在Java中,如果你没有明确初始化一个成员变量,那么它的值将会根据其类型得到一个默认值。具体来说:
对于基本类型的成员变量:
byte, short, int, long 的默认值是 0float, double 的默认值是 0.0char 的默认值是 \u0000 (即空字符)boolean 的默认值是 false 对于引用类型的成员变量,默认值是 null。
所以,题目中的选项 A (byte 的默认值是 0),B (boolean 的默认值是 false),D (char 类型的默认值是 '\'\u0000' 或者 '\0') 都是正确的。
但是,选项 C (long 类型的默认值是 0.0L) 是错误的。实际上,long 类型的默认值应该是 0L,而不是 0.0L。0.0L 是 double 类型的默认值。
因此,正确答案是 C。
在Java中,所有的变量都必须有一个确定的值。这就意味着,即使你没有显式地初始化一个变量,Java也会为你做这件事。这就是我们所说的“默认初始化”。
对于基本类型,它们的默认值取决于它们的类型:
整数类型(byte, short, int, long)的默认值都是0。浮点类型(float, double)的默认值分别是0.0f和0.0d。布尔类型(boolean)的默认值是false。字符类型(char)的默认值是\u0000,也就是Unicode编码的空字符。 对于引用类型,它们的默认值是null。这是因为引用类型实际上是对象的地址,如果没有指定具体的对象,那么就认为是没有指向任何对象,也就是null。
需要注意的是,这里的默认值只适用于类的成员变量。如果是局部变量(比如函数内部定义的变量),则需要显式初始化,否则编译器会报错。
确实如此。在Java中,局部变量不会像类的成员变量那样获得默认值。当你声明一个局部变量但未赋初值时,编译器会要求你在使用前为其赋值。这是为了防止由于意外的默认值导致的逻辑错误。
例如,以下代码会导致编译错误:
public class Test { public void testMethod() { int i; // 局部变量i未赋值 System.out.println(i); // 编译错误: 变量可能尚未初始化 }}要避免这个问题,你可以这样做:
public class Test { public void testMethod() { int i = 0; // 显式初始化局部变量i System.out.println(i); }}或者
public class Test { public void testMethod() { int i; if (someCondition()) { i = 1; } else { i = 2; } System.out.println(i); } private boolean someCondition() { return true; }}在这两个例子中,局部变量i都被显式初始化,因此不会出现编译错误。
字符串

字符串(String)在Java中是一个不可变的对象,一旦创建就不能改变。这意味著,如果你尝试修改一个String对象的内容,实际上是在创建一个新的String对象并丢弃旧的那个。因此,选项D “String类的对象长度是可以随意改变的” 是不正确的。
然而,尽管单个String对象不能改变,你仍然可以通过连接操作符 “+” 来拼接多个字符串,形成新的字符串。例如:
String s1 = "Hello";String s2 = "World";String s3 = s1 + s2; // 结果是 "HelloWorld"在这个例子中,s3是一个全新的String对象,包含了s1和s2的内容。s1和s2本身并没有发生改变。
另外,虽然String对象是不可变的,但这并不影响你在一个变量中存储不同的String对象。例如:
String s = "Hello";s = "World"; // s现在指向一个新创建的String对象在这个例子中,s最初指向一个内容为"Hello"的String对象,后来又被重新赋值为指向另一个内容为"World"的新String对象。这个操作并不会改变原来的"Hello" String对象,只是改变了s所指的对象。
在Java中,字符串(String)是一个非常常用的数据类型。它代表一系列的字符序列,可以用双引号(“”)括起来表示。例如:"Hello World!"就是一个字符串。
字符串在Java中有几个重要特性:
不可变性:一旦创建,字符串的内容就不能更改。这意味着,如果你试图修改一个字符串,实际上是在创建一个新的字符串对象。例如,下面的代码会创建三个不同的字符串对象:
String str = "hello";str += " world!";str.toUpperCase();在这段代码中,第一句创建了一个名为str的字符串对象,第二句创建了一个新的字符串对象并将原str对象替换掉了,第三句同样创建了一个新的字符串对象,但并未改变str的值。
final修饰:String类是用final关键字修饰的,这意味着它无法被继承。也就是说,你不能创建String类的子类。
字符串拼接:你可以使用"+"运算符来拼接字符串。例如:
String firstName = "John";String lastName = "Doe";String fullName = firstName + " " + lastName; // 结果是 "John Doe"字符串比较:有几种方式可以比较字符串。最常见的方式是使用equals()方法,它可以判断两个字符串的内容是否相同。例如:
String str1 = "hello";String str2 = "hello";boolean isEqual = str1.equals(str2); // 结果是true注意不要使用"=="来比较字符串,除非你是想比较它们是否是指向同一块内存的引用。
字符串长度:你可以通过length()方法获取字符串的长度。例如:
String str = "hello";int length = str.length(); // 结果是5类与对象

这张图片展示了几个选择题,涉及Java编程语言中的类和对象关系以及父类和子类关系的理解。以下是每个问题及其对应答案的解析:
第26题
问:下列两个名词之间的关系适合表示父类和子类的关系的是?
A. 运动和运动员B. 餐厅和菜单C. 课堂和学生D. 运输工具和卡车答:D. 运输工具和卡车
解析:运输工具是卡车的一个更广泛的类别,卡车是运输工具的一种。因此,运输工具是父类,卡车是子类。第27题
问:下列两个名词之间的关系符合类和对象关系的是?
A. 军营和士兵B. 图书馆和书C. 灰熊和棕熊D. 运动员和姚明答:D. 运动员和姚明
解析:运动员是一个类,姚明是一个具体的运动员实例,因此他们是类和对象的关系。第28题
问:下列两个名词之间的关系符合类和对象关系的是?
A. 团长和士兵B. 书和书架C. 狼和老虎D. 作家和曹雪芹答:D. 作家和曹雪芹
解析:作家是一个类,曹雪芹是一个具体的作家实例,因此他们是类和对象的关系。第29题
问:下列两个名词之间的关系符合父类和子类关系的是?
A. 教师和学生B. 房子和家具C. 狗和猫D. 交通工具和飞机答:D. 交通工具和飞机
解析:交通工具是飞机的一个更广泛的类别,飞机是交通工具的一种。因此,交通工具是父类,飞机是子类。第30题
问:下列两个工程之间的关系符合类和对象关系的是?
A. 铁路和火车B. 诗人和李商隐C. 楼房和房间D. 图书馆和图书答:B. 诗人和李商隐
解析:诗人是一个类,李商隐是一个具体的诗人实例,因此他们是类和对象的关系。这些题目旨在测试对Java中类和对象概念的理解,特别是如何识别父类和子类关系以及类和对象关系。
关系描述

第30题的答案是B,因为“诗人和李商隐”之间存在类和对象的关系。在这里,“诗人”是一个类,而“李商隐”是该类的一个具体实例。
第31题的答案是B,因为“工程机械和铺路机械”之间存在父类和子类的关系。在这里,“工程机械”是父类,而“铺路机械”是从“工程机械”派生出来的子类。
第32题的答案是B,因为“火车和高铁动车”之间也存在父类和子类的关系。在这里,“火车”是父类,而“高铁动车”是从“火车”派生出来的子类。
第33题的答案是B,因为“电梯和智能电梯”之间同样存在父类和子类的关系。在这里,“电梯”是父类,而“智能电梯”是从“电梯”派生出来的子类。
第34题的答案是A,因为“楼梯和手扶电梯”之间拥有同样的基类。在这里,“楼梯”和“手扶电梯”都可以看作是从某个共同的基类派生出来的。
第35题的答案是A,因为“宾馆和宿舍”之间拥有同样的基类。在这里,“宾馆”和“宿舍”都可以看作是从某个共同的基类派生出来的。
 第36题:湿度不宜作为“机械类”的属性,因为湿度通常与气候条件有关,而非机械本身的特征。
第36题:湿度不宜作为“机械类”的属性,因为湿度通常与气候条件有关,而非机械本身的特征。
第37题:运输能力不宜作为“家具类”的属性,因为家具的主要功能是提供舒适性和装饰效果,而不是用于运输物品。
第38题:温度不宜作为“飞机类”的属性,因为飞机的设计和性能主要依赖于高度、速度和重量等因素,而不是温度。
第39题:建筑面积不宜作为“楼房类”的属性,因为楼房的建筑层数、建筑材料和绿化等才是描述楼房的重要属性。
第40题:专业不宜作为“小学生类”的属性,因为小学生的年龄较小,还未进入专业的学习阶段。

在Java语言中,采用私有属性的主要优势在于便于保护实例数据的安全。私有属性只能由所属类的方法访问,这样就可以防止外部代码直接修改或读取这些属性,从而保证了数据的一致性和安全性。同时,通过提供公共的getter和setter方法,我们可以控制对外暴露的信息,并且可以在设置或获取属性值时添加验证或其他处理逻辑。这种方式被称为封装,它是面向对象编程的基本原则之一。

方法重载

在Java语言中,方法重载(Overloading)允许我们在同一个类中定义多个同名的方法,只要它们的参数列表不同即可。这里所谓的参数列表的不同包括参数的数量、顺序和/或类型的不同。换句话说,如果两个方法具有相同的名称,但它们的参数数量、顺序或类型至少有一点不同,那么这两个方法就被视为重载。
例如,假设我们有一个名为MyClass的类,其中包含以下两个方法:
class MyClass { public void myMethod(int x, double y) { // 方法体... } public void myMethod(double z, int w) { // 方法体... }}在这个例子中,myMethod方法有两个版本,分别接受不同类型和顺序的参数。这种情况下,我们就说myMethod方法被重载了。
注意,返回类型不能用来区分重载的方法。所有重载的方法必须有不同的参数列表。此外,虽然参数列表可以有所不同,但方法名必须完全一样。
总结一下,在Java中,方法重载的关键点如下:
同一方法名可以在同一类中多次声明。参数列表必须不同(参数的数量、顺序或类型至少有一点不同)。返回类型不能用来区分重载的方法。理解这一点非常重要,因为它可以帮助我们更好地设计和组织我们的代码,使得程序更加灵活和易于维护。
在Java中,方法重载是一种多态的形式,它允许在同一类中定义多个同名的方法,但是这些方法的参数列表必须不同。这种方法重载的概念在Java中是非常重要的,因为它提供了灵活性,使程序员能够以一种自然的方式来编写代码。
当调用一个重载的方法时,Java虚拟机(JVM)根据传递给方法的实际参数来决定应该调用哪个方法。这就是为什么我们可以说方法重载实现了编译期的多态。
下面是方法重载的一些规则:
方法名必须相同。参数列表必须不同。这可能是参数的数量、类型或者是顺序上的差异。返回类型不影响方法的重载。即使两个方法除了返回类型外其他部分都相同,也不能构成重载。访问级别(如public,private,protected,default)也不影响方法的重载。举个简单的例子,考虑一个名为Calculator的类,其中有两个名为add的方法,一个是接收两个整型参数,另一个是接收两个浮点型参数:
public class Calculator { public int add(int num1, int num2) { return num1 + num2; } public float add(float num1, float num2) { return num1 + num2; } public static void main(String[] args) { Calculator calc = new Calculator(); int result1 = calc.add(10, 20); float result2 = calc.add(10.5f, 20.5f); System.out.println("Result of integer addition: " + result1); System.out.println("Result of float addition: " + result2); }}在这个例子中,Calculator类有两个add方法,它们的参数类型不同,所以它们构成了方法重载。当我们调用calc.add()时,JVM会根据传入的参数类型自动选择合适的方法进行调用。
当然,让我们进一步探讨方法重载的更多细节。
首先,方法重载不仅限于构造函数,也可以应用于任何类型的普通方法。例如,你可以有一个名为display的方法,它既可以接受一个字符串参数,又可以接受一个整数参数,甚至还可以没有参数。
其次,方法重载还涉及到可变参数(varargs)的情况。可变参数允许你将任意数量的某种类型的参数传递给一个方法。例如,你可以有一个方法,它接受任意数量的整数参数,并计算它们的总和。
public class VarArgsExample { public static int sum(int... numbers) { int total = 0; for (int number : numbers) { total += number; } return total; } public static void main(String[] args) { int result = sum(1, 2, 3, 4, 5); System.out.println(result); // 输出 15 }}在这个例子中,sum方法接受一个可变参数numbers,它是一个整数数组。然后,我们可以在调用sum方法时传递任意数量的整数参数。
最后,方法重载还涉及到泛型方法(generic methods)的情况。泛型方法允许你指定一个类型参数,然后在方法体内使用这个类型参数。例如,你可以有一个名为printArray的方法,它接受一个任意类型的数组参数,并打印出数组的所有元素。
public class GenericMethodsExample { public <T> void printArray(T[] array) { for (T element : array) { System.out.print(element + " "); } System.out.println(); } public static void main(String[] args) { Integer[] integers = {1, 2, 3}; String[] strings = {"a", "b", "c"}; GenericMethodsExample example = new GenericMethodsExample(); example.printArray(integers); // 输出 1 2 3 example.printArray(strings); // 输出 a b c }}在这个例子中,printArray方法是一个泛型方法,它接受一个类型参数T。然后,我们可以在调用printArray方法时指定实际的类型参数,例如Integer或String。

选项D的说法不正确。Java源程序需要经过编译成字节码文件后才能在各类平台上运行,而不是直接在各类平台上运行。
!!!Java源程序需要经过编译成字节码文件详细过程
Java源程序需要经过编译成字节码文件的过程主要包括以下几个步骤:
编写Java源代码:首先,你需要使用文本编辑器或者集成开发环境(IDE)编写你的Java源代码。源代码是以.java为扩展名的纯文本文件。
编译Java源代码:接下来,你需要使用Java编译器(javac.exe)将Java源代码编译成字节码文件。字节码文件是以.class为扩展名的二进制文件。编译命令格式通常是:javac 文件名.java
执行字节码文件:最后,你需要使用Java解释器(java.exe)执行字节码文件。执行命令格式通常是:java 类名
需要注意的是,Java编译器和解释器都是Java开发工具包(JDK)的一部分。在开始上述步骤之前,你需要先安装并配置好JDK。
另外,Java的垃圾回收机制也是其核心特点之一。Java的垃圾回收机制会在适当的时候自动释放不再使用的内存空间,这对于开发者来说是一大便利,因为他们不需要手动管理内存分配和释放。

选项B说法错误。Java原程序并不是通过集成开发环境(IDE)翻译为字节码程序的。实际上,Java原程序是由Java编译器(如javac)编译成字节码程序的。IDE只是一个辅助工具,帮助开发者编写、调试和运行Java程序,但它并不负责编译工作。
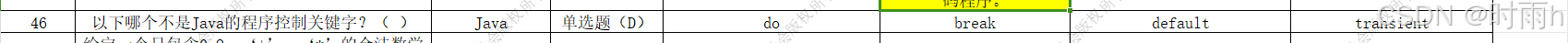
选项D中的"transient"不是Java的程序控制关键字。“do”、"break"和"default"都是Java的程序控制关键字。
Java 关键字是指那些在 Java 程序中有特殊含义的单词,它们不能用作变量名、方法名或类名。以下是 Java 中常用的一些关键字及其用途:
abstract: 定义抽象类或抽象方法。assert: 在运行时检查断言。boolean: 基本数据类型,表示布尔值 true 或 false。break: 终止循环或 switch 结构。byte: 基本数据类型,表示 8 位带符号整数。case: switch 语句的一部分,用于匹配特定情况。catch: try-catch 结构的一部分,捕获异常。char: 基本数据类型,表示单个字符。class: 定义类。const: 已废弃,曾用于声明常量。continue: 跳过当前迭代并继续下一次迭代。default: switch 语句的一部分,如果没有其他 case 匹配,则执行 default 部分。do: do-while 循环结构的一部分。double: 基本数据类型,表示双精度浮点数。else: if-else 结构的一部分,if 条件不满足时执行 else 部分。enum: 定义枚举类型。extends: 表示继承关系。final: 表示不可更改的对象、方法或变量。finally: try-finally 结构的一部分,无论是否发生异常都会执行 finally 部分。float: 基本数据类型,表示单精度浮点数。for: for 循环结构。goto: 已废弃,未实现。if: if-else 结构的一部分,判断条件。implements: 实现接口。import: 导入包或类。instanceof: 检查对象是否属于某个类或接口。int: 基本数据类型,表示 32 位带符号整数。interface: 定义接口。long: 基本数据类型,表示 64 位带符号整数。native: 标记本地方法。new: 创建新对象。package: 定义包。private: 访问修饰符,限制成员仅在类内部可见。protected: 访问修饰符,限制成员在类本身、子类以及同一包内的其他类可见。public: 访问修饰符,成员对所有类都可见。return: 返回方法的结果。short: 基本数据类型,表示 16 位带符号整数。static: 标识静态成员,独立于对象存在。strictfp: 强制浮点运算遵循 IEEE 754 规范。super: 访问超类的成员。switch: 开关结构,基于表达式的值执行不同的代码块。synchronized: 标识同步方法或代码块,确保线程安全。this: 当前对象引用。throw: 抛出异常。throws: 声明可能抛出的异常。transient: 标识序列化过程中忽略的字段。try: try-catch 结构的一部分,尝试执行代码块。void: 表示无返回值的方法。volatile: 标识共享变量,确保多线程环境下的可见性。while: while 循环结构。 以上就是 Java 的一些基本关键字,了解它们对于编写正确的 Java 程序至关重要。
操作题
栈的应用
给定一个只包含0-9、‘+’、‘’的合法数学表达式(长度<1000),规定加号‘+’的优先级高于乘号‘’,请输出计算结果。 输入说明: 合法的数学表达式 输出说明: 输出表达式的计算结果 输入样例: 123+122 输出样例: 360
这是一个典型的栈的应用问题。我们需要创建两个栈,一个用于存储数字,一个用于存储操作符。遍历输入的表达式,遇到数字就压入数字栈,遇到操作符就弹出栈顶的操作符和对应的数字进行计算,然后将结果压回数字栈。最后数字栈剩下的最后一个数字就是最终的结果。
下面是一个完整的Java程序实现:
import java.util.Stack;public class Main { public static void main(String[] args) { String expression = "12*3+12*2"; System.out.println(calculate(expression)); } public static int calculate(String s) { Stack<Integer> nums = new Stack<>(); Stack<Character> ops = new Stack<>(); int n = s.length(); for (int i = 0; i < n; i++) { char ch = s.charAt(i); if (Character.isDigit(ch)) { nums.push(Character.getNumericValue(ch)); } else if (ch == '+' || ch == '*') { while (!ops.isEmpty() && getPriority(ch) <= getPriority(ops.peek())) { nums.push(calculate(nums.pop(), nums.pop(), ops.pop())); } ops.push(ch); } } while (!ops.isEmpty()) { nums.push(calculate(nums.pop(), nums.pop(), ops.pop())); } return nums.pop(); } private static int calculate(int b, int a, char op) { switch (op) { case '+': return a + b; case '*': return a * b; default: throw new IllegalArgumentException("Invalid operator"); } } private static int getPriority(char op) { switch (op) { case '+': return 1; case '*': return 2; default: throw new IllegalArgumentException("Invalid operator"); } }}这段代码首先定义了一个calculate方法,该方法接受一个字符串参数s,代表要计算的表达式。然后,它创建了两个栈nums和ops,分别用于存储数字和操作符。
接着,它遍历输入的表达式,遇到数字就将其转换为整数并压入nums栈;遇到操作符则比较当前操作符和栈顶操作符的优先级,如果当前操作符的优先级小于等于栈顶操作符的优先级,就从nums栈中弹出两个数字,从ops栈中弹出一个操作符,进行计算并将结果压回nums栈;否则,直接将当前操作符压入ops栈。
最后,如果ops栈还有剩余的操作符,就重复上面的操作直到ops栈为空。此时,nums栈只剩下一个数字,即为最终的计算结果。
getPriority方法用于获取操作符的优先级,'+‘的优先级为1,’*'的优先级为2。
calculate方法用于执行具体的计算操作,根据操作符的不同,返回相应的计算结果。
HashMap
仓库新进了几批物资,只知道每批物资的数量和单价,请编写程序,按照每种物资的总价值,由高到低次序输出。 输入说明:第1行 一个整数N,表明物资的批次数量 第2-N+1行,每批物资的类别、数量及单价,中间用空格隔开,其中类别用A-Z加以区分。 输出说明:按物资价值降序输出排序结果,每行输出一种物资。 输入样例:5 A 5 10.00 B 3 2.00 A 5 8.00 B 3 2.50 C 10 3.50 输出样例:A 90.00 C 35.00 B 13.50
要解决这个问题,我们可以使用Java编写一个简单的控制台应用程序来处理输入数据,并根据每种物资的总价值进行排序。我们将使用HashMap来存储每种物资的总价值,并使用Collections类中的方法对这些值进行排序。
下面是完整的Java程序代码及其详细解析:
Java程序代码
import java.util.*;public class InventorySorter { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); // 读取物资批次数量 int N = Integer.parseInt(scanner.nextLine()); // 创建一个Map来存储每种物资的总价值 Map<String, Double> inventoryValue = new HashMap<>(); // 循环读取每批物资的信息 for (int i = 0; i < N; i++) { String line = scanner.nextLine(); String[] parts = line.split(" "); String category = parts[0]; int quantity = Integer.parseInt(parts[1]); double price = Double.parseDouble(parts[2]); // 计算该批物资的总价值并累加到Map中对应的物资类别上 double value = quantity * price; inventoryValue.put(category, inventoryValue.getOrDefault(category, 0.0) + value); } // 将Map转换为List以便排序 List<Map.Entry<String, Double>> sortedInventory = new ArrayList<>(inventoryValue.entrySet()); // 使用Comparator对物资按总价值进行排序(降序) sortedInventory.sort((e1, e2) -> e2.getValue().compareTo(e1.getValue())); // 输出排序后的结果 for (Map.Entry<String, Double> entry : sortedInventory) { System.out.printf("%s %.2f\n", entry.getKey(), entry.getValue()); } scanner.close(); }}代码解析
导入必要的类:
Scanner 类用于从标准输入读取数据。HashMap 和 ArrayList 类分别用于存储数据和排序前的数据准备。Collections 类提供了一些静态方法,用于操作集合。 主函数 (main 方法):
Scanner 对象来读取用户输入。读取第一行数据,即物资的批次数量 N。创建一个 HashMap 来存储每个物资类别的总价值。键是物资类别(字符串),值是该类别的总价值(双精度浮点数)。使用循环读取接下来的 N 行数据,每一行包含一个物资类别、数量和单价。计算出这批物资的价值后,将其累加到 HashMap 中对应物资类别的总价值上。将 HashMap 转换成一个 List,这样可以对其进行排序。使用 Collections.sort() 方法和自定义的 Comparator 对 List 进行排序,确保物资按照总价值从高到低排列。遍历排序后的列表,格式化输出每种物资的类别和总价值。 关闭 Scanner:
Scanner 对象以释放资源。 这个程序能够有效地处理给定的问题,它首先收集所有输入数据,然后计算每个物资类别的总价值,最后根据总价值对物资进行排序并输出结果。
第三题 解析和计算数学表达式的程序
给定一个只包含0-9、‘-’、‘’的合法数学表达式(长度<1000),规定减号‘-’的优先级高于乘号‘’,请输出计算结果。 输入说明: 合法的数学表达式(其中的数没有负数) 输出说明: 输出表达式的计算结果 输入样例: 123-122 输出样例: -216
要解决这个问题,我们需要编写一个解析和计算数学表达式的程序。由于题目规定了减号 - 的优先级高于乘号 *,我们需要先处理所有的减法运算,然后再处理乘法运算。
下面是完整的 Java 程序及其详细解析:
Java 程序代码
import java.util.*;public class ExpressionEvaluator { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String expression = scanner.nextLine(); // 先处理所有的减法运算 List<String> terms = splitByOperator(expression, '-'); // 计算每个减法项的结果 long result = 0; for (String term : terms) { if (!term.isEmpty()) { result -= evaluateMultiplication(term); } } // 输出最终结果 System.out.println(result); } // 分割表达式,返回一个列表,每个元素是一个子表达式 private static List<String> splitByOperator(String expression, char operator) { List<String> terms = new ArrayList<>(); StringBuilder currentTerm = new StringBuilder(); boolean inQuotes = false; for (char c : expression.toCharArray()) { if (c == operator && !inQuotes) { terms.add(currentTerm.toString()); currentTerm.setLength(0); // 清空StringBuilder } else { currentTerm.append(c); } } terms.add(currentTerm.toString()); // 添加最后一个子表达式 return terms; } // 计算乘法表达式的结果 private static long evaluateMultiplication(String term) { long result = 1; boolean isFirstNumber = true; for (String number : term.split("\\*")) { if (!number.isEmpty()) { long num = Long.parseLong(number); if (isFirstNumber) { result = num; isFirstNumber = false; } else { result *= num; } } } return result; }}代码解析
主函数 (main 方法):
Scanner 读取用户输入的数学表达式。调用 splitByOperator 方法将表达式按减号 - 分割成多个子表达式。初始化结果变量 result 为 0。遍历每个子表达式,调用 evaluateMultiplication 方法计算每个子表达式的乘法结果,并将其累加到 result 中(注意这里使用 -= 是因为减号的优先级更高)。输出最终结果。 分割表达式 (splitByOperator 方法):
StringBuilder 来构建当前的子表达式。遍历表达式的每个字符,如果遇到指定的运算符且不在引号内,则将当前子表达式添加到列表中,并清空 StringBuilder。最后将最后一个子表达式添加到列表中。返回子表达式的列表。 计算乘法表达式 (evaluateMultiplication 方法):
result 为 1。使用 split 方法将子表达式按乘号 * 分割成多个数字字符串。遍历每个数字字符串,将其转换为长整型并累乘到 result 中。返回乘法结果。 示例运行
假设输入表达式为 12*3-12*2:
splitByOperator 方法将表达式按 - 分割成 ["12*3", "12*2"]。对每个子表达式调用 evaluateMultiplication 方法: "12*3" 计算结果为 36。"12*2" 计算结果为 24。 将每个子表达式的结果累加到 result 中: result -= 36,结果为 -36。result -= 24,结果为 -60。 输出最终结果 -60。 三重循环来遍历数组中的所有可能的三元组组合
数字连连看,给出一个整数数组和一个目标值,请在数组中找到三个元素,它们的和为该目标值。 输入说明:第一行是整数N和T,N(N<10000)表示整数数组中元素个数,T是目标值。 第二行是N个整数,表示数组中的元素,且每个数的绝对值小于等于100000。 输出说明:找到的这三个匹配元素所在位置(数组元素起始位置为1),中间用一个空格隔开,若存在多个,请输出位置最小的一个(例如:数组为 8 5 4 5 3,目标值为16,位置1 2 5和1 4 5均满足条件,输出1 2 5);不满足输出-1。 输入样例:7 12 2 8 7 6 3 4 3 输出样例:1 3 5
要解决这个问题,我们可以使用三重循环来遍历数组中的所有可能的三元组组合,并检查它们的和是否等于目标值。为了优化性能,我们可以在遍历过程中记录最小的位置组合。
以下是完整的 Java 程序及其详细解析:
Java 程序代码
import java.util.Scanner;public class ThreeSumFinder { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); // 读取输入 int N = scanner.nextInt(); int T = scanner.nextInt(); int[] nums = new int[N]; for (int i = 0; i < N; i++) { nums[i] = scanner.nextInt(); } // 初始化结果变量 int minIndex1 = -1; int minIndex2 = -1; int minIndex3 = -1; // 使用三重循环遍历所有可能的三元组组合 for (int i = 0; i < N; i++) { for (int j = i + 1; j < N; j++) { for (int k = j + 1; k < N; k++) { if (nums[i] + nums[j] + nums[k] == T) { // 如果找到了新的三元组,更新结果变量 if (minIndex1 == -1 || i < minIndex1 || (i == minIndex1 && j < minIndex2) || (i == minIndex1 && j == minIndex2 && k < minIndex3)) { minIndex1 = i; minIndex2 = j; minIndex3 = k; } } } } } // 输出结果 if (minIndex1 != -1) { System.out.println((minIndex1 + 1) + " " + (minIndex2 + 1) + " " + (minIndex3 + 1)); } else { System.out.println(-1); } scanner.close(); }}代码解析
读取输入:
使用Scanner 读取输入数据。第一行读取两个整数 N 和 T,分别表示数组的长度和目标值。第二行读取 N 个整数,存入数组 nums 中。 初始化结果变量:
定义三个变量minIndex1, minIndex2, minIndex3,初始值为 -1,用于记录找到的第一个满足条件的三元组的位置。 三重循环遍历所有可能的三元组组合:
使用三重循环遍历数组中的所有可能的三元组组合。对于每个三元组(nums[i], nums[j], nums[k]),检查它们的和是否等于目标值 T。如果找到满足条件的三元组,更新结果变量 minIndex1, minIndex2, minIndex3,确保记录的是位置最小的三元组。 输出结果:
如果找到了满足条件的三元组,输出它们的位置(注意数组下标从0开始,而题目要求从1开始,所以输出时加1)。如果没有找到满足条件的三元组,输出-1。 示例运行
假设输入为:
7 122 8 7 6 3 4 3读取输入数据:
N = 7, T = 12nums = [2, 8, 7, 6, 3, 4, 3] 遍历所有可能的三元组组合:
找到的第一个满足条件的三元组是[2, 7, 3],位置分别为 1, 3, 5。 输出结果:
1 3 5