使用PySide6/QT实现YOLOv5/v8可视化GUI页面
在人工智能和计算机视觉领域,YOLO(You Only Look Once)是一种广泛使用的实时目标检测算法。为了直观地展示YOLO算法的检测效果,我们可以使用Python中的PySide6库来创建一个简单的GUI应用程序,将检测结果实时可视化。本文将指导你如何使用PySide6实现这一功能。
一、工具介绍
1、PySide6
PySide6是一款功能强大的GUI(图形用户界面)开发框架,它允许Python开发者使用Qt库的功能来构建跨平台的桌面应用程序。PySide6作为Qt的Python绑定版本,继承了Qt的跨平台特性,支持在Windows、macOS、Linux等多种操作系统上开发和部署应用程序。其具有以下特点:
丰富的组件库:PySide6提供了大量的GUI控件和布局管理器,如按钮、文本框、下拉框、复选框等,以及QGridLayout、QFormLayout、QStackedLayout等多种布局方式,方便开发者快速构建用户界面。高性能:基于Qt 6的底层实现,PySide6保证了应用程序的性能和响应速度,能够处理大型复杂的GUI。灵活的事件处理机制:PySide6能够处理各种用户输入事件,如鼠标点击、键盘输入等,实现丰富的交互功能。官方维护与支持:PySide6是Qt公司官方维护的Python绑定版本,享有官方的技术支持和更新服务,确保了框架的稳定性和可靠性。2、OpenCV
OpenCV(Open Source Computer Vision Library)是一个广泛使用的开源计算机视觉库,它提供了丰富的图像和视频处理功能,以及一些机器学习算法。
OpenCV具有广泛的应用领域,包括但不限于:
人脸识别和物体识别:使用OpenCV可以实现人脸检测和识别,以及目标检测等,可应用于人脸门禁系统、人脸支付、安全监控等场景。图像和视频分析:可用于视频压缩、视频稳定、行人跟踪、行为分析等。图像合成和3D重建:通过多个视角的图像来重建场景的三维结构。机器学习:OpenCV也提供了针对神经网络和深度学习的高级功能,支持常见的深度学习框架,如TensorFlow、PyTorch和Caffe,使开发者能够利用神经网络进行人脸检测、物体识别和语义分割等任务。二、环境准备
利用pip工具进行依赖项安装(也可以利用Annaconda进行依赖包安装),要求python≥3.8。
1、安装ultralytics包
打开CMD:Win键 + R打开<运行>,输入"cmd",回车,输入以下代码,即可快速安装YOLO。
也可以在PyCharm编辑器里打开终端进行安装。
# 安装ultralytics工具包pip install ultralytics# 如果安装速度比较慢可以换成清华源的镜像pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple 在ultralytics包里,会自动安装适配当前ultralytics版本的torch。
也可以根据自己的需要安装对应的torch版本:
pip install torch=2.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple2、安装PySide6工具包
使用 pip 或者 conda 安装 PySide6,打开你的终端或命令提示符,然后运行以下命令来安装 PySide6:
# 安装PySide6工具包pip install PySide6 -i https://pypi.tuna.tsinghua.edu.cn/simple3、安装OpenCV工具包
使用 pip 或者 conda 安装 OpenCV,打开你的终端或命令提示符,然后运行以下命令来安装 OpenCV:
# 安装opencv工具包pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple这个命令会安装 OpenCV 的核心功能,包括图像处理、视频捕获等。如果你还需要额外的功能,比如对 OpenCV 的贡献模块(如 xfeatures2d、stitching 等),你可以安装 opencv-contrib-python:
# 安装opencv工具包pip install opencv-contrib-python -i https://pypi.tuna.tsinghua.edu.cn/simple三、导入必要的库
在你的Python脚本中,导入所需的库:
import osfrom datetime import datetimeimport jsonimport cv2import torchfrom PyQt5.QtCore import pyqtSlotfrom PySide6.QtGui import QIconfrom PySide6 import QtWidgets, QtCore, QtGuifrom PySide6.QtCore import Qt, QDirfrom ultralytics import YOLO四、创建主窗口,初始化相关参数
class MyWindow(QtWidgets.QMainWindow): def __init__(self): super().__init__() self.init_gui() self.model = None self.timer = QtCore.QTimer() self.timer1 = QtCore.QTimer() self.cap = None self.video = None self.file_path = None self.base_name = None self.timer1.timeout.connect(self.video_show) def init_gui(self): self.folder_path = "./model_file" # 自定义修改:设置模型文件夹路径 self.setFixedSize(1300, 650) self.setWindowTitle('目标检测') # 自定义修改:设置窗口名称 self.setWindowIcon(QIcon("logo.jpg")) # 自定义修改:设置窗口图标 central_widget = QtWidgets.QWidget(self) self.setCentralWidget(central_widget) main_layout = QtWidgets.QVBoxLayout(central_widget)更换窗口背景图片:
# 自定义修改:设置窗口背景图self.set_background_image('bg.jpg')
五、编写页面布局
1、创建图片/视频展示区域
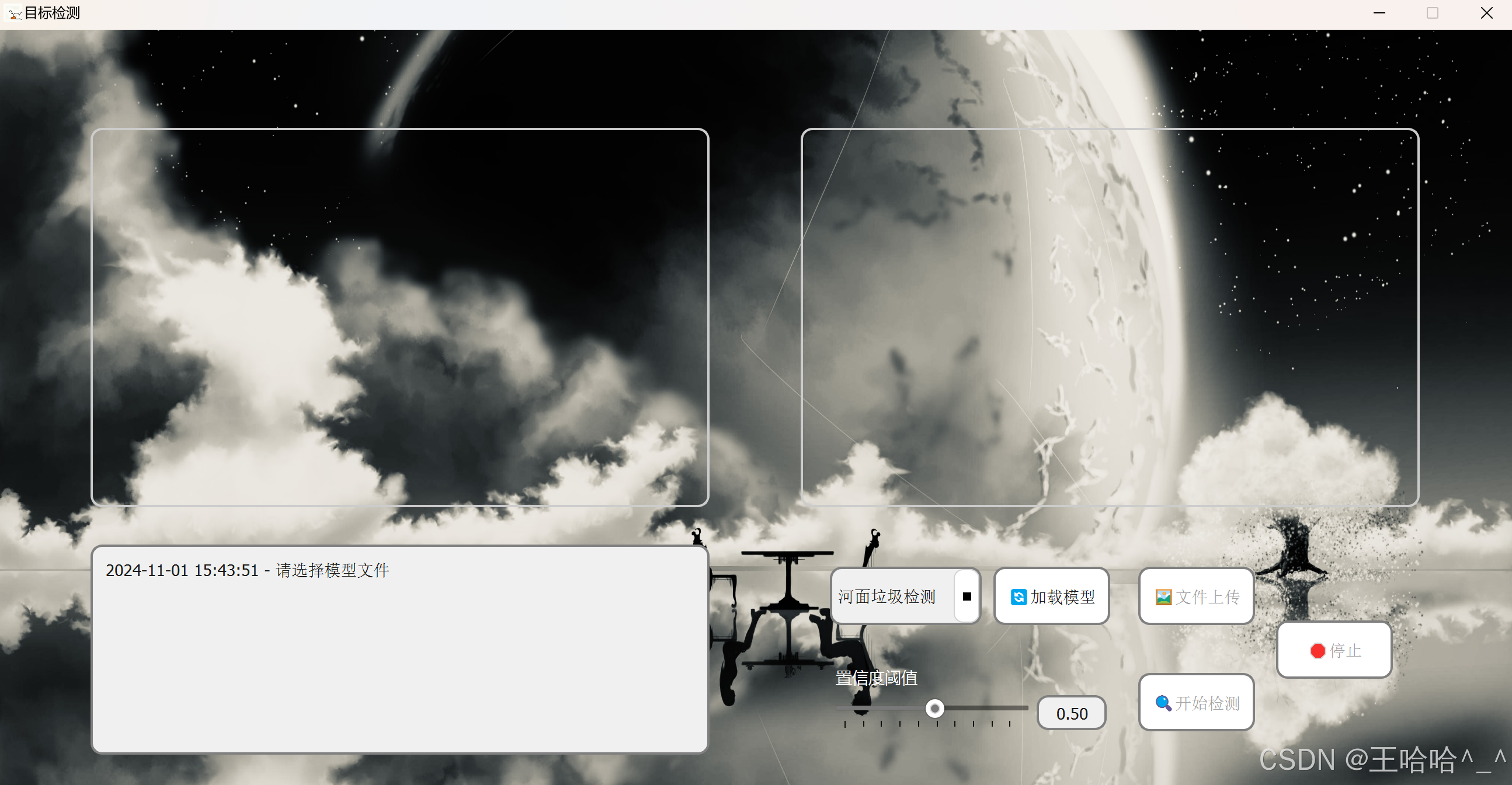
如上图所示,左侧是文件上传之后原图、原视频的展示区域;右侧是经模型加载并执行开始检测之后,用来展示预测结果的检测区。
页面布局代码如下:
# 界面上半部分: 视频框topLayout = QtWidgets.QHBoxLayout()self.oriVideoLabel = QtWidgets.QLabel(self)self.detectlabel = QtWidgets.QLabel(self)self.oriVideoLabel.setFixedSize(530, 400)self.detectlabel.setFixedSize(530, 400)self.oriVideoLabel.setStyleSheet('border: 2px solid #ccc; border-radius: 10px; margin-top:75px;')self.detectlabel.setStyleSheet('border: 2px solid #ccc; border-radius: 10px; margin-top: 75px;')topLayout.addWidget(self.oriVideoLabel)topLayout.addWidget(self.detectlabel)main_layout.addLayout(topLayout)在这段代码中,包含一个水平布局(QHBoxLayout),用于放置两个视频显示的标签(QLabel)。这两个标签分别用于显示原始视频(oriVideoLabel)和处理后的视频或检测结果(detectLabel)。
2、创建日志打印区域
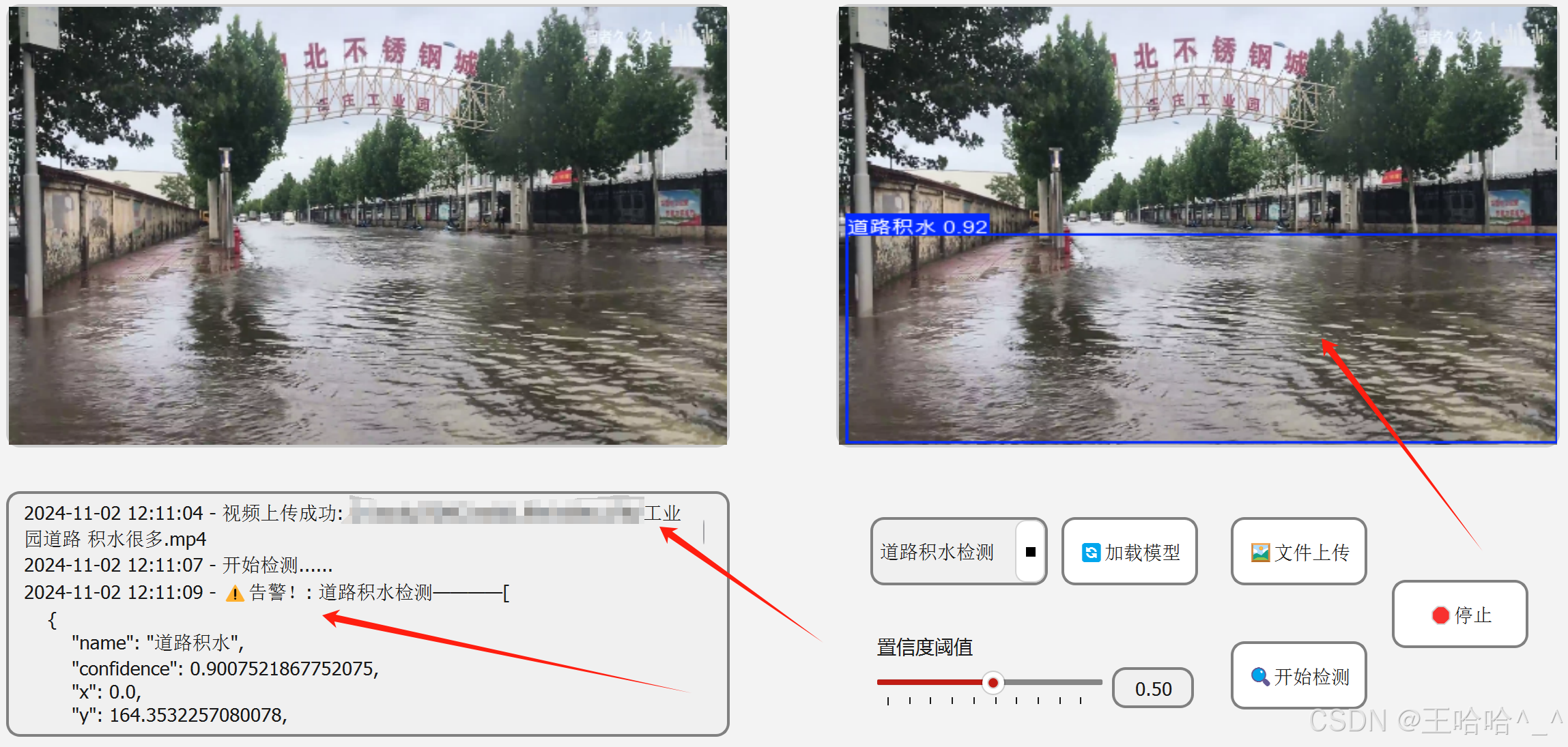
在基于YOLO的目标检测当中,我们需要记录一些操作日志,从而方便后续维护。此外,在实际生产环境中,如果置信度大于我们所设定的阈值,需要产生告警信息,而这些信息需要记录标签预测框的坐标信息、产生告警的时间以及告警的标签内容。日志打印区的效果图如下:
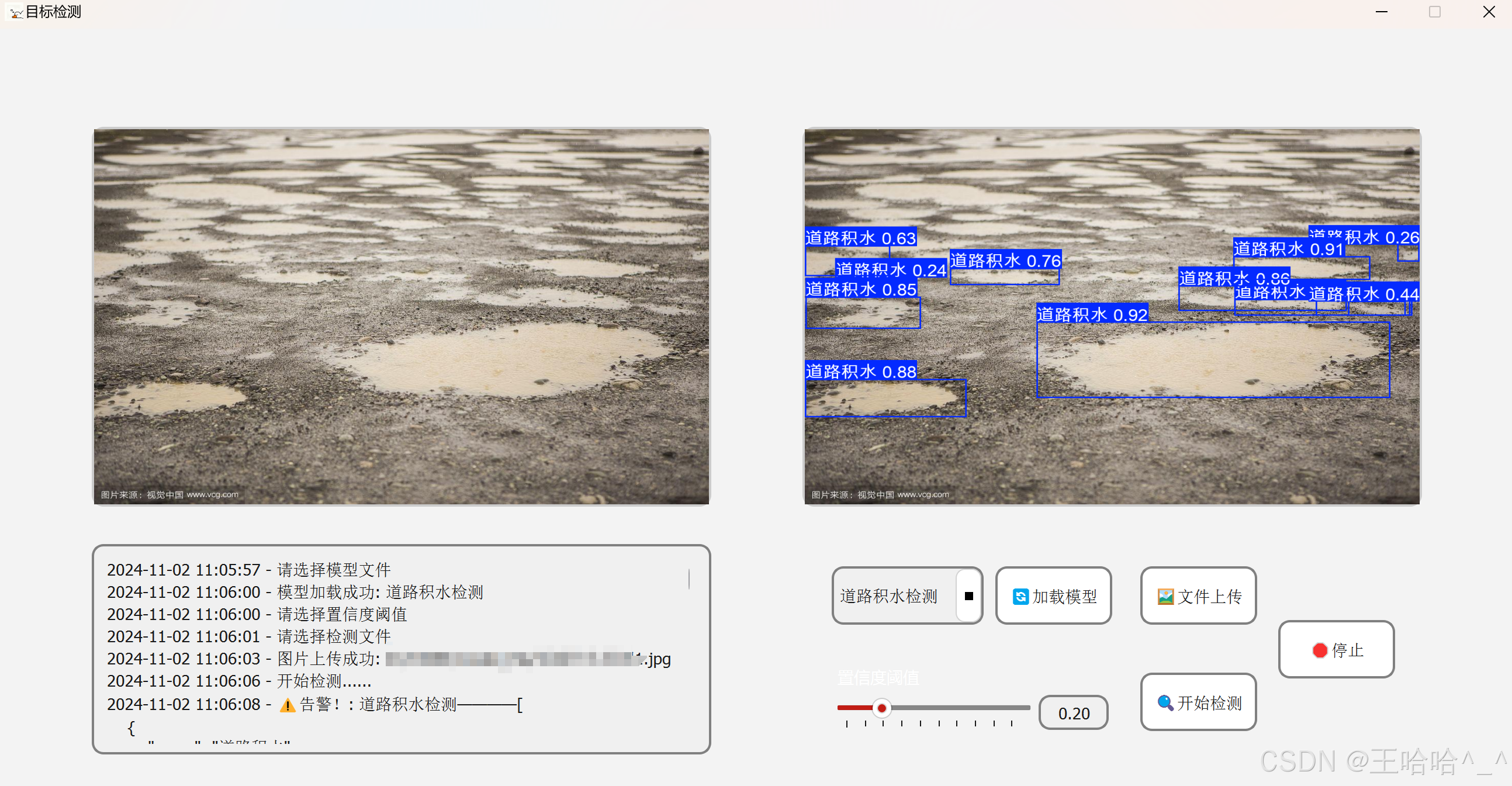

如上图所示,在启动程序之后会提示加载模型文件,之后进行文件上传,最后点击开始检测。在这个过程中会生成操作日志。
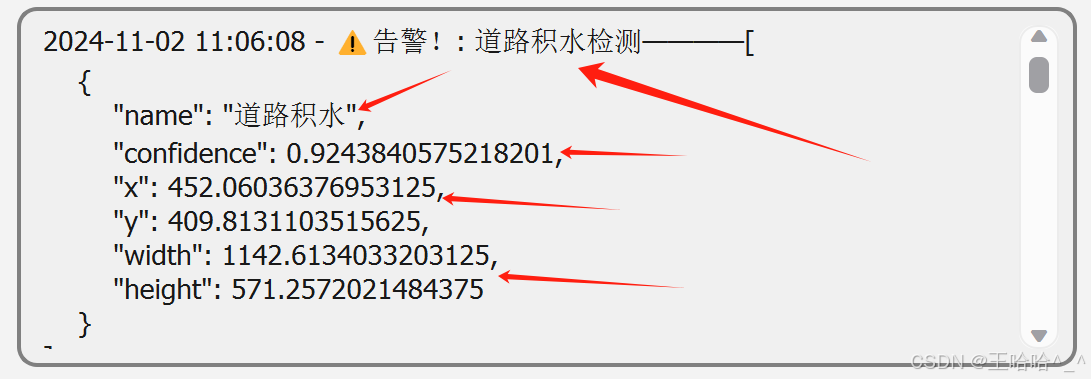
在日志打印区当中会生成JSON字符串格式的日志信息,信息内容为当前预测框中的告警信息,包括:
标签名称:"name": "道路积水", 置信度:"confidence": 0.9243840575218201,横坐标:"x": 452.06036376953125,纵坐标:"y": 409.8131103515625,预测框宽度:"width": 1142.6134033203125,预测框高度:"height": 571.2572021484375可以将上述告警信息封装之后以接口的形式传入相关数据平台进行分析和处理。
日志区域的页面布局代码如下:
# 创建日志打印文本框self.outputField = QtWidgets.QTextBrowser()self.outputField.setFixedSize(530, 180)3、加载YOLO模型
下载YOLO预训练模型,选择自己的预测模型进行加载.....

代码如下:
# 遍历文件夹并添加文件名到下拉框for filename in os.listdir(self.folder_path): file_path = os.path.join(self.folder_path, filename) if os.path.isfile(file_path) and filename.endswith('.pt'): # 确保是文件且后缀为.pt base_name = os.path.splitext(filename)[0] self.selectModel.addItem(base_name)# 添加加载模型按钮self.loadModel = QtWidgets.QPushButton('?️加载模型') # 新建加载模型按钮self.loadModel.setFixedSize(100, 50)self.loadModel.setStyleSheet(""" QPushButton { background-color: white; /* 正常状态下的背景颜色 */ border: 2px solid gray; /* 正常状态下的边框 */ border-radius: 10px; padding: 5px; font-size: 14px; } QPushButton:hover { background-color: #f0f0f0; /* 悬停状态下的背景颜色 */ } """)self.loadModel.clicked.connect(self.load_model) # 绑定load_model函数进行模型加载selectModel_layout.addWidget(self.selectModel) # 将下拉框加入到页面布局当中selectModel_layout.addWidget(self.loadModel) # 将按钮加入到页面布局当中load_model函数代码如下:
def load_model(self): filename = self.selectModel.currentText() full_path = os.path.join(self.folder_path, filename + '.pt') self.base_name = os.path.splitext(os.path.basename(full_path))[0] if full_path.endswith('.pt'): # 加载预训练模型 self.model = YOLO(full_path) self.start_detect.setEnabled(True) self.stopDetectBtn.setEnabled(True) self.openImageBtn.setEnabled(True) self.confudence_slider.setEnabled(True) self.outputField.append(f'{datetime.now().strftime("%Y-%m-%d %H:%M:%S")} - 模型加载成功: {filename}') self.outputField.append(f'{datetime.now().strftime("%Y-%m-%d %H:%M:%S")} - 请选择置信度阈值') else: self.outputField.append(f'{datetime.now().strftime("%Y-%m-%d %H:%M:%S")} - 请重新选择模型文件!') print("Reselect model")4、创建置信度阈值滑动条
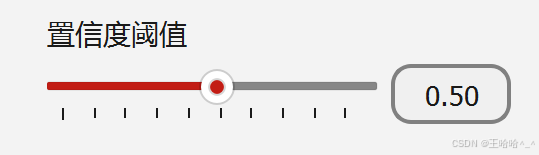

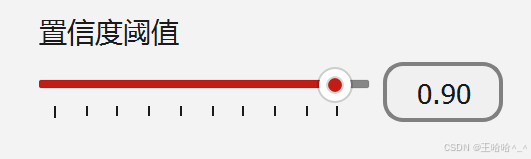
你可以根据自己的需求自定义置信度阈值,value值会绑定模型预测的conf,在预测过程中实时生效,效果图如下:
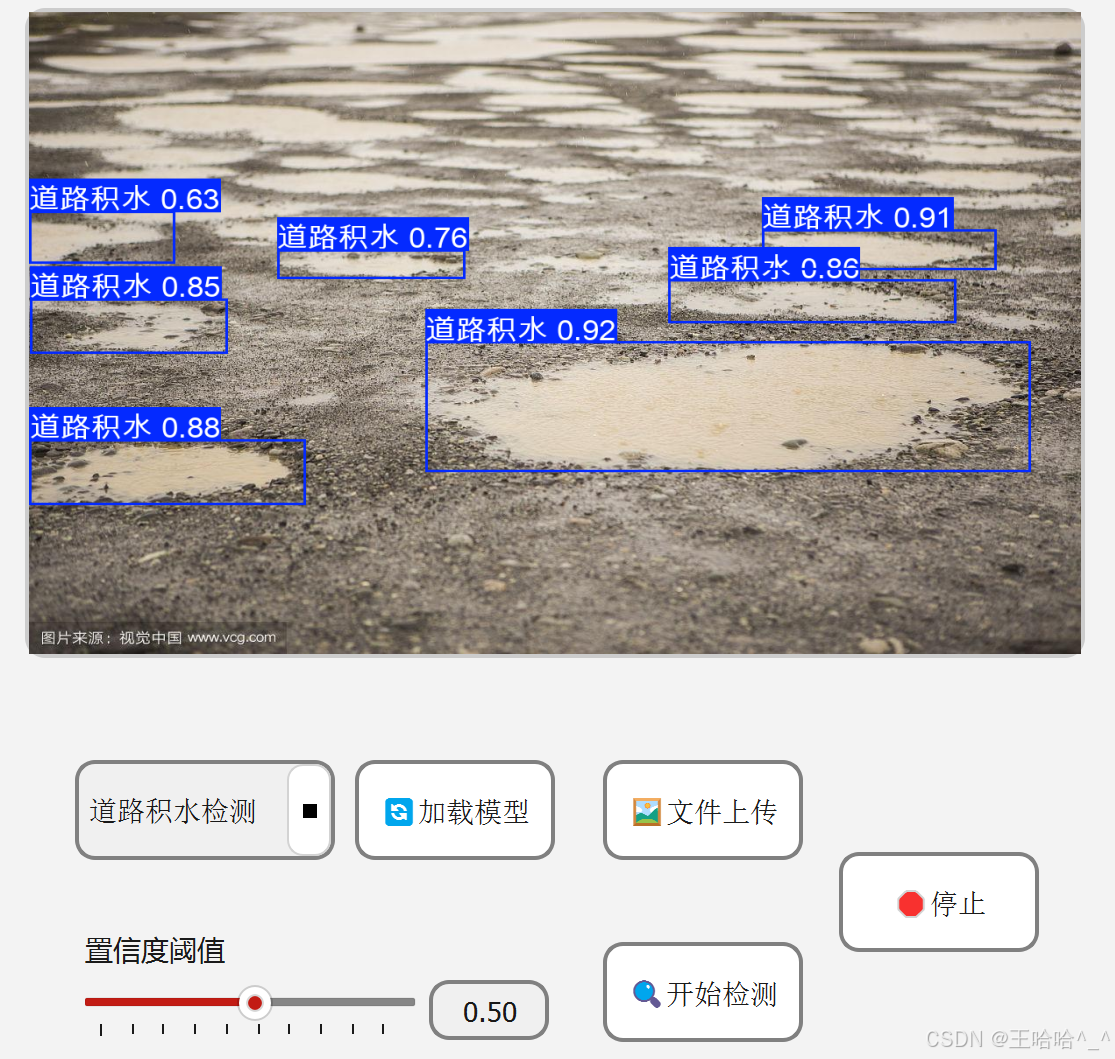
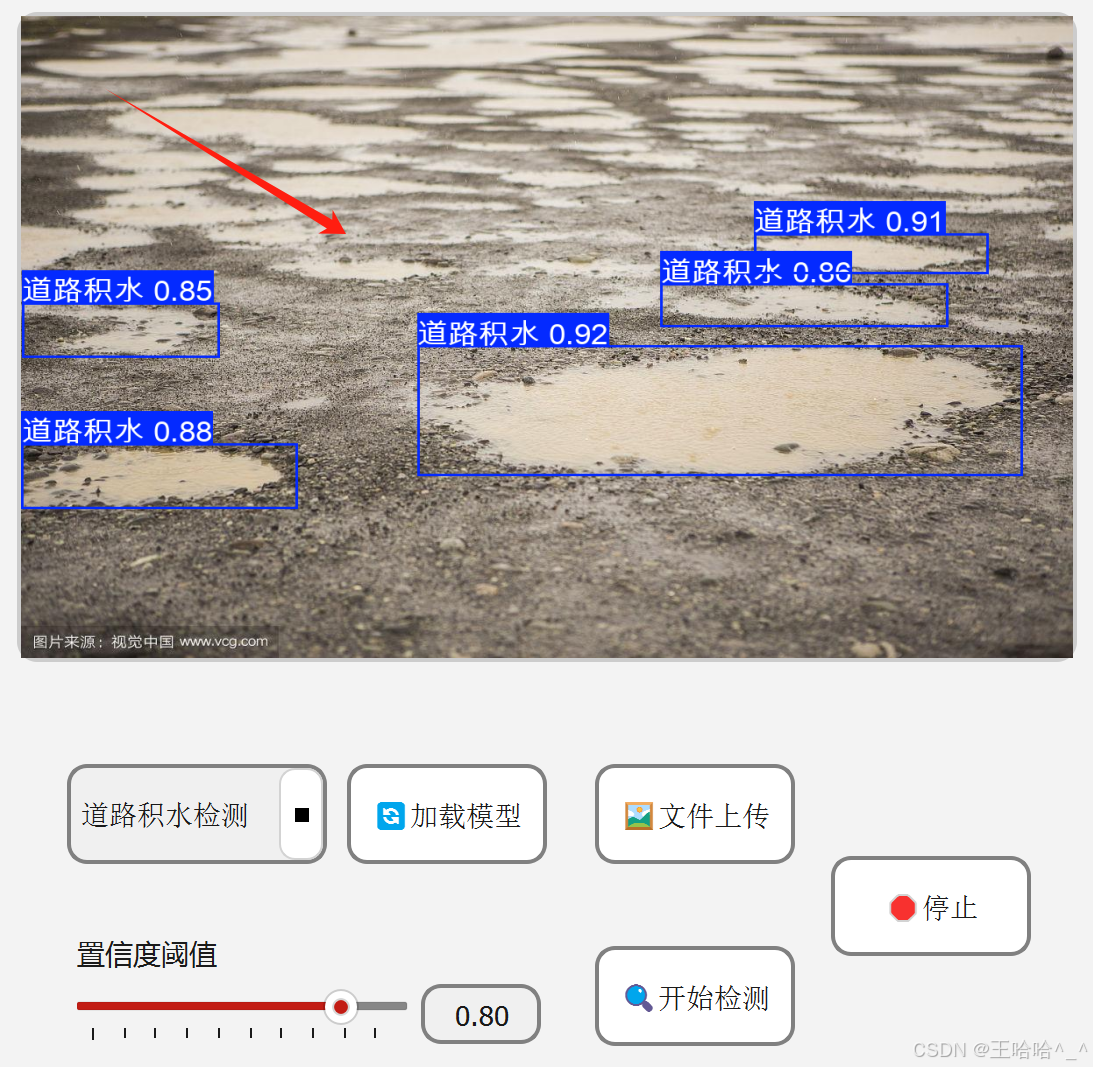
页面布局代码如下:
# 创建一个置信度阈值滑动条self.con_label = QtWidgets.QLabel('置信度阈值', self)self.con_label.setStyleSheet('font-size: 14px; font-family: "Microsoft YaHei";')# 创建一个QSlider,范围从0到99(代表0.01到0.99)self.slider = QtWidgets.QSlider(Qt.Horizontal, self)self.slider.setMinimum(1) # 0.01self.slider.setMaximum(99) # 0.99self.slider.setValue(50) # 0.5self.slider.setTickInterval(10)self.slider.setTickPosition(QtWidgets.QSlider.TicksBelow)self.slider.setFixedSize(170, 30)# 创建一个QDoubleSpinBox用于显示和设置滑动条的值self.spinbox = QtWidgets.QDoubleSpinBox(self)self.spinbox.setButtonSymbols(QtWidgets.QAbstractSpinBox.NoButtons)self.spinbox.setMinimum(0.01)self.spinbox.setMaximum(0.99)self.spinbox.setSingleStep(0.01)self.spinbox.setValue(0.5)self.spinbox.setDecimals(2)self.spinbox.setFixedSize(60, 30)self.spinbox.setStyleSheet('border: 2px solid gray; border-radius: 10px; ' 'padding: 5px; background-color: #f0f0f0; font-size: 14px;')self.confudence_slider = QtWidgets.QWidget()layout = QtWidgets.QVBoxLayout()hlayout = QtWidgets.QHBoxLayout()self.confudence_slider.setFixedSize(250, 64)layout.addWidget(self.con_label)hlayout.addWidget(self.slider)hlayout.addWidget(self.spinbox)layout.addLayout(hlayout)self.confudence_slider.setLayout(layout)self.confudence_slider.setEnabled(False)# 连接信号和槽self.slider.valueChanged.connect(self.updateSpinBox)self.spinbox.valueChanged.connect(self.updateSlider)5、文件上传
文件上传操作包括图片上传、视频上传,支持JPG格式和MP4格式,以文件流的形式读取需要被检测的文件。
# 对上传的文件根据后缀名称进行过滤file_path, file_type = file_dialog.getOpenFileName(self, "选择检测文件", filter='*.jpg *.mp4')
页面布局代码如下:
# 文件上传按钮self.openImageBtn = QtWidgets.QPushButton('?️文件上传')self.openImageBtn.setFixedSize(100, 65)self.openImageBtn.setStyleSheet(""" QPushButton { background-color: white; /* 正常状态下的背景颜色 */ border: 2px solid gray; /* 正常状态下的边框 */ border-radius: 10px; padding: 5px; font-size: 14px; margin-bottom: 15px; } QPushButton:hover { background-color: #f0f0f0; /* 悬停状态下的背景颜色 */ } """)self.openImageBtn.clicked.connect(self.upload_file) # 绑定upload_file事件self.openImageBtn.setEnabled(False) # 初始化按钮默认不可操作,加载模型之后可以操作文件上传成功之后会呈现在左侧的展示区域,效果图如下:
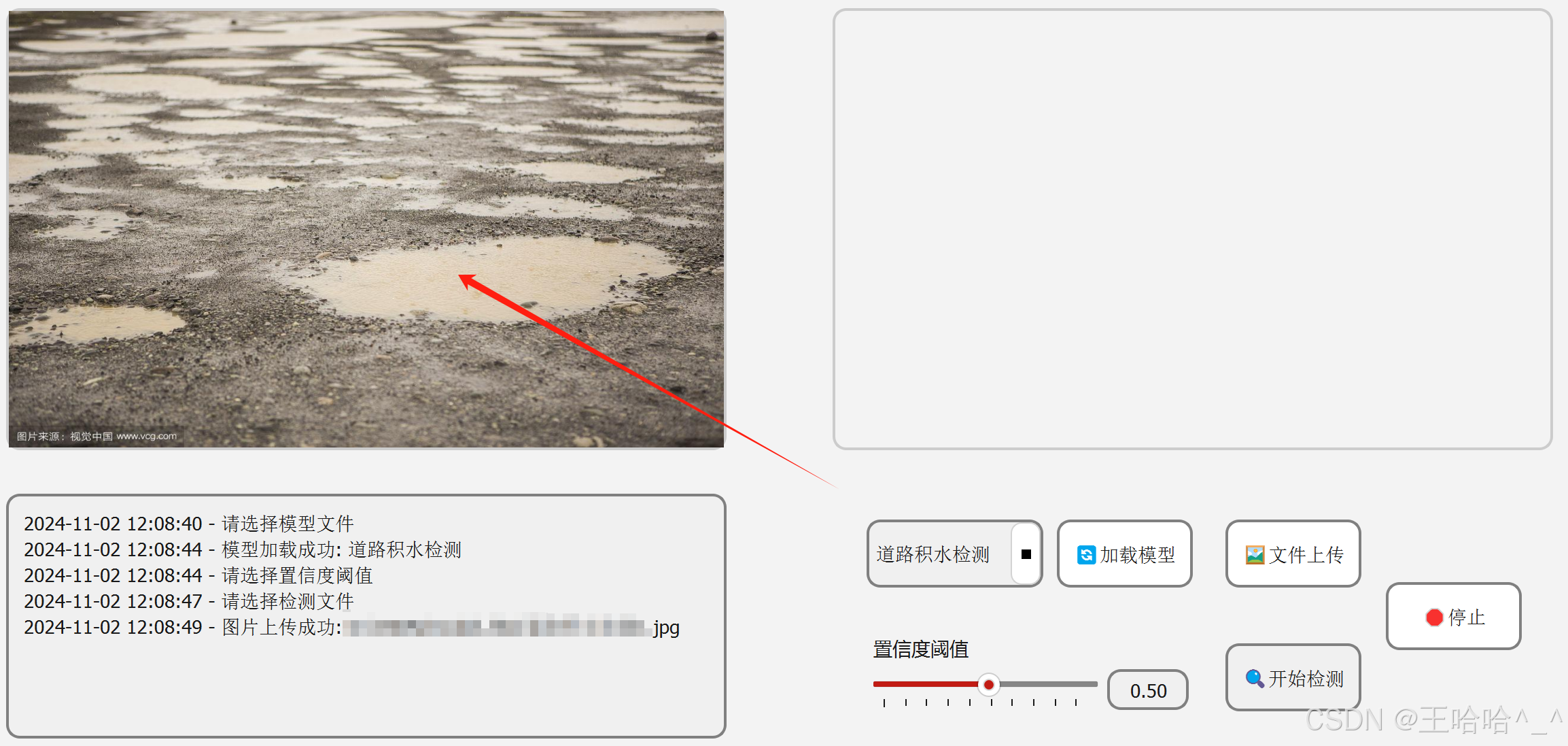
上传视频效果如下:
6、执行预测
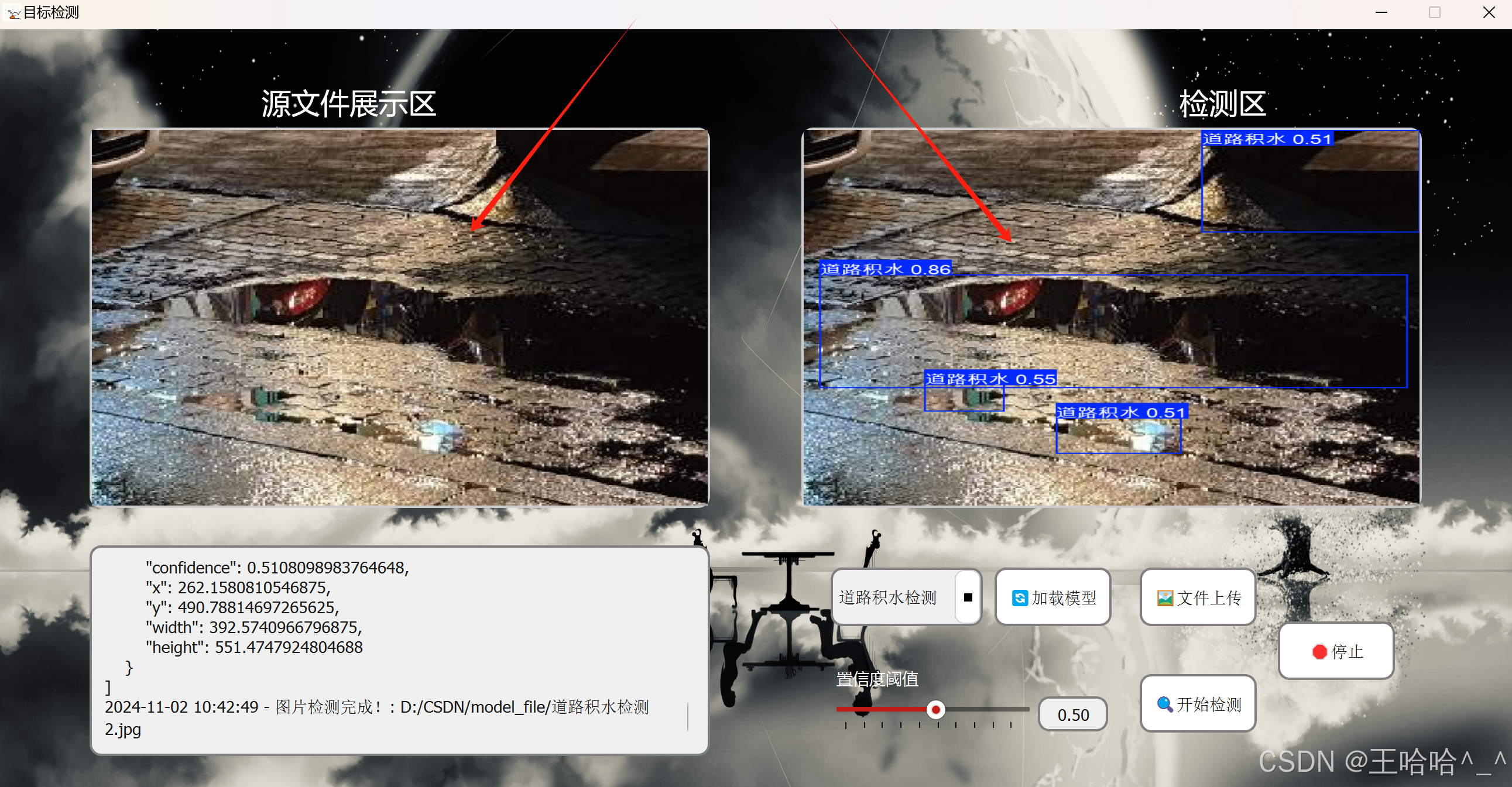
图片预测效果图如下:
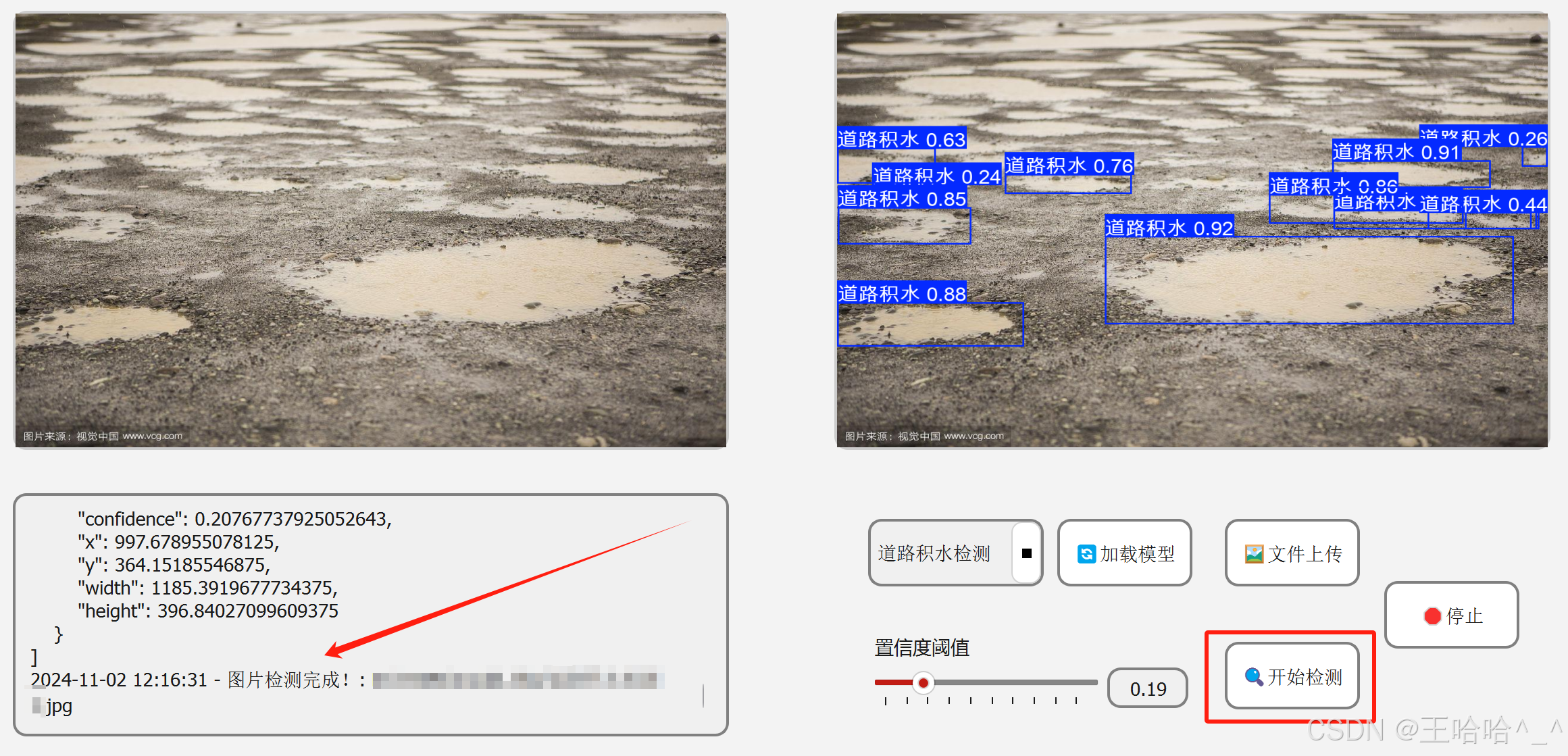
使用 OpenCV(cv2)库进行视频抽帧是一个常见的任务,可以用于从视频中提取特定的帧进行进一步处理或分析。
视频预测效果图如下:
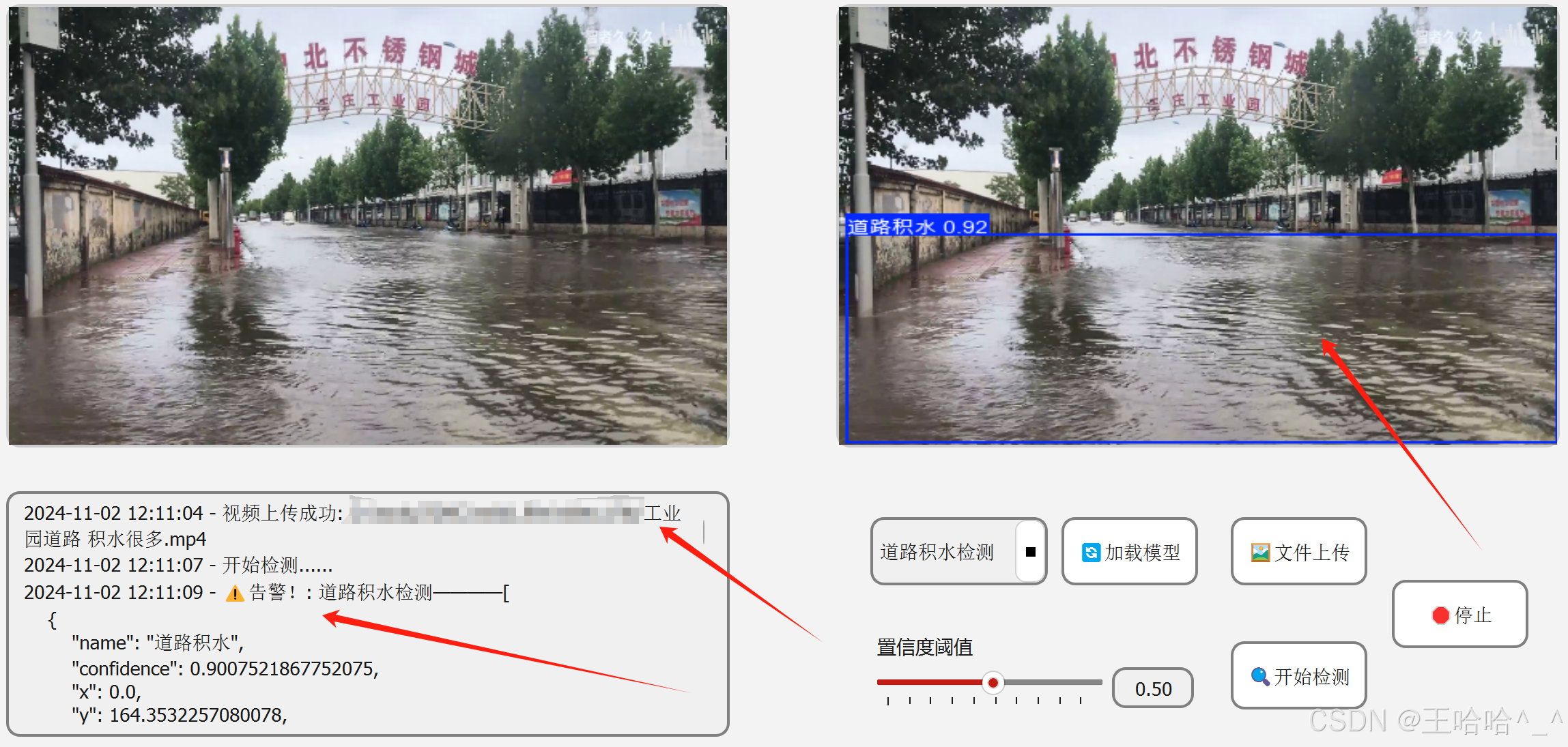
页面布局代码如下:
# 执行预测按钮self.start_detect = QtWidgets.QPushButton('?开始检测')self.start_detect.setFixedSize(100, 50)self.start_detect.setStyleSheet(""" QPushButton { background-color: white; /* 正常状态下的背景颜色 */ border: 2px solid gray; /* 正常状态下的边框 */ border-radius: 10px; padding: 5px; font-size: 14px; } QPushButton:hover { background-color: #f0f0f0; /* 悬停状态下的背景颜色 */ } """)self.start_detect.clicked.connect(self.show_detect) # 绑定show_detect函数事件self.start_detect.setEnabled(False)模型预测的核心代码:
将视频帧进行抽取之后转为QImage格式对预测结果进行展示。
frame = self.model(frame, imgsz=[448, 352], device='cuda', conf=self.value) if torch.cuda.is_available() \ else self.model(frame, imgsz=[448, 352], device='cpu', conf=self.value)7、停止检测
在视频检测的过程中可能发现上传错误,此时为了防止视频一直在后台检测导致占用内存,需要及时中断检测程序。
界面效果图如下所示:

日志打印区会输出“检测中断!”,检测区也会停在该视频的当前帧。
代码如下:
# 停止检测按钮self.stopDetectBtn = QtWidgets.QPushButton('?停止')self.stopDetectBtn.setFixedSize(100, 50)self.stopDetectBtn.setEnabled(False)self.stopDetectBtn.clicked.connect(self.stop_detect) # 绑定stop_detect中断检测事件# 中断检测事件def stop_detect(self): if self.timer.isActive(): self.timer.stop() if self.timer1.isActive(): self.timer1.stop() if self.cap is not None: self.cap.release() self.cap = None self.video = None self.ini_labels() self.outputField.append(f'{datetime.now().strftime("%Y-%m-%d %H:%M:%S")} - 检测中断!') self.file_path = None六、程序完整代码
(完整代码包含整体UI布局和按钮绑定事件)
上述内容为控件的页面布局和部分核心代码,戳我头像获取代码,或者主页私聊博主哈~
内容为本人原创,诚心需要提供内容指导!
非本人同意禁止转载......