目录
一、Ollama是什么?
二、如何在Mac上安装Ollama
1. 准备工作
2. 下载并安装Ollama
3. 运行Ollama
4. 安装和配置大型语言模型
5. 使用Ollama
三、安装open-webui
1. 准备工作
2. Open WebUI ⭐的主要特点
3. Docker安装OpenWebUI,拉去太慢可以使用手动安装
4. 配置本地大模型LLaMA2-7B
5. 验证配置
四、使用Ollama + AnythingLLM构建类ChatGPT本地问答机器人系
学习目标
1. 下载AnythingLLM
2. 安装AnythingLLM
3. 配置AnythingLLM
3.1 选择LLM、嵌入模型和向量数据库
3.2 设置环境变量(如果需要)
3.3 权限管理(如果需要)
4. 构建知识库
5. 开始使用
6. 自定义集成(如果需要)
7. 监控和反馈
8. 注意事项
9. 额外信息
参考文章
一、Ollama是什么?
Ollama是一个功能强大的开源框架,旨在简化在Docker容器中部署和管理大型语言模型(LLM)的过程。以下是关于Ollama的详细介绍:
定义与功能: Ollama是一个开源的大型语言模型服务工具,它帮助用户快速在本地运行大模型。通过简单的安装指令,用户可以执行一条命令就在本地运行开源大型语言模型,如Llama 2。Ollama极大地简化了在Docker容器内部署和管理LLM的过程,使得用户能够快速地在本地运行大型语言模型。特点与优势: 功能齐全:Ollama将模型权重、配置和数据捆绑到一个包中,定义成Modelfile。优化设置与配置:它优化了设置和配置细节,包括GPU使用情况。易用性:用户无需深入了解复杂的部署和管理流程,只需简单的安装和配置即可使用。支持热加载:用户无需重新启动即可切换不同的模型。支持的平台与模型: Ollama支持在Mac和Linux平台上运行。它支持运行多种开源大型语言模型,如Llama 2。API与界面: Ollama提供了类似OpenAI的API接口和聊天界面,方便用户部署和使用最新版本的GPT模型。安装与部署: Ollama的安装过程被极大地简化,并提供了多种选择,包括Docker镜像。综上所述,Ollama是一个为在本地运行大型语言模型而设计的强大、易用、功能齐全的开源框架。它通过优化设置和配置,简化了在Docker容器中部署和管理LLM的过程,使得用户能够快速、方便地在本地运行大型语言模型。
二、如何在Mac上安装Ollama
在Mac上安装Ollama的步骤如下,结合了参考文章中的信息,并进行了适当的总结和归纳:
1. 准备工作
确认系统兼容性:Ollama支持在Mac上运行,但请确保您的Mac满足运行大型语言模型所需的最低系统要求。检查存储空间:安装和运行Ollama以及大型语言模型可能需要较大的磁盘空间。请确保您的Mac有足够的存储空间。2. 下载并安装Ollama
访问Ollama官网:前往Ollama的官方网站(如:https://ollama.com/)下载适用于Mac的安装包。下载安装包:在官网找到适用于Mac的下载链接,下载Ollama的安装包。安装Ollama:双击下载的安装包,按照提示完成安装过程。3. 运行Ollama
打开终端:在Mac上打开终端(Terminal)。运行命令:在终端中,输入相应的命令来启动和运行Ollama。例如,使用ollama pull llama3命令来拉取并安装Llama 3模型(请注意,这只是一个示例命令,具体命令可能因Ollama的版本和您的需求而有所不同)。下载llama2地址: llama2下载命令:ollama run llama2:7b 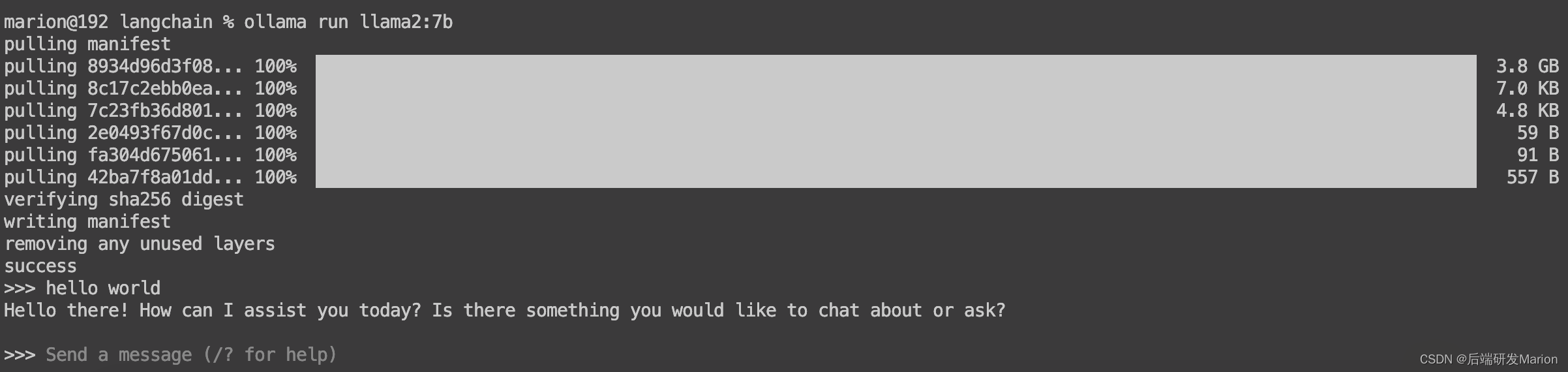
4. 安装和配置大型语言模型
选择模型:根据您的需求选择合适的大型语言模型。Ollama支持多种开源大型语言模型,如Llama 2、Llama 3等。安装模型:使用Ollama提供的命令来安装所选的模型。例如,使用ollama pull llama3命令来安装Llama 3模型。配置模型:根据模型的文档和说明,进行必要的配置和设置。这可能包括设置模型的参数、配置GPU使用情况等。 5. 使用Ollama
启动服务:在成功安装和配置模型后,您可以使用Ollama提供的命令或API来启动和运行模型服务。访问和使用:通过Ollama提供的Web界面或API接口,您可以访问和使用已部署的大型语言模型进行各种任务,如文本生成、问答等。API调用curl http://localhost:11434/api/generate -d '{
"model": "llama2:7B",
"prompt":"Why is the sky blue?"
}'
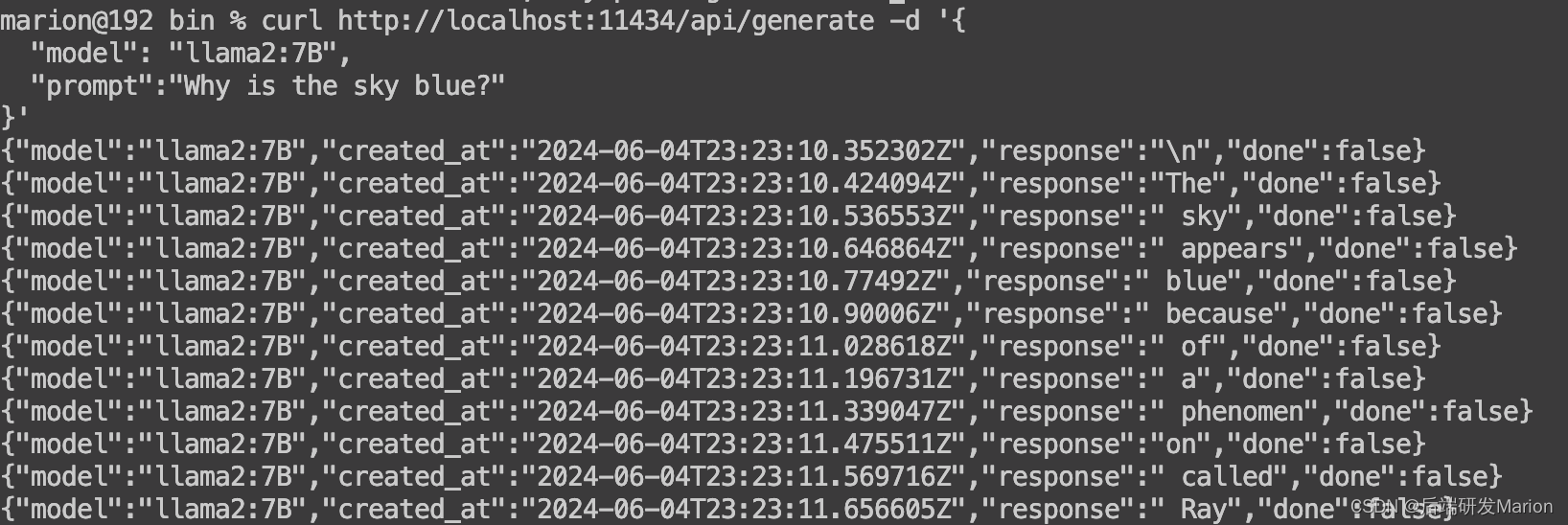 回答问题时CPU100%,MAC M1 8G内存
回答问题时CPU100%,MAC M1 8G内存 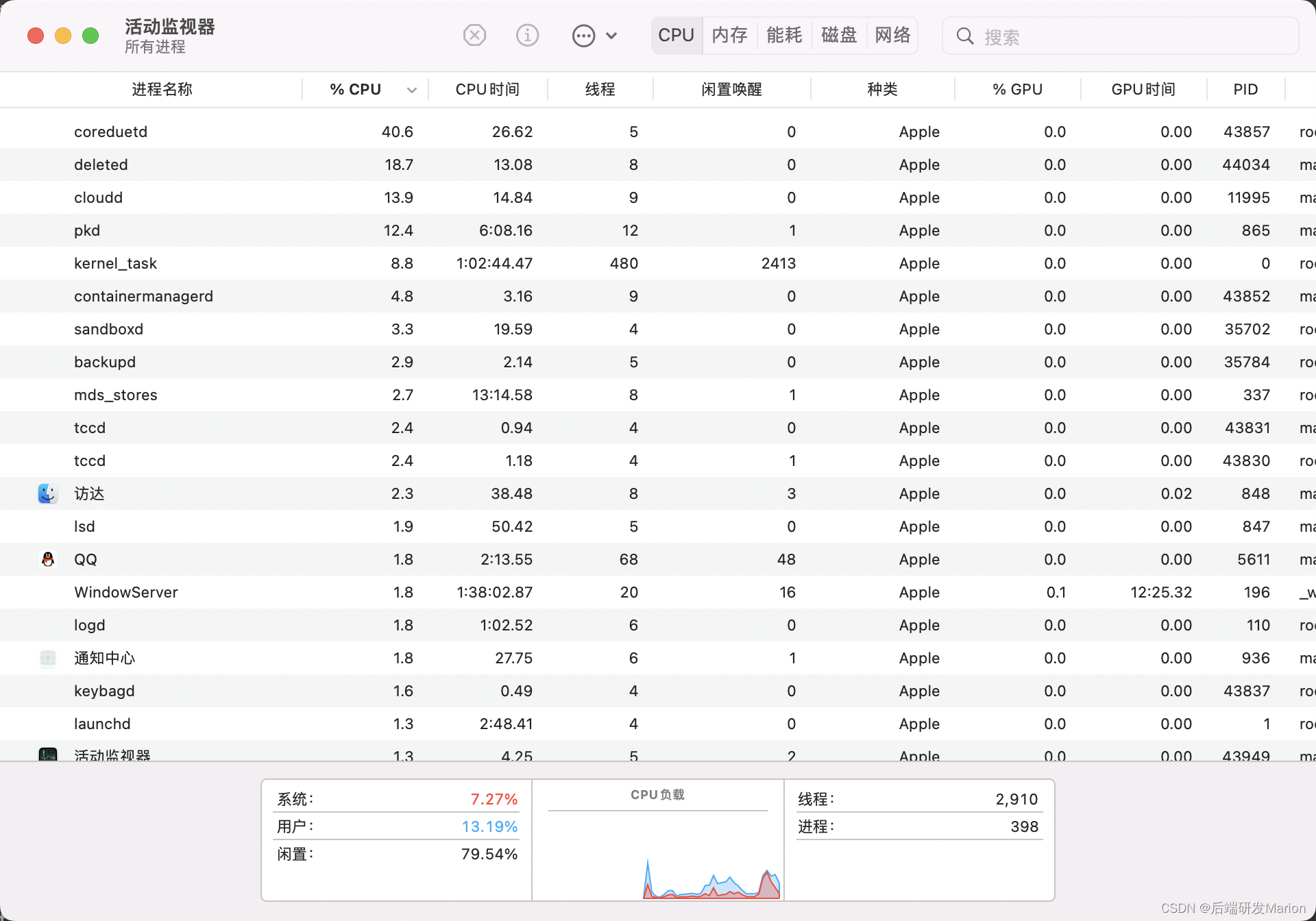
请注意,以上步骤和命令可能因Ollama的版本和您的具体需求而有所不同。建议您参考Ollama的官方文档和社区资源,以获取最准确和最新的安装和使用指南。
三、安装open-webui
1. 准备工作
安装Docker环境:确保你的系统上已经安装了Docker Desktop。你可以从Docker官网下载并安装适合你操作系统的Docker Desktop版本。配置Docker以支持GPU(可选):如果你的本地有GPU,并且希望利用GPU加速大模型效果,你需要在Docker Desktop中配置GPU支持。这通常涉及到在Docker Desktop的设置中启用GPU支持,并安装相应的驱动程序和软件。可参考文章:Macbook m1安装docker详细教程_mac m1安装docker-CSDN博客2. Open WebUI ⭐的主要特点
GitHub - open-webui/open-webui: User-friendly WebUI for LLMs (Formerly Ollama WebUI)
? 轻松设置:使用 Docker 或 Kubernetes(kubectl、kustomize 或 helm)无缝安装,提供无忧体验,同时支持标记映像和标记映像。:ollama:cuda
? Ollama/OpenAI API 集成:轻松集成兼容 OpenAI 的 API,与 Ollama 模型进行多功能对话。自定义 OpenAI API URL 以链接 LMStudio、GroqCloud、Mistral、OpenRouter 等。
? Pipelines、Open WebUI 插件支持:使用 Pipelines 插件框架将自定义逻辑和 Python 库无缝集成到 Open WebUI 中。启动您的 Pipelines 实例,将 OpenAI URL 设置为 Pipelines URL,探索无限可能。示例包括函数调用、控制访问的用户速率限制、使用 Langfuse 等工具进行使用情况监控、使用 LibreTranslate 提供多语言支持的实时翻译、有害消息过滤等等。
? 响应式设计:在台式电脑、笔记本电脑和移动设备上享受无缝体验。
? 适用于移动设备的渐进式 Web 应用程序 (PWA):使用我们的 PWA 在您的移动设备上享受类似本机应用程序的体验,提供对 localhost 的离线访问和无缝的用户界面。
✒️? 完整的 Markdown 和 LaTeX 支持:通过全面的 Markdown 和 LaTeX 功能提升您的 LLM 体验,以实现丰富的交互。
?️ 模型生成器:通过 Web UI 轻松创建 Ollama 模型。通过 Open WebUI 社区集成,轻松创建和添加自定义角色/代理、自定义聊天元素和导入模型。
? 本地 RAG 集成:通过突破性的检索增强生成 (RAG) 支持,深入了解聊天交互的未来。此功能将文档交互无缝集成到您的聊天体验中。您可以将文档直接加载到聊天中或将文件添加到文档库中,在查询之前使用命令轻松访问它们。#
? RAG 的 Web 搜索:使用 、 、 、 和 等提供程序执行 Web 搜索,并将结果直接注入到聊天体验中。SearXNGGoogle PSEBrave Searchserpstackserper
? Web 浏览功能:使用后跟 URL 的命令将网站无缝集成到您的聊天体验中。此功能允许您将 Web 内容直接合并到您的对话中,从而增强交互的丰富性和深度。#
? 图像生成集成:使用 AUTOMATIC1111 API 或 ComfyUI(本地)和 OpenAI 的 DALL-E(外部)等选项无缝整合图像生成功能,通过动态视觉内容丰富您的聊天体验。
⚙️ 许多模型对话:毫不费力地同时与各种模型互动,利用它们的独特优势来获得最佳响应。通过并行利用各种模型来增强您的体验。
? 基于角色的访问控制 (RBAC):确保使用受限权限进行安全访问;只有经过授权的个人才能访问您的 Ollama,并且为管理员保留独家模型创建/拉取权限。
?? 多语言支持:通过我们的国际化 (i18n) 支持,以您的首选语言体验 Open WebUI。加入我们,扩展我们支持的语言!我们正在积极寻找贡献者!
? 持续更新:我们致力于通过定期更新、修复和新功能来改进 Open WebUI。
想了解更多关于Open WebUI的功能吗?查看我们的 Open WebUI 文档,了解全面概述!
3. Docker安装OpenWebUI
拉取Open-WebUI镜像:使用Docker命令从GitHub Container Registry拉取Open-WebUI的镜像。例如,你可以运行以下命令来拉取最新的Open-WebUI镜像:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
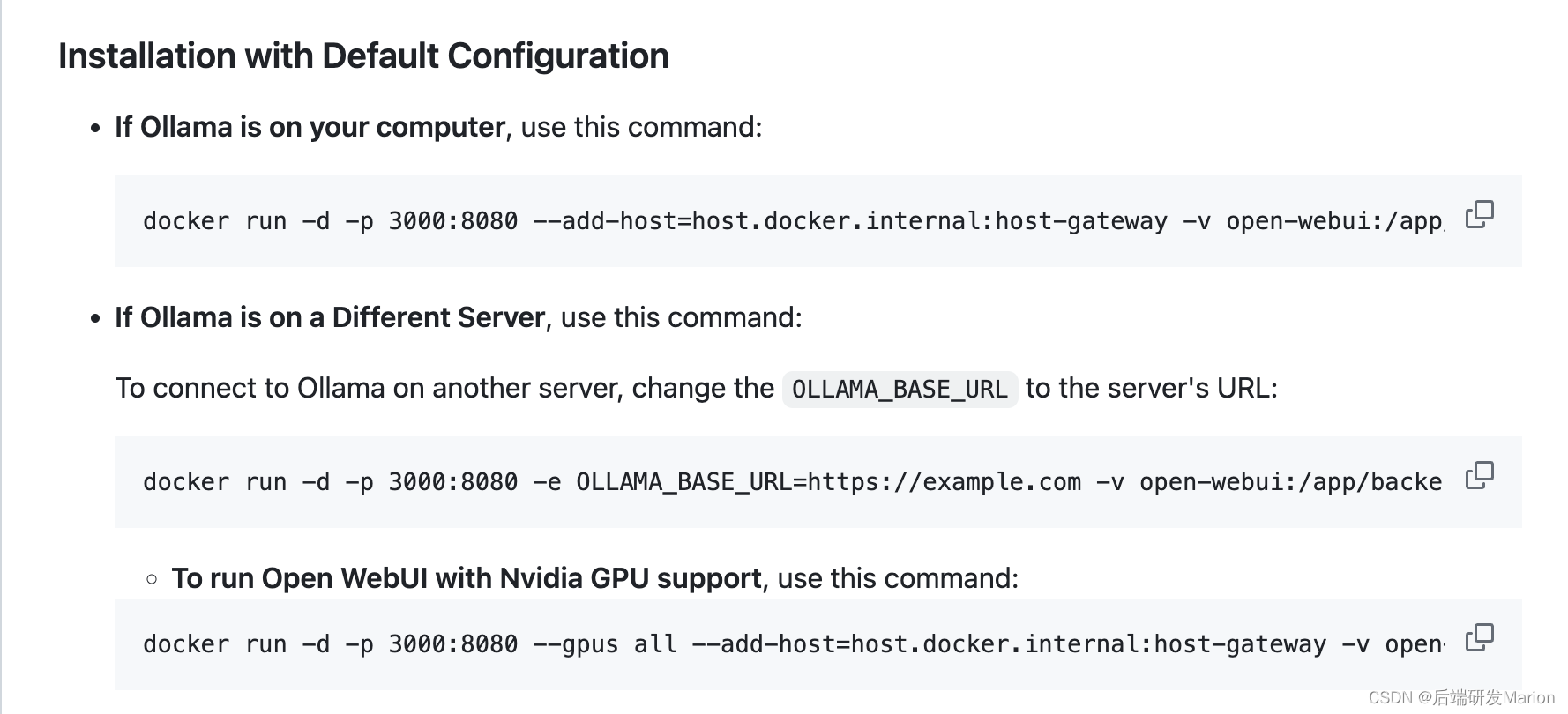
下载太慢,需要配置docker国内镜像仓库,参考这篇文章:
MacOS上配置docker国内镜像仓库地址_mac docker配置镜像源-CSDN博客
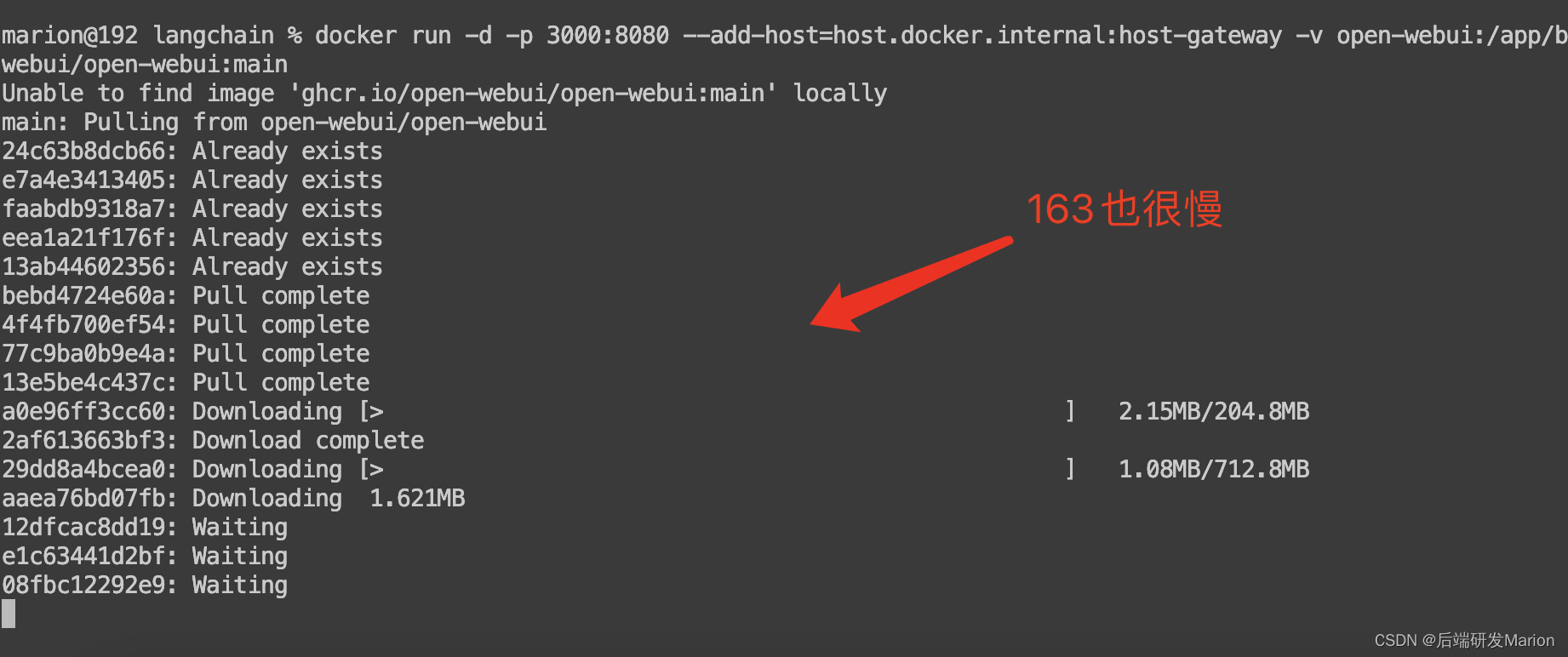
如果163也很慢,建议配置阿里云镜像地址,需要登陆阿里云 不过配置发现更慢!手动下载了
最后只能用魔法解决了
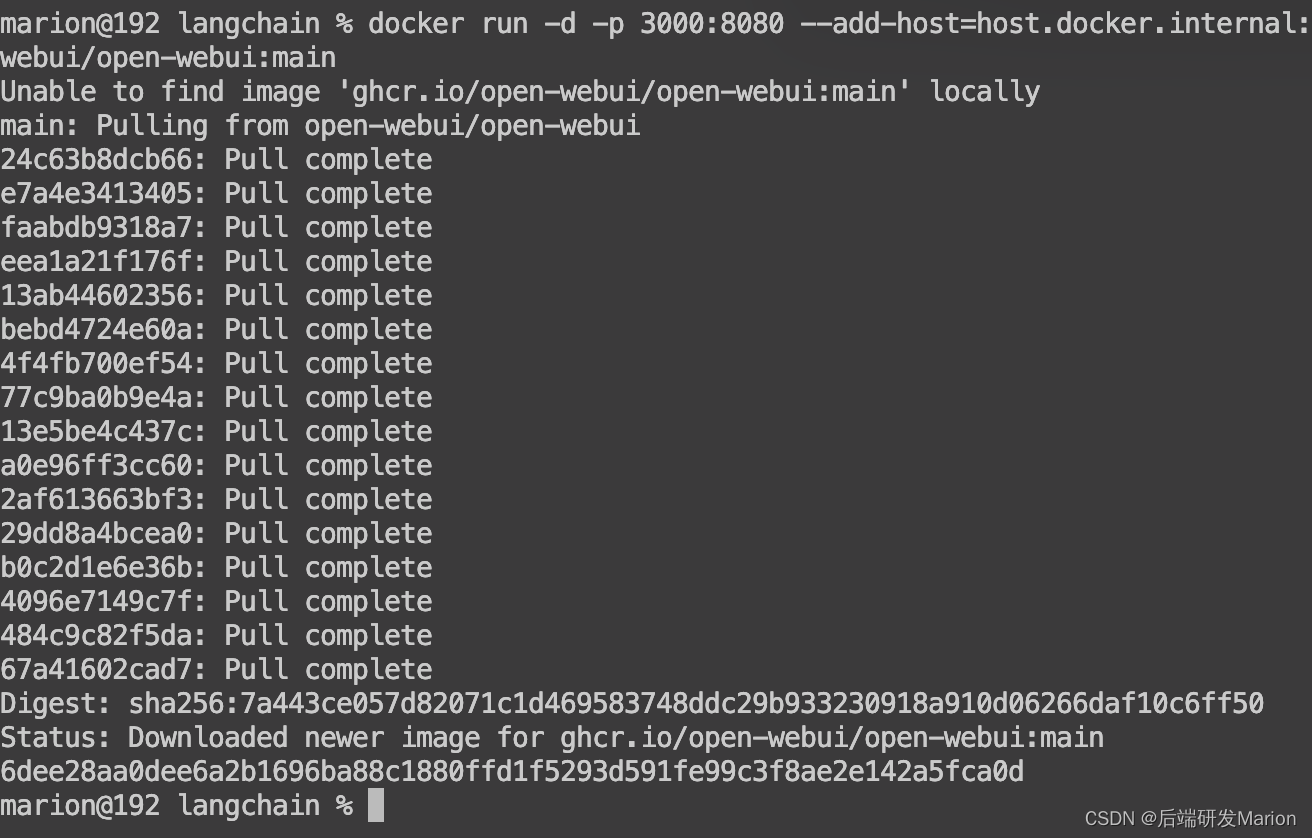
4. 安装完成
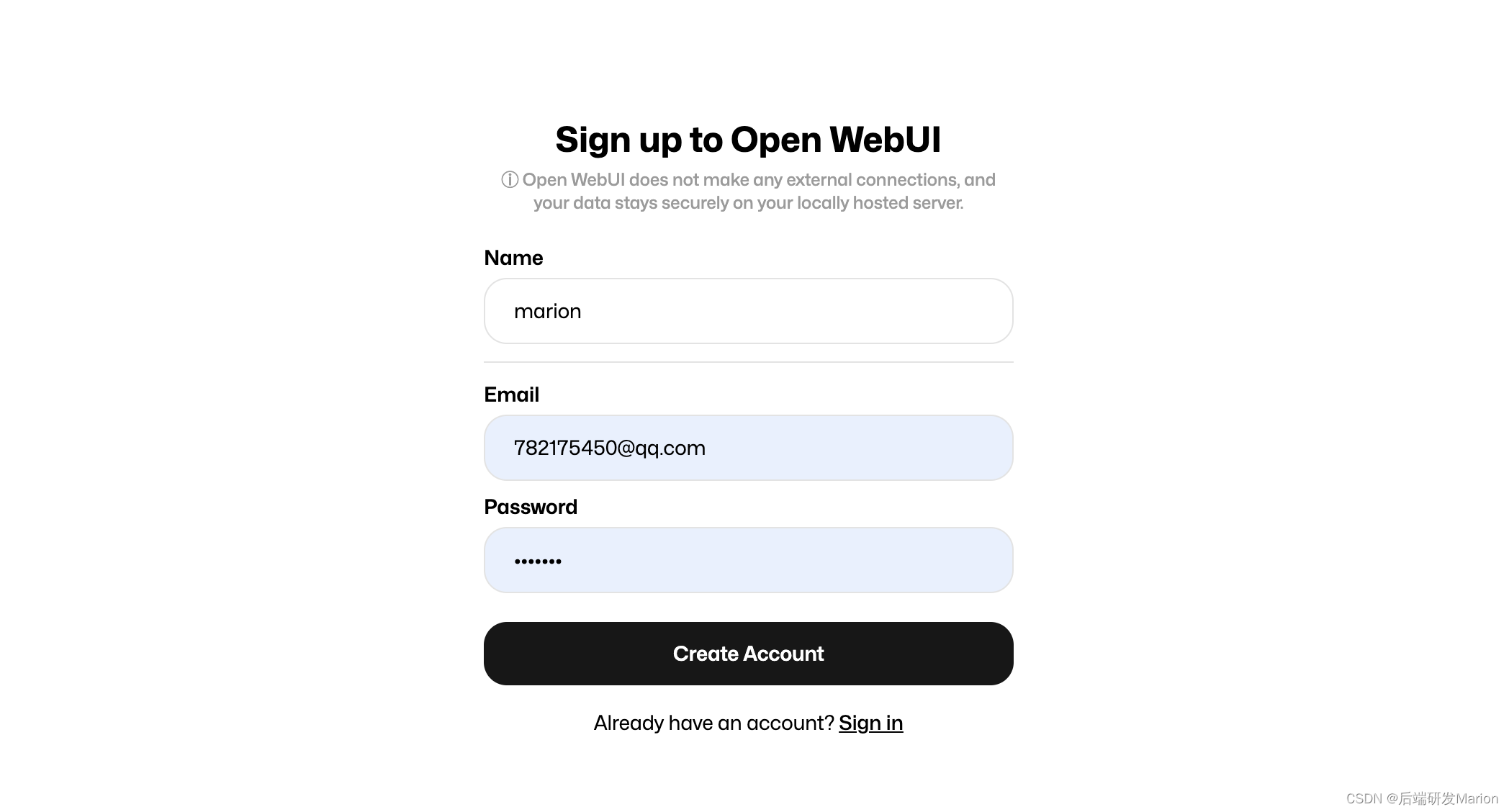
4.1 本地登陆
登陆地址 http://localhost:3000/ 注册账号登陆
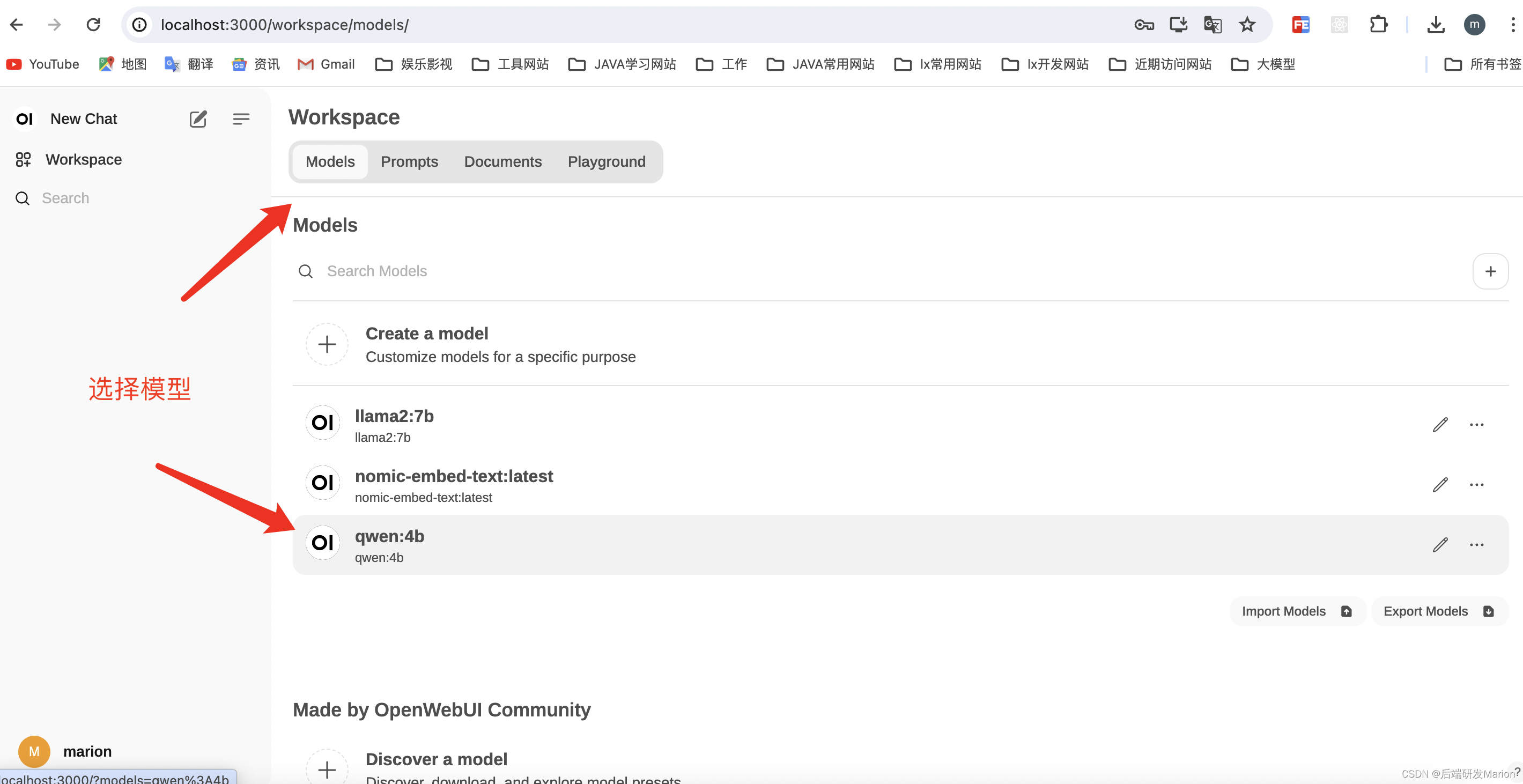
4.2 选择模型

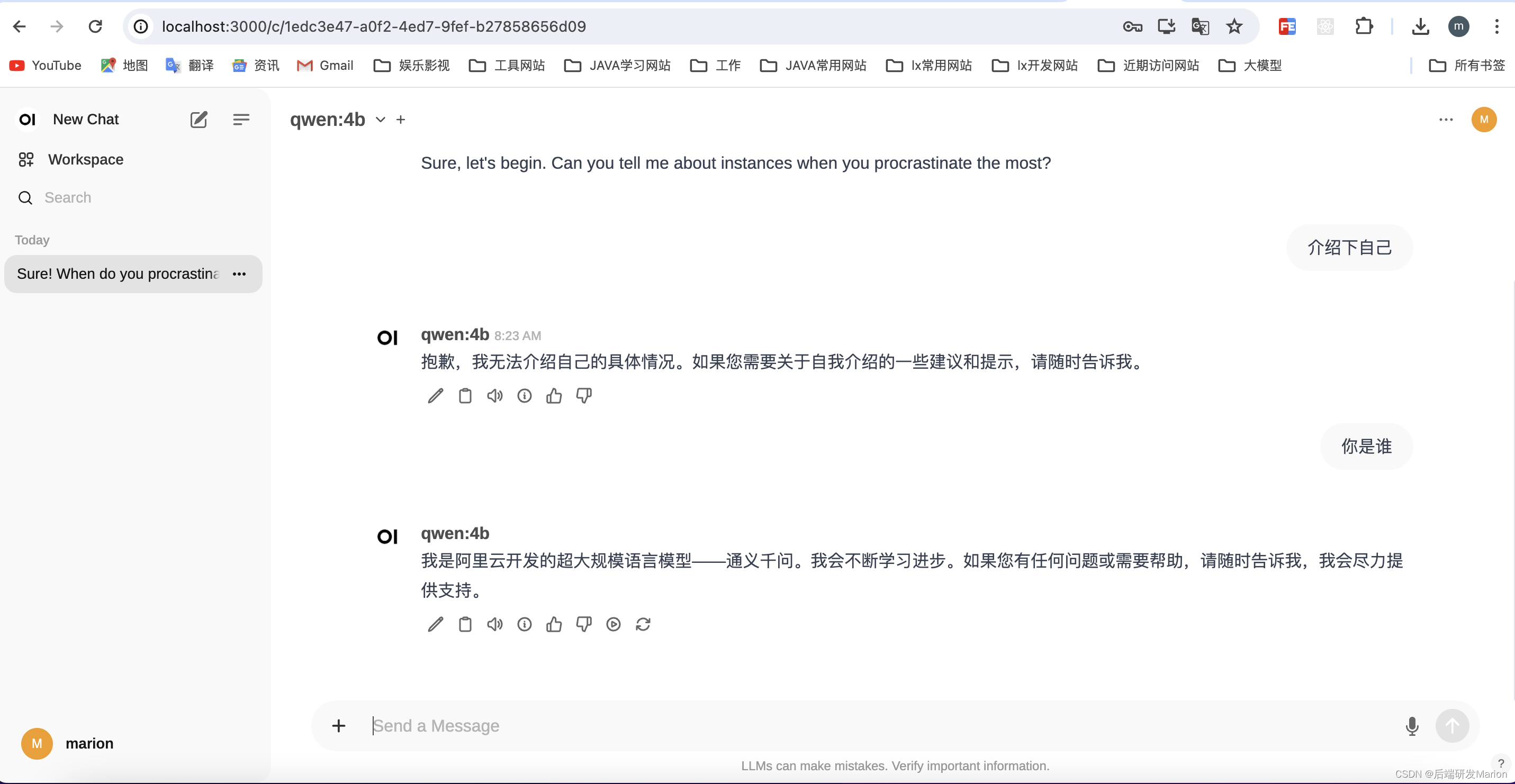
4.3 聊天
4.4 配置文本嵌入模型
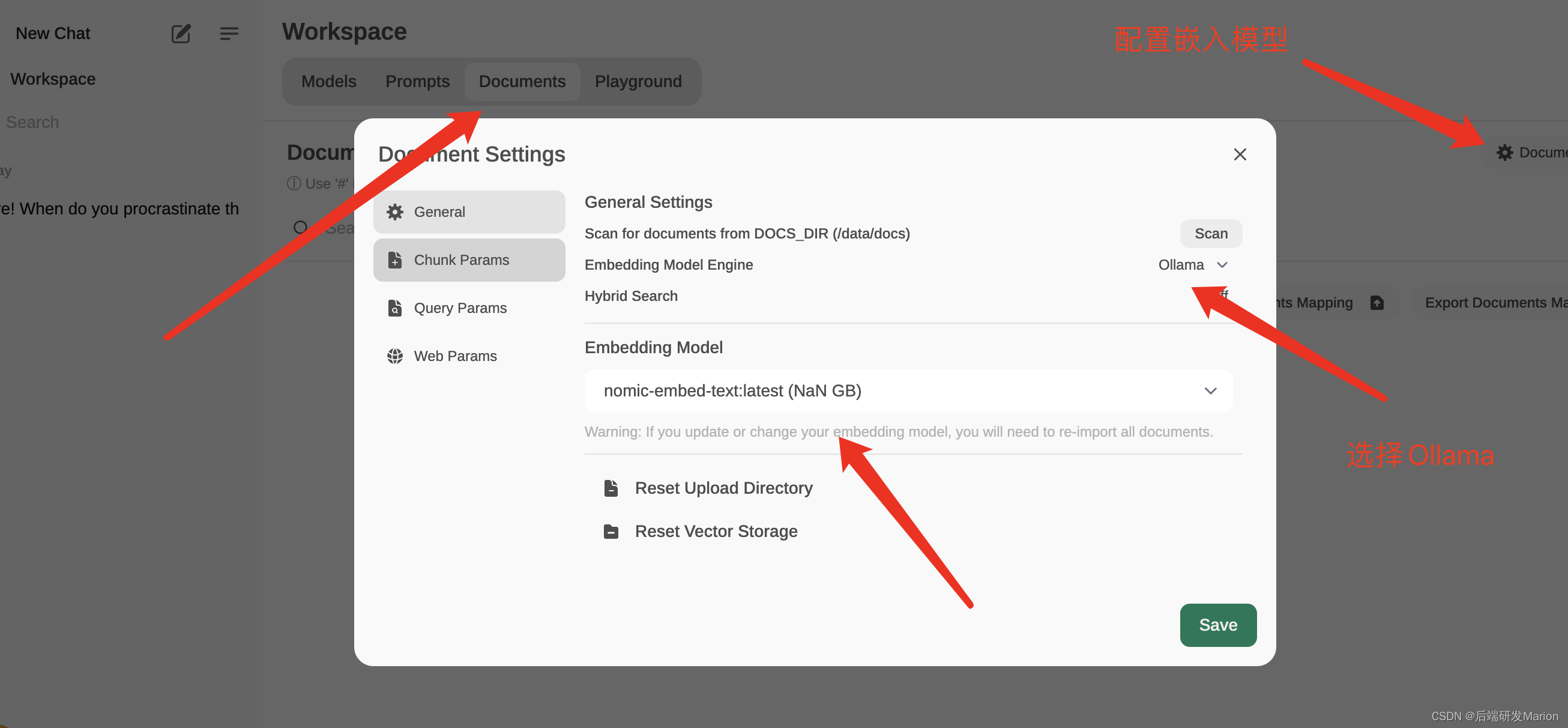
4.5 上传PDF文档
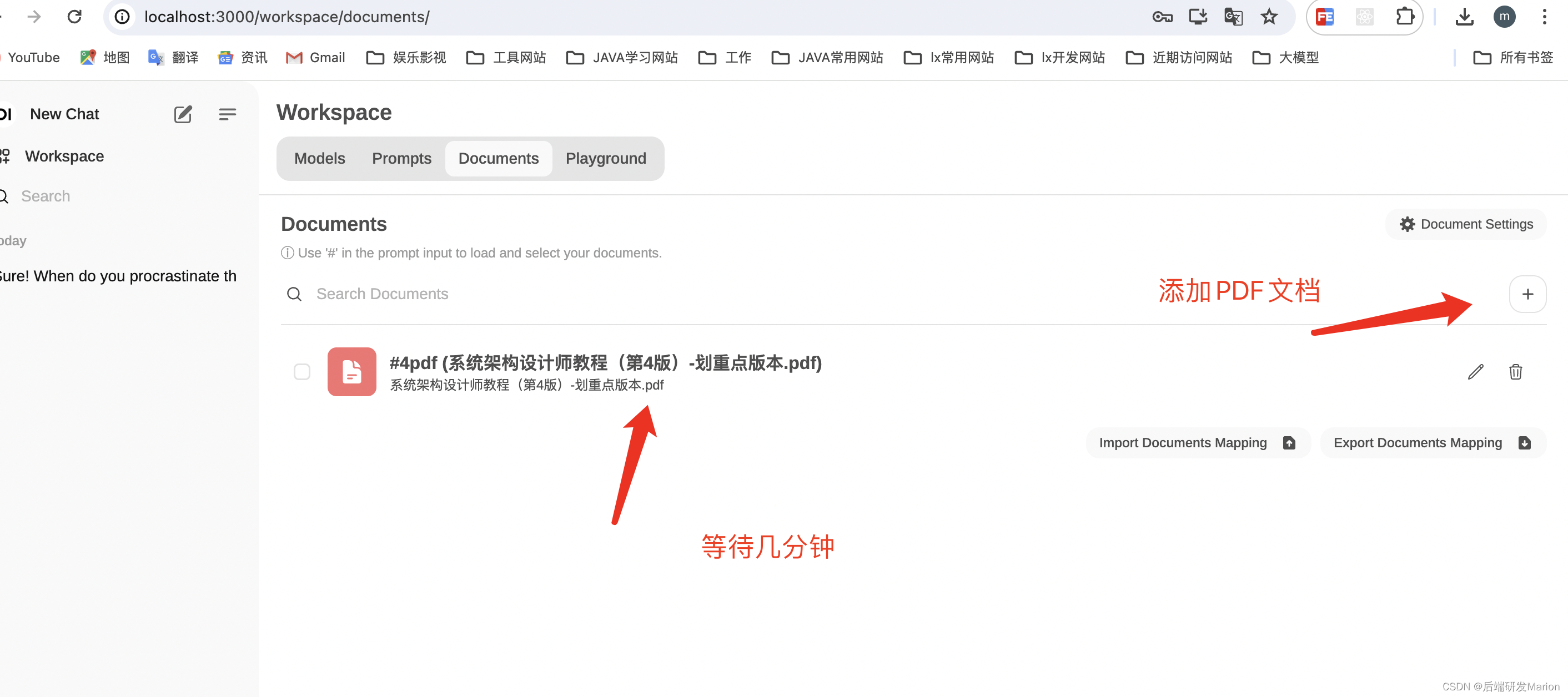
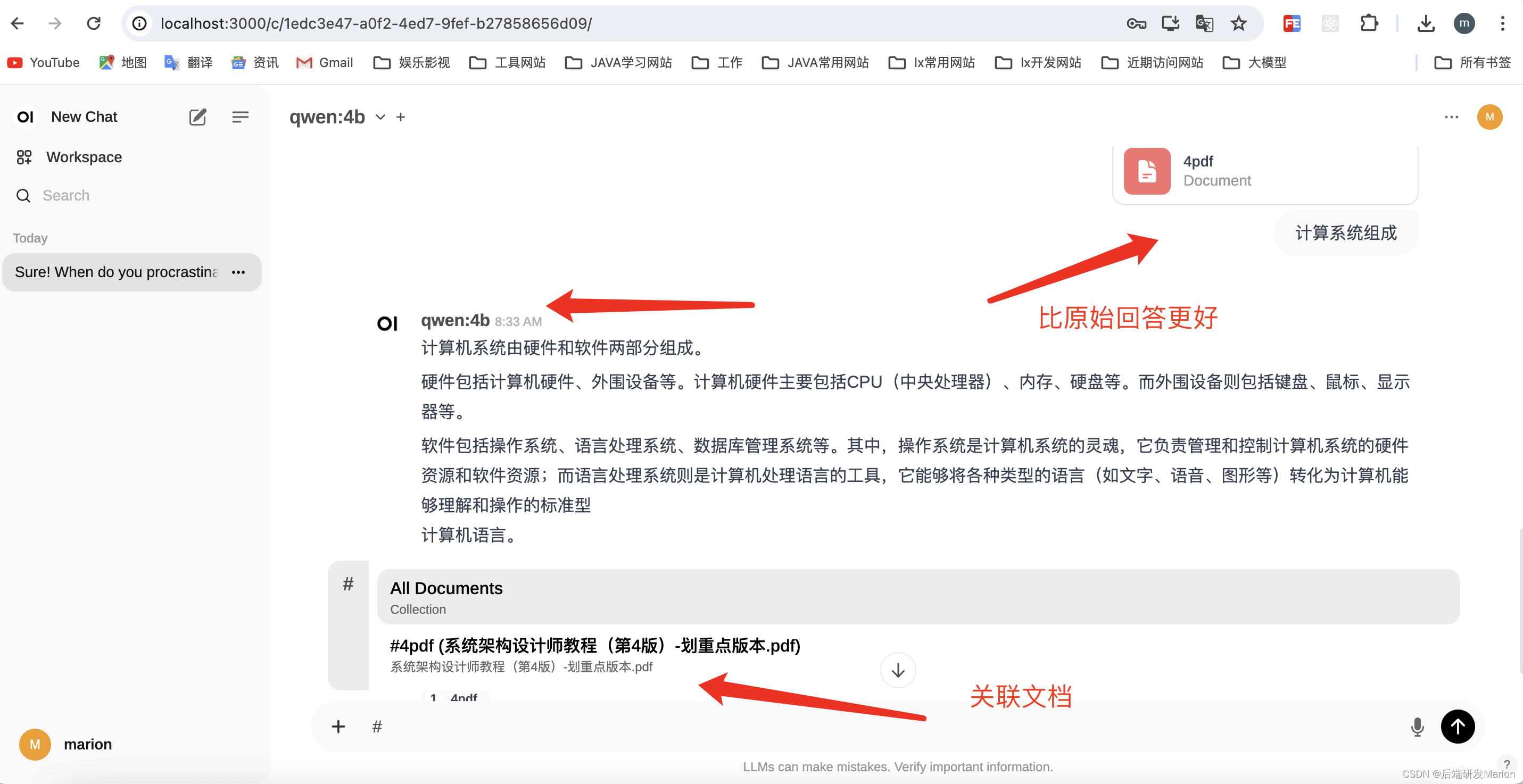
4.6 关联文档,回答问题
4. 配置本地大模型LLaMA2-7B
下载LLaMA2-7B模型:你需要从适当的来源(如Hugging Face的模型仓库)下载LLaMA2-7B模型的文件。由于模型文件可能非常大,下载可能需要一些时间。确保你有足够的存储空间来存储这些文件。配置Open-WebUI以使用LLaMA2-7B模型:Open-WebUI允许你通过配置文件或环境变量来指定要使用的模型。你需要根据你的Open-WebUI版本和配置方式,将LLaMA2-7B模型的路径或位置配置到Open-WebUI中。具体的配置方法可能因Open-WebUI版本而异,请参考Open-WebUI的官方文档或GitHub仓库中的说明进行配置。重启Open-WebUI容器:在配置完Open-WebUI以使用LLaMA2-7B模型后,你需要重启Open-WebUI容器以使配置生效。你可以使用Docker命令来停止并重新启动容器,或者如果Open-WebUI支持热重载配置,你也可以尝试重新加载配置而不必重启容器。5. 验证配置
访问Open-WebUI界面:在配置完成后,你可以通过浏览器访问本地的3000端口来访问Open-WebUI的界面。在界面上,你应该能够看到已经配置好的LLaMA2-7B模型,并可以开始使用它进行对话或其他任务。 测试LLaMA2-7B模型:在Open-WebUI界面中,你可以尝试与LLaMA2-7B模型进行对话或执行其他任务来验证配置是否正确。如果一切正常,你应该能够看到LLaMA2-7B模型对你的输入做出合理的响应。
测试LLaMA2-7B模型:在Open-WebUI界面中,你可以尝试与LLaMA2-7B模型进行对话或执行其他任务来验证配置是否正确。如果一切正常,你应该能够看到LLaMA2-7B模型对你的输入做出合理的响应。 四、使用Ollama + AnythingLLM构建类ChatGPT本地问答机器人系
学习目标
使用开源软件Ollama+AnythingLLM构建本地类ChatGPT问答机器人系统熟悉和了解基于LLM的本地RAG知识库搭建原理和逻辑,替换符合国内的LLM工具学会安装、配置、使用问答系统,找出符合企业私有化客服(对内)的产品规划逻辑对比和发现问题,寻找优劣点当在MAC上安装AnythingLLM时,以下是更详细的步骤,结合了参考文章中的信息:
1. 下载AnythingLLM
访问AnythingLLM的官方网站:Download AnythingLLM for Desktop(注意:链接可能随时间而变化,请以最新信息为准)。在下载页面选择适用于MacOS的桌面版dmg文件,点击下载。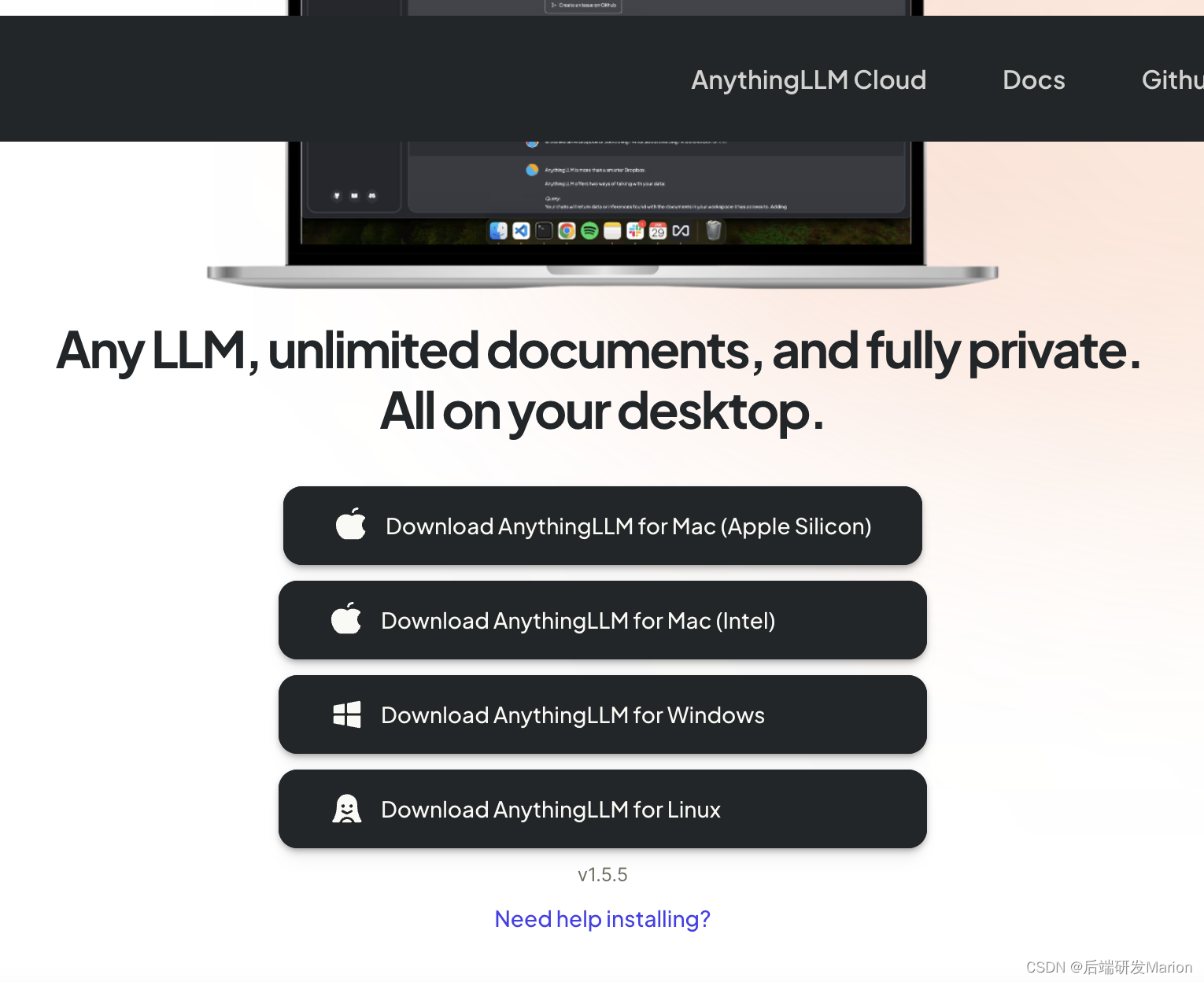
2. 安装AnythingLLM
下载完成后,找到下载的dmg文件,双击打开。跟随安装向导的指示,完成AnythingLLM的安装过程。安装完成后,打开AnythingLLM应用。初次启动可能需要一些时间进行初始化操作。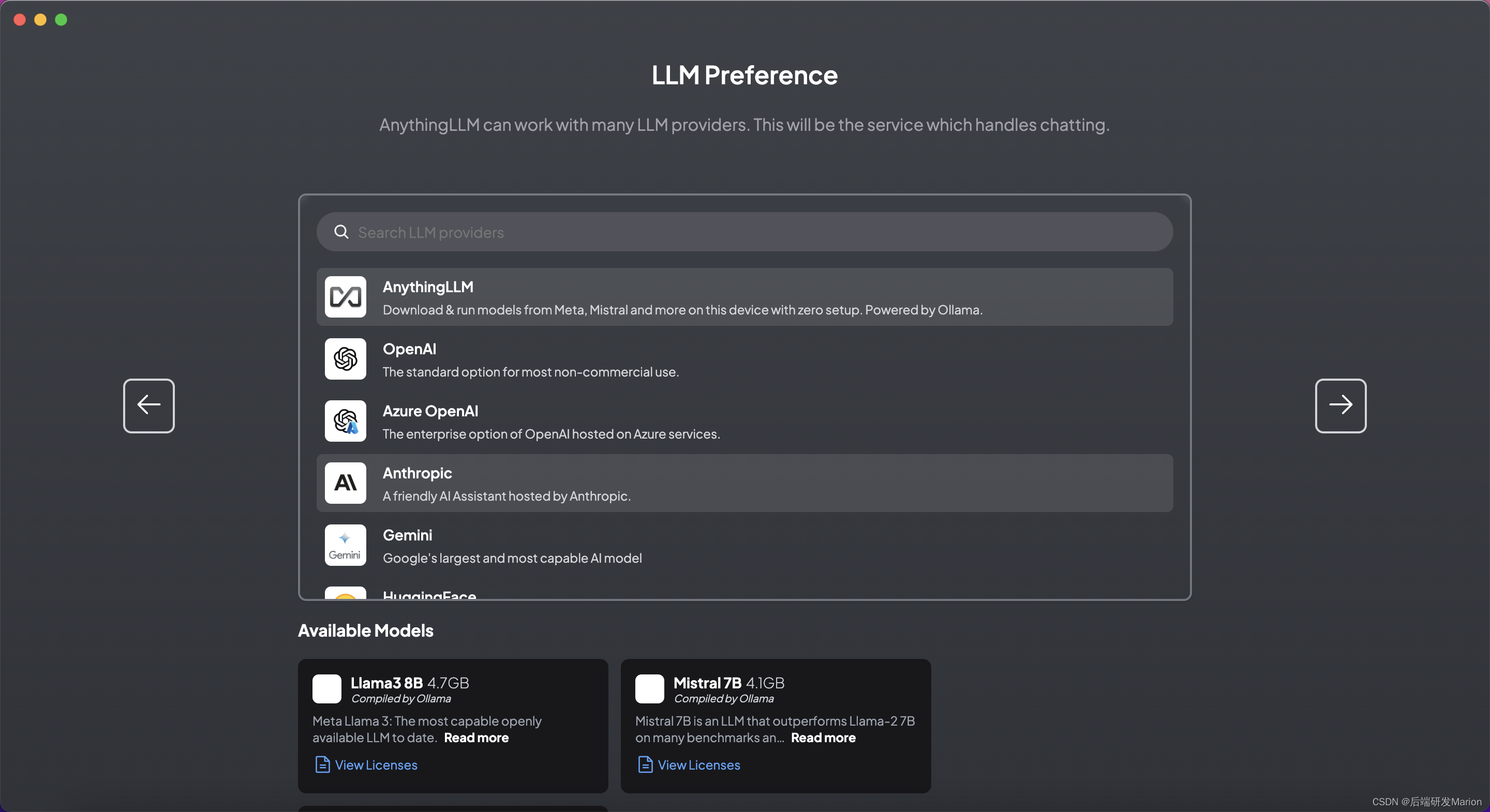

3. 配置AnythingLLM
3.1 步骤说明
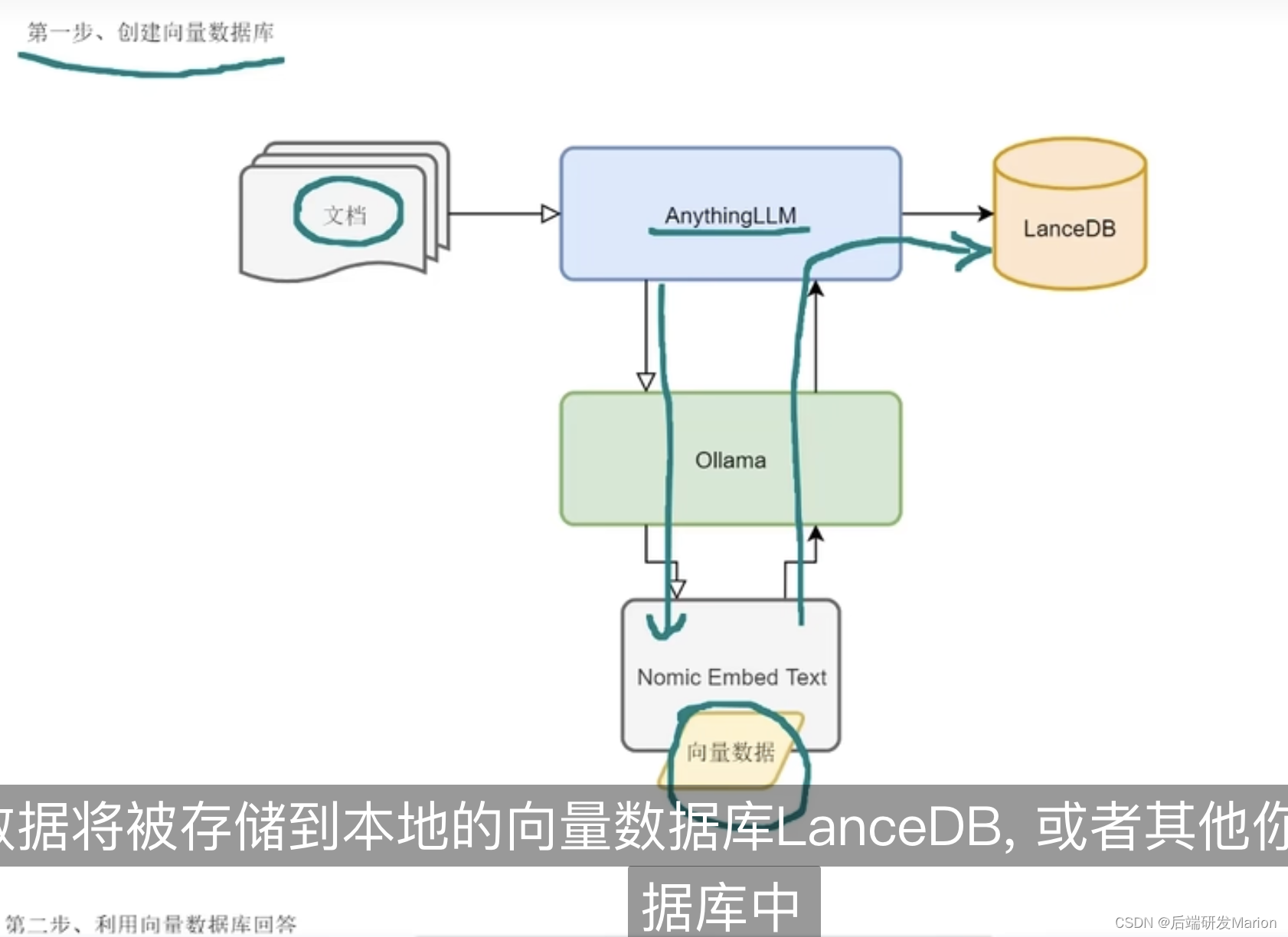

3.2 选择LLM、嵌入模型和向量数据库
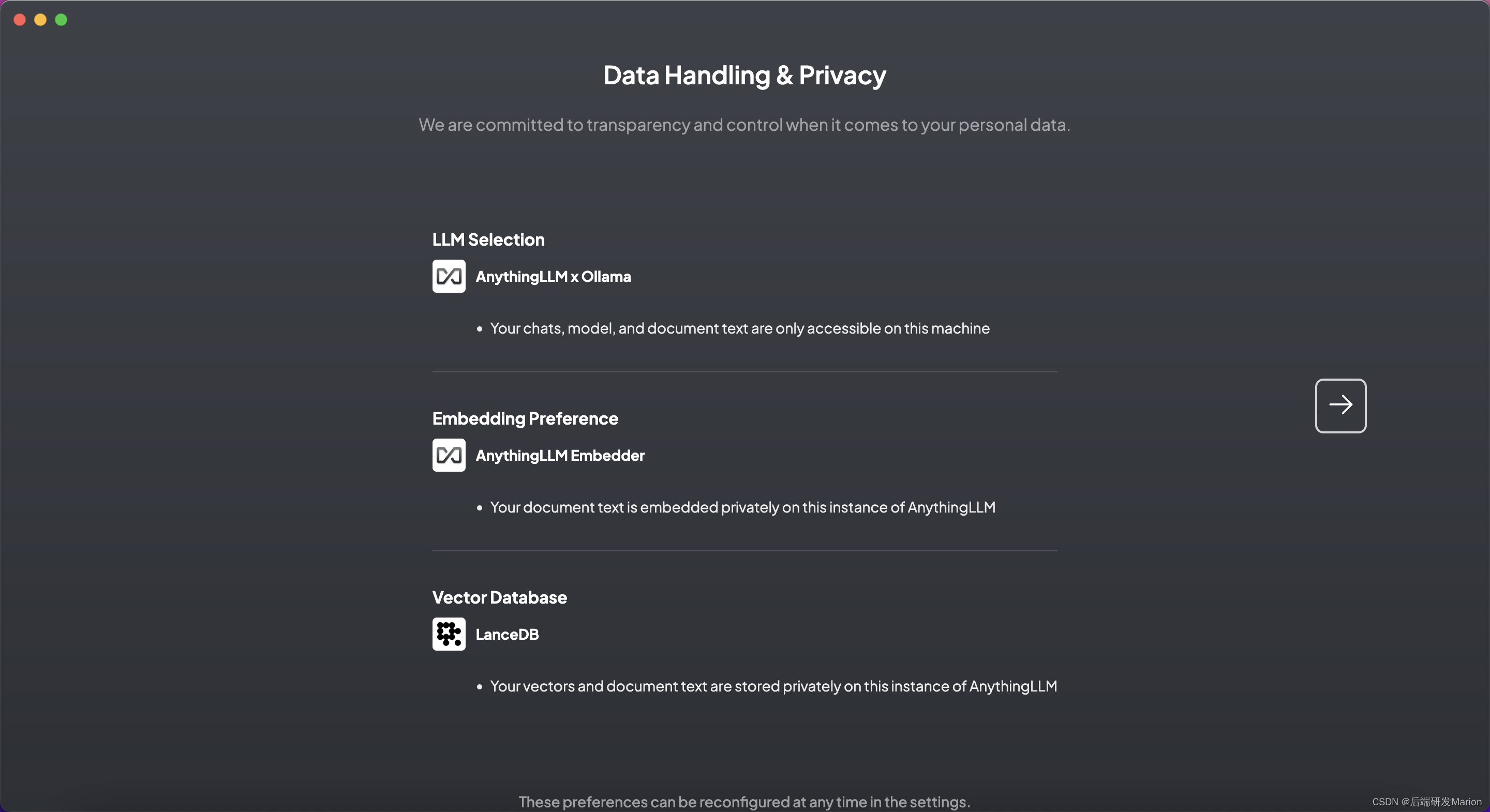
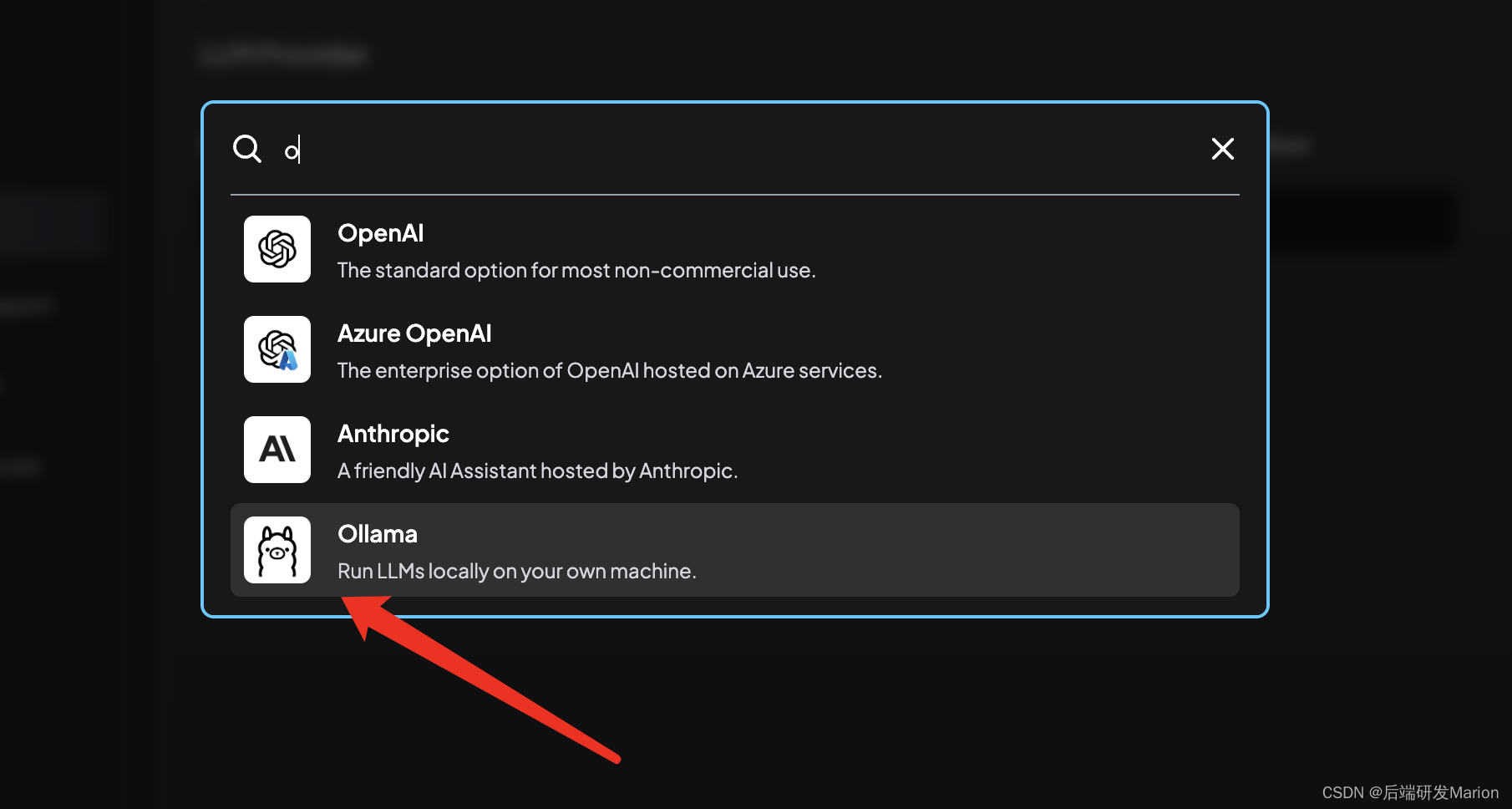
在AnythingLLM应用中,根据需求选择或下载适当的大语言模型(LLM)、嵌入模型和向量数据库。 LLM:AnythingLLM支持多种LLM,包括但不限于OpenAI的GPT系列、Gemini、Mistral等。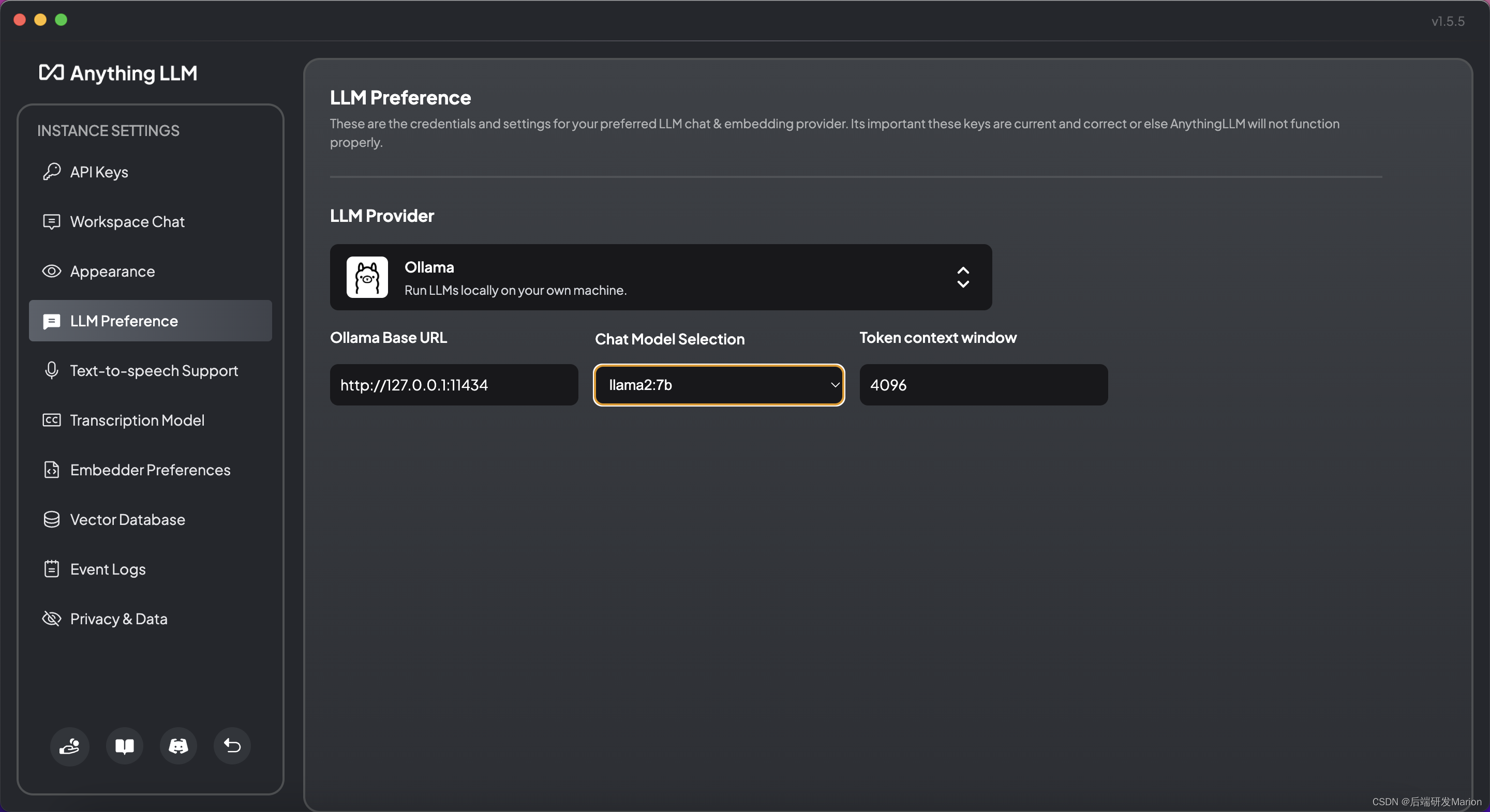 嵌入模型:可以选择内置的嵌入模型或下载其他模型,如OpenAI、LocalAi、Ollama等提供的嵌入模型。 nomic-embed-text
嵌入模型:可以选择内置的嵌入模型或下载其他模型,如OpenAI、LocalAi、Ollama等提供的嵌入模型。 nomic-embed-text
 向量数据库:默认使用内置的LanceDB,但也可以选择其他如Chroma、Milvus、Pinecone等。
向量数据库:默认使用内置的LanceDB,但也可以选择其他如Chroma、Milvus、Pinecone等。 3.3 设置环境变量(如果需要)
根据AnythingLLM的文档说明,如有需要,设置所需的环境变量,例如OLLAMA_MODELS。 3.4 权限管理(如果需要)
如果是企业级应用,可以设置多用户并进行权限管理,确保数据的安全性。4. 构建知识库
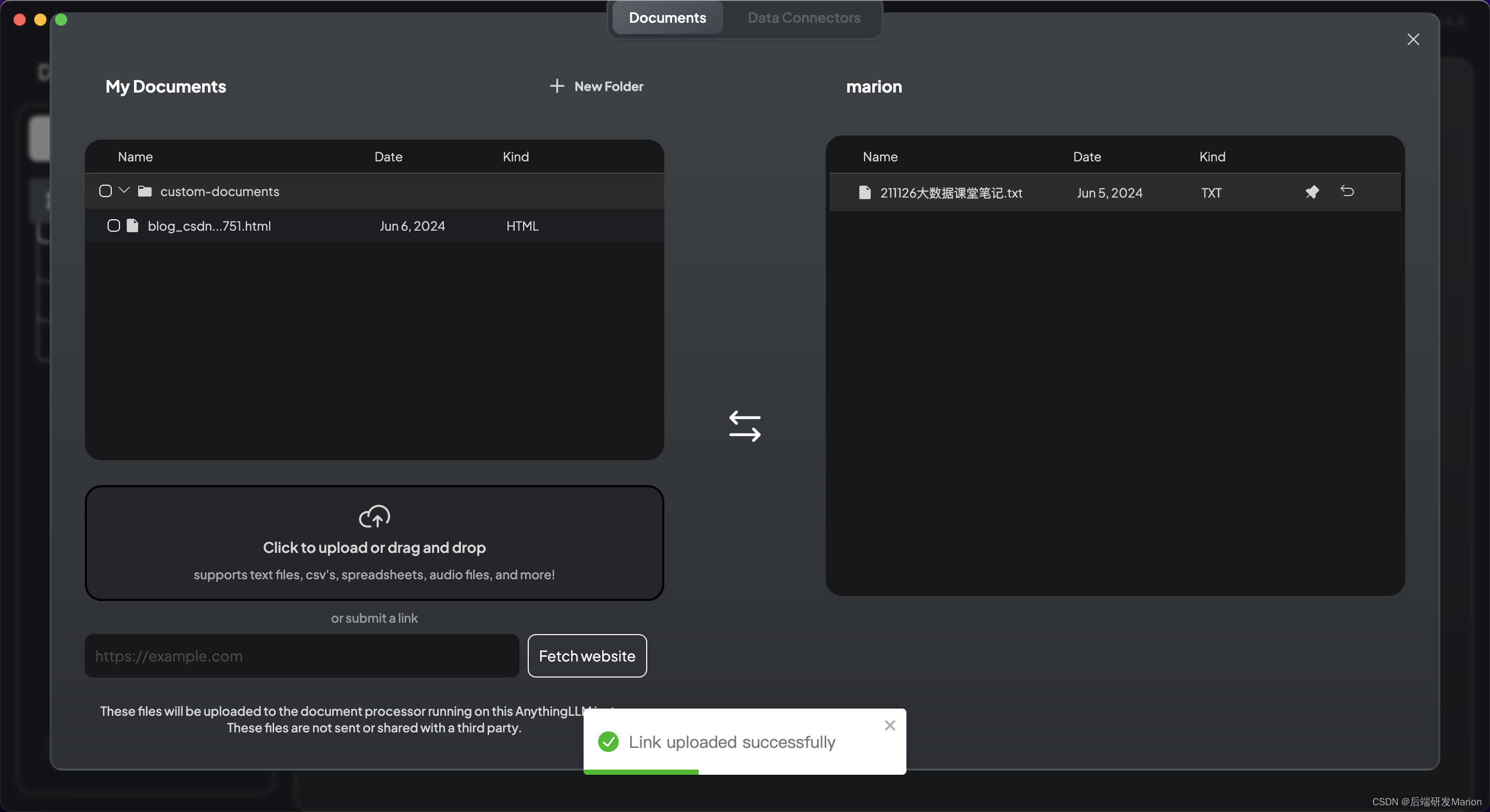
在AnythingLLM中,通过“选择知识”按钮上传文档或给定知识文件链接(支持PDF、TXT、DOCX等文档格式)。将文档通过嵌入模型转化为向量,并保存到向量数据库中。这个过程可能需要一些时间,具体取决于文档的大小和系统的性能。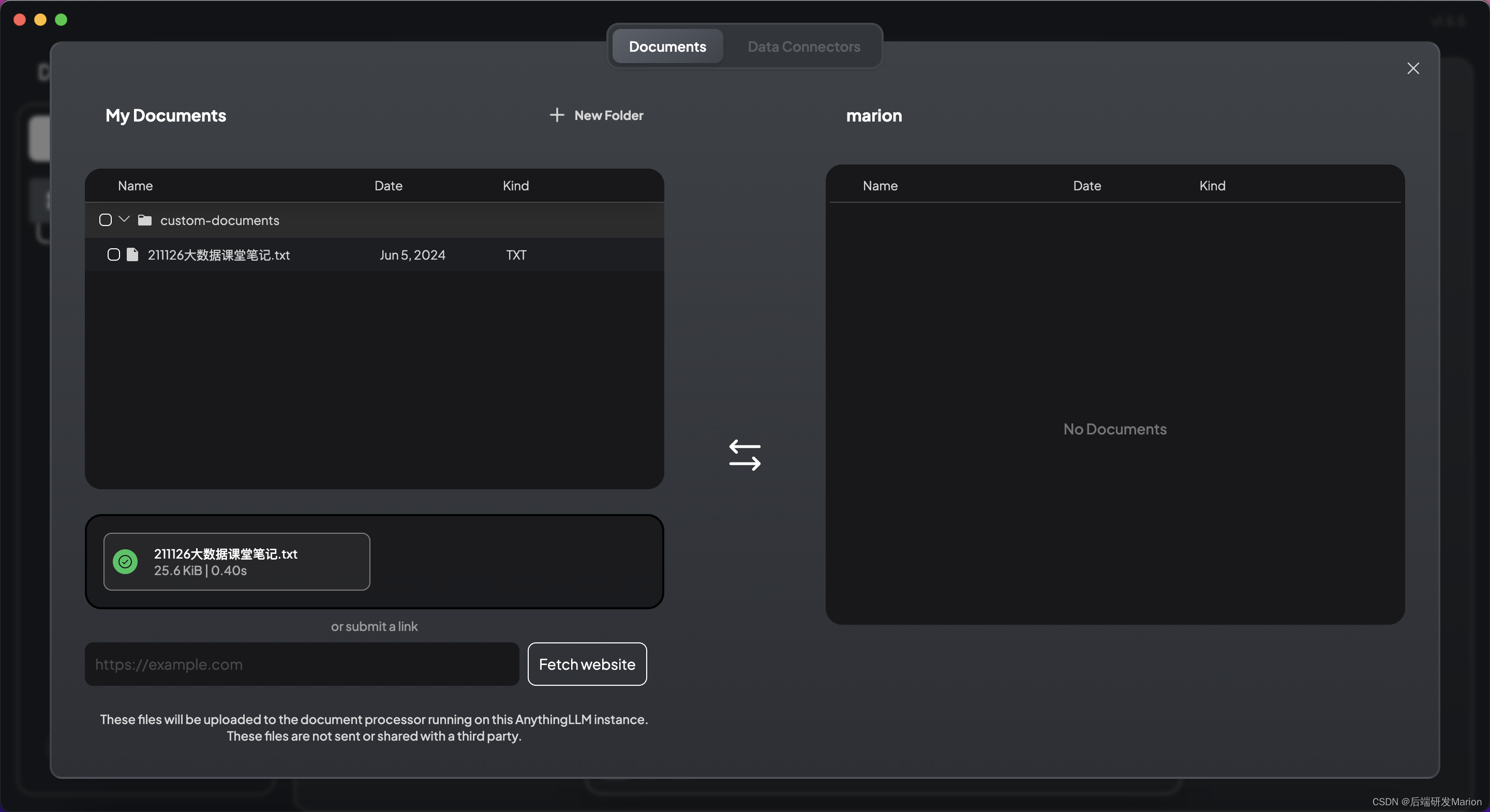
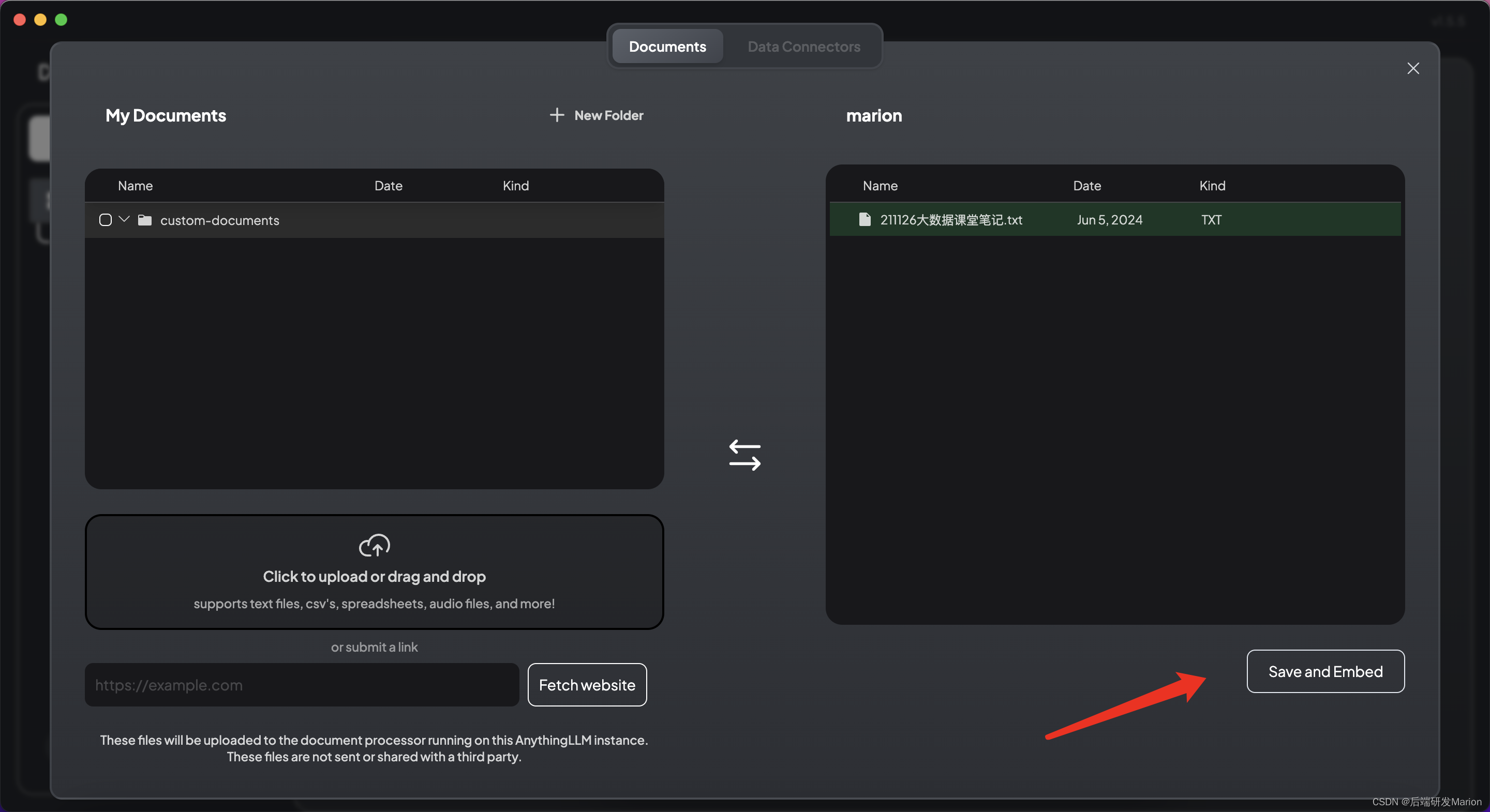
5. 开始使用
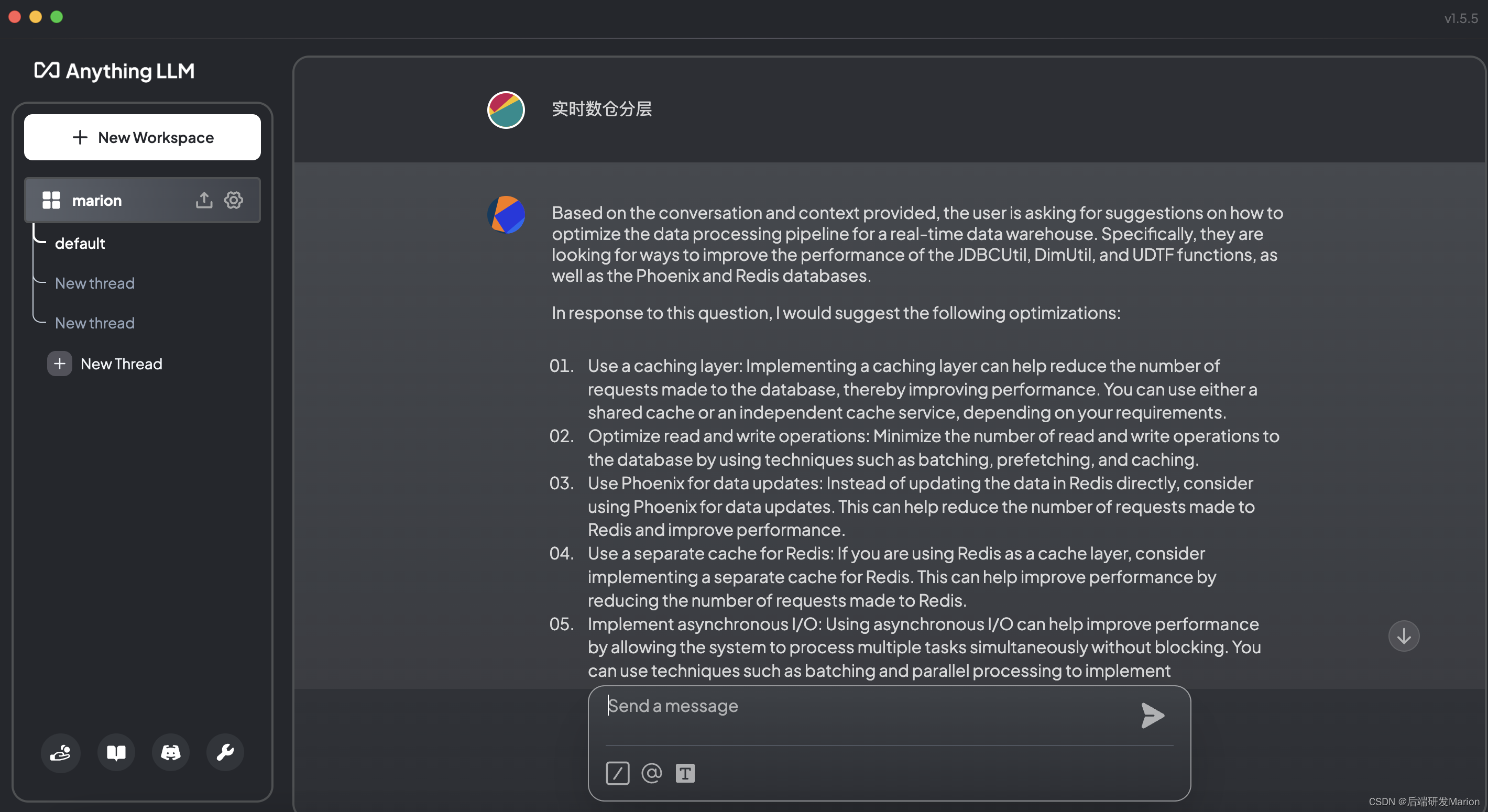
配置完成后,就可以在AnythingLLM中进行基于检索增强生成(RAG)的聊天或问答了。可以创建自己的工作区(workspace),设置不同的配置,并开始与LLM进行交互。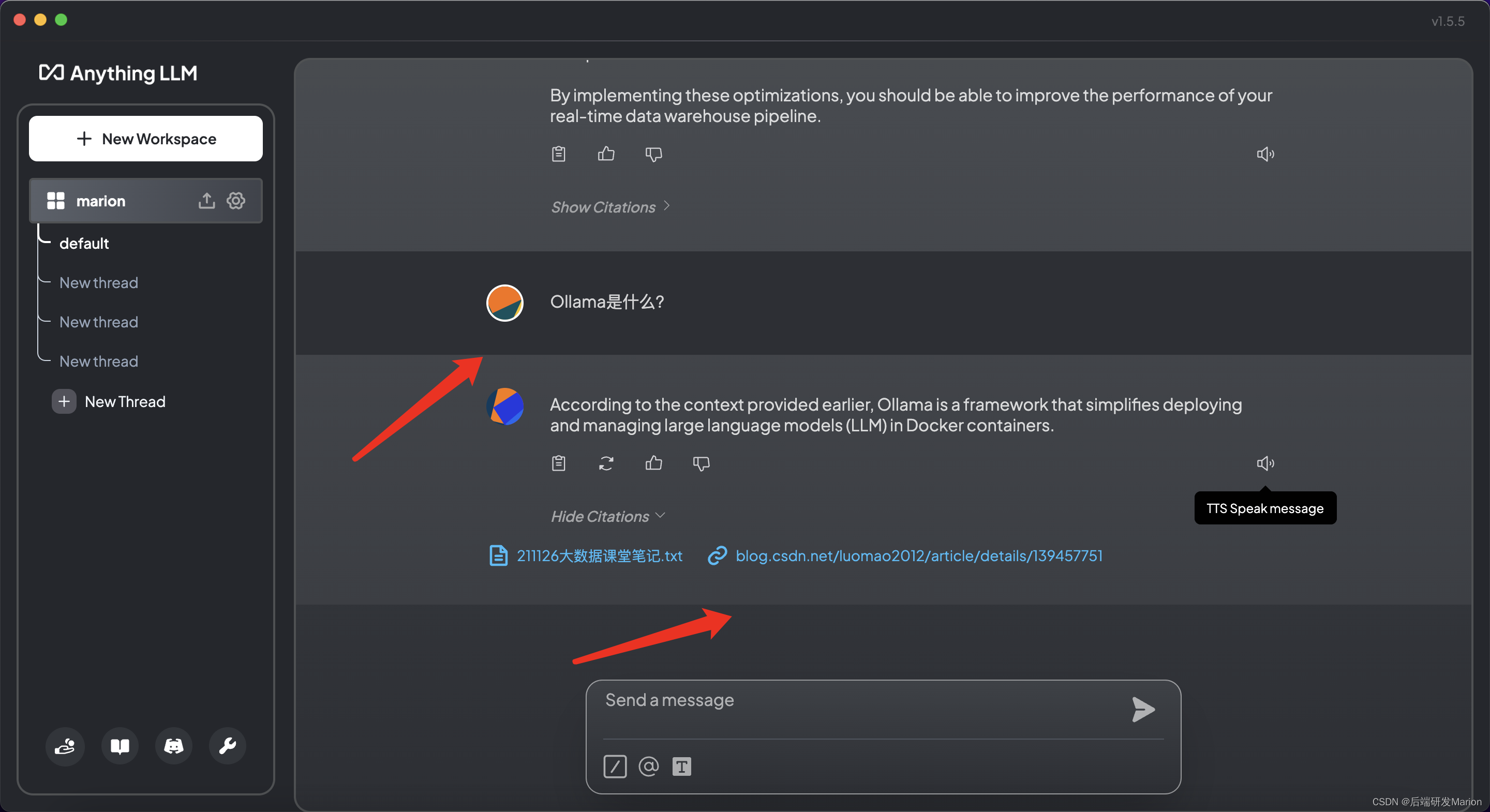
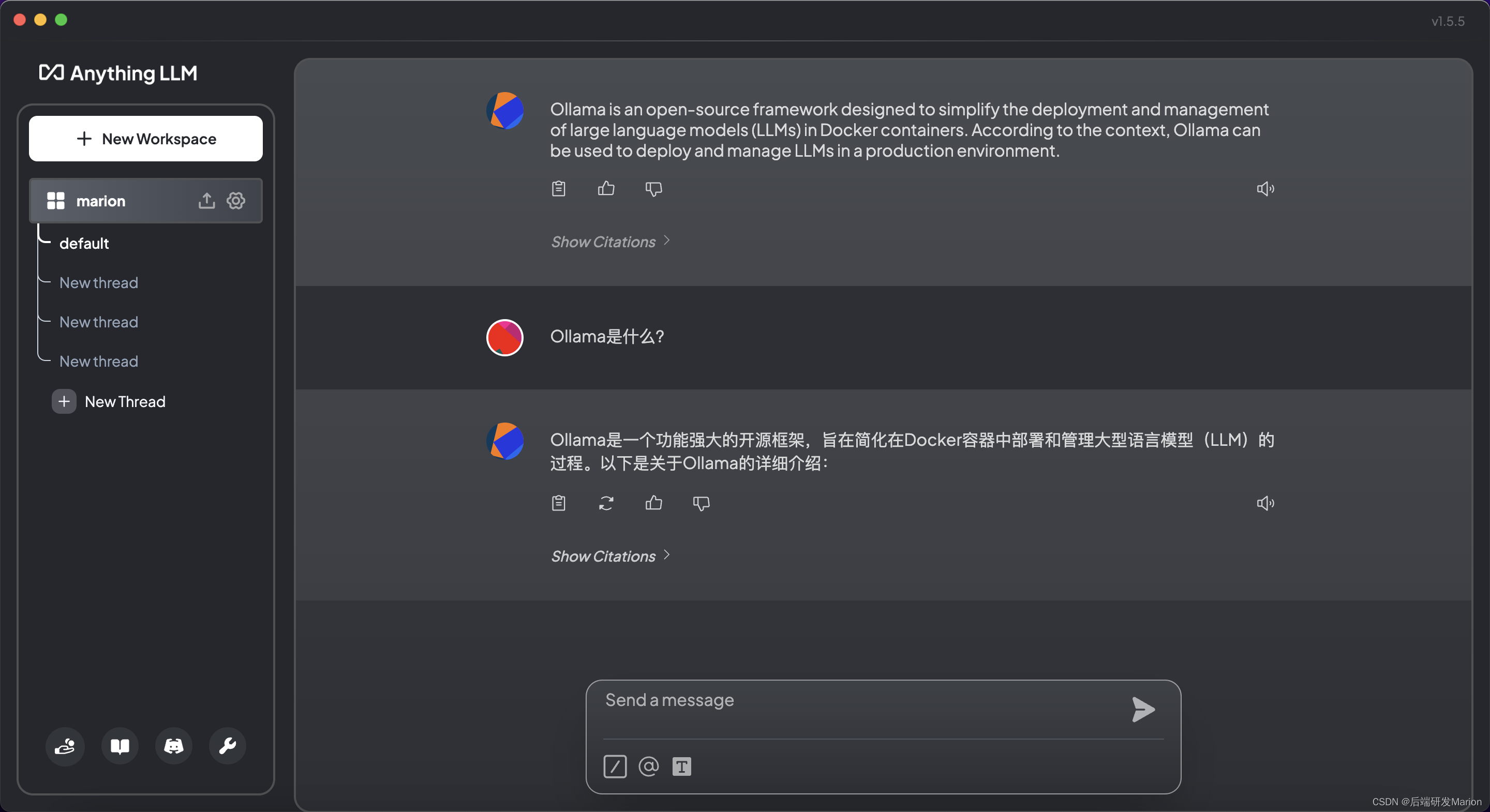
6. 自定义集成(如果需要)
如果需要,可以使用AnythingLLM的开发者API进行自定义集成,以满足特定的业务需求。7. 监控和反馈
利用AnythingLLM的遥测功能来监控应用的使用情况。如果遇到问题或需要改进,可以通过创建issue或PR来提供反馈。8. 注意事项
定期检查并更新AnythingLLM和相关的模型、嵌入模型、向量数据库,以获取最佳的性能和安全性。注意保护个人隐私和知识产权,确保上传的文档内容合法合规。9. 额外信息
AnythingLLM是一个全栈应用程序,允许用户将任何文档、资源或内容转化为任何LLM在聊天过程中可以用作参考的上下文。该应用程序支持多种LLM、嵌入器和向量数据库,并提供了多用户支持和权限管理功能。通过AnythingLLM,用户可以在本地或云端搭建个性化的聊天机器人系统,无需复杂设置。参考文章
Ollama-0001-安装
Ollama:本地大模型运行指南
ollama+open-webui,本地部署自己的大模型_ollama的webui如何部署-CSDN博客
Macbook m1安装docker详细教程_mac m1安装docker-CSDN博客
MacOS上配置docker国内镜像仓库地址_mac docker配置镜像源-CSDN博客
第九期: 使用Ollama + AnythingLLM构建类ChatGPT本地问答机器人系统 - 知乎 (zhihu.com)
AI小白使用Macbook Pro安装llama3与langchain初体验_mac安装llama3-CSDN博客
EP4 Ollama + AnythingLLM 解读本地文档 构建私有知识库_哔哩哔哩_bilibili