神经网络之手写数字
文章目录
- 神经网络之手写数字
- 00. 写在之前
- 01. 代码框架
- 02. 开始做一些准备工作
- 03. 框架的开始
- 04. 训练模型构建
- 05. 手写数字的识别
- 06. 想看源码的同学戳这里
- 07. 思考
首先鼓掌,又是一个有收获的五一小假期,想前年五一出门旅游,去年五一疫情在家写了爬虫【就是我博客里的那个口袋妖怪】,这个五一就写了一个神经网络。
代码参考学习于 python神经网络编程这本书。实话实说,这本书看了好几次,之前打算写来着,但不知道为什么总是不敢轻易尝试,今天把五一的任务的任务都完成了,早上就想给自己找点事儿干,于是就又把这本书翻出来了,打算正儿八经的写一次,但是没想到比我想象的简单那么多。咳咳。。。为啥我感觉越写越像写朋友圈???
不废话了,开始正文吧!
00. 写在之前
首先是写在之前的一些建议:
首先是关于这本书,我真的认为他是将神经网络里非常棒的一本书,但你也需要注意,如果你真的想自己动手去实现,那么你一定需要有一定的python基础,并且还需要有一些python数据科学处理能力
然后希望大家在看这边博客的时候对于神经网络已经有一些了解了,知道什么是输入层,什么是输出层,并且明白他们的一些理论,在这篇博客中我们仅仅是展开一下代码;
然后介绍一下本篇博客的环境等:
语言:Python3.8.5
环境:jupyter
库文件: numpy | matplotlib | scipy
01. 代码框架
我们即将设计一个神经网络对象,它可以帮我们去做数据的训练,以及数据的预测,所以我们将具有以下的三个方法:
- 首先我们需要初始化这个函数,我们希望这个神经网络仅有三层,因为再多也不过是在隐藏层去做文章,所以先做一个简单的。那么我们需要知道我们输入层、隐藏层和输出层的节点个数;
- 训练函数,我们需要去做训练,得到我们需要的权重。
- 通过我们已有的权重,将给定的输入去做输出。
02. 开始做一些准备工作
现在我们需要准备一下:
- 将我们需要的库导入
import numpy as np
import scipy.special as spe
import matplotlib.pyplot as plt
- 构建一个类
class neuralnetwork:
# 我们需要去初始化一个神经网络
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
pass
def train(self, inputs_list, targets_list):
pass
def query(self, inputs_list):
pass
- 我们的主函数
input_nodes = 784 # 输入层的节点数
hidden_nodes = 88 # 隐藏层的节点数
output_nodes = 10 # 输出层的节点数
learn_rate = 0.05 # 学习率
n = neuralnetwork(input_nodes, hidden_nodes, output_nodes, learn_rate)
- 导入文件
data_file = open("E:\sklearn_data\神经网络数字识别\mnist_train.csv", 'r')
data_list = data_file.readlines()
data_file.close()
file2 = open("E:\sklearn_data\神经网络数字识别\mnist_test.csv")
answer_data = file2.readlines()
file2.close()
这里需要介绍以下这个数据集,训练集在这里,测试集在这里
03. 框架的开始
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes # 输入层节点设定
self.hnodes = hiddennodes # 影藏层节点设定
self.onodes = outputnodes # 输出层节点设定
self.lr = learningrate # 学习率设定,这里可以改进的
self.wih = (np.random.normal(0.0, pow(self.hnodes, -0.5),(self.hnodes, self.inodes))) # 这里是输入层与隐藏层之间的连接
self.who = (np.random.normal(0.0, pow(self.onodes, -0.5),(self.onodes, self.hnodes))) # 这里是隐藏层与输出层之间的连接
self.activation_function = lambda x: spe.expit(x) # 返回sigmoid函数
Δ w j , k = α ∗ E k ∗ sigmoid ( O k ) ∗ ( 1 − sigmoid ( O k ) ) ⋅ O j ⊤ \Delta w_{j, k}=\alpha * E_{k} * \text { sigmoid }\left(O_{k}\right) *\left(1-\operatorname{sigmoid}\left(O_{k}\right)\right) \cdot O_{j}^{\top} Δwj,k=α∗Ek∗ sigmoid (Ok)∗(1−sigmoid(Ok))⋅Oj⊤
def query(self, inputs_list):
inputs = np.array(inputs_list, ndmin=2).T # 输入进来的二维图像数据
hidden_inputs = np.dot(self.wih, inputs) # 隐藏层计算,说白了就是线性代数中的矩阵的点积
hidden_outputs = self.activation_function(hidden_inputs) # 将隐藏层的输出是经过sigmoid函数处理
final_inputs = np.dot(self.who, hidden_outputs) # 原理同hidden_inputs
final_outputs = self.activation_function(final_inputs) # 原理同hidden_outputs
return final_outputs # 最终的输出结果就是我们预测的数据
这里我们对预测这一部分做一个简单的解释:我们之前的定义输出的节点是10个,对应的是十个数字。
而为什么会通过神经网络能达到这个亚子,我推荐这本书深度学习的数学 这本书的理论讲解非常不错!!!
04. 训练模型构建
之前的部分相对而言还是比较简单的,那么接下来就是如何去构建训练模型了。
def train(self, inputs_list, targets_list):
# 前期和识别过程是一样的,说白了我们与要先看看现在的预测结果如何,只有根据这次的预期结果才能去修改之前的权重
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
# 接下来将标签拿迟来
targets = np.array(targets_list, ndmin=2).T
# 得到我们的数据预测的误差,这个误差将是向前反馈的基础
output_errors = targets - final_outputs
# 这部分是根据公式得到的反向传播参数
hidden_errors = np.dot(self.who.T, output_errors)
# 根据我们的反馈参数去修改两个权重
self.who += self.lr * np.dot((output_errors * final_outputs * ( 1.0-final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0-hidden_outputs)), np.transpose(inputs))
如此我们的基础神经网络构建完成了。
05. 手写数字的识别
接下来神经网络是完成的,那么我们究竟该如何去将数据输入呢?
csv文件我们并不陌生【或许陌生?】,他是逗号分割文件,顾名思义,它是通过逗号分隔的,所以我们可以打开看一下:
眼花缭乱!!
但是细心的我们可以发现他的第一个数字都是0~9,说明是我们的标签,那么后面的应该就是图像了,通过了解我们知道这个后面的数据是一个28*28的图像。
all_value = data_list[0].split(',') # split分割成列表
image_array = np.asfarray(all_value[1:]).reshape((28,28)) # 将数据reshape成28*28的矩阵
plt.imshow(image_array, cmap='Greys', interpolation='None') # 展示一下
通过这段代码,我们可以简单的看一下每个数字是什么:
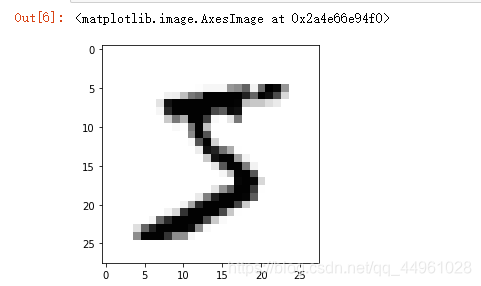
很好,知道这里就足够了,那么我们接下来就是将这些数据传入了!
我们在训练的时候,需要将他们都转化成数字列表,方便处理
data = [] # 用来保存训练过程的数据
sum_count = 0 # 统计总识别的正确的个数
for i in range(15): # 训练的轮数
count = 0 # 单次训练识别正确的个数
for j in range(len(data_list)): # 对60000张图片开始训练, 没有划分数据集的过程主要是别人直接给了,我也懒得自己去做了,主要就是展示一下神经网络嘛~
target = np.zeros(10)+0.01 # 生成初始标签集合,用来和结果对比
line_ = data_list[j].split(',') # 对每一行的数据处理切割
imagearray = np.asfarray(line_) # 将切割完成的数据转换成数字列表
target[int(imagearray[0])] = 1.0 # 将正确答案挑出来
n.train(imagearray[1:]/255*0.99+0.01, target) # 丢入训练,丢入的时候注意将数据转换成0.01~1.0之间的结果
for line in answer_data: # 对10000组测试集测试
all_values = line.split(',')
answer = n.query((np.asfarray(all_values[1:])/255*0.99)+0.01)
if answer[int(all_values[0])] > 0.85: # 查看对应位置是否达到自定义的阈值?
count += 1
sum_count += count
string = "训练进度 %05f\n本轮准确度 %05f\n总准确度 %05f\n\n"%(i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1)))
data.append([i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1))]) # 将数据保存方便生成训练曲线
print(string)
```
接下来我们将结果图片展示以下吧~
```python
data = np.array(data)
plt.plot(range(len(data)), data[:, 1:])
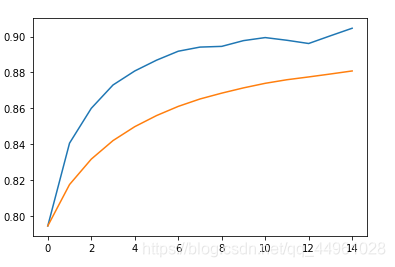
06. 想看源码的同学戳这里
把源码整理一下贴出来
import numpy as np
import scipy.special as spe
import matplotlib.pyplot as plt
class neuralnetwork:
# 我们需要去初始化一个神经网络
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.lr = learningrate
self.wih = (np.random.normal(0.0, pow(self.hnodes, -0.5),(self.hnodes, self.inodes)))
self.who = (np.random.normal(0.0, pow(self.onodes, -0.5),(self.onodes, self.hnodes)))
self.activation_function = lambda x: spe.expit(x) # 返回sigmoid函数
def train(self, inputs_list, targets_list):
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
targets = np.array(targets_list, ndmin=2).T
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors)
self.who += self.lr * np.dot((output_errors * final_outputs * ( 1.0-final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0-hidden_outputs)), np.transpose(inputs))
def query(self, inputs_list):
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
input_nodes = 784
hidden_nodes = 88
output_nodes = 10
learn_rate = 0.05
n = neuralnetwork(input_nodes, hidden_nodes, output_nodes, learn_rate)
data_file = open("E:\sklearn_data\神经网络数字识别\mnist_train.csv", 'r')
data_list = data_file.readlines()
data_file.close()
file2 = open("E:\sklearn_data\神经网络数字识别\mnist_test.csv")
answer_data = file2.readlines()
file2.close()
data = []
sum_count = 0
for i in range(15):
count = 0
for j in range(len(data_list)):
target = np.zeros(10)+0.01
line_ = data_list[j].split(',')
imagearray = np.asfarray(line_)
target[int(imagearray[0])] = 1.0
n.train(imagearray[1:]/255*0.99+0.01, target)
for line in answer_data:
all_values = line.split(',')
answer = n.query((np.asfarray(all_values[1:])/255*0.99)+0.01)
if answer[int(all_values[0])] > 0.85:
count += 1
sum_count += count
string = "训练进度 %05f\n本轮准确度 %05f\n总准确度 %05f\n\n"%(i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1)))
data.append([i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1))])
print(string)
data = np.array(data)
plt.plot(range(len(data)), data[:, 1:])
可以说是相对简单的一个程序,但却是包含着神经网络最基础的思想!值得好好康康~
07. 思考
- 如何识别其他手写字体等?
我的想法:通过图像处理,将像素规定到相近大小【尺度放缩】
- 图像大小运行速度问题
我的想法:如何快速的矩阵运算,通过C语言是否可以加速?相较于darknet这个神经网络仅有三层,运算速度并不是十分理想。当然cuda编程对于GPU加速肯定是最好的选择之一。
总结一下,真实学海无涯啊!