

目录
一、前言
二、正文
1.位图
1.1 位图概念
1.2 位图的实现
1.2.1 Set
1.2.2 ReSet
1.2.3 Text
1.3 位图的应用
2.布隆过滤器
2.1布隆过滤器的提出
2.2 布隆过滤器概念
2.3 布隆过滤器的实现
2.3.1布隆过滤器的插入
2.3.2 布隆过滤器的查找
2.3.3 布隆过滤器的删除
2.3.4 布隆过滤器优点
2.3.4 布隆过滤器缺陷
3.海量数据面试题
3.1哈希切割
3.2位图应用
3.3布隆过滤器
三、全部代码
四、结语
一、前言
在上一篇博客中,笔者为大家带来了哈希的介绍及其模拟实现,那么哈希有哪些应用场景呢,在这篇文章中,就为大家带来位图和布隆过滤器的讲解。
二、正文
1.位图
1.1 位图概念
在进行位图的讲解之前,小伙伴们可以先看看下面来自腾讯面试中的一道题目,想想如果是你的话,该如何解决呢?
Q:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。【腾讯】
看完以后,综合我们之前所学过的知识,小伙伴们可能会有两种解决思路:
①遍历——时间复杂度O(N)
②排序后再利用二分查找——时间复杂度 NlogN+logN
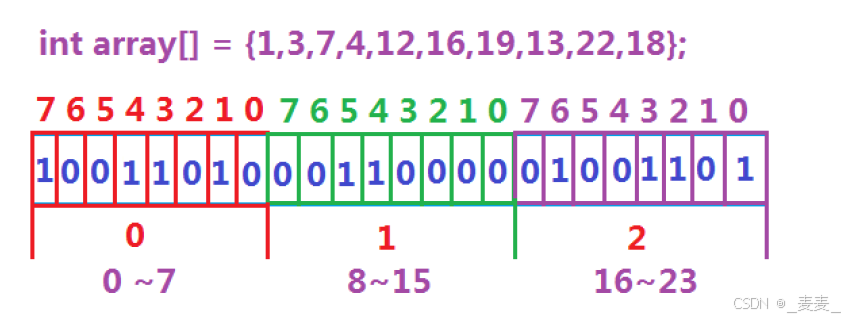
但是无论是上面哪种方法,都将面临一个问题,就是要处理的数据有40亿个,数据量约为16G(整型4个字节,10亿字节约为1G),想要存储这些数据所需要的空间太大了,那么有没有更好的方法呢,这时候就可以引入位图了,由于我们只是需要判断这个数是否在这40亿个数中,其实我们并不需要存储这40亿个整数,只需要通过一个标志位来记录整数是否存在,这样原本至少需要耗费4个字节才能表征的整型,我们只需要一个比特位就可以来代替了,数据量就从原来的16G变为了500M(4字节=4*8=32byte),数据量就大大缩小了,与此同时检索的效率也变成了O(1),这是因为我们将一个个数据通过直接定址分配到了整型数组的每一个比特位,只需通过数据所对应的地址上的比特位是否为1,我们就能判断其是否存在。具体解决可见下图:
那么到底什么是位图呢?所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
1.2 位图的实现
既然在处理海量数据的时候,位图的威力这么大,接下来我们就为大家进行位图的模拟实现,主要实现的有三个接口,分别是:Set,Reset和Text。
1.2.1 Set
Set这个接口的功能主要是将整型在对应数组中的那个比特位置1,来表征其存在。
实现这个接口主要利用的是我们在C语言阶段学习的位操作。由于本篇中我们采取的是整型数组来模拟实现,因此我们在实现Set的第一步是确定整型在该数组中位于第几个整型的第几个比特位,通过除以一个整型的大小,即32个bit,我们可以的得到其位于第几个整型(i);对32取摩就可以得到其位于该整型的第几个bit位(j)。eg:整型33就可以通过上述直接定址法定位到第二个整型的下标为1的比特位。在定位成功后,第二步就是将对应比特位置1,我们只需要对该整形1左移j位就可以实现该操作。
具体代码如下:
bool Set(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//将对应比特位设置为1_v[i] |= (1 << j);return true;}else return false;}1.2.2 ReSet
Reset这个接口与Set相反,是将整型对应的比特位置0.
第一步依旧是定位到对应的比特位,这一个与Set接口相同。第二步则是将对其比特位设置为0,大致思路是将对应整型左移j位0,但是我们只有左移1的操作,于是我们可以先将1左移j位,在对其进行取反,就可以得到只有对应位置为0,其余位置为1,最后再将我们的第i个整型对其进行与等,这样就可以实现对应位置设置为0,其余位置不变。
eg:我们想要对第i个整型的第1个比特位置0
1100 0010(操作前第i个整型)
1111 1101
1100 0001 (操作后第i个整型)
具体实现如下:
bool Reset(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//将对应比特位设置为0_v[i] &= (~(1 << j));return true;}else return false;}1.2.3 Text
Text的功能是来判断给定整型是否存在。
实现的第一步依旧同前两个接口一样,找到给定整型对应的第i个整型的第j个比特位。第二步再去查询该比特位所对应的值,为1则说明要查询的整型存在,为0则说明不存在,那么该如何拿到比特位上的值呢,需要将该比特位上的数与1进行与操作即可,通过将1进行左移j位再与第i个整型进行与操作后即可。
eg:查询第3位
0000 1000(操作前) 0000 0010(操作前)
0000 1000 0000 1000
0000 1000 (操作后) 0000 0000(操作后)
具体代码如下:
bool text(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//查询对应比特位的数据return _v[i]&(1<<j);}else return false;}1.3 位图的应用
位图的一些应用场景如下:
1. 排序 + 去重
2. 操作系统中磁盘块标记
3. 求两个集合的交集、并集等
4. 快速查找某个数据是否在一个集合中
2.布隆过滤器
2.1布隆过滤器的提出
我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的? 用服务器记录了用 户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
1. 用哈希表存储用户记录,缺点:浪费空间
2. 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理 了。
3. 将哈希与位图结合,即布隆过滤器
2.2 布隆过滤器概念
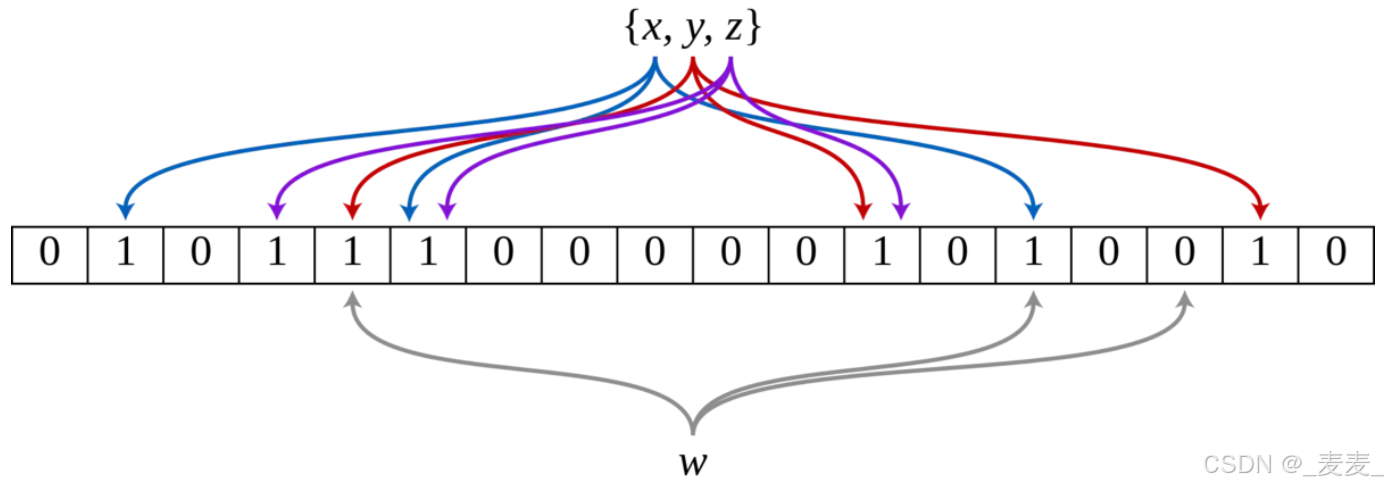
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
2.3 布隆过滤器的实现
2.3.1布隆过滤器的插入
在了解完什么是布隆过滤器之后,我们知道了为了减少减少误判率,一个关键词往往会对应多个地址,那么我们该如何实现它呢,即布隆过滤器的插入。
首先第一步,我们需要几个哈希函数来实现对于同一个关键词我们可以得到不同的地址。本文我们主要针对关键词为字符串,故可以采取字符串Hash函数,下面链接中有各种不同的字符串Hash函数,笔者选择其中三个不易产生哈希冲突的函数。各种字符串Hash函数
第二步就是通过哈希函数拿到的不同地址进行位图的操作,即在对应比特位上置1,在这里,我们就可以复用上面位图的Set接口。
具体示例图和代码如下:
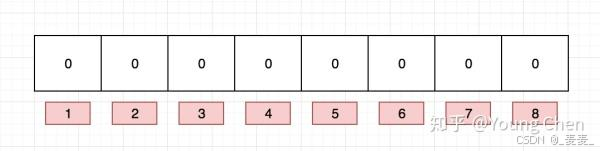
向布隆过滤器中插入:“baidu”
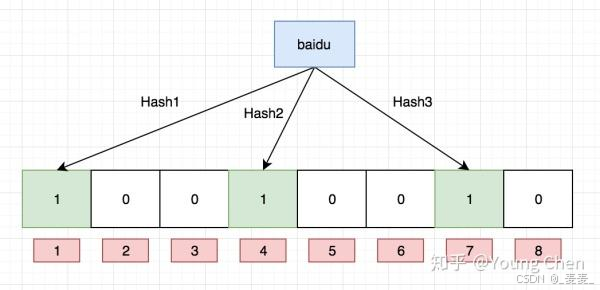
向布隆过滤器中插入“tencent”
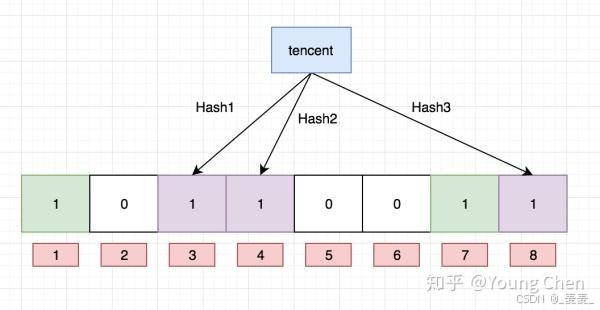
void Set(const K& key) { size_t Hashi1 = HashFun1()(key)%N; _bs.Set(Hashi1); size_t Hashi2 = HashFun2()(key)%N; _bs.Set(Hashi2); size_t Hashi3 = HashFun3()(key)%N; _bs.Set(Hashi3); //cout << s << ":" << Hashi1 << "-" << Hashi2 << "-" << Hashi3 << endl; }2.3.2 布隆过滤器的查找
布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。
比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
具体代码如下:
bool Text(const K& key) { if (!_bs.text(HashFun1()(key)%N)) return false; else if (!_bs.text(HashFun2()(key)%N)) return false; else if (!_bs.text(HashFun3()(key)%N)) return false; else return true; }2.3.3 布隆过滤器的删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。 一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储 间的代价来增加删除操作。
缺陷:
1. 无法确认元素是否真正在布隆过滤器中
2. 存在计数回绕
2.3.4 布隆过滤器优点
1. 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无 关
2. 哈希函数相互之间没有关系,方便硬件并行运算
3. 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
4. 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
5. 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
6. 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
2.3.4 布隆过滤器缺陷
1. 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再 建立一个白名单,存储可能会误判的数据)
2. 不能获取元素本身
3. 一般情况下不能从布隆过滤器中删除元素
4. 如果采用计数方式删除,可能会存在计数回绕问题
3.海量数据面试题
在了解完位图和布隆过滤器后,小伙伴们看看下面几道有关海量数据的面试题,看看能否有思路,笔者的拙见会在下一节中为大家揭晓。
3.1哈希切割
Q:给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
3.2位图应用
Q1:给定100亿个整数,设计算法找到只出现一次的整数?
Q2:给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
Q3:位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
3.3布隆过滤器
1. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法
2. 如何扩展BloomFilter使得它支持删除元素的操作
三、全部代码
//BloomFilter.h#include <bitset>#include <string>#include <vector>struct BKDRHash{ size_t operator()(const string& str) { size_t hash = 0; for (auto ch : str) { hash = hash * 131 + ch; } //cout <<"BKDRHash:" << hash << endl; return hash; }};struct APHash{ size_t operator()(const string& str) { size_t hash = 0; for (size_t i = 0; i < str.size(); i++) { size_t ch = str[i]; if ((i & 1) == 0) { hash ^= ((hash << 7) ^ ch ^ (hash >> 3)); } else { hash ^= (~((hash << 11) ^ ch ^ (hash >> 5))); } } //cout << "APHash:" << hash << endl; return hash; }};struct DJBHash{ size_t operator()(const string& str) { size_t hash = 5381; for (auto ch : str) { hash += (hash << 5) + ch; } //cout << "DJBHash:" << hash << endl; return hash; }};namespace mine{ template<size_t N ,class K=string ,class HashFun1 = BKDRHash ,class HashFun2 = APHash ,class HashFun3 = DJBHash> class BloomFilter { public: void Set(const K& key) { size_t Hashi1 = HashFun1()(key)%N; _bs.Set(Hashi1); size_t Hashi2 = HashFun2()(key)%N; _bs.Set(Hashi2); size_t Hashi3 = HashFun3()(key)%N; _bs.Set(Hashi3); //cout << s << ":" << Hashi1 << "-" << Hashi2 << "-" << Hashi3 << endl; } bool Text(const K& key) { //cout << s << ":" << HashFun1()(key)%N << "-" << HashFun2()(key)%N << "-" << HashFun3()(key)%N << endl; //cout << s << ":" << _bs.text(HashFun1()(key)%N) << "-" << _bs.text(HashFun2()(key)%N) << "-" << _bs.text(HashFun3()(key)%N) << endl; if (!_bs.text(HashFun1()(key)%N)) return false; else if (!_bs.text(HashFun2()(key)%N)) return false; else if (!_bs.text(HashFun3()(key)%N)) return false; else return true; } private: bitset<N> _bs; }; void text3() { BloomFilter<20> BF; //注改成11后,牛魔王会发生误判 vector<string> v1 = { "孙悟空","白龙马","猪八戒","唐三藏" }; for (auto& s : v1) { BF.Set(s); } cout << endl; vector<string> v2 = { "孙悟空","牛魔王","猪八戒","白骨精" }; for (auto& s : v2) { BF.Text(s); cout << s << ":" << BF.Text(s) << endl; } }}//BitSet.h#pragma once#include <vector>namespace mine{template<size_t N>class bitset{public:bitset(){_v.resize((N / 32) + 1);}bool Set(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//将对应比特位设置为1_v[i] |= (1 << j);return true;}else return false;}bool Reset(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//将对应比特位设置为0_v[i] &= (~(1 << j));return true;}else return false;}bool text(size_t val){if (val / 32 + 1 <= _v.size()){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//查询对应比特位的数据return _v[i]&(1<<j);}else return false;}private:vector<int> _v;};template<size_t N>class twobitset{public:// 00->未出现 01->出现一次 10->出现两次 11->出现两次以上void Set(size_t val){//第几个整型size_t i = val / 32;//第几个比特位size_t j = val % 32;//设置比特位//00->01if (!_bs1.text(val) && !_bs2.text(val)){_bs2.Set(val);}//01->10else if (!_bs1.text(val) && _bs2.text(val)){_bs1.Set(val);_bs2.Reset(val);}//10->11else if (_bs1.text(val) && !_bs2.text(val)){_bs2.Set(val);}//11->11else {}}//01bool is_once(size_t val){return !_bs1.text(val) && _bs2.text(val);}private:bitset<N> _bs1;bitset<N> _bs2;};//测试bitsetvoid text1(){bitset<SIZE_MAX> bs;int arr[] = { -5,1,5,8,7,9,6,2,3 };for (auto e : arr){bs.Set(e);}for (size_t i = 0; i < SIZE_MAX; ++i){if (bs.text(i)) cout << (int)i << " ";}cout << endl;bs.Reset(5);bs.Reset(9);for (size_t i = 0; i < 10; ++i){if (bs.text(i)) cout << (int)i << " ";}cout << endl;}//测试twobitsetvoid text2(){twobitset<15> tbs;int arr[] = { 1,1,2,5,8,6,6,10 };for (auto e : arr){tbs.Set(e);}cout << "只出现一次的数字" << ":";for (size_t i = 0; i < 15; ++i){if(tbs.is_once(i)) cout<<i<<" ";}cout << endl;}}//text.c#include <iostream>using namespace std;#include "BitSet.h"#include"Bloomfilter.h"int main(){//mine::text1();//mine::text2();mine::text3();return 0;}四、结语
到此为止,关于位图和布隆过滤器的内容就告一段落了,到此为止有关哈希的全部内容就全部完结啦,有关C++的其他内容小伙伴们敬请期待呀!
关注我 _麦麦_分享更多干货:_麦麦_-CSDN博客
大家的「关注❤️ + 点赞? + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下期见!