使用onnxruntime-web 运行yolov8-nano推理
ONNX(Open Neural Network Exchange)模型具有以下两个特点促成了我们可以使用onnxruntime-web 直接在web端上运行推理模型,为了让这个推理更直观,我选择了试验下yolov8 识别预览图片:
1. 跨平台兼容性
ONNX 是一种开放的格式,可以在不同的深度学习框架之间共享模型,如 PyTorch、TensorFlow、MXNet 和 Caffe2。这使得用户可以在一个框架中训练模型,然后在另一个框架中进行推理。
2. 模型标准化
ONNX 提供了一种标准化的模型表示,定义了操作符、数据类型和模型结构。这种标准化使得不同工具和库可以一致地理解和处理模型。
3. 高效性
ONNX 模型在推理时通常能够实现更高的效率,特别是在使用 ONNX Runtime 时。ONNX Runtime 是一个高性能的推理引擎,支持多种硬件加速(如 GPU、TPU 等)。
YOLOv8n 是 YOLOv8 系列中的 "nano" 版本,通常是指模型较小,参数较少,计算需求低。适合在资源受限的环境中使用,如移动设备和嵌入式系统。
首先需要下载这两个模型
yolov8n.onnx
nms-yolov8.onnx
https://huggingface.co/SpotLab/YOLOv8Detection/blob/3005c6751fb19cdeb6b10c066185908faf66a097/yolov8n.onnx
关于这两个模型可以多说两句,YOLOv8 和非极大值抑制(NMS)是目标检测任务中的两个关键组成部分。它们一起工作,以实现高效且精确的目标检测。以下是它们如何协同工作的详细说明:
1. YOLOv8 的工作原理
目标检测:YOLOv8 模型接收输入图像,并通过其深度神经网络对图像进行处理,生成多个候选边界框和相应的置信度分数。这些边界框用于定位检测到的对象。多类别检测:模型还能为每个边界框预测对象的类别,通常是通过 softmax 函数生成类别概率。2. NMS 的作用
去除冗余检测:由于模型可能会为同一对象生成多个重叠的边界框,NMS 被用来过滤这些冗余的框。NMS 通过以下步骤工作: 排序:根据置信度分数对所有预测框进行排序,选择置信度最高的框作为参考框。计算重叠:计算参考框与其他框之间的交并比(IoU)。阈值过滤:如果其他框与参考框的 IoU 超过设定的阈值,则认为这些框是冗余的,并将其移除。重复处理:对剩余框重复上述过程,直到所有框都被处理完。3. 工作流程
输入图像:将图像输入到 YOLOv8 模型。生成候选框:模型输出多个候选边界框和相应的置信度分数。应用 NMS: 将所有候选框传递给 NMS。NMS 处理并返回最终的边界框和类别标签,去除了冗余框,确保每个对象只保留一个最优框使用python 代码进行检测的时候是这样用的
# 假设 model 是 YOLOv8 模型,image 是输入图像boxes, scores, class_ids = model.predict(image)# 应用 NMSfinal_boxes, final_scores, final_class_ids = nms(boxes, scores, threshold)# 结果可视化for box, score, class_id in zip(final_boxes, final_scores, final_class_ids): draw_box(image, box, score, class_id)在web项目里使用onnxruntime-web 要简单些
import React, { useState, useRef } from "react";import cv from "@techstark/opencv-js";import { Tensor, InferenceSession } from "onnxruntime-web";import Loader from "./components/loader";import { detectImage } from "./utils/detect";import { download } from "./utils/download";import "./style/App.css";const App = () => { const [session, setSession] = useState(null); const [loading, setLoading] = useState({ text: "Loading OpenCV.js", progress: null }); const [image, setImage] = useState(null); const inputImage = useRef(null); const imageRef = useRef(null); const canvasRef = useRef(null); // Configs const modelName = "yolov8n.onnx"; const modelInputShape = [1, 3, 640, 640]; const topk = 100; const iouThreshold = 0.45; const scoreThreshold = 0.25; // wait until opencv.js initialized cv["onRuntimeInitialized"] = async () => { const baseModelURL = `${process.env.PUBLIC_URL}/model`; // create session const url =`${baseModelURL}/${modelName}` console.log(`url:${url}`) const arrBufNet = await download( url, // url ["加载 YOLOv8", setLoading] // logger ); const yolov8 = await InferenceSession.create(arrBufNet); const arrBufNMS = await download( `${baseModelURL}/nms-yolov8.onnx`, // url ["加载 NMS model", setLoading] // logger ); const nms = await InferenceSession.create(arrBufNMS); // warmup main model setLoading({ text: "model 预热...", progress: null }); const tensor = new Tensor( "float32", new Float32Array(modelInputShape.reduce((a, b) => a * b)), modelInputShape ); await yolov8.run({ images: tensor }); setSession({ net: yolov8, nms: nms }); setLoading(null); }; return ( <div className="App"> {loading && ( <Loader> {loading.progress ? `${loading.text} - ${loading.progress}%` : loading.text} </Loader> )} <div className="header"> <h1>onnxruntime-web 测试</h1> </div> <div className="content"> <img ref={imageRef} src="#" alt="" style={{ display: image ? "block" : "none" }} onLoad={() => { detectImage( imageRef.current, canvasRef.current, session, topk, iouThreshold, scoreThreshold, modelInputShape ); }} /> <canvas id="canvas" width={modelInputShape[2]} height={modelInputShape[3]} ref={canvasRef} /> </div> <input type="file" ref={inputImage} accept="image/*" style={{ display: "none" }} onChange={(e) => { // handle next image to detect if (image) { URL.revokeObjectURL(image); setImage(null); } const url = URL.createObjectURL(e.target.files[0]); // create image url imageRef.current.src = url; // set image source setImage(url); }} /> <div className="btn-container"> <button onClick={() => { inputImage.current.click(); }} > 打开图片 </button> {image && ( /* show close btn when there is image */ <button onClick={() => { inputImage.current.value = ""; imageRef.current.src = "#"; URL.revokeObjectURL(image); setImage(null); }} > 关闭图片 </button> )} </div> </div> );};export default App;session 用于存储模型的推理会话。loading 用于管理加载状态和进度。image 存储用户选择的图像。inputImage、imageRef 和 canvasRef 是对 DOM 元素的引用。 上面加载的顺序是 在 OpenCV.js 加载完成后,异步加载 YOLOv8 和 NMS 模型。使用 download 函数从指定 URL 下载模型,并创建推理会话。模型有个预热的过程
创建一个形状为 const modelInputShape = [1, 3, 640, 640] 的空张量,并运行一次模型以进行预热,确保模型准备就绪。
页面使用 <canvas> 元素来绘制检测结果。
运行测试下效果
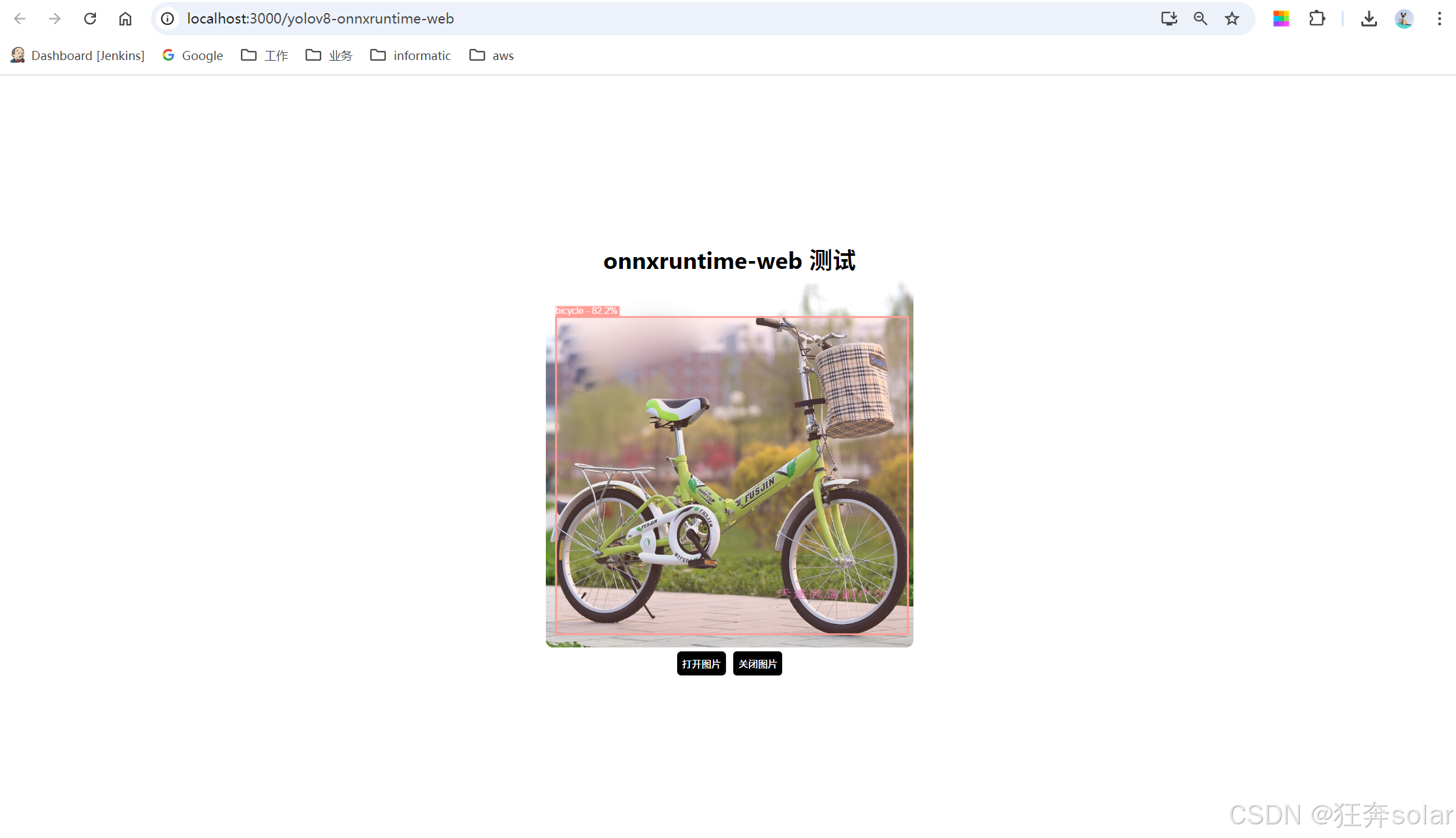
web使用onnx这个事给我很多启发,之前训练的一些模型完全可以在前端就实现推理
登录后可发表评论
点击登录